基于空間分布優(yōu)選初始聚類中心的改進K-均值聚類算法
2021-08-03 06:14:14宋仁旺蘇小杰
科學技術(shù)與工程 2021年19期
關(guān)鍵詞:效果
宋仁旺,蘇小杰,石 慧
(太原科技大學電子信息工程學院,太原 030024)
隨著信息行業(yè)的爆炸式發(fā)展,數(shù)據(jù)已成為行各業(yè)重要的生產(chǎn)因素,同時也對海量數(shù)據(jù)的挖掘提出新的挑戰(zhàn)。信息爆炸產(chǎn)生的海量數(shù)據(jù)對從大量數(shù)據(jù)中挖掘有用信息提出挑戰(zhàn)[1-4]。數(shù)據(jù)的聚類是數(shù)據(jù)挖掘?qū)嵤┻^程中的核心技術(shù)[5-6]。MacQueen[7]為解決數(shù)據(jù)挖掘問題提出了一個局部搜索的算法——K-means聚類算法。該算法原理簡單、運算高效、時間和空間復雜度較低,至今依然是工業(yè)和社會科學中最流行的算法[8]。但該K-means聚類效果對最初K個初始中心點的選取和離群值都非常敏感,當用于海量數(shù)據(jù)聚類時,由于其迭代次數(shù)過多且迭代過程涉及多次文件系統(tǒng)的讀寫操作非常費時[9-11],所以有必要對K-means聚類算法初始聚類中心點的選取進行改進以減少聚類過程中的迭代次數(shù),從而降低聚類所需的時間并提高聚類效果。
針對上述問題,學者從不同角度對K-means算法進行了改進。Arthur等[12]在K-means算法的基礎(chǔ)上對中心點的選擇進行改進,即基于每個數(shù)據(jù)點到已有中心點的距離采用線性概率選出下一個聚類中心點,簡單地說就是數(shù)據(jù)點離現(xiàn)有的中心點距離越遠就越有可能被選為類簇中心點,該方法能有效解決初始聚類中心點敏感的問題,但是由于類簇中心點的選擇具有有序性,這使得算法無法并行擴展,極大地限制了算法在大規(guī)模數(shù)據(jù)集上的應(yīng)用。K-medoids算法是在K-means聚類方法基礎(chǔ)演變而來,該算法的特點是選取的每個中心點都是樣本點,因此該方法能夠解決K-means算法對噪聲和離群值敏感問題,但是該算法時間復雜度高,不適合應(yīng)用于大批量數(shù)據(jù)集[13]。Goode[14]為了減少聚類的迭代過程提出了X-means算法,該算法利用K-means迭代和基于BIC(Bayesian information criterion)的停止規(guī)則確定聚類的最優(yōu)數(shù)目,但是該算法過程復雜,增加了算法復雜度,效果并不理想。
通過以上分析,可以發(fā)現(xiàn)現(xiàn)存對K-means算法改進的文獻所提出的算法都是具有代價的。現(xiàn)擬在分析K-means聚類算法的基礎(chǔ)上不降低K-means算法的準確性、高魯棒性等性能情況下,提高聚類算法的算法效率和高穩(wěn)定性。為此提出了一種針對海量數(shù)據(jù)集初始聚類中心點選擇的聚類算法。在該算法中,為了消除數(shù)據(jù)集中孤立的噪聲點對聚類效果的影響,采用冒泡排序法對數(shù)據(jù)集進行排序,獲取數(shù)據(jù)集的各維中心值組成第一個初始聚類中心點,為保證所有的聚類中心點均勻地分布在數(shù)據(jù)集密度較大的空間上,余下候選初始聚類中心點的優(yōu)化選擇依據(jù)其與第一個初始聚類中心點的歐式距離,并且所有聚類中心點兩兩之間設(shè)置一定的距離間隔,以此減少聚類過程中的迭代次數(shù)和提高聚類算法效率。改進后的K-means聚類算法能顯著減少聚類的迭代次數(shù),降低噪聲對聚類效果的影響,提高算法效率。最后選取UCI(University of California, Irvine)中多個針對聚類算法的數(shù)據(jù)集進行實驗驗證,對比K-means、K-means++聚類算法驗證本文算法的高效性和準確性。
1 K-均值聚類算法理論
聚類通常又被稱為無監(jiān)督學習,屬于一種動態(tài)算法。數(shù)據(jù)的聚類就是按照某個特定標準(如距離、密度)把一個集合分為互不相交的類簇,使得同一個類簇內(nèi)的對象的相似性盡可能大,同時不在同一個類簇中的對象的相似性盡可能地小[15-18]。根據(jù)分類對象和分析計算方法不同,聚類算法分為小數(shù)據(jù)聚類和大數(shù)據(jù)聚類兩種類型,其中小數(shù)據(jù)聚類包含傳統(tǒng)聚類和智能聚類算法,大數(shù)據(jù)聚類包含的算法分為并行聚類、分布式聚類和高維聚類[19]。
假設(shè)數(shù)據(jù)集X包含n個d維屬性的數(shù)據(jù)點,即X={x1,x2,…,xn},其中xi∈Rd。K-means聚類的目標是將n個樣本點按照數(shù)據(jù)集間樣本的相似性劃分到指定的K個類簇中,每個樣本只屬于到其中一個中心點距離最小的類簇中。首先K-means聚類算法是隨機產(chǎn)生K個聚類中心點{c1,c2,…,cn},然后計算每一個數(shù)據(jù)點到所有聚類中心的歐式距離,根據(jù)就近原則,把其余的數(shù)據(jù)點分配給距離最小的類簇中心點,最后通過計算每個數(shù)據(jù)點與其類簇中心點距離差的平方和來評價聚類的效果。
2 改進的K-means聚類算法
K-means聚類算法初始聚類中心點是隨機選取的,極有可能存在選取的初始聚類中心點是數(shù)據(jù)集邊緣的噪聲點或孤立點,或者選取的聚類中心點兩兩之間的空間距離十分接近,這可能增加聚類過程的迭代次數(shù),影響聚類效果。鑒于此,現(xiàn)提出一種改進的K-means聚類算法,該算法的核心思想是初始聚類中心點盡可能均勻分布在數(shù)據(jù)集密度較大的一定范圍內(nèi)且各個中心點的距離足夠大,同時應(yīng)避免一些極端距離的點被選為中心點,具體步驟如下。
Step1設(shè)置K值,令M=K,掃描數(shù)據(jù)集,采用冒泡排序法把數(shù)據(jù)集各維從小到大進行排序,排序后的數(shù)據(jù)集為X1。
Step2篩選數(shù)據(jù)的各維中心值作為第一個聚類中心點c1,保證第一個聚類中心點位于數(shù)據(jù)集空間的中心,即
c1=X1,p,p=[n/2]
(1)
式(1)中:[]表示取整運算;X1,p表示排序后數(shù)據(jù)集的第p個樣本。
Step3對數(shù)據(jù)集中的每個點xi,通過式(2)計算每一個數(shù)據(jù)點到已有聚類中心的歐式距離,即
(2)
式(2)中:xi表示第i個樣本;cj表示第j個類簇中心點;xit表示第i個樣本的第t維屬性;cjt表示第j個聚類中心點的第t維屬性。通過式(2)計算任意點xi到已有聚類中心點的距離,即
D(xi)=[d(xi,c1),d(xi,c2),…,d(xi,cj)]
(3)
其余k-1個聚類中心點要滿足以下兩點:
(1)候選的聚類中心點應(yīng)排除在距離指定中心點0.8d之外和0.2d之內(nèi)的空間上(d代表所有數(shù)據(jù)點距第一個初始聚類中心點的最遠歐式距離),即剩下k-1個聚類中心點分布在數(shù)據(jù)集數(shù)據(jù)密度較大的空間中。
(2)兩兩中心點之間設(shè)置一定的間隔,本文選取間隔為3d/M。
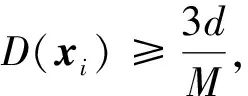
Step5重復Step 3、Step 4,直到其余k-1個聚類中心點全選擇出來。
Step6通過式(4)分別計算數(shù)據(jù)集中的所有數(shù)據(jù)點到K個類簇中心點的歐氏距離,并依據(jù)式(4)將所有數(shù)據(jù)點分別分配到距離中心點最近的類簇中;如果
(4)
則x∈ci,從而得到k個類簇{S1,S2,…,Sk}。
Step7在Step 6的基礎(chǔ)上,通過式(5)重新計算K個類簇各自的中心點,計算方法是取類簇中所有元素各自維度的算術(shù)平均值,即
(5)
式(5)中:ni表示類簇Si中數(shù)據(jù)點的個數(shù),且xj∈Si。Step8將K個類簇新的中心點與原有中心點進行比較,相鄰最小化平方誤差和不再變化或迭代次數(shù)達到設(shè)定的最大值,則輸出聚類結(jié)果。假設(shè)數(shù)據(jù)集劃分為{S1,S2,…,Sk},最終的最佳聚類目標是最小化誤差平方和(sum of the squared errors,SSE),即
(6)
總誤差平方和越小,聚類效果越好。
本文聚類算法流程如圖1所示。
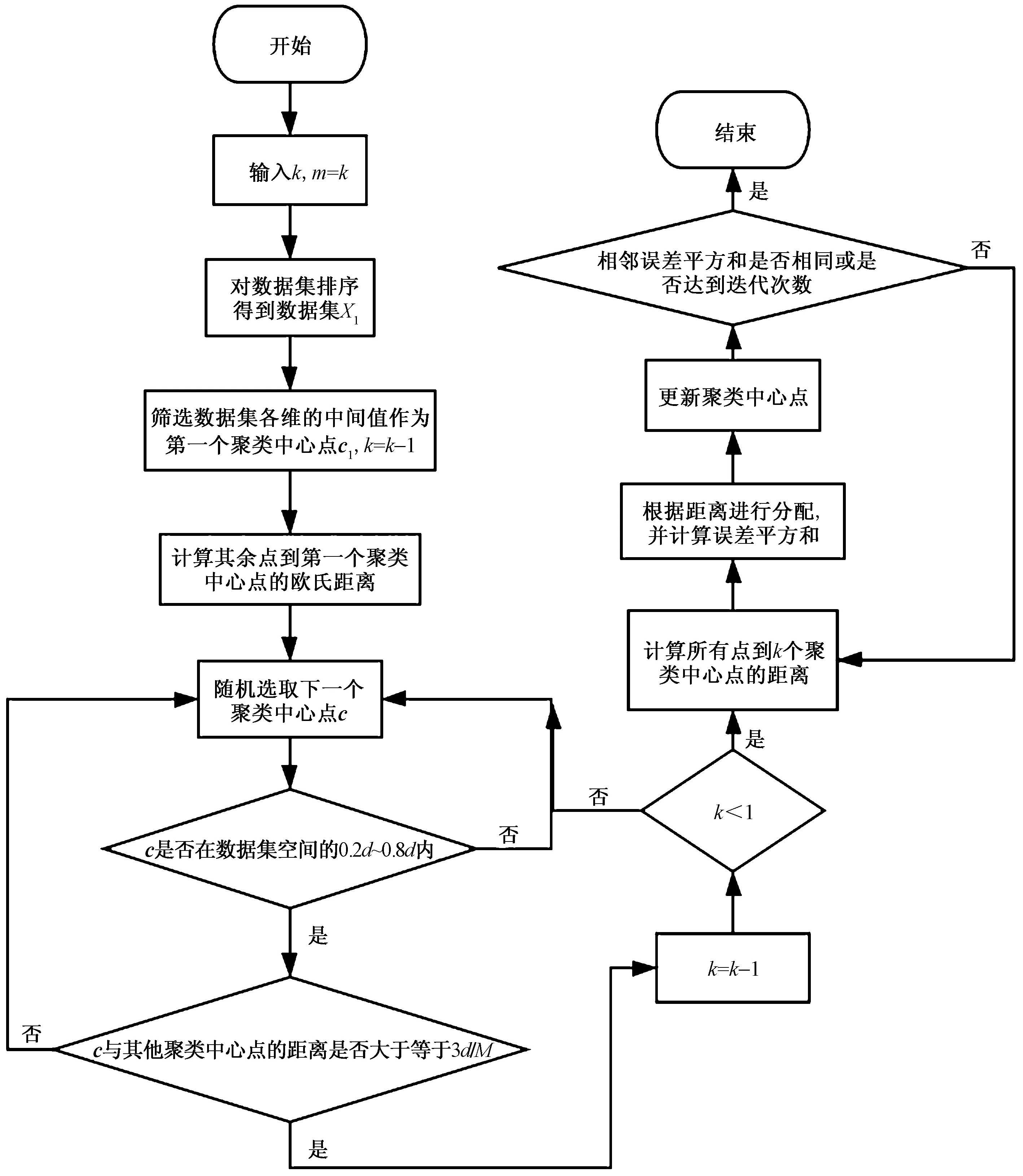
圖1 本文聚類算法流程圖
3 實驗驗證
為了說明本文改進的算法在減少迭代次數(shù)的同時不降低聚類的效果,算法高效。本文數(shù)據(jù)樣本包含兩部分:一部分是UCI中針對驗證聚類算法的Iris、Wilt、Avila、letter-recognition、Activity-recognition數(shù)據(jù)集作為實驗數(shù)據(jù)集,另一部分數(shù)據(jù)集是由MATLAB中標準正態(tài)分布函數(shù)產(chǎn)生的矩陣,并選取了K-means、K-means++聚類算法與本文提出的算法進行了對比實驗,檢驗算法效果。
實驗環(huán)境:LenovoG40-80筆記本、Windows10專業(yè)版、系統(tǒng)類型為64位操作系統(tǒng)、基于X64的處理器、Intel(R)Core(TM)i5-5200U CPU @ 2.20 GHz、4 G RAM、MATLABR2018a 集成開發(fā)環(huán)境。
為了能直觀地顯示本文算法的聚類效果,首先在由MATLAB中標準正態(tài)分布函數(shù)產(chǎn)生的數(shù)據(jù)集上進行實驗,實驗分別在K-means、K-means++和本文提出的聚類算法上進行。該二維數(shù)據(jù)集分為5個類簇,共400個數(shù)據(jù)點。聚類結(jié)果如圖2~圖5所示。

圖2 K-means算法聚類效果
圖2中五個黑色標記是K-means算法聚類的最終類簇中心點,坐標分別是(0.618,-1.749)(-0.388,-0.101)(-1.617,-1.288)(1.722,-0.075)(0.794,1.654)。
圖3中五個黑色標記是K-means++算法聚類的最終類簇中心點,坐標分別為(0.597,-1.718)(-0.677,-0.260)(-1.769,-1.518)(1.569,-0.088)(0.780,1.618)。
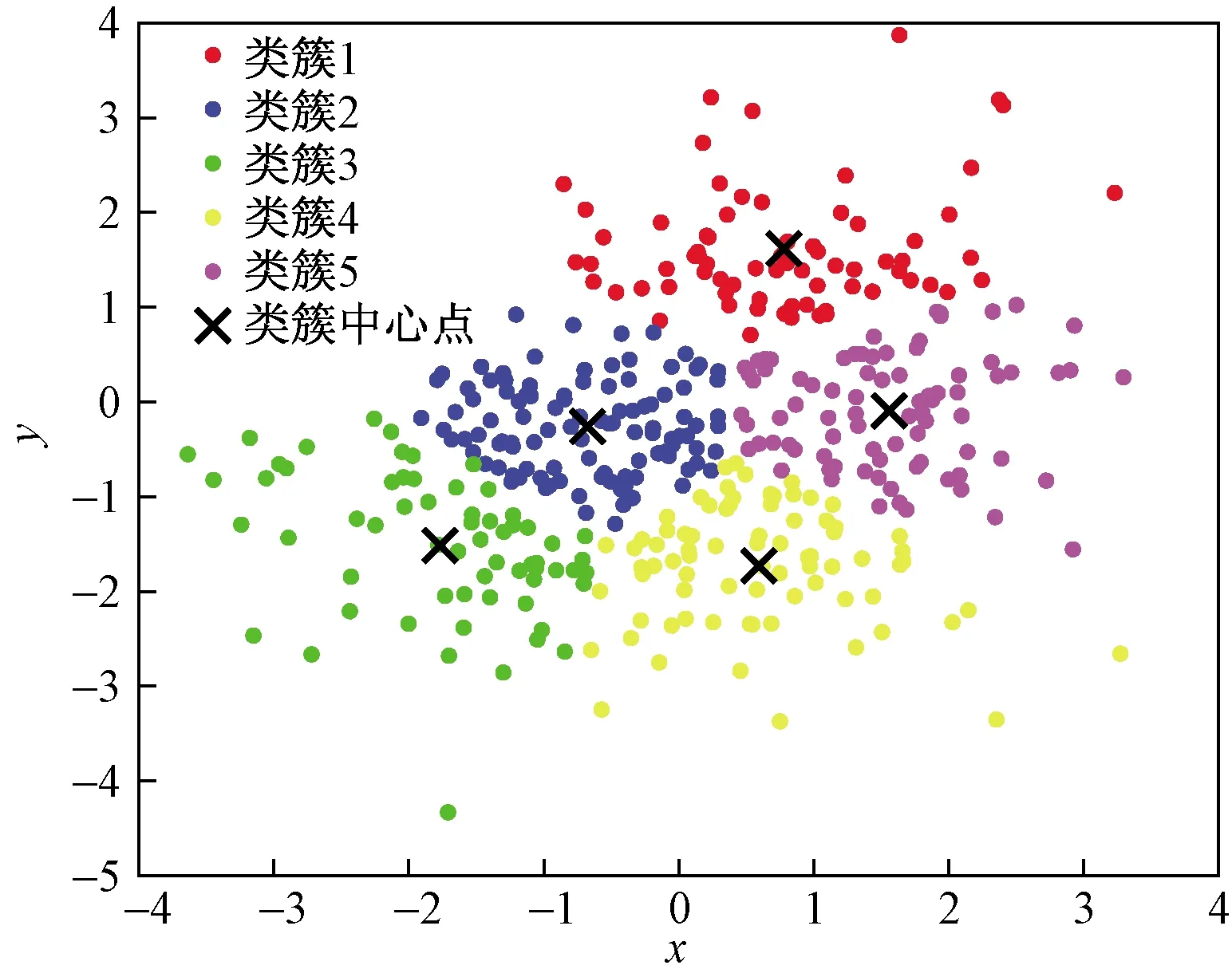
圖3 K-means++算法聚類效果圖
圖4中紅色的標記點是本文算法通過采用冒泡排序法自動選取數(shù)據(jù)集的各維中心點作為第一個初始聚類中心點,其余四個黑色的標記點是另外四個初始聚類中心點,坐標分別為(0.141,-0.453)(1.382,1.879)(2.081,-0.774)(-1.743,-0.294)(0.255,-2.326),每個藍色圓圈表示一個數(shù)據(jù)點,可以直觀看出本文算法選取的五個初始的聚類中心點可以離散均勻分布在數(shù)據(jù)集中數(shù)據(jù)點密度相對大的空間上。
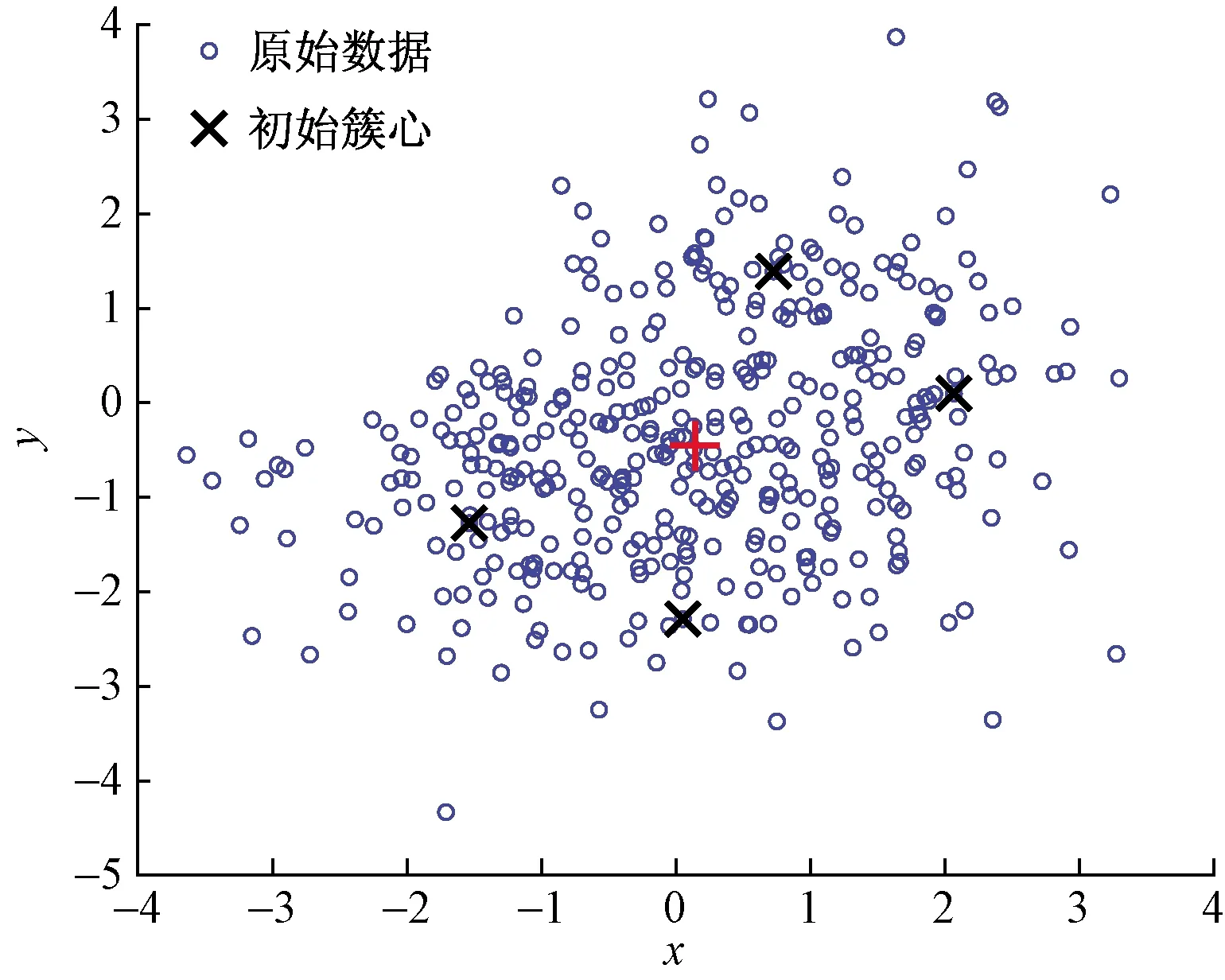
圖4 本文算法產(chǎn)生的初始簇心
在圖5中五個黑色標記是本文算法聚類的最終類簇中心點,坐標分別為(-0.294,-0.046)(0.991,1.591)(-1.722,-1.047)(1.629,-0.478)(0.132,-1.909),相同顏色的點屬于同一類簇。
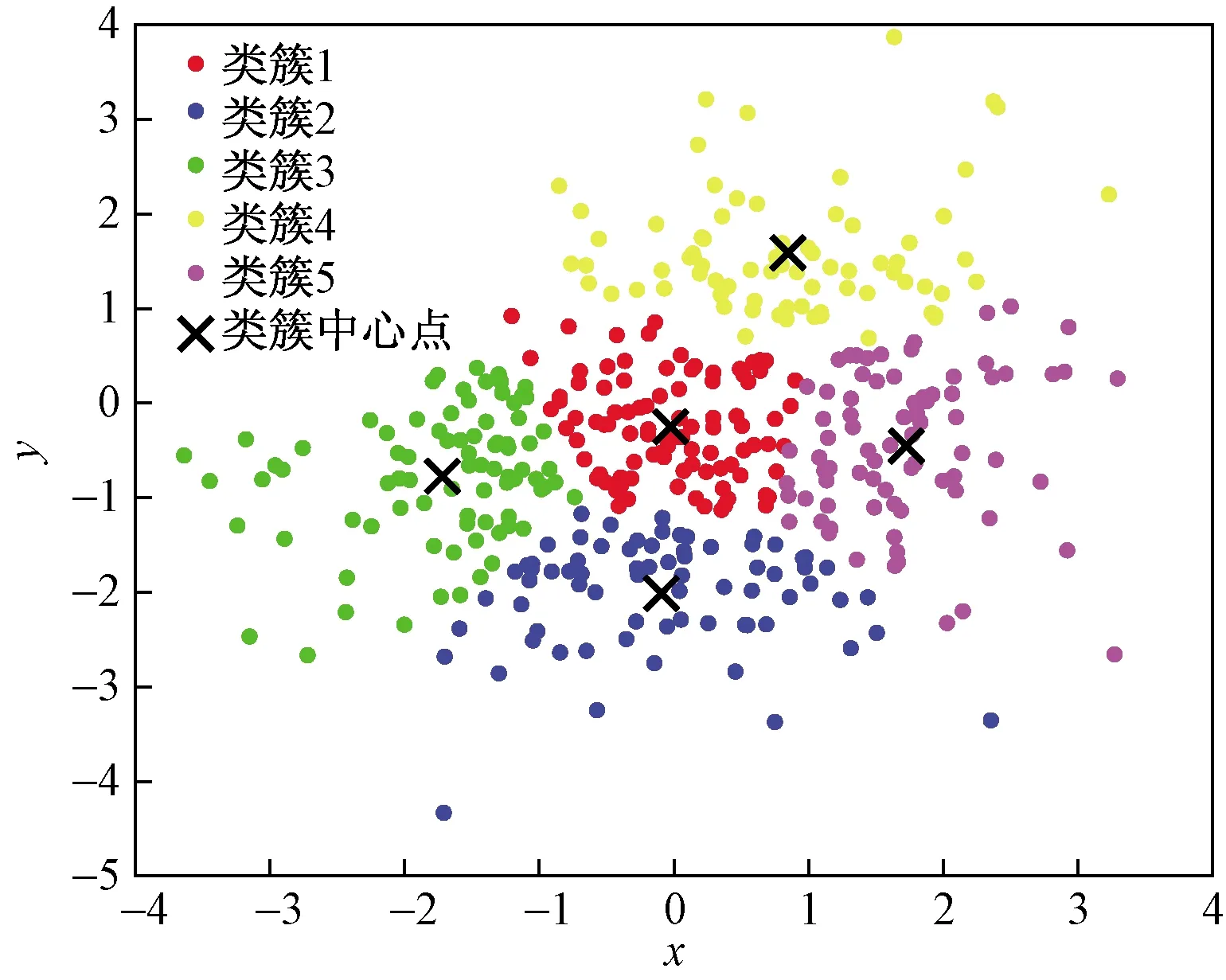
圖5 本文算法產(chǎn)生的聚類效果圖
通過對比圖2~圖5的類簇中心點坐標可以得出,三個聚類算法的最終類簇中心點的坐標的比較接近,而本文聚類算法自動選擇的5個初始聚類中心點的坐標與最終形成的類簇中心點坐標的位置十分接近,由此可以直觀地看出本文算法可以達到減少聚類過程中的迭代次數(shù),提高聚類算法效率預期效果。
通過分析表1可以發(fā)現(xiàn):和經(jīng)典的聚類算法相比較,本文提出的改進的聚類算法的迭代次數(shù)為10次,而K-means、K-means++的迭代次數(shù)分別為19和17次,可以看出本文算法在聚類過程中的迭代次數(shù)顯著的減少,這由于本文算法選擇的初始類簇中心點能夠離散均勻地分布在數(shù)據(jù)集中數(shù)據(jù)點相對集中的地方,即提高了算法的運行效率;通過對比三個聚類算法的運行時間,可以看出K-means++算法的聚類時間較大,而K-means算法和本文算法的時間相差不大,主要時由于K-means++算法選擇K個初始聚類中心點時同時采用串行的方式比較消耗時間;通過對比三個算法的誤差平方和可以發(fā)現(xiàn),本文算法的類簇內(nèi)的誤差平方和相比于其他算法也有所下降,即本文算法的聚類效果優(yōu)于K-means、K-means++聚類算法。主要原因是,傳統(tǒng)的聚類算法的中心點是在全數(shù)據(jù)集上隨機選取的,那么選取的中心點可能處于極端的孤立點或兩兩中心點之間間隔過大或過小,而本文提出的改進聚類算法所選擇的初始中心點是均勻地分布在數(shù)據(jù)點密度較大的空間中,這些初始中心點能非常好地貼近最終的聚類中心點。
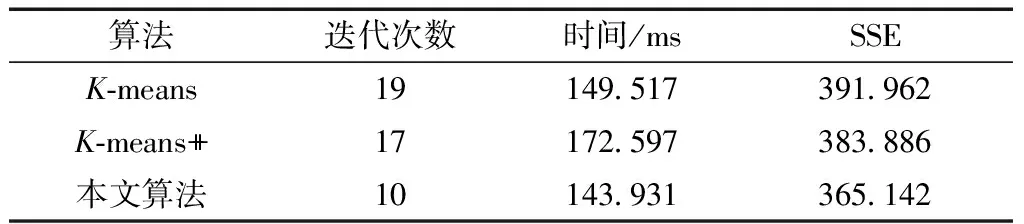
表1 針對人造二維數(shù)據(jù)集各算法的聚類性能結(jié)果
為了進一步檢驗本文算法在多維數(shù)據(jù)集上的聚類效果,驗證算法在聚類過程中減少迭代次數(shù)和提高聚類算法效率,現(xiàn)選取UCI中多個針對聚類算法的數(shù)據(jù)集進行聚類對比實驗。
數(shù)據(jù)預處理:由于UCI中的數(shù)據(jù)集中有一些原始數(shù)據(jù)中帶有數(shù)據(jù)的類別標識字母或數(shù)字,而我們進行實驗時是不需要將類別標識放入算法中,所以在進行實驗之前需要對數(shù)據(jù)集進行預處理,去掉數(shù)據(jù)集的標識部分。其中Activity-recognition數(shù)據(jù)集的采集包含房間1和房間2兩個數(shù)據(jù)集,本文選取的房間1采集的數(shù)據(jù)集。實驗數(shù)據(jù)集性質(zhì)如表2所示。
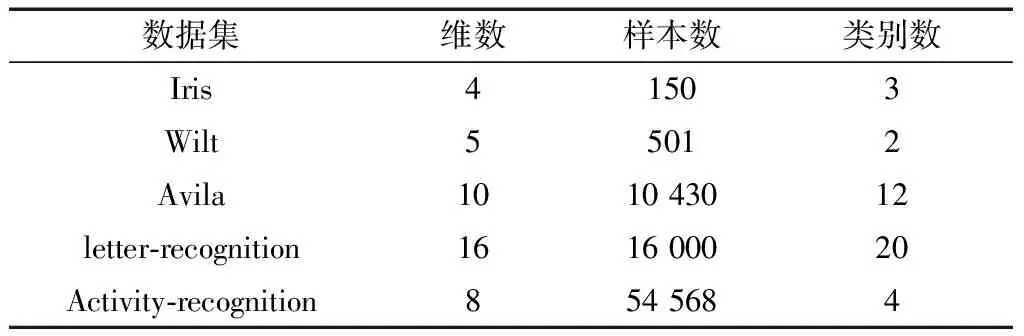
表2 UCI中針對聚類數(shù)據(jù)集的性質(zhì)
為了使本文選擇的數(shù)據(jù)集具有多樣性、代表性、說服力。本文選擇的數(shù)據(jù)集維數(shù)最低的是4維,最高的是16維,樣本數(shù)最少的是150個,最大的54 568,數(shù)據(jù)集的分類數(shù)也各不等,總的數(shù)據(jù)點最高的數(shù)據(jù)集Activity-recognition達436 544個,Iris數(shù)據(jù)集的最少數(shù)據(jù)點也達到600個。
通過對表3的分析可得:針對Iris、Wilt、Avila、letter-recognition、Activity-recognition多個不同的多維數(shù)據(jù)集的聚類,本文提出的聚類算法的迭代次數(shù)均小于K-means、K-means++聚類算法,特別是針對Iris、Activity-recognition數(shù)據(jù)集的迭代次數(shù),K-means、K-means++算法的迭代次數(shù)均2倍于本文算法的迭代次數(shù),針對letter-recognition,Avila數(shù)據(jù)集的迭代次數(shù),K-means算法的迭代次數(shù)也接近與本文算法迭代次數(shù)的2倍。由上可以看出本文的算法在迭代次數(shù)方面的性能較優(yōu)于K-means、K-means++聚類算法,特別是相對于K-means算法,本文算法更勝一籌。

表3 各算法迭代次數(shù)
在誤差平方和方面,通過對表4的分析可得:三個聚類算法針對Iris、Wilt、Activity-recognition數(shù)據(jù)集的誤差平方和十分接近,聚類的效果相差不大,本文算法針對letter-recognition數(shù)據(jù)集的聚類效果略優(yōu)于K-means、K-means++算法,而K-means算法針對 Avila數(shù)據(jù)集的誤差平方和卻遠遠高于K-means++和本文算法,主要原因是K-means算法選取了數(shù)據(jù)集邊緣的噪聲點為類簇中心,使算法陷入局部最優(yōu)的狀態(tài),影響了聚類效果。
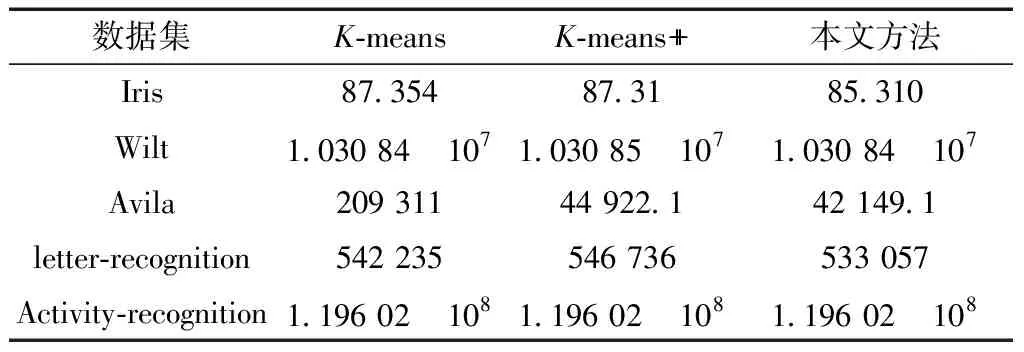
表4 各算法的誤差平方和
通過表5對比三個聚類算法針對相同數(shù)據(jù)集所需的時間,可以發(fā)現(xiàn),K-means算法的時間略低于K-means++算法,主要是由于K-means算法選取K個聚類中心點采用并行算法,而K-means++選用效率較低的串行算法,本文算法所用的時間最短,主要是本文算法的迭代次數(shù)顯著低于K-means、K-means++算法,從而縮短程序運行的時間,進而證明本文算法達到了減少聚類過程中的迭代次數(shù)和提高聚類算法效率的預期效果。
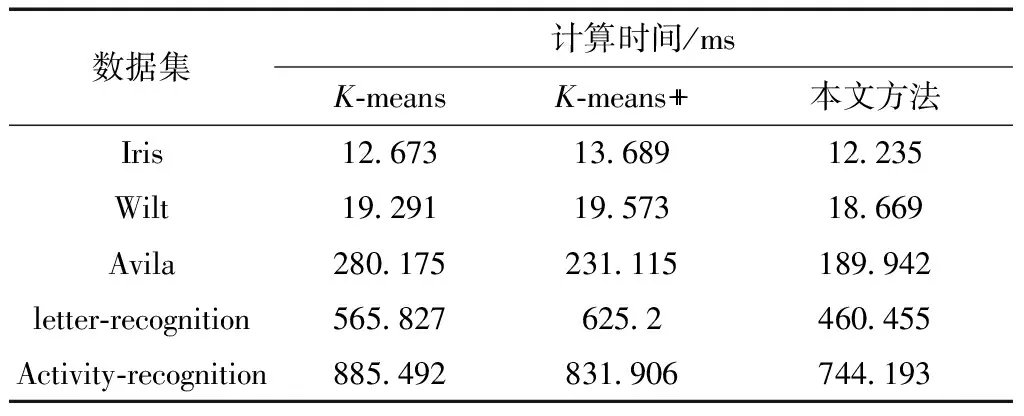
表5 各個算法的時間
針對驗證本文算法在實際實驗中的應(yīng)用,本文又選取了西安交通大學XJTU-SY滾動軸承加速壽命試驗數(shù)據(jù)中工況為1的第五個軸承的數(shù)據(jù)進行聚類,該數(shù)據(jù)集包含垂直和水平振動信號,共有1 638 400個數(shù)據(jù)點,失效位置分為內(nèi)圈和外圈兩類[20]。該數(shù)據(jù)集的具體聚類效果如表6所示。
通過對表6的分析可以看出,本文算法對滾動軸承加速壽命試驗數(shù)據(jù)實際的應(yīng)用效果中,迭代次數(shù),算法運行的時間均小于K-means、K-means++算法,即本文算法整體實驗效果優(yōu)于K-means,K-means++算法。
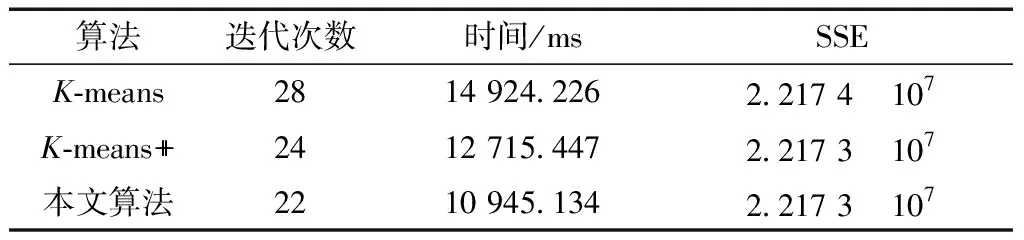
表6 針對XJTU-SY滾動軸承加速壽命試驗數(shù)據(jù)集各算法的聚類性能結(jié)果
4 結(jié)論
K-means算法是一種原理十分簡單和應(yīng)用十分廣泛的聚類算法,但是它存在著初始中心點不穩(wěn)定的問題。本文在分析了經(jīng)典的K-means聚類算法的基礎(chǔ)上,對傳統(tǒng)的聚類算法進行了改進,本文算法基于人工數(shù)據(jù)集和UCI數(shù)據(jù)集的實驗結(jié)果與經(jīng)典的聚類算法結(jié)果相比較表明,本文算法的迭代次數(shù)可以降低50%,甚至更高,所需的時間也顯著降低了10%,不僅解決初始中心點不穩(wěn)定對聚類效果帶來的影響,還改善了聚類效率,效果十分顯著。在下一步的工作中,針對一些數(shù)據(jù)波動范圍較大的數(shù)據(jù)集,考慮在本文的算法中加入數(shù)據(jù)的預處理,如歸一化的處理等,此外對初始聚類中心點的限制空間可以進一步進行優(yōu)化。
猜你喜歡
中老年保健(2021年12期)2021-11-30 02:58:01
好日子(2021年8期)2021-11-04 09:02:46
小學生學習指導(爆笑校園)(2020年6期)2020-07-03 10:01:10
攝影之友(影像視覺)(2019年2期)2019-03-05 08:27:14
攝影之友(影像視覺)(2018年12期)2019-01-28 09:01:02
攝影之友(影像視覺)(2018年12期)2019-01-28 09:01:02
中華詩詞(2018年11期)2018-03-26 06:41:34
小學生學習指導(低年級)(2017年11期)2017-10-23 01:32:36
Coco薇(2016年8期)2016-10-09 02:11:50
中國醫(yī)藥科學(2015年19期)2015-02-27 12:33:11
