基于大數據的電力企業財務數據分析系統建設
2021-09-18 08:36:08王森,劉麗
中國管理信息化 2021年14期
王 森,劉 麗
(云南電網有限責任公司麗江供電局,云南 麗江 674100)
0 引言
伴隨著信息技術的進步和大數據時代的到來,電力企業在財務管理的過程中需要處理的數據范圍愈加廣泛,同時面臨著日益加劇的數據龐雜冗余、垃圾數據過多、數據重復錄入、信息交流缺乏一致性等難題。此外,在保持數據完整性的同時對數據格式進行轉換,更是電力企業在進行財務數據處理時面臨的重要挑戰。由于電力企業的相關財務數據龐大復雜,且財務處理中往往涉及百余個參數,難以采用傳統方式對其加以度量,因此建立統一的、具有高度整合性的信息數據處理系統十分必要。
1 基于大數據的電力企業財務數據分析系統的層次結構
按照數據處理順序,可以將電力企業的財務大數據分析系統分為3 個層次,分別是數據存儲、數據預處理以及構建動態財務共享數據分析中心。其中,數據存儲能夠保證數據完整保留,數據處理能夠確保數據時效性,而動態數據分析體系能夠充分挖掘數據價值[1]。三者合為一體,能夠讓大數據的價值體現得更為完整和貼切。針對來自國家電網大數據中心以及外部數據源的大數據,文章分別從源數據層面、數據存儲層面、數據預處理層面以及數據分析層面分析財務數據分析系統的構建工作。在財務數據分析系統的整體技術框架中,主要以NoSQL 以及Hadoop 為基礎,對數據進行大數據預處理以及分析,將傳統的財務數據轉化為全數據并進行高性能的交互式分析,最終完成對財務大數據的分析[2]。具體技術框架如圖1 所示。
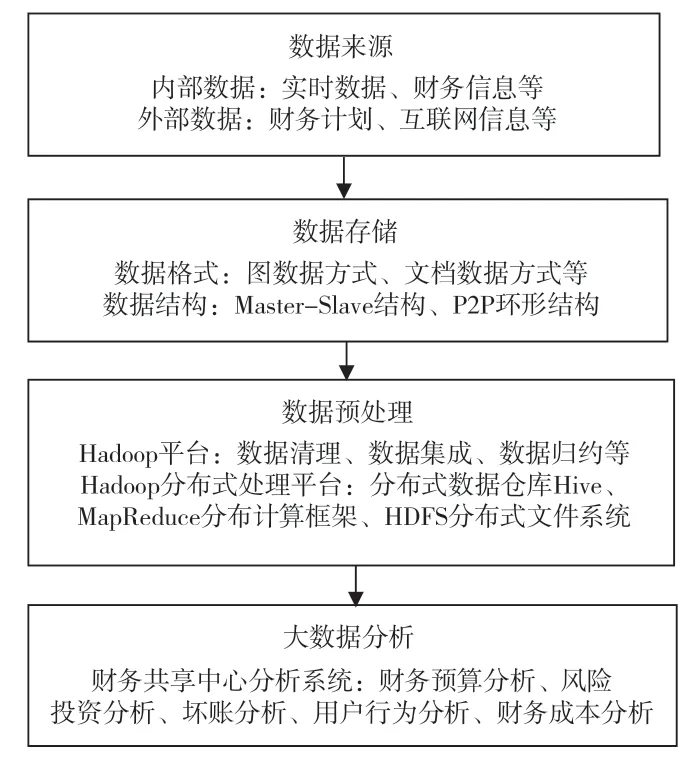
圖1 財務數據分析系統技術框架
2 電力企業財務數據分析系統的建設步驟
2.1 基于NoSQL 進行大數據存儲層面管理
面對海量財務信息數據,NoSQL 存儲體系能夠完整實現對電力企業財務信息的存儲以及全方位柔性管理。在數據存儲層面主要的儲存方式有3 種,分別是NoSQL 數據庫、關系型數據庫以及HDFS 分布式文件系統[3]。在存儲形式的分類上,NoSQL 以非關系型以及分布式數據存儲的方式實現海量數據的存儲,并以圖數據、Key-Value 以及面向文檔數據格式進行存儲,從而在高速的讀寫性能以及優越的查詢性能之上實現更高彈性的數據擴展能力。
NoSQL 的數據存儲系統包括Master-Slave 以及P2P 環形結構兩種。其中,Master-Slave 可控性好,且設計結構簡單,往往以水平分區為基礎實現數據分布。分開Master 節點與Slave節點之間的功能,可以將節點的功能負載減輕,并由Master 節點對Slave 節點進行維護和管理。其缺點是Master 中心的節點容易成為系統中的瓶頸。P2P 的環形結構系統則不存在中心節點,因此各個節點平等,以Hash 數據分布為基礎,具有協調性好、便于擴展等優點。P2P 環形結構有著更好的負載均衡性,但設計系統更為復雜,且不利于范圍查詢,可控性不強。上述兩種體系結構差別較大,各具一定的功能局限性。因此,在電力體系中,需要將P2P 的分布式結構以及Master-Slave 的集中式結構的優點相結合構成相應的數據存儲體系。常見的組合方式有Master-Slave 與Chord 的結合或是與Content-Addressable Network 的結合,從而確保數據存儲能夠兼顧全局性和局部性[4-5]。
2.2 基于Hadoop 進行財務數據預處理
Hadoop 是一種開源的大規模分布式計算框架,優點是可靠、高效并且可伸縮,因此被廣泛應用在大數據處理領域。技術人員可以以Hadoop 以及現有的電網財務體系為基礎,建立新的財務大數據預處理體系模型,結合Hadoop、HBase 以及Hive 在財務數據預處理平臺中對數據進行清洗、集成和歸約。利用噪聲處理,對缺失數據加以填補以及簡化數據屬性維度的關系來完成財務數據的預處理。這種方式利用Hadoop 平臺的特點,對需要進行預處理的任務添加監控與控制節點,每個節點都對應一個需要進行預處理的任務或是任務列表,針對該項任務,啟動對應的處理程序以及相關規則。具體的處理程序如圖2 所示。
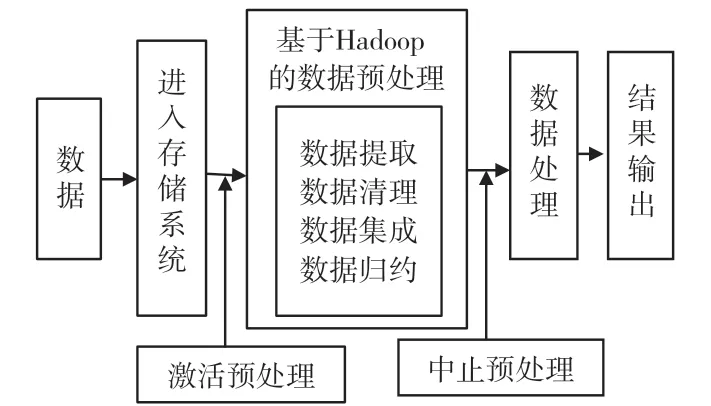
圖2 財務大數據預處理體系流程圖
2.3 基于Hadoop 建立分析集群對財務大數據進行分析
基于Hadoop 對財務數據加以預處理后,從現有的財務分析體系的局限出發,完善缺點,建立適合現行財務需要的財務分析系統并對財務數據進行分析。大數據分析體系的關注重點在于實現對財務管理過程的監督以及相關財務指標的分析,諸如項目預算分析、成本分析以及風險分析等內容。為了更好地實現財務分析效果,首先可從管理層面對電力企業的財務現狀加以調研,分析其中存在的財務管理難點諸如利潤報表、管理金額等。其次,在技術層面,結合傳統數據庫以及新商業智能的優點,對財務管理系統加以整合。針對電力企業的經營特點和財務特點,以大數據思想為基礎,對現有數據進行有效的存儲和分析,同時利用聚類算法抽取數據特征,挖掘數據價值。具體的財務大數據分析流程如圖3 所示。
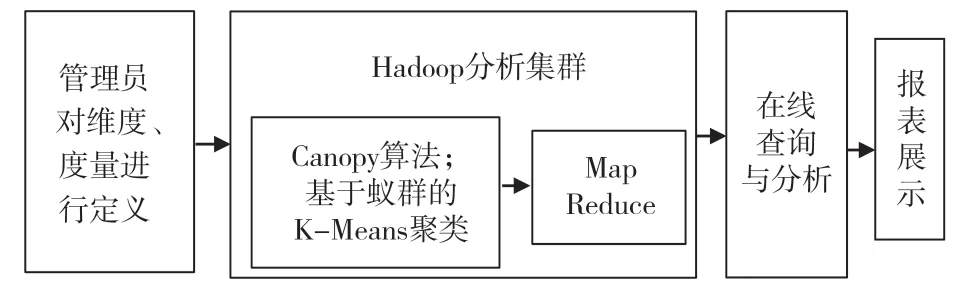
圖3 基于Hadoop 的財務大數據分析流程圖
3 針對財務數據分析系統建立評價指標體系
構建電力企業大數據分析系統后,需要對其功能需求加以分類,并選擇科學的評價指標對需求等級進行排序,從而便于系統后續的優化。文章選用自組織映射(Self-Organizing Map,SOM)神經網絡算法對系統中的數據樣本進行劃分,具體流程如下。
3.1 網絡初始化
利用集合Sj表示有j個輸出神經元,并用較小的權重設置輸入神經元到輸出神經元的連接。當t=0,j個神經元的臨近神經元表示為Sj(0);t時刻表示為Sj(t),隨著時間的推移,Sj(0)逐漸減小。
3.2 輸入向量
從集合中選擇輸入值,并對輸入值進行歸一化處理,輸入向量用X來表示,并輸入:

3.3 計算歐式距離
對所輸入的向量以及各個神經元間的權值歐式距離進行計算。計算方式如下:
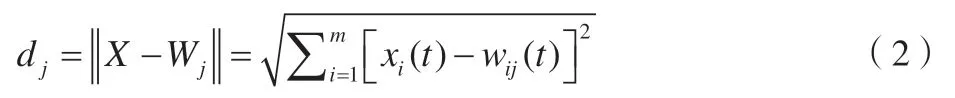
其中,Wij表示在輸入層的i神經元以及映射層中j神經元間的權重。將歐式距離最小的神經元標記為獲勝神經元j*,并輸出臨近的神經元的集合。
3.4 修正權值
參照式(3),對輸出神經元以及其附近的權值進行修正。
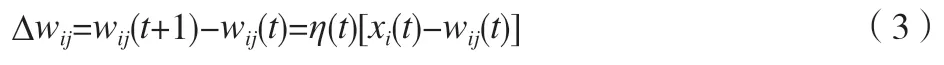
其中,η為學習率,是常數,且η∈[0,1],隨著時間推移,η逐漸趨于0。
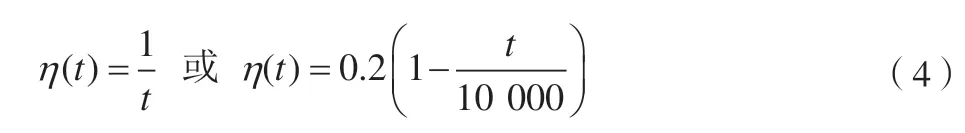
3.5 計算輸出
輸出Ok為:

智能化背景下的電力企業財務管理需要以大數據為基礎建立大數據分析系統,對不同數據的需求進行動態評價并及時根據不同類型數據的需求重要程度及時調整權重,這是優化數據分析系統、提升財務管理效率的關鍵。
4 結語
伴隨著智能電網的深入建設與推動,電力企業業務系統和數據中心的數據愈發龐雜,科學的分析能力、快速的計算速度等影響著電力企業的財務管理效率。加強建設電力企業的財務數據分析系統,不僅能夠從龐雜的數據中篩查出有效、有用信息,還能幫助電力企業提升財務管理水平,有效規避財務風險。
猜你喜歡
現代企業(2021年2期)2021-07-20 07:57:18
河南水利年鑒(2020年0期)2020-06-09 05:43:36
現代經濟信息(2020年34期)2020-06-08 06:02:40
意林·全彩Color(2019年9期)2019-10-17 02:25:48
消費導刊(2018年10期)2018-08-20 02:57:10
消費導刊(2018年8期)2018-05-25 13:20:09
能源(2017年9期)2017-10-18 00:48:25
河南水利年鑒(2017年0期)2017-05-19 02:29:27
通信電源技術(2016年6期)2016-04-20 06:21:48
行政事業資產與財務(2015年23期)2015-10-26 03:13:26
