零樣本學(xué)習(xí)綜述
2021-10-14 06:33:50王澤深向鴻鑫
計(jì)算機(jī)工程與應(yīng)用 2021年19期
王澤深,楊 云,2,向鴻鑫,柳 青
1.云南大學(xué) 軟件學(xué)院,昆明 650504
2.云南省數(shù)據(jù)科學(xué)與智能計(jì)算重點(diǎn)實(shí)驗(yàn)室,昆明 650504
近年來,海量數(shù)據(jù)資源的不斷涌現(xiàn)和機(jī)器計(jì)算能力的不斷提高,給正在興起的機(jī)器學(xué)習(xí)技術(shù)帶來了巨大的發(fā)展機(jī)遇與挑戰(zhàn)。隨著大量研究成果已投入實(shí)際應(yīng)用,機(jī)器學(xué)習(xí)技術(shù)催生出人臉識(shí)別、智慧醫(yī)療、智慧交通等多個(gè)前沿的商業(yè)化應(yīng)用。機(jī)器學(xué)習(xí)旨在通過計(jì)算機(jī)來模擬或者實(shí)現(xiàn)人類的學(xué)習(xí)行為,讓計(jì)算機(jī)具備能夠從海量數(shù)據(jù)中獲取新的知識(shí)的能力并不斷地改善自身的性能。這也使得傳統(tǒng)的基于監(jiān)督的機(jī)器學(xué)習(xí)算法在某些識(shí)別(人臉識(shí)別、物體識(shí)別)和分類等方面的性能已接近甚至超過人類。
然而擁有如此高超的性能所需要付出的代價(jià)是大量的人工標(biāo)記數(shù)據(jù)[1],這在實(shí)際應(yīng)用中會(huì)消耗大量的財(cái)力、物力。因此,為了將機(jī)器學(xué)習(xí)技術(shù)更好地應(yīng)用于實(shí)際問題中,減少大量標(biāo)記數(shù)據(jù)對(duì)機(jī)器學(xué)習(xí)技術(shù)的約束,需要相關(guān)技術(shù)具備有像人類一樣能夠思考、推理的能力[2],而零樣本學(xué)習(xí)技術(shù)在實(shí)現(xiàn)這個(gè)能力的過程中具有重要意義。通過這幾年的不斷研究,零樣本學(xué)習(xí)技術(shù)已經(jīng)具備了較為完整的理論體系。但是,零樣本學(xué)習(xí)技術(shù)在應(yīng)用方面卻沒有較好的總結(jié)。所以本文將回顧零樣本學(xué)習(xí)近些年來在商業(yè)應(yīng)用上的價(jià)值,為零樣本學(xué)習(xí)技術(shù)構(gòu)建一套比較完善的應(yīng)用體系。
本文主要綜述了零樣本學(xué)習(xí)的理論體系和應(yīng)用體系。第1 章論述零樣本理論體系中的相關(guān)基礎(chǔ)概念。第2章列舉經(jīng)典的零樣本學(xué)習(xí)模型。第3章構(gòu)建零樣本學(xué)習(xí)的應(yīng)用體系。第4 章討論零樣本學(xué)習(xí)應(yīng)用中的挑戰(zhàn),并對(duì)研究方向進(jìn)行了展望。
1 零樣本相關(guān)基礎(chǔ)理論
1.1 研究背景
在日常生活中,人類能夠相對(duì)容易地根據(jù)已經(jīng)獲取的知識(shí)對(duì)新出現(xiàn)的對(duì)象進(jìn)行識(shí)別[3]。例如:帶一個(gè)從未見過老虎的孩子到動(dòng)物園,在沒見到老虎之前,告訴他老虎長得像貓,但是比貓大得多,身上有跟斑馬一樣的黑色條紋,顏色跟金毛一樣。那么當(dāng)他見到老虎時(shí),會(huì)第一時(shí)間認(rèn)出這種動(dòng)物。通過已知的貓、金毛、斑馬推理出老虎過程如圖1所示。
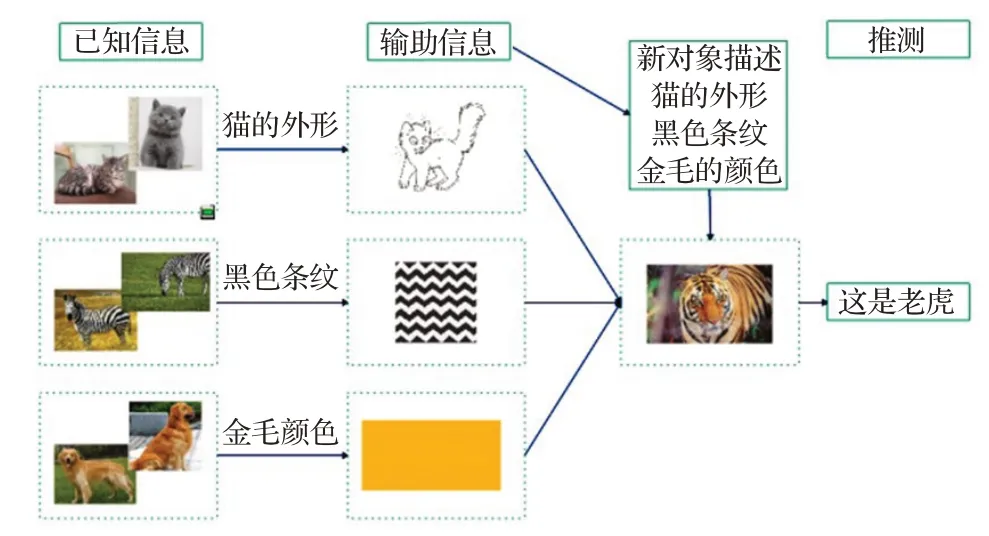
圖1 零樣本學(xué)習(xí)推理過程Fig.1 Reasoning process of zero-shot learning
這種根據(jù)以往獲取的信息對(duì)新出現(xiàn)的事物進(jìn)行推理識(shí)別的能力,在2009年被正式提出,并取名為零樣本學(xué)習(xí)(Zero-Shot Learning,ZSL)[4-5]。正因?yàn)榱銟颖緦W(xué)習(xí)具有推理能力,不需要大量的人工標(biāo)記樣本,對(duì)于一些實(shí)際問題中(如醫(yī)療影像圖像、瀕危物種識(shí)別等)具有極高的商業(yè)價(jià)值[3]。同時(shí),零樣本學(xué)習(xí)技術(shù)也能夠突破現(xiàn)有監(jiān)督學(xué)習(xí)技術(shù)無法擴(kuò)展到新出現(xiàn)的分類任務(wù)的難題。因此,零樣本學(xué)習(xí)成為機(jī)器學(xué)習(xí)領(lǐng)域最具挑戰(zhàn)性的研究方向之一[6]。
1.2 定義
將上述的推理過程抽象為通過已知信息加上輔助信息進(jìn)而推斷出新出現(xiàn)對(duì)象的類別。因此,推理過程中已知的信息(貓、斑馬、金毛)為訓(xùn)練集,輔助信息(貓的外形、黑色的條紋、金毛的顏色)為訓(xùn)練集與測試集相關(guān)聯(lián)的語義信息[7],推測(老虎)為測試集。訓(xùn)練集中貓對(duì)應(yīng)的貓類、斑馬對(duì)應(yīng)的馬類、金毛對(duì)應(yīng)的狗類,在訓(xùn)練前就已知,為可見類(seenclass);測試集中虎對(duì)應(yīng)的虎類,在訓(xùn)練過程中沒見過,為未可見類(unseenclass)。設(shè)X為數(shù)據(jù),Y為標(biāo)簽,S為可見類,U為不可見類,Tr為訓(xùn)練集類別,Te為測試集類別,則零樣本學(xué)習(xí)的定義為fzsl:X→YU,即通過訓(xùn)練可見類數(shù)據(jù)提取出對(duì)應(yīng)的特征,加上輔助知識(shí)的嵌入,最終預(yù)測出不可見類。其中Te與Tr不相交;Tr為S,Te為U。值得注意的是,預(yù)測時(shí)如果出現(xiàn)訓(xùn)練集對(duì)應(yīng)的類別,則無法預(yù)測。
由于零樣本學(xué)習(xí)依賴的已知知識(shí)仍是一種帶標(biāo)簽的數(shù)據(jù),可以得知零樣本學(xué)習(xí)是一種特殊的監(jiān)督學(xué)習(xí)技術(shù)。對(duì)比傳統(tǒng)的監(jiān)督學(xué)習(xí),其定義為f:X→Y,其中Tr包含于Te,Te與Tr均為S,可見與零樣本學(xué)習(xí)最大的區(qū)別是測試集的類別是否包含于訓(xùn)練集的類別。對(duì)比于廣義零樣本學(xué)習(xí),一種特殊的零樣本學(xué)習(xí),其定義為fgzsl:X→YU∪YS,其中Te與Tr不相交。Tr為S,Te為S和U。可見與零樣本學(xué)習(xí)最大的區(qū)別是預(yù)測時(shí)訓(xùn)練集對(duì)應(yīng)的類別是否能預(yù)測出來。三者的區(qū)別如表1所示。

表1 三種學(xué)習(xí)比較Table 1 Comparison of three kinds of learning
1.3 關(guān)鍵問題
由定義可知,零樣本學(xué)習(xí)是一種特殊的監(jiān)督學(xué)習(xí)。其存在的問題除了傳統(tǒng)的監(jiān)督學(xué)習(xí)中固有的過擬合問題外[8],還有領(lǐng)域漂移、樞紐點(diǎn)、廣義零樣本學(xué)習(xí)、語義間隔四個(gè)關(guān)鍵問題。
1.3.1 領(lǐng)域偏移問題(Domain Shift)
同一事物在不同領(lǐng)域的視覺效果相差太大。2015年,F(xiàn)u 等人[9]提出,當(dāng)可見類訓(xùn)練出來的映射應(yīng)用于不可見類的預(yù)測時(shí),由于可見類和不可見類所屬的域不同,可見類與不可見類相關(guān)性不大,不同域在同一事物的視覺特征上可能相差很大,在沒有對(duì)不可見類進(jìn)行任何適配的情況下,會(huì)出現(xiàn)領(lǐng)域偏移問題[10]。例如,在現(xiàn)實(shí)生活中,知道老虎的尾巴與兔子的尾巴在視覺上相差很遠(yuǎn)。如圖2所示。然而當(dāng)預(yù)測的類別為老虎,所給的輔助信息中有尾巴這一屬性,用兔的尾巴訓(xùn)練出來的效果不符合實(shí)際效果。

圖2 老虎尾巴與兔子尾巴Fig.2 Tiger tail and rabbit tail
目前學(xué)者們提出的解決辦法主要有:第一種是在訓(xùn)練過程中加入不可見類數(shù)據(jù)[9,11-35],即建立直推式模型。典型的例子有文獻(xiàn)[9]利用不可見類的流形,提出多視圖嵌入框架緩解領(lǐng)域偏移問題。第二種是對(duì)訓(xùn)練數(shù)據(jù)強(qiáng)制增加約束條件/信息[10,13,36-40],即建立歸納式模型。第三種是生成偽樣本到測試過程中,即建立生成式模型[13,41-60],其本質(zhì)是將零樣本學(xué)習(xí)轉(zhuǎn)換為傳統(tǒng)的有監(jiān)督學(xué)習(xí)。最經(jīng)典的例子是SAE[61]模型,在圖像空間嵌入語義空間的過程中添加約束條件,盡可能地保留圖像空間中的信息。
當(dāng)然,上述的解決方案都是建立在可見類與不可見類的數(shù)據(jù)分布在樣本級(jí)別上是一致的。而文獻(xiàn)[62]則直接通過聚類的方法獲取不可見類的數(shù)據(jù)分布。
1.3.2 樞紐點(diǎn)問題(Hubness)
某個(gè)點(diǎn)成為大多數(shù)點(diǎn)的最鄰近點(diǎn)。2014 年,Dinu等人[63]提出,從原始空間投影到目標(biāo)空間的過程中,某個(gè)點(diǎn)會(huì)成為大多數(shù)節(jié)點(diǎn)最鄰近的點(diǎn),同時(shí)也指出樞紐點(diǎn)問題是高維空間中經(jīng)常會(huì)出現(xiàn)的問題。例如,在使用零樣本學(xué)習(xí)模型進(jìn)行分類時(shí),采用的算法為最鄰近節(jié)點(diǎn)算法(K-Nearest Neighbor,KNN),則可能會(huì)出現(xiàn)一個(gè)點(diǎn)有幾個(gè)甚至幾十個(gè)最鄰近節(jié)點(diǎn),會(huì)產(chǎn)生多種不同的結(jié)果,導(dǎo)致模型的效果不佳。如圖3 所示。但樞紐點(diǎn)問題不僅存在于高維空間,Shigeto等人[64]指出低維空間中也會(huì)出現(xiàn)樞紐點(diǎn)問題,維度越高,出現(xiàn)樞紐點(diǎn)問題越嚴(yán)重。
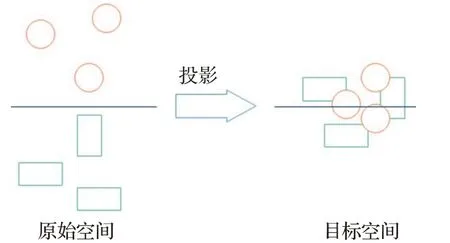
圖3 樞紐點(diǎn)問題Fig.3 Hubness problem
目前學(xué)者們提出的解決辦法主要有兩種:第一種是使用嶺回歸模型,建立從低維向高維映射,在計(jì)算機(jī)視覺中則為建立從語義到視覺的映射,這種方法也稱為反向映射[11,13,21,64-67]。其中,文獻(xiàn)[64]直接將圖像的特征空間進(jìn)行嵌入,建立語義到視覺的映射,有效地緩解了樞紐點(diǎn)問題。第二種是使用生成式模型[11,14,23,55,68-70],生成偽樣本,加入到測試過程中。
此外,非主流方法有文獻(xiàn)[63]提出一種優(yōu)化的近鄰搜索算法,從根本上解決最近鄰搜索問題。文獻(xiàn)[65]則將嶺回歸模型替換為Max-Margin Ranking,來緩解樞紐點(diǎn)問題。
1.3.3 廣義零樣本學(xué)習(xí)(Generalized Zero-Shot Lear-ning,GZSL)
訓(xùn)練集類別與測試集類別互斥。本章已經(jīng)對(duì)廣義零樣本學(xué)習(xí)的定義進(jìn)行描述以及同零樣本和傳統(tǒng)監(jiān)督學(xué)習(xí)進(jìn)行比較。零樣本學(xué)習(xí)的前提條件是測試集與訓(xùn)練集沒有交集,即可見類等于訓(xùn)練集,不可見類等于測試集。這意味著測試階段,如果樣本來自訓(xùn)練集,則無法預(yù)測。這在實(shí)際生活中是不現(xiàn)實(shí)的。因此,2019年,Wang 等人[71]提出廣義零樣本學(xué)習(xí),訓(xùn)練集仍是可見類數(shù)據(jù),測試集則為可見類與不可見類數(shù)據(jù)的混合。零樣本學(xué)習(xí)與廣義零樣本學(xué)習(xí)如圖4所示。

圖4 零樣本學(xué)習(xí)與廣義零樣本學(xué)習(xí)Fig.4 Zero-shot learning and generalized zero-shot learning
目前學(xué)者們提出的解決方法主要有兩種:第一種是先通過分類器,將測試集中可見類與不可見類數(shù)據(jù)進(jìn)行劃分。如果是可見類數(shù)據(jù),則直接使用分類器進(jìn)行分類;如果是不可見類數(shù)據(jù),則利用輔助信息進(jìn)行預(yù)測[72]。第二種生成模型,利用生成模型生成不可見類樣本,再將生成的樣本與可見類樣本一起訓(xùn)練一個(gè)分類器,將廣義零樣本學(xué)習(xí)轉(zhuǎn)化為傳統(tǒng)監(jiān)督學(xué)習(xí)[37,61,73]。
1.3.4 語義間隔(Semantic Gap)
語義空間與視覺空間流行構(gòu)成不同,相互映射有間隔。零樣本學(xué)習(xí)預(yù)測不可見類數(shù)據(jù)一般的解決方案是構(gòu)建圖像與語義之間的關(guān)系。2017年,Li等人[23]提出視覺特征來源于圖像空間,語義信息來源于語義空間,兩個(gè)空間的流行構(gòu)成有差別,直接建立兩者之間的映射,會(huì)導(dǎo)致語義間隔。
目前,學(xué)者們提出的主要解決方案是將從圖像空間提取的視覺特征與語義空間提取的語義信息映射到公共空間中,并將兩者進(jìn)行對(duì)齊[74-75]。
1.4 常用數(shù)據(jù)集
目前,零樣本學(xué)習(xí)在不同的領(lǐng)域得到了廣泛應(yīng)用。本節(jié)根據(jù)應(yīng)用的不同類型,文本、圖像、視頻,分別介紹其在零樣本學(xué)習(xí)中常用的數(shù)據(jù)集。
1.4.1 文本常用數(shù)據(jù)集
(1)LASER(Language-Agnostic Sentence Representations)
語言數(shù)據(jù)集。LASER 包括28 種不同字符系統(tǒng)的90多種語言,在零樣本學(xué)習(xí)任務(wù)中主要用于開發(fā)該數(shù)據(jù)庫中未包含的小語種。
(2)WordNet[11]
英文詞語數(shù)據(jù)集。WordNet 包括超過15 萬個(gè)詞,20 萬個(gè)語義關(guān)系。語義關(guān)系指的是名詞、動(dòng)詞、形容詞和副詞之間的語義關(guān)系。零樣本學(xué)習(xí)主要使用的是WordNet的名詞部分。
(3)ConceptNet[76-77]
常識(shí)數(shù)據(jù)集。ConceptNet主要由三元組構(gòu)成,包括超過2 100 萬個(gè)關(guān)系描述、800 萬個(gè)節(jié)點(diǎn)以及21 個(gè)關(guān)系。此外,其要素有概念、詞、短語、斷言、關(guān)系,邊等[11]。在零樣本學(xué)習(xí)任務(wù)中主要和知識(shí)圖譜結(jié)合。
1.4.2 圖像常用數(shù)據(jù)集
(1)AWA(Animal with Attribute)[78]
動(dòng)物圖像。AWA 由30 475 張動(dòng)物圖片構(gòu)成,其中有50 個(gè)動(dòng)物類別,每個(gè)類別至少有92 個(gè)示例,85 個(gè)屬性。此外,AWA 還提供7 種不同的特征。由于AWA 具有版權(quán)保護(hù),所以擴(kuò)展數(shù)據(jù)集AWA2 應(yīng)運(yùn)而生。AWA2包括37 322張圖片,與AWA同樣擁有50個(gè)動(dòng)物類別和85 個(gè)屬性。一般將40 類作為訓(xùn)練數(shù)據(jù)的類別,10 類作為測試數(shù)據(jù)的類別。
(2)CUB(Caltech-UCSD-Birds-200-2011)[79]
鳥類細(xì)粒度圖像。CUB由11 788張鳥類圖片構(gòu)成,其中有200類鳥類類別,312個(gè)屬性。一般將150類作為訓(xùn)練數(shù)據(jù)的類別,50類作為測試數(shù)據(jù)的類別。
(3)aPY(aPascal-aYahoo)[80]
混合類別圖像。aPY由15 339張圖片構(gòu)成,其中有32 個(gè)類別,64 個(gè)屬性。并且明確規(guī)定20 個(gè)類共12 695張照片作為訓(xùn)練數(shù)據(jù)的類別,12 個(gè)類共2 644 張照片作為測試數(shù)據(jù)的類別[6]。
(4)SUN(SUN attribute dataset)[81]
場景細(xì)粒度圖像。SUN由14 340張場景圖片構(gòu)成,其中包括717個(gè)場景類別,每個(gè)類別20張示例,102個(gè)屬性。一般將645類作為訓(xùn)練數(shù)據(jù)的類別,72類作為測試數(shù)據(jù)的類別。
(5)ImageNet[37,82-84]
混合類別圖像。ImageNet由超過1 500萬張高分辨率圖片構(gòu)成,其中有22 000 個(gè)類別,屬于大數(shù)據(jù)容量數(shù)據(jù)集。因此,一般使用其子數(shù)據(jù)集ILSVRC。IVSVRC由100 萬張圖片構(gòu)成,其中有1 000 個(gè)類別,每個(gè)類別1 000 張示例。一般將800 類作為訓(xùn)練數(shù)據(jù)的類別,200類作為測試數(shù)據(jù)的類別。
1.4.3 視頻常用數(shù)據(jù)集
(1)UCF101[85]
主要應(yīng)用于人類行為識(shí)別。UCF101由13 320視頻片段和101 個(gè)注釋類組成,總時(shí)長為27 個(gè)小時(shí)。在THUMOS-2014[86]行動(dòng)識(shí)別挑戰(zhàn)賽上,UCF101數(shù)據(jù)集得到擴(kuò)展。在UCF101的基礎(chǔ)上,收集了來自于互聯(lián)網(wǎng)的其他視頻,其中包括2 500 個(gè)背景視頻、1 000 個(gè)驗(yàn)證視頻以及1 574個(gè)測試視頻。
(2)ActivityNet[87]
主要用于人類行為識(shí)別。ActivityNet 由27 801 個(gè)視頻片段剪輯組成,擁有203 個(gè)活動(dòng)類(含注釋),總時(shí)長為849 個(gè)小時(shí),其主要優(yōu)勢是擁有更細(xì)粒度的人類行為。
(3)CCV(Columbia Consumer Video)[88-90]
主要用于社會(huì)活動(dòng)分類。CCV 由9 317 個(gè)視頻片段組成,擁有20個(gè)活動(dòng)類(含注釋),歸屬于事件、場景、對(duì)象3大類。
(4)USAA(Unstructured Social Activity Attribute)[90]
主要用于社會(huì)活動(dòng)分類。USAA對(duì)CCV(Columbia Consumer Video)中8 個(gè)語義類各選取100 個(gè)視頻進(jìn)行屬性標(biāo)注。一共有69個(gè)屬性,歸屬于動(dòng)作、對(duì)象、場景、聲音、相機(jī)移動(dòng)5大類。
2 經(jīng)典模型
本章通過介紹零樣本學(xué)習(xí)在3 個(gè)發(fā)展階段的經(jīng)典模型,為第3 章應(yīng)用體系的構(gòu)建提供理論體系的支撐。這3 個(gè)發(fā)展階段分別是:(1)基于屬性的零樣本學(xué)習(xí);(2)基于嵌入的零樣本學(xué)習(xí);(3)基于生成模型的零樣本學(xué)習(xí)。
2.1 基于屬性的零樣本學(xué)習(xí)
2013 年,文獻(xiàn)[76]提出基于屬性的零樣本學(xué)習(xí)方法,屬性是一種語義信息。這個(gè)方法是零樣本學(xué)習(xí)的開山之作,也是零樣本學(xué)習(xí)后續(xù)發(fā)展的基礎(chǔ)。
Direct Attribute Prediction(DAP)模型[78]在PAMI 2013會(huì)議上提出,其預(yù)測不可見類標(biāo)簽通過以下兩個(gè)步驟。第一,使用支持向量機(jī)(Support Vector Machine,SVM)訓(xùn)練可見類數(shù)據(jù)到公共屬性的映射,為每個(gè)可見類數(shù)據(jù)學(xué)習(xí)一個(gè)屬性分類器,這個(gè)屬性分類器也是可見類與不可見類之間的共享空間。第二,使用貝葉斯公式對(duì)不可見類的屬性進(jìn)行預(yù)測,再通過不可見類與屬性的關(guān)系,推出不可見類所屬的類別。DAP結(jié)構(gòu)如圖5所示。

圖5 DAP模型結(jié)構(gòu)Fig.5 Structure of DAP model
DAP 模型在挑選樣本方面,與AWA 數(shù)據(jù)集根據(jù)抽象名稱指定動(dòng)物和屬性不同,其更細(xì)致的考慮了示例圖像,根據(jù)圖像來指定動(dòng)物與屬性,并使得示例圖像中動(dòng)物出現(xiàn)在最突出的位置。在數(shù)據(jù)集配置方面將優(yōu)化后的數(shù)據(jù)集類別分為50%訓(xùn)練集和50%測試集。最終實(shí)驗(yàn)取得了多類別65.9%的準(zhǔn)確率。
通過利用屬性,DAP模型成功地將沒有數(shù)據(jù)的類別進(jìn)行預(yù)測,并且具有較高的精度。但是DAP 有三個(gè)明顯的缺點(diǎn):其一,對(duì)于新加入的可見類數(shù)據(jù),屬性分類器需要重新訓(xùn)練,無法對(duì)分類器進(jìn)行優(yōu)化和改善。其二,對(duì)于除了屬性外的其他輔助信息(如網(wǎng)絡(luò)結(jié)構(gòu)的數(shù)據(jù)集Wordnet),難以使用。其三,由于使用了屬性作為中間層,對(duì)于預(yù)測屬性,模型能夠做到最優(yōu)。但對(duì)于預(yù)測類別,卻不一定是最好的。
與DAP 模型一同出現(xiàn)的還有IAP(Indirect Attribute Prediction)[78]模型。IAP模型在PAMI 2013會(huì)議上提出,其預(yù)測不可見類標(biāo)簽通過以下兩個(gè)步驟:第一,使用支持向量機(jī)(SVM)訓(xùn)練可見類到屬性的映射以及不可見類到屬性的映射。第二,使用貝葉斯公式得到可見類數(shù)據(jù)與可見類的概率,為每個(gè)可見類數(shù)據(jù)學(xué)習(xí)一個(gè)類別分類器,繼而通過類別—屬性的關(guān)系,推出不可見類數(shù)據(jù)所屬的類別。IAP結(jié)構(gòu)如圖6所示。
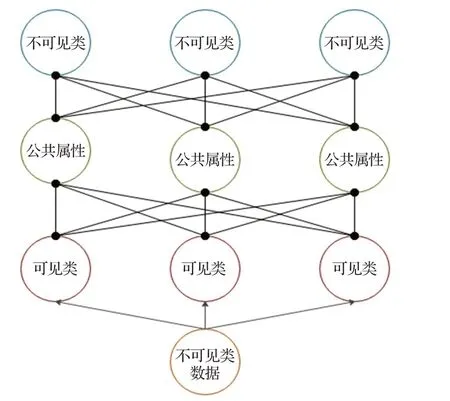
圖6 IAP模型結(jié)構(gòu)Fig.6 Structure of IAP model
與DAP模型一樣,IAP模型也成功的預(yù)測出沒有數(shù)據(jù)的類別,并且比DAP模型更加的靈活、簡單。當(dāng)有新類別需要進(jìn)行訓(xùn)練時(shí),IAP 模型的訓(xùn)練時(shí)間成本較小。但是IAP模型在實(shí)驗(yàn)中的效果并沒有DAP模型的好。
在基于屬性的零樣本學(xué)習(xí)中,除了經(jīng)典的DAP 和IAP 模型,文獻(xiàn)[91]還提出結(jié)合DAP、IAP 各自的優(yōu)點(diǎn),通過屬性分類器和相應(yīng)組合策略進(jìn)行零樣本學(xué)習(xí)的BAP(Bimodal Attribute Prediction)模型。文獻(xiàn)[92]提出的HAP(Hypergraph-based Attribute Predictor)更是將屬性這一語義信息用超圖構(gòu)建起來,更好地利用類別之間的關(guān)系。
2.2 基于嵌入的零樣本學(xué)習(xí)
隨著機(jī)器學(xué)習(xí)的不斷發(fā)展,計(jì)算機(jī)視覺逐漸成為研究者們的關(guān)注熱點(diǎn)。只有屬性的零樣本學(xué)習(xí),遠(yuǎn)不能滿足對(duì)圖像處理的需求,而且基于屬性的零樣本學(xué)習(xí)也存在著許多問題。因此,零樣本學(xué)習(xí)提出基于嵌入的零樣本學(xué)習(xí),將語義信息與圖像信息緊密結(jié)合起來。主要的方法有語義信息嵌入圖像空間、圖像信息嵌入語義空間、語義信息與圖像信息嵌入公共空間等。
在圖像信息嵌入到語義空間經(jīng)常使用的訓(xùn)練函數(shù)有單線性函數(shù)、雙線性函數(shù)、非線性函數(shù)等,損失函數(shù)有排序損失,平方損失等。
(1)Embarrassingly Simple Zero-Shot Learning(ESZSL)
ESZSL模型[93]在ICML 2015會(huì)議上提出,其將零樣本學(xué)習(xí)分為兩個(gè)階段,訓(xùn)練階段以及推理階段。通過SVM學(xué)習(xí)雙線性函數(shù)。一個(gè)在訓(xùn)練階段利用訓(xùn)練樣本實(shí)例與特征矩陣的相乘,建立特征空間與屬性空間之間的映射;另一個(gè)在推理階段利用訓(xùn)練樣本的描述和特征空間與屬性空間之間的映射獲得最終預(yù)測的模型,為每一個(gè)類別都學(xué)習(xí)了一個(gè)圖像空間到語義空間的映射。值得注意的是兩個(gè)階段均使用一行即可完成,且無需調(diào)用其他函數(shù),十分簡單的完成零樣本學(xué)習(xí)。ESZSL還建立了對(duì)應(yīng)的正則化方法以及平方損失函數(shù)對(duì)模型進(jìn)行優(yōu)化。ESZSL 模型結(jié)構(gòu)如圖7 所示。最終實(shí)驗(yàn)取得不錯(cuò)的效果。這是一種圖像信息嵌入語義空間的模型。
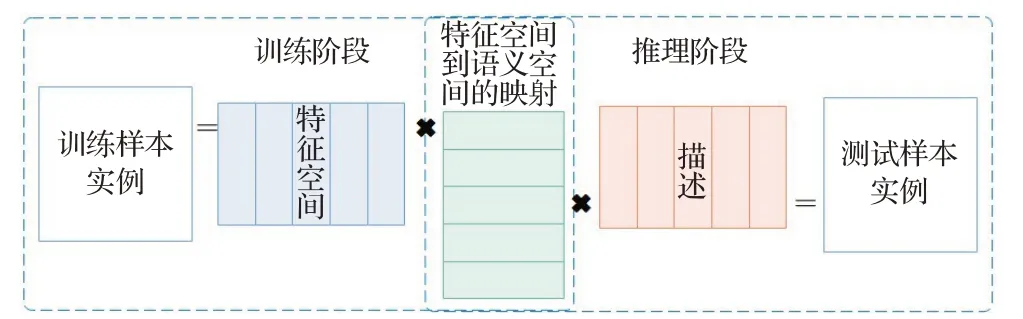
圖7 ESZSL模型結(jié)構(gòu)Fig.7 Structure of ESZSL model
ESZSL 模型在挑選樣本方面,直接選擇原始的AWA、aPY、SUN 數(shù)據(jù)集進(jìn)行訓(xùn)練以及測試。最終實(shí)驗(yàn)在AWA 數(shù)據(jù)集上獲得多類別49.3%的準(zhǔn)確率,比DAP模型多7.8 個(gè)百分點(diǎn);在SUN 數(shù)據(jù)集上則獲得多類別65.75%的準(zhǔn)確率,比DAP模型多13個(gè)百分點(diǎn);而在aPY數(shù)據(jù)集由于準(zhǔn)確度太低,不具備參考價(jià)值。
正因?yàn)镋SZSL 模型的簡單,使得在處理大規(guī)模數(shù)據(jù)上的表現(xiàn)不佳,并且每新來一個(gè)不可見類,就需要為其訓(xùn)練一個(gè)映射。而文獻(xiàn)[94]提出AEZSL(Adaptive Embedding ZSL)以及DAEZSL(Deep Adaptive Embedding ZSL)模型正好解決這些問題。AEZSL 模型在ESZSL基礎(chǔ)上進(jìn)行改進(jìn),利用可見類與不可見類之間的相似性,為每個(gè)可見類訓(xùn)練一個(gè)視覺到語義的映射,然后進(jìn)行漸進(jìn)式的標(biāo)注。DAEZSL模型則在AEZSL基礎(chǔ)上進(jìn)行改進(jìn),只需要對(duì)可見類訓(xùn)練一次,即可運(yùn)用于所有不可見類,解決了大規(guī)模數(shù)據(jù)上ESZSL 需要多次訓(xùn)練的繁瑣過程。
(2)Deep Visual Semantic Embedding(DeViSE)
DeViSE 模型[95]在NIPS 2013 會(huì)議上提出,其進(jìn)行零樣本學(xué)習(xí)通過以下3 個(gè)步驟。首先,預(yù)訓(xùn)練一個(gè)Word2Vec 中的skim-gram 詞向量網(wǎng)絡(luò)。網(wǎng)絡(luò)的作用是輸入單詞能夠找到其相近的單詞,即查找輸入單詞的上下文。其次,預(yù)訓(xùn)練一個(gè)深度神經(jīng)網(wǎng)絡(luò)。網(wǎng)絡(luò)的作用是對(duì)圖像的標(biāo)簽進(jìn)行預(yù)測。深度神經(jīng)網(wǎng)絡(luò)[95]采用的是在2012 年ImageNet 大型視覺識(shí)別挑戰(zhàn)賽獲獎(jiǎng)的1 000 類別分類器,同時(shí),分類器也可以使用其他預(yù)訓(xùn)練的深度神經(jīng)網(wǎng)絡(luò)。最后,將兩個(gè)預(yù)訓(xùn)練模型進(jìn)行預(yù)測的softmax層去除,然后合并兩個(gè)模型,通過學(xué)習(xí)雙線性函數(shù)以及相似性度量,對(duì)不可見類進(jìn)行預(yù)測。DEVISE模型還使用排序損失進(jìn)行優(yōu)化。模型結(jié)構(gòu)如圖8 所示。這是一種圖像信息嵌入語義空間的模型。
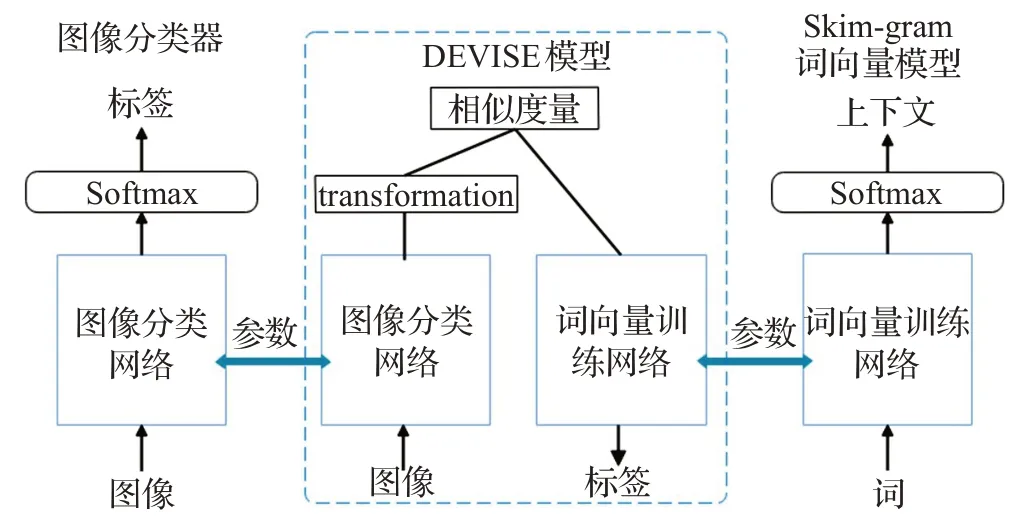
圖8 DeViSE模型結(jié)構(gòu)Fig.8 Structure of DeViSE model
DeViSE模型由于使用了skim-gram模型,其在語義上具有很強(qiáng)的泛化效果。這也使得它即使預(yù)測出來的標(biāo)簽錯(cuò)誤了,結(jié)果也是非常接近正確值。但是,其圖像分類器所采用的神經(jīng)網(wǎng)絡(luò)并非最佳,可以將其換為目前最好的圖像分類器,例如在WACV 2021 會(huì)議上由文獻(xiàn)[96]提出的Intra-class Part Swapping(InPS)模型。
DEViSE模型在挑選數(shù)據(jù)集方面,選擇使用ImageNet的子集ILSVRC。在數(shù)據(jù)集配置方面,將數(shù)據(jù)集分為50%的訓(xùn)練集以及50%的測試集。但最終實(shí)驗(yàn)由于分類器還不夠成熟,沒有取得很好的精確度。
(3)Attribute Label Embedding(ALE)
ALE 模型[97]在CVPR 2015 會(huì)議上提出,對(duì)于DAP模型的三個(gè)問題:無法增量學(xué)習(xí)、預(yù)測類別差強(qiáng)人意、無法使用其他輔助源,ALE 首先通過SVM 學(xué)習(xí)雙線性函數(shù),從圖像中提取特征以及將標(biāo)簽與屬性對(duì)應(yīng)起來。其次借助WSABIE 目標(biāo)函數(shù)的思路,設(shè)計(jì)排序損失函數(shù),使得特征空間與語義空間對(duì)齊損失最小化,繼而對(duì)不可見類預(yù)測進(jìn)行解決。同時(shí),屬性還可以換成其他輔助源,如HLE(Hierarchy Label Embedding)模型的層級(jí),AHLE(Attributes and Hierarchy Label Embedding)模型的層級(jí)與屬性結(jié)合。ALE 模型結(jié)構(gòu)如圖9 所示。這是一種圖像信息嵌入語義空間的模型。

圖9 ALE模型結(jié)構(gòu)Fig.9 Structure of ALE model
ALE模型在挑選樣本方面,選擇AWA以及CUB兩個(gè)動(dòng)物數(shù)據(jù)集。在數(shù)據(jù)集配置方面,將AWA 數(shù)據(jù)集分為40 個(gè)訓(xùn)練類和10 個(gè)測試類,將CUB 分為150 個(gè)訓(xùn)練類和50個(gè)測試類。最終實(shí)驗(yàn)在這兩個(gè)數(shù)據(jù)集上能夠取得多類別49.7%和20.1%的精確度。
ALE 模型的缺點(diǎn)也是顯而易見的:其一,標(biāo)簽所用屬性描述是人為定義的,如果兩個(gè)標(biāo)簽之間共享的屬性基本一致,則會(huì)導(dǎo)致它們?cè)趯傩钥臻g中難以區(qū)分;其二,從圖像中提取的不同特征可能對(duì)于同個(gè)屬性。
(4)Structured Joint Embedding(SJE)
SJE 模型[98]在CVPR 2015 會(huì)議上提出,其受SVM的啟發(fā),將語義空間一種語義信息(屬性)擴(kuò)展到了多種語義信息融合的空間。SJE 模型與ALE 模型的訓(xùn)練過程相似,首先通過SVM學(xué)習(xí)雙線性函數(shù),從圖像中提取特征以及將每一種語義信息與標(biāo)簽對(duì)應(yīng)起來。其次設(shè)計(jì)排序損失函數(shù),使得特征空間與每一種語義空間對(duì)齊損失最小化。最后比較每一種組合語義信息的效果,使用最好的效果對(duì)不可見類進(jìn)行預(yù)測。SJE 模型的語義空間可以是屬性、Word2Vec 編碼的類別、Glove 編碼的類別、WordNet 編碼的類別。損失函數(shù)選擇二分類損失。SJE模型結(jié)構(gòu)如圖10所示。
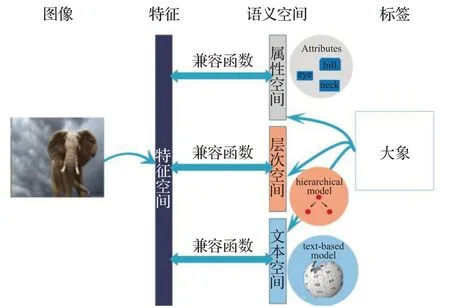
圖10 SJE模型結(jié)構(gòu)Fig.10 Structure of SJE model
SJE 模型在挑選樣本方面,選擇AWA、CUB 以及斯坦福大學(xué)推出的狗集3 個(gè)動(dòng)物數(shù)據(jù)集。在數(shù)據(jù)集配置方面,將AWA 數(shù)據(jù)集分為40 個(gè)訓(xùn)練類和10 個(gè)測試類,將CUB分為150個(gè)訓(xùn)練類和50個(gè)測試類。最終實(shí)驗(yàn)在AWA 數(shù)據(jù)集中最高可獲得66.7%的準(zhǔn)確率;能在CUB數(shù)據(jù)集中最高獲得50.1%的準(zhǔn)確率。
由于SJE 模型計(jì)算每一類語義空間與特征空間之間的兼容函數(shù),使得SJE模型能夠進(jìn)行細(xì)粒度識(shí)別。但也正因?yàn)槿绱耍浔仨氃谒屑嫒莺瘮?shù)計(jì)算完成后才能進(jìn)行,這使得它的效率較為低下。
(5)Latent Embeddings(LatEm)
LatEm 模型[99]在CVPR 2016 會(huì)議上提出,其是SJE模型的變體。LatEm模型預(yù)測標(biāo)簽由以下步驟完成:第一,將訓(xùn)練圖像分為多個(gè)特征并把每個(gè)特征使用線性函數(shù)映射到特征空間。第二,將標(biāo)簽與每個(gè)語義空間進(jìn)行映射。第三,計(jì)算每個(gè)特征與每個(gè)語義空間的兼容函數(shù)。第四,給定測試圖像,模型選擇一個(gè)最為合適的兼容函數(shù)進(jìn)行預(yù)測。LatEm模型將SJE模型中雙線性函數(shù)變更為分段線性函數(shù),是一個(gè)線性函數(shù)的集合,其作用是為測試樣本找到最好的線性模型,而選擇的過程可以看成是潛在變量。模型還針對(duì)分段函數(shù)無法使用常規(guī)優(yōu)化,提出了改進(jìn)版的隨機(jī)梯度下降(Stochastic Gradient Descent,SGD)與排序損失結(jié)合算法。LatEm 模型結(jié)構(gòu)如圖11所示。

圖11 LatEm模型結(jié)構(gòu)Fig.11 Structure of LatEm model
LatEm模型在挑選樣本方面,選擇AWA、CUB以及斯坦福大學(xué)推出的狗集3 個(gè)動(dòng)物數(shù)據(jù)集。最終實(shí)驗(yàn)在AWA 數(shù)據(jù)集中最高可獲得71.9%的準(zhǔn)確率;能在CUB數(shù)據(jù)集中最高獲得45.5%的準(zhǔn)確率。
由于LatEm模型考慮了圖像的重要信息,使得它在細(xì)粒度分類上表現(xiàn)出來的效果在當(dāng)下依然能夠達(dá)到不錯(cuò)的效果。當(dāng)然,在語義一致性以及空間對(duì)齊方面的問題也使得這個(gè)模型有些瑕疵。
(6)Semantic Similarity Embedding(SSE)
SSE模型[74]在ICCV 2015會(huì)議上提出,其假設(shè)不可見類為按照一定比例的混合的可見類。通過直方圖將所有數(shù)據(jù)(包括可見類和不可見類)表示為多個(gè)百分比的可見類。直方圖可以看作是可見類與不可見類之間的公共空間。SSE 模型將多種語義信息進(jìn)行融合嵌入到公共空間,同時(shí)也將圖像信息也嵌入到公共空間,計(jì)算兩者的相似度。如果語義空間映射到直方圖與圖像空間映射到直方圖相似,則將兩者歸為一類,繼而完成對(duì)不可見類的預(yù)測。SSE 模型推理過程如圖12 所示。模型針對(duì)僅使用分布對(duì)齊時(shí)會(huì)導(dǎo)致分類錯(cuò)誤的問題以及僅考慮分類會(huì)出現(xiàn)沒有完全對(duì)齊的問題,提出優(yōu)化的結(jié)合分布對(duì)齊和實(shí)例分類的零樣本學(xué)習(xí)。
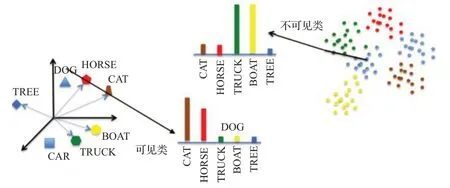
圖12 SSE模型推理過程Fig.12 Reasoning process of SSE model
SSE 模型在挑選樣本方面,選擇AWA、CUB、aPY、SUN 這4 個(gè)數(shù)據(jù)集。在數(shù)據(jù)集配置上AWA 數(shù)據(jù)集按50%為訓(xùn)練集,50%為測試集劃分,CUB數(shù)據(jù)集分為150個(gè)訓(xùn)練類和50個(gè)測試類,aPY數(shù)據(jù)集與AWA相同,SUN數(shù)據(jù)集中10 類作為測試集。最終實(shí)驗(yàn)在4 個(gè)數(shù)據(jù)集上分別最高可獲得76.33%、40.3%、46.23%、82.5%準(zhǔn)確率。SSE 模型能夠應(yīng)用于大規(guī)模數(shù)據(jù)集,文獻(xiàn)[92]的實(shí)驗(yàn)結(jié)果證明了這個(gè)優(yōu)點(diǎn),并且其在SUN 數(shù)據(jù)集上的運(yùn)行效果穩(wěn)定。但是,由于模型的類別是混合組成的,其對(duì)細(xì)粒度的分類并不能很好的識(shí)別。
(7)Joint Latent Similarity Embedding(JLSE)
JLSE 模型[75]在CVPR 2016 會(huì)議上提出,其首先使用SVM,通過雙線性函數(shù)學(xué)習(xí)語義空間到其子空間以及圖像空間到其子空間的映射。最后計(jì)算兩個(gè)子空間之間的相似度。而子空間是通過概率模型得到的與原空間概率分布類似的空間。JLSE模型能夠極大地減緩語義間隔的問題。
JLSE模型在挑選樣本方面,選擇AWA、CUB、aPY、SUN 這4 個(gè)數(shù)據(jù)集。在數(shù)據(jù)集配置上與SSE 模型相同。最終實(shí)驗(yàn)在4個(gè)數(shù)據(jù)集上分別最高可獲得80.46%、42.11%、50.35%、83.83%準(zhǔn)確率。
(8)Cross Modal Transfer(CMT)
CMT 模型[72]在NIPS 2013 會(huì)議上提出。與LatEm模型使用分段線性函數(shù)不同的是,CMT 模型通過兩層隱藏層的神經(jīng)網(wǎng)絡(luò)將從圖像中提取到的特征信息直接映射到50 維詞向量空間中。針對(duì)廣義零樣本學(xué)習(xí)問題,模型對(duì)所給的測試樣本先進(jìn)行分類,屬于可見類還是不可見類。由于是在語義空間中進(jìn)行分類,模型給出離群點(diǎn)檢查方法。對(duì)于可見類,使用傳統(tǒng)的Softmax 分類器進(jìn)行分類;對(duì)于不可見類,則使用混合高斯模型進(jìn)行預(yù)測。
CMT 模型在挑選樣本方面,選擇CIFAR10 數(shù)據(jù)集。最終實(shí)驗(yàn)在不可見類分類上最高可獲得30%的準(zhǔn)確率。
(9)Deep Embedding Model(DEM)
DEM 模型[66]在CVPR 2017 會(huì)議上提出,其與之前的嵌入到語義空間以及嵌入公共空間模型不同,模型選擇圖像空間進(jìn)行嵌入。原因是圖像空間的信息遠(yuǎn)比語義空間多,并能夠相對(duì)的減緩樞紐點(diǎn)問題。DEM 模型與DEVISE模型的架構(gòu)基本一致。第一,將圖像通過卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Networks,CNN)提取特征,形成特征空間。第二,語義表示可以有三種形式:一種語義、多種語義以及圖像的文本描述,第三種表示方式需要先通過雙向RNN 進(jìn)行編碼,最后通過兩個(gè)全連接層(FC)以及線性整流函數(shù)(Rectified Linear Unit,ReLU)提取語義信息。第三,這兩個(gè)分支通過最小二乘損失函數(shù)進(jìn)行連接。DEM模型結(jié)構(gòu)如圖13所示。

圖13 DEM模型結(jié)構(gòu)Fig.13 Structure of DEM model
DEM 模型在挑選樣本方面,選擇AWA、CUB 和ImageNet子集ILSVRC這3個(gè)數(shù)據(jù)集。在數(shù)據(jù)集配置上AWA、CUB 數(shù)據(jù)集采用SJE 模型配置,ImageNet子集采用360個(gè)類作為測試類。最終實(shí)驗(yàn)在3個(gè)數(shù)據(jù)集上分別最高可獲得88.1%、59.0%、60.7%準(zhǔn)確率。
DEM 模型除了有減緩樞紐點(diǎn)問題的優(yōu)點(diǎn)外,還能夠適用于多個(gè)模態(tài),并且提供端到端的優(yōu)化,能夠帶來更好的嵌入空間。但是,模型也只是停留在理論層面的優(yōu)勢,在實(shí)踐過程中,對(duì)零樣本學(xué)習(xí)的效果不佳。
以上的模型都是基于嵌入的模型,它們之間的比較如表2所示。

表2 基于嵌入的零樣本學(xué)習(xí)模型比較Table 2 Comparison of zero-shot learning based on embedding
2.3 基于生成模型的零樣本學(xué)習(xí)
近年來,生成模型這一發(fā)現(xiàn),引爆了計(jì)算機(jī)視覺許多領(lǐng)域,眾多具有高實(shí)用價(jià)值的應(yīng)用脫穎而出。現(xiàn)階段生成模型有生成對(duì)抗網(wǎng)絡(luò)(Generative Adversarial Network,GAN)、自動(dòng)編碼器(AutoEncoder,AE)、生成流(FLOW)。而在零樣本學(xué)習(xí)領(lǐng)域,將語義信息嵌入到圖像空間經(jīng)常使用生成模型。在獲取已知類視覺信息與語義信息的前提下,通過已知類與不可知類語義的連貫性,生成不可見類的樣本,使得零樣本學(xué)習(xí)變?yōu)閭鹘y(tǒng)的監(jiān)督學(xué)習(xí),將生成模型運(yùn)用到極致。
(1)Semantic AutoEncoder(SAE)
零樣本學(xué)習(xí)與AE 的結(jié)合。SAE 模型[61]在CVPR 2017會(huì)議上提出,其將語義空間作為隱藏層,通過編碼器將可見類圖像信息映射到語義空間,再通過已知類與不可知類語義的連貫性,使用解碼器將語義信息生成不可見類圖像,繼而將零樣本學(xué)習(xí)轉(zhuǎn)化為傳統(tǒng)的監(jiān)督學(xué)習(xí)。SAE 模型的前提條件是圖像信息到語義空間的映射矩陣是語義空間生成圖像的嵌入矩陣的轉(zhuǎn)置,并且加入了有懲罰項(xiàng)的約束,即圖像信息到語義空間的嵌入矩陣與可見類圖像信息表示的乘積等于隱藏層表示。這使得編碼后的圖像能夠盡可能的保留原始圖像的所有信息。SAE模型結(jié)構(gòu)如圖14所示。

圖14 SAE模型結(jié)構(gòu)Fig.14 Structure of SAE model
正是因?yàn)槿绱耍琒AE模型不僅模型簡單,效果好,還能夠運(yùn)用于廣義零樣本學(xué)習(xí),更能夠解決領(lǐng)域漂移問題。但是SAE 模型所使用的語義信息與圖像信息的嵌入函數(shù)過于簡單且固定,無法生成高質(zhì)量圖片,不能十分精確地預(yù)測不可見類樣本。
SAE 模型在挑選樣本方面,選擇AWA、CUB、aPY、SUN 和ImageNet 子集ILSVRC 這5 個(gè)數(shù) 據(jù)集。在數(shù)據(jù)集配置上采用1.4節(jié)的一般配置。最終實(shí)驗(yàn)在5個(gè)數(shù)據(jù)集上分別最高可獲得84.7%、61.4%、55.4%、91.5%、46.1%準(zhǔn)確率。
(2)f-x Generative Adversarial Network(f-xGAN)
零樣本學(xué)習(xí)與生成對(duì)抗網(wǎng)絡(luò)(GAN)的結(jié)合。f-xGAN模型在CVPR 2018會(huì)議上提出,指的是f-GAN、f-WGAN、f-CLSWGAN模型[48]的總稱,其強(qiáng)調(diào)的是生成特征,而不是生成圖像。首先,將圖片特征通過卷積神經(jīng)網(wǎng)絡(luò)提取出來。卷積神經(jīng)網(wǎng)絡(luò)可以其他特定任務(wù)訓(xùn)練得出的,例如GoogleNet、ResNet、ImageNet 預(yù)訓(xùn)練模型。其次,結(jié)合隨機(jī)噪聲以及語義信息,通過生成網(wǎng)絡(luò)得到生成特征。這個(gè)生成網(wǎng)絡(luò)可以是一般的條件生成對(duì)抗網(wǎng)絡(luò)GAN,也可以是加上優(yōu)化的Wasserstein距離的WGAN,亦或是在WGAN 基礎(chǔ)上加上分類損失的CLSWGAN。再而將語義信息、圖像特征以及生成特征一并放入判別器。最后產(chǎn)生的不可見類特征放入分類其中,完成對(duì)不可見類數(shù)據(jù)的預(yù)測。f-xGAN分類過程如圖15所示。
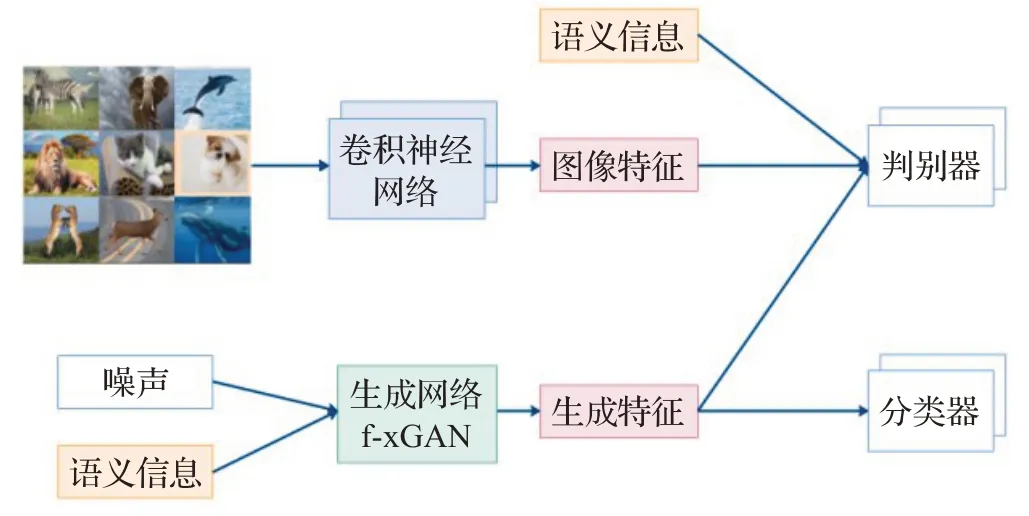
圖15 f-xGAN分類過程Fig.15 Classification process of f-xGAN model
f-xGAN 模型沒有訓(xùn)練語義與圖像之間的嵌入關(guān)系,而是通過生成特征,將圖像分類轉(zhuǎn)化為圖像特征分類來進(jìn)行零樣本學(xué)習(xí)。生成特征方法的好處在于生成特征數(shù)量無限,計(jì)算量小,訓(xùn)練時(shí)間少,效果好,還能夠運(yùn)用于廣泛零樣本學(xué)習(xí)。但由于f-xGAN模型使用的是生成對(duì)抗網(wǎng)絡(luò),生成數(shù)據(jù)的概率分布可能并不在給定數(shù)據(jù)上,會(huì)導(dǎo)致出現(xiàn)模型奔潰。
f-xGAN 模型在挑選樣本方面,選擇AWA、CUB、SUN、FLO(Oxford Flowers)這4個(gè)數(shù)據(jù)集。在數(shù)據(jù)集配置上采用1.4節(jié)的一般配置。最終實(shí)驗(yàn)在4個(gè)數(shù)據(jù)集上分別最高可獲得69.9%、61.5%、62.1%、71.2%準(zhǔn)確率。
(3)Invertible Zero-shot Flow(IZF)
零樣本學(xué)習(xí)與流模型(FLOW)的結(jié)合。IZF模型[73]在ECCV 2020會(huì)議上提出,其利用FLOW的思想,通過可逆神經(jīng)網(wǎng)絡(luò)將已知類圖像特征映射到語義和非語義空間,再利用可逆神經(jīng)網(wǎng)絡(luò)的逆網(wǎng)絡(luò)直接生成不可知類樣本,進(jìn)而將零樣本學(xué)習(xí)轉(zhuǎn)化為傳統(tǒng)的監(jiān)督學(xué)習(xí)。IZF結(jié)構(gòu)如圖16所示。可逆神經(jīng)網(wǎng)絡(luò)的優(yōu)點(diǎn)使得該模型只需要訓(xùn)練一次網(wǎng)絡(luò),得到參數(shù),就可以直接運(yùn)用于其逆網(wǎng)絡(luò),無需再次訓(xùn)練網(wǎng)絡(luò)。
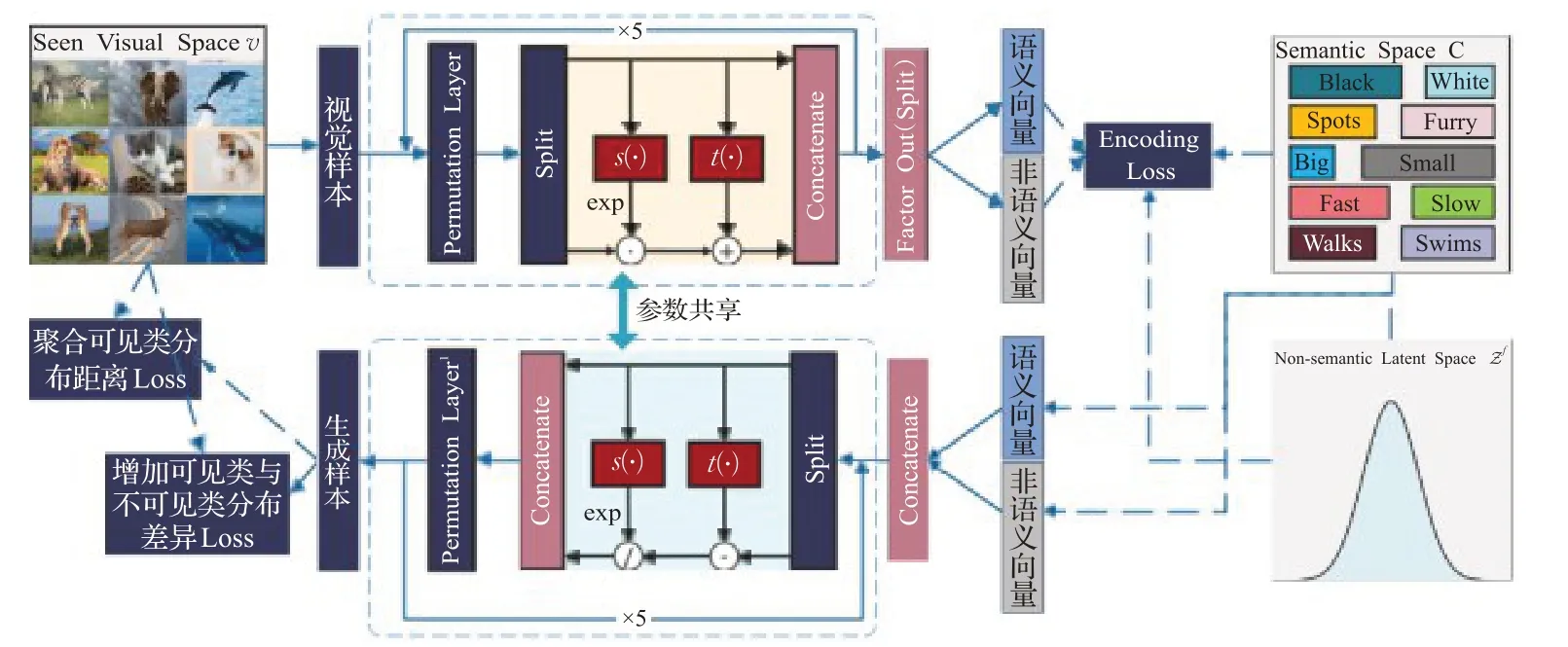
圖16 IZF結(jié)構(gòu)Fig.16 Structure of IZF model
IZF 模型通過雙向映射,充分的利用已知類信息,不僅解決了生成對(duì)抗網(wǎng)絡(luò)在零樣本下學(xué)習(xí)應(yīng)用中出現(xiàn)的模式奔潰問題,還解決了自動(dòng)編碼器在零樣本學(xué)習(xí)中無法生成高質(zhì)量圖片問題。IZF 模型更是通過擴(kuò)大已知類與不可知類的分布,解決了零樣本學(xué)習(xí)固有的領(lǐng)域漂移問題。但是IZF 模型與傳統(tǒng)的流模型NICE[100]、RealNVP[101]、GLOW[102]一樣有明顯的兩個(gè)缺點(diǎn):其一,可逆神經(jīng)網(wǎng)絡(luò)很難構(gòu)建;其二,多次變換所需求得的雅可比行列式復(fù)雜,計(jì)算量龐大,訓(xùn)練時(shí)間長。
IZF模型在挑選樣本方面,選擇AWA1、AWA2、CUB、aPY、SUN 這5 個(gè)數(shù)據(jù)集。在數(shù)據(jù)集配置上采用1.4 節(jié)的一般配置。最終實(shí)驗(yàn)在5 個(gè)數(shù)據(jù)集上分別最高可獲得80.5%、77.5%、68.0%、60.5%、57%準(zhǔn)確率。
綜上所述,在預(yù)測不可見類數(shù)據(jù)標(biāo)簽方面,基于屬性的零樣本學(xué)習(xí)多采用兩階段式,嵌入零樣本學(xué)習(xí)多采用轉(zhuǎn)移到能夠比較的空間方式,生成模型零樣本學(xué)習(xí)多采用生成不可見類樣本方式。在數(shù)據(jù)集方面,小數(shù)據(jù)使用AWA、CUB、aPY、SUN。如需進(jìn)行細(xì)粒度識(shí)別,則使用CUB、SUN 數(shù)據(jù)集。大數(shù)據(jù)集使用ImageNet。并且搭配常用的配置進(jìn)行訓(xùn)練與測試。在評(píng)估指標(biāo)方面,采用劃分傳統(tǒng)零樣本學(xué)習(xí)以及廣義零樣本學(xué)習(xí)的配置,以可見類、不可見類每類準(zhǔn)確率為指標(biāo),是一個(gè)零樣本學(xué)習(xí)模型最佳的評(píng)估方案。在實(shí)現(xiàn)效果方面,上述模型中在廣義零樣本配置下,不可見類每類準(zhǔn)確率在AWA、CUB、aPY、SUN數(shù)據(jù)集中最高的分別是IZF、IZF、DEM、IZF 模型。可見類準(zhǔn)確率則是DAP、IZF、SAE、IZF 模型。在局限性方面,基于屬性的模型取決于分類器的準(zhǔn)確率,基于嵌入的模型取決于提供的語義信息質(zhì)量,基于生成模型的模型取決于生成圖片的智力。零樣本學(xué)習(xí)經(jīng)典模型發(fā)展如圖17 所示;零樣本學(xué)習(xí)模型比較如表3所示。
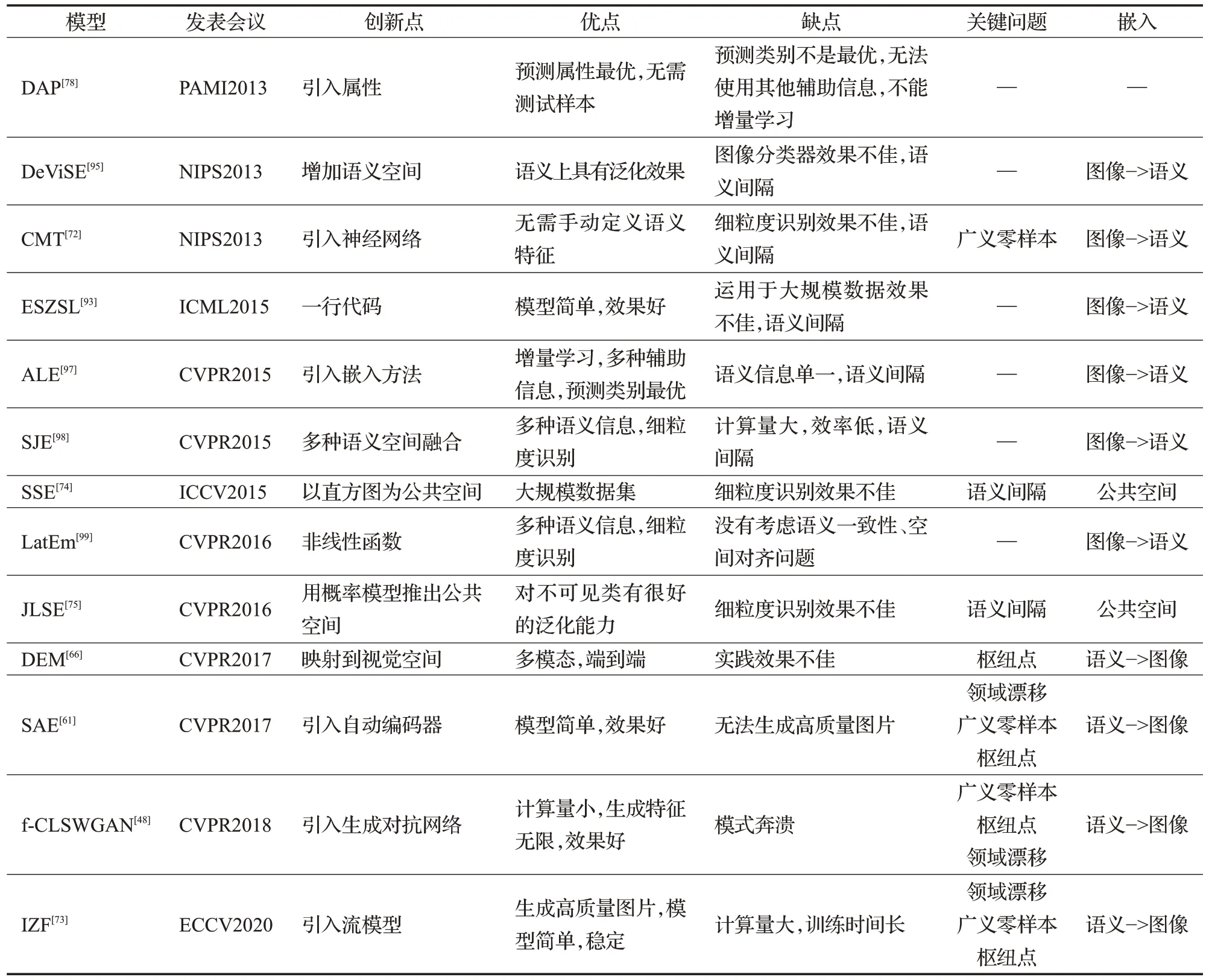
表3 零樣本學(xué)習(xí)經(jīng)典模型比較Table 3 Comparison of classic zero-shot learning model

圖17 零樣本學(xué)習(xí)經(jīng)典模型發(fā)展過程Fig.17 Development of classic zero-shot learning model
3 三維應(yīng)用體系
本章主要介紹零樣本學(xué)習(xí)在三個(gè)維度的應(yīng)用。第一維是詞。使用零樣本學(xué)習(xí)技術(shù)對(duì)詞作處理,并應(yīng)用于多個(gè)領(lǐng)域。第二維是圖片。在第一維應(yīng)用中產(chǎn)生的文本信息可以作為語義信息,嵌入到視覺空間中,推進(jìn)零樣本學(xué)習(xí)在圖片處理過程的應(yīng)用。第三維是視頻。視頻中的每一幀可作為圖片。將視頻切分為圖片,運(yùn)用第二維的方法,使零樣本學(xué)習(xí)在視頻方面的應(yīng)用更進(jìn)一步。
3.1 一維:詞
(1)對(duì)話系統(tǒng)
對(duì)話是由多個(gè)詞組成。在對(duì)話系統(tǒng)中,涉及的技術(shù)有語音識(shí)別(ASR)、口語理解(SLU)、對(duì)話管理(DM)、自然語言生成(NLG)、文本生成語音(TTS)。按照流水線結(jié)構(gòu)組成對(duì)話系統(tǒng)如圖18所示。而零樣本學(xué)習(xí)對(duì)對(duì)話系統(tǒng)的應(yīng)用的貢獻(xiàn)也是十分巨大的。例如文獻(xiàn)[103]構(gòu)建了一個(gè)統(tǒng)計(jì)口語理解模型,將口語理解模型推廣到訓(xùn)練中從未出現(xiàn)的輸入詞或者訓(xùn)練中從未出現(xiàn)的輸入類。在一個(gè)舊金山餐廳對(duì)話數(shù)據(jù)集中,實(shí)驗(yàn)出統(tǒng)計(jì)口語理解模型比支持向量機(jī)更好的運(yùn)用于零樣本學(xué)習(xí),且這個(gè)模型大大減少了人工標(biāo)注數(shù)據(jù)的數(shù)量。

圖18 流水線型對(duì)話系統(tǒng)Fig.18 Pipeline dialogue system
(2)機(jī)器翻譯
語言是詞的多種形式。在機(jī)器翻譯中,F(xiàn)aceBook開發(fā)了一款包含90多種語言和28種不同字母表編寫的工具包:LASER。該模型的原理是將所有語言使用多層BiLstm進(jìn)行訓(xùn)練。LASER所有語言嵌入與傳統(tǒng)單語言嵌入的區(qū)別如圖19 所示。在介紹文本中,LASER 首先通過英語這一語種的數(shù)據(jù)進(jìn)行訓(xùn)練,然后應(yīng)用于中文、俄文、越南語等語言上,最終都取得了很好的結(jié)果。這個(gè)模型的成功說明對(duì)于一些沒有樣本甚至早已不可考究的生僻語種(如斯瓦西里語),可以通過已知語種的信息對(duì)生僻語種進(jìn)行推理翻譯,進(jìn)而實(shí)現(xiàn)零樣本學(xué)習(xí)的應(yīng)用價(jià)值。

圖19 語言嵌入對(duì)比Fig.19 Comparison of language embedding
(3)文本分類
文本是由多個(gè)、多種詞組成的。在文本分類中,文獻(xiàn)[104]采用簡單的單詞嵌入來計(jì)算標(biāo)簽與文本之間的語義相似度,進(jìn)而預(yù)測出不可見類數(shù)據(jù)的標(biāo)簽。這個(gè)模型還能夠解決文本多標(biāo)簽問題。
3.2 二維:圖像
(1)圖像檢索
在圖像檢索方面,涉及的技術(shù)有基于文本的圖像檢索技術(shù)以及基于圖像內(nèi)容的圖像檢索技術(shù)。文獻(xiàn)[105]構(gòu)建了一種基于混合對(duì)象注意模塊以及通道注意模塊的模型來加強(qiáng)學(xué)習(xí)度量內(nèi)的區(qū)分和泛化,從而運(yùn)用于零樣本的基于圖像內(nèi)容的圖像檢索。該模型最終在CUB數(shù)據(jù)集上取得了比當(dāng)年最好的圖像檢索技術(shù)更好的效果。同時(shí),這也是零樣本學(xué)習(xí)與注意力機(jī)制的重要結(jié)合。
(2)目標(biāo)識(shí)別
在目標(biāo)識(shí)別方面,文獻(xiàn)[106]使用屬性描述來識(shí)別新出現(xiàn)的類別。這個(gè)模型在AWA 數(shù)據(jù)集上,對(duì)動(dòng)物識(shí)別的準(zhǔn)確率非常高。文獻(xiàn)[107]提出兩種方法對(duì)新出現(xiàn)的人臉在傳統(tǒng)人臉識(shí)別上效果不好的問題進(jìn)行優(yōu)化。第一種方法采用屬性分類器識(shí)別人臉圖像可描述屬性的存在與否,并預(yù)測出其屬于哪類人。第二種方法使用名為微笑的分類器,旨在計(jì)算臉部區(qū)域與特定人之間的相似性,繼而進(jìn)行人臉識(shí)別。這兩種方法的核心思想正是參考零樣本學(xué)習(xí)屬性以及嵌入的思想。這也是零樣本學(xué)習(xí)在目標(biāo)識(shí)別的重要應(yīng)用。文獻(xiàn)[108]構(gòu)建了一種以WordNet 大型社交多媒體語料庫為語義嵌入的對(duì)象分類器,實(shí)現(xiàn)對(duì)沒有出現(xiàn)場景的識(shí)別。最終,通過實(shí)驗(yàn)證明該模型在SUN以及Places2兩個(gè)大型數(shù)據(jù)集上表現(xiàn)優(yōu)于屬性模型。同時(shí),稀有物種的識(shí)別也是零樣本學(xué)習(xí)在圖像上的重大應(yīng)用。
(3)語義分割/圖像分割
在語義分割方面,文獻(xiàn)[109]提出一種新的模型ZS3NET。該模型結(jié)合深度視覺分割以及語義信息嵌入生成視覺特征的方法,實(shí)現(xiàn)零樣本語義分割任務(wù)。最終在PASCAL-VOC和PASCAL-CONTEXT兩個(gè)標(biāo)準(zhǔn)分割數(shù)據(jù)集上的實(shí)驗(yàn),ZS3NET在零樣本語義切分任務(wù)中表現(xiàn)出良好的性能,并且解決了廣義零樣本學(xué)習(xí)問題。
在圖像分割方面,在2021 年的CVPR 會(huì)議上,提出零樣本圖像分割的解決方案:基于背景感知的檢測-分割算法;并且文獻(xiàn)定義了零樣本下圖像分割的標(biāo)準(zhǔn),為數(shù)據(jù)樣本難以獲取的兩個(gè)代表性領(lǐng)域:醫(yī)療以及工業(yè)后續(xù)的發(fā)展提供可行性方案。
3.3 三維:視頻
(1)人體行為識(shí)別
人體行為識(shí)別領(lǐng)域,由于收集和標(biāo)注視頻中行為是十分困難且費(fèi)力的工作,零樣本學(xué)習(xí)通過文本的描述等信息可實(shí)現(xiàn)無樣本識(shí)別大受歡迎。文獻(xiàn)[110]通過支持向量機(jī)模型學(xué)習(xí)視頻和語義屬性之間映射,進(jìn)而實(shí)現(xiàn)零樣本人體行為識(shí)別。文獻(xiàn)[14]將詞向量作為可見類與不可見類之間的聯(lián)系,通過嵌入視頻以及標(biāo)簽實(shí)現(xiàn)零樣本人體行為識(shí)別。文獻(xiàn)[111]通過空間感知嵌入實(shí)現(xiàn)零樣本人體行為識(shí)別的定位以及分類。
(2)超分辨率
超分辨率領(lǐng)域,零樣本學(xué)習(xí)概念的引入,使得這個(gè)領(lǐng)域有了突破性的進(jìn)展。超分辨率技術(shù)如圖20 所示。與傳統(tǒng)的超分辨率技術(shù)——提供高分辨率以及其對(duì)應(yīng)的低分辨率樣本進(jìn)行訓(xùn)練不同,零樣本超分辨率技術(shù)只需要提供低分辨率樣本,然后通過退化(生成)模型得到更低分辨率的樣本后進(jìn)行訓(xùn)練即可。零樣本超分辨率技術(shù)目前應(yīng)用于多個(gè)領(lǐng)域,如在公共安全領(lǐng)域?qū)z像頭抓拍到的視頻進(jìn)行超分辨率,以便公共安全部門進(jìn)行識(shí)別;在醫(yī)療領(lǐng)域?qū)︶t(yī)生遠(yuǎn)程會(huì)診的視頻進(jìn)行超分辨率,恢復(fù)重要的局部細(xì)節(jié)[112]。

圖20 超分辨率Fig.20 Super resolution
4 挑戰(zhàn)與未來方向
作為新興的研究領(lǐng)域,零樣本學(xué)習(xí)已經(jīng)具備了較為完整的理論體系和實(shí)際應(yīng)用。根據(jù)嵌入方式的不同,其算法主要分為三大類,包括語義空間到視覺空間嵌入、視覺空間到語義空間嵌入和語義空間/視覺空間到第三公共空間嵌入。語義空間、視覺空間以及第三方空間,在機(jī)器學(xué)習(xí)領(lǐng)域也稱為模態(tài)。由于受到模態(tài)內(nèi)部的數(shù)據(jù)噪聲、跨模態(tài)間數(shù)據(jù)的異構(gòu)性以及跨模態(tài)導(dǎo)致的信息丟失等影響,使得零學(xué)習(xí)領(lǐng)域的性能仍具有較大的提升空間。目前,零樣本學(xué)習(xí)領(lǐng)域中面臨的主要挑戰(zhàn)如下:
(1)由于零樣本學(xué)習(xí)需要進(jìn)行跨模態(tài)間的數(shù)據(jù)分析,因此,如何有效化解1.3 節(jié)所提到的語義間隔,將不同模態(tài)信息對(duì)齊并映射到相同的特征空間成為首要解決的問題。為此,研究人員分別提出了3種嵌入方案進(jìn)行解決:語義到視覺的嵌入方法將可見類和不可見類的語義特征嵌入到同一個(gè)視覺空間進(jìn)行對(duì)比;視覺到語義的嵌入方法將可見類和不可見類的視覺特征嵌入到同一個(gè)語義空間進(jìn)行對(duì)比;語義特征/視覺特征到第三方公共空間嵌入將語義特征和視覺特征同時(shí)嵌入到同一個(gè)第三空間進(jìn)行比對(duì)。這些方法很好地解決了多模態(tài)數(shù)據(jù)在比對(duì)時(shí)信息不對(duì)稱的問題,然而,這些方法僅簡單地對(duì)跨模態(tài)數(shù)據(jù)進(jìn)行對(duì)齊,并未考慮數(shù)據(jù)本身存在的噪聲、信息不足等問題在多模態(tài)對(duì)齊時(shí)造成的影響。此外,這些方法在進(jìn)行模態(tài)間的信息對(duì)齊時(shí),丟失了大量模態(tài)轉(zhuǎn)化前的原始信息,并未綜合考慮不同映射方式之間存在的相互共享和補(bǔ)充的情況。
(2)在零樣本學(xué)習(xí)中普遍存在一個(gè)問題,即第1.3節(jié)提到的領(lǐng)域偏移問題,其問題的本質(zhì)是不同模態(tài)數(shù)據(jù)之間存在較大的鴻溝。針對(duì)這個(gè)問題,研究人員提出了許多處理方法,例如:采用語義—視覺—語義或視覺—語義—視覺的雙重嵌入方式來保證語義—視覺的強(qiáng)對(duì)應(yīng)關(guān)系。這些方法雖然能夠很好地解決語義—視覺的對(duì)應(yīng)關(guān)系,但是卻以較多置信度低的語義—視覺嵌入關(guān)系為代價(jià)。由于多個(gè)模態(tài)之間儲(chǔ)存的信息差異較大,在進(jìn)行雙重嵌入方式構(gòu)造對(duì)應(yīng)關(guān)系時(shí),會(huì)由于不同模態(tài)間的數(shù)據(jù)存在差異,影響最終的對(duì)齊效果。因此,如何有效地幫助信息儲(chǔ)備較低的模態(tài)引入更多信息是處理該挑戰(zhàn)的關(guān)鍵。
(3)零學(xué)習(xí)任務(wù)中可見類和不可見類的相關(guān)性會(huì)直接影響模型在不可見類上的預(yù)測性能。當(dāng)可見類(如動(dòng)物)與不可見類(如家具)相關(guān)性較小,存在較大的分布差異時(shí),很容易出現(xiàn)領(lǐng)域漂移行為,導(dǎo)致模型在不可見類的識(shí)別性能降低甚至是無法識(shí)別,即出現(xiàn)遷移學(xué)習(xí)中的負(fù)遷移現(xiàn)象。如何簡單有效地度量可見類與不可見類之間的差異來對(duì)模型進(jìn)行自適應(yīng)調(diào)整,迄今為止沒有一個(gè)通用的方法。
(4)目前,零樣本學(xué)習(xí)方法的訓(xùn)練模式較為單一,缺少協(xié)同訓(xùn)練(co-training)的過程。由于零樣本學(xué)習(xí)的跨模態(tài)特性,致使其對(duì)于模態(tài)噪聲更加敏感,而零樣本學(xué)習(xí)本身就具備多模態(tài)、多視角的特征,使得在零學(xué)習(xí)中的協(xié)同訓(xùn)練更加具有研究意義。文獻(xiàn)[113-116]中已經(jīng)提出使用不同質(zhì)(即不同模態(tài)或不同視角)的多個(gè)基礎(chǔ)學(xué)習(xí)器協(xié)同訓(xùn)練可以有效提高學(xué)習(xí)模型的泛化能力。對(duì)于不可見類數(shù)據(jù)已知但其標(biāo)簽未知的情況,如何設(shè)計(jì)有效的協(xié)同訓(xùn)練方案,來挑選出可靠的、高置信度的樣本進(jìn)行進(jìn)一步挖掘和訓(xùn)練并有效提高零學(xué)習(xí)的整體性能,是一個(gè)有待深入的問題。
針對(duì)以上4個(gè)挑戰(zhàn),引入集成學(xué)習(xí)思想是一個(gè)可行的解決方案。集成學(xué)習(xí)(Ensemble Learning)[117]是指通過構(gòu)建并組合多個(gè)分類器(弱分類器)來完成同一個(gè)學(xué)習(xí)任務(wù)的機(jī)器學(xué)習(xí)方法,由于其具有比單一學(xué)習(xí)器更加顯著的泛化性能而被廣泛應(yīng)用于情感識(shí)別[118-119]、文本分類[120-121]、圖像分類[122-123]等多個(gè)研究領(lǐng)域,具有廣闊的應(yīng)用前景。隨著集成學(xué)習(xí)研究的迅速發(fā)展,目前在零樣本學(xué)習(xí)研究工作中已經(jīng)出現(xiàn)了大量的引入集成學(xué)習(xí)思想來提高零樣本學(xué)習(xí)性能的研究成果[12,124]。相較于傳統(tǒng)的單模型零樣本學(xué)習(xí)算法,集成零樣本學(xué)習(xí)模型主要有以下優(yōu)勢:(1)集成樣本零學(xué)習(xí)方法具有更好的泛化性能;(2)集成零樣本學(xué)習(xí)通過對(duì)多模態(tài)數(shù)據(jù)進(jìn)行挖掘和集成,可以解決多模態(tài)數(shù)據(jù)在語義對(duì)齊(跨模態(tài))時(shí)導(dǎo)致的信息丟失問題,盡可能利用不同模態(tài)間的特征信息;(3)集成零樣本學(xué)習(xí)對(duì)每個(gè)模態(tài)數(shù)據(jù)進(jìn)行多視角挖掘,構(gòu)建多視角中樞,解決零樣本學(xué)習(xí)方法在學(xué)習(xí)過程中出現(xiàn)的領(lǐng)域偏移問題,增加模型泛化性;(4)集成零學(xué)習(xí)方法對(duì)于復(fù)雜的分布環(huán)境,如:噪聲、異構(gòu)數(shù)據(jù)、復(fù)雜數(shù)據(jù)分布等,具有很強(qiáng)的抗干擾能力。因此,如何產(chǎn)生差異性更大、泛化能力更強(qiáng)的多個(gè)跨模態(tài)語義對(duì)齊模型,并基于此構(gòu)建源自不同視角的學(xué)習(xí)器,進(jìn)而最終獲得比單一學(xué)習(xí)器性能更好的集成零學(xué)習(xí)方法,是4個(gè)挑戰(zhàn)的潛在解決思路。
5 結(jié)束語
本文通過124 篇文獻(xiàn)對(duì)零樣本學(xué)習(xí)的理論體系進(jìn)行回顧,綜述不同領(lǐng)域的應(yīng)用情況。首先,通過零樣本的研究背景推出其具體定義,并與傳統(tǒng)的監(jiān)督學(xué)習(xí)和廣義零樣本學(xué)習(xí)進(jìn)行比較。其次,對(duì)零樣本學(xué)習(xí)研究過程中出現(xiàn)的關(guān)鍵問題以及應(yīng)用中經(jīng)常使用數(shù)據(jù)集進(jìn)行介紹。從零樣本學(xué)習(xí)關(guān)鍵技術(shù)、屬性、嵌入以及生成模型,按照出現(xiàn)的時(shí)間順序列舉了13 種經(jīng)典模型,并對(duì)模型的過程、優(yōu)點(diǎn)、缺點(diǎn)進(jìn)行描述。然后,總結(jié)近些年來零樣本學(xué)習(xí)在詞、圖像、視頻中的應(yīng)用。最后,根據(jù)關(guān)鍵問題以及實(shí)際中應(yīng)用難題,提出零樣本學(xué)習(xí)領(lǐng)域的4 個(gè)挑戰(zhàn),并引入集成學(xué)習(xí)來應(yīng)對(duì)這些挑戰(zhàn),為研究者們提供新的研究方向。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
中華手工(2017年2期)2017-06-06 23:00:31
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
大連民族大學(xué)學(xué)報(bào)(2015年2期)2015-02-27 08:28:11
中外會(huì)展(2014年4期)2014-11-27 07:46:46
外語學(xué)刊(2011年1期)2011-01-22 03:38:33
