基于機器學習的遙感圖像超分辨綜述
2021-07-14 16:21:26張凱兵
計算機工程與應用 2021年13期
李 正,劉 薇,張凱兵
西安工程大學 電子信息學院,西安710048
目前,遙感成像技術已廣泛應用于目標匹配與檢測、土地覆蓋分類、超分辨土地覆蓋制圖、城市經濟水平評價、資源勘查等方面[1]。然而,由于遙感圖像的拍攝往往覆蓋廣闊的空間面積,即使圖像整體具有高的空間分辨率,分配到單個空間景物的分辨率仍難以將其清晰呈現,導致目標測量及識別時的誤差,這也成為限制其應用的關鍵瓶頸之一[1-2]。
提高遙感圖像的空間分辨率需要面對實現和價格兩方面的困難[3]。因此,通過軟件算法將已有低分辨率遙感圖像重建成高分辨率遙感圖像[2-4],成為解決該問題的另一可行出路,代表為超分辨率圖像重建技術。
超分辨(Super-Resolution,SR)的思想是20 世紀60年代提出的[5]。超分辨重建的一般思路是模擬退化過程,重建求解HR(High Resolution)圖像為退化模的逆過程。圖像退化的公式可表示為:

其中,g代表LR 圖像,H表示退化矩陣,H由下采樣矩陣、模糊矩陣、運動扭曲矩陣共同構成,z表示原始HR圖像,n代表著隨機高斯白噪聲。
早期的針對遙感圖像的SR 方法可大致分為:基于插值、基于重建和基于學習的方法。基于插值的方法[6-8]是非迭代的空域超分辨率重建方法,其核心是先將LR遙感圖像配準到HR圖像的網格上,然后運用非均勻插值得到HR遙感圖像每一個像素的值。基于重建的遙感SR方法[9-10]通常是需要將HR圖像退化處理為LR圖像,研究HR細節在低分辨下的表現,建立對應關系,最后構建模型來反應這種關系。典型的遙感SR重建算法是Li等[11]建立的小波域內的隱馬爾可夫鏈模型。由于相較于自然圖像,LR遙感圖像嚴重缺乏高頻細節信息,采用基于重建的方法僅能提升小的放大倍數[12]。
基于學習的SR方法[13]近年來發展迅速,其基于HR遙感圖像數據集,通過構建學習模型獲得先驗知識,從而重建HR遙感圖像。目前,基于學習的遙感SR方法主要為基于稀疏表示的方法和基于深度學習的方法兩類。基于稀疏表示的方法通過構建HR 和LR 字典,利用學到的字典和稀疏系數來重建HR遙感圖像[14]。深度學習領域有關算法,主要是通過卷積神經網絡(Convolution Neural Network,CNN)直接學習高低分辨率遙感圖像之間的映射關系,在定量和定性上都取得了顯著的改進。
目前遙感圖像的SR 重建仍然存在著以下挑戰[15]:遙感圖像難以配準;低頻信號模糊;模擬退化與實際不符合等等。本文主要對基于稀疏表示和基于深度學習的遙感圖像SR方法進行綜述。
1 基于稀疏表示的遙感SR方法
基于稀疏表示的方法認為高分辨圖像可以由學習到的字典進行稀疏表示而獲得。Yang 等[16]首次提出了基于稀疏表示的SR重建方法。該方法建立高低分辨率圖像塊的過完備字典,再求解L1范數稀疏正則化問題建立LR與HR之間的關系,測試階段利用LR圖像求得的稀疏系數α和HR 字典合成HR 圖像特征,具體過程如圖1所示。
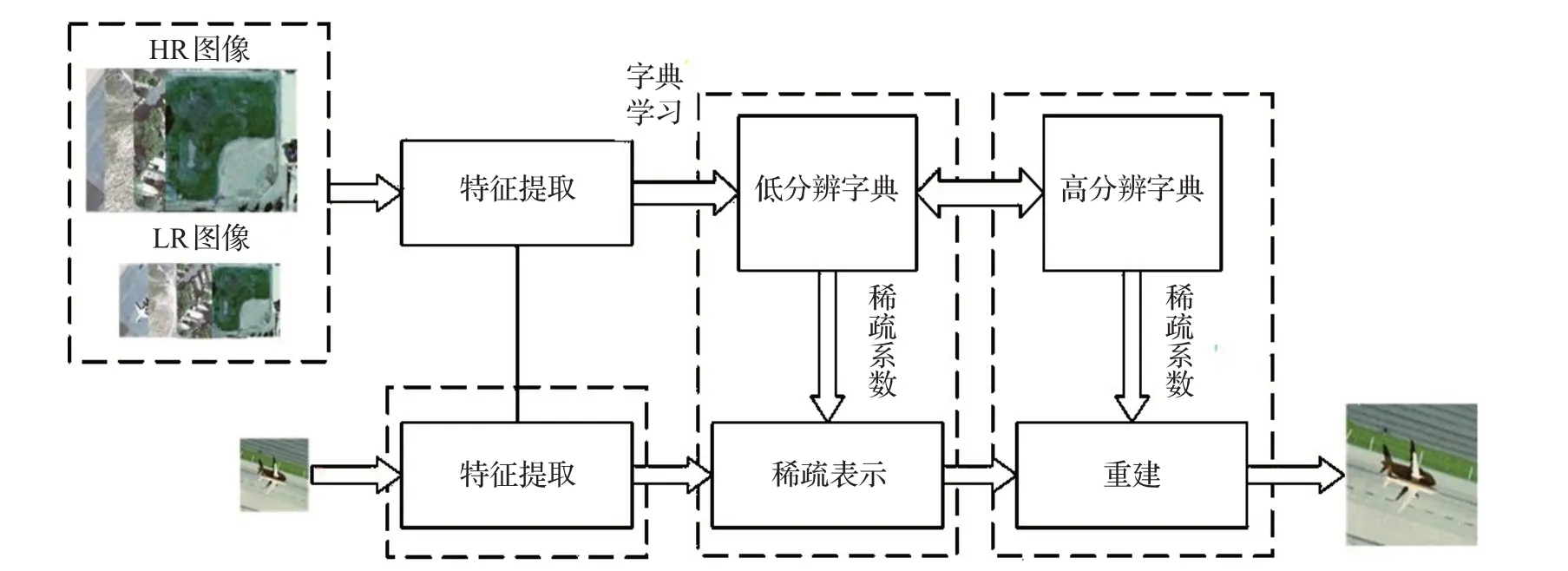
圖1 稀疏表示超分辨框架
1.1 基于聯合字典學習的遙感SR方法
Zheng等[17]首先將稀疏表示超分辨的方法應用到遙感圖像的超分辨重建中,并利用正交匹配追蹤(Orthogonal Matching Pursuit,OMP)[18]求解稀疏系數的同時抑制了噪聲。字典學習劃分圖像塊時會產生重疊區域導致SR 結果也產生了重疊,文獻[17]利用HR 和LR 遙感圖像的殘差圖像取得了一個新的約束,通過求解帶有重疊區域限制的高分辨字典,以此避免重建后像素估計不準確的問題。
稀疏表示方法需要建立退化模型來訓練圖像字典對,但是在對高分辨遙感圖像進行退化處理的過程中會丟失很多的信息。對此,Hou等[19]提出了基于稀疏表示和全局聯合字典模型(Global Joint Dictionary Model,GJDM)。通過細節圖像字典構建局部約束模型,用局部約束模型得到初始重建的SR 遙感圖像之后,結合相容項[20]和非局部自相似性[21]得到全局約束,增強了圖像塊之間的內在聯系,提高了模型的SR性能,并采用快速自適應收縮閾值算法解決了GJDM中的凸優化問題。
基于聯合字典的超分辨方法以圖像的稀疏性為基礎,利用字典學習的方式獲取高、低分辨率圖像之間共同的先驗信息,但高低分辨率字典共享稀疏系數,算法很難擬合LR和HR特征空間和系數[14]。
1.2 基于殘差字典學習的遙感SR方法
Zhang 等[22]認為經過訓練的字典是非結構化的,可能在某些結果圖像中產生振鈴效應。對此,其提出了針對遙感圖像的稀疏殘差字典學習方法。該方法認為可以用更基礎的字典,通過構建結構化的稀疏字典來減緩振鈴效應,并且通過學習原始高分辨遙感圖像與重建的高分辨遙感圖像的殘差字典,來重建殘差圖像補充圖像的細節信息。
由于成像的局限性,遙感圖像的HR 實例往往很難獲得,Gou 等[23]提出了一種只在LR 遙感圖像訓練字典對的方法。該方法利用圖像塊的結構相似性對特征圖像塊進行聚類,通過非局部均值濾波找到每個特征圖像塊的相似塊,加權得到估計圖像塊,并計算所有相似塊與其估計塊的得到殘差,從相似塊和其殘差部分訓練得到估計字典和殘差字典。最后,將改進后的圖像局部和非局部先驗作為約束正則化項,將光度信息、幾何信息和特征信息統一到重建框架中。
通過殘差圖像構建的殘差字典,使得先驗信息更加的精確,但殘差字典中的先驗信息相較于高低分辨字典更少,降低了超分辨的精確性。
1.3 基于單字典和多字典的遙感SR方法
Yang等[24]把壓縮感知理論和稀疏表示結合起來,將LR 圖像視為HR 圖像的壓縮文件,SR 過程視為解壓縮的過程,簡化了雙字典學習的方法提出了一種單字典學習的超分辨方法。該方法無需學習LR 字典,其要點在于通過LR 圖像求解稀疏系數,利用K-SVD(K-Singular Value Decomposition)[25]算法解出HR字典后,利用基追蹤算法(Basis Pursuit,BP)[26]求解帶有L1范數稀疏正則化的表示系數,最終通過表示系數和HR 字典重建SR圖像。
針對單一類型特征字典重建遙感圖像導致的偽影,Wu等[27]提出了一種學習多種類型特征的字典來表達圖像基本結構的SR 方法。該方法通過提取不同的特征,學習多個LR遙感圖像字典,通過這些字典重建LR圖像的誤差來指導其表示系數在重建HR 圖像時的貢獻權重,最終的HR圖像由HR特征圖疊加生成。
基于單字典的方法對于紋理簡單的圖像十分有效,但在紋理復雜的遙感圖像上具有一定的局限性,多字典的方法雖然能夠生成更精確的結果,但增加了計算量。
針對遙感圖像的基于稀疏表示的方法可以通過調整重構誤差項中的正則化系數來控制重構精度和抑制噪聲的能力,因此具有較高的靈活性和魯棒性。上述方法都需要學習特征字典,當圖像結構復雜需要較大的數據集時,此類方法要求的計算時間復雜度較高,且重建的質量與學習的字典的質量相關,面對結構復雜、缺少大量細節的遙感圖像,重建質量和SR 效率距離實際應用仍然有很大的差距。
2 基于深度學習的遙感圖像SR方法
2.1 有監督的深度學習遙感SR方法
2.1.1 基于CNN的遙感SR方法
2015年,Dong等[28]首次使用卷積神經網絡進行超分辨率重建。深度卷積神經網絡因其實現端對端的全局最優求解以及優越的性能表現,被廣泛使用在SR領域。
Liebe[29]將SRCNN(Super Resolution Convlution Neural Network)[28]引入了遙感圖像的超分辨中。因為地面采樣間隔大,遙感圖像SR 不能直接使用自然圖像高低分辨率之間的映射關系,因此作者利用SENTINEL-2 圖像(含有13 個頻帶,可達10 m)制作了遙感數據集,使用此數據集對SRCNN 重新進行了訓練,使其能夠學習到遙感圖像高低分辨率圖像之間的關系,得到了具有處理高輻射分辨率的多光譜衛星圖像的能力的網絡模型msiSRCNN(multispectral satellite images SRCNN)。
由于遙感圖像局部細節信息缺失嚴重,而普通的CNN超分辨方法往往只使用感受野較大的深層的特征進行SR 重建,忽略了局部信息,Lei 等[30]針對此問題設計了一種“分支”結構的網絡(Local-Global Combined Network,LGCnet),來學習遙感圖像的多尺度表示,利用CNN 隨著網絡深度加深感受野隨之擴大的特點,通過級聯淺層和深層的特征映射來實現局部與全局信息的結合,從而更好地指導遙感超分辨重建。
LGCnet 級聯了深度不同的卷積層,但并未改變卷積核的大小,Qin等[31]鑒于GoogLeNet[32]提出了級聯不同卷積核的多尺度卷積網絡(Multi-Scale Convolutional Neural Network,MSCNN)。在特征提取階段同時利用不同大小的卷積核多尺度提取圖像不同角度的特征,將提取到的特征進行通道拼接之后,利用深層次卷積將這些特征進行融合,得到更加全面的深度特征從而提高模型的SR效果。
上述兩種方法雖然都對遙感圖像局部信息缺失的特點的問題進行了研究,但兩者為了保證特征圖像能夠融合,都在卷積時對特征圖進行了填充,至此特征圖像含有較多的噪聲信號,導致模型訓練難度增加,且不利于最終SR圖像的重建。另外,上述方法網絡層數少,而遙感圖像結構復雜的同時信息量較大,因而網絡不能很好的擬合遙感圖像的高低分辨率之間的關系,影響SR結果的精確性。
2.1.2 基于殘差學習的遙感SR方法
為了解決網絡層數的加深,導致梯度爆炸和梯度消失的問題,He等[33]提出了殘差網絡。Pan等[34]受到Haris等提出的深度反投影網絡(Dense Back-Projection Networks,DBPN)[35]的啟發,提出了一種基于殘差稠密網絡的方法(Residual DBPN,RDBPN)。該方法在DBPN投影單元的基礎上添加了稠密的跳躍連接,從而構建了全局和局部殘差,并通過特征的復用為高倍放大提供了信息,因此使其在高倍放大時顯示出較好的性能。
針對大尺度超分辨需要大量的特征信息,文獻[34]利用了稠密殘差鏈接來實現特征的復用,Dong 等人[36]認為僅利用網絡末端的特征,限制了SR重建的效果,設計了稠密采樣機制(Dense Sampling Super Resolution,DDSR),將網絡不同深度的特征都傳遞到最終的上采樣模塊中進行最終的重建。該方法為了充分利用不同的特征,在網絡殘差塊中拓寬了通道注意力機制的輸入,并采用了鏈式訓練策略,以小比例因子的模型作為大比例超分辨的初始化參數以簡化訓練,提高性能。該方法對于大比例放大具有明顯的優勢。
針對遙感高分辨圖像數據缺乏的問題,為了不增加參數且保持模型性能,Haut等[37]把視覺注意力機制融入到基于殘差的網絡設計中(Remote Sensing Residual Channel Attention Network,RSRCAN),該機制可以引導網絡訓練過程朝向信息量最大的特征。注意力模塊通過增強圖像高頻信息,抑制低頻信息,從而讓模型的去更多學習高頻分量之間的映射關系,集中在需要更精細HR細節相關的地表特征上。
考慮到注意力機制能夠挖掘遙感圖像的高頻信息,Zhang 等[38]提出了高階混合注意力機制(Mixed High-Order Attention Network,MHAN)。在特征提取階段通過核為1的卷積給不同層次的卷積施加權重,保留了更重要的信息。在特征細化階段增加了頻率感知鏈接,通過高階注意力模塊將不同深度的特征進行融合提煉,以生成更豐富的高階特征。
針對遙感圖像場景差異大,且目標物尺寸差異大的問題,Zhang等[39]用遷移學習的方法對不同場景的HR和LR 遙感圖像進行建模(Multiscale Attention Network,MASN)。通過AID 數據集訓練好基準模型后,對30 個場景下的映射關系進行模型微調,最終獲得30個模型,對不同場景的遙感圖像能夠自適應的分配模型進行超分辨重建。該方法針對目標物尺寸差異大提出了多級激活特征融合模塊,采用了不同大小的卷積核提取不同尺度的特征,并利用通道注意力機制對不同尺度的特征進行了融合。此方法雖然取得了不錯的效果,但模型數量和參數量增加。
雖然網絡加深能夠提取到更抽象的特征,但目前大多數方法缺乏對淺層特征的利用。為了充分利用不同層次特征,Li 等[40]提出了群組并行鏈接模塊(Parallel-Connected Residual Channel Attention Network,PCRCAN)。在主干分支以外增加數個子分支進行特征提取,如此對相同的特征進行了多方面的提取,提高了信息利用的效率。
上述方法中的注意力機制雖然能夠加強網絡對重要特征的學習,但缺乏對同一特征不同空間區域的判別性學習能力。Lei等[41]提出了利用Iception模塊[32]提取不同尺度特征,結合通道注意力和空間注意力機制,學習區分重要特征的網絡(Inception Residual Attention Network,IRAN),再對每個特征圖的不同區域進行注意力分配。該方法能夠較為全面的對遙感特征進行判別性的學習,但增加了模型復雜度。
上述基于深度學習的方法都是在空間域進行重建的,并致力于學習LR 與HR 圖像中對應像素之間的關系,很少有研究將頻域的方法應用到深度學習當中。對此,Ma 等[42]將小波變換引入基于深度學習的遙感超分辨中,提出了結合小波變換的殘差遞歸網絡(Wavelet Transform Combined with Recursive Res-net,WTCRR)。該模型通過刪除DRRN(Deep Recursive Residual Network)[43]網絡的BN 層[44]得到。該方法利用小波變換對圖像在頻域進行分解,將小波分解得到的高頻分量和原始圖像一起作為網絡的輸入進行SR 映射。根據WTCRR中跳躍鏈接的方式,網絡中每個模塊都能夠使用原始特征,網絡末端能夠得到更加全面的深度特征來進行最終的小波逆變換SR重建。
基于殘差學習的超分辨方法雖然能夠有效提升SR結果的精確性,但網絡結構較為復雜,訓練時間較長,對數據的依賴性較高,在缺乏數據的情況下難以實現較好的結果。
2.1.3 基于生成對抗網絡(GAN)的有監督遙感SR方法
SRGAN[45]是設計專用于超分辨的GAN(Generative Adversarial Network),SRGAN能夠利用感知損失將SR結果推送到自然圖像的流形上,以得到更符合人類視覺感知的圖像,借助GAN的訓練策略能夠使SR生成器生成更加符合人的感知的圖像。鑒于SRGAN取得的優異效果,以下方法利用GAN的思想,使遙感圖像超分辨效果更符合人眼的觀測效果。
遙感圖像的退化過程受到很多因素的影響,往往包含較多的噪聲,而基于GAN 的原始方法對噪聲較為敏感,會產生與輸入圖像無關的高頻噪聲。在土地覆蓋分類,地面目標識別等高級計算機視覺任務中,該問題會降低準確性[46]。對此,Jiang 等[47]從邊緣增強的角度,提出了EEGAN(Edge-Enhanced GAN)。首先使用改良的稠密殘差塊組成生成網絡;生成SR 基準圖像后;通過Laplacian 算子構建的邊緣增強網絡,提取SR 基準圖像的邊緣并對其增強;得到增強的邊緣后于SR 基準圖像融合生成邊緣清晰的HR遙感圖像,以此緩解遙感圖像目標地物邊緣模糊的問題。
與自然圖像相比,遙感圖像有更多的平坦區域和更多的低頻圖像成分,使用GAN 對遙感圖像進行SR 時,判別器很難判斷這些圖像區域是從真實的HR遙感圖像生成還是采樣得到的(分辨模糊問題),導致生成HR遙感圖像質量受到影響。對此Lei 等[48]設計了一種新的GAN網絡:耦合鑒別GAN(Coupled-Discriminate GAN,CDGAN)網絡;通過構建雙通道網絡將真實HR圖像和SR 圖像同時輸入判別器,將雙通道網絡提取到的特征進行拼接輸入后續層中,并構建了專用的耦合損失函數來更新網絡參數,該模型增強了對遙感圖像低頻區域的鑒別力,改善了基于GAN的圖像SR方法在處理低頻圖像區域時分辨模糊的現象。
Yu 等[49]以DBPN[35]為基礎構建了生成器網絡E-DBPN(Enhanced-DBPN),并在其中加入了改進的殘差通道注意力機制,以促進網絡擁有對特征的判別性學習能力,從而保持對SR更有貢獻的特征。同時,設計了順序特征融合模塊,以漸進融合的形式處理上投影單元的特征映射。該方法利用了DBPN 的誤差反饋機制對LR和HR的深層關系進行了探索,以對抗生成策略加強了模型的SR性能。
基于GAN 的有監督學習方法,能夠有效提高生成的HR圖像的感知質量,但需要借助判別器網絡,增加了訓練的難度。在上述方法中EEGAN[47]對遙感圖像中地物的邊緣采取了強化,忽略了平坦區域的信息,CDGAN[48]對遙感圖像中較為平坦的區域進行增強,忽略了邊緣信息,而E-DBPN 缺乏對遙感圖像空間信息的判別性處理,對遙感圖像中微小細節的恢復能力不足。上述3種方法都只對遙感圖像中的一項特征進行增強,在實際應用時,有一定的局限性。
2.1.4 有監督深度學習遙感SR方法的分析對比
表1將有監督的深度學習遙感SR網絡模型的原理進行了解析,將每個模型的優點和不足進行了對比。

表1 有監督深度學習遙感SR方法對比
2.2 基于深度學習的遙感SR無監督方法
有監督學習的網絡結構實現了從LR 圖像到HR 圖像的映射,但高分辨遙感圖像通常難以獲取,且退化得到的圖像與實際的低分辨遙感圖像仍存在差異,而無監督的方法能夠在不使用任何其他外部數據的情況下對每個特定的LR 輸入圖像進行超分辨率處理,Haut 等[50]從無監督的角度對遙感數據進行SR重建,構建了SR遙感圖像的生成網絡模型(A New Deep Generative Network,ANDGN)。該方法首先將隨機噪聲擴張到目標HR維度,通過生成網絡補充圖像信息,利用網絡生成的HR 結果下采樣之后和原始LR 遙感圖像構建了迭代的損失函數以確保生成HR 圖像與LR 圖像相對應,在之后的迭代中將生成的圖像作為網絡輸入,通過反復的迭代直至生成最終需要的HR遙感圖像。
Wang等[51]基于CycleGAN[52]提出了一種用于遙感圖像SR的無監督學習網絡CycleCNN,該網絡包含圖像退化網絡和圖像超分辨網絡。在退化網絡中用GaoFen-2中GSD為1 m/pixel的全色圖像作為HR進行退化;在超分辨網絡中,將GSD為4 m/pixel的多光譜(MS)中的前3個波段轉換到YCbCr顏色空間,用作LR進行超分辨重建。將退化和超分辨網絡得到圖像又分別輸入超分辨和退化網絡中,構建循環損失函數,從而使退化網絡能夠退化出更真實的低分辨圖像,提高超分辨網絡的性能。
在文獻[50]的啟發下,Zhang 等[53]提出了一種基于GAN的無監督遙感圖像超分辨網絡模型(Unsupervised GAN,UGAN)。該網絡直接用LR遙感圖像作為生成網絡的輸入,采用核尺寸逐漸減小的卷積層提取不同尺度的特征,為無監督的SR保留了更多的信息,并通過計算每幅圖像及其高層特征的L1損失和SSIM損失,改進了損失函數。
在上述方法中,文獻[51]用不同的采樣間隔的數據集作為生成器和退化模型的輸入以模擬HR 和LR 圖像,與真實數據仍有一定的差距。而文獻[53]中采用平均池化,雖然能夠提高退化模型的泛化能力,但影響遙感圖像退化的因素眾多,池化不能完全表示退化模型。針對遙感圖像復雜的退化情況,Zhang 等[54]提出先用大量的合成退化的數據集來訓練一個退化模型,而后設計了生成器模型將原始遙感圖像先進行SR 再進行退化,以退化結果和原始LR的遙感圖像做差形成損失函數優化網絡。該網絡(Multi-Degradation GAN,MDGAN)能夠較為真實的模擬出退化過程,但遙感圖像退化與自然圖像退化仍有較大的差別,模擬遙感圖像退化需要考慮成像、大氣等因素,建模較自然圖像更為困難。
基于深度學習的遙感SR 方法能夠直接學習到LR遙感和HR 遙感圖像之間的關系。但在有監督的遙感SR 方法中,模型訓練需要對原始圖像進行人工下采樣得到訓練數據,人工下采樣得到的數據進行SR 之后和原始遙感圖像做差建立損失函數。這樣構建的模型是不合理的,現實中存在的LR 遙感圖像與HR 遙感圖像之間的關系復雜,只用人工下采樣來模擬,SR 效果有限。而基于深度學習的無監督的遙感SR方法性能并不顯著,與有監督的方法相比存在較大效果差異。
表2將無監督的深度學習遙感SR網絡模型的原理進行了解析,將每個模型的優點和不足進行了比對。

表2 無監督深度學習遙感SR方法對比
3 衡量算法性能的指標
峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)[55],是一個表示最大信號功率和影響它的背景破壞性噪聲功率的比值,PSNR基于對應像素點間的誤差,即基于誤差敏感的圖像質量評價。PSNR越大表示重建圖像的質量越高,通常將其作為衡量SR重建性能的重要指標。
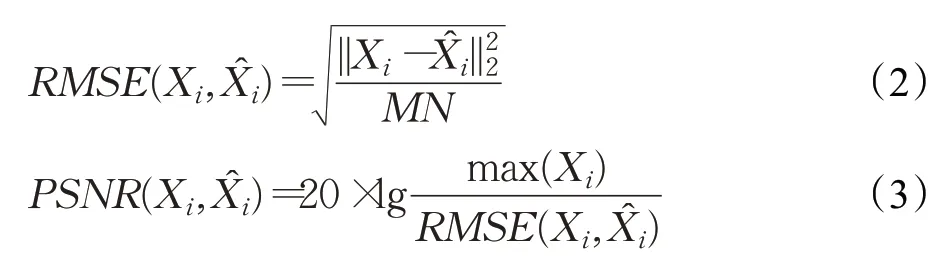
結構相似性指數(Structural Similarity index,SSIM)[56]從圖像組成的角度將結構信息定義為獨立于亮度、對比度的反映場景中物體結構的屬性,并將失真建模為亮度、對比度和結構3個不同因素的組合。用均值作為亮度的估計,標準差作為對比度的估計,協方差作為結構相似程度的度量。
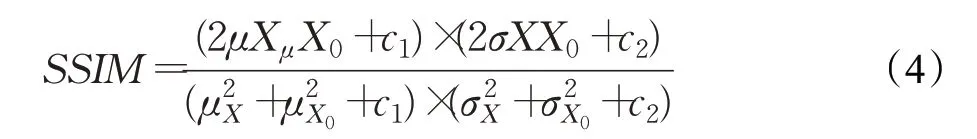
其中,μXμX0表示原始圖像X和生成圖像X0的均值,σX和σX0分別表示其標準差σXX0為兩個圖像間的協方差,c1和c2是為了避免分母為0維持穩定的常數。
3.1 性能指標對比
表3將本文出現的基于深度學習的遙感SR共用的性能指標進行了對比。

表3 深度學習遙感SR方法性能指標對比
LGCnet[30]和MSCNN[32],兩者網絡結構簡單計算效率高,綜合模型復雜度和SR效果比較,其模型更有可能在實際中應用。在大尺度因子的放大比較中,RDBPN[35]在×8比例SR遙感圖像中表現尚可,但在×4比例放大中并無明顯提升。MHAN[38]在×4和×8比例下性能優越,但在×2的效果略遜于DDSR[36]。在上述有監督的方法中,效果較好的是EEGAN[47]和IRAN[41],EEGAN在比例因子為×2、×3、×4的情況下都表現出顯著的優勢,證明了邊緣增強策略的有效性。IRAN 在×2、×3 上效果顯著,驗證了不同尺度特征對遙感圖像的SR重建的積極貢獻。無監督的方法中,PSNR和SSIM展現出的結果并不同步,PSNR最高的是ANDGN[50],而SSIM最高的是UGAN[53],但兩者并未出現明顯的優勢,證實了無監督的方法對于重建遙感圖像仍然存在較大的困難,但相比于有監督方法對已知的退化模型進行建模,無監督的方法更加適用于實際應用。
4 結束語
本文對基于機器學習的遙感圖像超分辨方法進行了綜述,將機器學習領域遙感超分辨的主流方法分為兩類:基于稀疏表示的遙感圖像SR 方法和基于深度學習的遙感圖像SR方法。對每個方法所針對的核心問題和解決方案進行了分析和總結。對基于稀疏表示的遙感SR 方法來說,字典特征的提取方式以及訓練字典的約束條件是其關鍵。針對遙感圖像的結構特點,可以通過學習與之相關的字典以及添加相關的正則項約束來優化算法,缺點是其重建效率會受到稀疏編碼計算效率的影響。基于深度學習的遙感SR 方法,其網絡結構以及損失函數的設置往往決定了SR的性能。此類方法利用卷積層提取深度特征,針對遙感圖像的特點可采用不同的特征提取策略來優化網絡的SR 性能,缺點是模型可解釋性弱,對數據的依賴度高。
這兩類方法的共同之處在于都在學習LR遙感圖像和HR遙感圖像之間的映射關系,優化遙感圖像特征的提取方式都能夠對SR效果產生一定的提升。基于深度學習的遙感SR 方法通過深度特征能夠直接構建LR 圖像和HR圖像之間的關系,而基于稀疏表示的方法則需要建立字典之間的關系,間接的表達高低分辨率圖像之間的關系。與基于稀疏表示的方法相比,基于深度學習的方法能更直接的表達高低分辨率之間的關系,且深度學習模塊靈活性高,訓練好的模型可以很快投入使用,因此該方法更容易推廣到實際應用當中。
綜上所述,基于機器學習的遙感圖像超分辨重建技術仍不夠成熟,依然存在許多亟待解決的關鍵問題,主要包括:
(1)原始HR遙感圖像難以獲取的問題。SR任務需要從LR 圖像重建HR 圖像,目前方法多利用標準數據集提供的HR-LR 對進行訓練和性能測試。然而,由于遙感圖像采集過程中大氣擾動、噪聲和運動等影響,真實的HR圖像難以獲得。因此,目前的方法距離實際使用還有一定的距離。
目前,基于GAN 網絡的方法試圖利用生成器克服這一困難,一些無監督的方法試圖通過學習退化過程得到HR圖像。考慮到遷移學習能夠從其他樣本中學得先驗,并在目標域中優化,可以從遷移學習和零樣本學習的方法中借鑒思路解決這一問題。
(2)遙感圖像較自然圖像,細節丟失更為嚴重。通常,遙感圖像單個像素所代表的實際距離超過5 m,導致圖像中細節損失,重建困難。對此,現有方法分別從局部-全局聯合特征提取、注意力機制、結合小波變換、邊緣增強等策略出發,試圖重建出更為豐富的細節信息。可以參考微小目標檢測的方法,對遙感圖像中的細微目標地物進行提取和增強,以緩解細節缺失的問題。
(3)遙感圖像場景內容差異較大。遙感拍攝往往涉及到多種地貌,因此會拍攝到多種場景內容,導致樣本的多樣性。因此,遙感數據集對于單個場景的貢獻也被削弱。這就要求所設計的方法對樣本的包容性更強,學習能力更強,即通過一個模型來描述不同場景下目標的HR與LR之間的關系。針對此問題,文獻[39]對30個不同的遙感場景進行了超分辨建模,但需要付出較大的計算和存儲代價。遙感SR模型的輕量化對于多場景建模具有重要意義。
(4)遙感圖像同一場景下,目標物空間大小差異較大。在一副遙感圖像中往往包含多個目標,且這些目標物的尺寸大小都不相同,如在街道場景中車輛可能只占了幾個像素,房屋占了幾百個像素,在卷積的過程中,可能丟失小目標的特征,從而影響SR 結果的精確性。因而,多級特征提取及特征融合在遙感SR 領域仍有重要的研究意義。
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
