基于MD-CGAN的情感語音去噪算法
2021-09-29 01:20:28李怡菲
杭州電子科技大學學報(自然科學版) 2021年5期
李怡菲,應 娜,楊 鵬
(杭州電子科技大學通信工程學院,浙江 杭州 310018)
0 引 言
語音情感識別系統是一種有效、準確的人類情感鑒別系統。語音采集過程中,除了目標人物的音頻信息,還會采集到干擾作用的冗余音頻信息,此類信息定義為噪聲[1]。在特殊應用場景下,采集過程中的環境因素(馬路上車輛行駛帶來的噪聲、餐廳中餐具碰撞的噪聲等)、系統因素(音頻傳輸時的高斯噪聲、泊松噪聲等),均會使采集到的音頻信息攜帶噪聲,降低了包含情感信息的音頻質量,影響了情感特征的提取,最終導致識別性能下降[2]。所以,語音情感去噪研究具有重要的研究意義。
傳統的語音去噪算法有譜減法、自適應噪聲抵消法、小波變換法等。張亞峰等[3]運用自適應濾波器經典算法之一的最小均方算法實現了語音信號的去噪處理。靳立燕等[4]提出一種基于奇異譜分析和維納濾波的語音去噪算法,解決了去噪處理后出現信號失真、信噪比不高的問題,更有效地去除了背景噪聲。針對傳統方法去除噪聲時情感特征恢復不明顯的問題,本文提出一種基于矩陣條件生成對抗網絡(Matrix Distance-Conditional Generative Adversarial Networks,MD-CGAN)的情感語音去噪算法,有效提升了語音情感識別率。
1 基于MD-CGAN的情感語音去噪算法
基于MD-CGAN的情感語音去噪算法在去除噪聲的同時還能有效保護情感特征。模型為了避免反卷積帶來的棋盤化效應和情感信息損失,生成器網絡采用維度保持結構;為了減少異常語音數據的影響,在生成器網絡中加入殘差結構;在損失函數中加入矩陣距離損失,并針對矩陣距離損失的權重設定進行探究,設定適用于情感特征恢復的最佳權重。
1.1 條件生成對抗網絡
原始生成對抗網絡(Generative Adversarial Nets,GAN)是由生成器(Generator, G)和判決器(Discriminator, D)組成的訓練生成式模型,將隨機噪聲和真實圖像輸入到GAN中,通過生成器和判決器之間不斷對抗學習,生成近似真實數據的圖像[5]。在對抗訓練中,生成器通過不斷迭代學習生成圖像,企圖“欺騙”判決器;判決器通過不斷學習,盡可能“不受欺騙”,判決器和生成器通過不斷的對抗訓練,尋求最優解。
由于GAN過于自由,較大的圖片出現超高維,影響生成器的訓練結果。為了解決這個問題,Mirza等[6]提出了條件生成對抗網絡(Conditional Generative Adversarial Networks,CGAN),在生成器和判決器的模型中都引入了約束條件Iy,通過約束條件指導生成器生成正確的數據。因此,CGAN將無監督的模型轉換為有監督的模型。
基于CGAN的語音去噪模型如圖1所示,Iz表示有噪聲的語譜圖,Ix表示干凈語譜圖,Ig表示去噪后的語譜圖,Iy表示語音情感類別標簽。生成器網絡G的輸入是Iz和標簽Iy,輸出是Ig,判決器網絡D的輸入是Ix和Ig,輸出為1或0。D需要將Ix判定為真,將Ig判定為假,從而使得G為了通過D的判定,將改變它的參數讓Ig更加接近Ix,而D通過反向傳播,在判定Ig和Ix方面變得更加優秀。Iy作為整個網絡的約束來指導語譜圖去噪過程。最后,訓練出適合去除語譜圖噪聲的生成器模型。
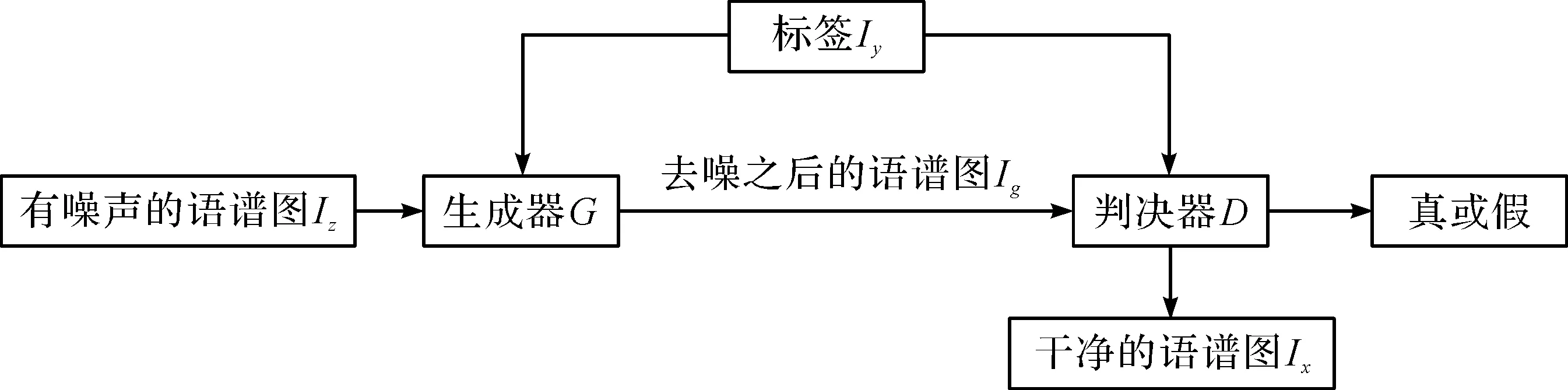
圖1 基于CGAN的語音去噪模型
1.2 生成器網絡結構
攜帶噪聲情感譜圖去噪的目的是將含噪圖像投影到干凈的圖像空間中,盡可能保留情感表征。本文的生成器網絡結構采用特征維度保持的結構,保證了情感表征的成功恢復。同時,加入殘差結構,將輸入Iz添加到最后1個卷積層的輸出,并連接到反卷積層[7]。卷積中感受野的范圍與學習結果有關,為了進一步提高情感表征的恢復效果,卷積核的大小隨通道數的變化而變化,從而學習不同感受野下的細節信息[8]。本文提出的生成器網絡的結構如圖2所示。

圖2 本文生成器網絡結構
1.3 判決器網絡結構
判決器網絡實際是二分類網絡,對去噪的結果進行評價,0代表去噪失敗,1代表去噪成功,判決器網絡評價的準確性影響模型的去噪性能。判決器網絡結構需要結合生成器網絡模型進行設計[9],判決器過強會導致生成器競爭失敗,無法進行正常去噪;判決器過弱會導致判決器的評價指標失去參考意義,最終得到的去噪模型去噪能力過弱。根據1.2小節中的生成器網絡來設計判決器網絡,網絡結構由5層卷積層組成,采用sigmoid函數將數值映射到0~1之間的概率,具體結構如圖3所示。

圖3 本文判決器網絡結構
1.4 訓練過程和損失函數
對于有噪聲語譜圖的CGAN的訓練目標如下:
minGmaxDV(D,G)=Ex~Pdata(x)[log2D(x|y)]+Ez~Pz(z)[log2(1-D(G(z|y)))]
(1)
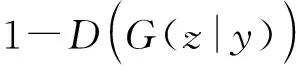
(1)給定生成器模型,優化判決器,判決器的損失函數如下:
L(D)=Ex~Pdata(x)[log2D(x|y)]+Ez~Pz(z)[log2(1-D(G(z|y)))]=
(2)
式中,Pdata(x)表示干凈的語譜圖概率分布,PG(x)表示通過生成器去噪之后的語譜圖概率分布。當輸入干凈的語譜圖時,D(x|y)輸出的概率值較大;當輸入去噪之后的語譜圖G(z|y)時,D(G(z|y))輸出的概率值較小,則1-D(G(z|y))的值較大;即判決器的訓練目標是使損失函數L(D)取得最大值[10]。當生成器G中的參數已給定時,Pdata(x)與PG(x)都可以看作是常數,通過對式(2)求導可得:
(3)
此時,判決器取得最優值。
(2)在判決器取得優的情況下,訓練生成器。生成器的訓練目標是輸出的去噪語譜圖能混淆判定器,使得判定器將去噪之后的語譜圖判定為1,即干凈的語譜圖。生成的損失函數如下:
L(G)=Ex~Pdata(x)[log2D(x|y)]+Ez~Pz(z)[log2(1-D(G(z|y)))]=
(4)
式中:
(5)
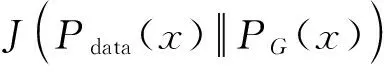
綜上所述,去噪之后的語譜圖當且僅當等于干凈的語譜圖時,生成器的損失函數取得最優值。
由于噪聲環境下提取的語譜圖與對應干凈語譜圖的矩陣距離差異過大,通過原始生成器的損失函數很難完全學習到2幅圖像間的映射關系。為此,本文提出矩陣條件生成對抗網絡(Matrix Distance-Conditional Generative Adversarial Networks,MD-CGAN),通過在生成器的損失函數L(G)中加入譜圖的矩陣距離參數來對譜圖的生成過程進行約束。該矩陣距離參數通過計算2個譜圖整體的歐氏距離得到,將譜圖損失和對抗損失結合起來共同作為損失方程。根據式(5)結合譜圖損失,得到改進后的損失方程如下:
(6)
式中,λ表示矩陣距離參數,權重Ig表示生成器的輸出,即去噪之后的語譜圖,Ix表示干凈的語譜圖,w,h,c分別表示語譜圖的寬度、高度和通道數。式(6)根據矩陣距離防止過擬合現象的發生,防止語譜圖去噪之后情感特征質量下降,使得去噪之后的語譜圖質量得到提升。
(3)返回步驟1,直到訓練達到最優值,即判決器的損失函數取得最大值,生成器的損失函數取得最小值。
當環境噪聲為白噪聲,信噪比為0 dB時,不同階段的語譜圖如圖4所示。

圖4 采用本文算法去噪前后語譜圖
圖4中,顏色的深淺表示能量的大小,顏色越淺表示能量越大,顏色越深表示能量越小。一條條橫向的條紋稱為“聲紋”,代表元音的基頻以及各次諧波,其中曲折、升降變化表示音高的變化[11]。對比3張圖可以看出,噪聲對語譜圖的“聲紋”和語音能量信息影響較大,而通過MD-CGAN去噪模型得到的語譜圖能夠較好的回復“條紋”和能量信息,與干凈的語譜圖較為相似。
1.5 矩陣距離權重選擇
生成器的損失函數中,矩陣距離權重λ影響去噪模型的整體性能。為了探究矩陣距離權重λ對本文算法去噪性能的影響,隨機選取100張攜帶噪聲的語音(包含馬路噪聲、餐廳噪聲、高斯噪聲等),設定不同矩陣距離權重λ,采用本文算法去噪后進行情感分類,分類結果如圖5所示。

圖5 不同矩陣距離權重下的識別性能比較
從圖5的結果可以看出,矩陣距離權重λ為0.76時,本文算法的去噪性能最優。
2 實驗結果與分析
在不同噪聲環境下,通過實驗來驗證本文提出的基于MD-CGAN的語音情感去噪算法的語音情感特征恢復效果。分別采用無去噪的情感識別算法、基于最小均方誤差(Least Mean Square,LMS)的經典語音去噪方法[12]和本文算法進行實驗,比較分析3種算法的情感識別率。
實驗采用語音情感CASIA數據庫和噪聲Noise-92數據庫。CASIA數據集是由中科院自動化研究所錄制的漢語語音情感數據庫,由4位專業人員(2位男生,2位女生),在沒有噪聲污染的錄音環境下錄制,包括6種情感:生氣(angry)、害怕(fear)、高興(happy)、中性(neutral)、傷心(sad)、驚奇(surprise)。整個語料庫的樣本語音采用16 kHz采樣,16 bit量化,選取相同文本50句的6種情感語音共1 200條構成實驗語音庫,每種情感有200個音頻[13]。Noise-92數據庫由荷蘭語音研究所測量的噪聲數據庫,包含100種不同的噪聲,樣本采樣率為19.98 kHz,16 bit量化,本文選取其中4種常見的噪聲,即白噪聲、餐廳噪聲、工廠噪聲和馬路上的噪聲。
針對信噪比的選擇問題,實驗選取較為典型的0 dB情況作為主要研究對象。實驗將2個語音按信噪比為0 dB進行混合,組成有噪聲的語音情感和干凈的語音情感。
實驗服務器GPU為NVIDIA TITAN RTX,訓練使用的深度學習框架為Pytorch,在MD-CGAN網絡中批次大小為32,迭代次數為100 000次,全局學習率為0.004,通過適應性矩估計(Adaptive moment estimation,Adam)優化器進行優化。經過MD-CGAN去噪后的語譜圖通過ResNet網絡進行情感分類,學習率為0.001,迭代次數為500次。實驗結果以識別率的形式呈現。
在4種噪音環境下,采用不去噪算法、LMS去噪算法和MD-CGAN去噪算法,經過ResNet識別網絡,得到的識別率如表1所示。

表1 不同噪聲環境下,不同去噪算法的情感語音識別率 單位:%
從表1可以看出,在4種噪聲環境下的情感語音識別效果較差,平均識別率為28.13%;經過傳統的LMS去噪算法去噪之后,平均情感語音識別率達到74.27%,去噪效果較好;經過本文提出的MD-CGAN去噪算法去噪后,平均情感語音識別率達到80.96%,去噪效果更加明顯,相較于不去噪識別率提升了52.83%,相較于傳統的LMS去噪算法,識別率提升了6.69%。所以,本文提出的語音去噪算法對情感語音有更好地去噪效果,有效提升情感語音識別率。
3 結束語
情感語音識別系統中常常面臨噪聲干擾,本文對此展開相關研究,分析噪聲給情感語音識別系統帶來的識別率下降等問題的原因,提出一種基于MD-CGAN去噪算法,有效提高了語音情感在噪聲環境下的識別率。但是,本文實驗所采用的數據庫是在實驗室環境下錄制的,缺少自然語音數據庫的實驗結果。在以后的研究中,會更加注重實際生活中的語音情感信息,加快語音情感識別系統在生活中的應用。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中國生殖健康(2020年5期)2021-01-18 02:59:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
家庭醫學(下半月)(2020年4期)2020-05-30 12:42:50
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
中國生殖健康(2018年5期)2018-11-06 07:15:40
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年6期)2016-08-21 13:49:38
