基于CNN-GRU 度量網絡的多目標跟蹤算法
2021-07-26 08:13:32王瀟瀟張雪芹
華東理工大學學報(自然科學版) 2021年4期
王瀟瀟, 張雪芹
(華東理工大學信息科學與工程學院,上海 200237)
多目標跟蹤是指通過分析視頻來識別和跟蹤行人、汽車等多個目標物體,在視頻監控[1]、自動駕駛[2]、動作識別[3]及人群行為分析等實際應用中都依賴于多目標跟蹤算法。目前多目標跟蹤仍然是一個具有挑戰性的視覺任務,其主要困難在于同時跟蹤多個目標時,由于目標之間的遮擋和外觀相似性,容易造成跟蹤目標丟失或者目標標識(ID)切換等問題。近年來,深度學習在圖像分類[4-6]、目標檢測[7-9]等計算機視覺任務中取得了成功,推動了多目標跟蹤技術的進步,與深度神經網絡相結合的多目標跟蹤算法成為研究熱點[10]。
多目標跟蹤框架一般都是基于檢測的跟蹤框架,即在已知當前視頻幀目標檢測框的情況下,進一步匹配得到目標的ID。基于檢測的多目標跟蹤框架的基本流程是:目標檢測、目標檢測框的特征提取、目標檢測框和軌跡框的相似度計算及數據關聯[11]。檢測階段主要依賴于目標檢測算法,而目前對多目標跟蹤算法的研究主要集中在后二項。
針對目標檢測框的特征提取問題,由于多目標跟蹤場景下一般都存在多個目標遮擋、交互的情況,因而提取判別性的特征很困難。特征提取階段最常用的方法是卷積神經網絡(Convolutional Neural Network, CNN),或者是將CNN 提取的外觀特征和人工提取的特征相結合。基于深度學習的外觀特征提取算法能夠有效提取目標的外觀特征,但是當多個目標外觀相似且發生重疊時,ID 切換率仍然較高。Wojke 等[12]將行人重識別網絡提取的外觀特征與位置特征相結合,用卡爾曼濾波器預測目標框位置,計算匹配相似度矩陣,改善了SORT 算法[13]ID 切換率高的問題。He 等[14]通過構建目標軌跡的運動模型、外觀模型以及尺度模型,減弱目標部分遮擋對外觀特征的影響。Lee 等[15]將金字塔網絡和Siamese網絡結合,采用上采樣和合并策略為金字塔分層創建特征,將深層特征與淺層特征合并在一起,以提供更具有判別性的特征。然而這幾種方法沒有很好地利用不同時序的目標軌跡框的特征。
在多目標跟蹤中的相似度計算方面,Chen 等[16]將行人重識別模型和前景網絡結合成一個外觀模型,利用該模型中前景網絡的位置敏感得分圖(Position-Sensitive Score Map)作為空間注意力,減少目標檢測框的背景以及遮擋的影響,通過前景分數聚合外觀特征并用歐式距離計算相似度。Xu 等[17]通過訓練Siamese 網絡來學習不同ID 目標間的差異度量,并在該網絡中分別提取目標全局和局部特征,減輕遮擋對多目標跟蹤結果的影響,用歐式距離計算度量網絡輸出特征的相似度。Hao 等[18]使用GoogLeNet 來提取外觀特征,利用余弦距離來計算檢測框和軌跡框之間的相似度,并結合運動預測計算整體相似度。然而這些方法只使用訓練得到的深度模型提取外觀特征,在相似度度量方面,將提取的特征直接使用預設好的距離度量如余弦距離或歐式距離求相似度,可能會造成ID 切換率和誤報率較高的問題。
在多目標跟蹤的數據關聯算法方面,Sun 等[19]構建了一個端到端的計算視頻幀中所有行人目標檢測框和軌跡框數據關聯成本矩陣的深度模型,通過直接學習成本矩陣來構建獨特的損失函數,但該方法只提取了目標中心點的特征,沒有完全學習到整個目標框的外觀表達。Thoreau 等[20]構建了基于度量學習的Siamese 網絡,以此來學習多個目標在不同視頻幀的相似度,其數據關聯算法使用外觀模型和運動模型,并通過給這兩個模型賦予固定的相似度權重,融合得到最后的檢測框和軌跡框的相似度,但是這種預先給外觀模型和運動模型設定固定權重的方式不能自適應學習外觀模型和運動模型各自的重要性。
以上方法證明了深度學習方法在外觀特征提取、相似度計算以及數據關聯過程中的有效性,不同模型在數據關聯算法中的融合使用可以增加模型的性能,但是針對相似目標難區分、目標軌跡框誤報率高的問題,仍有進一步提高的空間。
針對復雜多目標跟蹤場景中行人目標ID 切換率高和誤報率高的問題,本文提出了一個基于CNNGRU 度量網絡的多目標跟蹤框架。該框架主要包括行人重識別模型、CNN-GRU 度量網絡和數據關聯算法。在CNN-GRU 深度度量網絡中統一提取目標的外觀特征和運動特征,并學習其時間關聯性,使得目標具有更好的判別性,降低目標的ID 切換率。同時,通過訓練使網絡學習目標不同時序歷史軌跡框正確匹配的概率值,抑制目標軌跡中的誤檢以及低質量目標框對目標整體特征的影響,降低誤報率;在CNN-GRU 度量網絡結構中直接聚合不同時序的目標歷史軌跡框的外觀特征,再由該度量網絡直接輸出目標軌跡框和檢測框特征的相似度。該相似度與行人重識別模型輸出的特征計算得到的相似度再通過數據關聯算法,最終計算出匹配結果。
1 基于CNN-GRU 的多目標跟蹤框架
1.1 總體框架
本文提出的基于CNN-GRU 的多目標跟蹤框架如圖1 所示。
該多目標跟蹤框架主要由以下3 個部分組成:
(1)目標框提取。基于目標檢測算法提取視頻當前幀的目標檢測框,而軌跡框是歷史視頻幀計算得到的目標軌跡框。
(2)相似度計算。采用CNN-GRU 度量網絡計算目標檢測框和軌跡框的相似度。在該網絡中,先使用CNN 提取目標框的深度特征,再采用兩個GRU 分別學習目標歷史軌跡框的外觀特征和運動特征的時間關聯性,以及學習目標保存的每個歷史軌跡框正確匹配的概率值,聚合不同時序的目標軌跡框的外觀特征,再由CNN-GRU 網絡輸出目標軌跡框和檢測框特征的相似度。采用基于深度學習的行人重識別(Reid)網絡[21]分別提取目標檢測框和軌跡框的外觀特征,并計算它們之間的相似度(余弦距離)。
(3)數據關聯。將Reid 網絡和CNN-GRU 度量網絡輸出的相似度結合,得到檢測框和軌跡框的匹配關聯矩陣,通過匈牙利匹配算法[22]最終得到當前視頻幀所有檢測框和目標軌跡框的匹配結果。
該框架構建了一個直接輸出檢測框和軌跡框相似度的深度度量網絡,通過在該度量網絡中直接訓練相似度以及自適應結合外觀特征和運動特征的方式,應對多目標跟蹤復雜的場景變化;通過在深度度量網絡中學習不同時序的歷史目標軌跡框外觀特征和運動特征的時間關聯性,降低目標的ID 切換率;通過學習每個目標保存的不同時序的歷史軌跡框正確匹配的概率值,降低誤報率。同時結合深度度量網絡輸出的相似度和行人重識別網絡提取的外觀特征的相似度,得到最后的檢測框和軌跡框的匹配結果,進一步降低目標ID 的切換率。
1.2 CNN-GRU 的深度度量網絡
1.2.1 CNN-GRU 度量網絡結構 CNN-GRU 度量網絡結構如圖2 所示,由一個CNN 網絡和雙GRU 網絡構成。其中,CNN 網絡用于提取目標框的外觀特征,雙GRU 網絡分別用于學習目標外觀特征和運動特征的時間關聯性,采用雙GRU 結構學習多個時序之間特征的關聯性,減少目標遮擋、目標外觀和速度變化帶來的影響。在該網絡中,針對ID 切換率高的問題,對外觀GRU 和運動GRU 每個時序的隱狀態進行拼接,將外觀相似但速度不相似的目標區分開。同時,在雙GRU 拼接以后,通過連接一個全連接層和Sigmoid 函數,將屬于該目標的歷史軌跡框與不屬于該目標但進入該目標軌跡中的誤檢區分開,以降低誤報率。然后在CNN-GRU 度量網絡結構中繼續解決多目標跟蹤中目標歷史軌跡框的特征聚合問題,并輸出目標檢測框和軌跡框的相似度。

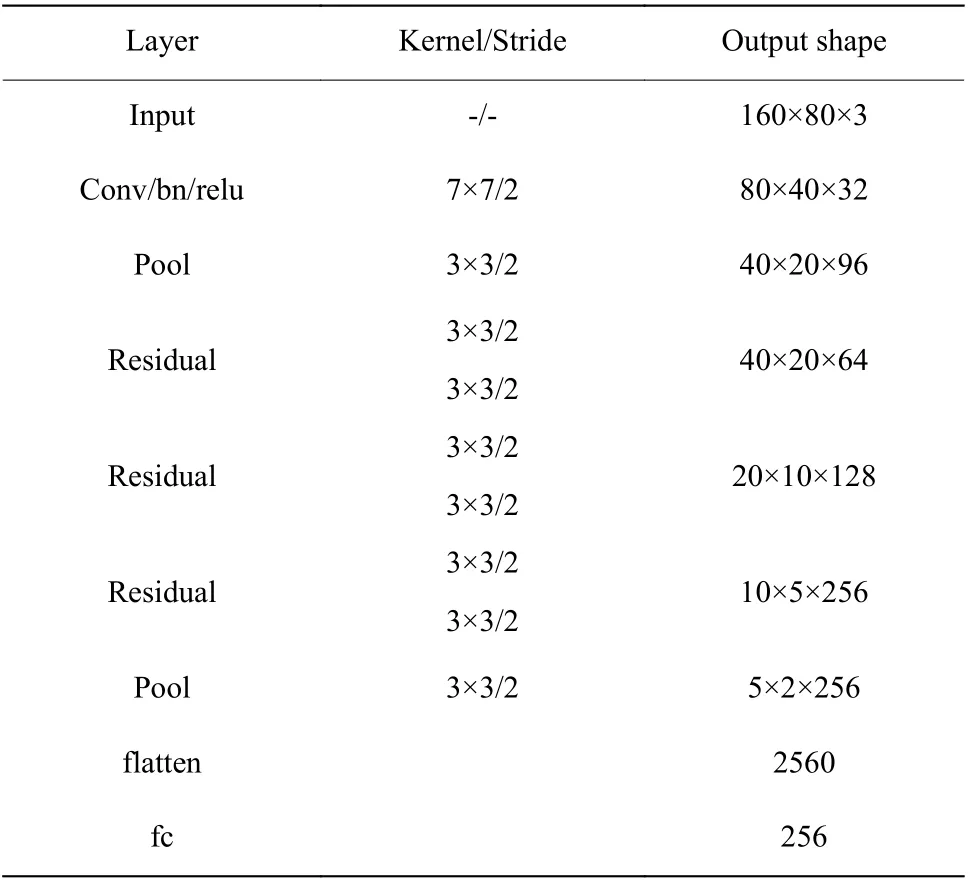
表1 CNN-GRU 中的CNN 網絡結構Table 1 CNN network structure in CNN-GRU

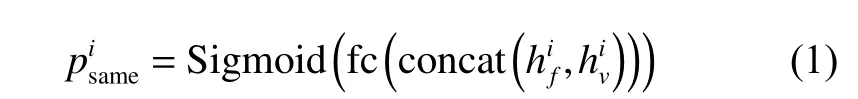

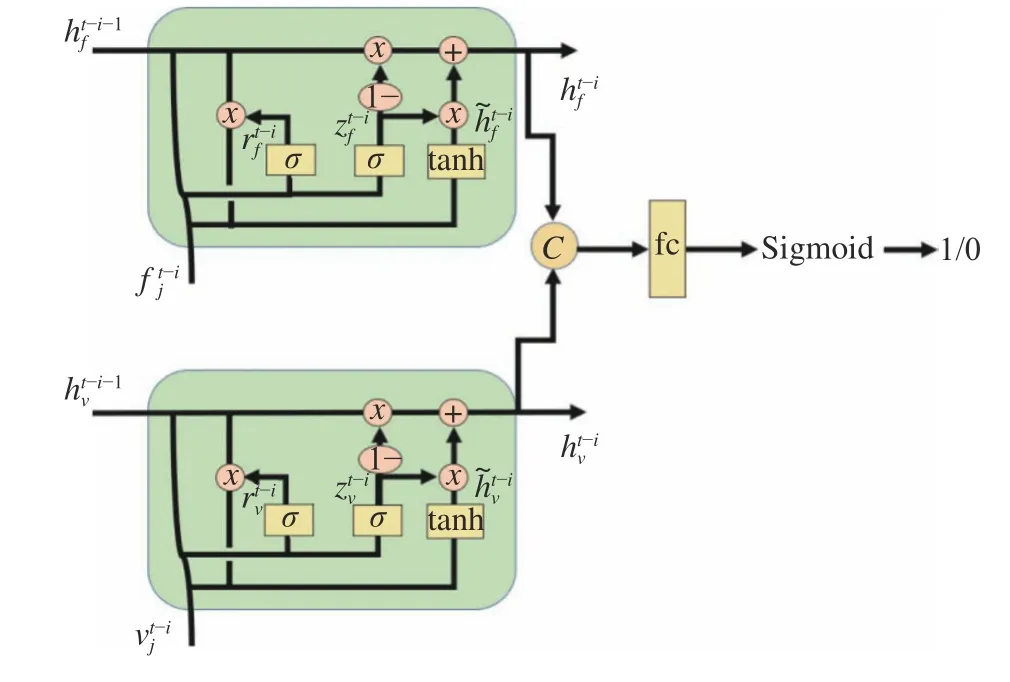
圖3 雙GRU 的結構圖Fig. 3 Structure of dual GRU
(3)度量學習。度量學習用于學習目標樣本對之間的距離或者相似度,學習度量空間使得實際屬于同個類別的目標特征的距離更小。在圖2 描述的CNN-GRU 度量網絡的結構圖內,在得到目標保存的各個時序的歷史軌跡框正確匹配的概率后,還需學習目標軌跡框和檢測框特征的相似度,即學習一種度量。該度量針對視頻圖像中同一軌跡中的特征向量輸出的相似度要比屬于不同軌跡中的特征向量返回的相似度要大。為了在CNN-GRU 網絡中得到目標軌跡框和檢測框特征的相似度,需要先聚合目標歷史軌跡框的特征。
在得到跟蹤目標保存的各個時序的歷史軌跡框正確匹配的概率后,以此概率為權重,聚合多個時序的目標歷史軌跡框的特征。對聚合的特征和目標檢測框的外觀特征求余弦距離,并經Sigmoid 函數計算目標軌跡框和檢測框特征的相似度。
CNN-GRU 度量網絡中聚合歷史軌跡框特征以及檢測框和軌跡框的相似度計算公式如下:

(4)損失函數。CNN-GRU 度量網絡主要采用3 種 損 失 函 數:Softmax loss、Binary cross entropy loss 和Triplet loss。 其 中, 分 類 損 失 使 用 的是resnet18-part 經過分類層輸出且L2 歸一化后的特征;Triplet loss 使用的是resnet18-part 全連接層輸出的256 維的特征;Binary cross entropy loss 在該網絡結構中用在兩個地方,一是雙GRU 結構中全連接層輸出的特征,二是CNN-GRU 網絡在聚合目標軌跡框特征后與檢測框計算的相似度特征。

在CNN-GRU 度量網絡中有兩處使用到Binary cross entropy loss,分別用于目標歷史軌跡框的正確匹配學習和相似度學習。
正確匹配學習的損失函數公式如下:
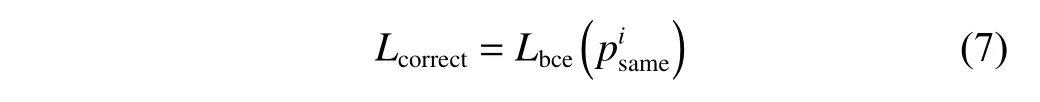

相似度學習的損失函數公式如下:
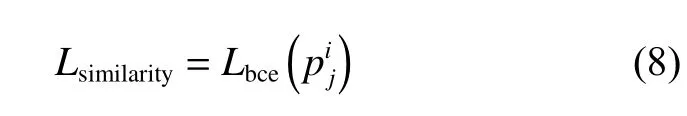
在整個CNN-GRU 度量網絡的訓練中,Softmax loss 損失函數主要是使得CNN-GRU 度量網絡中CNN 提取的外觀特征能區分不同ID 的目標;Triplet loss 損失函數主要是使得CNN-GRU 度量網絡中CNN 提取的不同ID 間的特征距離更遠,同ID 間的目標框的特征距離更近;Binary cross entropy loss 損失函數主要是使得CNN-GRU 度量網絡學習歷史軌跡框中每個時序的軌跡框正確匹配,以及用于目標軌跡框和檢測框的相似度學習。

其中:xt為GRU 當前時序輸入,本文中雙GRU 每個時序的輸入分別為第t-i幀軌跡框的外觀特征ft-i和速度特征;zt為GRU 的更新門; σ 為Sigmoid函數,主要是控制歷史信息的更新;rt為GRU 的重置門,主要是決定以前哪些信息需要重置;h~t為包含當前輸入和選擇記憶歷史信息后的輸出;ht為當前時序的隱狀態輸出值,其使用同一個門控zt來遺忘和選擇記憶。zt⊙h~t表示對當前時序信息進行選擇性的記憶; ( 1-zt)⊙ht-1表示對上一個時序的隱狀態的選擇性的遺忘, ⊙ 表示向量對應元素相乘(Element-wise multiplication);Wz、Wt、W和Uz、Ut、U為訓練階段學習到的權重矩陣。GRU 每個時序的隱狀態的更新都意味著遺忘上一個時序傳遞下來的隱狀態的某些維度的信息,并選擇性地加入當前時序輸入的某些維度的信息,從而學習視頻目標軌跡框之間的外觀和速度的時間關聯性,即每個時序保留一些利于區分當前目標框和其他目標的特征維度,遺忘一些冗余的特征維度。

1.3 行人重識別網絡
在多目標跟蹤中檢測框和跟蹤框之間的相似度函數是數據關聯的重要組成部分,為了求得相似度需要從視頻圖像中提取特征。研究證明從基于行人重識別任務的卷積神經網絡中學到的深層特征,可以結合到多目標跟蹤算法中以提高跟蹤性能[23]。
本文采用文獻[21]提出的行人重識別的網絡結構,命名為Reid。該網絡由GoogLeNet 和部分對齊全連接(fc)層的K個分支組成,并利用大規模的行人重識別數據集Market1501 等對網絡進行訓練。使用余弦距離度量Reid 網絡提取的外觀特征的距離。
1.4 數據關聯算法
數據關聯是指根據歷史軌跡框和檢測框的匹配矩陣得到每個檢測框對應的目標ID。其中,匹配矩陣的每一項是歷史目標軌跡框和檢測框特征的距離。


在得到匹配矩陣以后,還需利用每個跟蹤目標的卡爾曼濾波器在當前幀預測的目標位置,限制與當前目標軌跡框匹配的檢測框的范圍。最后,使用匈牙利匹配算法匹配所有軌跡框和剩下的檢測框,得到最后的目標ID 和檢測框的匹配結果。
1.5 基于CNN-GRU 的多目標跟蹤算法
基于CNN-GRU 的多目標跟蹤算法的完整描述如下:

-當一個軌跡連續3 幀與檢測框匹配,就認為這個軌跡的跟蹤狀態變為確定狀態,并將其添加到軌跡集合中
2 結果與分析
2.1 數據集
本文采用標準的多目標跟蹤數據集MOT16 和MOT17[24]進行實驗。MOT16 數據集共有14 個視頻序列,其中7 個為帶有標注信息的訓練集,7 個為測試集。MOT16 主要標注的目標是移動的行人與車輛,擁有不同拍攝視角、不同天氣狀況的復雜場景視頻。MOT17 數據集與MOT16 具有相同的視頻,但是MOT17 數據集中每個視頻提供3 組公開的目標檢測結果:分別來自Faster R-CNN[8]、DPM 和尺寸池化檢測器SDP[25]。本文采用MOT16 訓練集中可用的460 個可跟蹤目標訓練CNN-GRU 度量網絡。
在訓練CNN-GRU 度量網絡的過程中,采用隨機采樣同個目標軌跡中的相鄰的幀組成訓練集正樣本,并且在軌跡集中加入負樣本(即在目標軌跡框出現的視頻幀中隨機選擇其他目標框作為負樣本)構成訓練集。這樣即使目標軌跡中加入了其他目標檢測框,也可以通過在聚合歷史特征時通過式(2)給它分配低權重來降低其對整體軌跡特征的影響。
2.2 評估標準和實驗環境
針對本文關注解決的問題,采用MOTA、IDF1、IDs 和FP 作為主要評估指標。其中MOTA 指標結合了漏報、誤報和ID 切換率,其得分能夠很好地表征跟蹤精度,但不能評估軌跡一致性;IDF1 是識別F1 分數,表示正確識別的檢測數與平均groundtruth 和檢測數量之比,能更好地度量身份匹配的一致性[26];IDs 表示目標發生ID 切換的次數;FP 表示假正例(誤報)的數量。MOTA 的計算公式如下[27]:
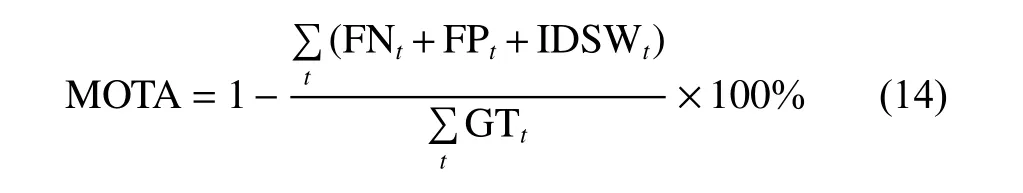
其中:FP 表示整個視頻中誤報的數量;FN 表示整個視頻中漏檢的數量; I DSW 表示目標ID 發生變化的數量; GT 表示ground-truth 目標框的個數。
本實驗的CPU 配置為Intel Core-i7-8750H @2.2 GHz,GPU 是NVIDIA GeForce GTX1060。
2.3 實驗與結果
實驗主要關注多目標的跟蹤結果,其中,在MOT17 數據集上的對比實驗采用該數據集提供的公開目標檢測結果;在MOT16 數據集上的驗證實驗的跟蹤器檢測部分的檢測結果使用文獻[28]的結果。
(1)有效性驗證實驗。為了驗證CNN-GRU 度量網絡的有效性,首先在MOT16 訓練集上進行驗證實驗。設跟蹤器的基線模型(基礎多目標跟蹤器)由卡爾曼濾波器(位置限定)+IOU 關聯+匈牙利匹配算法組成,命名為baseline。基線模型+CNN-GRU 度量網絡組成的多目標跟蹤器命名為b-cnngru。基線模型+行人重識別網絡組成的多目標跟蹤器命名為breid。b-reid+CNN-GRU 網絡命名為Ours(+)。為了進一步證明所提數據關聯方法的有效性,實驗還比較了將(行人重識別網絡輸出特征計算的相似度)×(CNN-GRU 輸出的相似度)作為總的相似度分數的方法,命名為Ours(*)。
圖4、圖5 分別示出了b-reid、Ours(+)和Ours(*)在IDF1、IDs 兩個指標上的比較結果。表2 示出了baseline、b-reid、b-cnngru、Ours(+)和Ours(*)在多個指標上的比較結果。
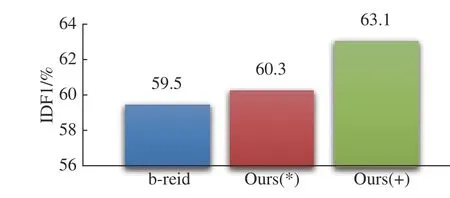
圖4 基于IDF1 指標的效果驗證Fig. 4 Verification of effects based on IDF1 index
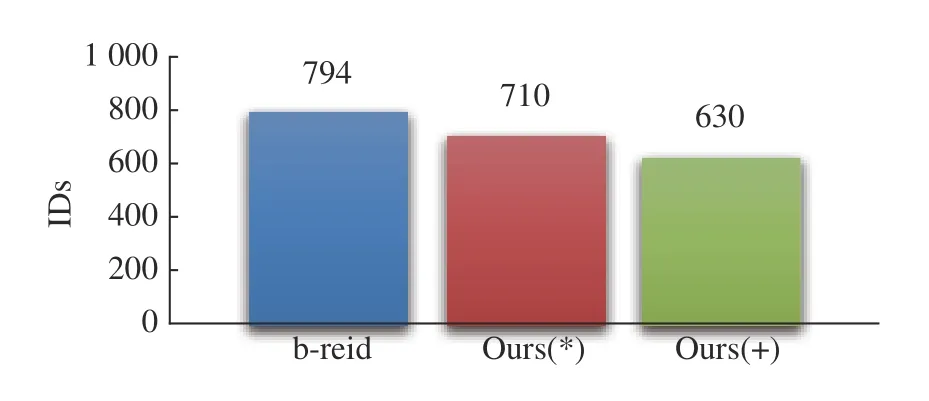
圖5 基于IDs 指標的效果驗證Fig. 5 Verification of effects based on IDs index
表2 中向下的箭頭表示該指標越小越好;向上的箭頭表示該指標越大越好。從表2 的結果可以看出,b-cnngru 的MOTA 得分比b-reid 高0.1%,且bcnngru 的IDF1、FP 和IDs 指標均優于b-reid,說明在baseline 中加入CNN_GRU 度量網絡比在baseline 中加入Reid 網絡的整體性能要高。與b-reid 相比,Ours(*)的IDF1 提高1.0%,IDs 下降了9.2%;Ours(+)的IDF1 提 高3.4%,IDs 下 降 了21.5%,FP 下 降 了5.9%,MOTA 提高0.3%。這幾個模型的FN 相差不多,b-cnngru 和Ours(+)略有增加。綜合來看,多目標跟蹤框架中加入CNN-GRU,對目標ID 切換次數、目標誤報率有較好的改進作用,目標ID 的一致性也有所提升,結合使用Reid 可以得到更好的跟蹤性能。5 種跟蹤器的運行速度比較結果如表3 所示。其中Hz 表示多目標跟蹤器在基準數據集上的處理速度(即每秒幀數,不包括檢測器部分,只包含跟蹤部分的處理速度)。
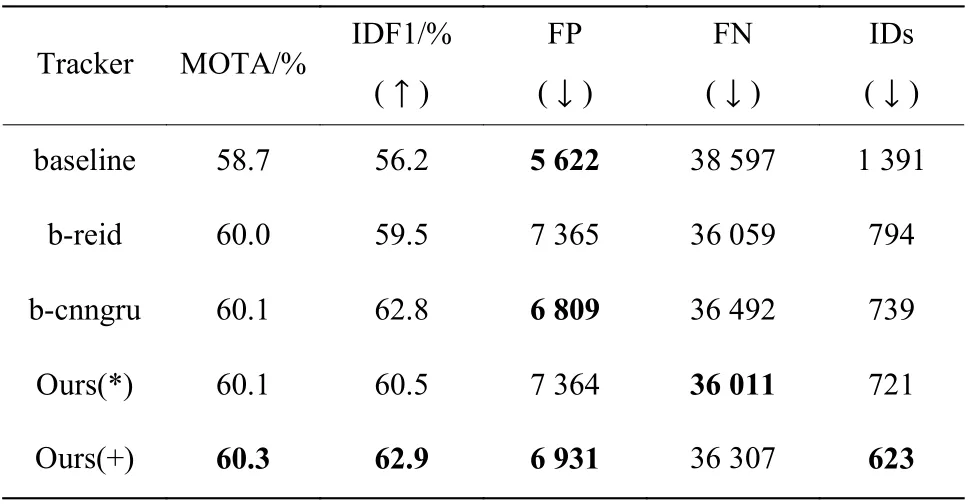
表2 CNN-GRU 的效果驗證(MOT16)Table 2 Effects verification of CNN-GRU (MOT16)
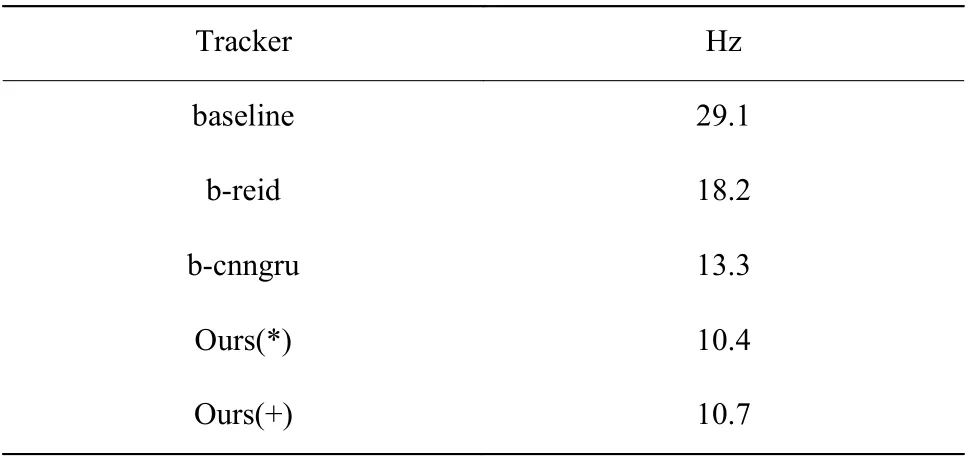
表3 CNN-GRU 的處理速度驗證結果(MOT16)Table 3 Processing speed verification of CNN-GRU (MOT16)
從表3 中可以看出,在基線模型中加入行人重識別網絡會使整個跟蹤器的處理速度降低,因為視頻中每個行人框都要提取外觀特征會消耗一定的時間。加入CNN-GRU 度量網絡后,處理上需要更多的時間。
(2)雙GRU 驗證實驗。為了驗證CNN-GRU 度量網絡中雙GRU 的有效性,比較了在雙GRU 結構中只使用運動GRU 或外觀GRU 時的性能(去掉雙GRU 結構中的Concat)。在MOT16 訓練集上進行驗證實驗,實驗結果如表4 所示。其中,Ours(+)使用的是單CNN 和雙GRU 的結構,而GRU-v 是使用單CNN 和運動GRU 的跟蹤器,GRU-a 是使用單CNN和外觀GRU 的跟蹤器。
由表4 的實驗結果可知,只使用單個運動GRU或者單個外觀GRU 時,多個性能指標如MOTA、IDF1、FP、FN 和IDs 均差于在跟蹤器中使用雙GRU的效果,使用雙GRU 結構性能高于只使用單個GRU 的性能。
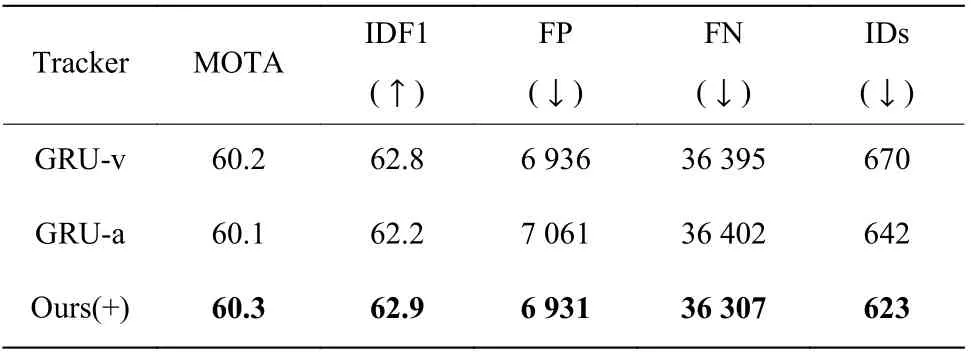
表4 CNN-GRU 的雙GRU 效果驗證(MOT16)Table 4 Effects verification of dual GRU in CNN-GRU(MOT16)
(3)跟蹤效果驗證實驗。為了進一步驗證加入CNN-GRU 度量網絡后多目標跟蹤算法的改進效果,圖6 示出了b-reid 模型和Ours(+)模型在兩個多目標跟蹤場景的對比效果圖。
在圖6 視頻場景(a1,a2)中,具有相似外觀的目標4 和目標8 發生重疊遮擋。可以看出,對于breid 模型,在相似外觀的目標4 和8 發生重疊遮擋后發生了ID 切換;而對于Ours(+)模型,這些目標在重疊遮擋以后依舊可以被正確區分,沒有產生ID 切換。在圖6 視頻場景(b1,b2)中,對于b-reid 模型,目標21 的軌跡框在第2 幀時被遮擋,且在第3 幀后目標21 的軌跡框中加入了目標37 的檢測框,發生了ID 切換和誤檢;而對于Ours(+)模型,目標26 在第3幀時匹配到其他目標檢測框,但由于本文模型可學習不同時序目標框正確匹配的概率,因此可重新正確識別目標。

圖6 視頻多目標場景的跟蹤效果對比圖Fig. 6 Comparison of tracking effect of video multi-target scene
(4)與現有跟蹤器的對比實驗。將本文所提跟蹤器與MOT 官網(https://motchallenge.net/)上近幾年提出的多目標跟蹤器性能進行比較。實驗在MOT17 測試集(該測試集包含3 組檢測結果)上進行,實驗結果見表5。
由表5 可以看出,在MOT17 測試集上,與MASS[29]和FPSN[15]跟蹤器相比,本文提出的跟蹤器雖然整體精度略低,但是有更低的誤報率以及更低的ID 切換次數。與GMPHD_DAL[30]、SORT17[13]和GMPHD_N1Tr[31]相比,除FN、Hz 外,本文提出的跟蹤器總體指標都有提升。與SAS_MOT17[32]相比,本文提出的跟蹤器有更高的MOTA 分數和更低的誤報率。與多個跟蹤器的處理速度相比,本文提出的跟蹤器的速度居中。總的來說,在MOT17 數據集的實驗結果表明,CNN-GRU 多目標跟蹤器在跟蹤準確度、ID 切換次數和誤報率方面具有良好的綜合性能。
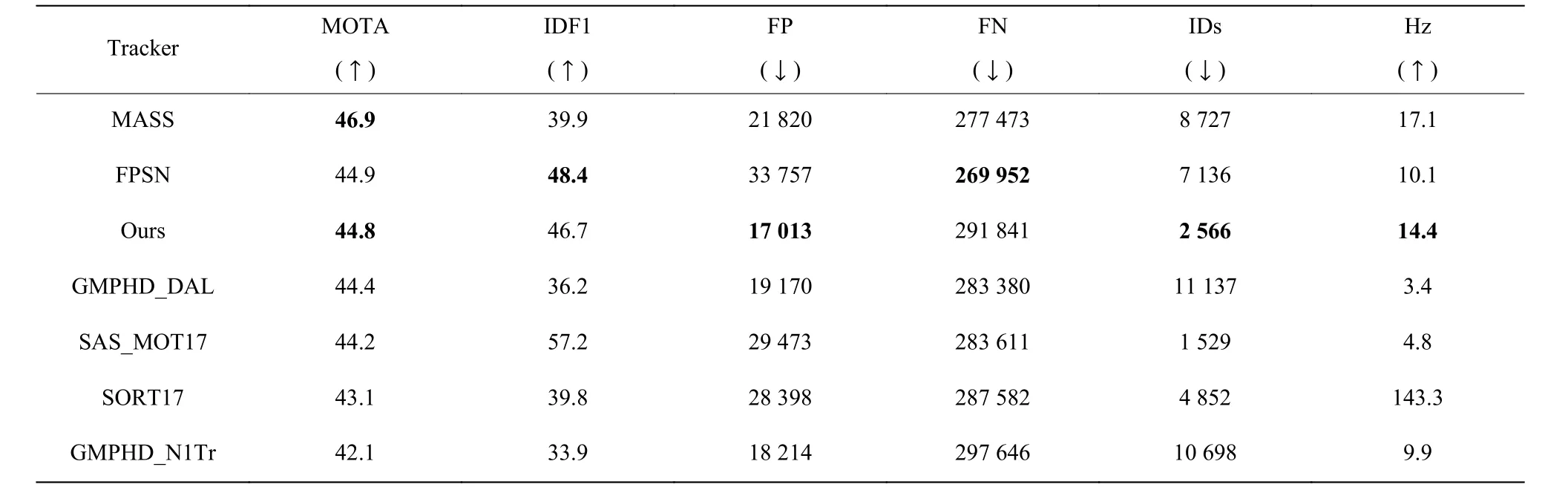
表5 MOT17 測試集結果Table 5 Comparison with public detector on MOT17 test dataset
3 結 論
本文提出了一種多目標跟蹤框架,該框架主要包括行人重識別模型、CNN-GRU 度量網絡和數據關聯算法。在CNN-GRU 深度度量網絡中統一提取目標的外觀特征和運動特征,并學習其時間關聯性,使得目標具有更好的判別性,以此降低ID 切換率。同時,通過訓練使CNN-GRU 度量網絡學習目標保存的不同歷史時序軌跡框正確匹配的概率值,抑制目標軌跡中的誤檢以及低質量目標框對目標整體特征的影響;通過在CNN-GRU 度量網絡結構中直接聚合不同時序的歷史軌跡框的外觀特征,再由該度量網絡直接輸出目標軌跡框和檢測框特征的相似度。該相似度與行人重識別模型輸出的特征計算得到的相似度通過數據關聯算法,最終計算出匹配結果。將Reid 網絡和CNN-GRU 度量網絡輸出的相似度結合進一步降低目標的ID 切換率。實驗評估結果表明,本文提出的框架能夠有效降低ID 切換率和誤報率,提高跟蹤精度。未來考慮加入邊界框回歸來修正目標檢測結果不夠精確的目標框的坐標。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
