采用參數(shù)化解調(diào)的變轉(zhuǎn)速下柱塞泵故障診斷方法
2021-10-11 02:34:10徐孜潮群高浩寒陶建峰劉成良孟成文
西安交通大學(xué)學(xué)報 2021年10期
徐孜,潮群,高浩寒,陶建峰,2,劉成良,2,孟成文
(1.上海交通大學(xué)機(jī)械與動力工程學(xué)院,200240,上海;2.上海交通大學(xué)機(jī)械系統(tǒng)與振動國家重點(diǎn)實(shí)驗(yàn)室,200240,上海)
柱塞泵作為液壓系統(tǒng)的動力源和關(guān)鍵元件,具有功率密度大、效率高、變量調(diào)節(jié)方便等優(yōu)點(diǎn),因此在航空航天、機(jī)器人、工程機(jī)械等領(lǐng)域得到了廣泛應(yīng)用[1]。在航空航天領(lǐng)域,電靜液作動器(Electro-Hydrostatic Actuator,EHA)取消了集中式液壓能源系統(tǒng),提高了飛機(jī)的安全性、可維護(hù)性和工作效率,是多電飛行器的關(guān)鍵部件之一[2]。作為EHA核心元件之一的軸向柱塞泵,需要在10 000 r/min范圍內(nèi)變速工作[3],高轉(zhuǎn)速下柱塞泵容易出現(xiàn)空化現(xiàn)象,引發(fā)氣蝕,破壞元件,產(chǎn)生強(qiáng)烈振動,造成泵出口流量降低[4],導(dǎo)致效率下降、壓力波動、設(shè)備故障,甚至造成災(zāi)難性后果。因此,在變轉(zhuǎn)速工況下,對柱塞泵空化故障進(jìn)行及時診斷,可以為液壓系統(tǒng)的維護(hù)帶來極大的方便,節(jié)省大量的時間和成本,提高液壓系統(tǒng)的可靠性與安全性。
常用的故障診斷方法有3類:基于模型的方法、基于知識的方法和數(shù)據(jù)驅(qū)動的方法[5]。基于模型的方法要求建立較為準(zhǔn)確的數(shù)學(xué)模型,由于柱塞泵結(jié)構(gòu)復(fù)雜且內(nèi)部多物理場耦合,因此很難建立準(zhǔn)確的數(shù)學(xué)模型。基于知識的方法需要大量專家經(jīng)驗(yàn)知識作為基礎(chǔ),但是泵的動態(tài)復(fù)雜性使得專家經(jīng)驗(yàn)知識難以獲得。數(shù)據(jù)驅(qū)動的方法由于僅需要?dú)v史數(shù)據(jù)受到越來越多的關(guān)注,人工神經(jīng)網(wǎng)絡(luò)[6]、支持向量機(jī)[7]等方法均在泵空化診斷上有成功應(yīng)用。近年來,深度學(xué)習(xí)迅速發(fā)展,因其強(qiáng)大的自動特征提取能力獲得研究者的青睞。Xiao等將小波包分解的特征輸入長短期記憶網(wǎng)絡(luò)(LSTM)[8],可準(zhǔn)確識別柱塞泵的健康水平,相比支持向量機(jī)有更高的準(zhǔn)確率。Chao等將三通道振動信號轉(zhuǎn)換成RGB圖像,輸入二維卷積神經(jīng)網(wǎng)絡(luò)(CNN)實(shí)現(xiàn)柱塞泵空化等級識別[9],具有良好的抗噪性能。
然而,目前多數(shù)柱塞泵故障診斷的研究都基于恒定工況的假設(shè),對變轉(zhuǎn)速條件下柱塞泵的故障特征缺乏深入了解,限制了在實(shí)際中的應(yīng)用。變轉(zhuǎn)速工況下信號是非平穩(wěn)的,其統(tǒng)計特征隨時間變化,使得常用的信號處理方法如傅里葉變換、帶通濾波等技術(shù)都不再適用。基于階次跟蹤的方法是公認(rèn)有效的變轉(zhuǎn)速下信號處理方法,其核心思想是根據(jù)轉(zhuǎn)速曲線在角域內(nèi)對信號進(jìn)行重采樣,將時變信號轉(zhuǎn)換為角域內(nèi)的周期平穩(wěn)信號,使得恒定工況下的信號處理、故障診斷技術(shù)可以延用。傳統(tǒng)的硬件式階次跟蹤通過硬件直接獲取角域信號,成本高且有安裝空間要求。計算式階次跟蹤通過插值算法進(jìn)行重采樣,簡化了硬件設(shè)備,在變轉(zhuǎn)速故障診斷上取得了一定的效果[10],但是存在3個問題:一是仍然依賴轉(zhuǎn)速測量設(shè)備,鑒于航空領(lǐng)域?qū)τ跍p小重量、體積的極端要求,額外的硬件安裝限制了該方法的應(yīng)用;二是角域重采樣過程中的角加速度恒定假設(shè)與插值算法會帶來誤差,尤其在轉(zhuǎn)速波動大的時候誤差無法控制;三是故障信號通常含有多個分量,但階次跟蹤無法分離故障分量[11]。針對第一個問題,研究者提出無轉(zhuǎn)速計式頻率估計方法[12],基于時頻變換提取瞬時頻率曲線。Wang等對軸承振動信號進(jìn)行短時傅里葉變換,使用峰度搜索從時頻圖中提取頻率曲線[13],再做角域重采樣,提取出軸承故障特征。針對第二個問題,Olhede等提出廣義解調(diào)算法[14],利用頻率曲線構(gòu)造解調(diào)因子,解調(diào)變換將信號在時頻域內(nèi)轉(zhuǎn)換成平行與時間軸的直線,無需重采樣即可實(shí)現(xiàn)時變信號的平穩(wěn)化。Ma等將自適應(yīng)線調(diào)頻模態(tài)分解算法與廣義解調(diào)相結(jié)合[15],增強(qiáng)了算法在變轉(zhuǎn)速滾動軸承故障診斷中的自適應(yīng)能力和抗噪聲能力。針對第三個問題,傳統(tǒng)信號分解方法如經(jīng)驗(yàn)?zāi)B(tài)分解存在模態(tài)混疊等缺陷,研究者提出迭代廣義解調(diào)算法。Feng等利用迭代廣義解調(diào)精確估計其振幅包絡(luò)和瞬時頻率[16],從而構(gòu)造無交叉項(xiàng)干擾的精細(xì)時頻分辨率的時頻表示,在非平穩(wěn)條件下行星齒輪箱故障振動信號分析中取得較好的應(yīng)用成果。變轉(zhuǎn)速下的故障診斷方法,瞬時頻率曲線的準(zhǔn)確估計仍是其核心,目前基于時頻分析的方法非常依賴于時頻變換的精度,且時頻變換過程中需計算很大的參數(shù)矩陣,導(dǎo)致無法處理數(shù)據(jù)量大的信號[17]。因此,Yang等提出參數(shù)化解調(diào)方法[18],基于頻譜集中性指標(biāo)和優(yōu)化算法實(shí)現(xiàn)瞬時頻率曲線的準(zhǔn)確估計,結(jié)合迭代解調(diào)變換,實(shí)現(xiàn)時變多分量信號的分解。
針對變轉(zhuǎn)速工況下柱塞泵故障診斷問題,本文在前人研究的基礎(chǔ)上做出改進(jìn),提出一種基于參數(shù)化解調(diào)結(jié)合1DCNN-LSTM網(wǎng)絡(luò)的柱塞泵空化故障程度識別方法,結(jié)合了參數(shù)化解調(diào)的非平穩(wěn)信號處理能力與深度學(xué)習(xí)的特征提取能力。該方法利用參數(shù)化解調(diào)對變轉(zhuǎn)速下泵出口壓力信號自適應(yīng)地提取重點(diǎn)分量并重構(gòu),重構(gòu)信號輸入CNN-LSTM網(wǎng)絡(luò)提取局域特征并學(xué)習(xí)長期時序信息。本文使用Pumplinx軟件建立計算流體動力學(xué)(CFD)仿真模型,進(jìn)行仿真實(shí)驗(yàn)來獲取變轉(zhuǎn)速下柱塞泵出口壓力信號,仿真實(shí)驗(yàn)驗(yàn)證了參數(shù)化解調(diào)提取信號分量的有效性;采集實(shí)測信號進(jìn)行驗(yàn)證,表明該方法在強(qiáng)噪聲環(huán)境下仍然能以較高的精度對柱塞泵空化程度進(jìn)行識別,且該方法有效抑制過擬合,具有良好的泛化性能。
1 診斷方法原理
1.1 參數(shù)化解調(diào)
變轉(zhuǎn)速工況下設(shè)備信號一般是非平穩(wěn)多分量的,其統(tǒng)計特征隨時間變化。參數(shù)化解調(diào)算法是一種處理時變信號的方法,能夠分離提取各信號分量。其方法是通過參數(shù)估計構(gòu)建解調(diào)因子,將時變信號轉(zhuǎn)換為頻率恒定的平穩(wěn)信號,在使用帶通濾波過濾后反解調(diào)獲得分離出的信號分量,多次迭代,即可獲得多個信號分量。
本文用多項(xiàng)式信號模型來描述非平穩(wěn)信號,多項(xiàng)式相位信號在旋轉(zhuǎn)機(jī)械、雷達(dá)探測等領(lǐng)域有廣泛應(yīng)用[19],其相位是時間的多項(xiàng)式函數(shù),定義為
(1)
式中:M為信號分量個數(shù),可以事先通過時頻分析如STFT來判斷;xm(t)為觀測到的第m個信號分量;ε(t)為復(fù)雜噪聲;Am為第m個分量的振幅;P為多項(xiàng)式相位的階數(shù);am,k(k=0,…,P)為第m個分量的相位系數(shù)。
使用參數(shù)化解調(diào)方法,對非平穩(wěn)多分量信號進(jìn)行重點(diǎn)分量提取并重構(gòu),算法總共分為4個步驟,流程如圖1所示。

圖1 基于參數(shù)化解調(diào)的信號分解重構(gòu)方法流程Fig.1 Flow chart of signal decomposition and reconstruction method based on parameterized demodulation

(2)

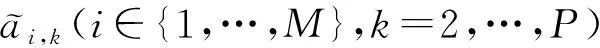

(a)原信號FFT

(b)解調(diào)后信號FFT圖2 解調(diào)變換對頻譜的影響Fig.2 Effect of demodulation transform on frequency domain
因此,構(gòu)建頻譜集中度(SCM)來量化解調(diào)后分量的集中程度,作為參數(shù)估計的指標(biāo),其定義為
DSCM=∑(|Zd(f)|q)
(3)
式中:Zd(f)是式(2)中xd(t)的傅里葉變換;q可以是任何正整數(shù),更大的q在一定程度上能夠增益目標(biāo)信號分量、抑制噪聲,從而減小優(yōu)化算法陷入局部最小值的可能性,但是更大的值并不一定會顯著改善搜索結(jié)果,本文中取q=3。
(4)
在處理含有多個分量的信號時,能量高的分量將優(yōu)先被提取。
1.1.2 解調(diào)變換 利用第1步中估計得的第i個分量的相位系數(shù),按式(2)對信號進(jìn)行解調(diào)變換。目標(biāo)分量將被變換為一個平穩(wěn)分量,集中在某一特定頻率上,在時頻圖上,該分量是一條與時間軸平行的直線。而其他分量會分布在較寬的帶寬中,噪聲則均勻地分散在所有頻段。
1.1.3 對解調(diào)信號進(jìn)行帶通濾波 將解調(diào)信號頻譜峰值所在頻率作為濾波器的中心頻率
(5)
濾波后獲得的信號為
e(t)≈Aiexp(j(ai,0+ai,1t))+e(t)
(6)
式中:e(t)為噪聲和小部分不需要的分量,其能量相比目標(biāo)分量很低;由于分量的系數(shù)被正確地估計了,Δai.k非常接近0。
1.1.4 恢復(fù)過濾后的分量 使用估計的系數(shù)來恢復(fù)過濾后的分量
(7)

從原信號中去除該分量得到信號殘差,按下式計算
(8)
迭代地執(zhí)行上述4個步驟,直到獲得所有目標(biāo)分量。
1.2 1DCNN-LSTM網(wǎng)絡(luò)
采用深度學(xué)習(xí)中較為常用的1D-CNN和LSTM網(wǎng)絡(luò)來搭建分類器。1D-CNN網(wǎng)絡(luò)能有效地從連續(xù)數(shù)據(jù)中提取特征,被廣泛應(yīng)用于早期診斷、異常檢測等領(lǐng)域[20]。LSTM網(wǎng)絡(luò)同樣是處理時間序列的強(qiáng)大工具,能夠?qū)W習(xí)長期依賴關(guān)系。
故障診斷模型結(jié)構(gòu)如圖3所示。原始數(shù)據(jù)經(jīng)參數(shù)化解調(diào)處理后輸入到1DCNN-LSTM網(wǎng)絡(luò)中,該網(wǎng)絡(luò)主要包括卷積層、池化層、LSTM層、全連接層和輸出層。
卷積層利用權(quán)值共享的卷積核對數(shù)據(jù)的局部區(qū)域進(jìn)行卷積運(yùn)算,實(shí)現(xiàn)對輸入信號的局部特征提取,卷積器的運(yùn)算公式為
yl+1,k=g(bl,k+Wl,k*Xl)
(9)
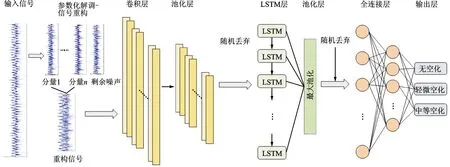
圖3 故障診斷模型結(jié)構(gòu)Fig.3 Structure of the fault diagnosis model
式中:yl+1,k為第l+1層第k個卷積核卷積后的輸出;g為激活函數(shù),此處采用線性整流函數(shù)(ReLU),增強(qiáng)網(wǎng)絡(luò)的非線性表達(dá)能力;Wl,k為第l層第k個卷積核的權(quán)重矩陣,bl,k為其偏置項(xiàng);Xl為第l層的輸入;*為卷積運(yùn)算。
池化層又稱下采樣層,可以減少數(shù)據(jù)處理量同時保留充足的有效信息,抑制模型過擬合。本模型采用最大池化方法,將池化區(qū)域內(nèi)的最大值作為池化后對應(yīng)神經(jīng)元的值
(10)
式中:pl+1,k(m)為池化后第l+1層第k個特征圖第m個神經(jīng)元的值;yl,k(i)為第l層第k個特征圖第i個神經(jīng)元的值,i∈[(m-1)L,mL],L為池化核尺寸。
LSTM是一種特殊的循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN),能夠?qū)W習(xí)長期依賴關(guān)系,又解決了傳統(tǒng)RNN在面對大數(shù)據(jù)量時的梯度消失或梯度爆炸的問題[21]。圖4是單個LSTM單元的結(jié)構(gòu),主要由遺忘門、輸入門、輸出門組成,遺忘門決定是否保留前一單元的狀態(tài),輸入門根據(jù)前一時刻狀態(tài)和此刻輸入來更新該單元的狀態(tài),輸出門控制單元的輸出。
LSTM單元的更新如公式(11)所示
(11)

?—向量積;?—向量加;σ—Sigmoid函數(shù);tanh—雙曲正切函數(shù);ft—遺忘門;it—輸入門;ot—輸出門;xt—單元輸入;ht—單元輸出;ct—狀態(tài)向量;候選狀態(tài)向量t。圖4 LSTM單元內(nèi)部結(jié)構(gòu)Fig.4 Internal structure of LSTM unit
式中:Wf、Wi、Wo分別為遺忘門、輸入門、輸出門的權(quán)重矩陣;bf、bi、bo分別為遺忘門、輸入門、輸出門的偏置項(xiàng)。
全連接層與輸出層位于模型的最后,將學(xué)習(xí)到的特征映射到樣本標(biāo)簽空間,輸出分類結(jié)果。
為提高診斷模型泛化能力,引入隨機(jī)丟棄機(jī)制,在池化層之后插入dropout層,dropout層隨機(jī)將一部分神經(jīng)元激活值置0,減少過擬合現(xiàn)象。
訓(xùn)練模型時,優(yōu)化器采用Adamt[22]來更新網(wǎng)絡(luò)參數(shù);損失函數(shù)采用稀疏多分類交叉熵,衡量真實(shí)標(biāo)簽與模型預(yù)測標(biāo)簽的相似性,其計算公式為
(12)

2 故障診斷流程
2.1 數(shù)據(jù)預(yù)處理
(1)使用參數(shù)化解調(diào)處理信號,按1.1節(jié)中的方法,提取泵出口壓力信號中能量高的前3個分量并重構(gòu)成一維壓力信號。
(2)采用滑動窗口的形式對信號進(jìn)行切片,要求切片后一個片段數(shù)據(jù)中至少包含一個轉(zhuǎn)動周期的信息。單個片段中含數(shù)據(jù)點(diǎn)1 024個,相鄰片段重合點(diǎn)數(shù)512個。對每個樣本數(shù)據(jù)進(jìn)行標(biāo)準(zhǔn)化,公式如下
(13)

(3)將數(shù)據(jù)集按照80%和20%的比例劃分為測試集與訓(xùn)練集。
2.2 1DCNN-LSTM模型建立
按照圖3的結(jié)構(gòu)建立深度學(xué)習(xí)模型,通過一維卷積層提取數(shù)據(jù)局部特征,再輸入LSTM層學(xué)習(xí)長期時序信息,添加池化層與dropout層抑制過擬合提高泛化能力。表1給出了深度學(xué)習(xí)模型主要網(wǎng)絡(luò)層的特征及參數(shù)。

表1 深度學(xué)習(xí)模型主要網(wǎng)絡(luò)特征及參數(shù)Table 1 The main network layer’s characteristics and parameters of the deep learning model
3 仿真驗(yàn)證
為了檢驗(yàn)參數(shù)化解調(diào)能否有效處理多分量時變信號以應(yīng)用于泵空化診斷,本節(jié)建立CFD仿真模型,通過仿真獲取變轉(zhuǎn)速工況下柱塞泵發(fā)生空化時出口動態(tài)壓力信號進(jìn)行驗(yàn)證,也為后續(xù)空化模擬實(shí)驗(yàn)提供參照。采用Pumplinx仿真軟件對柱塞泵進(jìn)行CFD仿真,仿真流程如下。
(1)使用三維建模軟件CREO提取被測泵的流體域模型導(dǎo)入Pumplinx,如圖5a所示,通過添加油膜來模擬柱塞泵中配流副、柱塞副、滑靴副的間隙,其中配流副和滑靴副油膜為5 μm,柱塞副油膜為10 μm。

(a)流體域

(b)網(wǎng)格劃分圖5 CFD模型流體域與網(wǎng)格Fig.5 Fluid domain and generated mesh for the CFD model
(2)對模型進(jìn)行網(wǎng)格劃分,生成的網(wǎng)格模型中包含292 707個網(wǎng)格單元,如圖5b所示。
(3)添加空化模型。仿真中采用的空化模型在Singhal[23]提出的全空化模型進(jìn)行了擴(kuò)展,添加基于道爾頓-亨利定律的平衡溶解氣體模型[24],該模型能夠較好地模擬軸向柱塞泵流體特性[25]。
(4)設(shè)置仿真參數(shù)。表2列出了仿真模型參數(shù),壓力為絕對壓力,轉(zhuǎn)速在6 000~10 000 r/min的范圍內(nèi)變化。

表2 仿真模型參數(shù)Table 2 Parameters for the simulation model
由于柱塞泵的實(shí)際工作環(huán)境常常比較復(fù)雜,工作條件惡劣,泵的信號難以避免被環(huán)境噪聲所污染。針對此種情況,將高斯白噪聲疊加在原始信號上,構(gòu)造噪聲信號,信噪比(SNR,用符號RSN表示)為0 dB。信噪比表征信號的污染程度,信噪比越低,污染越嚴(yán)重,其計算公式為
(14)
式中:Psignal和Pnoise分別為信號功率及噪聲功率。
對加噪聲信號按1.1節(jié)中的流程進(jìn)行參數(shù)化解調(diào)處理,提取能量最高的3個分量并重構(gòu)。圖6a~6c展示了原信號、加噪信號與重構(gòu)信號的時域波形圖,可見處理后的重構(gòu)信號比加噪信號更平滑,與原信號具有更高的相似性。圖6d~6f展示了原信號、加噪信號與重構(gòu)信號的STFT時頻圖,原信號中能量較高(顏色較淺)的3個非平穩(wěn)分量均被提取到重構(gòu)信號中,且加噪信號中遍布所有頻帶的噪聲均在處理后被去除,有效分量十分清晰。

(a)原信號時域波形

(b)加噪信號時域波形

(c)重構(gòu)信號時域波形

(d)原信號時頻圖
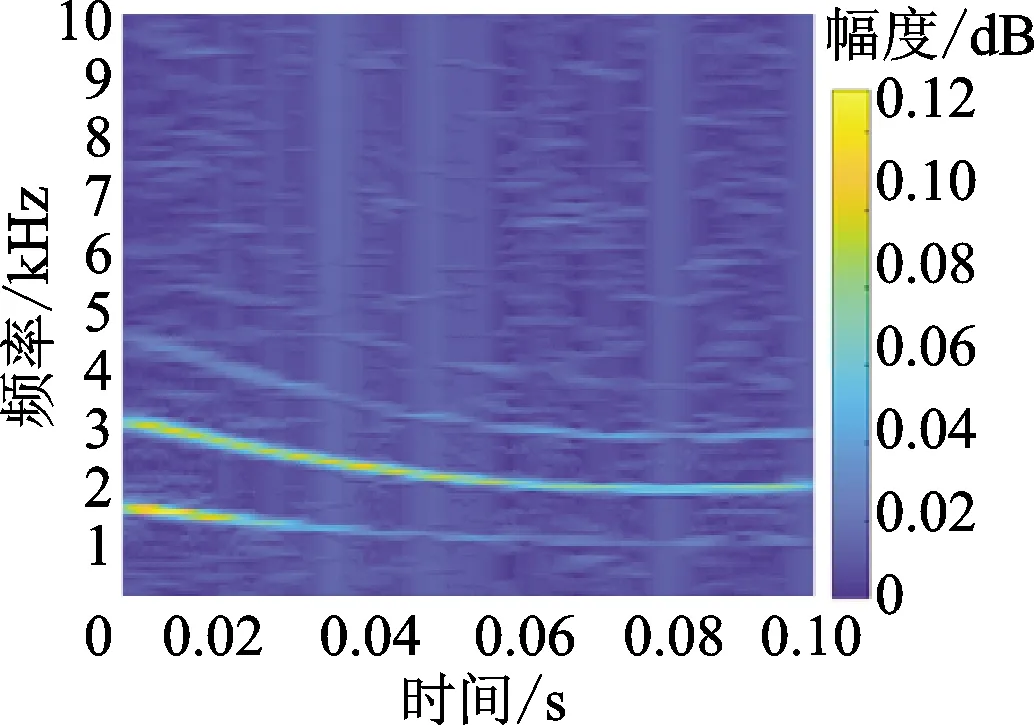
(e)加噪信號時頻圖

(f)重構(gòu)信號時頻圖圖6 參數(shù)化解調(diào)處理前后的壓力信號Fig.6 Pressure signals before and after parameterized demodulation
仿真結(jié)果表明,在噪聲環(huán)境下,參數(shù)化解調(diào)方法能夠成功地提取出非平穩(wěn)信號的分量,對噪聲有顯著的抑制效果。
4 實(shí)驗(yàn)驗(yàn)證
4.1 實(shí)驗(yàn)方案與數(shù)據(jù)采集
為了監(jiān)測軸向柱塞泵在變轉(zhuǎn)速工況下的空化情況,搭建了柱塞泵故障模擬試驗(yàn)臺,系統(tǒng)由主工作回路(圖7a)與冷卻過濾回路(圖7b)組成,通過油箱連接,實(shí)物圖如圖7c所示。主工作回路中,通過離心泵增壓,結(jié)合壓力傳感器調(diào)節(jié)被測柱塞泵進(jìn)口壓力,電機(jī)通過聯(lián)軸器帶動被測泵在不同的轉(zhuǎn)速下運(yùn)行;電磁比例溢流閥調(diào)節(jié)出口壓力,模擬負(fù)載。冷卻過濾回路中熱交換器將油溫穩(wěn)定在40 ℃左右,以減少油溫波動對柱塞泵工作狀態(tài)的影響。

(a)工作回路原理圖

(b)冷卻過濾回路原理圖

(c)試驗(yàn)臺實(shí)物圖圖7 柱塞泵故障試驗(yàn)臺實(shí)物圖Fig.7 Test rig for piston pump fault testing
實(shí)驗(yàn)臺安裝了9個主要的傳感器:壓力傳感器PS1-PS3測量泵入口、出口、回油壓力,采樣率為102 400 Hz;流量計FS1-FS2測量泵出口、回油口流量,采樣率為20 Hz;轉(zhuǎn)速計RS1測量被測泵的轉(zhuǎn)速,采樣率為102 400 Hz;溫度傳感器TS1-TS3測量泵入口、出口、回油口的油液溫度,采樣率為20 Hz。本文主要使用出口壓力信號對柱塞泵空化故障進(jìn)行診斷,由壓力傳感器PS2采集。
系統(tǒng)運(yùn)行時,傳感器連接到NI數(shù)據(jù)采集卡,通過以太網(wǎng)傳輸至計算機(jī)上存儲并進(jìn)行進(jìn)一步分析。使用測控軟件Labview定義被測泵入口壓力、出口負(fù)載、轉(zhuǎn)速來配置不同的工況,并通過PLC執(zhí)行。實(shí)驗(yàn)工況設(shè)定泵出口壓力為表壓5 MPa,入口壓力為表壓0.1~0.3 MPa。入口壓力和油液溶解氣體體積分?jǐn)?shù)是影響空化的主要參數(shù)[25],實(shí)驗(yàn)中維持油液溫度穩(wěn)定,減少其對溶解氣體體積分?jǐn)?shù)的影響,通過調(diào)節(jié)泵入口壓力來模擬空化故障的發(fā)生;柱塞泵在3 000~10 000 r/min的范圍內(nèi)運(yùn)行,轉(zhuǎn)速變化如圖8所示,變速段為有效數(shù)據(jù)。

圖8 柱塞泵轉(zhuǎn)速曲線Fig.8 Speed curve of piston pump
實(shí)驗(yàn)中,由于泵殼體不透明,無法通過觀察泵內(nèi)部氣泡來判斷空化發(fā)生情況。考慮到空化會引起泵出口體積流量下降,且流量下降程度與空化嚴(yán)重程度正相關(guān)[26],本文使用容積效率損失Δη來間接表征柱塞泵的空化程度,容積效率損失越大,空化程度越高。容積效率損失的計算公式如下
(15)
式中:qo為泵出口流量;qr為泵回油流量;Q為泵理論吸油流量;n為轉(zhuǎn)速;V為泵的排量。由于流量計采樣率較低,要求出口、回油流量qo、qr實(shí)現(xiàn)同步采樣,非采樣點(diǎn)處的Δη通過相鄰采樣點(diǎn)的Δη來估計范圍,若相鄰采樣點(diǎn)的Δη相差過大,則該段數(shù)據(jù)舍棄不用。
如表3所示,按容積效率損失分為3個空化等級[26]:無空化0%~1.5%,輕微空化2%~3%,中等空化7%~8%。在實(shí)驗(yàn)中,進(jìn)一步降低入口壓力時,泵將發(fā)生嚴(yán)重空化,會對被測泵造成不可逆的破壞,在實(shí)際應(yīng)用中,希望能在空化程度較輕的時候就能分辨出來,以便及時采取措施抑制空化發(fā)生。

表3 不同工況下的柱塞泵空化等級劃分Table 3 Cavitation degrees of piston pump under different working conditions
按第2節(jié)的流程處理數(shù)據(jù)、搭建診斷模型并進(jìn)行診斷。數(shù)據(jù)集按照80%訓(xùn)練集、20%測試集的比例隨機(jī)劃分,劃分情況如表4所示。

表4 訓(xùn)練集與測試集在不同空化等級下的樣本數(shù)量Table 4 Sample sizes of training set and testing set under different cavitation degrees
4.2 實(shí)驗(yàn)結(jié)果分析
4.2.1 參數(shù)化解調(diào)前處理的影響 一組原始信號經(jīng)過了參數(shù)化解調(diào)前處理,另一組信號未經(jīng)解調(diào)重構(gòu),分別將兩組數(shù)據(jù)作為輸入,用結(jié)構(gòu)、參數(shù)完全相同的模型進(jìn)行訓(xùn)練。圖9給出了2種方法在測試集上的分類結(jié)果混淆矩陣,每列為各空化等級的預(yù)測樣本占總樣本之比,每行為各空化等級的真實(shí)樣本占總樣本之比,對角的數(shù)值越接近1,說明分類準(zhǔn)確度越高。從圖9看出,采用參數(shù)化解調(diào)方法能夠很好地區(qū)分3種不同空化等級,而不采用該方法在無空化和輕微空化的分類上表現(xiàn)不佳,有較明顯的誤分類。為了進(jìn)一步評價該方法的分類效果,采用準(zhǔn)確率A、精確度P、回收率R及F1值這4個指標(biāo),其計算公式分別為
(16)
(17)
(18)
(19)

(a)參數(shù)化解調(diào)+CNN-LSTM

(b)CNN-LSTM圖9 使用兩種方法的診斷結(jié)果混淆矩陣Fig.9 Confusion matrixes of diagnosis results using two methods
式中:TP、FP、FN、TN是測試集中不同樣本的數(shù)量,TP是真正例,FP是假正例,FN是假負(fù)例,TN是真負(fù)例。準(zhǔn)確率A是預(yù)測正確的樣本占總樣本的比例;精確度P是衡量實(shí)際正例占預(yù)測正例的比例;回收率R指實(shí)際正例被預(yù)測為正的概率;F1是精確度與回收率的調(diào)和平均,綜合評價診斷模型的性能。
表5對比了是/否使用參數(shù)化解調(diào)在訓(xùn)練集和測試集上的分類性能評價指標(biāo),可見參數(shù)化解調(diào)方法在測試集上的各項(xiàng)指標(biāo)都比較高,其分類準(zhǔn)確率達(dá)到95.4%,比未解調(diào)的方法準(zhǔn)確率高了6.3%,說明該方法在變轉(zhuǎn)速工況下能有效地提高柱塞泵空化故障等級的識別能力。兩種方法在訓(xùn)練集上的準(zhǔn)確率很相近,但是未解調(diào)的方法在測試集上的準(zhǔn)確率下降得更多,說明對變工況下非平穩(wěn)信號進(jìn)行重點(diǎn)分量提取并重構(gòu),能夠有效抑制過擬合,提高模型的泛化能力。

表5 兩種方法的診斷性能對比Table 5 A comparison between the diagnostic performances of two methods
4.2.2 在噪聲數(shù)據(jù)集上的影響 在實(shí)際應(yīng)用中,柱塞泵工作環(huán)境惡劣,信號不可避免會被噪聲污染。為了評估診斷模型在噪聲環(huán)境下的變轉(zhuǎn)速工況空化等級識別能力,構(gòu)造一組含噪聲的信號,作為模型測試集。構(gòu)造方法是將不同信噪比的高斯白噪聲疊加到原始壓力信號上,信噪比范圍是0~10 dB。實(shí)驗(yàn)方法是,按照上一節(jié)的方法對原始壓力信號進(jìn)行參數(shù)化解調(diào)預(yù)處理后訓(xùn)練深度學(xué)習(xí)模型,然后對含噪聲信號同樣進(jìn)行參數(shù)化解調(diào)預(yù)處理后進(jìn)行測試。圖10展示了是否進(jìn)行參數(shù)化解調(diào)對噪聲環(huán)境下分類能力影響的對比。在中等空化程度下,兩種方法的診斷能力都很高,參數(shù)化解調(diào)處理對于噪聲環(huán)境下的診斷能力沒有明顯的提高;在無空化與輕微空化條件下,不經(jīng)參數(shù)化解調(diào)處理,隨著噪聲增強(qiáng),診斷準(zhǔn)確率顯著下降,在4 dB環(huán)境下無空化識別準(zhǔn)確率為67.6%,輕微空化識別準(zhǔn)確率僅為43.4%,無法滿足診斷需求,而參數(shù)化解調(diào)方法在噪聲環(huán)境下有較強(qiáng)的魯棒性,0 dB的強(qiáng)噪聲下準(zhǔn)確率維持在90%以上,說明該方法能在空化初生時就實(shí)現(xiàn)有效識別,便于及時采取措施抑制空化。

(a)無空化

(b)輕微空化

(c)中等空化圖10 兩種方法在噪聲數(shù)據(jù)集上的診斷性能對比Fig.10 A comparison between the diagnostic performances of two methods on noise dataset
5 結(jié) 論
針對變轉(zhuǎn)速工況下軸向柱塞泵故障診斷問題,本文提出一種基于參數(shù)化解調(diào)和深度學(xué)習(xí)的診斷方法。柱塞泵出口動態(tài)壓力信號經(jīng)過參數(shù)化解調(diào)處理,提取重點(diǎn)分量并重構(gòu),輸入到CNN-LSTM網(wǎng)絡(luò)訓(xùn)練,用于空化故障等級的識別。此外,將不同信噪比的高斯白噪聲疊加在原始壓力信號上構(gòu)造噪聲信號,經(jīng)由參數(shù)化解調(diào)處理后作為測試集對訓(xùn)練好的CNN-LSTM模型進(jìn)行評估。實(shí)驗(yàn)結(jié)果表明,本文方法能夠自動提取信號的重點(diǎn)分量,準(zhǔn)確地對柱塞泵空化嚴(yán)重等級進(jìn)行判斷,準(zhǔn)確率達(dá)到95.4%,相比未經(jīng)參數(shù)化解調(diào)的方法,本文方法能抑制過擬合,提高泛化能力,將分類準(zhǔn)確率提高了6.5%。在噪聲環(huán)境下,本文方法具有較強(qiáng)的魯棒性,0 dB的強(qiáng)噪聲下準(zhǔn)確率能維持在90%以上,而不采用參數(shù)化解調(diào)的方法,其準(zhǔn)確率隨噪聲增強(qiáng)顯著下降。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
鴨綠江(2021年35期)2021-04-19 12:24:18
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
電子制作(2018年11期)2018-08-04 03:25:42
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
鑿巖機(jī)械氣動工具(2016年3期)2016-03-01 04:00:25
Coco薇(2015年1期)2015-08-13 02:47:34
