檔案數據挖掘的應用實例分析★
2021-08-05 00:38:44鄢明芳鄭川
山西檔案 2021年3期
鄢明芳 鄭川
(1.湖南省語言文字培訓測試中心 長沙 410016;2.中南大學檔案技術研究所 長沙 410083)
1 引言
信息技術的進步推動社會進入大數據時代,數據的價值逐漸開始被各行各業重視。從海量的數據中發現以往未知的有價值信息,以實現豐富的技術應用,輔助科學的管理決策,成為數據挖掘的重要目的[1]。檔案是各行各業直接形成的對國家和社會有保存價值的第一手資料,具有極其重要的信息價值,但囿于檔案數字化、數據化和電子檔案歸檔的發展進程,以及過去檔案由不同地域、不同級別的檔案館分別保存,檔案數據的孤島效應明顯。隨著檔案信息化建設的提速,檔案數據挖掘技術有望發掘檔案數據的隱藏信息價值,提升檔案管理與服務水平,為國家和社會提供更多更好的檔案信息服務。
我國檔案學界與業界對檔案數據挖掘進行了許多研究。理論研究方面,黃小忠和史江探[2]討了數據挖掘技術在數字檔案知識管理中的應用和應該重點關注的問題。蔣紅健[3]研究了高校檔案館開展檔案數據挖掘在管理層面和技術層面的流程和策略。陶水龍[4][5]分析了檔案數據的富礦價值、檔案數據區別于大數據的特點,以及大數據環境下檔案信息化建設中存在的機遇與挑戰,并深入分析了語義網技術在檔案數據挖掘中的作用,在檔案管理系統建設中引入語義網可能存在的問題。張偉[6]研究了檔案數據挖掘在前期規劃、資源收集、數據預處理和數據分析模型等問題。王蘭成和劉曉亮[7][8]分析了網絡檔案數據挖掘的技術特點和發展趨勢,針對檔案數據挖掘過程涉及的檔案敏感信息,提出了敏感元祖及其密度的相關保護方案。張燕超[9]論述了設計檔案數據挖掘模型應遵守的原則與基本框架,并以江蘇省昆山市民生檔案智慧分析挖掘應用平臺項目作為案例進行了分析。實證研究方面,鄭向陽[10]結合兩個具體案例分析了數據挖掘技術在城建檔案中的應用方法和應用價值。陳玉亮和張代華[11]以江蘇科技大學的國家級科研項目數據為例敘述了科研檔案數據挖掘技術輔助學校科研分析和決策的經驗。黃華坤[12]介紹了國土資源知識服務需求背景下用AutonomyIdol開發國土資源檔案知識挖掘與應用平臺的經驗。覃艷[13]、劉煥[14]、榮晨[15]、李宇斐[16]、杜寶琛[17]、牛玉婷[18]等人介紹了醫療檔案、電子病歷在數據挖掘技術加持下用于開展知識發現與智能醫療服務的過程。楊茜雅[19]介紹了中國聯通建設“兩庫兩平臺”企業檔案利用系統,通過檔案知識圖譜實現電子檔案智能化管理、輔助企業決策的案例。張泰齊[20]以沈陽某企業為例介紹了基于數據挖掘的企業檔案管理信息系統的設計與實現。
從文獻梳理可知,與商業、金融、電信等其他容易產生大數據的行業相比,檔案行業的數據挖掘技術研究和應用相對還很少,其中醫療檔案數據挖掘的相關研究占比稍高,數據挖掘技術在其他類別的檔案與其他行業的應用場景下還有很大的發展空間。“精準扶貧”是我黨的戰略思想,高等學校是實施教育精準扶貧的重要陣地,做好高校貧困生資助工作,對破除貧困代際傳遞、落實我國扶貧戰略具有重要意義[21]。國家助學金作為高校覆蓋范圍最廣的資助手段,目前還難以做到完全精準地分配給相應的家庭經濟困難學生,將檔案數據挖掘技術應用于高校助學金評定的輔助分析與決策,將有助于我國教育精準扶貧工作的開展。
2 檔案數據挖掘相關知識
2.1 數據挖掘與檔案數據挖掘
數據挖掘是從大量的、隨機的、不完全的、有噪聲的、模糊的實際應用數據中,提取隱含在其中的人們過往不知道但又潛在有用的信息和知識的過程[22]。數據挖掘過程涉及數據庫技術、統計學、人工智能、可視化技術等多種技術的綜合運用,其任務分為預測和描述兩大類。預測性任務是從歷史數據中發現隱藏的知識和關系來預測未知數據的特性,描述性任務是不人為指定研究對象,通過模型算法尋找事物間的本質聯系[23]。
檔案數據挖掘是以檔案數據為特定對象,是數據挖掘技術在檔案領域的應用。檔案數據的構成一般包括檔案目錄數據、檔案元數據和檔案原文數據,其中目錄數據與元數據以結構化數據為主,檔案原文主要是文本數據。而檔案原文是數字檔案信息的主要組成部分,故文本挖掘技術在檔案數據挖掘中占有極重要的地位。根據數據對象、挖掘算法和應用目的的不同,檔案數據挖掘主要有聚類分析、分類預測、關聯分析、回歸分析、序列標注、信息檢索、文本處理等類型[24]。聚類任務的目標是將給定的檔案數據集合劃分成許多子集或簇,使得同一個簇內的樣本在屬性特征上盡可能相似,不同簇的樣本盡可能不同,其核心作用是對檔案數據進行降維處理。分類預測是基于已知屬性對檔案數據所屬的類別進行判斷,預測的類別通常是主觀指向性的,其目的是簡化用戶對檔案數據對象的認知與理解判斷。序列標注主要是檔案原文文檔數據在時間或空間維度上有前后依賴關系的特殊分類問題。信息檢索是從大規模非結構化檔案數據的集合中找出滿足用戶信息需求資料的過程,其重點是提供基于檔案內容和檔案知識的檢索服務。關聯分析是發掘存在于大量檔案數據集中的相關性或關聯性,從而描述檔案信息中某些屬性之間的隱藏規律和模式。回歸分析是研究檔案數據中某些因變量和自變量之間的因果關系。
2.2 檔案數據挖掘的基本流程
不同類別的檔案數據挖掘問題采用的算法不盡相同,在數據預處理、訓練測試方法、參數設置、模型評價等具體實施步驟上都有自身的特點和區別,但在主要問題處理流程上都有相通之處。檔案數據挖掘的基本流程可分為問題定義、檔案數據準備、檔案數據挖掘和解釋評估四個階段。
問題定義階段的主要任務是梳理檔案數據的基礎數據狀況,這是檔案數據挖掘的活水之源,基于已有的數據基礎條件分析在檔案業務上可以實現的具體需求;或是從檔案業務需求出發定義問題目標,分析實現該目標需要準備怎樣的檔案數據條件。問題定義是后續檔案數據挖掘的基礎。
檔案數據準備階段通常會在檔案數據挖掘工作中占據很大的工作量,是非常重要的階段,它將決定檔案數據挖掘項目是否成功。數據準備階段需要研究者建立檔案領域的基礎知識和業務知識,特別是項目預期目標、所期待的結果以及擬解決的業務問題,它將對之后的數據處理起到方向指引作用。對于檔案文本數據,需通過文本建模將其轉化為數值型數據、空間向量等結構化數據。數據準備階段包括檔案數據集成、檔案數據選擇、檔案數據預處理和檔案數據轉換等步驟,最終得到能表征原有檔案特性、具有規范統一格式、適合進行后續處理的有效數據。
檔案數據挖掘階段是選擇和運用合適的數據挖掘算法形成模型的過程。首先確定要發現的檔案知識含義和類型,其次根據具體要求選用不同的知識發現算法、參數和配置,構建數據挖掘模型,經算法計算以一定的方式進行知識表示后再對挖掘過程中發現的知識或模式進行解釋和評估,剔除其中冗余和無關的內容,若結果不能滿足目標要求,則需返回前面的某些步驟反復計算提取。
解釋評估階段對檔案數據挖掘模型及結果進行評價,確認模型和結果的功能性和可信度,并將所發現的知識和模式以可視化等用戶易理解的方式呈現出來。對檔案數據挖掘結果的檢驗可以使用原始未知樣本數據檢驗,也可以用另一批能反映客觀實際規律的數據進行檢驗,如不能達到預期要求,應分析問題理解是否偏差、檔案數據樣本是否缺乏代表性、建模算法是否有效、模型是否有效等。
3 基于檔案數據挖掘的高校助學金評定分析
3.1 檔案數據挖掘輔助助學金評定的問題定義
3.1.1 助學金評定的工作背景
目前高校助學金還難以做到完全精準地分配給相應的家庭經濟困難學生,助學金的評定主要存在三類偏差:(1)隱性貧困生,學生家庭經濟困難,但未被納入助學金發放范圍;(2)偽貧困生,學生并非家庭經濟困難,但被納入了助學金發放范圍;(3)評定等級錯配,學生家庭經濟困難,但未被納入與之等級對應的助學金發放范圍。助學金評定偏差讓本就稀缺的資助資源更為緊張,國內外學者和從業人員對如何準確評定助學金展開了很多研究,其中家庭經濟收入情況評估是關鍵標準。
美國、德國、英國、日本等經濟發達國家稅收體系相對健全發達,主要通過經認可的應稅收入按有關推斷算法計算學生的家庭收入[25];菲律賓、尼日利亞、秘魯等欠發達國家主要依靠包含收入證明、財產證明、家庭人口、父母職業等系列指標來評估學生的家庭收入情況[26][27]。我國高校助學金評定常與貧困生認定結合,主要依據有家庭經濟因素、特殊群體因素、地區經濟社會發展水平因素、突發狀況因素、學生消費因素和其他影響家庭經濟狀況的有關因素[28]。相關信息的準確齊全是正確評定的關鍵,也是實際工作中的難點,由此發展出了三級政府證明法、相關困難證件法、居民最低生活保障線比照法、班委會評選法、消費水平界定法等十余種評定方法[29]。
本文以湖南某高校的助學金發放工作為樣本,運用檔案數據挖掘技術綜合解析學校教學檔案、財會檔案和行政檔案,分析學生的在校消費水平與助學金評定等級的聯系,輔助定位助學金發放中的隱性貧困生、偽貧困生和評定等級錯配,并從定量分析的角度剖析助學金評定偏差的來源,為今后高校助學金的發放和精準扶貧工作提供輔助和指導。
3.1.2 檔案數據挖掘輔助助學金評定的需求分析
高校國家助學金分為一等(家庭經濟特殊困難)、二等(家庭經濟困難)和三等(家庭經濟一般困難),一等助學金資助金額最高,后兩級金額遞減。高校助學金發放采取“個人申請—學校認定—資助發放”的模式。學校統籌將國家助學金名額分配至各二級學院,由各學院學生資助工作分管領導、班主任、輔導員等相關人員組成國家助學金評定小組具體落實本院助學金評定推薦工作。學院在不突破本院總額度和各資助等級比例約束的前提下為本院學生分配助學金名額。
校園一卡通是在校大學生食堂就餐、超市購物、校車乘車、浴室、洗衣、機房、小額自助繳費等消費的載體,還具備圖書借閱、校醫院就診、門禁識別、身份認證等功能。系統包含了學生大量真實的生活及消費數據,盡管只是學生的校內消費情況,但這部分消費流水基本囊括了大學生在校的生活和學習消費,也是他們消費的主要方面,可以在很大程度上客觀地反映學生的日常消費水平,進而反映其家庭經濟水平。通過唯一的學號將三大類檔案數據串聯起來,揭示學生消費水平與助學金發放結果之間的聯系。就助學金評定的出發點而言,學生消費水平與其獲得助學金額度為負相關,在大樣本統計分析的情況下,離群點可作為隱性貧困生、偽貧困生和評定等級錯配的嫌疑點,進行重點調查。
3.2 檔案數據挖掘輔助助學金評定的數據準備
檔案數據來自該校的教學檔案、財會檔案和行政檔案。教學檔案中的招生、學籍管理等分類包含了學生的姓名、學號、學院、專業、學籍狀態等個人基礎信息。財會檔案中的賬簿、其他會計資料等分類包含了學生校園卡的消費明細賬、消費網點刷卡對賬單、分戶賬等財務數據。行政檔案中有國家助學金評定、發放的有關文件、評定記錄和發放名冊等信息。不同類別檔案數據的歸檔要求、字段組成、數據格式、數據類型等屬性均有差別,進行數據挖掘前需對其進行預處理,主要包括數據采集、數據清洗、數據集成等流程。
為了不影響原檔案數據并實現快速運算處理,通過Web Service接口從該校數字檔案管理系統采集2016-2017學年相關檔案數據,在SQL SERVER 2012中建立對應的數據表存儲,再用MATLAB 2015a 通過ODBC連接SQL SERVER進行數據處理。在全體校園卡刷卡消費數據中剔除與國家助學金無關的教職工、研究生、留學生、預科生、校友卡和臨時卡的刷卡記錄。剩余的本科生中,大四學生就業面試和實習會導致消費行為變化,大一新生適應高校生活期間消費行為可能不穩定,也予以排除,另外去除休學、退學、開除等特殊學生的數據,得到有效學生樣本8277人。以樣本學生的學號為索引從教學檔案中獲取其個人基本信息數據,再從行政檔案中獲取國家助學金發放名冊,統計時段內所有樣本學生中獲一等助學金者225人,二等助學金443人,三等助學金1513人,共計2181人。將學生學號作為主鍵,集成教學、財會和行政三類檔案數據。舍棄消費記錄中的節假日和寒暑假期間數據,保證所用學生樣本的校內消費行為具備一致性。刪除學生姓名、身份證號、設備號、流水號等隱私字段和無關字段,對存在字段缺省的記錄進行補齊處理,并清除噪點、統一數據格式、檢查數據一致性,方便后續統計分析。
3.3 檔案數據挖掘輔助助學金評定的運算
大學生校園卡消費主要由經常且必須的食堂就餐消費和超市購物、校車乘車、自助洗衣、機房等其他差異性消費組成。考慮到存在校外就餐等情況會導致不同學生的食堂就餐次數不盡相同,使用食堂餐均消費值相對食堂餐飲消費總值更能準確地表征學生在餐飲方面的消費水平。其他消費的發生時間和次數存在較強隨機性和個體差異,用統計期內的日均消費值計算,可濾除偶然性事件的大幅波動,反映學生長期穩定的消費水平。設樣本中任意一位學生的校園卡日均消費

其中AveBre(i)、AveLun(i)、AveDin(i)分別為該生早餐、中餐、晚餐的餐均消費值,AveElse(i)為其他日均消費值,AveCon(i)計算過程如下:
(1)將該生的所有校園卡消費記錄按食堂消費和其他消費聚類,再對聚類后的食堂消費按三個時間段進行離散化處理,06:00-10:00為早餐,11:00-13:00為中餐,16:00-19:00和21:00-22:00為晚餐。
(2)遍歷所有統計日,當日早餐時間段內有消費記錄的記為一次就餐,AveBre(i)=總早餐消費金額/總早餐就餐次數。同理計算AveLun(i)和AveDin(i)。
(3)統計聚類后的其他消費,AveElse(i)=(總超市消費+總校內公交消費+總浴室消費+總洗衣房消費+總其他小額消費)/統計期間總日數。
計算得到所有樣本學生的校園卡日均消費{AveCon(1),AveCon(2),……,AveCon(i)}后,通過線性函數轉換進行無量綱化處理

得到所有樣本學生的校內消費水平指數{Con(1),Con(2),……,Con(i)},Con取值范圍為[0,1],數值越大代表該學生校內消費水平越高。對Con以0.01為間隔離統計頻率得出所有樣本學生的消費水平分布,經K-S檢驗符合=0.4499,=0.1601的正態分布,顯著性水平為0.050。
以樣本學生的校內消費水平為依據推測理論上各級國家助學金的發放集合,再與行政檔案數據中的實際助學金發放集合進行對比,篩選異常偏離點作為隱性貧困生、偽貧困生和評定等級錯配三類評定偏差的嫌疑點。篩選所得的偏差越少,代表助學金的實際發放越精準。從流程上看,學校助學金發放精準度一方面取決于學校給各學院分配的助學金名額是否合理,另一方面取決于各學院對所獲助學金名額的評定是否準確。分別以全校為對象和以各學院為對象篩選三類助學金評定偏差,并對比兩種篩選對象下偏差的大小,推斷評定偏差來源于在哪個環節,當學院評定偏差不為零時:各學院偏差直接代表學院助學金評定環節的偏差情況;若全校偏差等于各學院偏差,則學校的助學金名額分配基本合理,總偏差來自學院的助學金評定環節;若全校偏差大于各學院偏差,則學校的助學金名額分配也存在偏差。
3.4 檔案數據挖掘輔助助學金評定的結果分析
3.4.1 助學金評定的三類偏差
根據該校助學金發放名冊,統計期內國家一、二、三等助學金實際發放比例分別為2.72%、5.35%和18.28%,對所有樣本學生按Con升序排列,以學生校內消費水平高低作為各級國家助學金的理論評定依據,Con值處于前2.72%的學生理論上獲得一等助學金,其發放集合為Con∈[0,0.1478)。同理得到二等助學金發放集合為Con∈[0.1478,0.2228),三等助學金發放集合為Con∈[0.2228,0.3451),無助學金發放集合為Con∈[0.3451,1]。在所有樣本學生Con列表中標記其實際獲得的助學金等級,得到一、二、三等助學金實際發放集合,這些集合為非連續區間。以0.01為間隔統計頻率,繪制所有樣本學生校內消費水平分布圖,并分別疊加國家一、二、三等助學金理論發放集合和實際發放集合中學生的校內消費水平分布,如圖1所示。

圖1 助學金理論發放與實際發放的學生消費水平分布圖
圖中綠、藍、粉三色柱狀體分別為一、二、三等助學金理論發放集合及其消費水平分布,灰色柱狀體為理論未獲助學金集合及其消費分布;黑、紅、紫三色曲線分別為一、二、三等助學金實際發放集合及其消費分布,黃色曲線為實際未獲助學金集合及其消費分布。分別統計圖1中理論發放和實際發放情況下一、二、三等助學金和無助學金學生的消費水平均值和分布區間寬度,結果如表1所示。

表1 理論發放和實際發放消費數據統計表
數據表明,該校助學金的實際發放總體上與學生消費水平呈負相關,一、二、三等助學金和無助學金學生的消費水平均值逐級增大,與理論發放情況的趨勢一致,但各級助學金的消費水平分布有交叉,有的甚至與均值偏離很大,這些異常偏離點中可能存在隱性貧困生、偽貧困生和評定等級錯配。對比每個學生分別在理論發放與實際發放情況下獲助學金的等級,建立評定偏差篩選規則如表2所示。

表2 助學金評定偏差篩選規則表
對任一樣本學生而言,理論等級與實際等級相同視為吻合;理論等級與實際等級相差一級,可能存在評定偏差,也可能是使用學生消費水平指數Con本身存在的系統性誤差;理論等級與實際等級相差兩級,存在評定偏差的可能性較強;理論等級與實際等級相差三級,則存在評定偏差的可能性極大。其中理論上應獲助學金但實際上無助學金的,考察隱性貧困生的可能;理論上無助學金但實際上獲得助學金的,考察偽貧困生的可能;理論上和實際上都獲助學金,只是二者等級不同,考察評定等級錯配的可能。按此規則在全校樣本學生中篩選出助學金評定偏差共743人,其中隱性貧困生167人,偽貧困生161人,評定等級錯配415人。
3.4.2 助學金評定偏差來源分析
(1)二級學院助學金評定偏差
以二級學院為對象,分別考察各學院助學金評定的三類偏差情況。
將全校樣本學生的消費水平指數Con按學院聚類后得到各二級學院的學生消費水平分布。對任一學院,將該院學生以Con升序排列,按該院各級助學金實際發放比例劃定該院的各級助學金理論發放集合,再在學生Con列表中標記其實際獲得的助學金等級,得到各級助學金實際發放集合。繪制該院學生校內消費水平分布圖,并分別疊加上述一、二、三等助學金理論發放集合和實際發放集合中學生的校內消費水平分布。通過表2的助學金評定偏差篩選規則篩選各學院的助學金評定偏差并統計。其中助學金實際等級與理論等級相差大于兩級的學生,作為評定偏差進行標記:理論上應獲一、二等助學金實際上未獲助學金的學生,標記為隱性貧困生;理論上可獲三等助學金和不能獲得助學金,實際上卻獲得一等助學金的學生,標記為偽貧困生;理論上應獲助學金等級與實際獲得的助學金等級相差兩級的學生,標記為評定等級錯配。
整理以各學院為對象和以全校為對象,分別篩選出來的隱性貧困生、偽貧困生和評定等級錯配的學生名單,綜合統計數量如表3所示。

表3 分學院篩選和全校篩選的助學金評定偏差統計
統計結果顯示,相同篩選算法下,相比在全校范圍共同篩選,各學院分別單獨篩選得到的三類助學金評定偏差數量減少了近一半,除“強偽貧”和“強隱貧”兩者篩選結果一致以外,其余偏差類型的比例都明顯降低。這表明各學院的助學金評定本身存在一定的偏差,同時學校的助學金評定偏差大于各學院的助學金評定偏差,二者的差值來源于學校給各學院分配助學金名額的過程。用篩選出的偏差人數估算,三類助學金評定偏差中,47.78%來源于學校的助學金名額分配環節,52.22%來源于學院內部的評定環節。
(2)學校助學金名額分配偏差
評價學校給各學院分配的助學金名額合理與否,實質上是判斷學院學生的家庭經濟水平情況與該院所獲各級助學金名額之間的匹配關系。在全校助學金理論發放和實際發放兩種情況下,分別計算各學院各級助學金獲得者的人數比例及其消費水平均值,考察它們的相關性,若實際值與理論值接近,則助學金額度分配合理。將各學院學生消費水平指數Con按全校各級助學金理論發放和實際發放聚類,分別在理論情況和實際情況下計算各學院獲一、二、三等助學金人數占該院總人數的比例和該院一、二、三等助學金獲得者的消費水平均值,繪制各學院助學金比例與學生消費水平關系散點圖,如圖2所示。
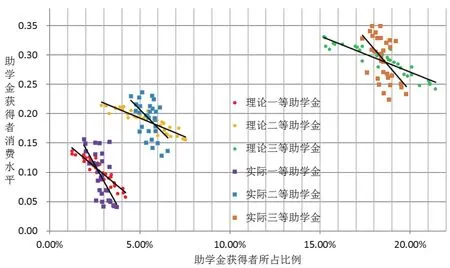
圖2 各學院助學金比例與學生消費水平關系圖
圖中橫坐標為學院某級助學金名額占該院總人數的比例,縱坐標為該院該級助學金獲得者的消費水平均值。每個學院的數據在圖中用六個點標記,紅、黃、綠三色圓點分別為一、二、三等助學金理論發放數據,紫、藍、橙三色方點分別為一、二、三等助學金實際發放數據,六條黑色直線為使用線性函數對六類散點擬合所得的趨勢線。對圖2中的數據進一步計算各學院獲各級助學金人數比例與其消費均值的分布區間,以及兩者的Pearson相關系數,結果如表4所示。
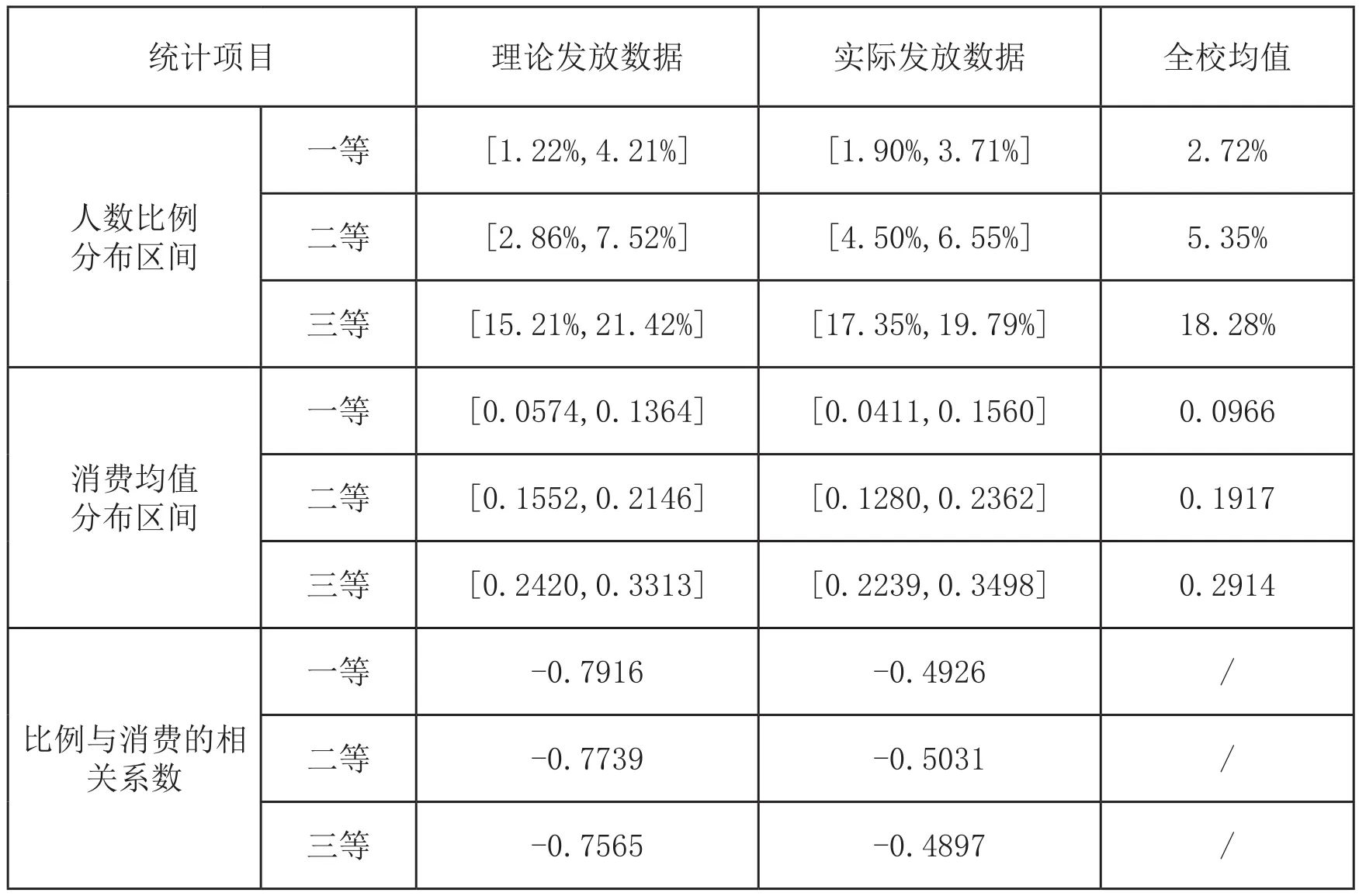
表4 各學院助學金發放數據分析結果
總體上看,各學院助學金發放比例與助學金獲得者的消費均值在理論情況下具有較強的負相關性:獲得助學金比例越高的學院,其學生消費水平均值越低,反之亦然。但在實際助學金發放時這種負相關較弱。具體來看,各學院各級助學金的實際發放比例比較接近全校平均值,學校在向各學院分配助學金名額時傾向于按學院的學生人口基數等比例分配;而理論發放情況下,各學院各級助學金的發放比例差別較大,特別是一、二等助學金比例的極大值、極小值與全校均值偏離50%左右。
全校所有樣本學生消費水平均值為0.4499,將樣本學生的消費水平指數Con按學院聚類后計算各院學生消費水平均值,所得結果在區間[0.3972,0.5012]內散布,說明學院之間的整體貧富程度存在差異。助學金理論發放與實際發放的比例差別,導致了各學院助學金獲得者的消費水平均值差異:理論上各學院各級助學金獲得者的消費水平均值更接近對應的全校均值;而實際上各學院各級助學金獲得者的消費水平均值與對應的全校均值差異較大,相對富裕學院助學金獲得者消費水平均值高于相對貧困學院。這種比例差別導致整體相對富裕學院的助學金評定門檻比整體相對貧困學院更低:如圖2中,消費水平均值0.15附近的學生群體在相對富裕的學院可獲一等助學金,而在相對貧困的學院只能獲得二等助學金(紫色方點與藍色方點在縱軸上的重合范圍);消費水平均值0.23附近的學生群體在相對富裕的學院可獲二等助學金,而在相對貧困的學院只能獲得三等助學金(藍色方點與橙色方點在縱軸上的重合范圍)。
由此可知,學院之間的助學金實際名額比例失衡,形成了助學金評定的規則性錯配,這種錯配偏差與各學院內部的助學金評定環節無關。
3.5 檔案數據挖掘輔助助學金評定的驗證評價
導出表3中以各學院為對象和以全校為對象,分別篩選出來的助學金等級實際值與理論值相差大于兩級的隱性貧困生、偽貧困生和評定等級錯配的學生清單,作為助學金評定偏差嫌疑點返回給學校學生資助管理中心進一步跟蹤排查。工作人員采取評定資料審查、與學生談話、生源地電話問詢、班級問卷調查等方式重新評估被排查對象的國家助學金等級。剔除1人因休學無法重新評估,人工排查結果如表5所示。

表5 助學金評定三類偏差人工排查結果
由表5知,從全校層面看存在三類助學金評定偏差嫌疑共76例,其中各學院助學金評定環節占42例,學校向各學院分配助學金名額環節占34例。即總評定偏差中,來源于學校名額分配環節和學院組織評定環節的偏差分別占44.7%和55.3%。通過改進學校助學金名額分配方案,有望消除此環節帶來的評定偏差。檔案數據挖掘算法篩選出的隱性貧困生、偽貧困生和評定等級錯配的準確率分別為60.9%,61.1%和53.1%,對學校助學金的評定和偏差嫌疑排查具有積極意義。
4 高校檔案數據建設的建議
檔案數據挖掘輔助高校助學金評定的案例將學校以往孤立的教學檔案數據、財會檔案數據和行政檔案數據關聯起來,通過數據挖掘技術中的異常檢測方法,發現了檔案數據中有價值的隱藏信息,為學校教育精準扶貧的判斷和決策提供助力和依據。檔案數據挖掘的實踐也為高校檔案數據收集、檔案數據建設和檔案數據應用積累了一定的經驗。
4.1 做好檔案數據化建設規劃
社會的數字化給檔案行業帶來了很大的挑戰,也帶來了許多新的機遇。2016年發布的《全國檔案事業發展“十三五”規劃綱要》提出要運用大數據、人工智能等技術,提高檔案館信息化程度,提高檔案信息資源深度開發與服務水平[30]。《國家中長期教育改革和發展規劃綱要(2010-2020年)》指出“信息技術對教育發展具有革命性影響,必須予以高度重視”[31]。高校檔案館作為高等教育檔案的主要管理機構,應該提前做好檔案數據化建設規劃,結合學校信息化建設目標與社會信息化發展趨勢制定既具有前瞻性又切合實際的檔案數據建設規劃。
4.2 擴大檔案數據的收集范圍
數據的價值會隨數據的數量增長在某個臨界點產生質的飛躍,大數據便是典型代表。傳統檔案工作由于實體檔案收集成本、管理成本等因素的限制,歸檔范圍通常只包含一些比較重要的文件范圍。而數字時代保管數據的空間成本和財務成本大大降低,電子檔案歸檔的邊際成本極低,歸檔系統建設完成后增加收集的數據范圍增加的系統開銷微乎其微。擴大檔案數據的收集范圍,在進行真實性、完整性、可用性和安全性檢測的基礎上對電子文件和數據應收盡收、應歸盡歸,對提升檔案數據資源庫的價值具有重要作用。未達到檔案規格的有關業務數據,以資料的形式收集保管也未嘗不可。
4.3 提高檔案數據的采集質量
規范的檔案數據是進行數據挖掘的基礎,從數據采集階段嚴格把控檔案數據質量,既有利于日常檔案管理利用,在進行檔案數據挖掘時也能大大減輕數據預處理的工作量。提高檔案數據采集質量,一方面要建立健全各類檔案數據歸檔的標準、制度和流程,讓數據質量評價有據可依,另一方面要從檔案數字化向檔案數據化跨越。如,實踐中發現數字化加工OCR識別的檔案原文與原生電子文檔相比,在數據挖掘時效果差距巨大。
4.4 積極探索檔案數據的應用
檔案的最終價值在于利用,數字檔案和檔案數據最大的優勢在于網絡傳輸效率高和可機器識別,其在網絡共享、大數據挖掘、知識化服務、數字人文等方面的潛在應用價值遠超傳統紙質檔案。在保障檔案數據的數據安全、個人隱私保護、商業秘密保護、檔案開放法律法規等問題的前提下,積極探索檔案數據的新型應用,也必將給高校檔案數據建設帶來積極的經驗和反饋。
猜你喜歡
作文大王·笑話大王(2021年4期)2021-04-26 19:00:35
大眾投資指南(2021年35期)2021-02-16 01:06:26
電影(2018年9期)2018-11-14 06:57:21
作文世界(小學版)(2018年4期)2018-10-16 17:13:34
電力與能源(2017年6期)2017-05-14 06:19:37
快樂作文·低年級(2016年12期)2017-01-03 20:52:44
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
快樂作文·低年級(2016年6期)2016-06-24 18:58:40
信息通信技術(2015年6期)2015-12-26 01:16:46
河南科技(2014年23期)2014-02-27 14:18:43
