面向視覺(jué)對(duì)話的自適應(yīng)視覺(jué)記憶網(wǎng)絡(luò)
2021-10-13 04:51:30高聯(lián)麗宋井寬
電子科技大學(xué)學(xué)報(bào) 2021年5期
趙 磊,高聯(lián)麗,宋井寬
(電子科技大學(xué)計(jì)算機(jī)科學(xué)與工程學(xué)院 成都 611731)
當(dāng)前,計(jì)算機(jī)視覺(jué)[1]與自然語(yǔ)言處理[2]相結(jié)合的跨模態(tài)任務(wù)獲得大量關(guān)注,如圖像描述生成(image captioning)[3-4]、視覺(jué)問(wèn)答(visual question answering)[5-6]等。視覺(jué)對(duì)話任務(wù)是指計(jì)算機(jī)根據(jù)圖片、圖片描述以及歷史對(duì)話信息對(duì)人所提出的問(wèn)題進(jìn)行流暢自然地回答。視覺(jué)對(duì)話技術(shù)可以應(yīng)用于大量的實(shí)際生活場(chǎng)景中,如協(xié)助視覺(jué)障礙患者完成對(duì)周圍環(huán)境的感知;如升級(jí)客服系統(tǒng),使之智能化地對(duì)消費(fèi)者所提出的問(wèn)題作答;或讓機(jī)器人擁有類似于人的交流能力。
視覺(jué)對(duì)話是一項(xiàng)充滿挑戰(zhàn)性的任務(wù)。其中,視覺(jué)共指消解問(wèn)題是關(guān)鍵的一個(gè)研究點(diǎn),它是指如何找到問(wèn)題中的代詞在圖片中的具體目標(biāo)指代。在視覺(jué)對(duì)話任務(wù)中最常用的數(shù)據(jù)集VisDial 中,有近38%的問(wèn)題以及19%的答案包含代詞,如‘he’‘his’‘it’‘there’‘they’‘that’‘this’等。文獻(xiàn)[7]通過(guò)神經(jīng)模塊網(wǎng)絡(luò)確定問(wèn)題中的代詞在歷史對(duì)話中所指代的具體實(shí)體,然后從輸入的圖片完成視覺(jué)定位。文獻(xiàn)[8]提出了適用于視覺(jué)對(duì)話的雙重注意力網(wǎng)絡(luò),它通過(guò)多頭注意力機(jī)制學(xué)習(xí)問(wèn)題與歷史對(duì)話信息之間的潛在關(guān)聯(lián),然后利用自底向上的注意力機(jī)制完成視覺(jué)上的目標(biāo)檢測(cè)。文獻(xiàn)[9]提出了遞歸的視覺(jué)注意力來(lái)對(duì)歷史對(duì)話進(jìn)行遍歷,直至找到高置信度的視覺(jué)指代。總結(jié)先前的工作,它們都是通過(guò)文本定位和視覺(jué)定位兩個(gè)步驟來(lái)解決視覺(jué)共指消解問(wèn)題。然而,每一步過(guò)程都有可能產(chǎn)生誤差,從而導(dǎo)致最終回答的問(wèn)題精度不足。誤差產(chǎn)生的主要原因是問(wèn)題中的代詞在對(duì)話歷史中所指代的目標(biāo)依然難以確定。如在歷史對(duì)話中其指代的目標(biāo)在比較靠前的輪次,或者存在語(yǔ)義相近,容易混淆的文本目標(biāo),這都容易導(dǎo)致文本定位的誤差。而由歷史對(duì)話中所找到的文本指代完成視覺(jué)定位同樣容易產(chǎn)生誤差。其原因?yàn)閳D像中背景信息比較復(fù)雜,如背景中有同目標(biāo)類似的物體,亦或其背景的顏色特征、紋理特征與目標(biāo)相近等,容易誤檢而造成誤差。同時(shí)先前工作都忽視了在很多情況下,問(wèn)題的回答不需要利用歷史對(duì)話,簡(jiǎn)單的視覺(jué)信息可以直接完成作答。
本文將對(duì)話過(guò)程中已完成定位的視覺(jué)信息存儲(chǔ)在外部的記憶庫(kù)中,從而將上述的兩個(gè)步驟進(jìn)行整合。在每回答一個(gè)問(wèn)題時(shí),不需要從歷史對(duì)話中尋找問(wèn)題中代詞具體的指代,而是直接從視覺(jué)記憶庫(kù)中進(jìn)行讀取。通過(guò)外部視覺(jué)記憶庫(kù)對(duì)文本定位和視覺(jué)定位的整合,將先前的兩步定位可能產(chǎn)生的誤差縮減為對(duì)單步視覺(jué)記憶讀取的誤差,理論上單步的誤差要小于兩步的誤差。為了更好地處理視覺(jué)信息可直接作答的情形,在讀取視覺(jué)記憶庫(kù)的時(shí)候,采用了自適應(yīng)的方式,即動(dòng)態(tài)地學(xué)習(xí)一個(gè)置信度。進(jìn)一步地,引入視覺(jué)殘差連接來(lái)緩解此問(wèn)題,從而更好地應(yīng)對(duì)不同的情況。
1 自適應(yīng)視覺(jué)記憶網(wǎng)絡(luò)
1.1 數(shù)據(jù)處理
(q2,a2),···,(qt?1,at?1)),以及候選答案A。視覺(jué)類數(shù)據(jù)包括圖片I,以及視覺(jué)記憶庫(kù)Mt=(m0,m1,···,mt?1)。
視覺(jué)對(duì)話任務(wù)中的輸入主要包括文本類數(shù)據(jù)和視覺(jué)類數(shù)據(jù)兩種模態(tài)數(shù)據(jù)。其中,文本類數(shù)據(jù)包括當(dāng)前輪次所提出的問(wèn)題qt,歷史對(duì)話Ht=(C,(q1,a1),
本文對(duì)文本類數(shù)據(jù)均利用詞嵌入方法將每一個(gè)詞映射為詞向量。隨后,映射后的當(dāng)前問(wèn)題qt利用自注意力機(jī)制得到帶權(quán)重的詞向量qa,用以表示在問(wèn)題中重要的詞語(yǔ)。同時(shí),將映射之后的歷史對(duì)話和候選答案都輸入LSTM 中,取最后一個(gè)隱藏層的狀態(tài)為其對(duì)應(yīng)特征,分別為=(h0,h1,···,ht?1)和Aλ。
視覺(jué)類數(shù)據(jù)中的圖片I利用在Visual Genome上預(yù)訓(xùn)練好的Faster R-CNN 提取目標(biāo)級(jí)特征V=(v1,v2,···,vn)。本文將提取的目標(biāo)數(shù)量固定為36 個(gè)。初始的視覺(jué)記憶庫(kù)m0是由圖片描述C對(duì)圖片I進(jìn)行軟注意力計(jì)算所得。
1.2 網(wǎng)絡(luò)模型
本文所采用的網(wǎng)絡(luò)框架為編碼器?解碼器模式。整體框架圖如圖1 所示,其中自適應(yīng)視覺(jué)記憶模塊是整個(gè)網(wǎng)絡(luò)的重點(diǎn)。它的輸入為當(dāng)前問(wèn)題的帶權(quán)重特征qa對(duì)圖片I的特征V進(jìn)行注意力計(jì)算所得到的視覺(jué)特征Vq,具體如下:
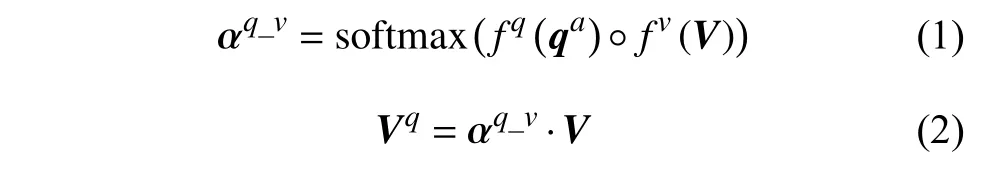
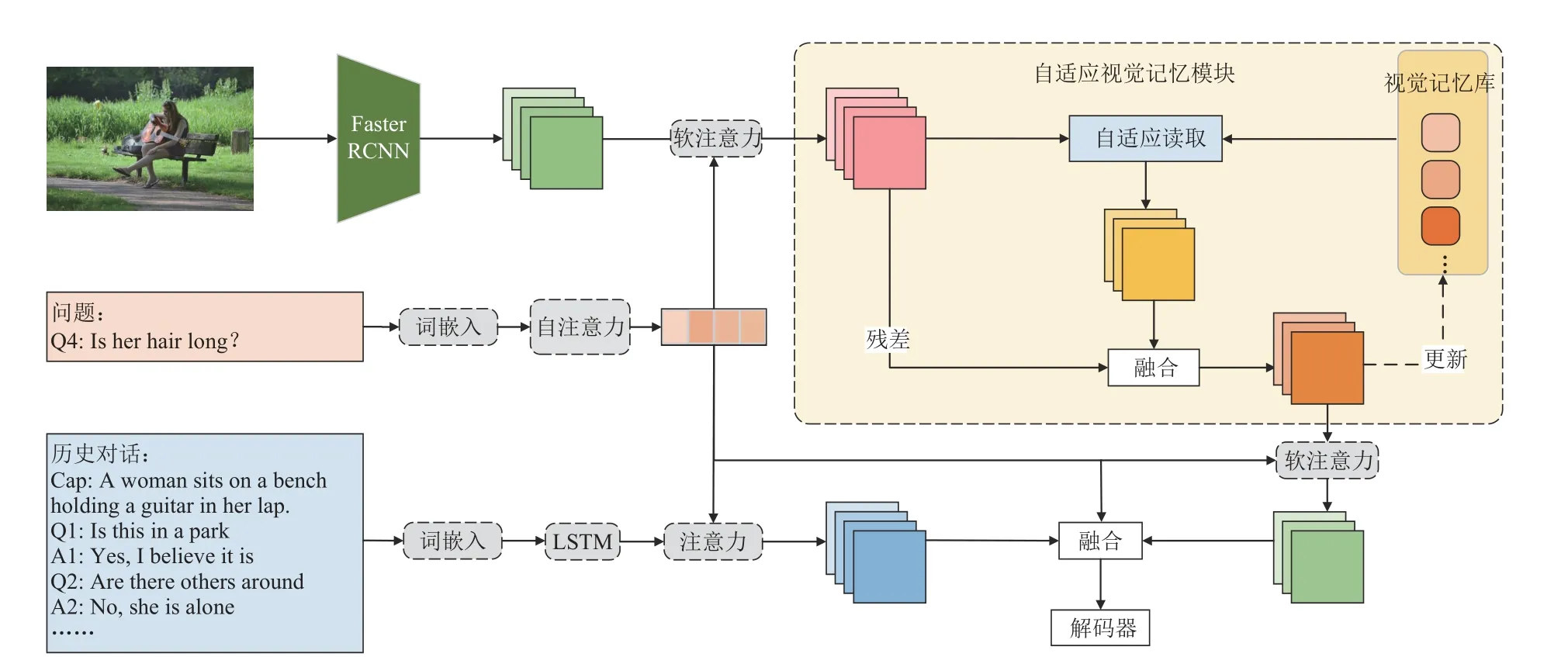
圖1 本文所設(shè)計(jì)的自適應(yīng)視覺(jué)記憶網(wǎng)絡(luò)AVMN 的框架圖
式中,fq和fv分別表示非線性變換函數(shù);“ ?”表示哈達(dá)瑪積;“·”表示矩陣相乘。
之后,Vq輸入到自適應(yīng)視覺(jué)記憶模塊中讀取外部的視覺(jué)記憶庫(kù)以完成初步的目標(biāo)定位。其詳細(xì)流程如算法1 所示。
算法1 自適應(yīng)視覺(jué)記憶模塊數(shù)據(jù)讀寫(xiě)流程:


考慮到在很多情形下問(wèn)題的回答不需要用到視覺(jué)相關(guān)的歷史信息,直接利用問(wèn)題便可從圖片中定位到目標(biāo)特征。因此,本文將Vq經(jīng)過(guò)線性變換處理后得到的特征輸入到sigmoid 函數(shù)中學(xué)習(xí)一個(gè)參數(shù)λ,并用此參數(shù)得到帶有權(quán)重的外部視覺(jué)記憶信息。然后利用軟注意力機(jī)制讀取到視覺(jué)記憶,具體如下:
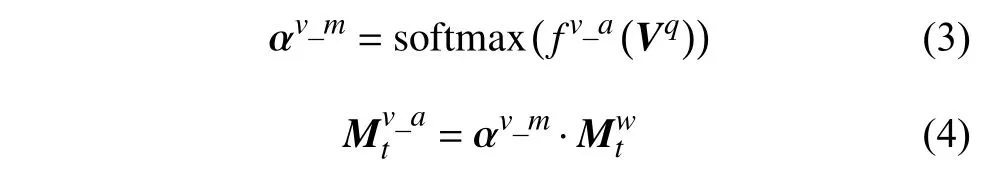
式中,fv_a表示非線性變換。進(jìn)一步地,將視覺(jué)特征Vq與取得的視覺(jué)記憶做融合,也可以視為對(duì)視覺(jué)特征Vq做殘差連接。具體融合方式為:

式中,F(xiàn)C 均表示全連接線性變換;Norm 和Gate分別表示L2 正則化運(yùn)算和門函數(shù);[,]表示向量之間的級(jí)聯(lián)操作。此階段所讀取到的最終特征mt還要被更新到外部記憶庫(kù)中。
為進(jìn)一步地提煉所讀取出來(lái)的視覺(jué)特征,使其更專注于所提出的問(wèn)題,利用經(jīng)過(guò)自注意力計(jì)算的問(wèn)題qa對(duì)mt做如下計(jì)算:
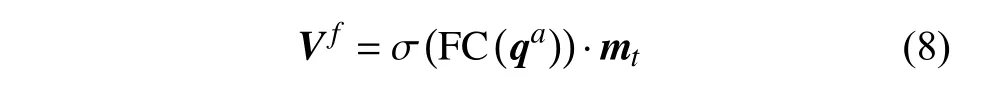
式中,σ表示sigmoid 函數(shù)。同時(shí)將歷史對(duì)話作為答案生成的補(bǔ)充信息。同樣利用注意力機(jī)制使歷史對(duì)話中的有效信息集中到相關(guān)問(wèn)題上,具體為:
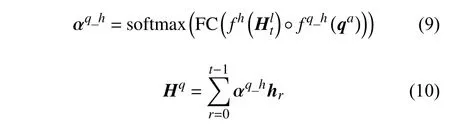
最終將當(dāng)前問(wèn)題特征、外部記憶庫(kù)所讀出來(lái)的視覺(jué)特征及歷史對(duì)話特征進(jìn)行融合,具體方式為:
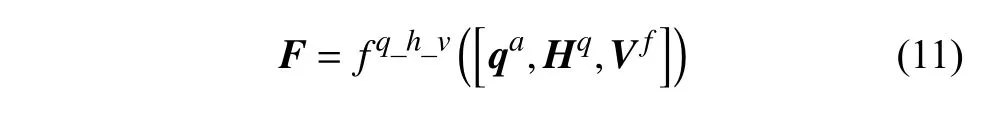
式中,fq_h_v為線性變換;[,]表示級(jí)聯(lián)操作;F則是融合之后的特征,也是整個(gè)框架中編碼器的輸出。它之后被輸入到解碼器中,用以給候選的100 個(gè)答案進(jìn)行排序。
本文中解碼器采用多任務(wù)學(xué)習(xí)機(jī)制,即判別式和生成式的融合。其中,判別式解碼器是通過(guò)計(jì)算每個(gè)候選答案的特征與編碼器輸出的融合特征之間的點(diǎn)乘相似度,用softmax 函數(shù)獲得候選答案的后驗(yàn)概率。并通過(guò)對(duì)交叉熵?fù)p失函數(shù)的最小化來(lái)訓(xùn)練模型。生成式編碼器是用LSTM 語(yǔ)言模型來(lái)直接生成答案,并通過(guò)對(duì)數(shù)似然損失函數(shù)完成訓(xùn)練。本文將兩者損失函數(shù)相加,完成對(duì)最終模型的訓(xùn)練。
2 實(shí)驗(yàn)結(jié)果及分析
2.1 數(shù)據(jù)集
本文所有實(shí)驗(yàn)都在數(shù)據(jù)集VisDial1.0[10]上進(jìn)行。該數(shù)據(jù)集采集于Amazon Mechanical Turk 數(shù)據(jù)采集平臺(tái)。其中,訓(xùn)練集的圖片均來(lái)自于COCO 2014 數(shù)據(jù)集,共包含大約12.3 萬(wàn)張圖片。驗(yàn)證集和測(cè)試集的圖片則采集于Flickr 數(shù)據(jù)集,分別包含2000 和8000 張圖片。訓(xùn)練集和驗(yàn)證集中,每張圖片對(duì)應(yīng)10 輪問(wèn)答,測(cè)試機(jī)則僅有一輪問(wèn)答。每個(gè)問(wèn)題都包含有100 個(gè)候選答案。
2.2 評(píng)價(jià)指標(biāo)
實(shí)驗(yàn)中所采用的評(píng)價(jià)指標(biāo)共4 類,包括:平均排序(mean)、平均排序倒數(shù)(mean reciprocal rank,MRR)、召回率(recall@)、歸一化折現(xiàn)累計(jì)收益(normalized discounted cumulative gain,NDCG)。
平均排序用于表示人工標(biāo)注的正確答案在所有候選答案排序中的平均排名。平均排序倒數(shù)是指將所有正確答案的排名取倒數(shù),并做平均化處理。召回率表示在所有候選答案的排序中人工標(biāo)注的正確答案位于前k所占的比例,本文將k設(shè)置為1、5 和10。歸一化折現(xiàn)累計(jì)收益則是考慮到候選答案中可能存在多個(gè)正確答案的情形,它旨在處罰那些正確但又排名較低的答案。
2.3 實(shí)驗(yàn)設(shè)置
本文所設(shè)計(jì)的模型主要基于PyTorch1.0 實(shí)現(xiàn)。模型在數(shù)據(jù)集上共訓(xùn)練15 個(gè)周期,批大小設(shè)為32,初始學(xué)習(xí)率設(shè)為0.001,經(jīng)歷一個(gè)熱身周期,并在第10 個(gè)周期后降至0.0001。訓(xùn)練優(yōu)化器選用Adam。
2.4 定量及定性實(shí)驗(yàn)
為驗(yàn)證本文所設(shè)計(jì)模型的有效性,將此模型和近年來(lái)效果最優(yōu)的算法進(jìn)行對(duì)比。對(duì)比方法包括:
1)VGNN[11]:利用圖神經(jīng)網(wǎng)絡(luò)將視覺(jué)對(duì)話模擬為基于局部觀測(cè)節(jié)點(diǎn)的圖模型推導(dǎo)。每輪對(duì)話被視為圖節(jié)點(diǎn),對(duì)應(yīng)的回答表示為圖中缺失的一個(gè)值。
2)CorefNMN[7]:利用模塊神經(jīng)網(wǎng)絡(luò)完成字詞級(jí)別的目標(biāo)定位。
3)DVAN[12]:以雙重視覺(jué)注意力網(wǎng)絡(luò)來(lái)解決視覺(jué)對(duì)話中的跨模態(tài)語(yǔ)義相關(guān)性。充分地挖掘了局部視覺(jué)信息和全局視覺(jué)信息,并利用3 個(gè)階段的注意力獲取來(lái)生成最終的答案。
4)FGA[13]:針對(duì)視覺(jué)對(duì)話的因子圖注意力方法,可以有效地整合多種不同模態(tài)的數(shù)據(jù)。
5)RVA[9]:用于遍歷歷史對(duì)話信息的遞歸注意力機(jī)制。
6)DualVD[14]:自適應(yīng)的雙重編碼模型。學(xué)習(xí)更豐富的、全面的視覺(jué)特征用以回答多樣的問(wèn)題。
表1 為本文所提出的算法AVMN 與上述方法在VisDial1.0 測(cè)試集上的實(shí)驗(yàn)結(jié)果在平均排序倒數(shù)(MRR)、召回率(recall@k)、平均排序(mean)、歸一化折現(xiàn)累計(jì)收益(NDCG)各項(xiàng)指標(biāo)上的對(duì)比。其中,AVMN*表示解碼器為判別式的,AVMN 表示解碼器采用多任務(wù)學(xué)習(xí)方式,在訓(xùn)練的時(shí)候加入了生成式損失函數(shù)。
從表1 可看出,本文所提出的AVMN 即使在沒(méi)有加入生成式損失函數(shù)的情況下已經(jīng)在各項(xiàng)指標(biāo)上全面超過(guò)了各對(duì)比方法。在采用多任務(wù)學(xué)習(xí)方式后,實(shí)驗(yàn)結(jié)果又獲得了可觀的提升,進(jìn)一步和對(duì)比方法拉開(kāi)了一定差距。具體地,完整的AVMN 在平均倒數(shù)排序MRR 上的結(jié)果比所有對(duì)比方法中最優(yōu)的方法DualVD 提升了0.6%,在召回率R@1 上比效果最佳的FGA 提升了0.59%,在同樣代表精確性的平均排序上取得了4.03 的結(jié)果。在保證答案的精確度的同時(shí),它在歸一化折現(xiàn)累計(jì)收益NDCG 上也取得了56.92 的結(jié)果,相比相關(guān)的最優(yōu)方法取得了0.7%的提升。FGA 在R@5 上的結(jié)果比AVMN 略高,但是它利用因子圖將多種類型數(shù)據(jù)進(jìn)行交互,所取得的提升建立在代價(jià)較大的計(jì)算上。以上實(shí)驗(yàn)結(jié)果證明了AVMN 的先進(jìn)性。
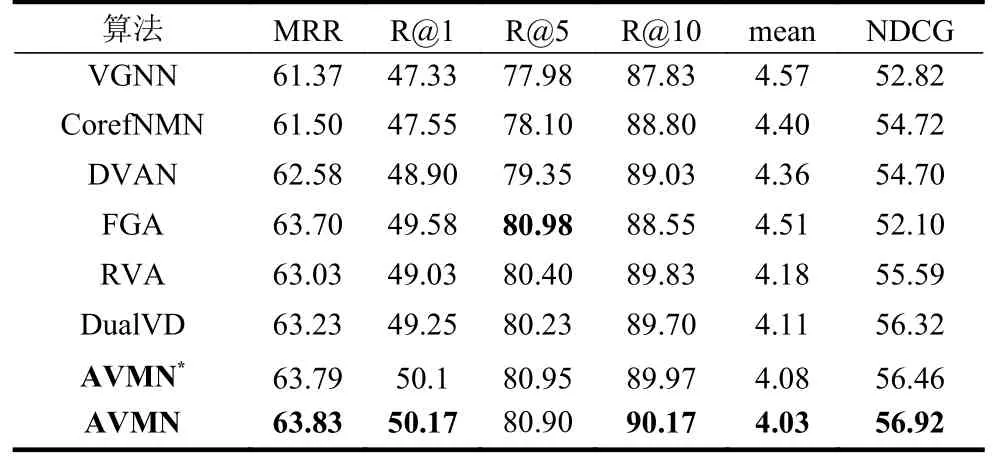
表1 本文算法與其他算法的結(jié)果對(duì)比
AVMN 在VisDial1.0 上的定性實(shí)驗(yàn)結(jié)果如圖2所示。其中Baseline 代表沒(méi)有加入自適應(yīng)視覺(jué)記憶模塊的基準(zhǔn)模型,GT 代表人工標(biāo)注的正確答案,Predict 代表AVMN 預(yù)測(cè)的答案。從圖中前兩個(gè)示例可以看出,AVMN 所生成的答案相較基準(zhǔn)模型更為準(zhǔn)確,和GT 一致。同時(shí),它也可以對(duì)不存在代詞的問(wèn)題進(jìn)行準(zhǔn)確的回答,如后兩個(gè)示例所示。

圖2 本文所設(shè)計(jì)的自適應(yīng)視覺(jué)記憶網(wǎng)絡(luò)AVMN 在VisDial1.0 數(shù)據(jù)集上的定性結(jié)果
2.5 消融實(shí)驗(yàn)
在此實(shí)驗(yàn)部分,設(shè)計(jì)針對(duì)本文所提出的算法AVMN 中主要組成部分在VISDial1.0 驗(yàn)證集上的消融實(shí)驗(yàn)。實(shí)驗(yàn)中主要設(shè)置了兩個(gè)算法的變體:1)沒(méi)有使用記憶庫(kù)的原始模型;2)僅使用了記憶庫(kù),但沒(méi)有采用自適應(yīng)讀取的模型。表2 為消融實(shí)驗(yàn)的結(jié)果展示。值得注意的是,此實(shí)驗(yàn)部分中所有模型的解碼器是判別式的。
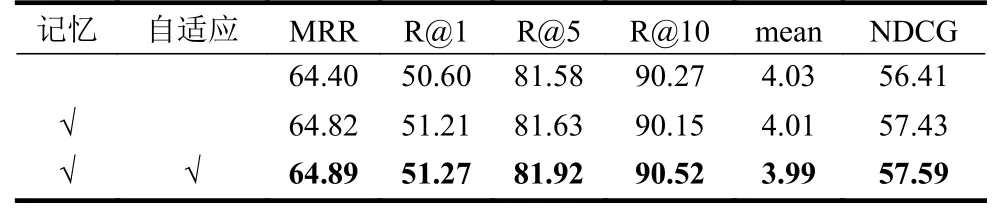
表2 針對(duì)算法主要模塊的消融實(shí)驗(yàn)結(jié)果
表2 中第一行是原始模型的實(shí)驗(yàn)結(jié)果。記憶代表AVMN 中使用的記憶庫(kù)。從數(shù)據(jù)可看出,原始模型相比完整模型的實(shí)驗(yàn)結(jié)果表現(xiàn)較差。第二行為加入記憶庫(kù)后模型的實(shí)驗(yàn)結(jié)果。它在平均排序倒數(shù)MRR 和歸一化折現(xiàn)累計(jì)收益NDCG 上提升明顯,尤其在NDCG 上,提升幅度超過(guò)1%。其原因是視覺(jué)記憶相比之前的方法縮減了定位步驟,其中間誤差減少,準(zhǔn)確性以及相關(guān)性隨之提升。第三行是加入對(duì)記憶庫(kù)自適應(yīng)讀取后完整模型的實(shí)驗(yàn)結(jié)果。相較于進(jìn)加入記憶庫(kù)后的模型,它主要在召回率R@5 和R@10 上取得了較大的提升。其原因是自適應(yīng)讀取的加入使得本不需要?dú)v史信息的問(wèn)題得到了更精確的回答。
3 結(jié)束語(yǔ)
本文設(shè)計(jì)了一種為解決視覺(jué)對(duì)話中視覺(jué)共指消解的自適應(yīng)視覺(jué)記憶網(wǎng)絡(luò)AVMN。先前的方法為緩解指代模糊的問(wèn)題,基本都是分兩步,先從歷史對(duì)話中找到代詞的具體指代,然后再?gòu)膱D片中定位到視覺(jué)目標(biāo)。視覺(jué)記憶網(wǎng)絡(luò)直接將對(duì)話歷史中已完成定位的視覺(jué)信息存儲(chǔ)到外部的記憶模塊中。這種方式將兩步縮減為一步,減少在文本定位和視覺(jué)定位兩步過(guò)程中所產(chǎn)生的誤差。同時(shí)在面臨僅需要圖片便能回答的問(wèn)題,加入了對(duì)外部視覺(jué)記憶的自適應(yīng)讀取,以及初始圖片的殘差連接。在視覺(jué)對(duì)話領(lǐng)域最流行的數(shù)據(jù)集VisDial 上的實(shí)驗(yàn)結(jié)果證明了本文所設(shè)計(jì)模型相較于其他優(yōu)秀算法的先進(jìn)性。消融實(shí)驗(yàn)驗(yàn)證了視覺(jué)記憶網(wǎng)絡(luò)內(nèi)對(duì)最終結(jié)果的影響,更進(jìn)一步地證明了它的有效性。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫(huà)刊(2022年9期)2022-11-04 02:31:42
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學(xué))(2019年6期)2019-10-10 01:01:50
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
