一種基于梯度提升的云安全機器學習算法
2021-09-22 01:34:40賈布里莫騰飛武永成
科技創新導報 2021年16期
關鍵詞:機器學習
賈布里 莫騰飛 武永成


摘? 要:近年來,云計算技術飛速發展,許多企業和機構將自己的業務遷移到云上,這樣不僅降低費用,還能提高效率。但隨之而來的是云服務提供者和用戶被大量的惡意軟件攻擊。許多機器學習算法通過對云平臺上可能發生的行為進行預測,來保護云系統不受攻擊,取得了不錯的效果。但當所學習的數據集較大和稀疏時,這些機器學習算法效果不是很好。本文采用了一種梯度提升的決策樹算法,能對云計算系統上的惡意軟件攻擊進行更準確的預測。實驗驗證了本方法的有效性。
關鍵詞:云計算安全? 機器學習? 梯度? 下采樣? 決策樹算法
中圖分類號:TP391? ? ? ? ? ? ? ? ? ? ? ? ? ?文獻標識碼:A? ? ? ? ? ? ? ? ?文章編號:1674-098X(2021)06(a)-0072-04
A Gradient Boosting Machine Learning Algorithm for Cloud Security
Gabriel? MO Tengfei? WU Yongcheng*
(Jingchu University of Technology? ?Computer Engineering School, Jingmen, Hubei Province, 448000 China)
Abstract: In recent years, with the rapid development of cloud computing technology, many enterprises and institutions transfer their business to the cloud, which not only reduces costs, but also provides efficiency. But then it is easier for cloud service providers being attacked by a large number of malware. Many machine learning algorithms are used to protect the cloud system from attack by predicting the possible behavior on the cloud platform, and achieved good performance. However, when the data set is large and sparse, the effect of these machine learning algorithms is not good. In this paper, a gradient boosting decision tree algorithm is adopted, which can more accurately predict the malware attacks on cloud computing system. Experiment results show the effectiveness of the proposed method.
Key Words: Cloud computing security; Machine learning; Gradient; Down sampling; Decision tree algorithm
信息化時代,每家公司和機構都利用計算機進行相關數據處理。對一家公司來說,一臺計算機的運算能力往往無法滿足需求,因此該單位就要購置一臺運算能力更強的計算機,也就是服務器。如果單位的規模再大一些,可能需要多臺服務器,組成一個數據中心。建立一個數據中心,除了巨大的初期建設成本之外,后期的計算機和網絡維護支出,都是中小型單位和企業難以支付的。云計算(Cloud Computing)就是在此背景下誕生的。云計算是以互聯網為基礎的分布式計算,使用者可以從云提供商那里隨時按需獲得自己所需的計算資源,像使用自來水一樣,按需付費即可,不必每家單位都建立和維護一個自己的服務器和數據中心,這樣大大降低了成本和提高了效率。
云計算提供的服務主要分3種:軟件即服務(SaaS,
Software as a Service)、基礎設施即服務(IaaS,
Infrastructure as a Service)、平臺即服務(PaaS, Platform as a Service)。但伴隨著云計算產生的安全問題,帶來很多挑戰[1-3]。比如對于公有云平臺,由于被很多租戶使用,這樣大大增加了某租戶非法訪問其他租戶的內容和信息的風險。
機器學習(Machine Learning)是人工智能(Artificial Intelligence, AI)中的一個跨學科的領域,它通過對相關的數據進行學習,實現決策支持。在云計算安全性問題和云數據管理方面,機器學習是一種較高效的方法。一些機器學習的算法如線性回歸、支持向量機、貝葉斯等,和其他一些安全措施結合在一起,能用來提高云服務的安全性[4-6]。但是,當這些機器學習算法學習的數據集較大且稀疏時,效果不是很理想[7]。
本文提出了一種梯度提升(Gradient Boosting)的決策樹(Decision Tree)算法,能對云計算系統上的惡意軟件攻擊進行更準確的預測。在一個較大且稀疏的數據集上,驗證了本算法在惡意軟件檢測率和運行時間方面的有效性。
1? 相關工作
盡管云計算服務迅猛發展,企業和個人都轉向利用云服務,但其安全性問題的確是個嚴峻挑戰。A. Vieira采用決策樹和隨機森林對用戶的在線行為進行了預測[7]。決策樹是一種樹狀的決策工具,它包含一些分支和葉子。決策樹比其他的機器學習方法如人工神經網絡(artificial neural network)、邏輯回歸(logistic regression)速度要快,且更容易可視化。它的缺點是容易產生對數據的過擬合。隨機森林(random forests)是一種用來進行分類或回歸的機器學習算法。它學習和訓練一組決策樹,最后決策的結果由森林中每個決策樹輸出結果的眾數決定。總體來說,它比單一的決策樹算法具有更高的準確性。但無論是決策樹還是隨機森林算法,如果學習的數據集很稀疏時,效果都不理想[7]。
H. Kuswanto等實現了一種基于邏輯回歸的算法,用來對用戶不良行為進行預測[8]。一般的邏輯回歸的因變量是二分類的,H. Kuswanto等的這種算法將邏輯回歸涉及的因變量劃分成幾個子空間,從而實現多分類。其目的是能對基于云服務的大數據集進行學習,并準確預測用戶的不良行為。對于大的數據集,如果它是線性可分的,邏輯回歸具有優勢,但它只適合預測離散數據,而且當數據集較大時,容易產生過擬合[9]。
2? 基于梯度提升的云安全算法
為了對惡意軟件攻擊進行預測,本文采用了一種梯度提升決策樹算法[10]。梯度提升(gradient boosting)是一種提升(boosting)算法,它屬于集成學習(ensemble learning)的一種。提升(boosting)是一種可將弱學習器提升為強學習器的算法。提升算法基于這樣一種思想:對于一個復雜的任務,將多個分類器(classifier)的判斷總和得出的結果要比任何一個分類器單獨的判斷好。
2.1 梯度單向采樣方法
因為傳統的梯度提升決策樹算法很耗時,為減少性能開銷,許多方法被采用。例如可通過下采樣(downsample)方式來減少樣本的數量,從而減少運行時間。但它要考慮數據樣例的權重,所以不能直接用于梯度提升算法。同樣,減少每個數據樣例的特征數也是一個減少梯度提升算法運行時間的方法,但這樣會影響算法的精度。本文采用下采樣方法:采用了一種梯度單向采樣方法,用來減少樣本的數量。
雖然供學習的數據集中的每個實例數據沒有一個固有權重值,但在計算信息增益時,可以采用梯度,即:梯度越大的實例,對信息增益的貢獻率就越高。在采用下采樣將樣本數減少時,梯度小的樣本就被清洗掉了。這樣會帶來一個問題:整個數據集的數據分布被破壞了。為此,在梯度小的數據實例上進行隨機采樣,對梯度大的數據則全部保留[7]。具體算法如下:先對整個數據集中的實例按梯度進行排序,然后按從大到小的順序選出所有梯度高的實例(占整個數據集的a)。對剩余的實例,以采樣率b隨機選取。最后,對選擇的這些梯度較小的實例,按(1-a)/b 的比例進行對其權值擴大。這樣可以保證,在下采樣的情況下,原數據集的分布基本沒有被改變。
2.2 基于梯度提升的云安全算法
本文提出的基于梯度提升的云安全算法,完整描述如圖1所示。
算法中,損失函數采用交叉熵損失函數,如公式(1)所示:
(1)
在二分類問題中,當yi=1時,LogLoss= - logpi,預測輸出越接近真實樣本標簽1,損失越小。當yi=0時,LogLoss= - log(1-pi ),預測輸出越接近真實樣本標簽0,損失越小。該公式的意義在于:當預測類型與真實標簽的值越接近,損失函數的值越小,樣本的重要性就越高,越應該在下采樣時被采樣。
3? 實驗
本算法使用的是微軟公司提供的一個云安全環境中惡意軟件預測數據集[11]。該數據集有訓練數據4.04GB,測試數據3.55GB。先用訓練數據對算法進行訓練,得到分類器。然后用學習到的分類器,在測試數據上進行測試,分析預測的準確性。因為數據量很大,所以采用傳統的隨機森林等算法將非常耗時。由于本算法采用下采樣方法,大大減少了訓練數據的樣本數,將在基本不影響預測精度的情況下,大大減少運行時間。
測試數據的輸出包含2個屬性值:userID和Has Detection,在預測結果和用戶之間建立一種映射關系。同時,在用戶與其所占的地理位置之間也有關聯。根據對惡意軟件預測的概率,對用戶未來的網絡攻擊行為進行預測,從而保護云安全。
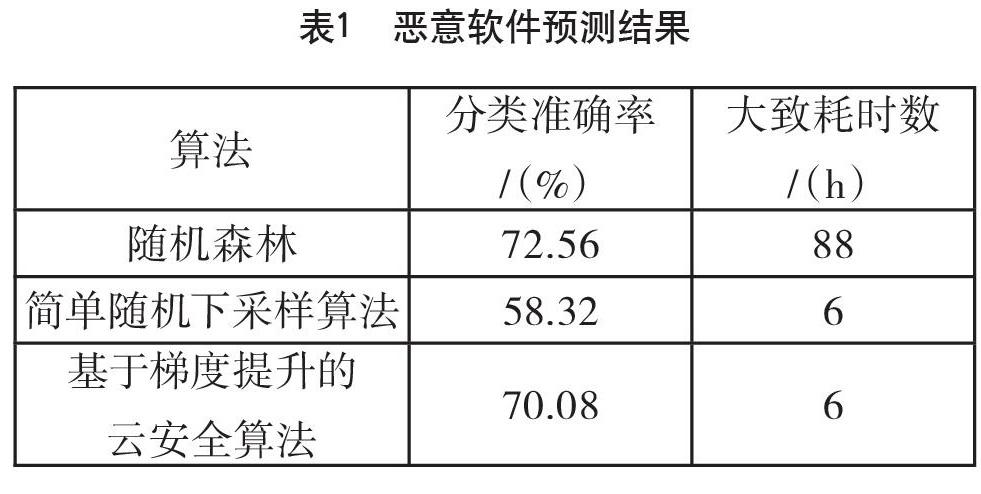
在該數據集上,分別采用隨機森林、簡單隨機下采樣算法、基于梯度提升的云安全算法進行實驗。簡單隨機下采樣算法很簡單,即直接在訓練數據集上,按a+b的比例,選取樣本。實驗環境是Inter Core i5-4210H CPU和Windows8 操作系統。算法迭代次數為500。基于梯度提升的云安全算法實驗最后的準確率為70.08%,比隨機森林有所下降,但運行時間只有6h左右,時間大大減少。具體如表1所示。
4? 結語
隨著云計算的快速發展,云安全變得越來越重要。傳統的機器學習算法進行惡意軟件預測,當數據集很大時,非常耗時。本文提出了一種基于梯度提升的云安全機器學習算法,采用了一種單向梯度采樣方法,在保持樣本分布不變的情況下,大大減少了訓練樣本數,實驗驗證了本算法的有效性。
參考文獻
[1] Mathkunti N.Cloud Computing: Security Issues [J].Int. J. Comput. Commun. Eng.,2014(3):259–263.
[2] 劉明,孫銀.淺談大數據云計算環境下的數據安全[J].南方農機,2019,50(5):147.
[3] 高源,雷瑩瑩.云計算環境大數據安全和隱私保護策略研究[J].網絡空間安全,2017(6):7-9.
[4] Le Duc T., Leiva, R.G., Casari, P.Machine Learning Methods for Reliable Resource Provisioning in Edge-Cloud Computing: A Survey[J]. ACM Comput. Surv.,2019(52):1–39.
[5] 李丹彤,馮海云,高涌皓.一種基于機器學習算法的網絡安全評估方法[J].電子設計工程,2021,29(12): 138-142.
[6] Guo A J X, Zhu F.Spectral-spatial feature extraction and classification by ANN supervised with center loss in hyperspectral imagery[J].IEEE Transactions on Geoscience and Remote Sensing, 2019, 53(3):1755-1767.
[7] A. Vieira.Predicting online user behaviour using deep learning algorithms[J/OL].http://arxiv.org/abs/1511.06247.
[8] H. Kuswanto, A. Asfihani, Y. Sarumaha.? Logistic regression ensemble for predicting customer defection with very large sample size[J].Procedia Computer Science,2015,72:86–93.
[9] X. Chen, P. Ender, M. Mitchell,et al.Logistic regression with Stata[M].UCLA: Academic Technology Services, Statistical Consulting Group,2011.
[10] J. H. Friedman.Greedy function approximation: A gradient boosting machine[J].The Annals of Statistics,2001,29:1189–1232.
[11] Microsoft malware prediction dataset[EB/OL].https://www.kaggle.com/c/microsoft-malware-prediction/data.
猜你喜歡
電子技術與軟件工程(2016年22期)2016-12-26 21:36:42
時代金融(2016年27期)2016-11-25 17:51:36
科教導刊(2016年26期)2016-11-15 20:19:33
活力(2016年8期)2016-11-12 17:30:08
科學與財富(2016年28期)2016-10-14 21:19:17
電腦知識與技術(2016年20期)2016-08-19 18:49:49
電腦知識與技術(2016年12期)2016-06-14 00:45:31
科教導刊·電子版(2016年10期)2016-06-02 19:17:03
科教導刊·電子版(2016年10期)2016-06-02 18:04:11
電腦知識與技術(2016年3期)2016-04-07 16:12:55
