Audio2Face基于音頻文件智能生成虛擬角色面部動畫
2021-09-27 07:43:40蔡國鑫
現(xiàn)代電影技術(shù) 2021年9期
近日英偉達 (Nvidia)公司發(fā)布了一款基于人工智能 (AI)的Audio2Face應用程序,根據(jù)音頻源生成3D 虛擬角色面部動畫并實現(xiàn)唇音同步,可用于實時交互應用或作為內(nèi)容創(chuàng)作通道。傳統(tǒng)虛擬角色面部動畫制作需進行建模、綁定、動畫等一系列處理,而Audio2Face以.wav或.mp3音頻文件為輸入,直接生成角色面部動畫或幾何緩存,制作人員只需根據(jù)應用需求進行調(diào)整定制即可使用。
1 Audio2Face技術(shù)難點與解決方案
僅由音頻源生成虛擬角色面部動畫和實現(xiàn)唇音同步的難點在于基于同一音頻源可能生成多種不同的面部動畫。盡管深度卷積神經(jīng)網(wǎng)絡(luò) (DCNN)在各種推理和分類任務中非常有效,但如果訓練數(shù)據(jù)中存在歧義,其往往會向均值回歸,因此基于深度卷積神經(jīng)網(wǎng)絡(luò)為虛擬角色生成逼真且一致的面部動畫尚存在一定困難。
針對技術(shù)難點,Audio2Face提出了以下解決方案:
(1)設(shè)計一種深度卷積網(wǎng)絡(luò),用于有效處理人類語音并在不同的虛擬角色上實施模型泛化。
(2)采用一種新穎方法,使網(wǎng)絡(luò)能夠發(fā)現(xiàn)訓練數(shù)據(jù)中不能由音頻單獨解釋的變化,即明顯的情緒狀態(tài)。
(3)構(gòu)建具有三個損失項的損失函數(shù) (Loss Function),確保在數(shù)據(jù)高度模糊的情況下,網(wǎng)絡(luò)依然能夠具有時間穩(wěn)定性和快速響應能力。
2 Audio2Face網(wǎng)絡(luò)結(jié)構(gòu)
按照功能劃分,Audio2Face網(wǎng)絡(luò)由頻率分析網(wǎng)絡(luò)(Formant Analysis Network)、發(fā)音網(wǎng)絡(luò) (Articulation Network)和輸出網(wǎng)絡(luò) (Output Network)組成,網(wǎng)絡(luò)結(jié)構(gòu)如圖1所示。
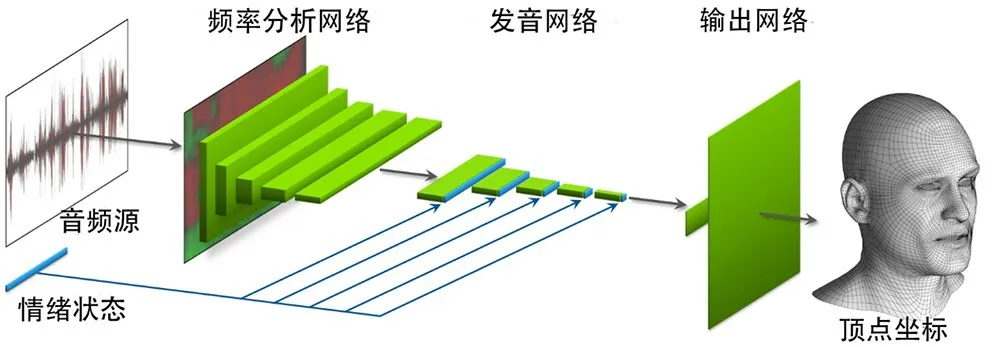
圖1 Audio2Face網(wǎng)絡(luò)結(jié)構(gòu)
頻率分析網(wǎng)絡(luò) (Formant Analysis Network)包括一個固定功能的自相關(guān)分析層 (Fixed-Function Autocorrelation Analysis Layer)和5 個卷積層。自相關(guān)分析層使用線性預測編碼 (Linear Predictive Coding,LPC),以提取音頻的自相關(guān)系數(shù)。自相關(guān)系數(shù)描述了原始音頻信號共振峰的能量譜分布,可用于表示音頻特征。自相關(guān)層以多幀音頻信號為輸入,處理后輸出2D 音頻特征圖,2D 音頻特征圖再經(jīng)5個卷積層對自相關(guān)系數(shù)進行壓縮,學習并提取與面部動畫相關(guān)的短時特征,如語調(diào)、強調(diào)和特定音素等,最終輸出特征向量。發(fā)音網(wǎng)絡(luò)(Articulation Network)使用5 個卷積層在時序上提取相鄰序列幀的關(guān)聯(lián)特征,輸出語音特征圖。由于語音不僅與聲音頻率密切相關(guān),還與說話者的情緒和類型等特征密切相關(guān),因此發(fā)音網(wǎng)絡(luò)還需輸入通過訓練提取的情緒狀態(tài)。情緒狀態(tài)采用數(shù)據(jù)驅(qū)動方法由神經(jīng)網(wǎng)絡(luò)自動學習生成,并被添加到發(fā)音網(wǎng)絡(luò)所有層的激活列表中,成為損失函數(shù)計算圖的一部分,在誤差反向傳播期間隨著網(wǎng)絡(luò)權(quán)重變化而更新。輸出網(wǎng)絡(luò) (Output Network)通過兩層全連接層實現(xiàn)從特征到人臉表情頂點坐標的映射,其中第一個全連接層將語音特征映射到人臉表情系數(shù),第二個全連接層將表情系數(shù)映射到頂點坐標值。
3 Audio2Face訓練數(shù)據(jù)集
訓練數(shù)據(jù)采用專業(yè)動作捕捉設(shè)備采集,直接捕捉演員頭骨、肌肉和皮膚的細微動作,通過多角度重建技術(shù)獲得每幀的3D 人臉數(shù)據(jù),并逐幀對齊到標準人臉模版,以得到拓撲一致的逐幀表情數(shù)據(jù)。整個數(shù)據(jù)集包括兩個演員的表演數(shù)據(jù),訓練數(shù)據(jù)集和測試數(shù)據(jù)集分別包括15000幀和2600幀的圖像數(shù)據(jù)。錄制人員通過不同情緒分別說出所有字母和指定劇本,盡可能包含不同字母的發(fā)音,以獲得更多的情緒樣本。
4 Audio2Face損失函數(shù)
損失函數(shù)(Loss Function)用來評價模型預測值和真實值 (Ground Truth)的差異度,損失函數(shù)值越小,模型性能就越好,不同模型一般使用不同的損失函數(shù)。考慮到訓練數(shù)據(jù)的模糊性,Audio2Face設(shè)計了一個包含三個損失項的損失函數(shù):(1)位置項 (Position Term):描述了期望輸出與預測輸出之間的逐頂點坐標值的均方差值,以確保輸出的每個頂點位置大致正確,位置項只約束了單幀預測誤差,并未考慮幀間關(guān)系,容易導致幀間表情動作波動;(2)運動項 (Motion Term):可確保輸出的幀間頂點運動趨勢與數(shù)據(jù)集一致,以有效避免表情動作抖動,使表情動作更趨平滑;(3)正則項(Regularization Term):用于確保網(wǎng)絡(luò)正確地將短時效應歸因于音頻信號,將長時效應歸因于情緒狀態(tài),避免學習到的情緒狀態(tài)包含與音頻信號相似的特征。對于包含多個損失項的損失函數(shù),主要挑戰(zhàn)在于如何給各個損失項確定適宜的權(quán)重值,以實現(xiàn)整體最優(yōu)并區(qū)分重要性,為此Audio2Face對每一項都進行了歸一化處理,以避免額外增加權(quán)重。
5 相關(guān)研究及解決方案
2019年浙江大學和網(wǎng)易伏羲AI實驗室曾發(fā)表了一篇由音頻源智能生成虛擬角色面部動畫的論文,該方法在網(wǎng)絡(luò)輸入、網(wǎng)絡(luò)結(jié)構(gòu)、損失函數(shù)上均與Audio2Face有所不同。關(guān)于網(wǎng)絡(luò)輸入,該論文通過對梅爾頻譜進行倒譜分析得到梅爾頻率倒譜系數(shù)(Mel Frequency C epstrum Coefficient,MFCC),將其作為聲學特征輸入網(wǎng)絡(luò)。該論文也對MFCC和線性預測編碼 (LPC)進行了分析比較,考慮到訓練數(shù)據(jù)特點,最終選擇了MFCC。
關(guān)于網(wǎng)絡(luò)結(jié)構(gòu),該神經(jīng)網(wǎng)絡(luò)由輸入層、長短時記憶層 (Long Short-Term Memory Layer,LSTM 層)、注意力層(Attention Layer)和輸出層組成,如圖2所示。該神經(jīng)網(wǎng)絡(luò)的特點是LSTM 層包含兩個雙向長短時記憶網(wǎng)絡(luò) (Bidirectional LSTM),LSTM 層將音頻特征作為輸入提取高級語義信息并輸出到注意力層學習注意力權(quán)重。這種結(jié)構(gòu)使網(wǎng)絡(luò)能夠記憶以往輸入的音頻特征,并鑒別可對當前動畫幀產(chǎn)生影響的音頻特征。
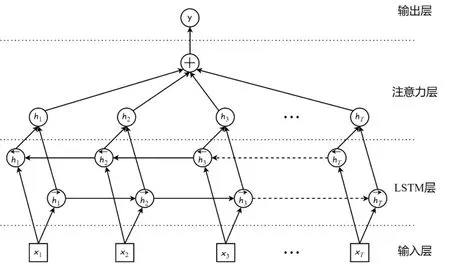
圖2 浙大論文所采用的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)
關(guān)于損失函數(shù),該論文也采用了擁有多個損失項的損失函數(shù),該損失函數(shù)包括目標損失和平滑損失,前者用于確保每個輸出的BlendShape角色表情參數(shù)基本正確,后者用于保證在訓練網(wǎng)絡(luò)時的時間穩(wěn)定性和幀間平滑度。以上兩項損失的作用與Audio2Face損失函數(shù)的位置項、運動項大致相同。總之,浙大論文與Audio2Face的主要區(qū)別在于采用不同方法來解決同一音頻源生成虛擬角色面部動畫不一致的問題,其使用注意力層來鑒別可對動畫產(chǎn)生影響的音頻特征,Audio2Face則引入情緒狀態(tài)并配合損失函數(shù)正則項,通過情緒狀態(tài)特征來確定最終的輸出動畫。
6 未來展望
上述兩種方法由于角色的眨眼與音頻之間無任何關(guān)聯(lián)性,無法準確地模擬角色眨眼和眼球運動,此外浙大論文中所述模型尚無法生成高質(zhì)量的面部圖像。Audio2Face目前仍處于公開測試階段,應用案例很少,其在升級版中將允許用戶直接通過訓練參數(shù)調(diào)整輸出結(jié)果或通過組合不同表情以實現(xiàn)復雜效果,因而制作人員可省去建模、綁定等步驟,根據(jù)實際需求智能生成音頻對應的面部動畫。總之,根據(jù)現(xiàn)有功能實現(xiàn)和未來擴展升級,Audio2Face有望能夠簡化虛擬角色面部動畫制作流程,提升虛擬角色面部動畫制作效率,有效服務影視虛擬角色動畫的智能化制作。
猜你喜歡
數(shù)學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
小哥白尼(趣味科學)(2021年12期)2021-03-16 05:40:38
小學科學(學生版)(2020年10期)2020-10-28 07:52:18
世界科學技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
文苑(2019年22期)2019-12-07 05:28:56
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年3期)2018-05-30 07:01:39
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
學生天地(2016年9期)2016-05-17 05:45:06
