基于視頻的人體狀態快速識別方法研究
2021-09-10 07:22:44桑康西祝凱劉振宇朱文印王和龍
青島大學學報(自然科學版) 2021年1期
桑康西 祝凱 劉振宇 朱文印 王和龍



摘要:識別人體狀態與理解人類情感是家電智能化的最終目的,人體許多日常行為并不攜帶明顯的狀態信息和情感傾向,而諸如跌倒、打哈欠、腰痛等出現頻率較低卻包含豐富的人體狀態信息。以帶有一定情感傾向或意圖的人體狀態為研究對象,從公開數據集中篩選出9種帶有人體狀態信息的典型行為,考慮到家居環境下實時產生的原始視頻數據量龐大、存在特征冗余,提出用相鄰視頻幀做減法得到的RGB連續差分圖像序列作為輸入,鑒于樣本少,使用常規大型網絡容易過擬合,因此采用最新的輕量級網絡模型MobileNetV2,極大減少訓練參數量,進而實現快速有效的人體狀態識別。研究結果表明,本方法能夠達到較高的準確率,基本可以滿足家居環境下的人體狀態檢測要求。
關鍵詞:人體狀態識別;RGB視頻;卷積神經網絡;MobileNetV2
中圖分類號:TP391.4
文獻標志碼:A
文章編號:1006-1037(2021)01-0040-06
基金項目:
山東省新舊動能轉換重大課題攻關項目(批準號:201905200432)資助。
通信作者:祝凱,男,博士,講師,主要研究方向為機器視覺與人工智能。E-mail:zhu_kaicom@163.com
隨著物聯網的快速發展和智能家居的普及,準確高效地識別用戶的行為、狀態、情感、意圖逐漸成為提高智慧家庭智能化水平的關鍵技術之一[1]。家居環境下的情緒識別歸根結底是理解人的狀態,推斷人類意圖,進而讓機器做出準確回應[2]。研究表明,當人類表達情感意圖時,語言信號所傳達的情感信息僅占35%,而非語言信號傳達的信息占比達65%[3]。非語言信號主要包括面部表情與人體行為,而實際場景中由于遮擋、偏移、光照、距離等原因導致面部特征無法準確獲取和計算,因此空間尺度更大的人體動作或行為視頻逐漸成為識別情感和預測意圖的重要數據來源[4]。國內外學者對人體行為分類算法進行了較多研究。Bull[5]發現,部分情感與不同的身體姿勢和動作有關,如興趣或無聊,贊同或反對等。Pollick等[6]發現,一些特定的上肢手臂運動,可以輔助人類以顯著高于基準水平的準確度辨別基本情感。Coulson[7]研究發現,靜態身體姿勢對于分類識別過程具有重要作用。Castellano等[8]提出了一種根據人體運動指標(如幅度、速度和流動性) 識別情緒的方法,通過圖像序列和測試運動指標建立情緒模型。Saha等[9]使用Kinect傳感器獲得人體骨架數據,選取與上肢相關的11個關節,提取不同關節間的距離、角度、加速度共9個特征,并比較了集成決策樹、k近鄰、神經網絡等分類器的分類效果。Shen等[10]用深度神經網絡進行了一個探索性實驗,從80個志愿者身上捕獲了43 200個簡單姿態的RGB視頻,分別使用TSN[11]和ST-GCN[12]提取RGB特征和骨架特征,并取得一定的改進。目前在行為分類或通過人的行為推斷情感上已有一定研究,主要表現在數據集的建立和分類算法上。實際上大量的人體日常行為并不能反映明顯的人體狀態或情感信息(比如站立、行走、喝水,只是日常行為,并不攜帶情感信息),而那些攜帶人體狀態或情感信息的行為(如咳嗽、跌倒、打噴嚏等)研究的相關文獻報道很少。這些行為中蘊含信息豐富,應是重點研究對象。本文以家居場景下實時監控視頻數據為研究對象,從NTU RGB+D 120數據集[13]中篩選帶有人體狀態的樣本構建成人體狀態相關數據集,鑒于樣本量少而特征維度過高,因此將RGB原始圖像視頻相鄰幀做減法運算,得到RGB差分圖像作為輸入以減少冗余,鑒于樣本少使用常規大型網絡容易過擬合,因此采用MobileNetV2輕量級網絡進行訓練,實現人體狀態的快速有效識別。
1 方法
1.1 整體框架
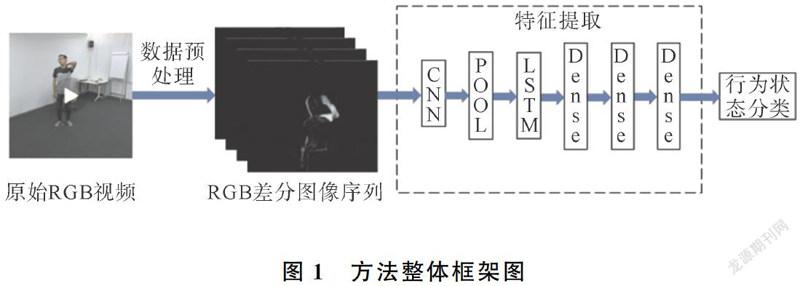
本文整體框架如圖1。具體描述如下:
Step 1:對原始的RGB視頻數據進行一系列預處理操作之后,通過前后幀相減獲得RGB差分圖像;
Step 2:以連續的RGB差分圖像序列作為輸入,采用MobileNetV2模型提取特征;
Step 3:對輸入的行為狀態進行分類。
1.2 RGB差分圖像
對于原始RGB圖像序列,通過前后幀對應像素值相減,得到RGB差分圖像序列。目的是削弱圖像的相似部分,突出顯示圖像的變化部分,極大減少特征冗余,為后續模型提供精簡特征輸入。
本文截取了幾幀真實環境下的RGB視頻原始圖像及RGB差分圖像,如圖2。可知,在人體運動狀態明顯的區域,RGB差分圖像都能夠很好的以白色區域的形式表征出來。這是因為單幀的RGB圖像只能顯示出人體靜態外觀,缺少表征前后幀的上下文信息。而RGB差分圖像,通過前后幀相減操作,可以減除無關的背景,有效保留兩個連續幀之間的外觀變化信息。
1.3 深度可分離卷積網絡
從2016年開始,神經網絡的輕量級模型取得較大進展。研究者們分別提出了SqueezeNet[14]、ShuffleNet[15]、NasNet[16]以及MobileNet系列等輕量級網絡模型。這些模型使移動終端、嵌入式設備運行神經網絡模型成為可能。而MobileNetV2[17]網絡在輕量級神經網絡中具有較高的應用。由于MobileNetV2獨特的卷積方式以及內部結構優化,比經典的大型網絡擁有更小的體積、更少的計算量以及較高的準確率,可在移動終端實現目標檢測、目標分類、動作識別和人臉識別等應用。
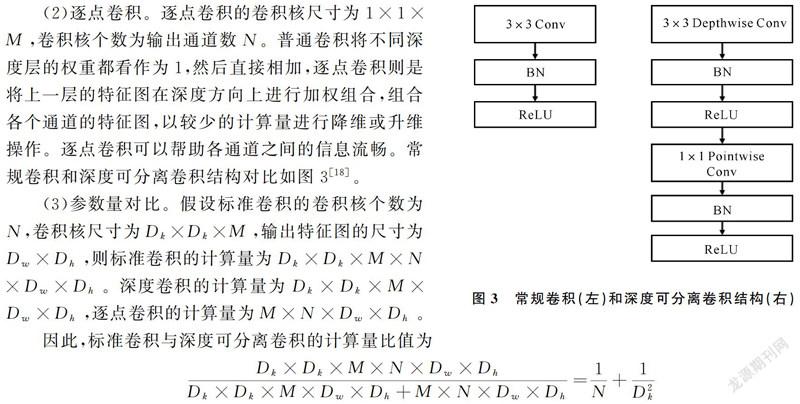
MobileNetV2使用了深度可分離卷積(Depthwise Separable Convolution)。與標準卷積結構不同,深度可分離卷積是一種特別的卷積結構,將標準卷積分解為深度卷積(Depthwise Convolution)和逐點卷積(Pointwise Convolution)兩個步驟,且每一層卷積之后都緊跟著批規范化和ReLU激活函數。
1.4 模型比較
相對于VGG-16、InceptionV3等大型經典網絡,本模型需要訓練的參數量大幅減少;與GoogleNet、MobileNetV1相比,其參數量處于同一數量級且依然少于兩模型。鑒于模型在參數量的明顯優勢,當樣本量較小時使用該模型可有效避免過擬合。
(1)深度卷積。深度卷積的卷積核尺寸為Dk×Dk×1,卷積核個數與輸入數據的通道數M相對應。在常規卷積中,每個卷積核的維度與輸入維度相同,每個通道單獨做卷積運算再相加;深度卷積時,深度卷積核的維度為1,相當于將常規卷積核拆分成為M個具有單通道形式的卷積核,各個通道獨立進行卷積運算無相加操作,可有效降低參數量的同時,也導致通道之間的信息不流暢。因此需要逐點卷積來完成卷積后的相加操作以整合不同通道的信息。
(2)逐點卷積。逐點卷積的卷積核尺寸為1×1×M,卷積核個數為輸出通道數N。普通卷積將不同深度層的權重都看作為1,然后直接相加,逐點卷積則是將上一層的特征圖在深度方向上進行加權組合,組合各個通道的特征圖,以較少的計算量進行降維或升維操作。逐點卷積可以幫助各通道之間的信息流暢。常規卷積和深度可分離卷積結構對比如圖3[18]。
(3)參數量對比。假設標準卷積的卷積核個數為N,卷積核尺寸為Dk×Dk×M,輸出特征圖的尺寸為Dw×Dh,則標準卷積的計算量為Dk×Dk×M×N×Dw×Dh。深度卷積的計算量為Dk×Dk×M×Dw×Dh,逐點卷積的計算量為M×N×Dw×Dh。
因此,標準卷積與深度可分離卷積的計算量比值為
實際應用中,卷積核的個數N較大,通常所使用的是3×3的卷積核,即Dk=3時,計算量會下降到原來的1/9~1/8。同時,MobileNetV2網絡還引入了線性瓶頸層和反向殘差結構,能夠進一步減少參數量,在空間和時間上同時優化網絡。
2 實驗
2.1 數據集及預處理
NTU RGB+D 120數據集[13]是在NTU RGB+D 數據集[19]的基礎上擴展得到的,樣本規模由原來的60個類和56 800個視頻樣本擴展為120個類和114 480個樣本。這兩個數據集都包含每個樣本的 RGB 視頻、深度圖序列、3D骨骼數據和紅外視頻4種數據模態。NTU RGB+D 120數據集包括日常行為、醫療相關行為和交互行為三大類。數據集所包含的大量日常動作(如喝水、站立等)并不具有明顯的情感傾向或意圖,從中篩選了9個與醫療相關的部分行為狀態作為研究對象,所選樣本視頻共432個,其中75%作為訓練樣本,25%作為測試樣本。分別為:咳嗽、搖晃、跌倒、頭痛、打哈欠、背痛、脖子痛、嘔吐、扇扇子。從數據庫中截取的幾類視頻示例如圖4所示。
考慮到數據樣本較少,為增加訓練的數據量,防止過擬合,提高模型的泛化能力,可以使用數據增強方法來擴充數據量。選擇旋轉、平移、水平翻轉、縮放4種增強方式,對于每幀圖像隨機選擇2~4種增強方式。由于RGB圖像的像素值在0~255之間,本文對圖像進行歸一化處理,使圖像的像素值轉化為 0~1 之間分布的數據。通過歸一化的方法,可以有效防止仿射變換的影響,減小集合變換的影響,同時加快梯度下降求最優解的速度。
2.2 結果與分析
實驗使用的CNN是MobileNetV2網絡,其權值已在ImageNet預訓練。輸入MobileNetV2網絡的數據維度為(8,224,224,3),即每個視頻隨機選取8幀,每幀圖像的像素值為224×224,通道數為3。從MobileNetV2網絡輸出的數據經過平均池化,再輸入LSTM,其后面又添加3個全連接層(dense層),每層節點個數分別是64、24、9,每層的dropout值為0.5。最后一層使用softmax函數分類并輸出結果。
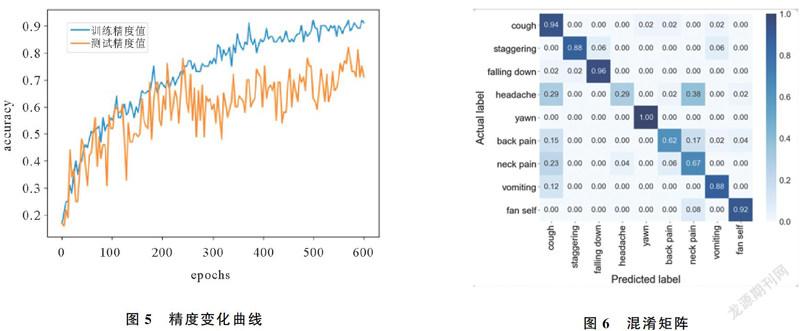
本模型在網絡訓練過程中,使用隨機梯度下降算法和交叉熵損失函數,以精度作為衡量指標。實驗采用TensorFlow框架,Python3.6版本,在配有Geforce RTX 2060的Windows10系統上運行。batch-size設置為4,epoch設為600。最終平均測試精度達到80.7%,精度變化曲線和混淆矩陣分別見圖5、圖6。
由圖5可知,隨著訓練批次epoch的增加,訓練精度和測試精度都逐漸上升。當訓練批次達到350左右,訓練精度和測試精度逐漸趨于穩定,精度值分別上升至85%、75%。在訓練階段后期,訓練精度已接近90%,測試精度在80%左右。
圖6是經網絡模型預測出能反映人體狀態類別的混淆矩陣,由圖可見,打哈欠、跌倒、咳嗽、和扇扇子4類動作狀態的識別精度最好,準確率均超過90%,背痛、脖子痛兩類動作狀態的識別效果稍差,精度在70%左右;頭痛樣本的識別精度不足30%,觀察第四行可知,大量的頭痛標簽樣本被錯誤識別為咳嗽或脖子痛。由混淆矩陣第一列數據可知,識別準確率最低的三類動作有一個共同點,即在相當程度上都被錯誤識別為咳嗽。分析認為,這幾個動作基本都涉及到手部與頭部的組合動作,特征具有較高的相似性,神經網絡未能學習到動作間的細微差別,應是識別錯誤的主因;總樣本量為432,樣本量少也是導致模型未能充分挖掘特征的另一個重要原因。
根據圖7所示的咳嗽和頭痛兩種動作的圖像序列對比可以看出,這兩類動作相似程度較高,即使人眼也容易造成誤判。
3 結論
RGB差分圖像相對于RGB圖像,能更好獲得幀序列間的動態變化信息,以RGB差分圖像作為輸入,使用CNN和LSTM的動作識別方法,具體以MobileNetV2和LSTM構建網絡模型,分別提取空間信息和時間信息。并結合NTU數據集中9類有關人體狀態的動作進行識別,大部分動作的識別精度在80%以上。由于識別準確率不高的動作比較集中,主要涉及到手部與頭部等兩個身體部位的動作組合,下一步可專門對這些動作進行細致研究,并制作專門的人體狀態視頻數據集,或對本文算法進行改進,提高識別準確率。
參考文獻
[1]鄔晶晶. 基于深度學習的情緒識別技術[M].北京:中國科學院大學(中國科學院深圳先進技術研究院),2020.
[2]KLEINSMITH A, BIANCHI-BERTHOUZE N. Affective body expression perception and recognition: a survey[J]. IEEE Trans on Affective Computing, 2013, 4(1) : 15-33.
[3]ELMAN J. Encyclopedia of language and Linguistics[M]. 2nd ed. Oxford: Elsevier, 2005
[4]GELDER D. Why bodies? Twelve reasons for including bodily expressions in affective neuroscience[J]. Philosophical Transactions of the Royal Society B: Biological Sciences, 2009, 364(1535): 3475-3484.
[5]BULL P. Posture & gesture[M]. Amsterdam: Elsevier, 2016
[6]POLLICK F, PATERSON H, BRUDERLIN A, et al. Perceiving affect from arm movement[J]. Cognition, 2001, 82(2): B51-B61
[7]COULSON M. Attributing emotion to static body postures: Recognition accuracy, confusions, and viewpoint dependence[J]. Journal of Nonverbal Behavior, 2004, 28(2): 117-139
[8]CASTELLANO G, VILLALBA S, CAMURRI A. Recognising human emotions from body movement and gesture dynamics[C]// Proc. of International Conference on Affective Computing and Intelligent Interaction.Berlin,2007: 71-82.
[9]SAHA S, DATTA S, KONAR A, et al. A study on emotion recognition from body gestures using Kinect sensor[C]// 2014 International Conference on Communication and Signal Processing. Melmaruvathur, 2014: 56-60.
[10]SHEN Z, CHEN J, HU X, et al. Emotion recognition based on multi-view body gestures[C]// 2019 IEEE International Conference on Image Processing (ICIP). Taipei, 2019: 3317-3321.
[11]WANG L, XIONG Y, WANG Z, et al. Temporal segment networks for action recognition in videos[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 41(11): 2740-2755.
[12]YAN S, XIONG Y, LIN D. Spatial temporal graph convolutional networks for skeleton-based action recognition[C]// AAAI Conference on Artificial Intelligence, New Orleans, 2018:7444-7452.
[13]LIU J, SHAHROUDY A, PEREZ M, et al. NTU RGB+D 120: A large-scale benchmark for 3D human activity understanding[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2019,42(10): 2684-2701.
[14]FORREST N, SONG H, MATTHEW W, et al. Squeezenet: Alexnet-level accuracy with 50x fewer parameters and <0.5 MB model size[J/OL]. [2020-09-21]. http://arxiv.org/abs/1602.07360.
[15]ZHANG Z, ZHOU X, LIN M, et al. Shufflenet: An extremely efficient convolutional neural network for mobile devices[C]// IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City, 2018: 6848-6856.
[16]ZOPH B, VASUDEVAN V, SHLENS J, et al. Learning transferable architectures for scalable image recognition[C]// IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City, 2018: 8697-8710.
[17]SANDLER M, HOWARD A, ZHU M, et al. MobileNetV2: Inverted residuals and linear bottlenecks[C]// IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City, 2018: 4510-4520.
[18]HOWARD A, ZHU M, CHEN B, et al. MobileNets: Efficient convolutional neural networks for mobile vision applications. [J/OB] [2020-09-11].http://arxiv.org/abs/1704.04861.
[19]HOWARD A, ZHU M L, CHEN B, et al. NTU RGB+D: A large scale dataset for 3D human activity analysis[C]// IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, 2016:1010-1019.
