基于SVM和CRF雙層模型的FrameNet框架消歧
2021-09-26 10:46:14秦博宇郝曉燕劉永芳
計算機工程與應用 2021年18期
秦博宇,郝曉燕,劉永芳
太原理工大學 信息與計算機學院,太原030600
框架語義學(frame semantics)是由Fillmore于20世紀70年代提出的。框架語義學作為認知語言學語言結構研究的兩大基礎理論之一[1],認為語言及詞匯的理解必須建立在框架(frame)之上。在框架語義分析中,FrameNet作為一個獨特的語義知識庫已經得到了眾多研究者的關注。FrameNet是在Fillmore等學者的主持之下由加州大學伯克利分校建立的一項以框架語義學為基礎理論的研究工程,曾作為國際計算語言學協會(ACL)國際語義測評SemEval-2007的第19項任務[2]——Frame Semantic Structure Extraction的測評語料對框架語義結構進行抽取。
框架消歧任務是框架語義分析的一個子任務,同時它也是框架語義分析中必不可少的中間環節,具有非常重要的作用。其主要任務是在例句中根據給定目標詞的上下文語境,自動識別出該目標詞所屬的框架。框架消歧任務可以解決自然語言當中的“一詞多義”現象,在一定程度上為機器翻譯、信息檢索等領域提供了語義支持。
目前的框架消歧研究都是將其看作一個傳統的單模型分類問題。雖然框架消歧任務在單個模型中都取得了較好的結果,但是仍然存在以下幾方面的問題。首先,其結果比較依賴統計模型的性能及參數設置。其次,分類模型將目標詞看作獨立的個體進行分類不能很好地利用目標詞之間的隱性聯系。最后,特征標記被認為相互獨立,特征之間的關聯性較小。
針對以上這些問題,本文選擇了在框架消歧任務中表現較好的SVM分類模型和CRF序列標注模型進行組合,首次提出了基于SVM和CRF的雙層模型對FrameNet語料進行框架消歧的方法。首先利用SVM模型對待消歧目標詞進行分類得到分類標簽,然后將分類標簽序列與文本特征序列輸入到CRF模型,建立特征之間的關聯并進行序列標注。
基于SVM和CRF的雙層模型利用分治思想將框架消歧問題轉化為分類問題和序列標注問題,解決了雙層模型在FrameNet框架消歧任務中的空白局面。首先,CRF模型可以充分利用觀察序列中的全部特征信息[3-4],彌補了SVM模型對目標詞單獨分類導致忽略了目標詞之間的隱性聯系這一缺陷。同時,CRF模型作為雙層模型的第二層可以充分利用SVM模型的分類標簽這一特征。這些分類標簽可以提供大量的分類信息,與原有的文本語義特征結合可以建立起特征之間的聯系,在一定程度上解決了特征之間無關聯的問題。其次,SVM模型適合處理有限樣本的分類問題,并且可以獲得全局最優值[5],解決了CRF模型只能取得局部最優值這一缺陷。由于雙層模型優勢互補,能夠進一步提高框架消歧的準確率,最終本文提出的新的可行的FrameNet框架消歧方法取得了較為理想的結果。
1 框架消歧研究現狀
目前針對框架消歧的研究并不是很多,大部分都借鑒詞義消歧的方法,采用單個統計模型分類的思想來解決。美國的Bejan和Hathaway[6]抽取詞元特征和命名實體特征,利用支持向量機和最大熵模型建立多分類器,將框架識別看作是多分類問題。結果顯示使用SVM進行框架消歧的準確率比最大熵模型要高。瑞典的Johansson和Nugues[7]使用基于依存句法的方法來提取框架語義結構。他們利用過濾規則來提取能夠激起不同框架的目標詞,然后利用SVM模型對目標詞進行分類。實驗中選取了目標詞的詞根、詞形、目標詞的依存類型集合、子節點和父節點集合作為特征,在FrameNet語料上取得了較好的結果。該研究證明在一定程度上,依存句法特征可以提升框架消歧的準確率。Li等[8]針對漢語框架消歧提出了基于依存分析的條件隨機場模型,首次將框架消歧問題看作是一個序列標注問題,框架識別效果較好。該研究初步驗證了條件隨機場序列標注模型在框架消歧任務中的有效性。劉海靜[9]將框架消歧分別看作是序列標注和分類問題,利用SVM模型和T-CRF模型的框架消歧結果進行對比。實驗證明了T-CRF模型相較于SVM模型來說在漢語框架消歧任務中可以得到較好的結果。李濟洪[10]等將框架消歧看作是分類問題,選取了詞、詞性、基本塊和依存句法樹上的特征,用最大熵模型進行框架消歧。該模型得到最好的結果是69.28%。李國臣等[11]認為人工特征選擇方法不能有效利用每個目標詞的語義特征,因此針對漢語框架消歧問題提出了特征模板自動選擇算法,利用最大熵模型建模,取得了較好的結果。
綜合上述研究可以發現,傳統的單分類模型比較依賴統計模型的性能及參數設置。并且,分類模型將目標詞看作獨立的個體進行分類,無法利用目標詞之間的隱性聯系。另外,特征標記被認為相互獨立,特征之間的關聯性較小。因此針對以上問題本文提出了基于SVM和CRF雙層模型的框架消歧方法。與以往的研究不同的是,該方法融合了雙層模型不同標記間的聯系信息,建立起不同標記序列間的信息交互,有效解決了無法提取目標詞之間的隱性特征和特征之間無關聯的問題。本文研究的是使用SVM和CRF雙層模型對于FrameNet框架消歧的有效性。
2 基于SVM和CRF的雙層框架消歧模型
2.1 支持向量機(SVM)
SVM是建立在統計學習的VC理論和結構風險最小化原則上的[12],善于處理小樣本、非線性及高維模式識別問題,是目前機器學習中最常用且性能表現較好的一個分類器。在本文的研究中主要討論的是將SVM模型用于為待消歧目標詞分類。
假設訓練數據集為T={(x1,y1),(x2,y2),…,(xm,ym)},其中xi∈輸入空間,yi∈{-1,+1}是xi的標記,i=1,2,…,n。如果xi屬于正類,則將yi標記為+1;否則將yi標記為-1。SVM的任務就是尋找能夠將訓練數據劃分為兩類的最優超平面,即求解下面公式(1)的凸二次規劃方程:
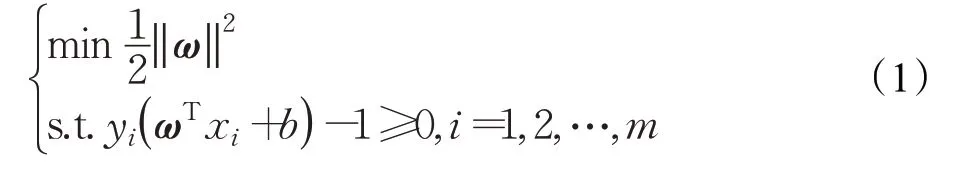
針對本文的框架消歧任務來說,每個待消歧詞元可以激起的框架不止一個,因此可以將框架消歧任務看作是一個多分類的問題,采用“一對一(One versus One)”的策略構造多分類器。SVM模型識別的對象是FrameNet例句中的待消歧目標詞,將這些詞的語義特征提取成支持向量集,計算其到超平面的距離,如果得到了大于0的值,則意味著是+1類,否則為-1類。
2.2 條件隨機場(CRF)
條件隨機場(CRF)模型是由Lafferty等人于2001年提出的,它是基于最大熵模型和隱馬爾可夫模型的判別式概率無向圖學習模型,其中線性條件隨機場(CRFs)是最簡單的一種。
給定一個觀測序列X={X1,X2,…,Xn},Y={y1,y2,…,yn}為X對應的狀態序列,CRF模型如圖1所示。
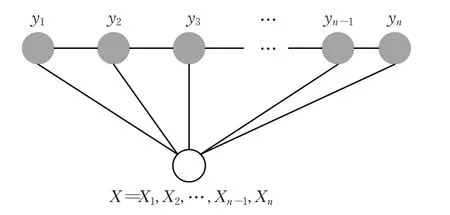
圖1 CRF模型結構圖Fig.1 Structure diagram of CRF model
CRFs定義其對應狀態序列的條件概率為:

在訓練過程中,通過訓練數據集并使用最大似然估計獲得條件概率模型;解碼時采用Viterbi解碼算法,對于給定的條件序列X,求出條件概率最大的輸出序列Y*。
特別地,CRF可以很好地利用上下文信息且一般用于序列標注任務,是目前主流的序列標注模型。對于本文研究的框架消歧任務來說,目標詞的上下文信息對于消歧結果非常重要,但是框架消歧是針對有歧義目標詞為其分配合適的框架,并不是一個典型的序列標注任務。因此,為了將框架消歧任務換成一個序列標注的問題,本文將每個待消歧目標詞所屬的正確框架分配給該目標詞,其他目標詞被標記為“O”,這樣就可以實現基于CRF模型的框架消歧方法。
2.3 基于SVM與CRF的雙層模型
對于傳統的單模型方法來說,大部分研究采用了分類的思想對歧義目標詞進行分類。然而單分類模型沒有考慮到目標詞之間的聯系,導致隱性特征難以被提取、特征之間的關聯性較小,并且分類結果比較依賴于分類模型的性能及參數的設置。
針對上述不足,本文提出了基于SVM和CRF雙層模型的框架消歧方法。在雙層模型的第一層采用SVM模型對語料進行粗分類并得到語料的分類標簽;然后將分類標簽作為新的特征與原有的語義特征結合,在雙層模型的第二層利用CRF模型進行序列標注,最終獲取到待消歧目標詞最合適的框架。具體的實現過程分為兩個步驟(兩層):
(1)利用SVM模型對文本序列的特征向量進行粗分類,得到文本中對應待消歧目標詞的分類標簽序列,并且使用分類標簽對文本序列進行預標注,標簽集?1={labeli,O},i=1,2,…,n。其中labeli表示待消歧目標詞對應的標簽,O表示其他詞。
(2)將SVM分類標簽作為特征加入CRF模型的特征模板,為已經預標注的文本序列標注其對應的框架名稱,標簽集?2={F,O},其中F表示待消歧目標詞激起的正確框架名稱,O表示其他詞。
在本文的FrameNet框架消歧任務中,將文本的特征向量輸入到SVM模型中,利用SVM模型將文本分類并且得到文本中語料的分類標簽label。通過第一層SVM分類得到的分類標簽label,可以得到文本的一個分類標簽序列L={L1,L2,…,Ln},輸入序列X為FrameNet文本序列,輸出序列Y為文本對應的標簽序列。將分類標簽序列L和輸入序列X共同作為CRF模型的輸入。在隨機變量X取值為x,隨機變量L取值為l的條件下,隨機變量Y的條件概率為:
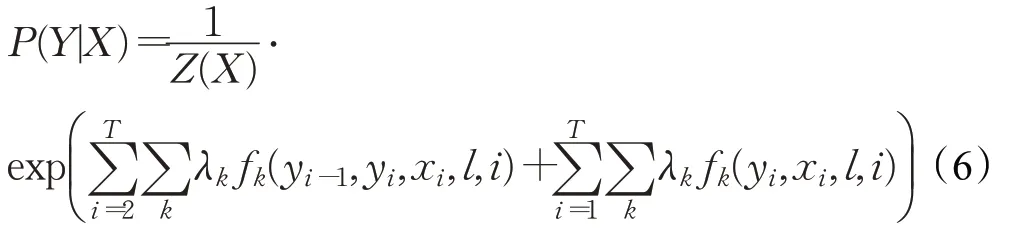
在給定輸入序列X={x1,x2,…,xn}的情況下最大化輸出標簽序列Y的聯合條件概率的似然估計,最大可能的標記序列為:

從定義可以看出基于SVM和CRF的雙層模型將分類標簽作為特征加入勢函數中,可以融合雙層模型不同標記間的聯系信息,建立起不同標記序列間的信息交互,將相互獨立、沒有信息交互的序列聯系到了一起,解決了特征之間無關聯的問題,豐富了特征模板。
雙層模型的算法實現具體步驟如下:
(1)輸入:FrameNet語料序列X={X1,X2,…,Xn}。
(2)抽取特征集F={f1,f2,…,fn}。
(3)利用SVM模型對文本的特征向量進行粗分類,得到SVM模型的分類標簽序列L={L1,L2,…,Ln}。
(4)將分類標簽label作為特征增加到CRF模型特征模板當中,此時抽取的特征集為F*={f1,f2,…,fn,label}。
(5)將語料序列X、SVM模型的分類標簽序列L及文本特征F*輸入到CRF模型,得到第二層的標注序列
Y={Y1,Y2,…,Yn}。
(6)輸出:標注結果。
基于SVM和CRF的雙層框架消歧模型系統分析流程圖如圖2所示。
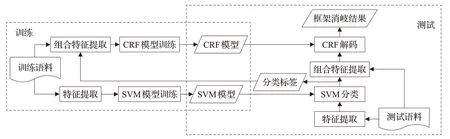
圖2 雙層模型系統分析流程圖Fig.2 Analysis flow chart of two-stage model system
3 特征提取及選擇
3.1 SVM模型的特征
SVM模型特征主要包括兩個方面,分別是詞性和依存句法關系。提取文本中句子的詞性特征及依存句法特征時分別使用了Stanford大學的自然語言處理工具stanford-postagger及stanford-parser。
以目標詞“CAN”為例,特征提取及選擇步驟的具體示例如下:
例句1Breakfast came with tea in petrol CANS.
將例句進行依存句法分析后可以得到一棵依存句法樹,如圖3所示。
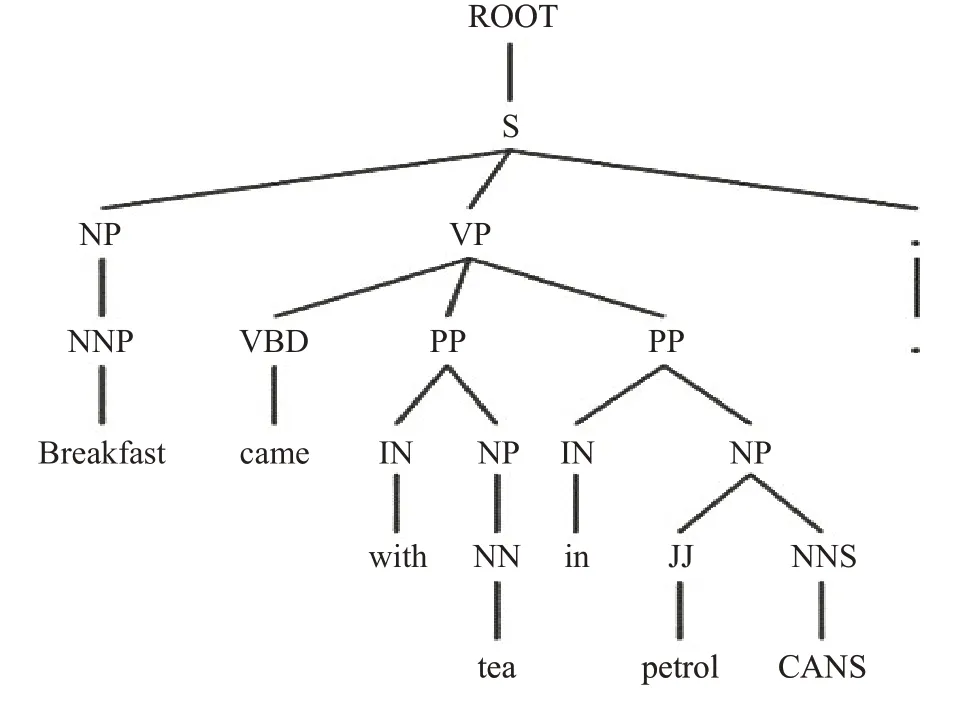
圖3 依存句法樹Fig.3 Dependency syntax tree
依存句法樹中的葉子節點對應著句子中的單詞,圖3中的ROOT表示要處理的句子,S表示陳述句。在依存句法分析樹中,對于句子中的每個單詞或短語所充當的成分都有明確的標記,這些功能符號都具有對應的含義。表1顯示了部分常用的各種標記及其功能。
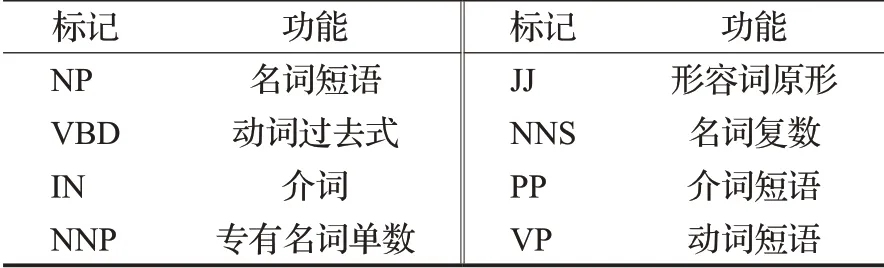
表1 依存句法樹中常用的標記及其功能Table 1 Tags and their functions commonly used in dependency syntax trees
在依存句法樹中每個葉子節點所表示的單詞與其父節點之間存在著依存句法關系。本文所選取的依存句法關系(DEP)包括:nmod(復合名詞)、conj(并列成分)、nsubj(名詞性主語)、amod(形容詞)、dobj(直接賓語)、case(介賓短語)這六種。
因SVM分類模型針對的是待消歧的目標詞,通過訓練后得到的模型對目標詞進行預測框架類型,所以只需要考慮與待消歧目標詞關系密切的文本特征即可。本文選擇目標詞、目標詞前后位置的詞、目標詞的詞性、目標詞前后位置的詞性、目標詞的父子節點的詞性、目標詞前后位置詞的父子節點的詞性、目標詞與父節點的依存句法關系、目標詞與子節點的依存句法關系、目標詞前后位置詞與其父節點的依存句法關系及目標詞前后位置詞與其子節點的依存句法關系作為SVM模型的特征,從而將一個句子轉化成特征向量。例句1待消歧目標詞“CANS”在窗口大小為[-1,1]范圍的句子分析結果如表2所示。
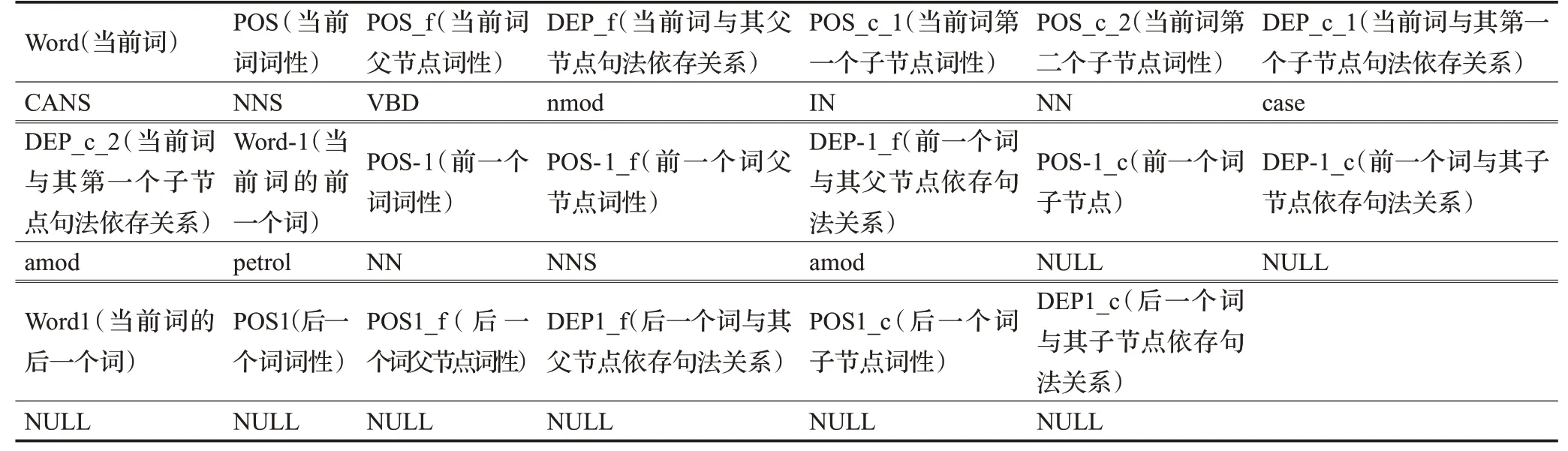
表2 例句分析結果Table 2 Analysis results of example
3.2 CRF模型的特征
CRF模型中比較重要的一步就是選取合適的特征構成特征模板。本文使用了開源工具包CRF++(V0.58)對語料進行框架消歧的訓練和測試。CRF++工具包的特征模板格式為:%[row,col],其中row和col表示相對的行偏移和列偏移,當前標記值的行偏移和列偏移均為0。該格式不僅可以表示原子特征,還可以表示復合特征,格式為:%[row1,col1]/%[row2,col2]。
實驗選取了詞、詞性、依存句法關系,及由SVM模型輸出的分類標簽作為特征進行實驗。CRF模型實驗中原子特征如表3所示,其中i=-3,-2,-1,1,2,3。

表3 CRF模型的原子特征Table 3 Atomic features of CRF model
利用原子特征進行組合,構建組合特征,能夠更好地利用待消歧目標詞的上下文信息,使得CRF模型能夠獲取上下文中更多隱性特征,進而能夠提高框架消歧的準確率。具體的組合特征如表4所示。
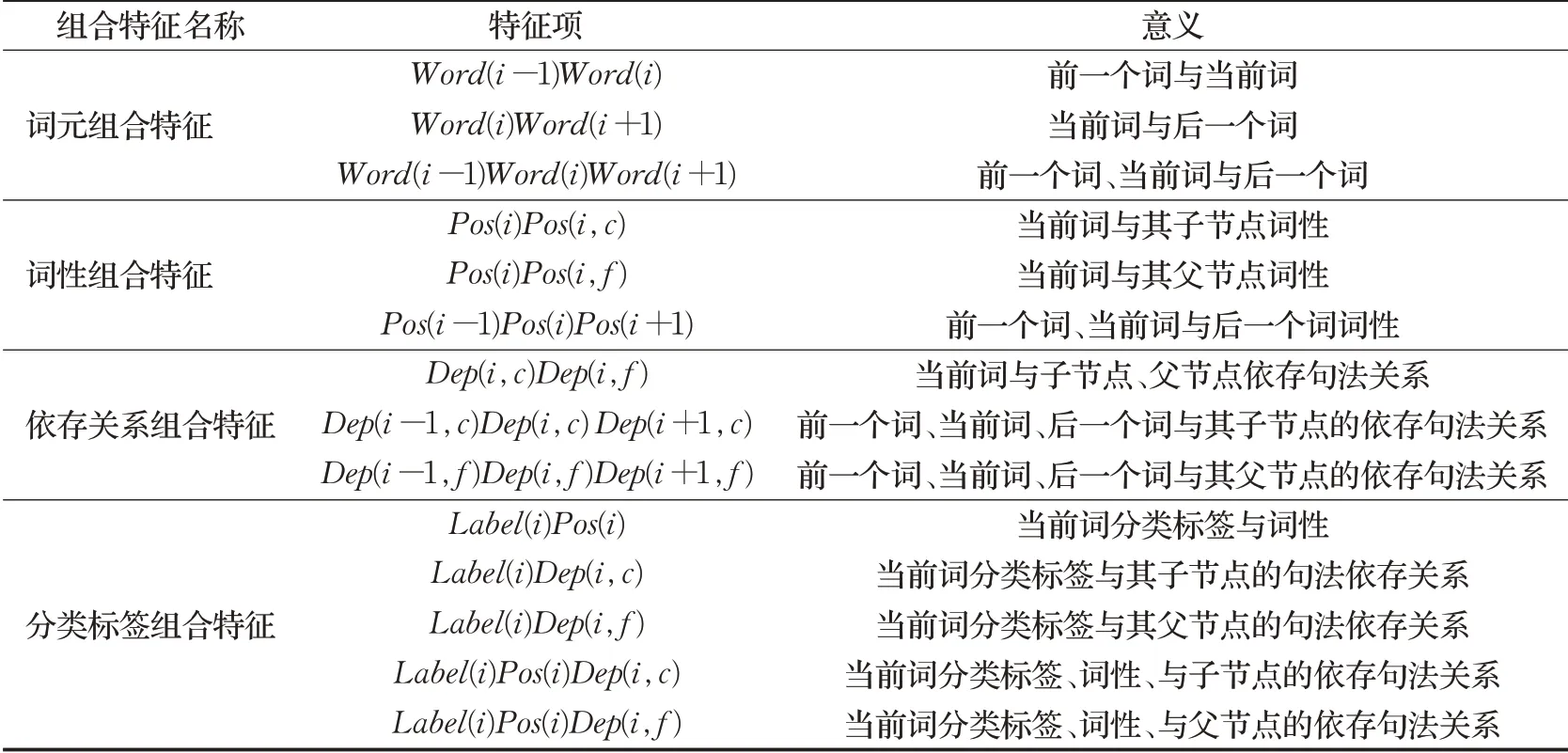
表4 CRF模型組合特征Table 4 Combination features of CRF model
綜合以上原子特征及組合特征構建了CRF模型的特征模板,本文CRF模型的實驗中特征模板如表5所示。

表5 特征模板設置Table 5 Feature template setting
4 實驗與分析
本文在訓練SVM模型時使用了sklearn工具包進行實驗,并且使用了其中的SVC函數。根據文獻[9]可知,在SVM對待消歧目標詞進行分類時可以選擇線性核函數和非線性核函數(高斯核函數、多項式核函數、sigmoid核函數)進行實驗,其實驗結果顯示如果參數設置比較合理的話,多項式核的結果是最優的。但是考慮到多項式核函數由于其參數設置過多,在參數訓練中增加了難度,也增加了時間復雜度,因此選擇框架消歧結果與其相差不大的線性核函數。
在訓練CRF模型時使用了開源工具包CRF++(V0.58),并且設置了6組特征模板進行實驗,充分利用了SVM模型對語料進行粗分類以后得到的分類標簽,使得標簽進一步輔助CRF進行序列標注任務。
4.1 實驗語料
針對FrameNet框架消歧任務,本文從FrameNet語料庫中選擇了18個具有代表性的能夠激起多個框架的詞元、共2 614條例句,及49個框架,語料分布情況如表6所示。對獲取的FrameNet語料過濾垃圾串,例如:無效字符及URL鏈接等。并且將預處理后的語料分別轉化為CRF++和sklearn包所要求的訓練格式。
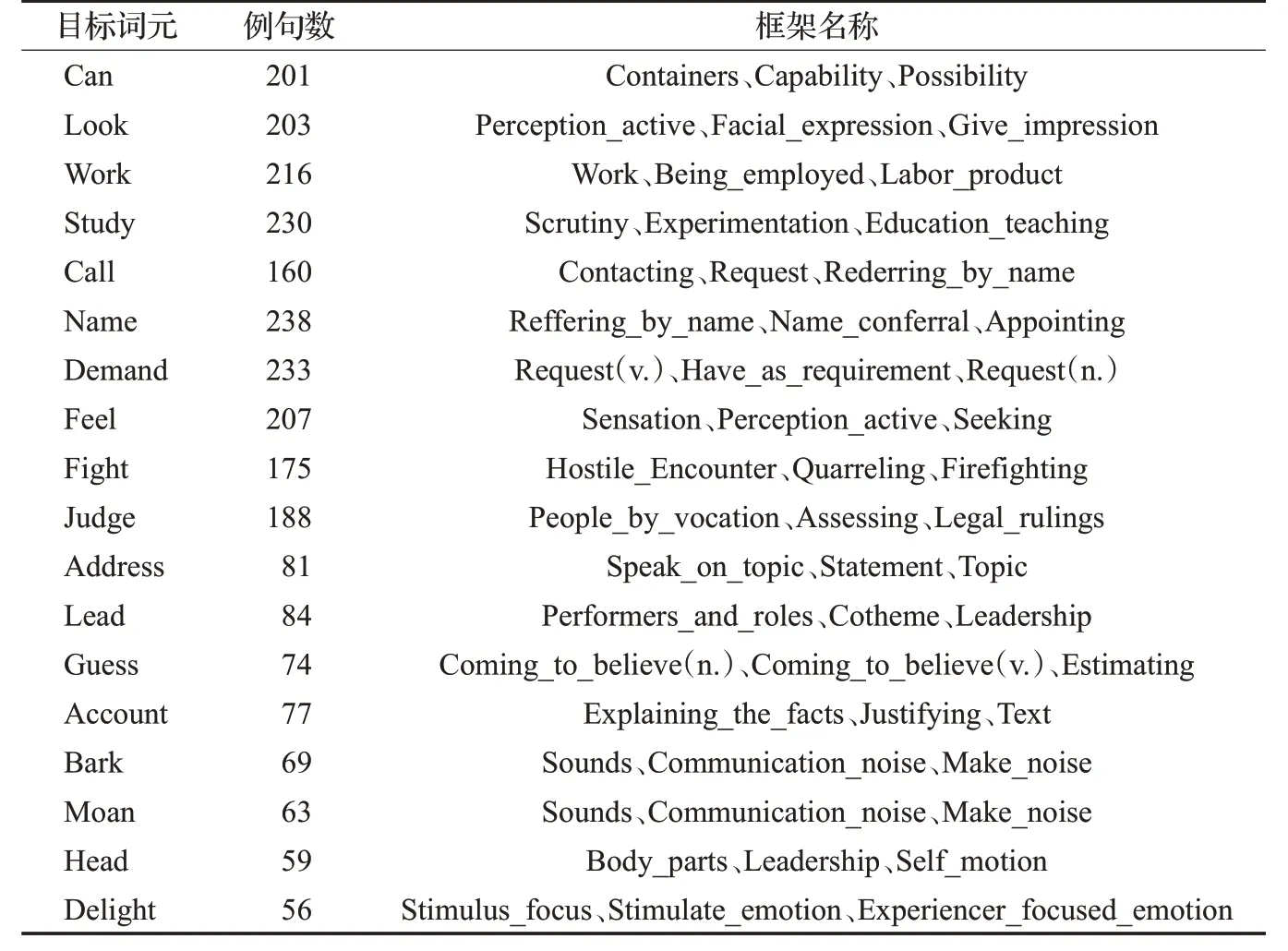
表6 語料分布情況Table 6 Distribution of corpus
4.2 模型評價指標
目前交叉驗證在機器學習的研究中被廣泛應用,尤其是在SVM模型的評測中經常出現該評價方法[13]。由于交叉驗證可以在一定程度上減小過擬合并且能從有限的數據中獲得更多有效的信息,因此本文采用交叉驗證的方法對FrameNet框架消歧結果計算準確率,以評價實驗結果。
給定一個目標詞Targeti(i=1,2,…,n),n為選擇的詞元總數(本文選擇個數n=10),在5-fold交叉驗證實驗CVj(j=1,2,…,5)下,目標詞的分類準確率評價指標如下面的公式(8)所示:
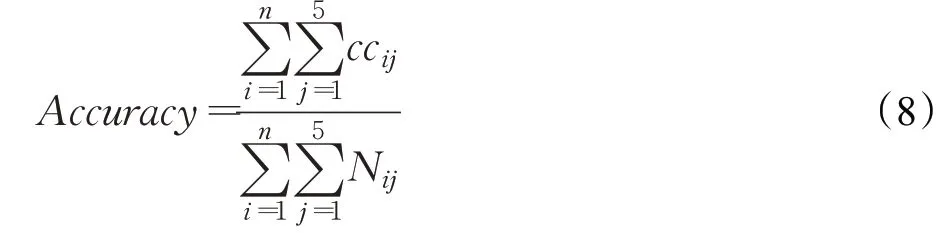
其中,Nij是目標詞Targeti的例句均分為5份后,取第j份作為測試例句的數目,Cij是目標詞Targeti的測試例句中框架標注正確的例句個數。
4.3 實驗結果及分析
4.3.1 支持向量機模型(SVM)、條件隨機場模型(CRF)與最大熵模型(ME)的實驗結果對比及分析
為了測試傳統的框架消歧模型在FrameNet語料上的性能,本文使用SVM模型[7]、ME模型[10]、CRF模型對18個待消歧目標詞進行實驗,并且計算在不同模型下的框架消歧準確率,結果如表7所示。
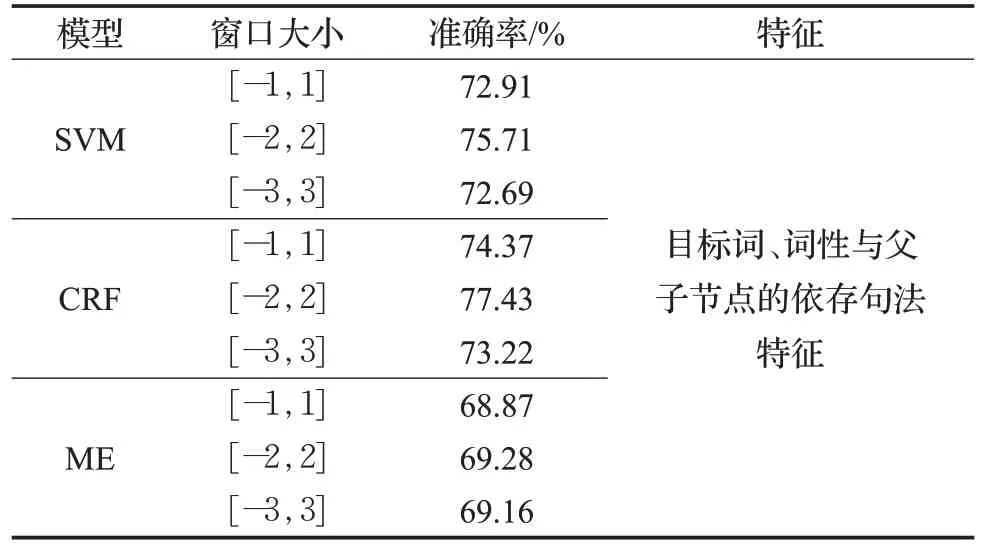
表7 單分類模型下的框架消歧結果對比Table 7 Comparison of frame disambiguation results under single classification model
由表7的結果可以看出,CRF模型在消歧結果上會比SVM模型準確率略高。CRF模型的框架消歧準確率最高可以達到77.43%,而SVM模型的最優框架消歧準確率為75.71%,與CRF模型相比低了1.72個百分點。因此可以看出在處理小樣本數據時,CRF模型較SVM模型來說準確率略有提升,但是不明顯,原因可能是上下文信息中含有噪聲。ME模型與CRF模型和SVM模型相比較,最優框架消歧準確率較低,僅為69.28%,比CRF模型和SVM模型分別低了8.15和6.43個百分點,說明ME模型在處理小樣本數據時性能明顯較差。
4.3.2 CRF模型的實驗結果及分析
表8列出了使用表5中設計的6個特征模板并且進行5-fold交叉驗證得到的CRF模型的實驗結果。由表8中的實驗結果可以得出以下結論:
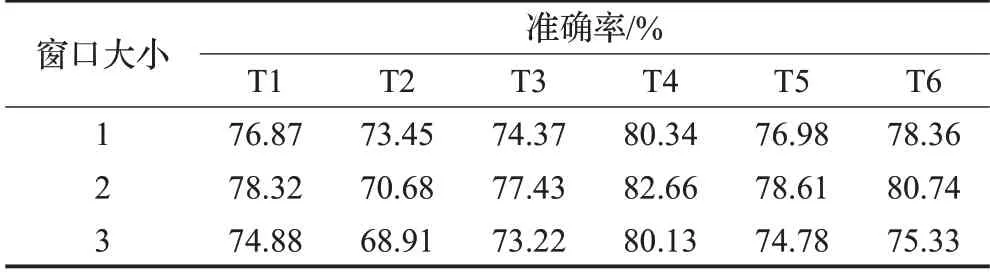
表8 CRF特征模板實驗結果Table 8 Results of CRF feature template
(1)對比T1、T2模板可以看出,引入父節點的依存句法關系后,準確率明顯下降。這是因為當前詞的父節點并不能對當前詞產生關鍵的語義影響,反而父節點特征的加入會使得系統噪聲增加,影響了框架消歧的準確率。
(2)在加入分類標簽的原子特征和組合特征(T4、T5)之后,相較于沒有增加分類標簽的特征模板,框架消歧的準確率為82.66%、78.61%,較T1、T2模板準確率78.32%、70.68%有所提升。這是因為對于框架消歧任務來說,每個待消歧的目標詞至少可以激起兩個以上的框架,要準確識別難度會比較大。經過SVM分類后得到的分類標簽本身就攜帶了大量目標詞的分類信息,CRF模型可以充分利用觀察序列中的全部特征,因此可以在原本相互獨立的、沒有關聯的分類標簽序列和語義特征序列之間建立信息交互,使分類標簽與文本特征之間的相關性在一定程度上豐富了特征模板,進而可以提升框架消歧準確率。因此該實驗驗證了第一層SVM模型得到的分類標簽特征對于本文提出的基于SVM和CRF的雙層模型來說可以在一定程度上提升框架消歧的準確率。
4.3.3 雙層模型的實驗結果及分析
為了驗證本文提出的基于SVM和CRF雙層模型的框架消歧方法比其他雙層模型的框架消歧準確率高,本文使用4.3.1小節提到的傳統的框架消歧模型進行組合,構成三個雙層模型與本文使用的基于SVM和CRF雙層模型的框架消歧方法進行對比實驗,分別是ME+SVM、ME+CRF、CRF+CRF。本文基于SVM和CRF的雙層模型的框架消歧結果與其他雙層模型的框架消歧結果對比如表9所示。

表9 雙層模型框架消歧實驗結果對比Table 9 Comparison of disambiguation results of two-stage model
由表9的結果可以看出,ME+CRF模型的框架消歧準確率最低,對比ME+SVM模型來說準確率低了1.32個百分點,但是差別不明顯。原因在于在訓練數據中除目標詞以外的詞會被標記為“O”,所以經過特征選擇之后這種標記被CRF模型學習到,就會在測試結果當中出現,導致一些本來應該標注為某一框架的目標詞被錯誤地標記為“O”,進而影響準確率。
CRF+CRF模型的準確率與ME+SVM、ME+CRF模型的準確率相比較會有所提升,分別增加了3.32和4.64個百分點。原因在于CRF模型相較于ME模型來說,CRF模型可以避免嚴格的獨立性假設和數據歸納偏置問題,還能夠建立起標簽序列與文本特征序列之間的關聯,提高了框架消歧的準確率。
表9中其他的復合模型與本文的基于SVM和CRF的雙層模型的框架消歧準確率進行比較,本文的雙層模型準確率較高。原因在于其他雙層模型僅僅是兩次序列標注的簡單疊加,并沒有將兩層模型聯系起來。而本文提出的基于SVM和CRF雙層模型的框架消歧方法是將SVM分類之后產生的分類標簽作為特征輸入到CRF模型中,將分類標簽序列與文本特征序列融合,建立起不同標記序列間的信息交互,解決了特征之間無關聯的問題,豐富了特征模板。
由于語料規模對框架消歧任務有一定影響,而且實驗中標記的語料數量較多,因此針對以上提到的四個復合模型在實驗語料逐步擴大的情況下進行了對比實驗,實驗結果如圖4所示。從圖4可以看出,隨著語料規模的逐漸增加,四個復合模型的框架消歧準確率都會不斷提升,但是當語料中的例句數達到700個例句之后,框架消歧結果逐漸趨于穩定。圖4也側面證明了該研究中使用的框架消歧語料例句數可以滿足實驗的要求。
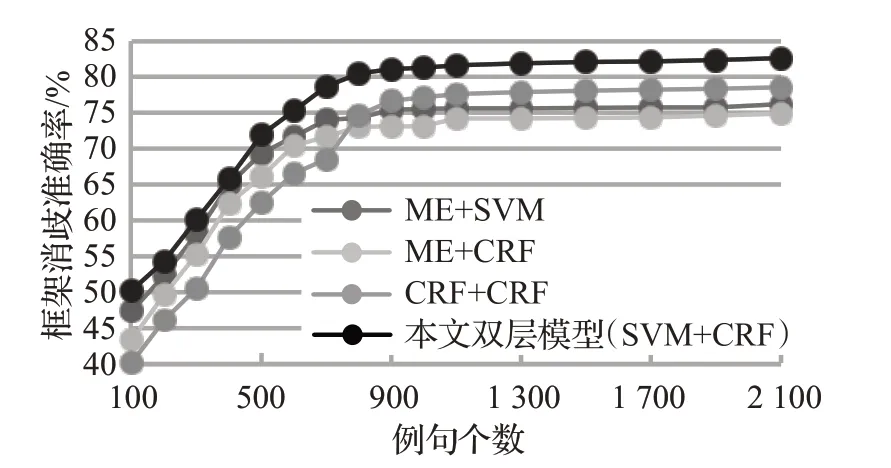
圖4 不同語料規模下模型最優框架消歧準確率對比Fig.4 Com of optimal frame disambiguation accuracy of model under different corpus sizes
綜合來看,利用SVM模型得到的分類標簽作為特征與原有的文本語義特征結合可以使得本文提出的雙層模型的框架消歧準確率達到82.66%,本文提出的方法在FrameNet框架消歧中取得了較好的效果。
5 結束語
本文在傳統的利用單個模型處理框架消歧任務的基礎上,選擇在分類任務中表現較好的SVM模型及在序列標注任務中主流的CRF模型作為雙層模型的結構,利用分治的思想將框架消歧任務分解為對待消歧的目標詞分類及序列標注任務。結果也證明了本文提出的基于SVM和CRF的雙層模型可以在一定程度上將兩層模型的優勢互補。一方面CRF模型能很好地利用目標詞之間的隱性聯系,并且在特征選擇上充分利用了分類標簽與文本特征之間的相關性,使得特征模板得以豐富;另一方面,SVM模型適合處理有限樣本的分類問題,并且可以獲得全局最優值,因此提升了FrameNet語料框架消歧的準確率。通過實驗結果也證明了本文方法在處理FrameNet框架消歧任務上具有一定優勢。
同時,FrameNet語料中還存在著豐富的文本信息,本文雖然利用了分類標簽特征以提高框架消歧的準確率,但是特征的選擇還是很局限。今后可以將框架之間的關系和句子所在的段落或者篇章這些豐富的上下文信息引入到框架消歧的研究中,以進一步提升框架消歧的準確率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
