改進的基于多尺度融合的立體匹配算法
2021-09-07 02:02:16陳星張文海候宇楊林
西北工業大學學報 2021年4期
陳星, 張文海, 候宇, 楊林
1.重慶文理學院 智能制造工程學院, 重慶 402160; 2.重慶交通大學 機電與汽車工程學院, 重慶 400074;3.重慶長安工業(集團)有限責任公司 特種車輛研究所, 重慶 400023
雙目立體視覺如今廣泛地應用在虛擬現實、巡線無人機作業、智能車、非接觸測距等諸多領域。立體匹配是雙目立體視覺的核心技術之一,其難點表現在:①搜索匹配點時,一般會存在多個對應點,尤其是在重復紋理區域;②由于實際場景中的各個物體空間關系復雜、相互遮掩等噪聲的影響,造成了一些特征點不能找到正確的匹配點;③場景中存在反光、弱紋理區域、透明物體和深度不連續等問題。
現有的立體匹配技術算法大致可以分為局部算法、全局算法和半全局算法。局部立體匹配算法的主要思想是通過支持窗口獲得聚合代價,從而獲得單個像素的視差,具有模型復雜度低、效率高的優點,但存在匹配精度相對較差的缺點。半全局立體匹(semi-global-matching,SGM)[1],是基于一種逐像素匹配的方法,具有在保證近似于全局匹配算法匹配準確率的條件下,大幅度降低算法復雜度,提升計算速度的特點。全局立體匹配的主要思想是構造能量函數,通過最小化能量函數來得到匹配結果,主要有動態規劃(DP)[2]、置信度傳播[3]等算法,這類算法優點是精度高,但具有時間復雜度高、實時性差的缺點。
近年來,深度學習發展迅速,因此有學者通過訓練卷積神經網絡來完成圖像塊的匹配計算。?bonta等[4]提出了(stereo matching by CNN,MC-CNN),首次將卷積神經網絡應用于匹配成本的計算,利用卷積從一對立體圖像獲取更為抽象魯棒的特征,計算兩者的相似性作為匹配成本。Shaked等[5]提出了對文獻[4]的改進方法。但很多基于卷積神經網絡的立體匹配算法只是對深層網絡的特征進行計算,而忽略了淺層網絡的信息。深層網絡更注重于語義信息,而淺層網絡更注重細節信息,只采用深層網絡的語義信息進行預測對小物體的匹配效果差。因此,有學者采用了一種結合圖像金字塔的方法[6],將原圖像采用高斯下采樣構造出圖像金字塔,在圖像金字塔每層進行計算,得到不同尺度的視差圖進行融合,從而提高匹配精度,然而這種算法的缺點是計算量大、需要大量的內存。還有學者在不同特征層分別計算匹配成本[7],這樣做可以獲得不同層的特征,但是沒有將特征進行融合,獲得的特征不夠魯棒。
基于上述問題,本研究提出了一種結合特征金字塔結構(feature pyramid networks,FPN)[8]和卷積神經網絡(CNN)的立體匹配算法,試圖建立一個將深淺網絡特征進行疊加融合的網絡。本研究的優點是將深層特征和低層特征進行融合,即可以充分利用低層特征所提供的準確位置信息,又可以利用深層特征提供的語義信息,融合多層特征信息,且分別計算,再融合多組計算結果,可以得到較優的匹配結果。
1 算法描述
根據Scharstein等[9]提出的立體匹配算法分類和評價,立體匹配的步驟通常分為4個部分:①匹配代價計算;②代價聚合;③視差選擇;④視差后處理。本文也遵循此步驟。
1.1 特征金字塔(FPN)
識別不同尺寸的物體是機器視覺的難點之一,通常的解決辦法是構造多尺度金字塔。如圖1a)所示的圖像金字塔,由原圖像進行一系列的高斯濾波和下采樣構造而成,文獻[6]采用此結構,該做法雖然可以提高精度,但存在復雜度高、浪費內存的問題。圖1b)則在原圖像上進行一系列卷積池化,獲得不同尺寸的特征圖,然后使用深層特征進行計算,這種做法速度快、需要內存少,但精度有所下降,且只使用深層特征,而忽略了淺層特征的細節信息。因此有了圖1c)的改進方法,分別對每一層特征進行計算,同時利用淺層和深層特征的信息,這樣做一定程度可以提高精準度,但是它獲取的特征不夠魯棒。
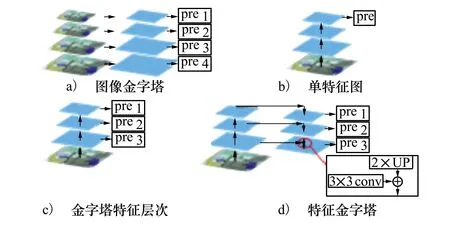
圖1 各多尺度方法框架
因此,本研究采用特征金字塔結構(FPN),架構如圖1d)所示,首先對原圖像進行卷積池化,獲取不同尺寸的特征圖,接著對深層特征圖進行上采樣,次一層進行下采樣使上下特征具有相同尺度,進而將2張特征圖進行融合,融合后的特征用來第一次計算;接著將融合特征再進行上采樣,再次一層特征下采樣,融合兩組特征,再進行一次計算,往復直至較淺層網絡,得到多組計算結果。該結構將淺層特征和深層特征融合,既獲得淺層特征的細節位置信息,又可以利用深層特征的語義信息,使得特征魯棒,計算結果準確。
1.2 基于FPN的網絡架構
根據以上介紹的FPN結構特點,本文設計了基于FPN的孿生[10]卷積網絡(FPN Siamese CNN,FS-CNN)來計算初始代價。網絡結構如圖2所示,整個網絡結構分為2個部分:
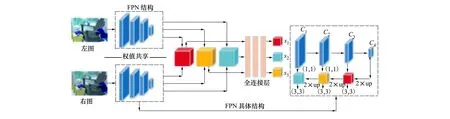
圖2 FS-CNN網絡結構
1) 第一部分用于圖像的特征提取,由2個結構相同的子網絡構成。每個子網絡首先對輸入的15×15的圖像塊分別經過4個卷積層,每一層都跟隨著批歸一化層(batch normalization layer)和ReLU激活函數,其中除了第一層步長為1,其余層步長均為2,經過4層卷積后,獲得了具有不同尺寸特征的網絡結構。接著采用FPN結構,首先對C4卷積層特征圖進行上采樣,使得尺寸和C3卷積層特征圖一致,把2個特征圖進行相加(add)處理得到融合特征,為了消除采樣后的混疊效應,在融合之后加入卷積核大小為3×3的卷積層。左右子網絡將分別得到的融合特征圖進行拼接(concatenate)處理,即可得到1個待匹配的融合拼接特征,重復以上的結構,就可以得到3個待匹配的融合拼接特征。值得注意的是需要在C2和C1卷積層特征圖融合前加入卷積核為1×1卷積層,目的是進行通道數降維,使得特征圖維度相同。
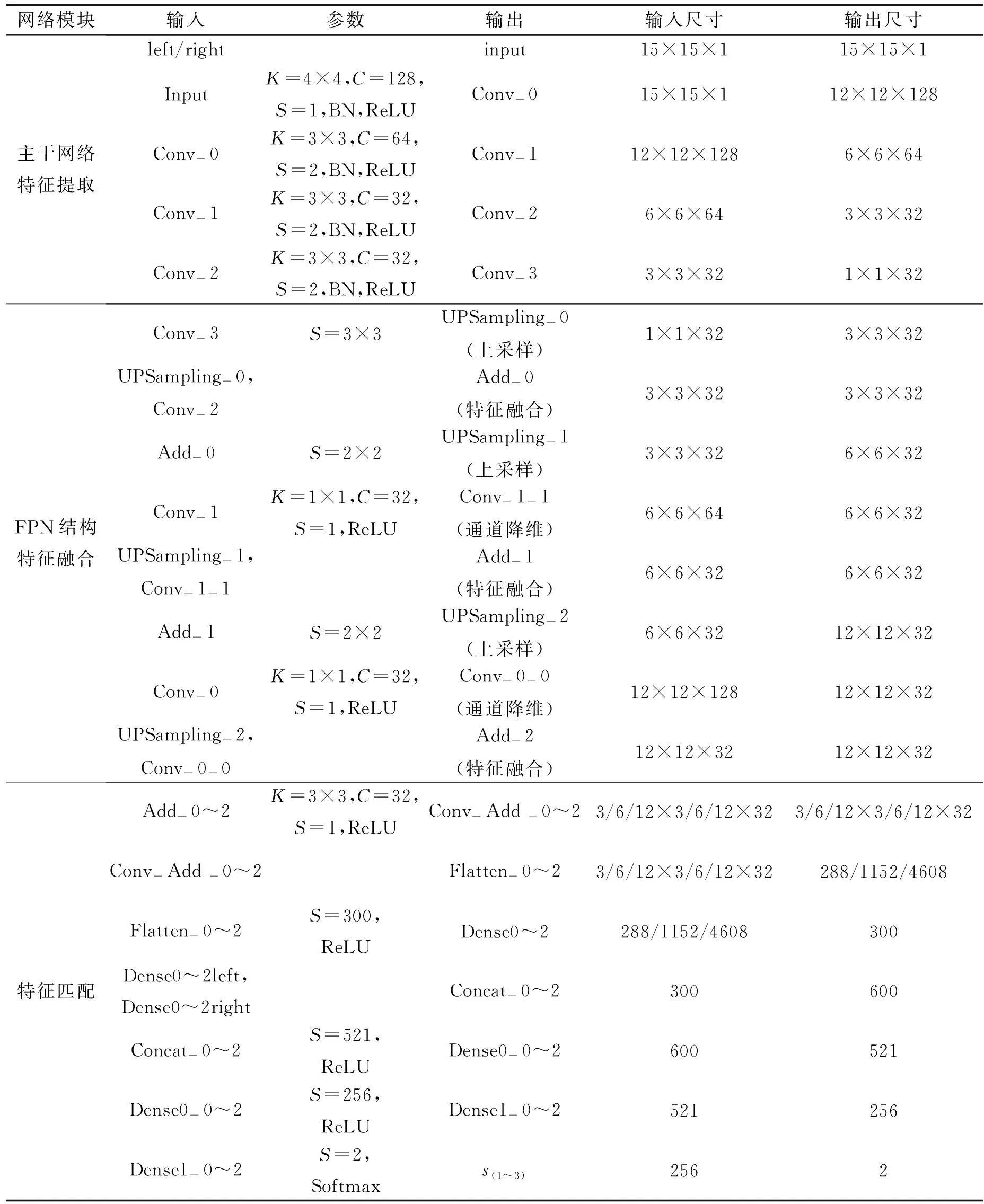
表1 FS-CNN網絡結構參數表
2) 第二部份用于特征匹配,為3層全連接層。將3個待匹配的融合拼接特征分別輸入,得到3個匹配結果s1,s2,s3作為在不同尺度下計算的匹配相似度。除了全連接層最后一層采用Softmax激活函數,其余層均采用ReLU激活函數,上采樣均采用雙線性插值算法。網絡參數由表1給出,其中Add-0~2表示Add-0或Add-1或Add-2,其余Conv-Add-0~2等同符號意思相同;3/6/12×3/6/12×32表示3×3×32或6×6×32或12×12×32,其余同符號意思相同。
1.3 匹配代價的計算
設以(i,j)為中心的左圖像塊為ρL(i,j),相應視差為d時的右圖像塊為ρR((i,j),d),由于本文設計的網絡有3個輸出,即可得到3個初始匹配代價
(1)
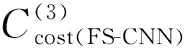
(2)
式中:x,y是代價空間DSI上像素點坐標;d為對應的視差值,d≤dmax,dmax=W×r為最大視差;W為原圖像的寬;r為一常數,取0.16;α為參數常量,取0.2。
1.4 代價聚合
代價聚合就是通過一定的規則在得到初始匹配代價的局部區域中進行累加聚合。一定角度上看,局部區域的代價聚合可以看做在代價空間DSI中的進行濾波,即
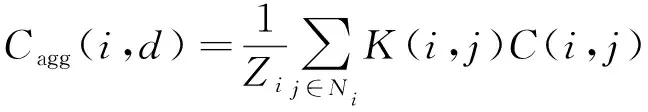
(3)

引導圖濾波技術是一高效有效的濾波技術,相比雙邊濾波器,引導圖濾波的計算復雜度僅為O(N),N為輸入圖像大小,因此引導圖濾波僅與輸入大小有關,與支持窗口的大小無關。采用引導圖濾波器進行代價聚合即就是在代價空間DSI上進行濾波,輸入的p即為各個視差值所在代價空間層DSI(:,:,d),引導圖I則為左右原立體圖像。
1.5 視差的選擇
在視差選擇階段傳統的做法一般采用貪婪算法(WTA)進行簡單的視差選取。雖然WTA快速有效,卻忽略了相鄰像素的視差容限。因此有學者采用動態規劃(DP)的全局思想來進行視差的選擇,首先構造能量函數M(x,y,d),采用DP最小化能量,并保存能量最小值所對應的視差位置,可表示為
(4)
式中:Cagg(x,y,d)為像素點(x,y)在視差為d時的代價值;d′為相鄰像素點(一般指前一個像素點)的視差選取;γ為參數常量。
但是采用這樣的做法,相鄰像素的視差選取為0~dmax,該算法的復雜度為O(WD2),W為圖像寬,D為選取視差范圍。所以,本研究采用改進的動態規劃的方法來進行視差選擇:①首先縮小相鄰像素點視差選取的范圍,將視差范圍0~dmax縮小為{d,d+1,d-1};②接著結合WTA算法,將WTA獲取的視差值dWTA也作為格外的視差候選值。
改進后的算法復雜度僅有O(WD),該算法的核心是結合WTA,提供格外的視差候選值,可以有效地避免出現過度平滑的現象,改進后的算法可以表示為
(5)
1.6 視差后處理
由1.5節獲得的初始視差圖中還存在一些誤匹配,需要進行視差精細化。本文采用左右一致性檢測來檢測遮擋點,接著進行遮擋點填充,最后采用加權的中值濾波器對視差圖進行平衡濾波,獲得最終的視差圖。
2 結果與分析
2.1 實現細節
FS-CNN網絡采用Tensorflow進行訓練,訓練采用小批度(mini-batch),批度大小(batch size)為64,使用Adam優化器,學習率為1×10-4,訓練周期為50,動量為0.9,匹配窗口為15×15。其余超參數neg-low=4,neg-high=8,pos=1,γ=2,ωk支持窗口為5×5,ò=0.01,參數具體意義可參考文獻[4]。運行平臺為Windows10×64位系統,CPU為Intel Core i5。
2.2 Middlebury 2014數據集
本研究采用Middlebury 2014數據集[11]。該數據集提供了30張立體圖像,圖像內容多為室內場景。其中包含15張帶有真實視差值訓練圖像,15張未帶真實視差值的測試圖像。
訓練數據集的構造本研究采用在15張帶真實視差圖的圖像對上,對于每對圖像對,在左圖像隨機截取15×15的圖像塊,在右圖像上根據正負樣本對應截取。正樣本表示右圖像在左圖像塊偏移真實視差值[+1,-1]對應的位置下截取的右圖像塊,負樣本表示右圖像在左圖像塊偏移真實視差值[-4,+8]對應的位置下截取的右圖像塊。接著隨機組合左圖像塊與右圖像像塊,對于左圖像塊與正樣本右圖像塊的組合設定標簽為(1),對左圖像塊與負樣本右圖像塊的組合設定標簽為(0)。
2.3 消融實驗
對FS-CNN網絡的每個結構的作用進行分析。在接下來的研究中,以與本研究提出的網絡最為相似的Dense-CNN網絡作為參考。實驗的評判標準采用算法得到的視差值與真實視差值的差值絕對值小于3像素或小于真實視差的 6% 時,認為該點所得視差值是正確的,否則將該點計為視差錯誤點,即
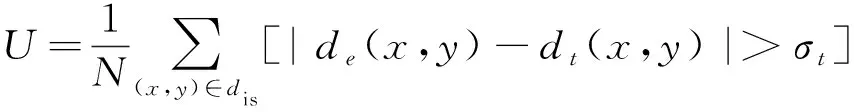
(6)
式中:N為視差圖像素點總數;de(x,y)為算法得到視差圖的視差值;dt(x,y)為真實視差圖的視差值;σt為設定的誤差限,本研究設置為3。
首先對主干特征提取結構進行測試,通過增加結構的卷積層數,測試對結果的影響。接著對FPN特征融合結構進行實驗。最后測試特征匹配結構,通過改變全連接層數。實驗結構如表2所示。

表2 不同網絡結構的評估結果
從表2的實驗結果發現,增加特征匹配結構的全連接層數量對結果的精度影響不大;增加主干特征提取結構的卷積層數,在一定程度下能降低誤匹配率,但是降低的程度有限,而且增加了運算成本;FPN特征融合結構的引入,可明顯提高匹配精度,降低誤匹配率,精度超過了參考網絡Dense-CNN。
2.4 不同算法的對比試驗和結果展示
對比算法本文采用:SGBM[1](參數:Sblock=9,Ndisparities=64,p1=200,p2=800);BM(參數:Sblock=9,Ndisparities=64);NCC算法;同等條件處理的Dense-CNN[4]。圖3為不同算法生成的圖像對視差圖,從上到下依次是Adirondack,Recycle,Sword1,Piano,PianoL,Playtable,Sword2。

圖3 圖像對在各類算法生成的視差圖
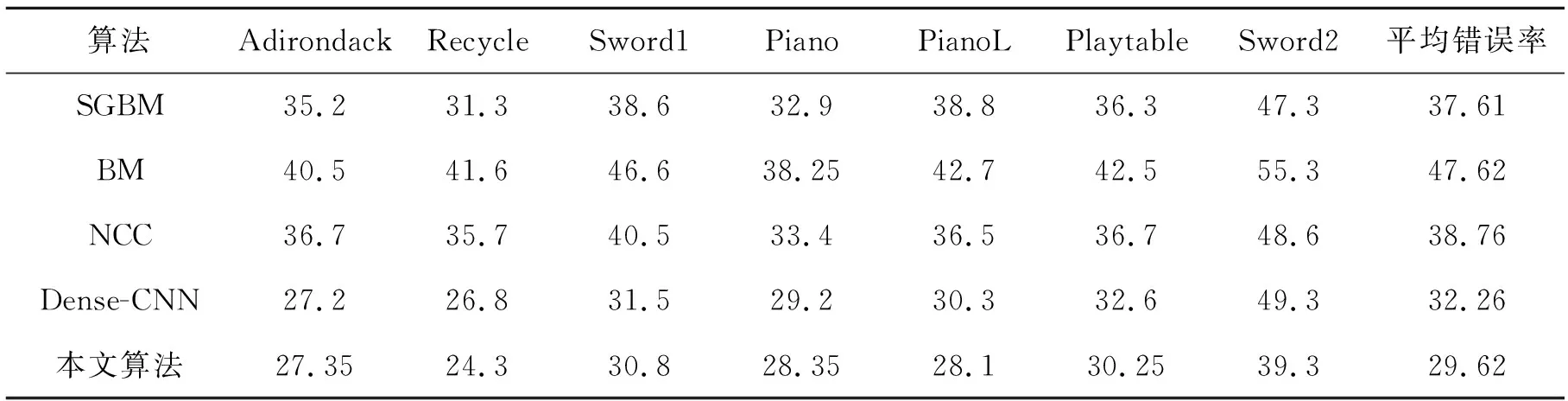
表3 圖片誤匹配率U%
由表3觀察到,本研究提出的算法在不同場景的匹配精度明顯都高于半全局算法SGBM,且遠高于BM、NCC局部算法。在同等條件下本研究算法誤匹配率低于傳統的Dense-CNN。值得注意的是,在PianoL場景中,由于左右圖像具有不同的光照條件,SGBM、BM、NCC 3個算法誤匹配率明顯變高,而Dense-CNN算法和本研究算法誤匹配率并無顯著變大,可以看出基于神經網絡的匹配算法對光照影響具有一定的魯棒性。在場景Sword2中,傳統的Dense-CNN算法具有較高的誤匹配率,而本研究提出的改進方法可以顯著地降低誤匹配率。
3 結 論
提出了一種結合特征金字塔(FPN)卷積神經網絡的立體匹配算法,該算法在卷積網絡(CNN)基礎上,應用了特征金字塔結構,自上而下地融合不同尺度的特征圖,且分別進行特征匹配計算,得到3組特征匹配結果,再計算得3組匹配成本,融合3組匹配成本獲得最終匹配成本,利用引導圖濾波器進行快速有效的代價聚合,在視差選擇階段采用改進的動態規劃(DP)算法,結合DP和WTA,既提高了匹配精度,又降低了復雜度。結果表明,所提算法精度優于現有部分優秀的匹配算法。目前該算法僅在CPU上實現,今后可利用GPU的并行運算來提高算法的效率。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
無線電工程(2020年11期)2020-10-29 01:25:46
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
