基于word2vec與LDA主題模型的技術相似性可視化研究
2021-10-11 10:14:40席笑文宋欣娜
情報學報 2021年9期
席笑文,郭 穎,宋欣娜,王 瑾
(1.中國科學院檔案館,北京 100190;2.中國政法大學商學院,北京 100088;3.北京理工大學管理與經濟學院,北京 100081)
1 引 言
社會經濟的快速發展和需求的快速更迭,迫使研發主體需要不斷提高技術創新性與復雜性,以適應瞬息萬變的現代經濟。這就要求研發主體不斷地進行創新活動,來保持自身的先進性,以在激烈的市場競爭中把握先機、搶占技術制高點。而技術相似性是研發主體進行識別潛在競爭與合作伙伴、技術轉移、協同創新、并購等創新活動的重要依據[1],同時,也是企業、組織或國家進行技術情報分析的重要內容。由此可見,如何科學、準確地測度技術相似性成為值得考慮的問題。
傳統的技術相似性測度方法主要依賴于專利分類體系,然而,分類體系存在著兩個明顯的問題:一是無法直觀地反映專利的技術特征;二是不同類和子類可能出現重要的重疊,從而出現技術相似程度高的專利卻屬于不同分類的情況。隨后,學者們開始嘗試從專利引用關系角度進行分析,主要包括專利耦合、專利互引分析等,由于該方法存在專利引文施引動機的不明確性以及專利引用的滯后性等問題,使得技術相似性測度結果的準確性受到質疑。為了解決上述問題,基于文本挖掘的技術相似性測度方法開始受到研究者的廣泛關注。該類方法通常采用one-hot向量或者詞袋模型表示專利權人的技術主題,一方面,僅考慮詞的共現關系,未考慮詞間的語義關聯性,無法細粒度地表示專利權人的技術主題;另一方面,高維稀疏向量的運算煩瑣且復雜,這使得測度結果在準確性上具有較大的局限性。近年來,較為流行的深度學習方法,能夠將文本內容包含的上下文語義信息表示為低維稠密向量,能夠有效地解決上述問題。
因此,本文引入深度學習方法,構建基于word2vec和LDA(latent Dirichlet allocation)主題模型的技術相似性測度框架,并選取NEDD(nano en‐abled drug delivery)領域為例,論證本文的合理性與科學性,以期為進一步測度技術相似性的研究工作提供借鑒與參考。
2 文獻綜述
1986年,Jaffe[3]首次運用美國專利局的原始分類體系,將專利劃分為400個左右的子類,并基于此計算各發達國家間的技術相似程度,開創了基于專利分類法計算技術相似性的先河。隨后,Jaffe等[4]在進行企業間知識流動的研究時,利用專利分類法查看各個企業間專利重疊程度,來衡量企業間的技術相似性。蔡虹等[5]也借鑒此類方法對比了中國與一些創新型地區或國家的技術相似性。Kogler等[6]提出,基于專利分類法計算技術相似性時,應該將專利所屬技術類別的權重考慮在內。此類方法主要依賴于專利局的分類體系衡量專利間的技術相似性以及企業專利組合間的相似性,顯然存在以下問題:①傳統的IPC(international patent classifica‐tion)分類體系堅持以應用為主、功能為輔的分類原則,無法直接體現專利的技術主題特征;②不同的類和子類可能包含重要的重疊,可能出現技術上相似的專利但卻屬于不同分類的情況。
之后很多學者開始借鑒文獻計量學的方法測度技術相似性。Lai等[7]依據專利間的引用關系,構建專利分類體系,從而計算專利間的技術相似性。張曦等[8]利用專利共被引分析法,以選取的28家世界500強企業為研究對象,探討了企業和產業間的技術關聯以及技術的相似性。同時,也有部分學者使用專利耦合分析法測度專利相似性。例如,Huang等[9]選取臺灣地區的58家高科技電子企業為分析對象,運用專利文獻耦合方法計算企業間的技術聯系。Lo[10]在專利耦合方法的基礎上,創新性的結合相關性分析和多維尺度分析,來探究基因工程領域內重點研發機構間的技術關聯。洪勇等[11]在專利耦合分析原理的基礎上,改進了耦合強度的計算方法,并構建了企業間技術相似性可視化分析與應用流程框架,且選取平板顯示技術領域為實例進行論證。然而,該類方法由于專利引文施引動機的不明確以及專利引用存在的滯后性等問題,顯然較難真實地反應專利權人間的技術相似程度。
為了解決上述問題,學者們開始從文本挖掘的角度展開研究。例如,Arts等[2]學者通過關鍵詞間的語義相似性,來度量專利間技術相似性,且由來自不同領域的美國專家進行驗證,證明了該方法的測度效果優于基于專利分類體系的測度效果。Yoon等[12]以專利文獻為研究對象,采用文本挖掘技術構建關鍵詞的詞向量,進而運用歐幾里得距離來計算專利的相似度。彭繼東等[13]基于文本挖掘技術,以專利標題、摘要、權利要求和說明書4個文本元素的加權相似度作為專利相似度的測量。張端陽等[14]運用LDA主題模型獲取專利文檔的技術主題向量,并采用余弦相似度來測度專利間的技術相似度。該類方法往往僅考慮詞間的共現關系,忽略了詞與詞間的上下文語義關系,使得技術主題特征的表示缺乏語義,同時,存在計算復雜性高的問題。word2vec模型能夠有效解決語義關系抽取問題,且能夠將技術主題特征表示為低維稠密向量,使得從詞粒度層面對專利權人進行精細語義建模成為可能[15]。
基于此,本文構建了基于word2vec和LDA主題模型的技術相似性測度方法,嘗試從“詞粒度”層面實現專利權人的精細語義建模;同時,由于缺乏將技術相似性測度結果直觀展示并加以應用的流程框架,本文進一步構建了能夠綜合反應專利權人與技術主題關系的二模網絡[16],以全面揭示研究領域專利權人技術布局情況及技術相似性關系,為企業、組織或國家識別潛在競爭關系和合作伙伴提供參考。
3 研究方法
本節內容主要介紹了基于word2vec和LDA主題模型的技術相似性可視化研究框架的構建過程,選取專利文本為研究對象。首先,利用word2vec模型學習特征詞在文檔集合中的上下文語境信息;其次,結合LDA主題模型,構建的專利權人-專利-技術主題三層概率分布合成“詞粒度”層面的主題向量、專利文本向量及專利權人向量;再次,基于向量相似度計算指標計算專利權人間的語義相似度;最后,構建能綜合揭示專利權人-技術主題關聯的二模網絡。本文的研究方法框架如圖1所示。
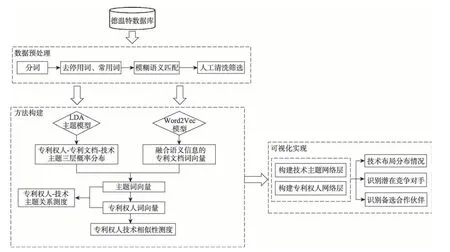
圖1 研究框架流程圖
3.1 數據預處理
本文以分析領域內的專利權人作為研究對象,通過從專利文本內容(摘要與標題)中提取技術特征詞表征專利權人的技術主題集合。因此,需要對專利權人及專利文本內容進行預處理,從而方便研究對象的選取與技術主題的提取。
1)專利權人的清洗
因不同表達形式、中途改名等會使得專利權人名稱存在重復的情況,也會因公司并購或解體出現專利權人名稱不存在的情況,故本文需要對專利權人的名稱進行統一。DII數據庫為每個專利權人均提供了唯一且標準化的專利權人代碼。因此,本文采用專利權人代碼實現專利權人名稱的清洗。
2)文本結構化處理
本文使用VantagePoint中自然語言處理相關模塊,對專利文本內容(標題和摘要)進行預處理,主要包括分詞、去停用詞、模糊語義匹配、去除低頻詞等步驟,以減少文本噪音,提高信息質量。
3.2 構建基于word2vec和LDA主題模型的技術相似性測度方法
1)利用word2vec模型學習特征詞向量
word2vec通過訓練特征詞在專利文檔中的上下文語義信息,將包含文本語義的特征詞表示為低維稠密向量。其主要包含CBOW(continuous bag-ofwords model)模型和skip-gram模型,前者是利用詞的前后n個詞來預測當前詞,后者則利用當前詞所在的語境預測前后n個詞[17]。
為了解決LDA主題模型的語義提取及高維稀疏向量的問題,本文嘗試引入word2vec學習專利文本的上下文語義信息,更為細粒度地表示專利權人的研究主題特征。具體來說,將分詞后的專利文本集合作為模型的輸入,通過不斷調參,得到包含語義信息的特征詞向量,從而為后續生成專利權人的技術主題向量奠定基礎。
2)利用LDA主題模型構建專利權人-專利-技術主題概率分布
LDA主題模型的基本思想是將文檔看作多個隱含主題的集合,然后不斷模擬文檔生成過程,從而識別語料或者文檔中的潛在主題信息,利用獲得的文檔-主題概率關系來反映每個文檔的潛在主題,通過獲得的主題-主題詞項概率分布來反映每個主題的主要內容。通過對大規模的語料庫或者文檔的建模,能夠挖掘出文檔中隱含的主題信息。
本節首先通過專利文檔集合訓練LDA主題模型,得到專利-主題、主題-主題詞項間的概率分布關系;然后,依據專利文本與專利權人所屬的對應關系,構建專利權人-專利-技術主題三層概率分布。三層概率分布的具體構建方法如圖2所示。
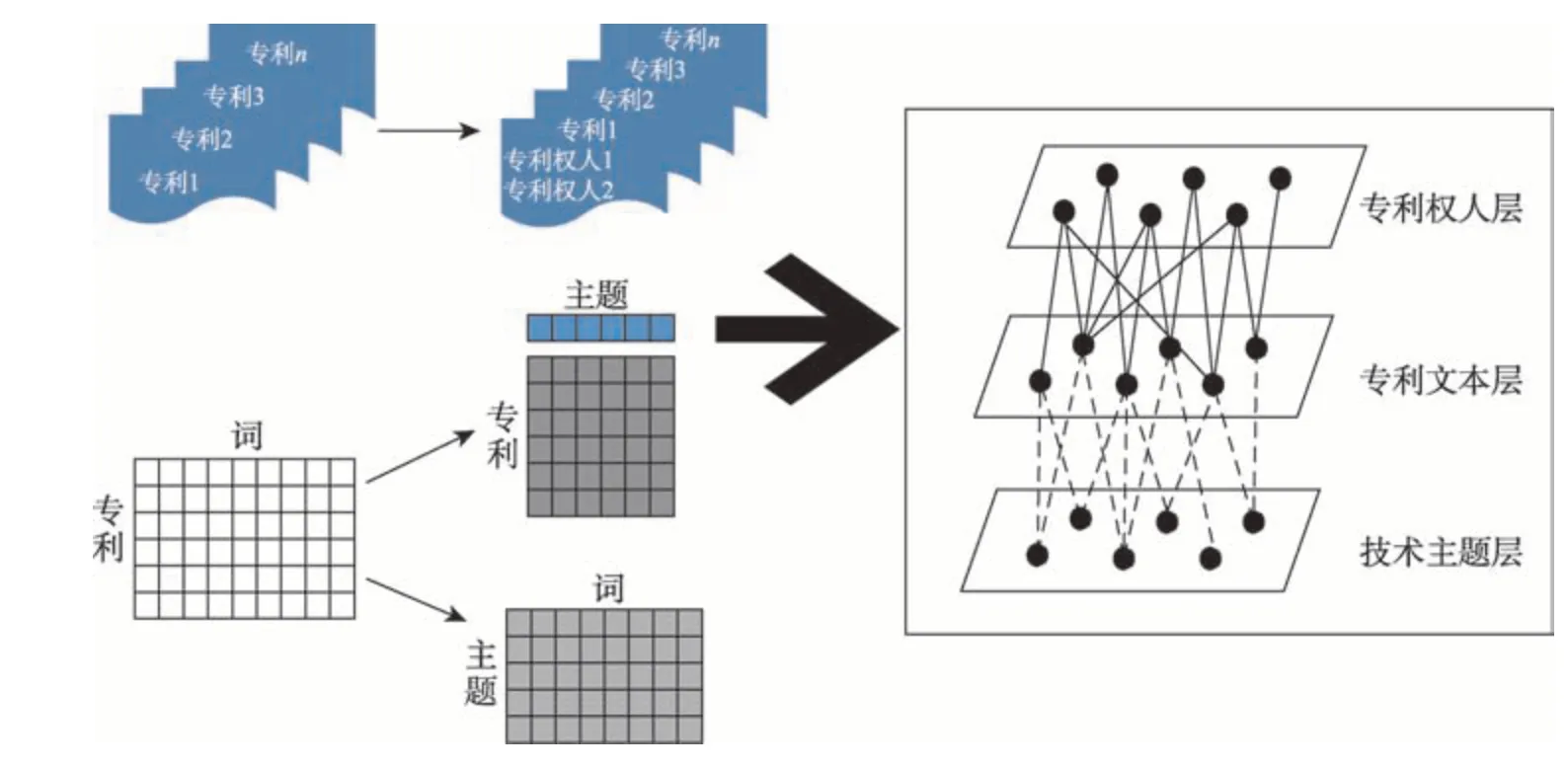
圖2 專利權人-專利-技術主題三層概率分布
3)基于詞向量的主題向量及專利權人向量表示
假設專利文檔集合D={d1,d2,…,dn},共包含V個詞{w1,w2,…,wv}。首先,利用word2vec訓練出文檔集合所包含詞的詞向量{v(w1),v(w2),…,v(wv)};然后,基于LDA主題模型得到主題-主題詞項概率分布,假設專利文本共包含N個主題{t1,t2,…,tn},其中,將第i個主題ti生成的第j個詞記為tij,將生成第j個詞的概率記為θij。本文認為,一個主題詞項所屬主題概率越高,該主題詞項就越能夠表征該主題的主題信息,也就應賦予該主題詞項更高的權重。因此,為計算出基于詞向量的主題向量,將選取每個主題中主題詞分布概率位于前h的詞,進一步對每個主題在選中的h個詞上的分布概率進行歸一化處理,即
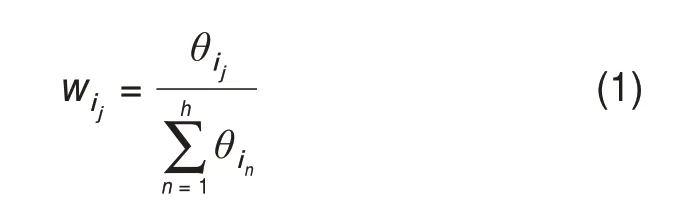
并將歸一化結果作為每個主題詞項的權重。
綜上,基于詞向量的主題向量表示為某主題中前h個詞的詞向量分別乘以其權重并加和,即
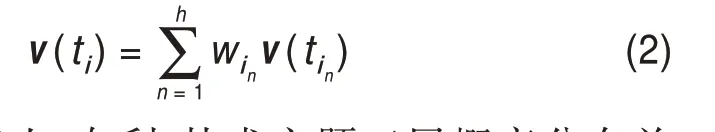
基于專利權人-專利-技術主題三層概率分布關系,由于專利文檔中一個技術主題所屬概率越高,該技術主題越能夠表征該專利文檔的主題信息,就應賦予此技術主題更高的權重。其中,將第i個專利文檔di生成的第j個技術主題dij的概率記為Xij,故首先選取專利文檔中技術主題分布概率位于前m的技術主題,并將每篇專利文檔在選中的m個技術主題上的分布概率進行歸一化,即
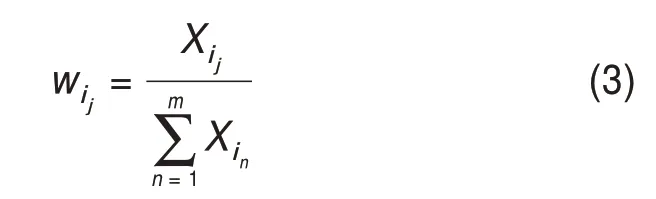
且將歸一化結果作為每個技術主題的權重。因此,基于詞向量的專利文檔向量表示為某專利文檔中前m個技術主題向量分別乘以其權重后加和,計算公式為
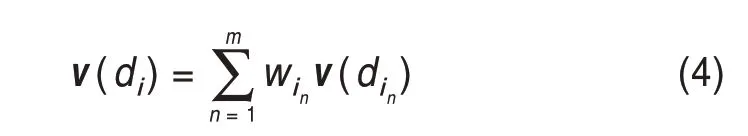
專利權人Ci的向量表示為專利權人所包含文檔向量總和與文檔總數之比,即

4)利用詞向量計算專利權人的語義相似度
將分析領域里的每一個專利權人表示為一個固定維度的空間向量后,專利權人間的技術相似性測度就轉變為專利權人向量間的空間相似度問題。若計算結果相似度值越高,則說明未來變成競爭對象或者合作伙伴的概率也就越大[18]。代表性的向量間相似度計算方法包括歐幾里得度量相似度、余弦相似度及Jaccard系數等。本文選取余弦距離來計算相似 性,Ci=(c1,c2,c3,…,cn)和Cj=(c1,c2,c3,…,cn)分 別 表示為兩個專利權人的向量,具體計算公式為
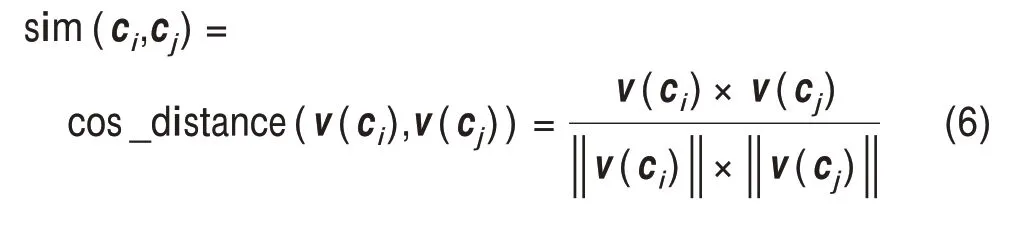
3.3 構建專利權人-技術主題二模網絡
為了更加直觀地將技術相似度測度分析結果應用于技術情報分析中,本文繪制出專利權人技術主題二模網絡,如圖3所示。其中,專利權人網絡表示專利權人間技術相似性關系。節點大小表示專利權人持有專利數量的多少,節點間連邊的粗細程度表示專利權人間所持技術的相似程度。在技術主題網絡中,節點表示所分析技術領域的熱點技術主題,節點大小表示該技術主題受關注程度。兩層網絡間的聯系表示為專利權人所包含的技術主題。該圖譜可直接作為企業技術情報人員分析特定技術領域的技術布局情況、潛在競爭對手與備選合作伙伴等分析的主要依據。
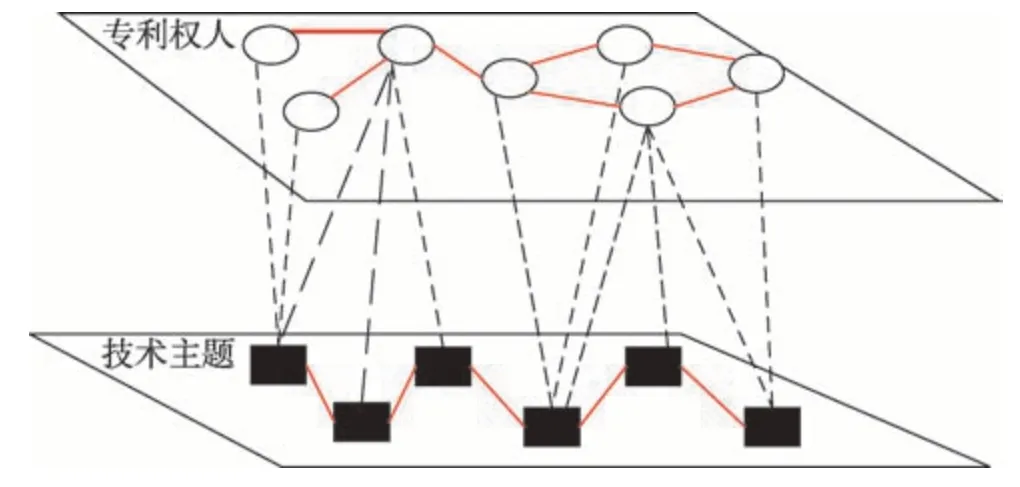
圖3 專利權人-技術主題雙層復雜網絡圖
4 實證分析
以納米導藥系統領域特定時間段內的專利權人為研究對象:首先,基于word2vec和LDA主題模型生成包含文本語義關系的專利權人向量;其次,利用余弦相似性計算專利權人間的語義相似性;再次,構建專利權人相似性網絡及專利權人與技術主題關系網絡;最后,基于實例與LDA主題模型測度結果進行對比,從而驗證該模型在技術相似性測度分析中具有更好的效果。
4.1 數據獲取及預處理
本文選取納米導藥系統為案例進行研究,采用Zhou等[19]的檢索策略在德溫特數據庫上進行檢索,時間跨度定為1999—2019年(時間截止到2019年2月16日),共檢索得到16293條記錄。
1)專利權人清洗
由于專利持有量較少的專利權人在技術領域內的影響力相對較弱,本文選擇持有專利數量前30位的專利權人作為研究對象,共持有專利2287條,如表1所示。其中,加利福尼亞大學(簡稱“加州大學”)獲得的授權專利數量最多,為234件;其次是麻省理工學院(141件)和法國國家科學研究中心(136件)。
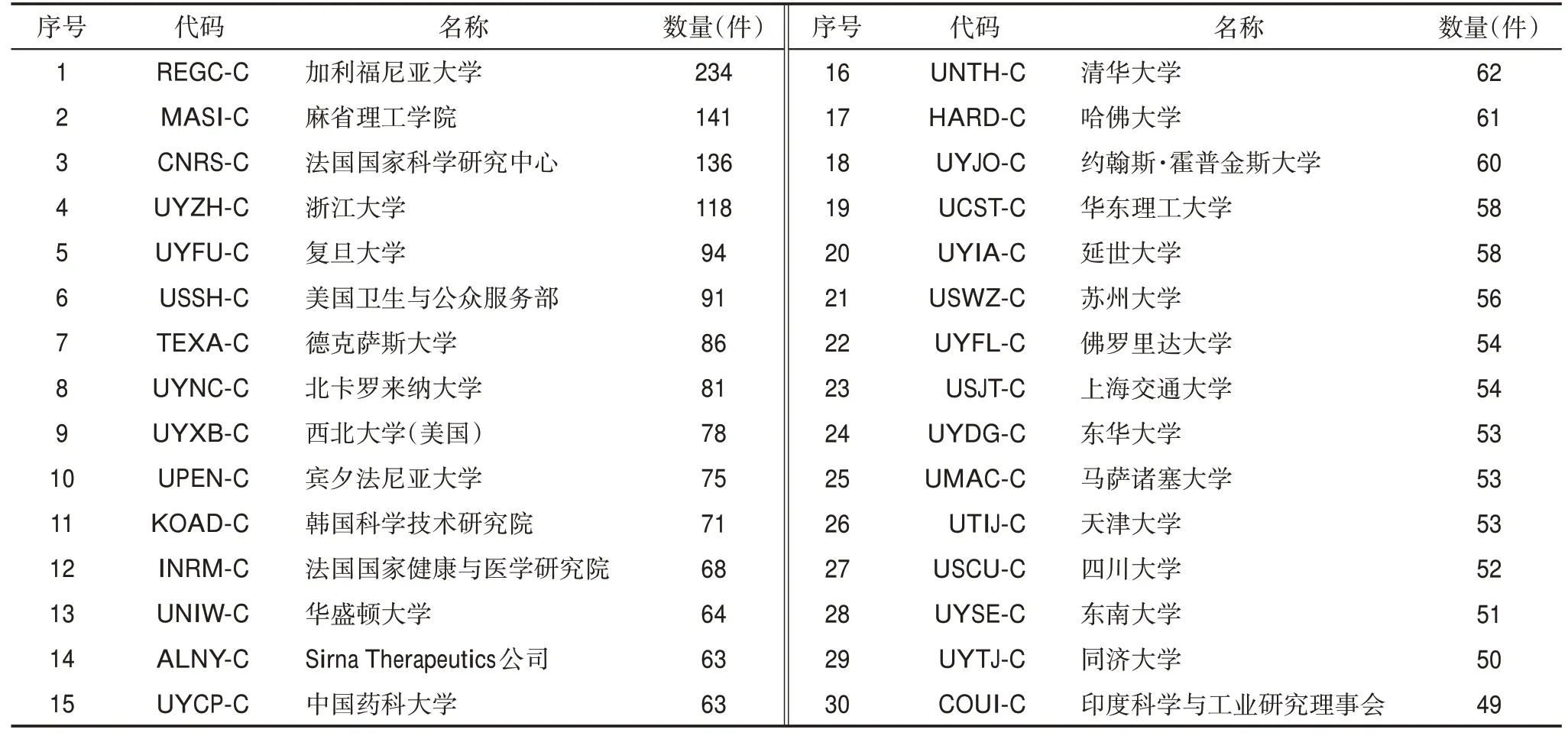
表1 Top30的專利權人及擁有專利數量
2)專利文本清洗
本文運用VantagePoint軟件實現文本內容的結構化處理。①合并專利文本的標題和摘要并進行分詞處理,選取長度為1~3、詞頻不低于4的特征詞;②經過去停用詞、去常用詞、模糊語義匹配及人工篩選等步驟,得到8000個特征詞;③以單個專利為維度,根據獲得的主題詞表分別提取16293條專利的特征詞,形成16293個詞表文件。
4.2 構建基于word2vec和LDA主題模型的技術相似性測度方法
首先,選取word2vec模型中的skip-gram模型進行專利文檔的訓練,得到包含上下文語義信息的特征詞向量,通過多次實驗結果對比,設置向量維度參數值為200,滑動窗口參數值為2。然后,基于吉布斯采樣法訓練LDA主題模型,得到專利權人-專利-技術主題三層概率分布,通過多次實驗結果對比,發現當主題數設置為20時,技術主題內容間的交叉性最小,故主題數確定為20。接著,合成“詞粒度”層面的主題向量、專利向量、專利權人向量。最后,基于余弦相似性計算專利權人間的語義相似度,部分研發主體技術相似性測度如表2所示。
由表2可知,該矩陣為對稱矩陣,對角線上的數值均為1,說明專利權人與自身的技術相似度為100%,這與實際情況相符。從矩陣中的其他數值能夠看出不同專利權人間的技術相似性。例如,矩陣中第9行第1列,數值為0.831196,則表示加州大學與西北大學(美國)所授權專利中有超過83%的研究內容相似。通過對比兩者所關注研究內容發現,加州大學與西北大學(美國)在納米藥物載體、藥物遞送、腫瘤治療納米藥物、抗菌治療納米藥物、納米檢測等內容均有交集,存在技術上的相似性,且兩者曾圍繞納米材料的合成、特性及癌癥治療等方面有過論文合作。
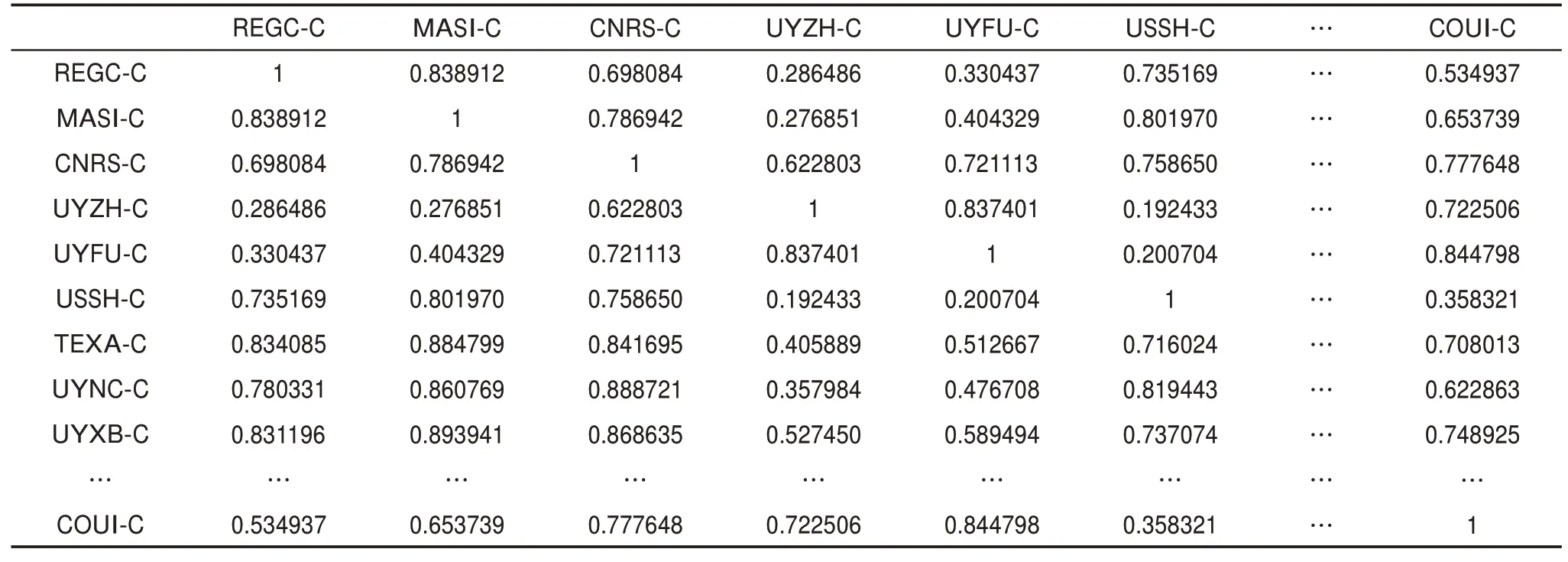
表2 部分專利權人技術相似性測度結果
4.3 構建專利權人-技術主題二模網絡
為了更加直觀地將技術相似性測度結果應用于企業、組織或國家間技術相似性分析,有效指導企業、組織或國家技術情報分析實踐,本文構建了專利權人技術相似性網絡以及專利權人-技術主題關系網絡圖。
1)專利權人技術相似性網絡有效分析
為了更加直觀地展現專利權人間的技術相似性情況,將上述技術相似性矩陣導入Gephi中,構建網絡圖如圖4所示。
由圖4可知,節點表示專利權人,節點標簽大小表示專利權人擁有專利數量的多少,節點間的連線表示專利權人間的技術相似程度,連線越粗、顏色越深則表示技術相似程度越高。以麻省理工學院為例,與其技術相似程度排名前3位的專利權人情況如表3所示。通過對比專利權人所關注領域發現,表3中3位專利權人與麻省理工學院分別在納米遞藥系統、藥物載體、納米顆粒及癌癥治療等方面具有一定的重疊性,存在技術上的相似性。初步推斷,麻省理工學院可能與這3位專利權人存在合作關系。據調查發現,麻省理工學院曾與哈佛大學合作研發名為BIND014的納米藥物遞送系統,曾與約翰斯·霍普金斯大學在Science上共同發表有關碳熱震蕩合成納米粒子方法的研究成果,曾將勒梅爾森獎授予西北大學(美國)國際納米技術研究所所長Chad Mirkin,以表彰其對納米領域作出的杰出貢獻。

表3 與麻省理工學院技術相似性排名前3位的專利權人情況

圖4 專利權人技術相似性網絡圖
2)專利權人-技術主題關系網絡有效分析
為了直觀展示專利權人的技術布局情況,將專利權人與技術主題關系矩陣導入UCINET中,構建專利權人-技術主題關系網絡圖如圖5所示。
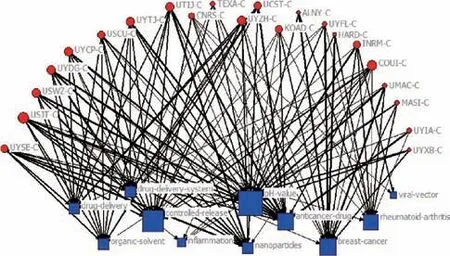
圖5 專利權人-技術主題二模網絡圖譜
首先,由技術主題層能夠明晰研究領域當前的技術熱點。如納米導藥領域的研究熱點主要為納米藥物載體、藥物遞送、腫瘤治療納米藥物、納米粒子緩控釋藥物、免疫學疾病治療納米藥物、納米檢測、納米催化物的制備等。
其次,由專利權人-技術主題關系層能夠明確專利權人的技術布局情況。如UTIJ-C主要從事納米顆粒、納米粒子緩控釋藥物等的研究,UMAC-C主要研究腫瘤治療納米藥物、抗菌治療納米藥物等,TEXA-C主要關注納米遞藥系統、納米顆粒制備、癌癥治療等。據報道,2019年,TEXA-C在PNAS(《美國科學院院刊》)發表了利用X射線和銅-半胱胺納米粒子治療深部腫瘤的研究成果[20]。
最后,結合專利權人相似性網絡與專利權人-技術主題關系網絡能夠識別潛在競爭對手及合作伙伴。關于潛在競爭對手的識別,在專利權人相似性網絡連線越粗、顏色越深的專利權人之間越具備技術上的相似性,越有可能成為技術競爭對手。專利權人可根據專利權人-技術主題關系圖,判斷競爭者的技術布局情況,并采取相對應的競爭策略以占領技術高地。
關于合作對象的選取,則需要考慮兩種不同情況:①集聚力量攻克研究領域內共同面臨的“卡脖子”問題。該類合作需要彼此間在共同關注領域上具備較高的技術相似程度與較強的技術實力,因此,需尋求在專利權人相似性網絡中彼此連線較粗、顏色較深,且在專利權人-技術主題網絡中關注同一研究領域的專利權人展開合作。例如,加州大學、復旦大學兩者具有較高的技術相似性和技術實力,且兩者共同關注腫瘤治療納米藥物的研究,基于此,推斷兩者可能存在相關的合作。通過已有合作調查發現,兩者共同開發了一種紅細胞膜包覆藥物納米晶的主動靶向仿生納米藥物,并進行了抗腦膠質瘤治療的相關研究。②解決不同技術環節的融合問題,該類合作需要彼此間在不同關注領域具備較高的技術研發實力,因此,需尋求在專利權人-技術主題網絡中關注不同研究領域,且在專利技術相似性網絡中節點較大的專利權人進行合作。例如,浙江大學在改良納米顆粒、納米材料制備的研究中具有較強的技術實力,加州大學在納米藥物緩釋控、藥物遞送方面具有較強的技術實力,基于此,推斷兩者可能存在跨研究領域的合作。據報道,在2005年中國浙江省人民政府、中國浙江大學和美國加州納米技術研究院三方共建浙江加州國際納米技術研究院,且之后與加州大學勞倫斯伯克利國家實驗室共同研發納米生物醫藥、納米遞送系統。
4.4 技術相似性測度效果評價
為了證明本文提出的方法相對于目前應用較多的LDA主題模型測度結果的精確性,進一步運用NEDD領域的數據,將兩種方法測量結果進行對比。
利用LDA主題模型測度技術相似性的部分結果如表4所示。由表4可知,相似性最大的為REGC-C與MASI-C,其值為0.990251,這表明兩個專利權人持有的NEDD領域技術幾乎完全相同。相似性最小的為UTIJ-C與INRM-C,其值為0.728429752,這表示相似程度最小的兩個專利權人仍共同持有70%以上的NEDD領域技術。
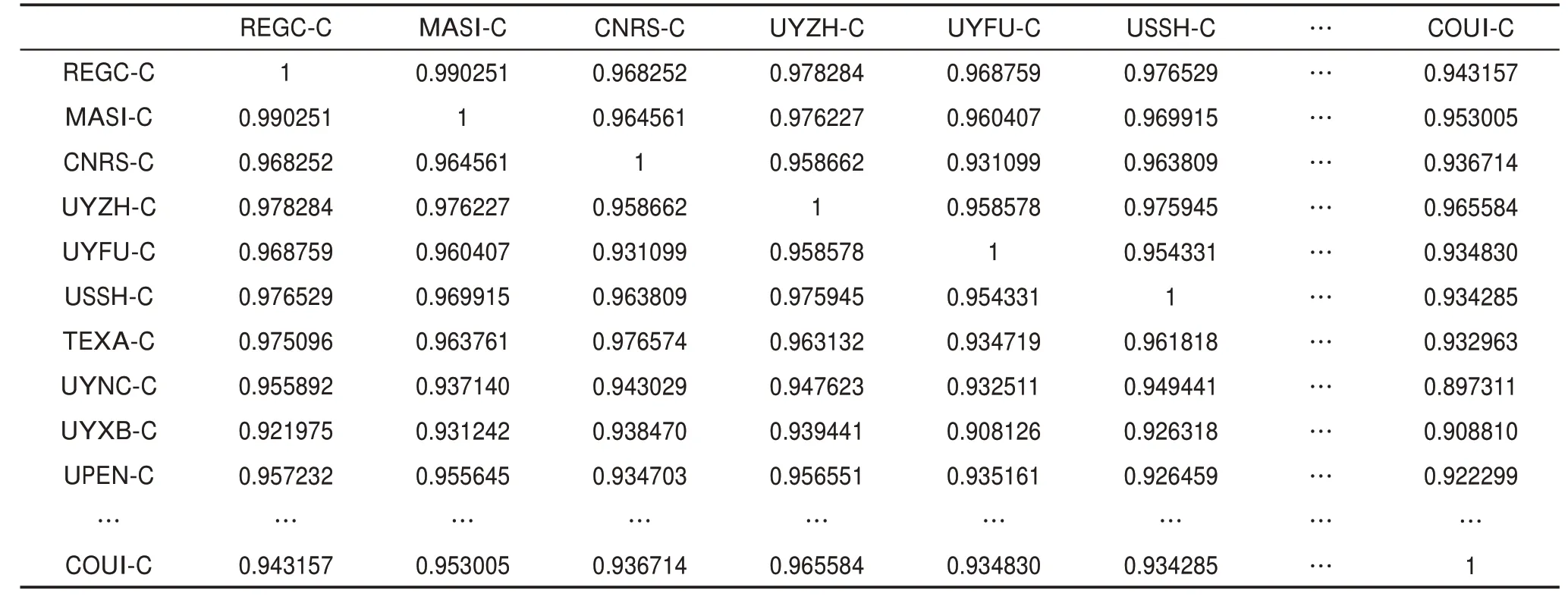
表4 基于LDA主題模型的部分研發主體技術相似性測度結果
為比較兩種方法在測度結果上的準確性,本文選取LDA主題模型測度結果排名前10位和后10位的專利權人組合作為驗證對象,通過對專利權人組合間主要關注領域進行對比,并參考專家意見對兩種方法的測度結果進行評價。
1)排名前10位的專利權人組合技術相似性測度結果對比
兩種方法的測度結果如表5所示。觀察表5可發現,以上專利權人組合中,REGC-C出現次數較多,因此,選取含有REGC-C的專利權人組合MA‐SI-C®C-C(序號1)、UYZH-C®C-C(序號3)以及USSH-C®C-C(序號5)3組進行對比研究,并在專家的指導下枚舉各個專利權人主要涉及的研究內容。
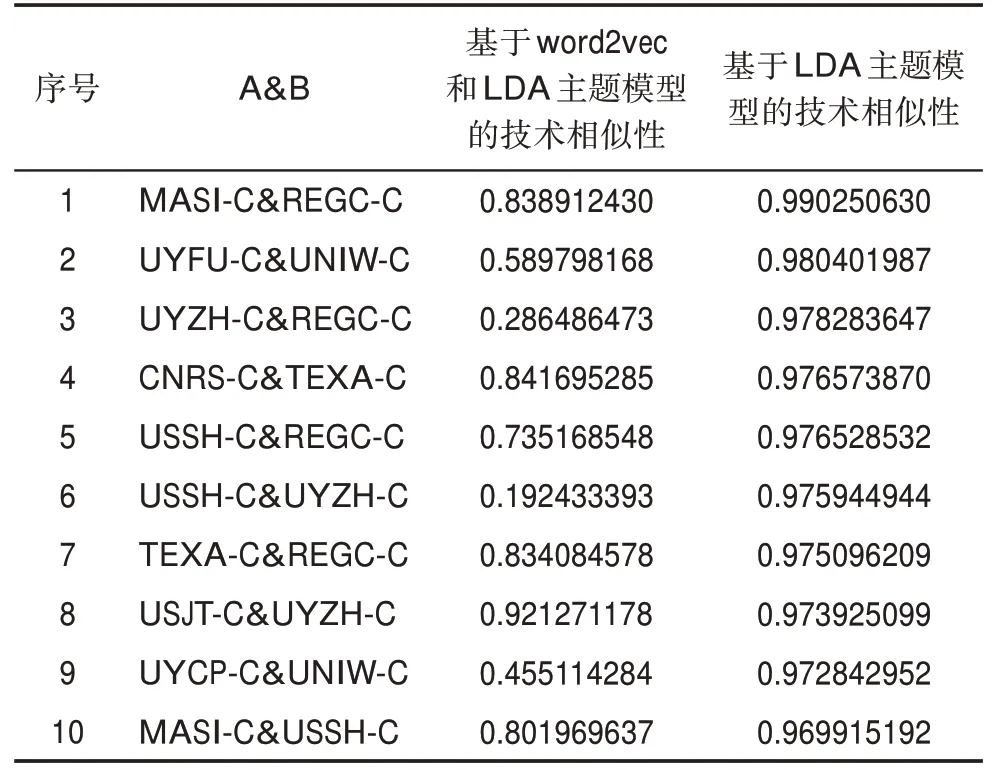
表5 排名前10位的專利權人組合兩種測度方法結果對比
REGC-C持有專利數量234件,內容涉及廣泛,如納米藥物載體、疾病治療納米藥物、納米探針、納米材料、納米遞送系統、納米測量等;MASI-C持有專利數量141,主要涉及納米藥物載體、納米藥物治療、納米粒子及納米粒子緩控釋藥物等的研究。由此可見,REGC-C與MASI-C的研究內容在納米藥物載體、納米藥物治療、納米粒子方面存在交叉性,但并非完全相同,因此,兩者間的技術相似性不應高達99%。REGC-C與UYZH-C均在納米粒子制備、納米遞送系統方面有所涉及,但REGCC明顯研究內容范圍更廣,由此判斷,兩者間的技術相似性也不應高達97%。USSH-C研究內容主要為納米藥物載體、癌癥治療納米藥物與納米粒子緩控釋藥物等,發現其與REGC-C的研究內容具有一定的重疊性,但仍存在各自獨具的研究內容,如納米粒子緩控釋藥物的相關研究,顯然兩者間的技術相似度達不到96%。
2)排名后10位的專利權人組合技術相似性對比
兩種方法的測度結果如表6所示。本節選取測度結果差異較大的UTIJ-C&INRM-C(序號1)、AL‐NY-C&UTIJ-C(序號8)以及KOAD-C&UTIJ-C(序號10)三組進行對比分析。
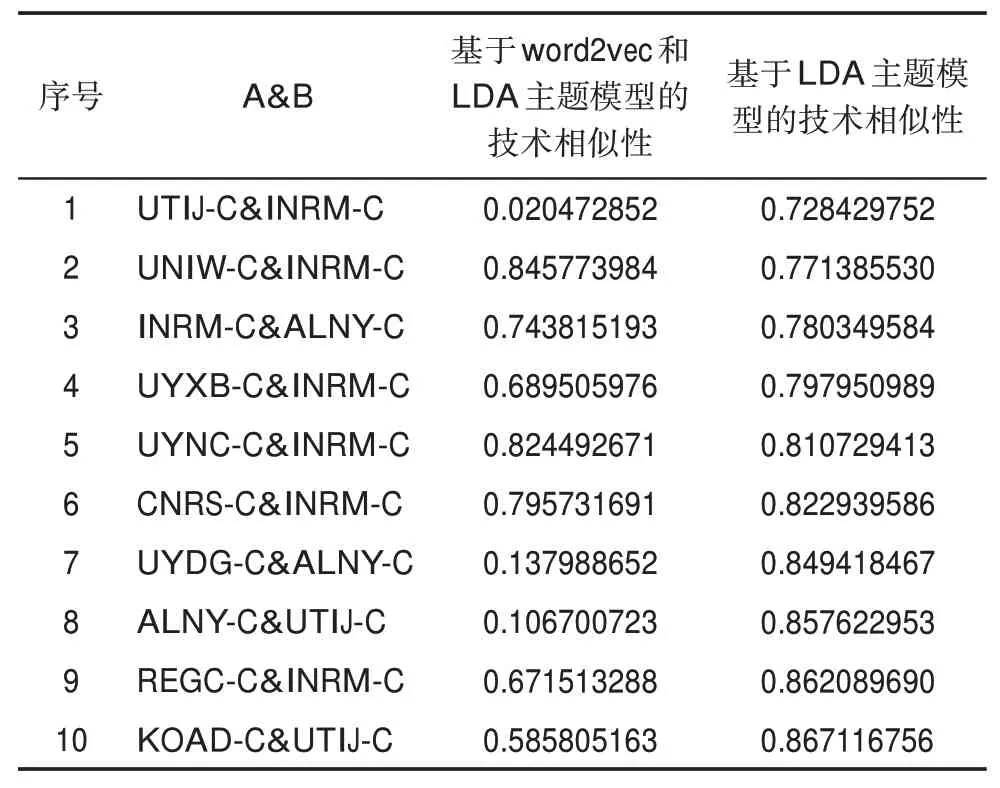
表6 排名后10位的專利權人組合兩種測度方法結果對比
INRM-C中存在部分內容(如納米粒子制備)在UTIJ-C所研究的范圍內,但INRM-C有很大一部分內容是UTIJ-C沒有涉及的,如納米藥物載體、納米粒對艾滋病、老年癡呆癥等疾病的治療等。UTIJ-C與ALNY-C、KOAD-C亦是如此,如ALNYC、KOAD-C與UTIJ-C均在納米粒子制備方面存在一定的重疊性,但各自卻擁有大部分UTIJ-C未涉及的研究方向。由此可見,LDA主題模型的測度結果值均偏高。
究其原因,發現LDA主題模型是基于詞的共現頻率來提取文本中潛在的主題信息,未考慮到專利文本上下文間的語義關聯性,導致其無法細粒度的表示專利權人的技術主題特征,使得測度結果值偏高。而word2vec模型能夠將專利文本內容中的語義信息表示為稠密低維的向量,使得從詞粒度層面表征專利權人的技術特征成為可能。因此,基于word2vec和LDA主題模型的技術相似性測度結果更為準確,與實際判斷情況相符。
5 結論
技術相似性是專利權人識別潛在競爭和備選合作伙伴的重要依據,是作為企業、組織或國家技術情報分析的主要內容。因此,技術相似性測度結果在精確性上有較高的要求。針對傳統LDA主題模型測度方法未考慮專利文本上下文間語義關系的問題,本文提出基于word2vec和LDA主題模型的技術相似性的可視化研究方法。首先,基于word2vec模型學習特征詞在文檔集中的上下文語境信息,并結合LDA主題模型,構建專利權人-專利-技術主題三層概率分布生成“詞粒度”層面的主題向量與專利權人向量;其次,通過向量相似度指標計算專利權人間的語義相似度,并在此基礎上構建能綜合反映專利權人-技術主題關系的雙層復雜網絡圖譜;最后,以NEDD領域為例驗證了該方法在技術相似性測度結果準確性上的優越性。
從方法上講,深度學習、機器學習與技術相似性測度的成功融合和應用,表明深度學習與機器學習方法的結合也可拓展應用于與此相關的技術情報分析的其他方面,如基于深度學習和機器學習結合的主題聚類及其演化分析、文本分類等。
從內容上來講,專利權人-技術主題二模網絡圖譜的展示對于企業、組織及國家技術情報分析與技術創新實踐具有重要意義。首先,通過技術主題層可以明晰研究領域的熱點技術主題;其次,通過專利權人技術相似性網絡層能夠識別企業、組織或國家主要潛在競爭對手與合作伙伴;最后,通過專利權人-技術主題層能夠直觀展示企業、組織或國家的技術布局情況。
本文僅選取了NEDD領域30家主要研究機構作為分析對象,在該領域技術情況反映的全面性上還存在局限,未來將擴大分析對象的范圍,拓展專利數據的來源。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
甘肅教育(2020年8期)2020-06-11 06:10:02
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
核科學與工程(2015年4期)2015-09-26 11:59:03
