基于優化策略和深度學習的低光照圖像增強
2021-07-16 05:51:02黃子蒙陳躍鵬
南昌大學學報(理科版) 2021年2期
黃子蒙,陳躍鵬
(1.武漢科技大學信息科學與工程學院,湖北 武漢 430081;2.武漢理工大學自動化學院,湖北 武漢 430070)
可見度高的圖像能夠呈現出目標場景的清晰細節,這對于基于視覺的自動駕駛技術來說是必不可少的,如車輛檢測[1],車道識別[2]等。然而,通常在低光條件下拍攝的圖像可見度很差,其實際應用價值受到限制。目前,國內外學者已經提出了許多圖像增強技術來增強低光照圖像,包括基于直方圖的方法[3-7],基于非線性單調函數的方法[8-9],灰度映射和基于濾波的方法[10-12],基于Retinex理論的方法[13-15]和基于去霧的方法[16-17]。雖然現有的方法能夠取得不錯的效果,但由于忽略或錯置非線性相機響應函數(Camera Response Function,CRF),可能導致圖像增強過度或增強不足。
Ren等人介紹了新相機響應特性的增強框架[18],通過估計圖像的亮度成分獲得最佳曝光率,然后根據相機響應功能模型獲得中等曝光增強效果。但是,與使用估計精確的三通道響應曲線相比,其方法中使用的固定攝像機響應曲線仍會產生增強圖像的失真。近年來,深度學習在計算機視覺領域取得了巨大成功[19-21]。與傳統算法相比,深度學習方法具有較強的自適應能力,可以通過優化策略獲得更強大的模型。
卷積神經網絡(CNN)在圖像恢復和增強應用中已經證明了其有效性。例如,Li等人訓練了深度卷積神經網絡(LightenNet)來執行低光圖像增強任務[19]。Guan等人試圖通過小波深度神經網絡去除圖像中的條紋噪聲[20]。在這些應用中,可以輕松生成與低質量圖像相對應的高質量圖像。使用這些成對的訓練數據,CNN可以用來學習低質量圖像與其相應的高質量參考圖像之間的映射函數。然而,對于移動設備來說,卷積神經網絡技術由于其計算復雜性和模型較大而難以部署。
針對以上問題,本文提出了一種新的融合相機響應模型與深度學習的低光照圖像增強方法,通過采用相機響應模型方法生成的數據集訓練一個專門設計的深度學習網絡用于對低光照圖像細節的進一步增強,并且通過實驗驗證該方法的有效性。
1 融合非線性相機響應函數模型的深度學習方法
1.1 方法流程
本文提出的融合非線性相機響應函數模型的深度方法,基本思路是:a)基于相機響應函數模型,根據輸入圖像估計最佳曝光率,對曝光不足的區域做增強曝光處理,生成增強曝光的中間圖像;b)設計一種輕量級反向殘差卷積神經網絡 (Lightweight Reverse Residual Convolutional Neural Network,LRNet)來預測中間圖像與參考圖像之間的殘差;c)在網絡的最后階段,將丟失細節信息的輸入圖像與預測的殘差圖像進行融合得到最終的增強圖像。
整個方法的流程圖如圖1所示。首先,中間圖像采用基于相機響應模型的方法來生成。隨后,提出了一種LRNet,它可以直接學習中間圖像與參考圖像之間的殘差映射,以恢復中間圖像的細節。

圖1 本文方法流程圖
1.2 基于相機響應模型的最佳曝光中間圖像生成
圖像的成像過程可用相機響應模型來解釋,相機響應函數(CRF)可用做描述相機響應模型,該模型刻畫了相機的曝光量E和圖像亮度值P之間的非線性關系[22],其定義為:
P=f(E)
(1)
式中f為相機響應函數。
設P和P¢分別是在同一場景下不同曝光量E和E¢拍攝的圖像,且E¢=kE,其中k為曝光比。P和P¢的關系可表示為:
P′=g(P,k)
式中g為亮度映射函數(Brightness Mapping Function,BMF),它刻畫同一場景下不同曝光的圖像之間的亮度非線性映射關系[23]。由式(1)可得,
P=f(E),P′=f(E′)=f(kE)
因此,CRF與BMF之間的轉換關系可以表示為:
g(f(E),k)=f(kE)
于是,相機響應模型也可以用BMF來表達。當BMF已知時,通過對圖像P設置不同的曝光比k來生成不同曝光的圖像P′,從而起到改變圖像像素曝光值的效果。
為了實現更好的增強效果需要找到最佳曝光比,利用式(2)獲到僅包含曝光不足的像素灰度值集合:
Q={I(x)|T(x)<τ1}
(2)
式中T(x)為I(x)的光照分量圖,τ1為區分曝光不足像素的灰度閾值。于是,曝光不足的像素點信息熵為:
H(Q)=-∑ipilog2pi
式中pi代表Q中每個灰度等級i出現的概率。這樣,由圖像信息熵最大化原則就可以求解最佳曝光率:
從而得到更加優化的增強曝光中間圖像:
P¢=g(P,k)=eb(1-ka)Pka
(3)
對于給定的相機,其BMF是固定的,參數也是固定的。本文使用文獻[18]中的參數a=-0.329 3,b=1.125 8,給定一幅輸入圖像,可以得到更加優化的增強曝光中間圖像。
1.3 通過LRNet恢復中間圖像的細節信息
通過輕量化網絡恢復中間圖像信息的方法如圖2所示。設P為待處理的低光照圖像,P′為生成的中間圖像,它可以用式(3)來表示。
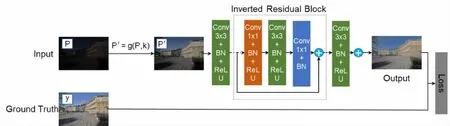
圖2 輕量化網絡恢復中間圖像細節
設y是圖像P的參考圖像,可以表示為
y=yl+yh
式中yl和yh分別是參考圖像中的低頻分量和高頻分量。基于深度學習方法通常使用端到端的方法來表示y。在此過程中,神經網絡必須保留所有輸入圖像的詳細信息,這對于許多權重層來說,需要長期儲存的端到端關系,容易出現梯度消失/爆炸的問題[24]。本文通過殘差學習來解決該問題。設y的初始圖像表現形式為F(P),它可以被視為已知的信息。設(y-F(P))為y′,即y的未知信息。則:
本文采用的LRNet如圖3所示,具有三種不同顏色的類型模塊,分別描述如下:
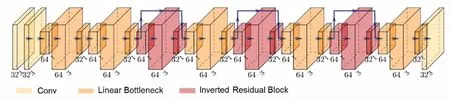
圖3 輕量級反向殘差卷積神經網絡結構
(1)卷積層模塊:(帶有標準化層和PReLU)采用了32個3×3的卷積核(stride 1,pad 1);
(2)線性瓶頸模塊:又由三個卷積層構成,第一卷積層(帶有標準化層和PReLU)采用64個1×1的卷積核,第二卷積層(帶有標準化層和PReLU)采用32個3×3的卷積核(stride 1,pad 1),第三卷積層(帶有標準化層)采用32個1×1的卷積核;
(3)反向殘差模塊:在線性瓶頸模塊的基礎上增加了捷徑。插入捷徑方式的動機與經典殘差連接的動機類似:希望提高梯度在乘數層之間傳播的能力[25]。反向殘差模塊有兩個優點:(1)重用特征以緩解特征退化;(2)減少計算量和參數數量。這樣處理不僅可以加快網絡的收斂速度,還可以減少訓練樣本的數量。由于池化在尺寸縮減過程中可能會丟失圖像信息,因此不會在網絡中使用。
2 實驗結果與分析
在本節中,通過構建道路圖像數據集,并使用Caffe來訓練LRNet。為了評估本文方法優勢,先后通過對自制數據集和公共數據集SICE[26]進行訓練,并將訓練結果與五種現有的低光照圖像增強方法進行了比較。
2.1 自制數據集上的比較
本文自制數據集的圖像包含500個在真實場景中捕獲的低曝光/中曝光圖像對,其中部分如圖4所示:第一行為低光照圖像,第二行為參考圖像。為了避免受到其他因素干擾,只更改曝光時間,同時固定相機的其他配置。在室外環境中,拍攝移動物體(如行人、車輛和搖曳的樹木)很難獲得一個對齊良好的序列。因此需要通過使用三腳架防止相機抖動,并使用連續包圍模式自動捕獲一系列曝光圖像,以確保只改變曝光。本文通過數據集中圖像的多樣化,包括街道、道路標識、建筑等場景,來表明LRNet方法的魯棒性。最后,本文隨機將數據集中的圖像分為兩個子集:460個圖像用于訓練,其余的圖像用于測試。

圖4 部分自制數據集
將本文的方法與五種現有的低光照增強方法,如:LIME[16]、NPE[27]、Dong[17]、LECARM[18]和 RetinexNet[28]進行比較。如圖5所示,LIME方法處理后的圖像非常明亮,許多明亮的區域已經飽和。NPE方法處理后的圖像在亮度較高區域產生了較為嚴重的失真。Dong方法處理后的圖像有很多夸張的邊緣,使圖像看起來像一幅藝術畫。LECARM處理后的圖像增強效果不明顯,圖像亮度整體偏暗。而RetinexNet處理后的圖像失真比較嚴重,出現了偏色和偽影的問題。本文方法處理后的圖像整體亮度較為均衡,在恢復出道路標線的同時,也保證了道路兩旁的物體沒有過度增強,看起來比較自然,有利于人眼的視覺觀察。


圖5 不同方法的增強結果對比
定量比較使用常用的四個指標:SSIM和PSNR進行定量評估,NIQE用于評估自然保存,LOE用于評估亮度失真。SSIM和PSNR越高,增強的圖像與參考圖像越接近,NIQE和LOE值越低,圖像質量越高。所有最佳結果都以粗體顯示,如表1所示。本文方法生成的測試圖像具有平均值更高的 SSIM、PSNR 和更低的NIQE。對于LOE平均值,它落后于LIME 和NPE。正如Guo等人[16]所說,使用輸入的低光照圖像本身來計算LOE是有問題的。因此,使用文獻[29]中使用參考圖像的方法來計算LOE,類似于計算SSIM和PSNR,并表示為 LOEref。這樣,本文的方法更具有一定的優勢。

表1 不同方法增強結果在自制數據集上的定量比較
2.2 公共數據集上的比較
為了進一步證明本文方法的魯棒性,本文還對公共數據集SICE進行了實驗。表2顯示了本文方法和五種現有的低光照增強方法的定量比較。由于SICE數據集的對比度很高,某些圖像看起來不太自然,因此只選擇了一部分圖像作為參考。可以看到,雖然在LOE和LOEref中,略落后于NPE排在第二位,但是在SSIM和PSNR上,本文的方法優于其他所有方法。對于非參考指標NIQE,本文方法也可以得到較低的值。實驗結果說明本文方法在恢復圖像細節質量上具有一定的優勢。
3 結論
本文提出了一個新的融合非線性相機響應函數模型的深度學習方法,以提高低光照圖像質量,為智能導航和自動駕駛提供高可見度的圖像。本文的主要思想是使用LRNet來學習殘差圖像,而不是簡單的端到端映射,從而利用殘差圖像的簡單性讓網絡有效地學習細節。此外,本文還創建了一個包含500個曝光不足圖像對的新數據集,使網絡能夠恢復低光照圖像清晰的細節,更接近真實的參考圖像。本文在自制數據集和SICE數據集上進行了實驗,并比較了本文的方法與五種現有的方法,證明了本文的解決方案在可視化比較、SSIM、PSNR、NIQE和LOE指標的定量比較方面的優勢。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
