基于改進Faster R-CNN的自然環境下麥穗檢測方法
2021-09-13 03:41:13凌海波周先存張靜雅何富貴
赤峰學院學報·自然科學版 2021年7期
凌海波 周先存 張靜雅 何富貴


摘 要:小麥麥穗的自動檢測在產量預估、種子篩選等方面具有一定的科研應用價值。為進一步提高自然環境下麥穗識別與計數的準確性,本文提出了基于改進型Faster R-CNN深度神經網絡麥穗檢測方法。針對傳統Faster R-CNN算法應用于麥穗檢測時存在漏檢的問題,并結合自然環境下麥穗重疊和遮擋的特點,本研究采用加權框融合(Weighted Boxes Fusion,WBF)算法代替原有的非極大值抑制(NMS)算法,通過區域建議網絡產生的所有預測框的置信度來構造融合框。試驗證明,改進后的Faster R-CNN在全球麥穗檢測數據集上的平均精度均值mAP0.5:0.75、mAP0.5分別達到了74.21%和92.15%,相較于傳統Faster R-CNN提升了5.75%和3.74%,提升效果明顯,減少了麥穗漏檢的情況,能夠在自然環境下對麥穗進行計數和產量預估。
關鍵詞:麥穗檢測;深度神經網絡;區域建議網絡;加權框融合
中圖分類號:TP391.41 ?文獻標識碼:A ?文章編號:1673-260X(2021)07-0017-05
1 引言
小麥是世界上最重要的糧食作物,在全世界廣泛種植。小麥產量的穩定在全球糧食安全中起著至關重要的作用,準確的小麥麥穗計數是小麥產量精確估計的重要依據[1]。傳統的人工肉眼計數的方式效率不高,主觀性較強,實用性一般,計數周期長,并且缺乏統一的統計標準。目前麥穗自動檢測主要是基于機器視覺的方法進行研究。利用小麥的RGB圖獲取麥穗的顏色、形狀等特征,通過計算機視覺方法構建小麥麥穗識別分類器,以實現對麥穗檢測和計數[2,3]。Fernandez-Gallego等[4]使用濾波和尋找最大值的方法來檢測田間小麥穗圖像中的麥穗數,其識別精度達到90%。Li等[5]在試驗室的環境下提出使用特征參數,利用小麥穗圖像中穗頭的顏色和質地等特征,結合神經網絡來檢測麥穗,其檢測精度約為80%。李毅念等[6]通過特定裝置獲取田間麥穗群體圖像,利用基于凹點檢測匹配連線方法分割得到麥穗數量,其識別精度為91.6%。杜世偉等[7]使用拋物線方法將單個小麥中的所有穗部分開,獲得穗數,其識別精度為97.01%。范夢揚等[8]在現有研究的基礎上,使用支持向量機學習方法準確地提取麥穗的輪廓,同時構建麥穗特征數據庫來對麥穗進行計數,其平均識別精度達到93%。
近些年隨著人工智能的快速發展,深度學習成為當前研究的熱點,其中,基于卷積神經網絡的目標檢測方法廣泛應用于計算機視覺領域。在植物器官計數[9,10]、雜草識別[11,12]、植物識別及物種分類[13]等農業領域均有廣泛的應用。在小麥麥穗檢測方面,澳大利亞Hasan等采用R-CNN深度神經網絡對采集到自然環境下的10類25000左右小麥麥穗的進行訓練,其模型平均識別精度達到93.4%;張領先等[14]利用卷積神經網絡建立麥穗識別模型,通過依靠經驗設定固定滑窗尺寸,但檢測出的麥穗效果不佳。REZA M N[15]分別提出利用不同的深度學習網絡結構實現對自然場景下的小麥麥穗計數的方法。高云鵬[16]采用Mask R-CNN算法實現自然場景下的小麥麥穗計數的方法,其準確率分別達到87.12%和97%。
現有的研究成果大多以各自較少的試驗數據為對象建立了麥穗檢測模型,由于對不同的栽培條件、品種沒有通用性,因此難以擴大規模。本研究以全球麥穗檢測數據集(Global Wheat Head Detection,GWHD)為研究對象,結合自然環境下麥穗檢測的特點,針對傳統Faster R-CNN算法的不足,提出了改進的Faster R-CNN麥穗檢測算法,將傳統Faster R-CNN中NMS算法替換為WBF算法,可有效地減少遮擋麥穗漏檢的情況,提高小麥麥穗的檢測精度。
2 Faster R-CNN目標檢測
Faster R-CNN是一個端到端的深度學習目標檢測算法,其網絡結構如圖1所示,包括特征提取網絡、區域建議網絡和區域卷積神經網絡。
2.1 特征提取網絡
本研究選取殘差結構卷積神經網絡ResNet 101作為特征提取網絡的基礎網絡,如圖2所示為基于ResNet101[17]的Faster R-CNN。圖中ResNet101包括Conv1、Conv2_x、Conv3_x、Conv4_x和Conv5_x, ResNet101的Conv4_x的輸出為RPN和感興趣區域池化層(Region of Interest,RoI Pooling)共享的部分,RoI Pooling輸出經過Conv5_x得到2048維特征,分別用于分類和回歸。
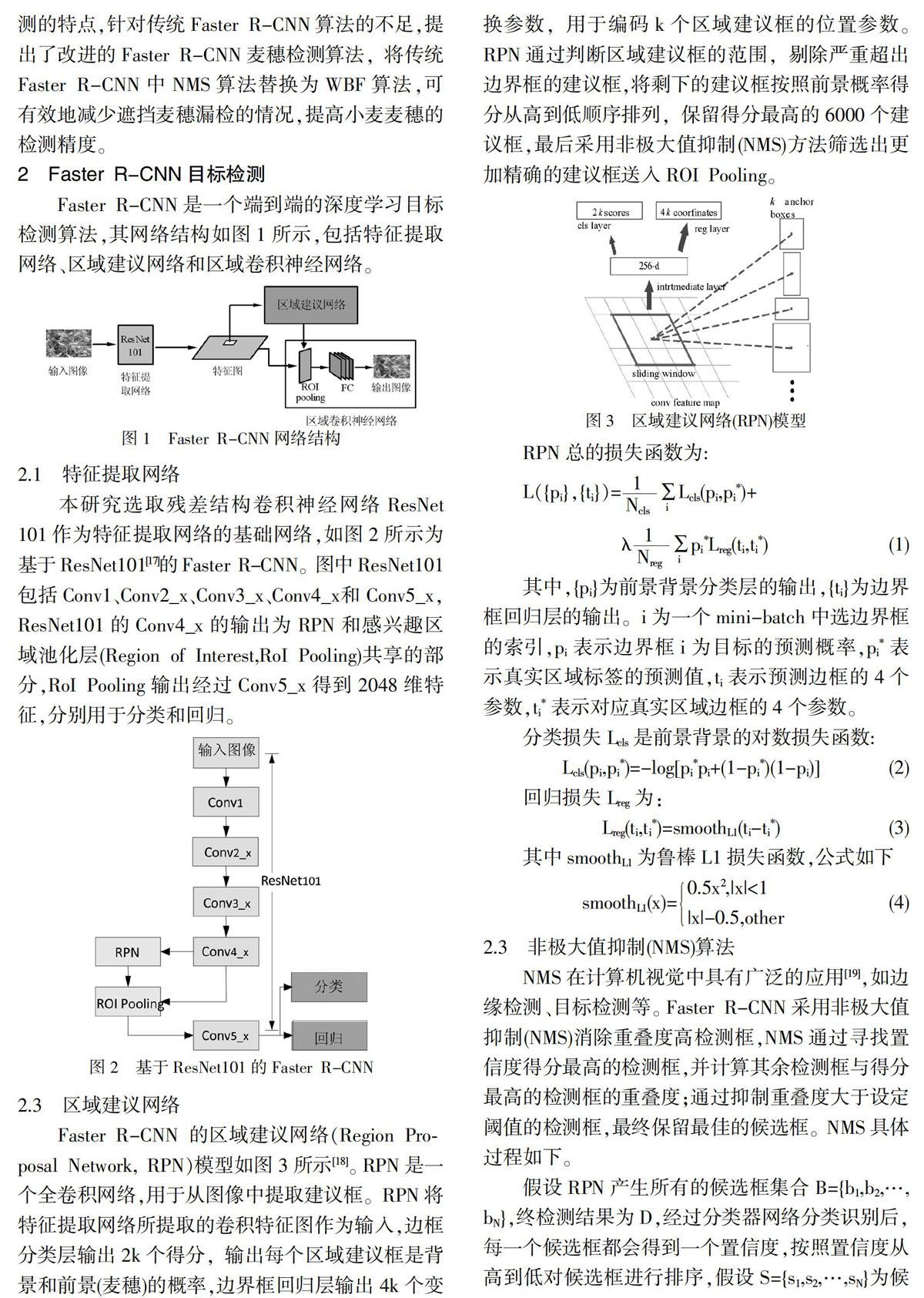
2.3 區域建議網絡
Faster R-CNN 的區域建議網絡(Region Proposal Network, RPN)模型如圖3所示[18]。RPN是一個全卷積網絡,用于從圖像中提取建議框。RPN將特征提取網絡所提取的卷積特征圖作為輸入,邊框分類層輸出2k個得分,輸出每個區域建議框是背景和前景(麥穗)的概率,邊界框回歸層輸出4k個變換參數,用于編碼k個區域建議框的位置參數。RPN通過判斷區域建議框的范圍,剔除嚴重超出邊界框的建議框,將剩下的建議框按照前景概率得分從高到低順序排列,保留得分最高的6000個建議框,最后采用非極大值抑制(NMS)方法篩選出更加精確的建議框送入ROI Pooling。
RPN總的損失函數為:
其中,{pi}為前景背景分類層的輸出,{ti}為邊界框回歸層的輸出。i為一個mini-batch中選邊界框的索引,pi表示邊界框i為目標的預測概率,pi*表示真實區域標簽的預測值,ti表示預測邊框的4個參數,ti*表示對應真實區域邊框的4個參數。
分類損失Lcls是前景背景的對數損失函數:
Lcls(pi,pi*)=-log[pi*pi+(1-pi*)(1-pi)] ?(2)
回歸損失Lreg為:
Lreg(ti,ti*)=smoothL1(ti-ti*) ?(3)
其中smoothL1為魯棒L1損失函數,公式如下
smoothL1(x)=0.5x2,|x|<1|x|-0.5,other ?(4)
2.3 非極大值抑制(NMS)算法
NMS在計算機視覺中具有廣泛的應用[19],如邊緣檢測、目標檢測等。Faster R-CNN采用非極大值抑制(NMS)消除重疊度高檢測框,NMS通過尋找置信度得分最高的檢測框,并計算其余檢測框與得分最高的檢測框的重疊度;通過抑制重疊度大于設定閾值的檢測框,最終保留最佳的候選框。NMS具體過程如下。
假設RPN產生所有的候選框集合B={b1,b2,…,bN},終檢測結果為D,經過分類器網絡分類識別后,每一個候選框都會得到一個置信度,按照置信度從高到低對候選框進行排序,假設S={s1,s2,…,sN}為候選框B所對應的置信度列表,選擇置信度最高分的檢測框M,將M從B集合中移除,加入最終的檢測結果D中。然后遍歷B中剩余的候選框,判斷B中剩余的檢測框與M的重疊度IoU(Intersection over Union,IoU),IoU為兩個區域相交部分與兩個區域的相并部分的比值,判斷IoU是否大于某個設定的閾值t,按照公式(5)函數計算,該函數衰減與最高置信度檢測框M有重疊的相鄰檢測框分數,與檢測框M高度重疊的檢測框,其得分衰減越嚴重,將大于閾值t的候選框從B中剔除,從中再次選擇置信度最高的候選框加入檢測結果D中,重復該過程直至B集合為空,此時檢測結果D中即為最終保留的候選框。
si=si,iou(M,bi) 其中si=sie,即將當前檢測框置信度si乘以一個高斯權重函數,M為置信度最高的檢測框,t為IoU閾值。 2.4 soft-NMS算法 文獻[20]對NMS進行了優化,提出了soft-NMS算法,soft-NMS不是完全刪除具有高重疊度和高置信度的檢測框,而是根據IoU重疊按比例降低置信分數,按照公式(6)的函數降低其置信度,使更多的檢測框被保留下來,從而將重疊的物體被更大程度檢測出來。 si=si, ? ? ?iou(M,bi) 其中si=sie,M為置信度最高的檢測框,t為IoU閾值。 3 改進Faster R-CNN Faster R-CNN的區域建議網絡生成大量的檢測框并且重疊度非常高,本研究對原始FasterR-CNN的區域建議網絡進行優化,采用WBF算法代替原有的NMS算法,與簡單地刪除部分預測框的NMS和soft-NMS方法不同,WBF算法使用所有預測邊界框的置信度得分來構造平均框,將所有的檢測框進行加權融合。具體過程如下: 設有N個不同模型對同一圖像邊界框預測, (1)將每個模型的每個預測框按照置信度得分 從高到低添加到列表W中。 (2)建立兩個空列表L和F,列表L中的每個位置包含一組檢測框(或單個檢測框),這些檢測框形成一個簇,列表F中的每個位置僅包含一個檢測框,該檢測框為列表L中相應簇的融合框。 (3)循環遍歷列表W中的檢測框,在列表Y中尋找與檢測框重疊度IoU>thr匹配的檢測框。 (4)如果找不到匹配檢測框,則將列表W中當前的檢測框添加到列表L和F的末尾作為新條目,然后轉到列表W中的下一個檢測框;如果找到匹配檢測框,則將此檢測框加入列表L中,加入的位置是該檢測框在列表F匹配框相對應的位置index。 (5)根據列表L[index]中添加的所有T個檢測框,更新L[index]中的置信度得分和檢測框坐標,將融合框的置信度設置為形成它的所有框的平均置信度,融合框的坐標是構成它的框的坐標的加權總和,其中權重是相應框的置信度得分,計算公式如公式(7)—公式(9)。 其中,C為融合框的置信度,Ci為列表L[index]中每個檢測框的置信度,X1、X2、Y1、Y2為更新后L[index]中融合框的坐標。因此,具有較高置信度的框比具有較低置信度的框對融合框坐標的貢獻更大。 遍歷完成W中的所有檢測框之后,對列表F中的置信度得分再進行一次調整,調整方法通過公式(10)方式完成,減少某些檢測框只被少數模型預測到的置信值。 4 試驗結果與分析 4.1 試驗數據集與試驗環境 試驗數據集采用全球麥穗檢測數據集(Global Wheat Head Detection, GWHD),該數據集包含4698張帶有標簽的小麥麥穗圖像,每張圖像含有20-60個麥穗,共包含188445個標記過的麥穗頭。其中來自歐洲和北美的3422張圖像作為訓練數據,驗證數據來自中國、澳大利亞和日本的1276張圖像,數據集圖像尺寸為1024×1024像素。 本次試驗操作平臺為臺式計算機,運行環境為Ubuntu 18.04,處理器為Intel Corei9-9900K,主屏為4.4GHZ,16G運行內存,顯卡為NVIDIA GeForceGTX2080TI,運行顯存為11G,搭建Pytorch深度學習框架,實現小麥麥穗目標識別網絡模型的訓練與測試。 4.2 試驗結果分析 為了評價模型對麥穗檢測的效果,評價指標選用在全球麥穗檢測數據集上的平均精度均值(mean Average Precision,mAP)評估模型,通過公式(11)、公式(12)計算出每個IoU閾值處的精度值的平均值來獲得單個圖像的平均精度,最終獲取測試數據集中所有圖像的平均精度均值,如公式(13)所示。 其中,t為閾值,N為測試數據集圖像的個數,APj表示第j張圖像的平均精度,TP(True Positives):正樣本被正確識別為正樣本,FP(False Positives):負樣本被錯誤識別為正樣本,FN(False Negatives):正樣本被錯誤識別為負樣本;本試驗中TP表示正確檢測出麥穗;FP表示被誤檢的麥穗或者對同一麥穗進行多重檢測,FN表示沒有被檢測出來的麥穗或者在同一目標框內模型檢測出多個麥穗。 試驗采用殘差結構卷積神經網絡ResNet101作為特征提取網絡,利用COCO數據集的預訓練模型進行初始化參數,設置輸入圖像大小設置為512×512像素,訓練模型的優化器選擇隨機梯度下降(SGD)算法,學習率lr設置為0.00349,動量因子momentum設置為0.9,權值衰減weight_decay設置為0.0004,batch_size=16。在全球麥穗檢測數據集的測試數據集上分別采用NMS、soft-NMS和WBF算法進行試驗預測,針對不同的交并比閾值計算出平均精度均值。試驗分別選取IoU閾值范圍從0.5到0.75,步長為0.05和IoU閾值為0.5的平均精度均值,測試結果如表1所示。 由表1可知,采用soft-NMS模型比原始NMS模型的平均精度均值mAP0.5:0.75、mAP0.5分別提高了3.87%和2.02%;采用WBF改進后模型的平均精度均值mAP0.5:0.75、mAP0.5由原始的68.46%、88.41%提升到74.21%和92.15%,提升幅度分別達到5.75%和3.74%,提升效果顯著。改進前后的小麥麥穗檢測結果對比圖如圖4所示,其中圖4(I)中a、b、c為傳統Faster R-CNN模型檢測結果,圖5(II)中d、e、f為WBF改進后模型檢測結果。可以看出,傳統Faster R-CNN對于重疊或遮擋的麥穗存在很多漏檢的現象,而改進后的Faster R-CNN檢測效果改善明顯。 5 結束語 本研究以全球麥穗檢測數據集(Global Wheat Head Detection,GWHD)為研究對象,研究了基于改進Faster R-CNN深度神經網絡小麥麥穗檢測方法,以實現自動麥穗計數的目的。通過對三種網絡檢測效果對比分析,發現采用加權框融合框改進后的Faster R-CNN模型在全球麥穗檢測數據集上的模型性能最佳,在測試數據集上模型mAP0.5:0.75、mAP0.5分別達到74.21%和92.15%,與NMS模型、soft-NMS模型相比,麥穗檢測效果提升顯著,減少了遮擋麥穗漏檢的情況,提高了小麥麥穗的檢測精度,為小麥產量的精準估計奠定基礎。 參考文獻: 〔1〕李向東,呂風榮,張德奇,等.小麥田間測產和實際產量轉換系數實證研究[J].麥類作物學報,2016, 36(01):69-76. 〔2〕趙鋒,王克儉,苑迎春.基于顏色特征和AdaBoost算法的麥穗識別的研究[J].作物雜志,2014,30(01):141-144. 〔3〕劉濤,孫成明,王力堅,等.基于圖像處理技術的大田麥穗計數[J].農業機械學報,2014,45(02):282-290. 〔4〕Fernandez-Gallego J A, Kefauver S C, Gutiérrez N A, et al. Wheat ear counting in-field conditions: High throughput and low-cost approach using RGB images[J]. Plant Methods, 2018, 14(01): 1-12. 〔5〕Li Q Y, Cai J, Berger B, et al. Detecting spikes of wheat plants using neural networks with laws texture energy[J]. Plant Methods, 2017, 13(01): 1-13. 〔6〕李毅念,杜世偉,姚敏,等.基于小麥群體圖像的田間麥穗計數及產量預測方法[J].農業工程學報,2018,34(21):185-194. 〔7〕杜世偉,李毅念,姚敏,等.基于小麥穗部小穗圖像分割的籽粒計數方法[J].南京農業大學學報,2018,41(04):742-751. 〔8〕范夢揚,馬欽,劉峻明,等.基于機器視覺的大田環境小麥麥穗計數方法[J].農業機械學報,2015, 46(04):234-239. 〔9〕周云成,許童羽,鄭偉,等.基于深度卷積神經網絡的番茄主要器官分類識別方法[J].農業工程學報,2017,33(15):219-226. 〔10〕高震宇,王安,劉勇,等.基于卷積神經網絡的鮮茶葉智能分選系統研究[J].農業機械學報,2017,48(07):53-58. 〔11〕TANG J, WANG D, ZHANG Z, et al. Weed identification based on K-means feature learning combined with convolutional neural network[J]. Computers and Electronics in Agriculture,2017,135: 63-70. 〔12〕FERREIRA A D S, FREITAS D M, SILVA G G D, et al. Weed detection in soybean crops using ConvNets[J]. Computers and Electronics in Agriculture, 2017,143: 314-324. 〔13〕GHAZI M M, YANIKOGLU B, APTOULA E. Plant identification using deep neural networks via optimization of transfer learning parameter[J]. Neurocomputing, 2017, 235: 228 - 235. 〔14〕張領先,陳運強,李云霞,等.基于卷積神經網絡的冬小麥麥穗檢測計數系統[J].農業機械學報,2019,50(03):144-150. 〔15〕REZA M N, NA I S,LEE K H. Automatic counting of rice plant numbers after transplanting using lowaltitude UAV images[J]. International Journal of Contents, 2017,13(03):1-8. 〔16〕高云鵬.基于深度神經網絡的大田小麥麥穗檢測方法研究[D].北京林業大學,2019. 〔17〕Kaiming He, X. Zhang, Shaoqing Ren. Deep Residual Learning for Image Recognition[C].// 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 〔18〕REN S, HE K, GIRSHICK R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[C]//Inter?螄national Conference on Neural Information Processing Systems.Cambridge:MIT,2015:91- 99. 〔19〕HOSANG J, BENENSON R, SCHIELE B. Learning non-maximum suppression[C]∥ IEEE Conference on Computer Vision &Pattern Recognition, 2017: 6469-6477. 〔20〕N Bodla, B Singh, et al. Soft-NMS:Improving Object Detection With One Line of Code[C],//2017 IEEE International Conference on Computer Vision (ICCV).
