基于原圖-光照不變圖視覺詞典改進的閉環檢測方法
2021-08-04 04:08:46胡章芳曾念文肖雨婷鐘征源
電子科技大學學報 2021年4期
關鍵詞:單詞
胡章芳,曾念文,羅 元,肖雨婷,鐘征源
(重慶郵電大學光電工程學院 重慶 南岸區 400065)
近年來,同步定位與建圖(SLAM)[1]是機器人自動導航技術方面的研究熱點。在SLAM中,通過后端優化可以不斷地修正誤差,但是微小的誤差會不斷累積。消除累計誤差的代表性方法是判斷機器人是否“到訪”過某個區域,如果是則視為同一位置,這就是閉環檢測[2]。閉環檢測可以極大地校正漂移誤差,是視覺SLAM的重要組成部分。目前大多數研究是基于外觀的方法,利用提取的圖像特征和描述符來估計是否到達過某個位置。如3DMAP[3]、卷積神經網絡(convolutional neural networks,CNN)[4]、視覺詞袋法(bag-of-words, BoW)[5]等。視覺詞袋法目前在閉環檢測中較為常用。文獻[6]提出了一種基于外觀和顏色組合的雙視覺詞典方法,并添加了貝葉斯濾波來判斷是否閉環。文獻[7]結合了詞袋模型和ORB-SLAM算法,使用場景分割的方法略微提高了準確率。最富標志性的是FABMAP[8]和DBoW2[9],它們使用離線的預訓練詞匯進行在線測試,分為離線預處理和在線處理兩個階段。前者從采集到的整個圖像數據庫中提取視覺單詞,并對其量化構造成一個視覺詞典;后者查找的圖像由基于視覺詞典的直方圖表示,并與數據庫直方圖進行比較來判斷是否閉環。然而,移動機器人不可避免地會處于復雜多變的環境中,包括光照、時間、天氣等,閉環檢測是視覺SLAM的最重要組成部分,易受到上述因素的影響,改善移動機器人在各種條件下(尤其是在光照變化下)的魯棒性,是視覺SLAM不可或缺的工作。
為了減少光照變化對閉環檢測的影響,本文改進了基于視覺詞袋法的閉環檢測方法。除了將原始的彩色圖像作為視覺詞典,還將彩色圖轉為光照不變圖,同時并行生成光照不變圖的視覺詞典,并對其直方圖進行比較,最后計算兩者的最終得分矩陣來判斷是否為閉環。實驗結果表明,本文算法能穩健應對光照變化較大的場景。
1 圖像處理和詞典構建
1.1 原圖特征提取
考慮到系統的性能和運行時間要求,本文使用ORB[10]特征點,選擇描述符長度為256 bit,每位描述符的計算公式如下:
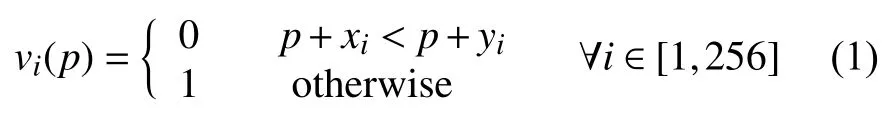
式中,vi是 第i個位描述符的值;xi、yi是通過高斯分布在該點周圍預先建立的隨機選擇位置的灰度值;p代表正在計算的點。本文使用漢明距離來計算描述符之間的距離:

式中,v(p)、v(q)是描述符;XOR表示異或操作。獲得特征和描述符后,將它們轉換為視覺單詞,并將圖像轉換為稀疏向量。
1.2 光照不變圖的生成
文獻[11]提出了一種算法,使得圖像外觀變化只只與光源有關。根據文獻[11],光譜靈敏度F(λ),圖像傳感器的光照響應R,物體的表面反射率S(λ)和物體上的發射光譜功率分布E(λ)之間存在以下關系:
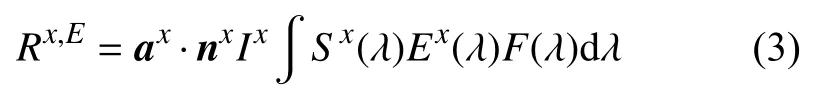
式中,單位向量ax和nx表示物體反射光源的方向和表面法線的方向,取決于物體的材料特性;Ix表示物體點x上 反射光的強度。將光譜敏感度函數F(λ)假設為以波長 λi為中心的狄拉克增量函數[12],從而產生以下響應函數:
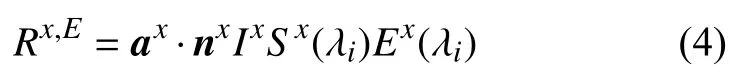
為減少光照強度Ix的影響,得到取決于表面反射率S(λi)的 光照不變圖?,將式(4)取對數:
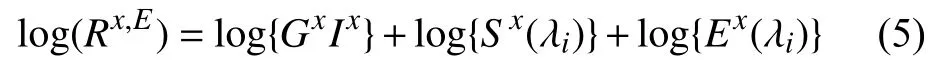
將光照近似為普朗克光源[13],再將維恩常數近似代入普朗克光源中:
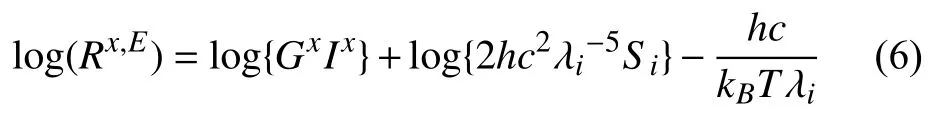
式中,Gx=ax·nx;h為普朗克常數;c為光速;k為玻爾茲曼常數;T是黑體源的相關色溫。
文獻[11]使用一維色彩空間?,該色彩空間由相機傳感器在有序波長 λ1<λ2<λ3下的峰值靈敏度R1、R2、R3決定:
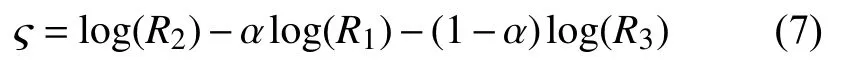
將式(4)代入式(5),當參數α滿足以下約束時,一維色彩空間? 與相關色溫T無關:
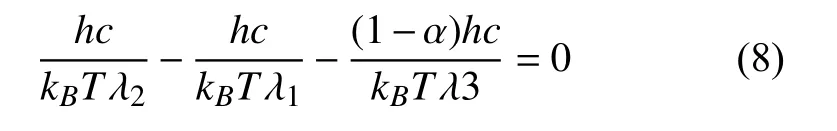
簡化為:
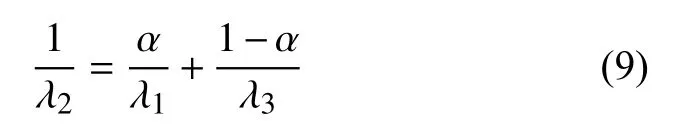
因此,可根據相機傳感器取適當的α值,將原始圖像轉化為光照不變圖像?。
1.3 視覺詞典的構建
先對整個圖像序列進行光照不變變換,再生成原圖-光照不變圖視覺詞典。
將采集到的彩色圖像設為集合SRGB,將光照不變圖設為集合SII,兩者存在以下關系:
SII=?(SRGB)
從每個圖像集中提取特征集FRGB和FII,該特征集由位置xi、si和 特征描述符di組成。
最后,使用如圖1所示的樹數據結構[5]來構建詞典,在每一層使用K-means聚類方法對描述符進行分類。其中只有葉節點存儲可視單詞,而中間節點僅用于查找單詞。該詞典的總容量為Kd。搜索特定的視覺詞匯時,只需要與聚類中心進行d次比較即可完成查找,時間復雜度為O(logN),保證了搜索效率。同時,為了區分每個單詞的重要性,使用直接索引法[5],該方法將單詞的父節點存儲在目錄中以加快比較速度。
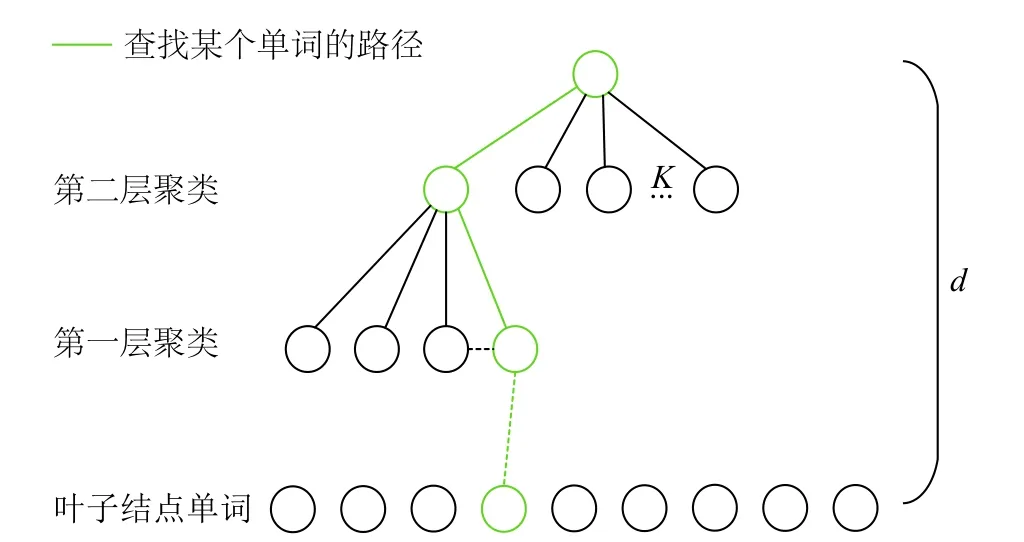
圖 1 詞袋樹結構模型圖
綜上可以生成基于原圖-光照不變圖視覺詞典,圖2總結了該算法。
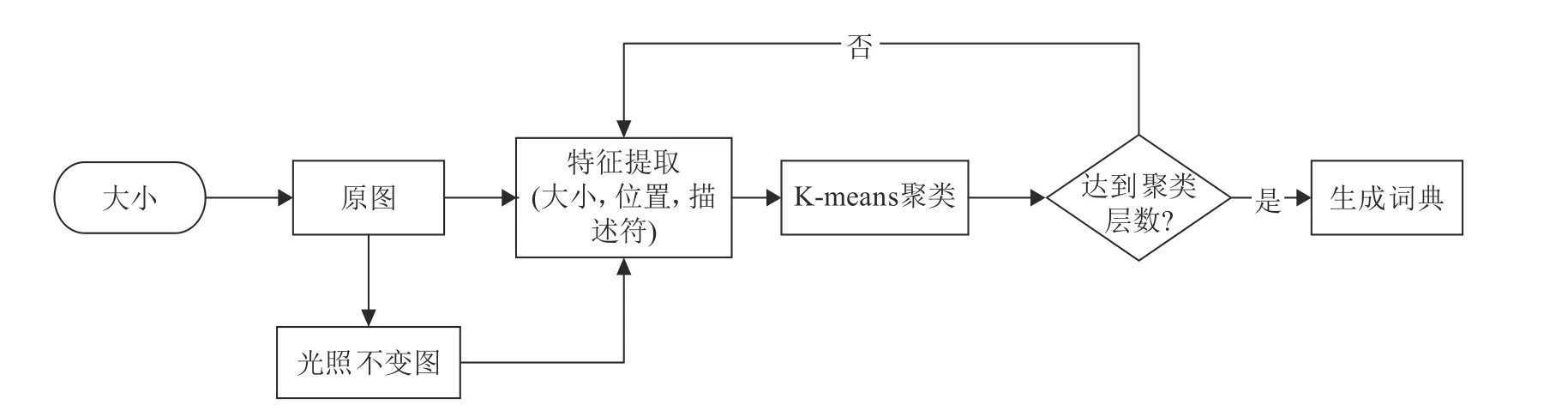
圖2 原圖-光照不變圖詞典生成框圖
2 閉環檢測算法
2.1 單詞篩選
在提取圖像特征和生成詞典后,再利用這些數據完成閉環檢測。盡管視覺描述符已經轉換為視覺單詞,但并非所有視覺單詞都具有相同的識別和區分度。如某些單詞很常見,在許多幀中都可以找到,這種情況下詞類視覺單詞在閉環檢測中基本無作用。因此本文采用詞頻-逆文本頻率指數(term frequency-inverse document frequency, TF-IDF)[14]方法來區分不同單詞的重要性。在詞袋模型中,可以在處理圖像之前計算IDF,即在構建字典時確定IDF屬性。將視覺單詞wi總數用n表示,含有wi的圖像數量用ni表示,則wi的逆文檔頻率為:
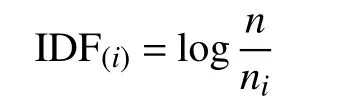
文檔頻率為:
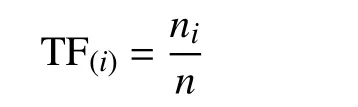
視覺單詞wi的權重為:
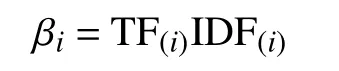
在考慮單詞的權重之后,對于特定的圖像A,將原圖特征和光照不變圖特征添加到詞袋中,完善原圖-光照不變圖詞典:
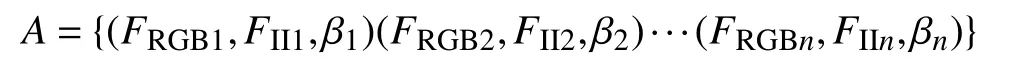
2.2 候選幀的篩選和回環幀確定
根據前文生成的視覺詞典,對每幀圖像計算兩個直方圖。為了快速進行兩幅圖像間的直方圖比較,本文采用直方圖交叉核(histogram intersection kernel)[15]方法來測量兩個矩陣的相似性得分。其原理是先將圖像特征在多分辨率的超平面上進行映射,進而生成多層次的直方圖,最后進行相似度的加權疊加。其交集函數(核函數)的定義如下:
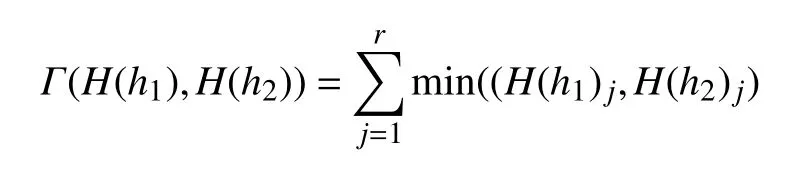
式中,h1,h2為 欲比較的兩個直方圖;H(h1)j為h1直方圖中的第j個bin;r為直方圖中bin的個數。兩個bin的最小值為兩個直方圖每個bin的重疊數,所有bin重疊數之和為該層次的交集函數值。直方圖的相似性函數定義為:
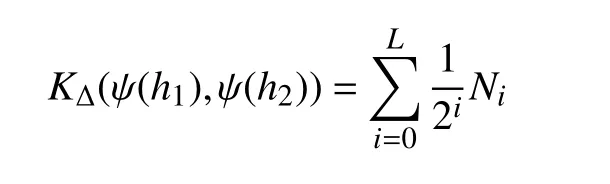
其值可以用來比較相似度。式中,L表示直方圖的層次數;Ni表示連續量的層次之間的交集函數值的差:Ni=Γ(Hi(h1)),Hi(h2))-Γ(Hi-1(h1)),Hi-1(h2))。
定義兩個矩陣間的相似性得分S=KΔ,完成兩個矩陣的相似性得分計算以后,對得分進行歸一化:
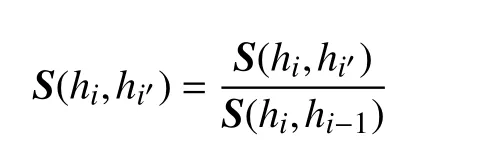
生成最終的得分為:
Sfinal=SRGB+η·Sii
式中,SRGB是原始彩色圖像的視覺詞袋歸一化得分矩陣;Sii是得到的光照不變圖像的視覺詞袋歸一化得分矩陣;Sfinal是最終的得分矩陣;η是兩個得分矩陣間的平衡因子。
由于相鄰兩幅圖像十分相似,容易誤判為閉環。因此,本文將圖像序列根據規模進行分組。每個組通過累加組內每個候選幀的相似性得分來獲得累加的得分。累加分最高的組視為閉環組,閉環組中得分最高的圖像將作為最佳候選幀。選擇分數大于得分閾值的最佳候選幀作為判定正確的閉環對,具體的算法偽代碼如下:


3 實驗結果
3.1 數據集選擇
為了驗證本文算法對光照的魯棒性,需要捕獲同一場景在不同照明條件下的圖像。因此,本文選擇了Nordland數據集,該數據集采集自挪威北部4個不同季節,分為春夏秋冬4個部分,其相同場景在不同時間的比較如圖3所示。同一場景隨著時間的改變發生了很大的變化。本文首先選擇光照變化最為顯著的春季和冬季序列作為實驗序列。

圖3 同一場景在不同時刻的表現形式
3.2 評價指標
第一個評價指標是真(假)陰(陽)性,當機器人經過同一位置時,閉環檢測算法應給出“是閉環”(真陽性)的結果,反之則應該給出“不是閉環”(真陰性)的結果。
另外一個評價指標是準確率(precision)和召回率(recall)。準確率是指某個算法中檢測到的閉環是真實閉環的概率,即P recsion=TP/(TP+FP),召回率是指在所有真實閉環中被正確檢測出來的概率,即 Recall=TP/(TP+FN)。準確率-召回率是一對矛盾,當算法設計得比較“嚴格”時,準確率可以達到100%,但必然會造成召回率下降。因此,在確定一個指標后,若某算法得到的另一個指標比其他算法高,則說明該算法更優。
3.3 圖像匹配結果
為了直觀地分析圖像匹配的相似性規律,本文與閉環檢測中最常用的BoW[5]算法和文獻[16]提出的一種基于改進TF-IDF的SLAM回環檢測算法進行了比較。首先在Nordland數據集的冬季序列中選取了800張在視覺上有明顯差異的圖像,接著在春季序列中選擇了一張圖像,然后逐一匹配冬季序列中的圖像并計算相似度,獲得的相似度曲線如圖4所示。橫軸表示冬季序列索引,縱軸是與選取的春季圖像的相似度值。曲線的最大值表示算法匹配最為相似的圖像,BoW算法、文獻[16]算法、本文算法計算出的最大相似度圖像分別在第29、200、482幀處。
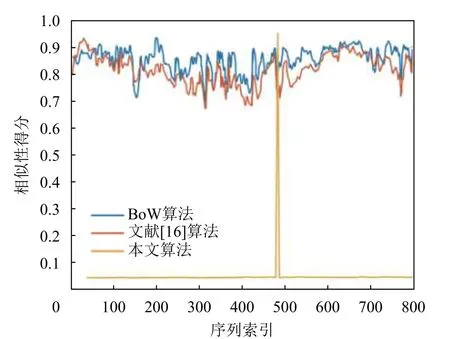
圖4 相似性得分曲線
選取的春季序列圖像與3種算法匹配的圖像如圖5所示。由圖5可知,當同一場景的光照發生變化時,本文算法匹配到了同一場景的圖像,而其他算法都匹配到了錯誤的圖像。

圖5 選取的圖像和算法匹配的圖像
3.4 閉環檢測性能
為了進一步驗證本文算法對光照變化的魯棒性,繼續從春季選擇了800個序列圖像,從冬季選擇了800個序列圖像。將序列中的一個圖像與另一序列中的所有圖像進行比較。每兩個序列計算一次相似度得分,然后根據編號排列得分,得到相似度矩陣S。顯然,S是一個對稱矩陣。離對角線越近意味著圖像與自身和連續幀最為相似,得到的相似度矩陣結果如圖6所示。本文算法基于原圖和光照不變圖,而不是簡單地進行一次圖像的特征匹配,獲得的相似度矩陣基本上沿對角線分布,且噪點較少;而BoW算法出現了多處對角線較為稀疏的地方,如圖中圓圈標識;文獻[16]方法獲得的相似度矩陣有很多噪聲點,且對角線較為稀疏,表示這是錯誤的閉環。因此,本文算法在光照變化明顯的環境中表現良好。
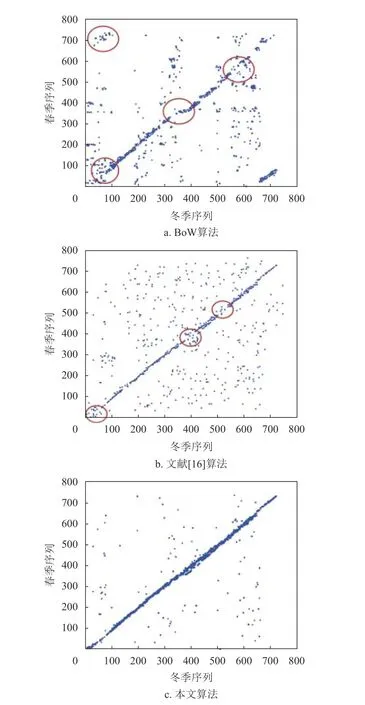
圖6 3種算法的相似度矩陣
3.5 召回率測試
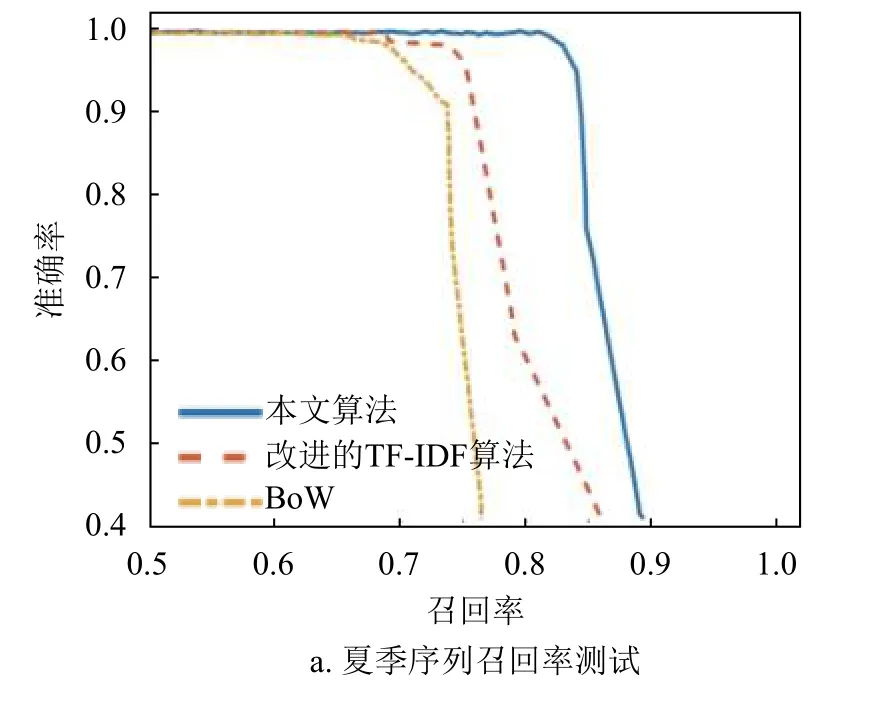
本部分使用Northland數據集的夏季和冬季序列進行詞典構建,然后選擇春季序列進行召回率測試,在100%準確率的前提下實現較高的召回率,夏季序列和冬季序列的結果分別如圖7a、圖7b所示。在冬季序列中,部分場景被積雪覆蓋,可提取的圖像特征減少,本文提出的光照不變圖算法表現更佳。
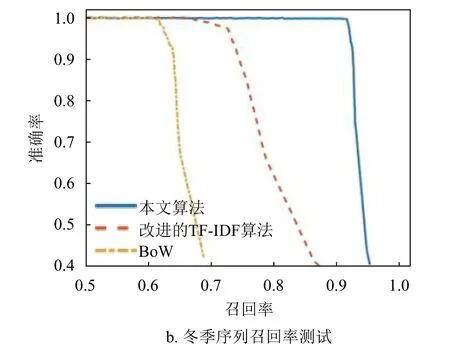
圖7 召回率測試結果
4 結 束 語
視覺詞袋模型因為其計算速度快且圖像表示形式簡單,在閉環檢測中得到了廣泛的應用,但是光照的變化會降低其魯棒性。為了克服這個缺點,本文在傳統的詞袋模型上進行了改進,通過生成原圖-光照不變圖的視覺詞典,歸一化計算最終矩陣相似性得分來提高對光照變化的魯棒性。通過在數據集上和其他算法進行比較,證明了本算法對光照變化具有更好的魯棒性。最近熱門的室外自動駕駛,在長時間運作時,可能會由于陽光的變化而產生錯誤閉環檢測,本文算法可適用于此類情況。然而,在實驗中發現由于另一個視覺詞典的加入,使得本文算法的實時性有所下降,如何在光照魯棒性的前提下保證速率的問題將是下一步研究的重點。
猜你喜歡
閱讀(快樂英語中年級)(2024年9期)2024-10-23 00:00:00
時代英語·高三(2024年3期)2024-09-03 00:00:00
時代英語·高三(2024年3期)2024-09-03 00:00:00
時代英語·高三(2024年3期)2024-09-03 00:00:00
時代英語·高三(2024年3期)2024-09-03 00:00:00
時代英語·高三(2024年3期)2024-09-03 00:00:00
時代英語·高三(2024年3期)2024-09-03 00:00:00
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
智慧少年·故事叮當(2018年11期)2018-05-14 11:48:18
意林(繪英語)(2017年5期)2017-05-15 02:17:23
