維吾爾語形態分析研究綜述
2021-08-06 08:23:08阿布都克力木阿布力孜姚登峰哈里旦木阿布都克里木
計算機工程與應用 2021年15期
劉 暢,阿布都克力木·阿布力孜,2,姚登峰,哈里旦木·阿布都克里木,2
1.新疆財經大學 信息管理學院,烏魯木齊 830012
2.新疆財經大學 絲路經濟與管理研究院,烏魯木齊 830012
3.北京聯合大學 北京市信息服務工程重點實驗室,北京 100101
隨著“一帶一路”戰略提出,我國與中亞各國聯系日益密切,新疆地區迎來了新的發展機遇,同時也面臨著巨大的挑戰,語言交流問題成為其中的一個關注焦點。維吾爾語是一門歷史悠久的語言[1],其使用者主要分布于中國新疆,也是新疆官方用語之一,經常用于當地的電視頻道、交通標志和廣告牌等。中國境內維吾爾語使用者大約有1 000萬~2 500萬人[2]。為了達到語言互通的目的,翻譯等人工語言處理需要耗費大量的人力財力物力。
自然語言處理(Natural Language Processing,NLP)是主要的語言信息處理技術,其目標是通過對文本或語音的有效處理從而達到促進人機交互、方便人與人之間交流的目的[3]。
在NLP中,形態分析(Morphological Analysis)用于研究詞匯內部的構造和變化問題。與句法分析(Syntax Analysis)[4]和命名實體識別(Named Entity Recognition,NER)[5]等NLP 其他工作相比,形態分析更加注重詞匯內部結構及其變化的分析,能夠提高后續相關技術性能。做好維吾爾語形態分析工作,不斷地提高機器處理能力,能夠為“一帶一路”等戰略提供技術支撐,達到降低交流成本和語言互通的目的。
近幾年,國內外維吾爾語形態分析工作發展較為迅速,新疆師范大學、新疆大學、中國科學院、日本京都大學、清華大學和中央民族大學等機構發表了較多的研究成果。
1 維吾爾語
維吾爾語屬于阿爾泰語系突厥語族中的一支[6]。歷史上,維吾爾語有多種書寫文字,目前新疆地區主要采用阿拉伯文字書寫,有時轉換成拉丁文字進行處理。與英語(屈折語)、漢語(孤立語)等大規模流行語言不同,維吾爾語主要使用黏著法構詞并且屬于低資源語言[7],每個維吾爾語單詞由從右向左書寫的字符構成[8]。根據形態學結構,每個維吾爾語單詞可以被劃分為子詞(Sub-Word)單元,根據語法一般分為詞素(Morpheme)、音節(Syllable)和音素(Phoneme)[9]。構建子詞模型有助于緩解未登錄詞(Out of Vocabulary,OOV)等問題[10-12]。子詞單元實例如表1所示。

表1 維吾爾語子詞單元實例Table 1 Examples of sub-word units in Uyghur
在維吾爾語中,詞素又稱語素,是不可再分的語法單位[13],包括詞根(Root)和詞綴(Affix)等。維吾爾語共有40 000 多詞根(外來詞除外)[14],32 個字符對應32 個音素[15]。其中,詞根是最小的語義單位[16]。詞干則是由多個詞根或詞根和構詞詞綴構成[17],有時不會區分詞干和詞根。通過有限的詞干和詞綴不同組合,理論上維吾爾語能夠產生無限詞匯,表達出不同的語義,同時由于多數詞匯出現次數較少造成了嚴重的數據稀疏性現象[18],從而導致嚴重的OOV問題[7]。維吾爾語詞匯的一般形態結構是:詞干+詞綴1+詞綴2+…+詞綴n。同一單詞在不同的語境條件下會有不同的切分結果[19]。在維吾爾語中,詞綴根據位置分為前綴和后綴。前綴(Prefix)數量較少,共有6 個;后綴(Suffix)數量較多,共有532 個[20-21]。因此一般認為詞綴指后綴,部分文獻將詞綴稱為詞尾[22]。詞綴根據在詞匯中的作用分為構詞附加成分(Word Building)和構形附加成分(Inflection)[23]。構詞附加成分,即構詞詞綴或派生詞綴(Derivational Affixes),主要用于構成新詞;構形附加成分,即構形詞綴或屈折變化詞綴(Inflectional Affixes),主要用于表示新的語法意義[24-25]。部分文獻將構詞詞綴稱為詞綴,將構形詞綴稱為詞尾(Word Ending)[26]。例如(讀,詞根)+(構詞詞綴)+(構形詞綴)=(學生)。術語使用不一致的現象增加了學術交流和維吾爾語自然語言處理等方面的難度。
音素是最小語音單位,共有32個包括8個元音和24個輔音[19]。音節由音素構成,是語音的基本構成單位[17],結構一般形式為:元音+輔音1+輔音2+…+輔音n。其中元音可以成為單獨的音節而輔音不可以,輔音在音節中可以出現0 個或多個[27]。一般音節格式為“[C]V[CC]”(C 代表輔音,V 代表元音),有V、VC、CV、CVC、VCC、CVCC 等基本音節結構[28]。部分受外來語影響的格式有“CVV[C]”(漢語)等[6]。詞干與詞綴之間連接時會產生音變現象,增加了處理難度,解決方法有音變還原和音節切分等。
2 維吾爾語自然語言處理現狀
NLP 主要流程有首先使用語言學相關理論分析文本,然后使用數學建模分析,最后使用計算機處理[29]。研究層面包括詞法分析、句法分析、語義分析和語用分析等,層面之間相互聯系,處理時需逐層分析[30]。其中,維吾爾語詞法分析(Lexical Analysis 或Morphological Analysis)含義有廣義和狹義之分。廣義上的維吾爾語詞法分析從詞的所有角度分析包括形態分析和詞性標注等,狹義上的維吾爾語詞法分析即形態分析,主要研究詞內部結構和變化。
英、漢等大規模流行語言NLP需求大,起步早,處理技術較為成熟。相比,維吾爾語相關研究人員較少,處理技術較為落后并且缺少統一標準,難以滿足現有需求。值得注意的是,部分處理技術和語言無關,可以將其運用到維吾爾語相應工作中。
維吾爾語NLP 面臨最突出挑戰包括對詞匯、句法、語義等級別的歧義消除和解決未知語法問題[31-33]。
3 維吾爾語語言知識庫與語料庫
自然語言處理基本資源包括語言知識庫(Language Knowledge Base)和語料庫(Corpus)[34]。
3.1 維吾爾語語言知識庫
維吾爾語語言知識庫主要分為規則庫(Rule Base)和詞典(Dictionary)。規則庫主要為基于規則的方法提供依據,有時需要考慮不規則現象。詞典包括詞庫(表)和詞干庫(表)等[32],能夠匹配詞和詞干等數據,進行詞性分類和詞形變換等工作,易于擴展和維護[35]等,是基于詞典的方法基礎。維吾爾語語言知識庫面臨問題主要有規模有限,需要專家不斷完善,對人力要求較高。
Wushouer 等[36]根據維吾爾語語法特點和技術處理需求等方面構建了《維吾爾語語法信息詞典》解決了傳統詞典不能在信息平臺共享、不考慮NLP技術特點和詞匯量有限等問題,推動了基于詞典方法的發展。
3.2 維吾爾語語料庫
語料庫是存放語言材料的數據庫[34]、統計模型[33]和神經網絡模型的基礎,當前主流基于統計和基于深度學習方法對語料庫依賴性較大。語料庫的規模和規范性影響著后期訓練模型的性能,因此構建優質語料庫對于維吾爾語形態分析有著重要意義。目前,維吾爾語形態分析相關語料庫大致分為單語平衡語料庫和維漢雙語平行語料庫[33]。構建步驟主要有:(1)獲取文本;(2)處理(標注、切分等);(3)核對。其中,在獲取文本時,需要從多資源(網絡、報紙等)獲取,盡可能獲取規范語料[9]。
3.2.1 單語平衡語料庫
維吾爾語單語平衡語料庫主要選取具有代表性和平衡性的維吾爾語語料,能夠充分反映出維吾爾語使用現狀。
構建工作最早始于2002 年玉素甫·艾白都拉等構建的800 萬詞次的維吾爾文語料庫[37]。在此期間,玉素甫·艾白都拉[38]通過研究維吾爾語詞義排歧等方面,完善了維吾爾語句法分析器,推動了維吾爾語語料庫構建進程。
吐爾根·依布拉音等[37]從2002年開始研究語料庫構建工作,通過選取差異度較大的小規模語料庫,不斷更新標注規范體系和分析工具,經過多次修改,構建了百萬詞次的維吾爾語詞法分析語料庫。
2017 年,哈里旦木·阿布都克里木等[39]從天山網獲取語料構建清華大學維吾爾語形態切分語料庫(THUUyMorph)。該語料庫分為詞級和句子級形態切分語料庫,包含10 596個文檔、69 200個句子,詞語類型為89 923 個。該語料庫是少數公開維吾爾語語料庫之一,主要用于維吾爾語分詞、形態切分和詞干提取等任務,推動了維吾爾語NLP的發展,但在規范性等方面存在問題。
3.2.2 維-漢雙語平行語料庫
維-漢雙語平行語料庫是對維漢兩種語言平行取樣和加工,反映二者之間的對應關系,構建工作對于后續機器翻譯和維漢對比等應用起到重要推動作用。相關工作最早開始于吐爾根·依布拉音等構建的維漢雙語對齊平行語料庫[40-41]。
3.2.3 問題與建議
維吾爾語形態分析相關語料庫構建近幾年發展迅速,目前存在主要問題有:(1)缺乏規范性,語料來源和處理方法參差不齊,難以整合多個語料庫和產生子庫,重復利用較為困難并且容易受到其他規范的制約;(2)大部分語料庫規模較小,對于基于統計和深度學習相關方法模型性能限制較大;(3)公開語料庫較少,難以實現資源共享和提高效率;(4)維-漢雙語平行語料庫雙語對齊方面受到語言差異影響較大。
在語料庫規范方面,構建標準應盡可能與國際接軌,參考國際主流語料庫UniMorph[42-43]技術規范。Uni-Morph 是由約翰·霍普金斯大學語言和語音處理中心(Center for Language and Speech Processing,CLSP)主持的國際權威項目,主要研究多種語言NLP 系統中復雜形態問題,已經發布數十種國際高度認可的標注數據集。從范圍和語言數量來看,UniMorph 已經成為最大的形態詞典,在低資源語言標記與注釋等語料庫工作有著較高的參考價值[44-46]。此外,在統一標準的同一語系的語料庫條件下,有利于采用遷移學習(Transfer Learning)方法緩解低資源語言數據稀疏問題。由于缺乏相關標準的標注數據集,國際形態分析競賽SIGMORPHON2020 語種只有較少項目包含維吾爾語[47-48],限制了維吾爾語形態分析的發展。因此根據國際標準構建維吾爾語語料庫對于推廣維吾爾語形態分析工作有著重要意義。
擴大語料庫規模研究可以考慮以下措施:(1)在標注方面可以結合機器標注[49]方法,提高標注效率;(2)利用機器翻譯的方法將高資源語言語料生成目標語言語料[50-55]。該方法對于機器翻譯要求較高,容易出現錯誤;(3)利用遷移學習方法[56-57]。引入大規模相似輔助數據集,后續工作可選取相應的英語或土耳其語等源模型訓練,遷移參數到維吾爾語模型并進行微調(Fine-Tuning),可以達到擴展語料庫的目的。
4 維吾爾語形態分析現狀
形態分析,又稱詞素分析或詞法分析,是NLP 中的基礎工作,影響著后續工作進展。由于每一種語言書寫和語法等方面都各不相同,因此每一種語言的形態分析工作都需要具體考察。
維吾爾語形態分析工作從分析目標的詞性角度分為對名詞和動詞等基本實詞的形態分析;從方法角度分為音變還原(Phonetic Restoration)、詞干提取(Stemming)、形態切分(Morphological Segmentation)以及其他工作,工作時間軸如圖1所示。其首要目標包括對詞綴、詞干的切分和提取以及對音變現象進行還原等[58]。形態分析能夠為后續的機器翻譯、語音識別和信息檢索等具體應用提供幫助。
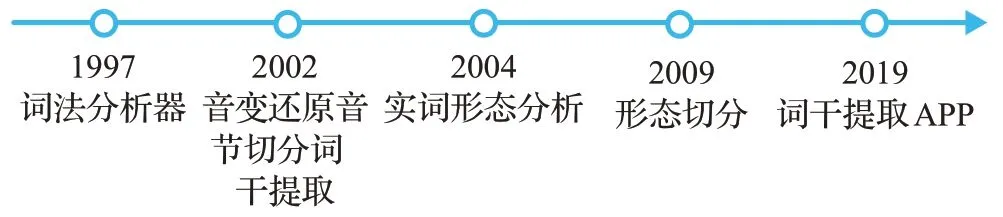
圖1 維吾爾語形態分析工作時間軸Fig.1 Work time axis of Uyghur morphological analysis
1955 年,Harris[59]首先開始英語詞素邊界識別相關研究,開創了自然語言形態分析研究先例;1997年,玉素甫·艾白都拉[60]等首次對維吾爾語形態分析方面進行研究,提出一種詞法分析器構造方法。
常見的維吾爾語形態分析方法主要分為基于規則、詞典、統計、深度學習和混合的方法。
(1)基于規則的方法
根據語言學語法等規則,建立規則庫,將語言結構理解為符號結構進行處理,屬于理性主義方法。優點在于有較強的概括性,容易推廣,缺點有規則容易缺乏一致性和完整性[29],規則之間可能有所沖突,處理不規則現象欠佳,無法有效利用上下文信息等。主要模型有兩層分析法(Two-Level)[61]和有限狀態自動機(Finite State Machine,FSM)等。
(2)基于詞典的方法
根據詞典中的語法等內容進行檢索并作出進一步處理,屬于理性主義方法。該方法處理速度較快,對詞典要求較高,但是詞典覆蓋面有限,無法有效處理詞典未收錄的詞,即OOV等問題,一般結合基于規則等其他方法使用。主要模型有哈希表(Hash Table)等。
(3)基于統計的方法
基本步驟是通過建立語料庫,使用模型進行大規模訓練,將語言內部關系問題轉換為概率統計問題[27],屬于經驗主義方法。優點有覆蓋面高、不受語言限制、能夠利用上下文信息等。缺點有無法使用語言學規則進行引導、特征設計困難、受到數據稀疏性影響較大等。主要模型有條件隨機場(Conditional Random Field,CRF)[62],最大熵模型(Maximum Entropy Model,MEM)[63]和N-gram模型。
(4)基于深度學習的方法
一種新興的方法,主要使用神經網絡等方法進行處理,緩解數據稀疏問題,提高覆蓋面,但對于語料庫規模要求較高,可能存在錯誤切分等問題。主要模型有循環神經網絡(Recurrent Neural Network,RNN)[64],門限遞歸單元(Gated Recurrent Unit,GRU)[65-66]和長短時記憶網絡(Long Short-Term Memory,LSTM)[67]等。
(5)基于混合的方法
結合至少兩種上述方法,達到優勢互補的目的。主要模型有貪婪搜索算法和最大后驗估計(Maximum a Posteriori,MAP)[68]模型等。
維吾爾語形態分析主要模型分類如圖2所示,主要形態分析方法總結如表2所示。
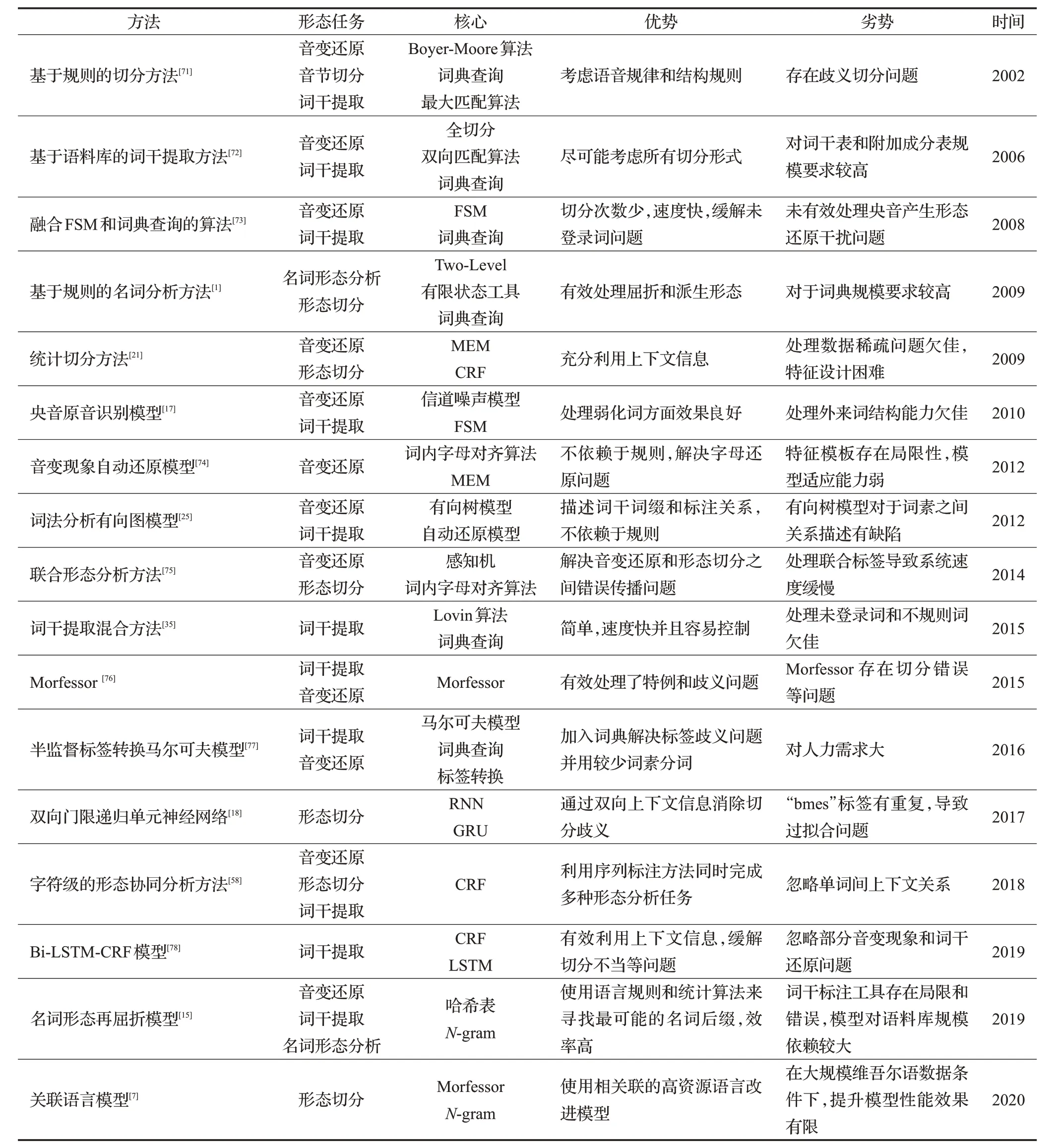
表2 維吾爾語形態分析主要方法總結Table 2 Summary of main methods of Uyghur morphological analysis
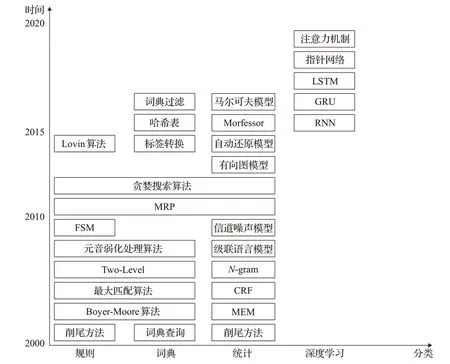
圖2 維吾爾語形態分析主要模型分類Fig.2 Classification of main models of Uyghur morphological analysis
4.1 實詞形態分析
維吾爾語實詞形態分析主要包括對維吾爾語名詞和動詞等具體實詞的形態分析,分析方法主要分為基于規則、統計和詞典的方法,總結出具體實詞形態的一般規律,為后續處理提供參考依據。
在基于統計和規則方法方面,阿依克孜·卡德爾等[69]對維吾爾語名詞進行形態分析,總結出名詞基本形態參數以及參數的組配規律和類型,分別將基于統計和基于規則的削尾方法用于名詞形態分析、轉換和生成。其中基于統計的削尾方法優點在于有較好的一致率和覆蓋率,而基于統計的削尾方法優點在于能夠充分利用已有語言學知識,二者優勢互補。Munire等[15]考慮維吾爾語高度變化和音變現象等問題,構建維吾爾語名詞再屈折(Re-Inflection)模型,減少數據稀疏性對名詞形態分析的影響。
在基于詞典和規則方法中,常見的有Two-Level。其中兩層分為詞匯層和表面層:在表面層,單詞以其原始的Orthographic Form表示;在詞匯層,單詞通過其所有的功能成分表示。兩層模型基于詞典系統和兩層規則,用于描述形態學和形態音學現象。Orhun等[1,70]首次使用施樂有限狀態工具分別構建了維吾爾語名詞和動詞的有限狀態兩層形態分析器,分別用于處理名詞和動詞屈折和派生形態。
4.2 音變還原
音變還原針對詞干與詞綴連接時產生的音變現象進行還原處理。
維吾爾語中的音變現象主要分為元音弱化(同化)[71]、增音和脫落以及語音和諧。元音弱化表示詞干與詞綴連接時元音變化成其他元音的現象,在維吾爾語中普遍出現且形式較為靈活[29],處理較為困難,外來詞會導致稀疏性問題,處理方法包括對同化詞干復原,對弱化的音節進行處理等。元音增音表示詞干與詞綴連接時字母發生增加的現象,可利用規律還原。元音脫落情況較少,表示詞干詞綴連接時字母發生減少的現象[17],一般可以采用詞典查詢方法解決。語音和諧現象在維吾爾語中大量存在,約束詞干和詞綴以及音節之間連接形式[23,71],分為元音和諧和輔音和諧[79]。力提甫·托乎提[80]證明維吾爾語語音和諧有規律可循,可以用計算機處理。
音變現象在維吾爾語中大量存在,音變還原過程并非簡單逆過程,容易出現歧義等問題。因此音變還原是做好詞干提取和形態切分等后續工作的重要前提。
解決的方法主要分為基于規則和詞典、基于統計的方法兩種。
4.2.1 基于規則和詞典的音變還原方法
基于規則的音變還原方法依賴于語音和諧規律等語法規則,但容易產生歧義,無法有效處理復雜變化 和外來詞音節特征,使用詞干庫等方法可以解決部分特殊現象,但會出現覆蓋面小和多個還原候選等問題。
古麗拉·阿東別克等[71]首先在詞干提取工作中考慮音變還原處理包括語音同化處理和語音和諧規律處理規則。艾山·吾買爾等[73]在詞綴庫中添加弱化和增音形態,構建語音脫落詞庫,根據還原規則處理詞綴對詞干、詞綴內部語音弱化和詞綴對詞干的語音脫落問題,但無法有效判斷部分弱化現象。米熱古麗·艾力等[23]根據維吾爾語元音弱化規則和詞干庫構建元音弱化處理算法,但對于外來詞處理欠佳。
4.2.2 基于統計的音變還原方法
傳統基于統計的音變還原方法解決了上述基于規則的方法覆蓋面小等問題,主要采用訓練統計模型的方法選擇最優還原候選,但在處理復雜音變現象效果仍然欠佳[74]。Aisha等[21]結合語音和諧規律使用CRF從人工標注的語料庫學習“映射”知識處理語音和諧現象。艾山·吾買爾等[17]采用信道噪聲模型處理元音弱化問題。
為了解決上述問題,麥熱哈巴·艾力等[25,74]提出音變現象的自動還原模型,將音變還原問題轉變為線性序列標注問題。主要步驟有:首先利用詞內字母對齊算法得到字母原形候選集合;接著根據特征模板使用MEM 訓練語料得到原形候選;最后通過計算得到概率最大的原形。該方法減少了制定處理規則等復雜步驟,但在處理部分字母等方面存在問題。張海波等[75]提出基于字符分類的音變還原方法,利用詞內字母對齊算法得到分類標簽,將音變還原轉變為詞性標注工作,使用多元分類感知機訓練得到序列標注權重,最高分為還原序列。在上述工作基礎上,徐春等[81]提出另一種詞內字母對齊算法,通過對音變后字母0-1賦值,計算得分得到整個詞的最優匹配模式,速度較快。
后續工作可以考慮添加語言規則、增加語料庫規模和改進特征模板等方法提高模型性能。
4.3 詞干提取
維吾爾語詞干提取的主要任務是分開詞干和構形詞綴,即詞干和詞綴連接的逆過程[74]。其目標是將發生形態變化的單詞還原為詞干形式,獲得目標單詞的意義,降低特征維度,提高后續任務處理性能[16,33,82]。主要步驟有:(1)取詞,去除構形詞綴;(2)詞干還原。在進行還原過程中,首先需要充分考慮語音變化等問題,減少一個詞干不同形式現象[72]。維吾爾語詞干提取重要程度等同于中文分詞,應用于電子詞典[83]和詞性標注[76]等。
維吾爾語詞干提取面臨的挑戰主要有:(1)維吾爾語中大量出現的同形異義詞和外來詞[84]提高了處理難度;(2)元音弱化現象多;(3)存在切分不準確問題[33],詞干、詞綴切分后帶有歧義。
在維吾爾語實詞中,名詞占比最高,因此將名詞作為優先詞干提取對象有助于提高整體研究效率[33]。維吾爾語詞干提取使用較多的方法可分為基于詞典、規則、統計、深度學習和混合的方法。
4.3.1 基于詞典的詞干提取方法
基于詞典的詞干提取方法根據已構建的詞典進行詞形轉換,不斷切除字符串中的子串直到匹配到詞典中的詞為止,對有效詞進行處理,減少詞干還原過程,但各方面處理性能對詞典規模有較大的依賴性[35,76],詞典內容無法涵蓋所有形式,無法有效處理OOV問題,一般結合其他方法使用。
4.3.2 基于規則的詞干提取方法
基于規則的詞干提取方法根據建好的規則庫,利用語言學規則去除構形詞綴,進行詞干提取,但對于少數不規則的情況可能會出現失靈的現象,一般結合其他詞干提取方法使用,相關模型包括FSM等。
維吾爾語詞干提取FSM 是一種有向圖模型,其中弧表示狀態轉移,節點表示狀態,根據詞綴表和詞綴連接規則構造,分為確定性有限狀態自動機(Deterministic Finite State Machine,DFSM)和非確定性有限狀態自動機(Nondeterministic Finite State Machine,NFSM)。FSM 通過狀態轉移和匹配詞綴不斷地去除目標詞的詞綴,最終達到提取詞干的目的。構建維吾爾語FSM 難點有詞綴多,語法較為復雜,音變現象有較大的干擾。傳統的維吾爾語詞干提取方法[71,85]依賴于詞典,每次切分一個詞綴并和詞干庫匹配判斷詞干提取是否成功,FSM 可以根據規則切分從而不依賴于詞典,減少切分次數,但無法有效處理少數帶有相近詞綴和詞尾的詞,并且處理外來詞元音結構和口語單詞等現象欠佳,存在過度切分問題。艾山·吾買爾和早克熱·卡德爾等根據阿依克孜·卡德爾等[69]的名詞形態分析工作分別構建了名詞[16,86]和形容詞[87]詞綴DFSM,后續FSM 詞干提取工作在此基礎之上結合其他模型進一步探討詞干提取方法。
4.3.3 基于統計的詞干提取方法
與基于詞典和規則的詞干提取方法相比,基于統計的詞干提取方法能夠解決OOV 不規則詞等問題,但在進行詞干提取時會受到噪聲影響。基于統計的詞干提取方法使用模型一般分為序列標注模型和有向圖形態分析模型[81]。
序列標注模型將維吾爾語形態分析轉化為線性序列標注任務。CRF 是一種無向圖模型,起到預測作用,能夠根據具體需求擴展,將序列化數據進行分段和標記,特征選擇較為自由,通過特征歸一化得到最優解。維吾爾語形態分析一般采用線性鏈CRF,使用時需要將形態分析問題轉變為序列標注問題。Abdurahim Mahmoud 等[28]提出一種基于CRF 的詞干提取方法,考慮添加屈折后綴的音變現象。在訓練語料庫中將單詞切分為音節,根據單詞與音節關系手動貼上標簽,判斷觀察到的音節是否屬于已定義的標注集,選取音節作為特征,并采用CRF++工具包訓練。
基于有向圖模型的方法根據詞圖得到標注結果。麥熱哈巴·艾力等[25]提出維吾爾語有向樹模型,結合音變還原自動還原模型,進行切分和標注,該方法在詞干提取正確率等性能方面優于線性模型[88],但容易產生非法候選,造成歧義。賽迪亞古麗·艾尼瓦爾等[84]以N-gram 模型為基本框架,結合詞性特征和上下文詞干信息解決上述切分歧義問題,模型對于語料庫規模和上下文特征等方面依賴較大。有向樹模型的優點在于能夠有效處理詞干與詞干之間的關系,不依賴于規則,能夠用于其他黏著語。
上述基于序列標注模型和樹狀模型方法以句子為分析單位,導致考慮上下文信息有限。徐春等[81]提出維吾爾語圖狀模型,綜合考慮各詞素之間的關系,有效改善了模型性能。
4.3.4 基于深度學習的詞干提取方法
基于深度學習的方法是一種特征學習過程,在維吾爾語詞干提取工作取得了一定進展。傳統的神經網絡方法僅通過后向算法學習參數,仍存在較大的切分問題。
為解決上述問題,古麗尼格爾·阿不都外力等[78]將Bi-LSTM-CRF模型用于詞干提取,采用{B,I,O}標記詞干,準確識別了詞干、詞綴,緩解了切分不準確等問題,其中Bi-LSTM 起到根據上下文提取特征作用,CRF 層起到了增加模型約束條件和對特征解碼能力等效果。在加入候選特征后,獲得較高的F1 值,優于CRF、LSTM、Bi-LSTM 和LSTM-CRF 模型,但沒有考慮到音變現象。后續工作可以考慮加入規則改善模型。
4.3.5 基于混合的詞干提取方法
基于混合的詞干提取方法綜合考慮了上述多種方法,考慮更多特征,處理具有復雜形態變化并且形態變化規則不嚴格的語言[73]。主要分為規則和詞典、規則和統計等混合方法。
基于規則和詞典方面,古麗拉·阿東別克等[71]最先開始維吾爾語詞干提取相關工作研究,構建規則庫和詞典,采用“前綴+詞干”和“詞干+后綴”結構的Boyer-Moore算法和正向最大匹配算法提取詞干,根據維吾爾語詞結構和音變規律等方面切分和還原,但容易受到規則庫規模等方面限制,無法有效處理詞綴詞尾相近問題,初步探討了基于規則和詞典的詞干提取方法。陳鵬[72]采用全切分和雙向匹配的方法,結合詞典查詢進行詞干提取。熱娜·艾爾肯等[35]根據維吾爾語特點和Lovin算法[89]設計出詞干提取器。
維吾爾語詞干提取FSM主要結合詞典查詢、MEM、CRF 和信道噪聲等模型方法使用,并取得一系列進展。其中,詞典查詢方法構建了詞綴與詞尾相似詞的詞干庫,緩解了錯誤切分問題[73]。MEM是一種統計方法,首先確定詞干長度和音節數等特征選擇,根據上下文和歷史數據判斷模糊后綴是否為真實后綴,可以解決FSM切分歧義問題,但受到數據稀疏性的影響較大[90]。CRF模型則是對MEM 的改進,不同在于MEM 獨立考慮各狀態數據,而CRF分析序列數據,實驗結果表明CRF模型在召回率等性能優于MEM[91]。信道噪聲模型用于處理元音弱化等音變現象[83]。結合上述多種模型有利于提高FSM性能[33]。
米爾阿迪力江·麥麥提[76]采用基于統計的Morfessor[92]和基于規則的元音弱化處理算法的混合方法,分別有效地處理了歧義和特例問題。Tursun 等[77]提出一種基于標簽過度的馬爾可夫模型進行詞干提取。該方法利用詞典獲得詞干和詞綴的標簽,馬爾可夫模型計算最有可能的標簽轉換。后期加入規則考慮特定情況提升正確率。古麗尼格爾·阿不都外力等[82]提出字符序列標注的方法,以字符為切分粒度,根據詞典過濾語料并使用CRF進行預測,后續工作可以采用神經網絡方法提高準確率。
4.4 形態切分
形態切分又稱詞素切分(Morpheme Segmentation),是維吾爾語形態分析中的一個關鍵任務,用于解決詞干詞綴的復雜組合問題。每個維吾爾語詞匯可以擁有相同的詞素,處理時需要將維吾爾語切分成詞素,形成詞素序列。因此形態切分能夠減少詞匯量并且緩解稀疏性和OOV 等問題并且通過去除句法后綴等停用詞(Stop Words)能夠減少噪聲和降低特征維數[93],是處理維吾爾語的有效方法。一般步驟主要有:(1)切分;(2)標注。形態切分對后續技術處理起到重要推動作用[39],例如機器翻譯[94],命名實體抽取[95]等。
形態切分與詞干提取一般區別有:(1)切分方面,詞干提取主要考慮詞干與構形詞綴之間的切分,有時不會細致切分每一個詞綴;(2)分析方面,形態切分研究詞素序列,詞干提取主要考慮詞干,標注方法有區別;(3)保留語義方面,形態切分盡可能保留了所有語義,詞干提取可能因為丟棄詞綴導致語義缺失。有時二者之間不作出嚴格區分。
維吾爾語形態切分面臨的問題主要有[6]:(1)同化問題(即弱化和不和諧)[71];(2)形態變化;(3)語音和諧;(4)模糊性。
形態切分的方法主要分為基于規則的方法、基于統計的方法、基于深度學習的方法和基于混合的方法。
4.4.1 基于規則的形態切分方法
傳統的基于規則的形態切分方法[1]主要依賴于人類專家經驗,對人力要求較高,利用上下文信息能力較差,容易出現歧義切分現象。后續工作一般結合統計的方法使用。
4.4.2 基于統計的形態切分方法
基于統計的形態切分方法主要分為兩類:(1)使用CRF 等方法處理序列,方法關鍵在于語料庫和特征設計,采用監督的方法從標注或未標注語料提取詞素;(2)使用Morfessor等軟件,之后采用半監督的方法提取詞素。其中,Morfessor 是一種不依賴于語言種類的統計軟件,能夠對維吾爾語進行詞切分工作,處理OOV問題,但對于語料庫規模等性能要求較高。
針對傳統基于規則的方法出現過度切分等現象的局限性,Aisha等[21]首次提出基于統計的形態切分方法,包括兩步切分的統計方法和字母標記方法(Letter Tagging Approach,LTA)[96-97],主要使用CRF 等統計模型。在兩步切分的統計方法中,第一步不考慮語音和諧,使用MEM從手動構建的語料庫中以統計的方式學習單詞結構知識,將單詞或類短語分解成“準詞”;第二步使用CRF 學習“準詞”和真實詞之間的知識處理語音和諧現象。LTA在此基礎之上進行標注工作,采用“bmes”和形態分析標簽進行標注。其中b、m 和e 分別表示詞素起始、中間和結束字符,s表示單字符詞素[98]。實驗結果表明結合LTA 的CRF 能夠有效使用上下文信息,解決標簽偏差問題,在切分方面性能在優于最大熵馬爾可夫模型。但是,“bmes”標簽并非相互獨立,容易導致模型過擬合問題,對F1值等性能有負面影響[99]。
為緩解維吾爾語形態豐富和語言模型的缺陷引起的OOV等問題,Abulimiti等[7]利用相關聯并且資源豐富的土耳其語改善維吾爾語詞素模型,通過映射等預處理工作最大化兩種語言詞匯之間的重疊。文本數據根據GlobalPhone 語料庫構建步驟[100]收集,采用Morfessor 進行形態切分和SRILM工具包[101]進行訓練和評估語言模型,通過使用改進的Kneser-Ney 折扣法[102]訓練三元模型。實驗表明相比單語數據訓練,使用雙語數據訓練的基于詞素模型困惑度有所降低。
基于統計的形態切分方法容易出現錯誤傳播問題,即音變還原的處理工作的速度和準確率等性能會對下一步的切分工作產生負面影響。為解決錯誤傳播問題,張海波等[75]提出聯合音變還原和形態切分的方法。該方法使用的聯合標簽同時考慮了音變還原和形態切分,其中使用線性序列標注模型進行形態切分,并且使用“BMES”標注和感知機進行訓練。吐爾洪·吾司曼等[58]在張海波等[75]工作基礎上,設計出維吾爾語形態切分、形態標注以及音變還原協同標記方法,提高系統總體正確率。
從總體上來看,基于統計的形態切分方法準確率較高,缺點主要有:(1)處理數據稀疏能力較弱;(2)特征設計困難;(3)可能存在錯誤切分等問題。可以結合規則和深度學習等方法改善。
4.4.3 基于深度學習的形態切分方法
基于深度學習的形態切分方法主要采用神經網絡模型進行切分和標注工作。
哈里旦木·阿布都克里木等[18]首次將深度學習引入到維吾爾語形態切分工作中,主要使用基于雙向GRU神經網絡和“bmes”標注方法。與傳統基于統計的方法(Morfessor 和CRF)和單向GRU 相比,該方法充分考慮了上下文信息消歧切分,有效緩解了數據稀疏問題并且通過自動學習特征緩解其覆蓋面問題。Yang 等[99]使用帶有GRU 的指針網絡(Pointer Network)進行維吾爾語形態切分,并采用注意力機制(Attention)改進。不同于先前“bmes”標注工作,該方法將較少的獨立且包含全面信息的標簽(即“b”和“s”)用于形態切分,有著較好的穩健性。Liu 等[103]使用加入注意力機制的Bi-LSTM 的方法,通過給輸出加權和來增加中間時間步長(Time Steps)的影響,解決傳統Bi-LSTM方法忽略中間時間步長的部分重要信息問題。
基于深度學習的維吾爾語形態切分方法仍處于起步階段,可以考慮借鑒其他語種基于深度學習的詞法分析方法。
4.4.4 基于混合的形態切分方法
基于混合的方法則考慮了上述多種方法,主要有統計與規則結合的方法。
薛化建等[104-106]提出一種基于統計和基于規則的形態切分方法。采用規則切分法進行切分,MAP 模型評分,級聯語言模型(Cascaded Language Model)提高模型準確性,貪婪搜索算法選擇最優模型,最后得到最有可能的切分方法。相比于Morfessor,該模型錯誤切分的現象顯著減少。Ablimit 等[79]采用結合序列標注和詞內二元模型方法,將詞切分為詞素或音節,考慮音變還原,詞素切分準確率較高。
4.5 其他形態分析方法
音節切分是一種對音節的形態分析方法,可根據音節規律找出對應的詞素或詞,有助于進行后續切分和音變還原[23]工作,也可以將音節作為特征進行模型訓練。
古麗拉·阿東別克等[71]在首次詞干提取工作中加入音節切分,判斷是否將詞單獨處理[85]。Ablimit等[6]進行語言模型(Language Model,LM)實驗和自動語音識別技術(Automatic Speech Recognition,ASR)實驗時,綜合考慮了形態切分和音節切分,設計出詞素切分器。Mahmoud等[28]采用音節切分的方法并對音節進行標注,將詞干提取轉變為序列標注問題,選取音節作為基本特征,采用CRF工具進行模型訓練,獲得較高的準確率等性能,但存在歧義標注等問題。
4.6 形態分析系統和軟件構建工作
維吾爾語形態分析系統和軟件有著較為完整的流程體系,實用性強,在維吾爾語文字處理等方面有著廣泛應用。
玉素甫·艾白都拉等[60]首次進行維吾爾語形態分析工作,認為維吾爾語詞尾變化實現詞法變化,針對詞尾分析等方面提出詞典分級構造法和單詞分析法,構建一種詞法分析器。
米吉提·阿布力米提等[85,107]根據古麗拉·阿東別克等[71]提出的切分原理分別構建了維吾爾語文字校對系統和維吾爾語詞法分析器。維吾爾語文字校對系統實現多文種混合處理,基本思路是將文字信息輸入與已構建好的詞法庫進行比較并輸出反饋結果。其中詞法庫主要分為詞根表、總詞綴表(基本詞綴及其組合)和詞綴表(基本詞綴)。系統主要流程包括詞根庫校對、音節切分、詞根和詞綴切分以及元音同化和語音和諧處理等步驟,對于特殊情況單獨處理或報錯。該校對系統具有較好的穩定性和速度等性能。缺點在于構建大規模詞根表需要大量人力資源。維吾爾語詞法分析器系統的工作流程和維吾爾語文字校對系統相似,不同點有:(1)數據庫增加了音節表,主要保留根據音節規則將詞根切分成的音節;(2)采用最小編輯距離算法找出拼寫錯誤候選詞。該系統能夠用于文字校對和語法校對相關工作。
Ablimit等[108-110]先后開發了詞素切分器和語音形態處理工具。根據維吾爾語語言結構特點和音變還原規則,構建了一種半監督的詞素切分器,其中詞干列表是切分的基礎。該切分器檢測詞干詞綴邊界的準確率較高,但在處理復雜結構時效果欠佳。語音形態處理工具根據包括維吾爾語在內的三種少數民族語言的詞素和音素的性質構建,在拼寫錯誤檢查等方面效果良好。
Orhun 等[111]根據形態規則構建維吾爾語形態消歧器,結合上下文,給出所有單詞的形態解析,解決歧義問題。該消歧器速度較快并且能夠給出明確結果,但無法考慮所有情況的規則。
艾孜爾古麗等[112]開發現代維吾爾語詞干提取系統,對9 家維吾爾文網站文本詞干情況進行有效分類和統計。該系統包括文件格式轉換模塊、文本整理與校對模塊、詞干詞典維護模塊和詞干提取模塊。其中詞干提取模塊采用基于詞典的方法,將詞匯不斷切分,和詞干庫和詞綴庫進行比對,人工擴充不匹配詞匯的詞干和詞綴。隨著詞干庫不斷擴充,模塊性能不斷提高,缺點在于未考慮音變現象,人力資源耗費較大。類似的,玉素甫·艾白都拉等[113]采用結合網站用詞調查的方法進行詞干提取,設計了詞尾統計系統,主要用于切分詞尾和統計詞尾使用頻率。其中構建詞干庫和詞尾庫時,考慮語音弱化等音變現象,從而達到正確切分和符合語言學習慣的目的。通過自動和人機交互方法統計出詞尾使用情況,其中高頻(頻率超過一萬)詞尾作用有:(1)同時充當構詞詞綴和構形詞綴;(2)包含多種語法功能。在高頻詞尾中,名詞性詞語的詞尾數量較多,是詞尾研究重點。低頻詞尾種類較多,大致呈現出隨長度增加,頻數減少的趨勢。該統計分析對于形態分析工作具有重要參考意義。
艾孜爾古麗等[114]提出一種最大熵名詞詞干識別模型,考慮維吾爾語形態結構等語法方面以及詞內部和前后依存詞特征,構建了維吾爾語名詞識別系統。
哈里旦木·阿布都克里木等[18]在雙向GRU 神經網絡模型基礎上構建了維吾爾語形態切分系統。
帕麗旦·木合塔爾等[115]根據Android 系統和維吾爾語的特點構建出詞性標注和詞干提取APP,打破了詞干提取依賴于PC機的傳統,操作簡潔,靈活方便。
5 維吾爾語形態分析的應用研究
維吾爾語形態分析在機器翻譯、模式匹配和NER等領域有著廣泛應用。
5.1 機器翻譯
機器翻譯(Machine Translation)是一種利用計算機自動翻譯人類語言的技術[116]。根據方法可分為基于規則、實例、統計和深度學習的機器翻譯[117]。機器翻譯能夠緩解語言不通方面的障礙,從一定程度上減少人力和財力。維吾爾語機器翻譯領域常見的有維漢機器翻譯。維吾爾語形態分析在提高詞對齊和保留語義信息等方面對于提高機器翻譯性能有著重要推動作用。其中詞對齊是雙語對齊重要組成部分,也是維吾爾語機器翻譯的基礎,影響著后續翻譯的進程,其任務是根據字符串找出雙語對應匹配單詞。維漢翻譯和英漢翻譯等在詞對齊方面仍有著較大差距。
維漢機器翻譯面臨困難主要有:(1)維吾爾語和漢語語法、語義和句法等方面差異較大;(2)維吾爾語形態高度變化且數據稀疏;(3)缺乏大規模優質雙語平行語料庫;(4)存在OOV問題。
在處理音變現象方面,徐春等[14]利用自制維吾爾語形態切分工具,根據詞干庫和構形詞綴庫,去掉構形詞綴,并進行弱化和脫落現象的音變還原,如果匹配不到詞干庫則歸類為備用切分方案。最后得到目標詞干和詞綴,提高詞對齊的準確率,進一步提高了維漢(漢維)機器翻譯的準確率。
在緩解稀疏性問題方面,李欽欽[117]在碩士論文中通過使用Morfessor進行維吾爾語形態切分,包括對名詞、動詞和形容詞的切分,緩解稀疏性和維吾爾語單詞對應漢語短語問題。Mi 等[2]提出了形態切分的對數線性模型,同時基于單語和雙語語料庫進行模型優化,綜合考慮CRF特征、雙語詞對齊特征和單語后綴詞共現特征并且保留了有用詞綴,解決數據稀疏等問題。類似的,麥熱哈巴·艾力等[118]提出一種將詞干詞綴先分離再對齊的方法,并統一詞綴變體形式,采用GIZA++詞對齊工具[119]處理,有效緩解了數據稀疏問題,提高了詞對齊準確率和維漢機器翻譯性能。但是這種方法將詞綴視為獨立的符號(Token)處理,將所有詞綴保留,增長了句子長度,不利于GIZA++處理。
為了解決上述問題,麥合甫熱提等[120]提出“分離-丟棄”方案,根據詞尾翻譯概率的高低判斷對詞尾“分離”或“丟棄”并探討了不同詞尾粒度模板性能。該方法保留了有意義的信息,有效緩解了切分后句子過長問題同時增加了維漢詞對的數量,維漢機器翻譯BLEU值有一定的提高,但幅度有限,主要原因在于受到語料庫規模和詞尾選擇方法限制,仍需要改進模板。類似的,Mi等[121]認為將詞綴簡單的丟棄會削弱機器翻譯能力,提出一種優化維吾爾語切分方法,不同的是該方法僅通過少數特征表示維漢句子之間對應關系。使用CRF訓練過的基于字符標注的模型切分維吾爾語單詞,結合雙語詞典查詢,通過邏輯回歸模型輸出的標簽判斷是否去除詞綴。
在研究模型粒度方面,米莉萬·雪合來提等[122]提出一種基于有向圖的“詞干-詞綴”語言模型的漢維機器翻譯方法,將維吾爾語詞轉化為詞干詞綴粒度,相比詞粒度翻譯系統,BLEU值有所提升。
麥熱哈巴·艾力[123]在博士論文中綜合上述多種方法,構建基于實例的維漢機器翻譯系統。主要形態分析工作有:自動還原模型采用基于統計的方法,能夠有效處理復雜音變現象;有向圖模型充分考慮了詞干與詞干之間關系和詞干與詞綴之間的關系;詞干、詞綴分離則采用“分離-丟棄”方法。
針對傳統神經機器翻譯只考慮高頻詞未能較好處理OOV問題和錯誤切分的現象,Pan等[19]提出一種形態學分析方法,結合維吾爾語形態規則保留詞匯語言語義信息,主要采用形態切分和字節對編碼(Byte Pair Encoding,BPE)的方法,減少訓練詞匯量。
綜合上述工作,基于實例和基于統計的維漢機器翻譯處于主導地位,基于深度學習的維漢機器翻譯相關研究仍處于初始階段。考慮更多的形態學知識、復雜語法結構和語義信息[124]能夠提高詞對齊性能等方面性能。在后續的基于深度學習的神經機器翻譯(Neural Machine Translation,NMT)方面,可以采用以下方法:
(1)遷移學習[125-127]。先利用高資源且相似的語言詞素訓練模型,之后遷移到維吾爾語詞素得到翻譯結果。其中可采用的模型包括BPE[128]、預訓練和微調等,其中在加入預訓練方法時需要考慮語言間相似性和算力資源等[129]。
(2)元學習(Meta-Learning,ML)[130-131]。利用機器學習方法學習如何學習(Learning to Learn),能夠快速適應新任務,減少對訓練數據樣本需求,提高模型泛化能力[132],可以結合遷移學習方法使用。
(3)數據增強方法(Data Augmentation)[129]。更多的利用已有的單語數據來彌補雙語數據缺失問題,能夠擴充訓練數據,但需要注意偽數據和噪聲問題。主要分為回譯(Back-Translation)方法[133-135]和詞語替換方法[136-138]。
(4)多語言翻譯方法[139-140]。構建多語言語料庫,考慮語言關聯現象,實現多源NMT。該方法能夠提高準確率,但容易出現內容冗余問題,可以通過微調方法緩解。
5.2 其他應用
Abliz 等[24]將形態分析工作應用于模式匹配,針對維吾爾語元音弱化和后綴引起的形態變化等方面進行分析,在原有Boyer-Moore 算法的基礎上提出Boyer-Moore-U算法和可檢索音節編碼格式,解決了元音弱化問題,提高了詞干形態變化單詞匹配能力。
瑪依熱·依布拉音等[20]提出一種基于最小編輯距離的方法,用于處理維吾爾語詞語檢錯與糾錯。該方法考慮了維吾爾語音節分析,詞干-詞綴的切分和元音同化現象,結合語音和諧規律處理算法,應用于文本校對和檢索領域。
維吾爾語分詞(Word Segmentation或Tokenization)定義主要分為兩種:(1)詞內部結構切分,以詞素為單位,即維吾爾語詞干提取或形態切分;(2)詞之間切分,以詞為單位。詞之間切分層面上,傳統方法采用簡單的空格分割來獲取維吾爾文單詞[71]作為基本語言單位存在較大的局限性,無法獲得上下文關聯語義。吐爾地·托合提等[141]首先對維吾爾語分詞工作進行研究。采用基于頻繁模式挖掘的組詞方法,并結合使用詞干提取解決同一詞不同詞形的問題,獲得較高的組詞正確率,解決了傳統分詞問題。
如先姑力·阿布都熱西提[27]將詞干提取應用于維吾爾語詞語自動校對系統中。系統處理的總體步驟主要有:首先提取維吾爾文單詞;其次進行詞級分析包括音節分析和詞干提取等方面,從而找出錯誤詞匯;最后根據錯詞找出候選詞。
鄒岳琳等[142]將詞干提取應用于維吾爾語事件類時間短語識別任務中,主要使用融合CRF和UETE識別系統的方法,具有一定的推廣意義。
米吉提·阿不里米提等[9]構建語音識別系統時采用詞-詞素兩層間的優化方法,顯著降低了單詞錯誤率。
Chaudhary 等[143]分析音素、詞素和字形三種字詞單位,考慮維吾爾語和土耳其語表面形式和形態等方面的相似性,提出CT-Joint和CT-FineTune兩種模型,應用于NER和機器翻譯等。
Sardar等[93]采用詞素切分工具[110]將單詞序列切分成最優詞素序列,降低了特征維數,提高了后續文本分類的能力。
沙爾旦爾·帕爾哈提等[144]在維-哈語文本關鍵詞提取工作中采用了詞干提取和形態切分的方法。實驗證明,詞干提取能夠減少派生類語言粒度容量,利用多語言處理工具生成的詞素序列能夠提高后續關鍵詞提取準確率。
6 其他語種基于深度學習的詞法分析方法
在英語等語言形態分析方面,Cotterell 等[145]提出Canonical Segmentation 形態切分方法,打破了形態分析屬性值對(Attribute-Value Pairs,AVP)傳統方法,充分考慮了音變還原現象,處理派生和屈折形態更加靈活。Ruzsics 等[146]在此方法中添加語言模型,獲得更低的切分錯誤率。üstün等[147]從Word2vec(Word to Vector)模型[148]中學習詞嵌入,將獲得的語義信息整合到最大似然估計(Maximum Likelihood Estimate,MLE)方法和MAP模型中進行無監督形態切分。該方法對于語料庫規模要求低,適用于低資源語言。Wu等[149]提出一種啟發式方法(Heuristic Approach),用于去除派生形式。
處理低資源語言方面,Kann 等[150]首次提出基于跨語言遷移(Cross-Lingual Transfer)的形態切分方法,構建多語言模型,結合多任務訓練和數據增強方法,有效緩解低資源語言數據匱乏問題。Malaviya 等[151]認為聯合模型更適合分析低資源形態豐富語言,在LSTM和神經序列到序列(Sequence-to-Sequence)模型基礎上,提出一種聯合詞形還原(Lemmatization)和形態標注的神經有向圖模型。該模型在詞形還原和形態標注有著較高的準確率,但在標注方法上仍有改善空間。
在中文分詞(Chinese Word Segmentation,CWS)工作中,Tian 等[152]首次提出一種鍵值(Key-Value)記憶神經框架WMSEG,更加充分利用上下文單詞信息。郭星星[153]提出Bert-BiGRU-CRF 中文分詞方法,獲得豐富語義信息。黃曉輝等[154]利用卷積循環神經網絡模型,有效提取字序列局部空間特征和長距離時序依賴特征,減小分詞誤差,有利于提高后續NER 能力。王星等[155]以字根信息序列標注為基礎進行中文分詞工作,利用融合ALBERT[156]語言模型和卷積神經網絡(Convolutional Neural Networks,CNN)[157]的方法,分別用于訓練動態詞向量和特征提取。該方法在少量標注數據條件下分詞效果良好,但存在訓練時間較長等問題。
參考相近語言的形態分析工作,有利于理解維吾爾語形態特點并且更容易找到改進思路。Güng?r等[158]采用局部可理解的與模型無關的解釋(Local Interpretable Model-Agnostic Explanations,LIME)技術,研究了土耳其語特征影響的強度和方向,探討了特征之間的關系問題。
綜合上述其他語言工作,基于深度學習的維吾爾語形態分析方法今后需要探討重點主要有:(1)更加充分利用上下文信息;(2)改進序列標注方法;(3)遷移學習方法,包括預訓練(Pre-Training)和微調等;(4)綜合考慮維吾爾語語言特征等方面。
7 挑戰與機遇
維吾爾語形態分析發展較為迅速,但仍面臨一系列挑戰。
(1)資源貧乏。和英漢等熱門語言不同,維吾爾語缺乏規模較大的開源語料庫,數據稀疏和資源匱乏等問題成為提高訓練模型精確度等指標時的一大障礙。在低資源的條件下,可以考慮采用與維吾爾語語法相似且資源豐富的語言數據(例如土耳其語)改善模型。語料庫規模的大小影響著前沿模型的訓練效果,因此構建高標準和大規模的開源語料庫也將會是未來維吾爾語形態分析的重要方向。
(2)形態結構多變。維吾爾語在詞素組合方面具有高度靈活性,能夠通過組合有限的詞干和詞綴可以生成無限的詞語,會給后期機器翻譯等應用帶來OOV 等問題,因此維吾爾語形態豐富和黏著性等語法特點和數據稀疏性等問題仍然是研究重點,目前形態切分等相關方法在解決上述問題取得了一定成果。在今后的工作中,需要更多的考慮維吾爾語語法規則改善模型。
(3)不確定性。方言和來源于互聯網等途徑的維吾爾語編碼或拼寫存在噪聲和不確定性等特點。一些外來詞匯,不同地區和歷史上不同時間使用不同字符,即“一文多語”的現象均會帶來較大影響,需要進行降噪和轉換等一系列預處理工作。
(4)缺乏標準化。相關術語命名以及定義、語法規則和處理技術等方面缺乏標準化和統一化,對于學術交流和維吾爾語NLP等方面有著一定的阻礙作用,后續工作需要集思廣益制定各方面標準。
(5)處理技術相對過時。維吾爾語與英漢等大規模流行語言相比處理技術仍有較大差距。維吾爾語形態分析工作可以結合維吾爾語自身語言特點借鑒大語種處理方法思路。近幾年,隨著計算機性能的提高,基于深度學習的方法得到飛速發展,以Vaswani 等提出的Transformer 深度神經網絡[159]以及GPT(Generative Pre-Training)[160-161]、BERT(Bidirectional Encoder Representations from Transformers)[162]和Roberta[163]等模型為代表的預訓練技術得到越來越多的重視,能夠減少對標注數據的需求,避免重復訓練[164]。Conneau 等[165]在Transformer 基礎上提出了XLM-R 預訓練模型,能夠提高低資源語言NER準確率等性能。此外,Conneau等還構建了維吾爾語預訓練語料庫,后續預訓練研究工作將會陸續展開。
8 總結
本文主要對維吾爾語形態分析現狀和發展作出總結,根據維吾爾語形態分析任務類型對不同的方法作出分類和比較,各種模型方法均有優劣,最后指出挑戰與機遇。總體而言,維吾爾語形態分析近幾年發展迅速,與此同時存在較多問題。
隨著計算機算力不斷提高,以基于深度學習為主的維吾爾語形態分析方法是未來發展的趨勢,同時可以考慮結合子詞聯合標簽、遷移學習和元學習等多種方法改善模型。根據最前沿技術和維吾爾語語言特點不斷地改進形態分析方法對于后續研究有著重要推動作用。
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
紅河學院學報(2021年4期)2021-11-19 08:59:14
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
文苑(2020年4期)2020-05-30 12:35:30
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
Coco薇(2017年11期)2018-01-03 20:59:57
西夏研究(2017年1期)2017-07-10 08:16:55
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
少兒科學周刊·少年版(2015年4期)2015-07-07 21:11:17
