分布熵懲罰的支持向量數據描述
2021-09-09 08:09:18胡天杰胡文軍王士同
計算機應用 2021年8期
胡天杰,胡文軍,王士同
(1.湖州師范學院信息工程學院,浙江湖州 313000;2.江南大學人工智能與計算機學院,江蘇無錫 214122)
0 引言
異常檢測的目標是從正常樣本中訓練得到一個分類模型,進而對未知樣本進行檢測和識別,目前許多學者在訓練樣本中加入少量異常樣本提升了異常檢測的準確率,如帶異常樣本的支持向量數據描述(Support Vector Data Description,SVDD)[1]和深度神經網絡(Deep Neural Network,DNN)[2]等。在實際生活的各領域中,如故障診斷[3]、網絡入侵檢測[4]、醫療圖像診斷[5]、視頻異常檢測[6]和信用卡欺詐行為識別[7]等,獲取正常樣本較為容易,而獲取異常樣本需要花費很高的代價,因此異常檢測方法得到了廣泛使用。目前異常檢測的建模方法較多,比如基于統計學習的方法[8]、基于神經網絡方法[9]和基于密度估計方法[10]等。
Tax等[11]在2004年提出了SVDD方法,目標是在特征空間中找到一個能夠包含所有或大多數正常樣本的最小超球,作為一種典型的數據描述方法,在異常檢測領域受到了廣泛關注[12]。之后,很多學者對它進行了進一步的研究,并針對不同的問題提出了SVDD的改進方法,如為了增大超球體邊界與異常樣本之間的間隔,Wu等[13]在2009年提出了小球體大間隔(Small Sphere and Large Margin,SSLM)的支持向量數據描述方法。針對多分布數據,文獻[14-15]中提出了多球支持向量數據描述(Multi-Sphere SVDD,MS-SVDD)方法。楊小明等[16]從數據的幾何結構出發,綜合數據全局和局部幾何結構信息,在2015年提出了局部分塊的支持向量數據描述(SVDD based on Local Patch,OCSVDDLP),該方法通過局部分塊和局部樣本重構捕捉數據的局部結構信息。此外,為了提高SVDD的決策速度,胡文軍等在2011年提出了快速決策的SVDD方法(Fast Decision Approach of SVDD,FDA-SVDD)[17],該方法利用超球體球心原像將SVDD的決策復雜度降至O(1)。上述方法在建模時,都使用了相同的懲罰參數對所有松弛變量進行懲罰,即每個松弛變量的懲罰度一樣,當選擇不同懲罰參數時得到不同的訓練模型,因此上述方法對懲罰參數過于敏感。為此,Wang等[18]在2013年提出了位置正則的支持向量數據描述(Position regularized SVDD,P-SVDD),該方法利用映射后特征空間中的樣本點與均值點的歐氏距離設計不同的權重,以對相應松弛變量進行不同的懲罰。另外,Cha等[19]在數據原始空間中,基于數據分布為每個樣本點設計一種密度,并將此密度作為對應松弛變量的懲罰參數,提出了密度權的支持向量數據描述(Density Weighted SVDD,DWSVDD)。
如前所述,SVDD對懲罰參數相當敏感,其本質是懲罰參數直接影響到支持向量,而支持向量又決定著超球的球心和半徑。雖然P-SVDD和DW-SVDD從不同角度設計了每個松弛變量的懲罰參數,也獲得了一定效果,但這兩種方法都僅使用了正常樣本,無法適應包含少量異常樣本的場景。在包含異常樣本的場景下,SVDD中訓練樣本的數據分布勢必會變得更加復雜,一般地,在異常檢測任務中,獲取正常樣本容易而獲取異常樣本困難,正常樣本在數量上遠遠多于異常樣本,且正常樣本來自同一正常模式,數據分布單一,而異常樣本通常來自不同的異常模式,數據分布較為復雜,因此,正常樣本的分布對整體數據結構起決定性作用。為了避免少量異常樣本復雜的數據分布對SVDD建模的影響,本文將從高斯核空間中正常樣本的全局分布出發,提出一種距離度量,并基于此距離度量設計一種概率以評估樣本正常或異常的可能性,最后利用此概率構造基于分布熵的懲罰度對樣本進行懲罰,提出了一種分布熵懲罰的支持向量數據描述(Distribution Entropy Penalized SVDD,DEP-SVDD)異常檢測方法。該方法針對包含少量異常樣本的場景,在訓練樣本中加入了正常樣本和少量的異常樣本,并利用核空間中各個樣本點到正常樣本的全局分布中心之間的距離和熵的概念對各個樣本點實施不同的懲罰,降低了樣本在分類時的不確定度。
1 支持向量數據描述
1.1 高斯核空間
給定數據集:X={xi∈Rd|i=1,2,…,n}。其中,前m個樣本是正常樣本,即標簽yi=1(1≤i≤m),其他樣本是異常樣本,即標簽yj=-1(m+1≤j≤n)。一般地,數據是線性不可分的,為了解決此問題,常用方法是通過一個非線性映射函數將原始空間非線性映射至高維特征空間F,即?:x→?(x)。同時,利用一個核函數計算特征空間中的內積,即k(xi,xj)=?(xi)T?(xj),其中k(xi,xj)是某個核函數,常用核函數包括線性核、多項式核和高斯核[20]等。因高斯核能更好地捕捉數據的結構信息,故其最為常用,定義如下:
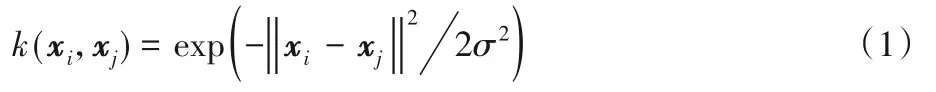
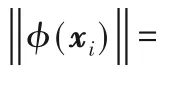
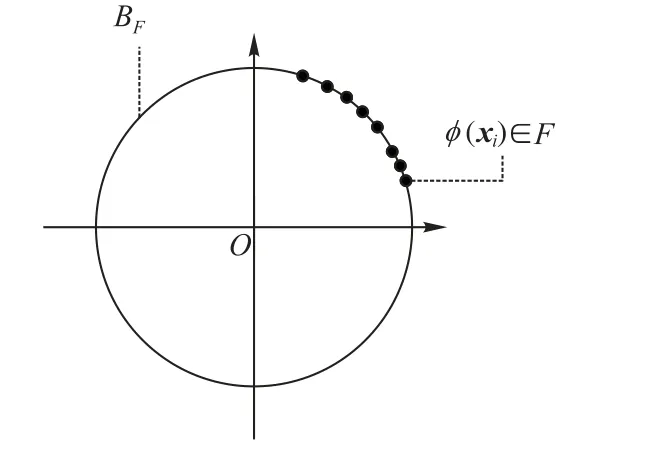
圖1 高斯核空間的幾何含義Fig.1 Geometric interpretation of Gaussian kernel space
1.2 傳統SVDD
SVDD的目標是構造一個包含所有或大部分正常樣本的最小超球,位于球面及球內的樣本為正常樣本,位于球外的樣本為異常樣本。其原始問題的數學模型為:
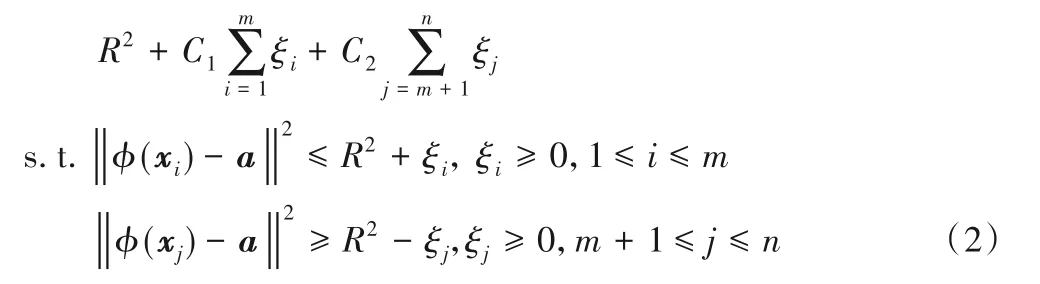
其中:R和a分別是超球的半徑和球心,C1和C2是懲罰參數,ξ=(ξ1,ξ2,…,ξn)T是引入的松弛變量,當正常樣本位于球外時,ξi>0,否則ξi=0;當異常樣本位于球內時,ξj>0,否則ξj=0。利用拉格朗日技巧可得上述問題的對偶形式:
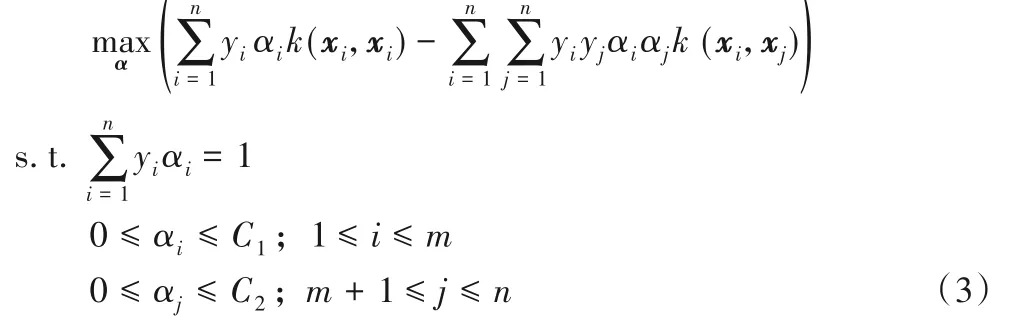
其中α=(α1,α2,…,αn)T是拉格朗日乘子。顯然,式(3)是一個含等式和不等式約束的二次規劃(Quadratic Programming,QP)問題。根據KKT(Karush-Kuhn-Tucker)條件可得如下結論:
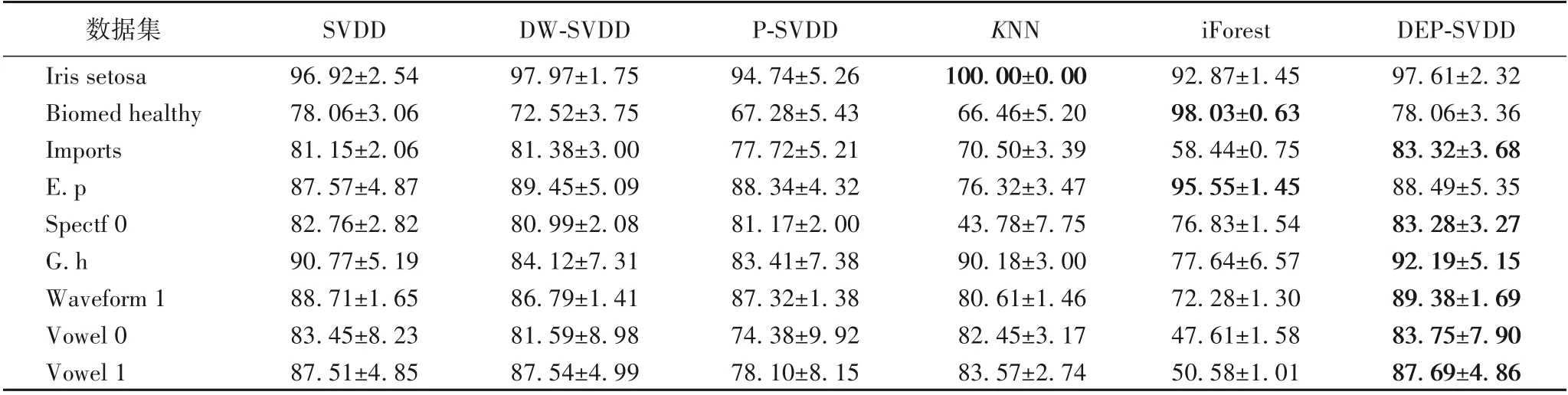
結論1 對于正常樣本,1)αi=0對應的樣本?(xi)位于超球內;2)0<αi 結論2 對于異常樣本,1)αj=0對應的樣本?(xj)位于超球外;2)0<αj 其中,?(xk)為位于超球面上任意一個樣本點。對于未知樣本x∈Rd,可通過如下函數進行決策: 當f(x)≤0時,x為正常樣本,否則為異常樣本。 圖2 高斯核空間中的距離度量Fig.2 Distancemeasure in Gaussian kernel space 比較樣本點與近鄰樣本或樣本類中心之間的距離,也是異常檢測的方法之一[22]。從樣本分布結構來看,若樣本點距離某類樣本越近,則其屬于該類樣本的可能性越大,故距離可以評價樣本點隸屬的可能性。下面基于距離定義兩種概率。 1)正常樣本的異常概率。 2)異常樣本的正常概率。 在信息論領域中,熵是樣本所攜帶信息的度量,可對信息的不確定度進行評價[24],其定義如下: 設一個離散隨機變量A={a1,a2,…,an}服從概率分布p(a),則信息熵定義為: 根據式(7)或(8)的概率pi與式(9)為各個樣本點設計信息熵: 考慮到式(10)中的熵由數據的全局分布信息計算而來,因此本文將其稱為分布熵。由式(10)可知,樣本點屬于正常或異常的概率pi越大,對應的分布熵呈現先增大后減小的趨勢,這與正常樣本和異常樣本在分類時的不確定度趨勢是一致的。 為解決SVDD中懲罰參數固定不變的問題,在目標函數中對松弛變量加權是一種有效的辦法,將式(10)中每個樣本點的懲罰度Wi應用至SVDD中,得到DEP-SVDD原始問題的數學模型: 需要注意的是,熵一般作為模型中獨立的一項進行優化,對一個動態系統進行不確定性的度量,而本文在參數確定之后,模型系統是靜態的。因此,本文借用熵的概念對松弛變量進行加權去修正SVDD的懲罰參數,如式(11)所示。 引入拉格朗日乘子構造如下拉格朗日函數: 其中,α=(α1,α2,…,αn)T≥0,β=(β1,β2,…,βn)T≥0是拉格朗日乘子。式(12)對原始變量R和ξi、ξj求偏導并置為0,對α求偏導并置為0,得: 根據α≥0,β≥0和式(15)、(16),可得0≤αi≤C1Wi,0≤αj≤C2Wj。將式(13)~(16)代入式(12)得到原始問題的對偶形式: 顯然,式(17)是一個二次規劃(QP)問題,根據KKT(Karush-Kuhn-Tucker)條件可得如下結論: 結論3 對于正常樣本,1)αi=0對應的樣本?(xi)位于超球內;2)0<αi 結論4 對于異常樣本,1)αj=0對應的樣本?(xj)位于超球外;2)0<αj 利用超球面上的任意一個樣本點和球心式(14)可計算超球的半徑,其表達式和式(4)相同,對于未知樣本x∈Rd,可通過式(5)進行決策。 DEP-SVDD算法的實現步驟如下: 輸入:數據集X={xi∈Rd|i=1,2,…,n},高斯核帶寬參數σ和懲罰參數C1、C2。 輸出 對于未知樣本x,根據式(5)進行決策,當f(x)≤0時,x為正常樣本;否則為異常樣本。 步驟1 利用式(6)計算各個樣本點到全局分布中心的距離di; 步驟2 利用式(7)計算正常樣本屬于異常樣本的概率pi,或利用式(8)計算異常樣本屬于正常樣本的概率pi;步驟3 利用式(10)計算各個樣本點的懲罰度Wi;步驟4 求解式(17)的二次規劃問題。 DEP-SVDD計算的時間復雜度主要包括兩部分:第一部分是利用各個樣本點到數據的全局分布中心的距離計算每個樣本的懲罰度(步驟1~3),根據式(6)可知步驟1計算距離的時間復雜度為O(mn),得到該距離后,利用式(7)、(8)和(10)為n個樣本分別計算其屬于正常或異常樣本的概率和懲罰度(步驟2和3),時間復雜度都為O(n)。第二部分是求解式(17)的二次規劃問題(步驟4),時間復雜度為O(n3)[25]。綜上,DEP-SVDD的訓練過程的時間復雜度為O(n3+mn+2n),SVDD雖然少了算法步驟1~3,但仍需進行二次規劃問題的求解,時間復雜度為O(n3),因此DEP-SVDD算法會略慢于SVDD。在對未知樣本進行決策時,因DEP-SVDD和SVDD都使用式(5)作為決策函數,故它們的復雜度一樣,均為O(n)[17]1086。 實驗環境:CPU Intel Core i7-4712MQ 2.30 GHz,12 GB RAM,64位Windows 10,Matlab R2017b。 利用幾種廣泛使用的異常檢測數據集將DEP-SVDD與SVDD、DW-SVDD、P-SVDD、K最近鄰(K-Nearest Neighbor,KNN)[26]和孤立森林(isolation Forest,iForest)[27]進行分類精確度的比較,如表1所示,其中E.p和G.h分別對應Ecoli periplasm和Glass headlamps數據集,具體信息可參考http://homepage.tudelft.nl/n9d04/occ/index.htm l和http://archive.ics.uci.edu/m l/datasets.php。 表1 實驗數據集描述Tab.1 Description of experimental datasets 在實驗中,首先對所有樣本的特征進行歸一化到[-1,1]的處理,然后從正常樣本中隨機抽取70%的樣本,從異常樣本中隨機抽取若干樣本使得其占訓練樣本的20%,剩下的樣本用作測試樣本。所有算法都使用高斯核函數進行實驗,帶寬參數σ從{2n s}中選擇,其中n={-6,-5,…,6},s是所有訓練樣本2范數均值的平方根[28];由于DW-SVDD和DEPSVDD皆利用權值對懲罰參數進行了修正,而該權值的范圍在0~1,因此懲罰參數設置的范圍應大于1,故將從{0.3,0.5,0.7,0.9,1.1,1.3,1.5,1.7,1.9}中選擇懲罰參數,由于傳統SVDD中的懲罰參數必須小于等于1,因此對于SVDD,該網格1.1及之后的值都置為1;另外,DW-SVDD和KNN需要尋找數據的K最近鄰,參數K從{3,5,7,9}中選擇;孤立森林方法中,孤立樹的數量設置為100,子采樣大小設置為256[27]418。 首先分別驗證懲罰參數C1和C2對DEP-SVDD算法的影響,設置懲罰參數為1.3,高斯核帶寬參數σ為2-2s,結果如圖3和圖4所示。 圖3 懲罰參數C1對算法的影響Fig.3 Influenceof penalty parameter C1 on algorithm 圖4 懲罰參數C2對算法的影響Fig.4 Influenceof penalty parameter C2 on algorithm 從圖3可以看出:懲罰參數C1的取值小于等于0.7時,DEP-SVDD算法對C1較為敏感,大部分數據集的分類精度波動都較為明顯,其中,在Biomed healthy數據集上達到了30%;在C1的取值大于0.7時,DEP-SVDD的分類精度趨于平穩,除Glass headlamps數據集外,對其他數據集的分類精度波動都在6%以內。從圖4可以看出,除Biomed healthy數據集外,其余數據集的分類精度較為平穩,DEP-SVDD算法對懲罰參數C2的取值相對不敏感。 然后對所有數據集進行10次獨立重復的實驗并取均值和標準差進行比較,結果如表2所示。表2顯示了DEP-SVDD與傳統SVDD、解決懲罰參數敏感問題的DW-SVDD和PSVDD以及基于近鄰的KNN和基于集成學習的孤立森林異常檢測方法的幾何精度對比。一方面,從表2中的幾何精度可以看出,本文提出的DEP-SVDD對上述數據集的分類精度大多都達到了83%以上。其中,在Iris setosa數據集中KNN的分類精度最高,達到了100%;在Biomed healthy和E.p數據集中iForest方法的分類精度最高且明顯高于其他方法,分別達到了98.03%和95.55%;在其余數據集中DEP-SVDD算法都取得了最好的效果。除此之外,DEP-SVDD在絕大多數數據集上的表現都要優于SVDD以及同樣解決懲罰參數敏感問題的DW-SVDD和P-SVDD。另一方面,從表2中的標準差可以看出,iForest方法的穩定性明顯高于其他方法,而除iForest之外的異常檢測方法的穩定性都較為接近。綜上所述,本文提出的DEP-SVDD在一定程度上提高了異常檢測的準確率,這是因為DEP-SVDD利用正常樣本作為數據的全局分布,并在特征空間中構建了能更準確描述樣本間分布結構信息的距離度量,基于該距離度量設計了評估各個樣本點屬于正常或異常樣本的概率,最后利用此概率構造基于分布熵的懲罰度對各個樣本點實施不同的懲罰,解決了SVDD對懲罰參數過于敏感的問題。 表2 不同算法的幾何精度 單位:%Tab.2 Geometric precisionsof different algorithms unit:% 針對SVDD對懲罰參數過于敏感的問題,本文提出了分布熵懲罰的支持向量數據描述方法(DEP-SVDD)。該方法將訓練樣本映射至高斯核誘導的特征空間,構建核空間中各個樣本點到正常樣本全局分布中心之間的距離度量來評估各個樣本點屬于正常或異常樣本的概率,并利用此概率構造基于分布熵的懲罰度對各個樣本點實施不同的懲罰。相較于SVDD,所提方法使用了更多的信息,并最小化樣本分類時的不確定度,提升了算法的分類精確度,最后的實驗結果表明提出的DEP-SVDD是一種有效的異常檢測方法。但本文僅討論了數據的全局分布,沒有考慮數據的局部信息對算法的影響,并且只考慮了高斯核函數的使用,并沒有研究其他核函數在參數條件合適的情況下的使用,這都將是下一步的重點研究方向。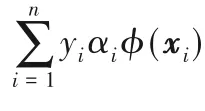
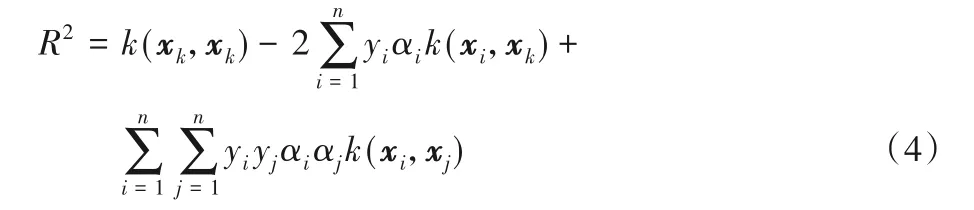
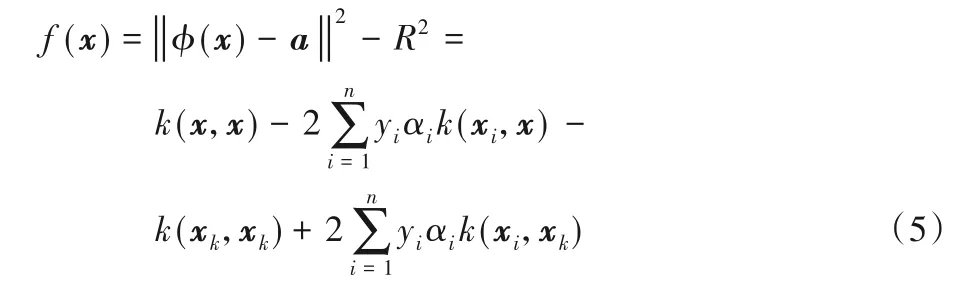
2 分布熵懲罰的SVDD
2.1 距離度量
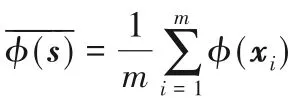
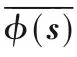
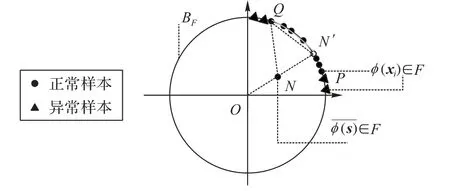


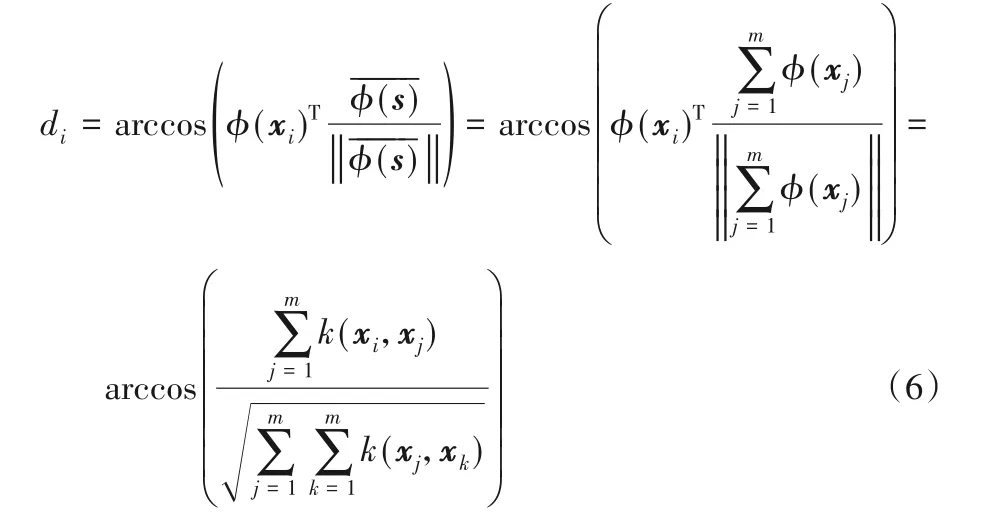
2.2 基于熵的懲罰度

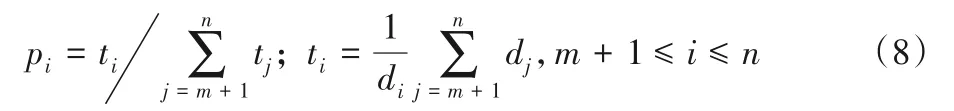
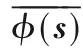

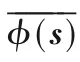
2.3 DEP-SVDD
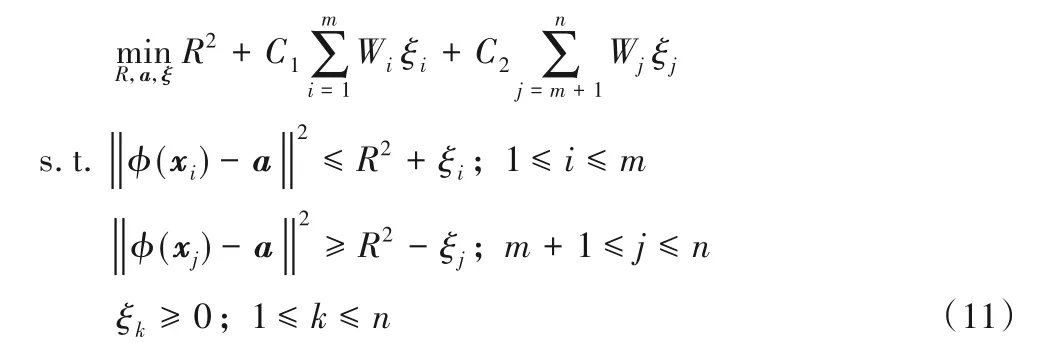
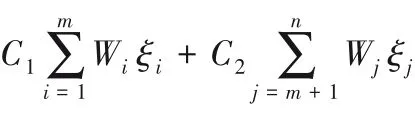
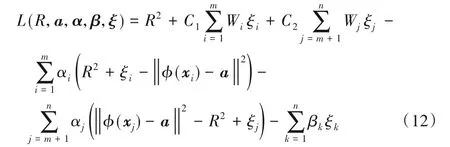
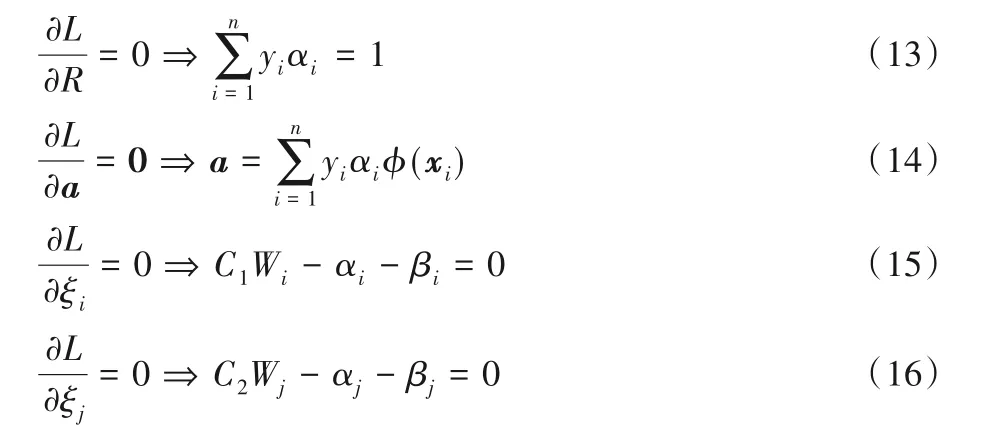
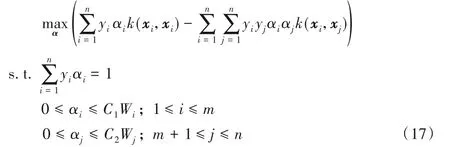
2.4 算法實現
2.5 時間復雜度分析
3 實驗與分析
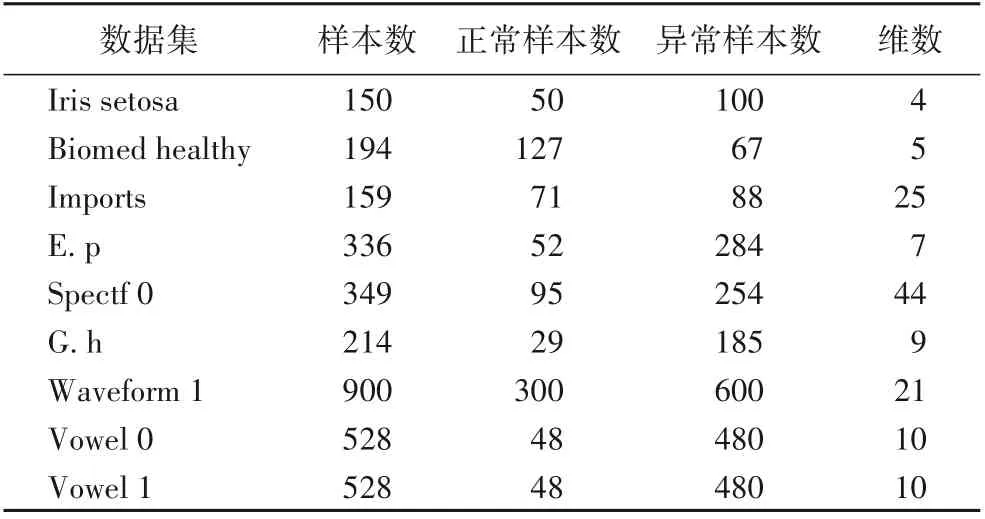
3.1 數據集與幾何精度
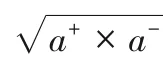

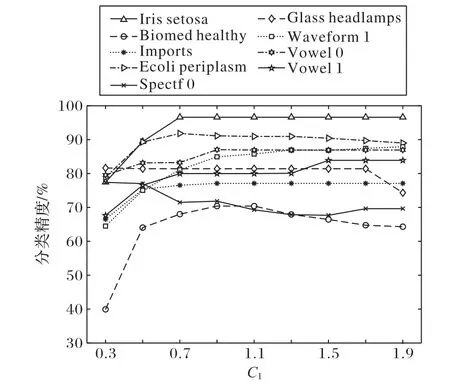
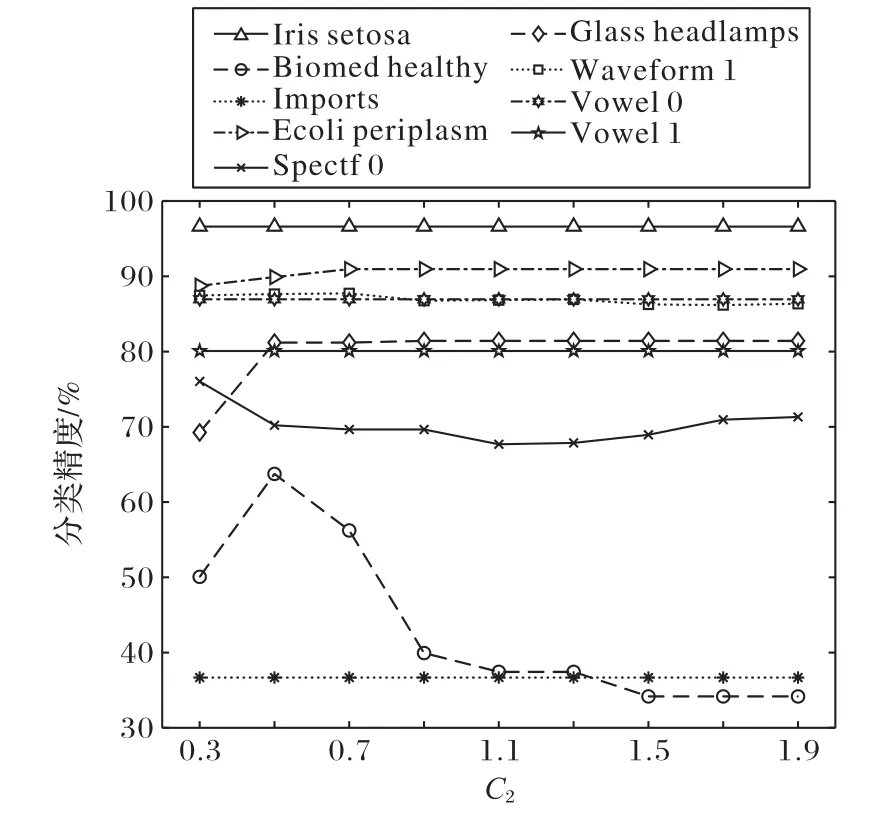
3.2 實驗結果及分析
4 結語
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58小讀者(2020年2期)2020-03-12 10:34:06趣味(語文)(2018年1期)2018-05-25 03:09:58海峽科技與產業(2016年3期)2016-05-17 04:32:12Coco薇(2016年2期)2016-03-22 02:42:52Coco薇(2015年1期)2015-08-13 02:47:34學苑創造·A版(2015年6期)2015-07-01 09:00:12小雪花·成長指南(2015年4期)2015-05-19 14:47:56
