改進強化學習算法應用于移動機器人路徑規劃
2021-09-26 10:46:42王科銀楊正才楊亞會王思山
計算機工程與應用 2021年18期
王科銀,石 振,楊正才,楊亞會,王思山
1.湖北汽車工業學院 汽車工程學院,湖北 十堰442002
2.汽車動力傳動與電子控制湖北省重點實驗室(湖北汽車工業學院),湖北 十堰442002
3.湖北汽車工業學院 汽車工程師學院,湖北 十堰442002
隨著科技的發展,移動機器人越來越多地走進人們的日常生活。移動機器人的路徑規劃問題也越來越受到重視。路徑規劃技術能夠在參照某一指標的條件下,幫助機器人避開障礙物規劃出一條從起點到目標點的最優運動路線。根據路徑規劃過程中對環境知識的已知程度,路徑規劃可以分為全局路徑規劃和局部路徑規劃[1-2]。其中應用較為廣泛的全局路徑規劃算法有A*算法[3]、dijkstra算法[4]、可視圖法[5]、自由空間法[6]等;局部路徑規劃算法有人工勢場算法[7]、遺傳算法[8]、神經網絡算法[9]、強化學習算法[10]等。強化學習算法是一種適應性比較強的算法,可以在完全未知的環境中通過不斷試錯尋找最優路徑,這也使得強化學習算法在移動機器人路徑規劃領域獲得越來越多的關注。
在移動機器人路徑規劃領域應用最為廣泛的強化學習算法是Q-learning算法。傳統的Q-learning算法存在以下問題:(1)在初始化的過程中將所有的Q值設置成0或者是隨機值,這使得智能體在起始階段只能是盲目搜索,導致算法出現過多的無效迭代;(2)在動作選擇時采用ε-貪婪策略,太大的ε值會使智能體更多地探索環境不容易收斂,太小ε值會導致智能體對環境探索不夠而找到次優解,難以平衡探索和利用之間的關系[11]。
針對上述問題,很多學者提出了各種Q-learning的改進算法。宋勇等人[12]引入人工勢場,利用先驗知識確定每點的勢能值,根據勢能值初始化Q值,提高了算法初始階段的學習效率。董培方等人[13]聯合人工勢場和環境陷阱搜索作為先驗知識初始化Q值,得到更快的收斂速度和更優的規劃路徑。Wen等人[14]基于模糊規則初始化Q值,加快了算法的收斂速度。徐曉蘇等人[15]在引入人工勢場初始化Q值的基礎上,增加移動機器人的搜索步長和方向因素,縮短了路徑規劃時間,提高了路徑的平滑度。上述對Q-learning算法的改進都是根據一定規則對Q值初始化,這在一定程度上提高了算法性能,但是缺乏對智能體動作選擇策略的研究。針對當前研究現狀的不足本文提出一種改進的Q-learning算法,在Q值初始化的過程中引入改進人工勢場的引力場函數,使得越靠近目標位置狀態值越大從而智能體在起始階段就能朝著目標位置進行搜索,減少算法起始階段的無效迭代;在動作選擇上改進ε-貪婪策略,根據算法的收斂程度動態調整貪婪因子,更好地平衡探索和利用之間的關系,進一步加快算法收斂速度,并且保證算法的收斂穩定性。
1 相關理論
1.1 Q-learning算法
Q-learning是一種離線的時序差分強化學習算法[16]。智能體根據某一策略對狀態-動作對(s,a)進行k次采樣,得到狀態動作值函數估計值Q(s,a),當進行下一次采樣時,可獲得獎勵值R(s,a)并進入下一個狀態s′,智能體直接選擇狀態s′所對應的最大狀態動作值Q(s′,a′)來更新上一個狀態s的Q(s,a),更新公式如下:
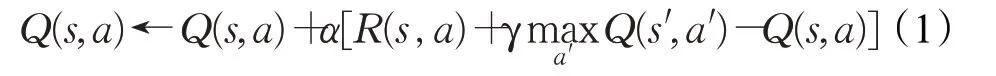
其中,(s,a)為當前狀態-動作對,(s′,a′)為下一時刻的狀態-動作對,R(s,a)為狀態s下執行動作a的即時獎勵,α為學習率,通常設置a為小于1的正數,γ為折扣因子,折扣因子的取值范圍是0~1。
在Q-learning的應用中,通常采用ε-貪婪策略來選擇下一狀態的動作,其表示在智能體選擇下一動作時以ε(ε<1)的概率隨機在動作空間中選擇動作,以1-ε的概率選擇最優動作。
1.2 改進人工勢場法
人工勢場包括引力場和斥力場,其中目標點對移動機器人產生引力,引導機器人朝著目標點運動,越靠近目標點引力越大。障礙物對機器人產生斥力,避免與之發生碰撞。移動機器人運動路徑上的每一點所受的合力等于該點所受目標點的引力和障礙物的斥力之和,在合力的作用下移動機器人從起始位置出發,避開障礙物到達目標位置。因為本文的研究基于未知環境,障礙物位置無法確定,所以只考慮引入引力場,提出如下引力場函數:

其中,ζ是大于0的尺度因子,用來調節引力大小, ||d為當前位置與目標點所在位置的距離,η為正常數,防止目標點處引力值出現無窮大。
該方法構造的人工勢場,整個勢能場從起點到目標點呈現單調遞增趨勢,目標點具有最大勢能值且不為無窮大。
2 改進Q-learning算法
2.1 Q值初始化
傳統的Q-learning算法把所有Q值初始化為0或者是隨機數值,在算法初期智能體只能是隨機地選擇動作,從而產生巨大的無效迭代。通過1.2節中改進的引力場函數初始化狀態值,通過狀態動作值函數和狀態值函數關系式(3)對Q值初始化。通過該方法初始化的Q值使得智能體在初始階段就能以更大的概率向目標點方向移動,減少了算法初期的大量無效迭代,加快算法收斂。

其中,P(s′|s,a)為當前狀態s和動作a確定的情況下轉移到狀態s′的概率,V(s′)為下一狀態的狀態值函數,對于本研究初始化Q值時,V(s′)=Uatt。
2.2 貪婪因子動態調整
如何平衡強化學習當中探索和利用之間的關系是強化學習算法實際應用的難點之一。探索是指智能體在選擇動作時,不遵循已經學習到的策略,而是運用其他可能不太好的策略擴大對環境的搜索范圍,減小出現局部最優的可能性;利用是指智能體在選擇下一步動作時根據已經學習到的策略選擇當前最優動作。ε-貪婪策略在一定程度上平衡了探索和利用,但是智能體每次都以ε的概率在動作集中隨機選擇動作,不好的動作也以同樣的概率被選擇,由此會導致整個過程收斂速度慢,即使在最后收斂也會因為以ε的概率隨機選擇動作使得結果存在一定的波動。針對該問題,本文提出一種改進的ε-貪婪策略。
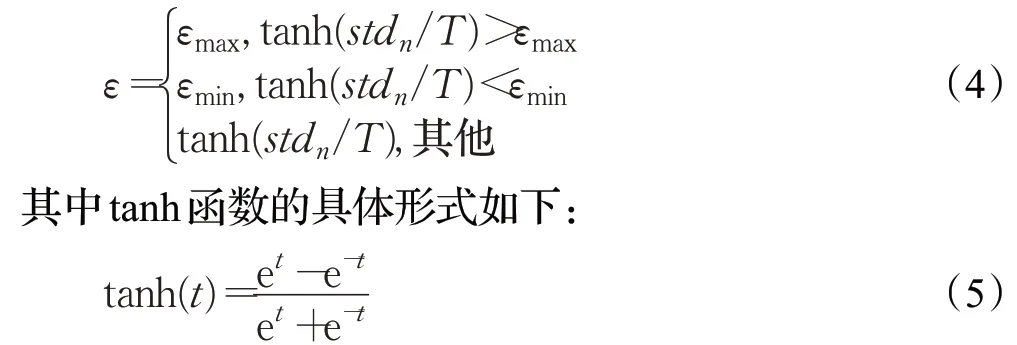
e為自然對數的底,當自變量t大于0時,tanh(t)的取值范圍為(0,1);stdn為連續n次迭代次數的步數標準差;T為系數,與模擬退火算法[17]中的溫度值作用相反,T越大隨機性越小;εmax和εmin分別為所設置的探索率的最大值和最小值。
在強化學習算法起始階段,因為算法不收斂stdn較大,智能體以εmax的概率隨機選擇動作;隨著算法的進行stdn減小,使得ε在(εmin,εmax)范圍內取值,stdn越大表明迭代次數之間的步數差別越大,環境越需要探索,ε的取值就越大;stdn較小時,表明算法趨于收斂,ε穩定在εmin。由以上分析可以看出,該方法設計的貪婪因子動態調整策略,使得前期以更大的概率對環境進行探索,隨著算法的進行,逐漸趨于利用,能夠更好地平衡探索和利用之間的矛盾。
3 仿真實驗與結果分析
3.1 實驗環境
利用Python的Tkinter標準化庫,搭建如圖1所示的20×20的格柵地圖作為仿真環境,每個小格柵的尺寸是20×20像素。其中方塊代表障礙物,白色格柵為無障礙區域。格柵地圖中的每一格代表一個狀態,共400個狀態。起點設置在(10,10)的坐標位置,即狀態(1,1),終點設置在狀態(18,14)。
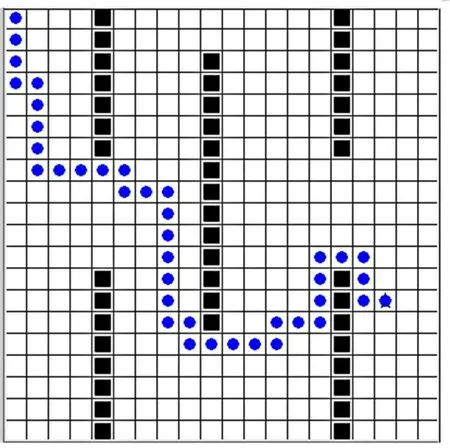
圖1 路徑規劃仿真環境Fig.1 Simulation enviroment of path planning
3.2 實驗參數
在仿真環境中對比以下4種算法:Trad_Q-learning代表傳統的Q-learning算法;APF_Q-learning代表引入人工勢場法初始化Q值的改進算法;Adj_Q-learning代表使用貪婪因子動態調整策略替代ε-貪婪策略改進算法;Imp_Q-learning代表本文提出的最終改進算法。
4種算法的相同參數設置為:學習率a=0.01,折扣因子γ=0.9,最大迭代次數20 000次。其他設置如表1。
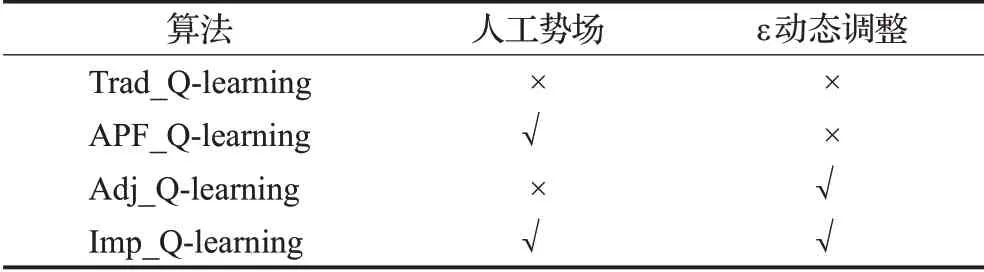
表1 4種算法的設置Table 1 Settings of 4 kinds of algorithms
對于4種算法獎勵函數設置為:

貪婪因子動態調整策略參數如下:εmax=0.5,εmin=0.01,T=500,n=10。
3.3 實驗結果與分析
圖2中(a)~(d)依次表示上述4種算法的收斂情況,當路徑長度在小范圍內波動時認為算法收斂。表2詳細對比了4種算法的性能,收斂條件都設置為連續10次迭代步數標準差小于5,每種算法運行10次取數據平均值。
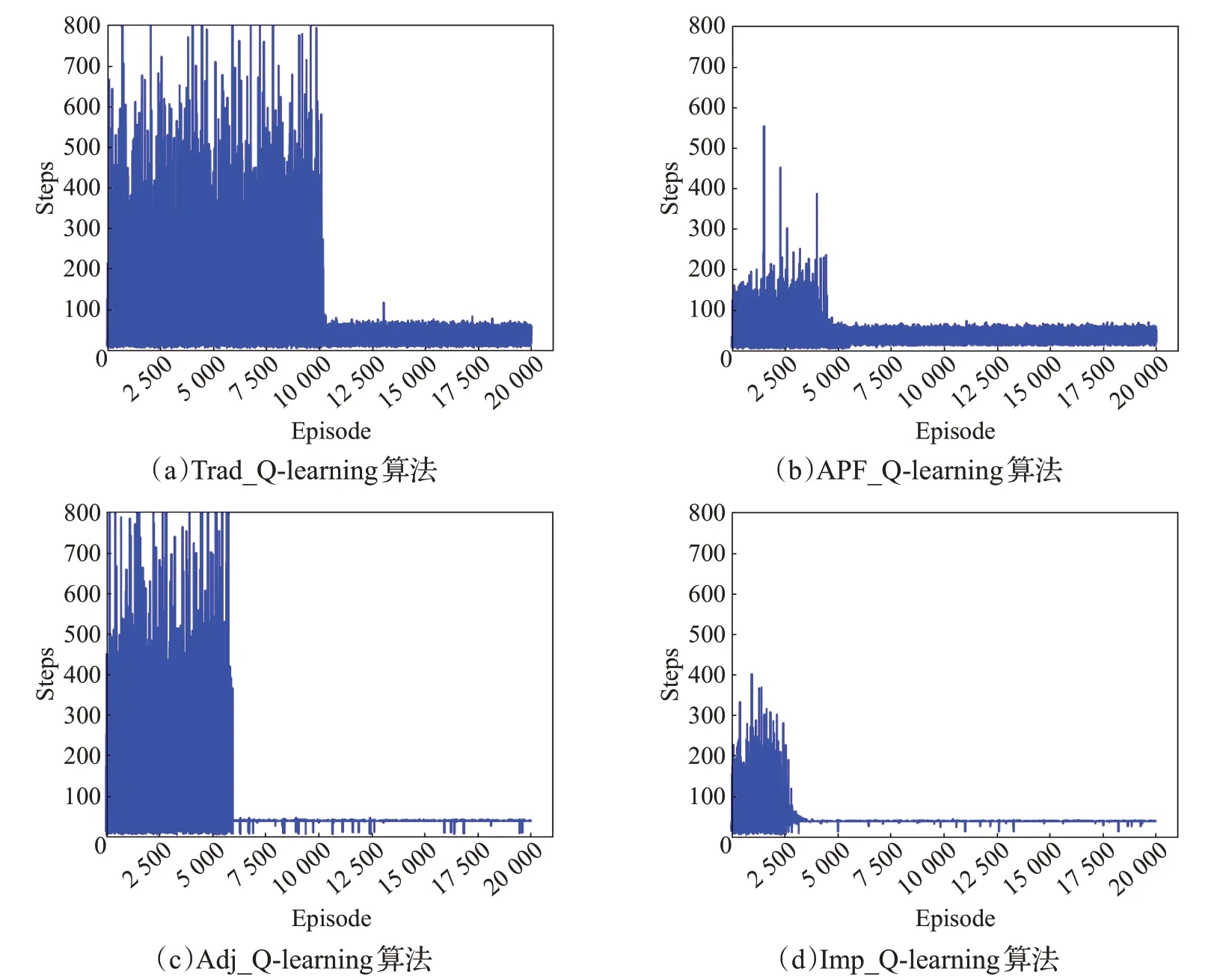
圖2 4種算法收斂回合Fig.2 Convergence episode in 4 kinds of algorithms
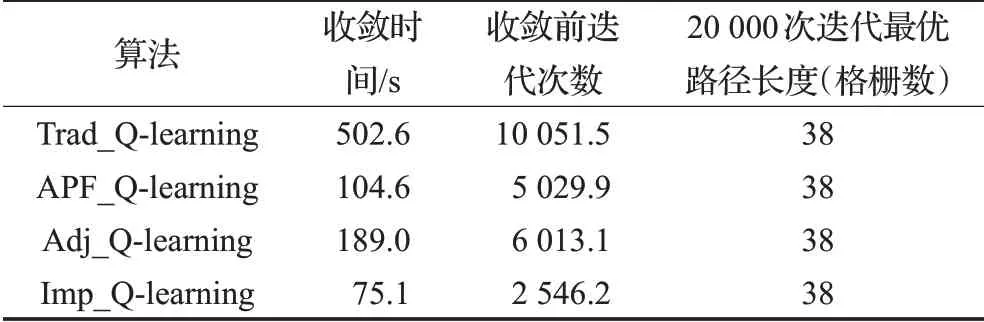
表2 4種算法性能比較Table 2 Performences comparison of 4 kinds of algorithms
實驗結果表明4種算法在迭代一定次數后都可以規劃出最優路徑,圖1中的藍色圓點展示了某次實驗規劃出的最優路徑。對比算法APF_Q-learning和算法Trad_Q-learning可知,引入人工勢場法初始化Q值可使得算法收斂時間縮短79.2%,迭代次數減少50.0%,但是算法在收斂穩定性上沒有提升;對比算法Adj_Q-learning和算法Trad_Q-learning可知,動態調整貪婪因子可使得算法收斂時間縮短62.4%,迭代次數減少40.2%,算法的收斂結果穩定性得到了提升,算法收斂后只有極少數的波動;對比算法Imp_Q-learning和算法Trad_Q-learning可知,本文提出的最終改進算法在初始化Q值時引入人工勢場法,在動作選擇時動態調整貪婪因子可使得算法收斂時間縮短85.1%,迭代次數減少74.7%,同時算法的收斂結果穩定性也得到了提升。
4 結語
針對未知靜態環境下移動機器人的路徑規劃問題,為了提高強化學習算法的收斂速度和收斂結果穩定性,本文在傳統Q-learning算法的基礎上引入改進人工勢場法初始化Q值,同時在動作選擇時動態調整貪婪因子。通過實驗表明算法的效率和收斂結果的穩定性都得到大幅提升。但是該算法在應用時需要根據不同的情境設置6個參數,如何設置算法中的參數,使得算法具有更好的適應性是接下來研究的重點。
猜你喜歡
北京航空航天大學學報(2022年6期)2022-07-02 01:59:12
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
領導決策信息(2018年50期)2018-02-22 06:17:16
商周刊(2017年5期)2017-08-22 03:35:26
制造技術與機床(2017年3期)2017-06-23 08:11:21
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
中國衛生(2016年2期)2016-11-12 13:22:16
中國工程咨詢(2016年4期)2016-02-14 07:28:28
少兒科學周刊·少年版(2015年4期)2015-07-07 20:56:37
