基于聚合酶鏈置換反應的2D-LASM混沌文本加密算法
2021-09-10 06:00:40王夕遠殷志祥崔建中徐如解
廣州大學學報(自然科學版) 2021年2期
王夕遠, 殷志祥,2*, 唐 震, 楊 靜, 崔建中, 徐如解
(1. 安徽理工大學 數學與大數據學院, 安徽 淮南 232001;2. 上海工程技術大學 數學與統計學院, 上海 201620; 3. 淮南聯合大學 計算機系, 安徽 淮南 232001)
近年來由于科技的迅猛發展,傳統電子計算機已經難以滿足人們的需求.DNA計算機是近些年最有獨創性和出乎意料的發現之一,其具有高度的并行性、運算速度快、存儲容量大、耗能低和DNA分子資源豐富等優點.為了制造出DNA計算機,人們開始對DNA計算進行研究.DNA計算的第一個例子解決了一個7城市哈密頓路徑問題[1].2000年,Head等[2]提出了使用DNA質粒的一種新的計算方法,列出了潛在的優勢.通過報告計算圖頂點集最大獨立子集基數的NP完備算法題的一個實例計算,說明了新方法的有效性.2003年,殷志祥等[3]提出了在基于表面的DNA計算采用熒光標記策略,解決了簡單的0-1規劃問題.2011年,Qian等[4]提出了DNA鏈置換級聯的神經網絡計算.此外,DNA計算還可以用來構建半加器、半減器、全加器、全減器[5-9].2019年,Chao等[10]在DNA折紙上利用DNA單分子導航儀求解迷宮問題.同年,唐震等[11- 12]利用了DNA折紙術解決了一類特殊的整數規劃問題,還提出了在DNA折紙基底上的一種動態的與非門計算系統.
隨著計算機技術的發展和運用,人們通過網絡進行信息傳輸的頻率越來越頻繁.為了防止傳輸的信息被截獲破解,人們越來越重視對信息的傳輸加密.由于混沌系統具有有界性、遍歷性、偽隨機性、對初值條件和控制參數敏感性等特點,人們把混沌系統用于信息加密領域.2010年,王林林[13]提出了基于混沌的密碼算法設計與研究.2015年,賈嫣等[14]提出了基于改進混沌映射的圖像加密算法,該算法采用的是雅克比橢圓映射對初始密鑰進行迭代產生新的密鑰.2020年,嚴利民等[15]提出了混沌映射和流密碼結合的圖像加密算法.2021年,蔡敏等[16]設計并實現了基于混沌時間序列的圖像加密算法.同年,曾祥秋等[17]提出了基于改進的Logistic映射的混沌圖像加密算法.考慮到DNA可以存儲大量信息的特點,人們開始將DNA和混沌系統進行結合,并用于信息加密領域.2016年,Wang等[18]提出使用CML和DNA序列操作的彩色圖像加密方案.該方案將圖像的每一個像素進行DNA編碼,并給出了8種相對應的DNA編碼規則.2017年,孫倩等[19]提出了基于DNA編碼與統計信息優化的圖像加密算法.2020年,朱凱歌等[20]設計了基于DNA動態編碼和混沌系統的彩色圖像無損加密算法.
之前,人們所提出的將DNA用于信息加密的算法中,并沒有涉及到DNA計算中的化學反應,只是將數據轉換成了DNA編碼的形式.本文提出了一種基于聚合酶鏈置換反應的2D-LASM混沌映射文本加密算法,成功將DNA計算中的化學反應結合到加密過程中,并對該算法進行了密鑰空間分析,表明該算法具有較好的加密效果.
1 準備工作
1.1 二維Logistic-Adjusticed-sine (2D-LASM)映射
本文的加密算法采用結構簡單、性能優良的二維Logistic-Adjusticed-sine(2D-LASM)映射,其數學表達式如下:
其中,μ∈[0,1],Xn,Yn∈(0,1).這里給定初值,設X1=0.5,Y1=0.5,為了消除瞬態效應迭代n次,產生兩個長度為n的偽隨機數組X和Y.
1.2 DNA序列編碼
DNA(脫氧核糖核酸)是染色體的主要組成成分,同時也是主要遺傳物質.DNA是雙螺旋結構,有兩條脫氧核苷酸鏈,一個脫氧核苷酸分子由三個分子組成:一分子含氮堿基、一分子脫氧核糖及一分子磷酸.脫氧核苷酸共有4種含氮堿基分別為:A(腺嘌呤)、T(胸腺嘧啶)、G(鳥嘌呤)和C(胞嘧啶).按照Watson-Crick堿基互補配對原則,A和T互補,C和G互補.在計算機中,信息的存儲是用二進制0和1進行表示.二進制中0和1是互補的,因此00和11,10和01也是互補的.若將A、T、C、G分別用00,01,10,11進行表示共有24種,而符合互補原則的只有8種,見表1.
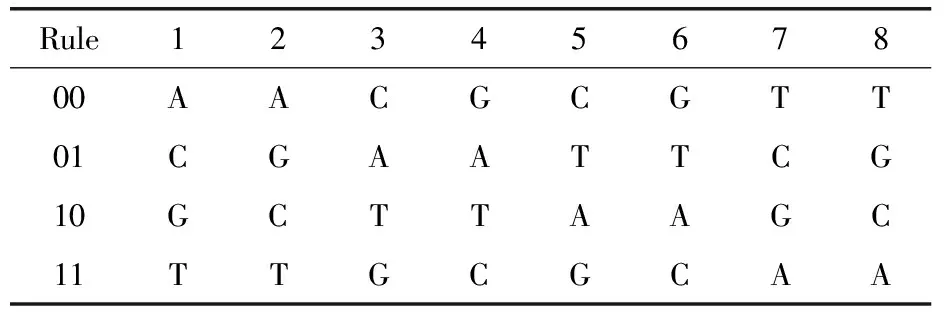
表1 DNA編碼規則
1.3 聚合酶鏈置換反應原理
聚合酶鏈置換反應(Polymerase Strand Displacement, PSD)是一種基于聚合酶的鏈置換反應,其和一般的鏈置換反應不同的是該反應需要有酶的參與.反應原理見圖1,這里的A和A*互補,B和B*互補,C和C*互補,D和D*互補.這種反應類似于聚合酶鏈式反應(PCR).首先,引物和部分互補的雙鏈DNA粘性末端按堿基互補配對原則結合,即A和A*相結合;其次,將溫度調至DNA聚合酶最適反應溫度,在DNA聚合酶的作用下,從引物的3′端開始以5′→3′端的方向延伸,合成與模板5′-D-C-B-A-3′互補的DNA鏈,將部分互補的雙鏈DNA中的單鏈5′-C*-D*-3′置換出來.

圖1 聚合酶鏈置換反應原理Fig.1 Principle of polymerase strand displacement reaction
2 本文的加密算法
2.1 算法框架
(1)將待加密的文本信息進行置亂處理,隨后和2D-LASM混沌映射產生的偽隨機序列進行異或操作,之后再根據產生的隨機種子選擇相應的DNA編碼規則得到相對應的DNA序列;
(2)將所得到的DNA序列進行PSD反應,得到一組新的DNA序列.根據隨機種子選擇相應的DNA解碼規則,得到加密的文本.
本文的加密算法具體框架如圖2所示.
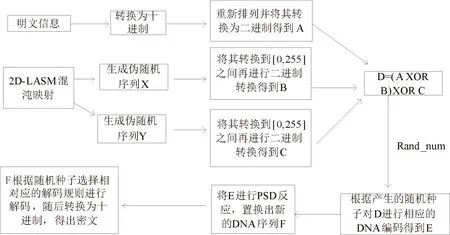
圖2 算法框架Fig.2 Algorithm framework
2.2 加密算法的工作步驟
Step1:輸入一段明文,將其轉換為十進制的數,長度為L;
Step2:采用randperm函數將十進制數進行重新排列,并將其轉換為二進制數,記為A;
Step3:通過二維Logistic-Adjusted-Sine混沌映射迭代1 000+L次,得到兩個偽隨機序列X,Y;
Step4:分別取X,Y的后L位,經過mod(floor(k*108),256)將其轉換到[0,255]之間并進行二進制處理得到B,C,這里mod表示取余,floor表示向下取整;
Step5:對Step2中的A和Step4中所得到的B,C進行異或操作得到D;
相關的地方性立法目前還不健全,特別是自然地理環境特殊的省份,例如西藏自治區發展高原農業和河谷農業,東北三省有廣袤的東北平原發展專業化農業,都沒有出臺相關文件。“各地可結合當地的優勢農產品布局,形成各具特色的農業機械化區域,進一步拓展農業機械化的服務和作業領域,突出綜合性、多樣性、優質高效性,實現農業機械化的跨越式發展,促進農業機械化與地區經濟協調統一發展。”[5]即形成地理單元與行政區劃緊密連接的農業機械化發展格局。伴隨著我國經濟的發展和全面深化改革進程的加快,農業機械化立法已經明顯滯后于現實的發展,制約了農業機械化在發展農業現代化中的作用。
Step6:根據產生的隨機種子選擇相應的DNA編碼規則對D進行編碼,得到DNA序列E;
Step7:將所得到的DNA序列E按照長度為m進行分割,得到u條DNA序列.再將這u條序列分別進行PSD反應,可以置換出u條新的DNA序列;
Step8:將Step7所得到的u條DNA序列在DNA連接酶的作用下組成一條新的DNA序列F;
Step9:根據隨機種子選擇相應的DNA解碼規則對F進行解碼,并將其轉換為十進制數G;
Step10:對G使用char函數得到相應的密文.
解密過程是加密過程的逆過程,這里由于篇幅問題就不再闡述.
2.3 實例分析
該實例的仿真是在Matlab 2016a仿真軟件上進行的,這里所采用的明文為you are a better man;將其轉換為十進制數得到[121,111,117,32,97,114,101,32,97,32,98,101,116,116,101,114,32,109,97,110],可知L為20.并將其進行重新排列得到[97,101,98,114,110,121,97,109,116,32,32,32,117,32,101,116,111,97,101].隨后轉換為二進制數得到A;
通過二維Logistic-Adjusted-Sine混沌映射迭代1 000+20次,得到兩個偽隨機序列X,Y;
分別取X,Y的后20位,經過mod(floor(k* 108),256)將其轉換到[0,255]之間并進行二進制處理得到B,C,這里mod表示取余,floor表示向下取整;
對A,B,C進行異或操作得到D;這里產生的隨機種子為2,即選擇第二種DNA編碼規則進行編碼得到DNA序列E: CGACCGTCGTTTCTACAAAGGGAGTAATTCGGCTATACTTTGTTGACGG-GCGAAGCCTAGCCCTGTGACTCCTTCCCCAT長度為80 nt;對DNA序列E按照長度為16 nt進行分割,可得到5條DNA序列,見圖3.
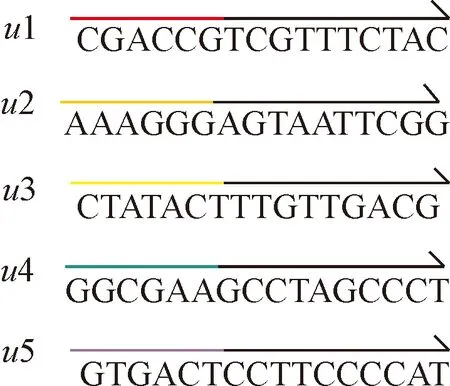
圖3 DNA序列E的分割Fig.3 Segmentation of DNA sequence E
將所得到的5條DNA序列進行PSD反應,具體過程見圖5.為了保證和DNA序列E相對應,生成一組隨機數,根據上述的方法進行DNA編碼得到DNA序列F:CCGCAGTTCATGGACCGCTCGGTTAGACTCGAGATCTTTCATTAAAAGATTCCGACG-CCACCTCGGTGTTTGGCGTACCT長度為80 nt;對F按照16 nt進行分割得到5條DNA序列,見圖4.

圖4 DNA序列F的分割Fig.4 Segmentation of DNA sequence F
經過PSD反應之后得到5條長度為16 nt的DNA單鏈,將這5條單鏈按照m1-m2-m3-m4-m5的順序進行合并得到F.這樣通過PSD反應將文本信息轉換的DNA序列E成功變成了DNA序列F;接下來根據隨機種子選取相對應的DNA解碼規則將其轉換為二進制數G,將G轉換成十進制數H,之后得到密文“|Jn_N<>h?]g+”.
通過以上步驟成功將明文you are a better man轉換為|□Jn_N<>□h?]g+.需要注意的是這里的DNA序列F是根據產生的隨機數進行DNA編碼的,產生的隨機數不同這里的F就不同,最終得到的密文也就有所不同.
3 算法安全性分析
若想對密文進行解密需要知道明文所對應的DNA序列E和所產生的隨機種子,但由于DNA序列F是由產生的隨機數所得到的,再加上PSD反應是不可逆的,因此,得到DNA序列E就顯得很困難,此外還需要知道明文信息轉換為十進制之后是如何進行重新排列的.本文將經過PSD反應(圖5)所置換出來的DNA單鏈設置為16 nt,由于DNA具有4種含氮堿基,因此,每條DNA單鏈共有416種可能性.由于滿足互補條件的DNA編碼規則共有8種,因此,相對應的DNA解碼規則也有8種.對明文信息轉換成十進制的數進行重新排列共有20!種,因此,該算法的密鑰空間為(20!)*8*8*416*416*416*416≈2184遠大于2100,這說明該算法可以抵抗窮舉攻擊,安全性能高.
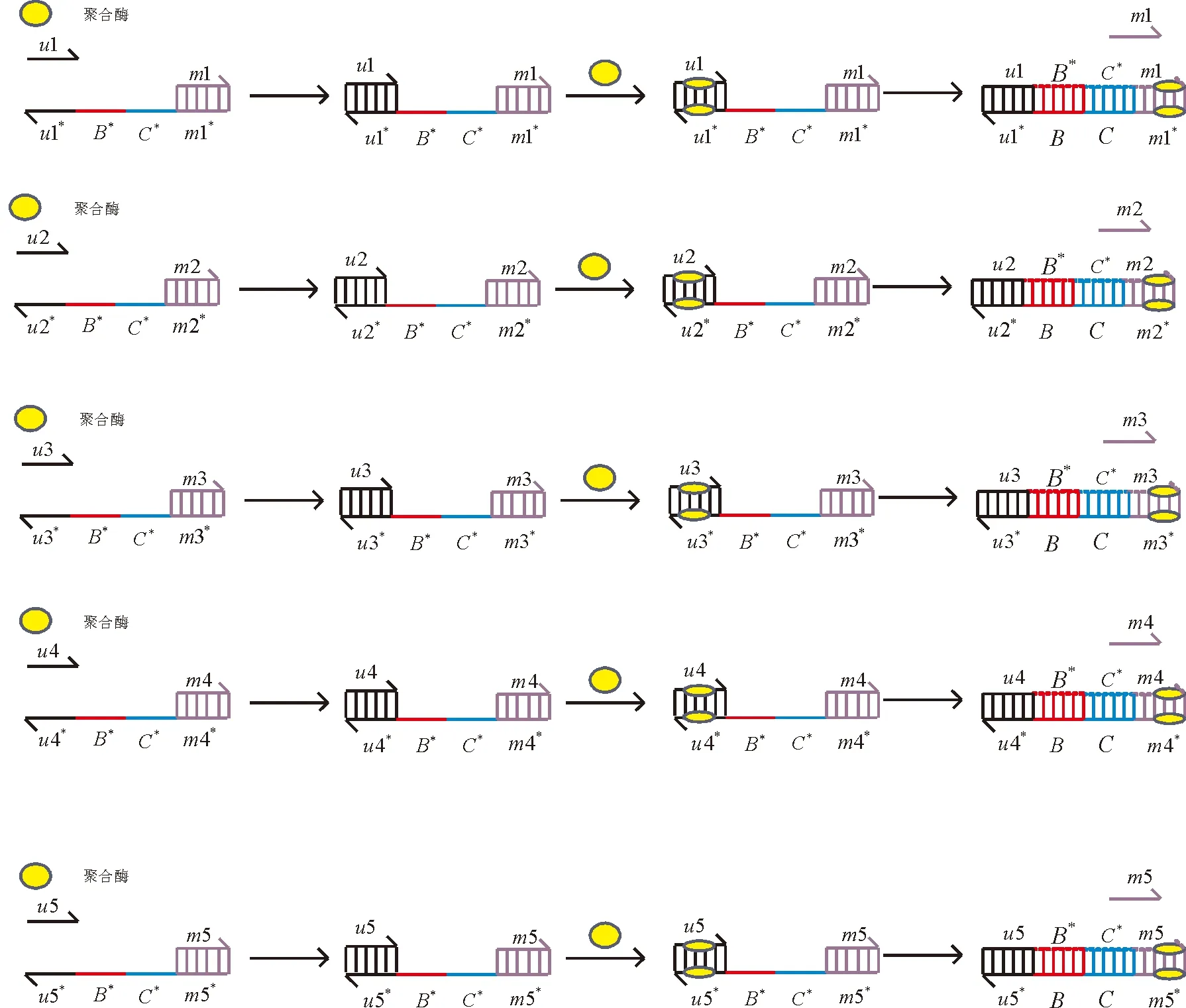
圖5 PSD反應Fig.5 Polymerase stand displacement reation
4 結 論
本文提出了一種基于聚合酶鏈置換反應的2D-LASM混沌映射文本加密算法,克服了之前DNA加密算法中沒有涉及到DNA計算加入化學反應這一缺點.加入化學反應之后,算法的密鑰空間有了很大的改善.同時,這一算法還為圖像加密提供了思路.如何將DNA計算中的化學反應用于圖像加密,這是以后需要解決的問題.
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
幸福(2018年33期)2018-12-05 05:22:42
Coco薇(2017年11期)2018-01-03 20:59:57
中華手工(2017年2期)2017-06-06 23:00:31
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
中國科技信息(2016年14期)2016-07-31 21:16:32
中外會展(2014年4期)2014-11-27 07:46:46
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
