生成對抗網絡及其應用研究綜述
2021-10-14 06:33:54魏富強古蘭拜爾吐爾洪買日旦吾守爾
計算機工程與應用 2021年19期
魏富強,古蘭拜爾·吐爾洪,買日旦·吾守爾
新疆大學 信息科學與工程學院,烏魯木齊 830046
伴隨著信息技術的革新、硬件設備的算力不斷更替,人工智能在信息化社會蓬勃發展,以生成模型[1]為代表的機器學習領域,持續受到研究者關注。它被廣泛應用于計算機視覺方向,如圖像生成[2-4]、視頻生成[5-7]等任務;以信息隱寫[8-9]、文本生成[10]等任務為代表的自然語言處理方向;音頻領域的語音合成[11]等方向,并且在這些任務中,生成模型均表現出了與其他模型相比驚人的效果。
相比其他生成模型,2014年由Goodfellow等人[12]首次提出的生成對抗網絡模型在生成圖像數據方面的表現令研究者驚異,目前它在計算機視覺、醫學、自然語言處理等領域的研究一直保持著活躍狀態。此外,生成對抗網絡模型的研究工作主要集中在以下兩個方面:一是聚焦于理論線索嘗試提高生成對抗網絡的穩定性和解決它的訓練問題[13-17],或考慮從不同的角度如信息論[18-19]和模型效率[20-22]等方面豐富其結構;二是關注于生成對抗網絡在不同應用領域內的變體結構和應用場景[13,23-24]。除了圖像合成,生成對抗網絡還在其他方向成功應用,如圖像的超分辨率[25]、圖像描述[26]、圖像修復[27]、文本到圖像的翻譯[28]、語義分割[29]、目標檢測[30-31]、生成性對抗攻擊[32]、機器翻譯[33]、圖像融合[34-37]及去噪[38]。基于以上論述,系統地在理論和應用層面研究生成模型具有重要的意義。
本文首先介紹了生成式模型的基本原理,闡述了生成對抗網絡的理論支撐。其次介紹了評價生成式網絡的各項指標,說明了它們之間的區別與聯系。緊接著討論了生成對抗網絡在圖像和其他領域方面的熱點應用研究進展,并指出了研究生成對抗網絡的挑戰及潛在的突破口,最后對論文進行了概括總結。
1 生成對抗網絡研究
1.1 生成網絡
基于數學表達形式區分,最大似然原理是生成模型實現建模的數學基礎。根據其似然的表示特點可以分為基于顯式密度估計和隱式密度估計的方法。基于顯式密度估計的生成模型,其難點在于找到可以全面表達所有生成數據復雜度的模型,通過改變似然結構表達式的形式,使用梯度優化方法使模型密度函數的定義融入似然結構的表達式達到最優,計算方式在形式上分為精確計算和近似估計兩種。基于隱式的密度估計的生成模型,重點在于通過定義的隱變量來確定擬合的模型,相比顯式密度估計方法不需要計算密度函數。
基于以上內容的介紹,以最大似然原理為理論基礎的生成模型大家族分類及各分類下所具有的代表性模型結構,如圖1所示。
1.2 生成對抗網絡(GAN)
GAN[12]是另一種基于直接方式的隱式密度生成模型,它的結構圖和處理過程如圖2 所示,其中關鍵結構為生成器G和判別器D:G負責從輸入數據的噪聲分布中隨機采樣,學習其分布生成盡可能“真”的假樣本來欺騙D;而D則負責對G生成的樣本,結合真實數據進行識別并判斷真偽(Real或者Fake,記為R和F)。
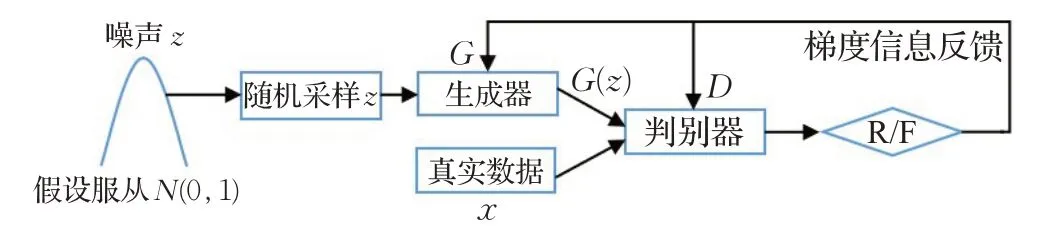
圖2 生成對抗網絡模型Fig.2 Model of Generative Adversarial Network(GAN)
GAN的值函數V(G,D)為:
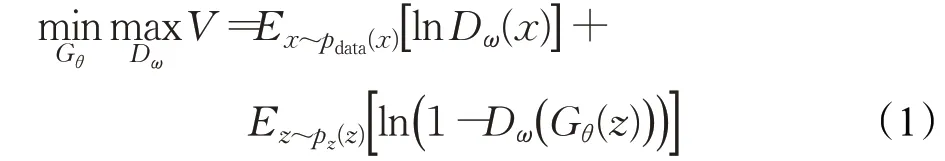
其中,值函數的優化目標為最大化G的參數ω和最小化G的參數θ。判別器的目的是讓公式(1)最大,即公式中的第一項和第二項都要最大。第一項最大的意思是Dω(x)->1,真樣本為真的概率接近1;而第二項最大的話,需要Dω(Gθ(z))->0,假樣本為真的概率為0;相反,生成器的目的是讓公式最小,其第一項和第二項都要小,即Dω(x)->0,Dω(Gθ(z))->1,這要求真樣本為真的概率小,假樣本為真的概率接近1,此時,生成的樣本就可以假亂真。
由公式(1)可知,生成對抗網絡是從噪聲中采樣一次就生成一個樣本,非Markov chain形式串行方式生成樣本,且不需要計算變分下界可直接生成。這使得生成的樣本質量比其他的生成模型好。但生成對抗網絡也引入了新的挑戰:生成過程中的內在表現方式無法展示和不可控因素較多;訓練過程中的不穩定性;以及如何客觀地評價生成模型。
對GAN 模型理論的溯源討論之后,如何評價模型性能的衡量指標是值得關注的,文章接下來詳細概述了模型評價指標,并分析了生成對抗網絡在生成數據方面的研究進展及GAN 改進的經典變體,其次列舉了熱點應用領域,最后展望了末來研究的潛在突破口。
2 模型評價指標
鑒于定性評估的內在缺陷,尋找合適的定量評估來提高模型性能變得尤為重要,它們應該盡可能考慮以下的要求:
(1)質量可評價性。對生成樣本清晰度高、視覺感知較好等圖像質量問題可以評價,即對能夠評價生成質量優劣的模型給予高分。
(2)多樣性。可以評價GAN各種失衡影響因素,如過擬合、模式缺失、模式崩潰、簡單記憶等現象,即對生成具有多樣性樣本的模型應給予高分。
(3)可控性。針對連續性質的隱空間,其中若對于GAN 的隱變量z具有明顯的含義指向,樣本的生成結果就可控制z的變化得到,即對隱變量處理更好的模型應給予高分。
(4)有界性。即對評價指標的數值作范圍界定,給出其上下界。
(5)一致性。即評價指標的結果與人類感知的判定結果相似或一致。
(6)低差異性。即評價指標對圖像變換前后語義信息未改變的數據,評價差別應足夠小。
(7)輕量性。即評價指標的設計過程中減少樣本的參與,以少樣本低計算復雜度為目標。
由于實際應用場景的復雜性,以上要求不可能同時滿足,但參考上述要求所設計的各個GAN 評估指標之間既有聯系也有區別,還有其自身的優缺點不可忽視,本文以下內容對GAN 模型的評價指標進行了全面詳述。
2.1 IS相關
對GAN生成圖像的質量優劣評價是基于人類的主觀意識,故計算機由于其局限性無法像人一樣清晰辨別生成圖片的好壞。在客觀評價時,常把不符合目標預期的圖片和線條足夠明晰但感知異常的圖片均視為低質量生成樣本,故需要設計量化指標來統一衡量標準。
2.1.1 Inception分數
Inception 分數(Inception Score,IS)指標是GAN 模型生成圖像常用的評價標準之一,采用熵的形式體現了量化的概念。生成圖片的多樣性越好,表現在類別分布上會趨向均勻分布,此特性也是IS考慮的問題之一。多樣性的描述與熵的大小成正比關系,即相對于類別熵的取值越大多樣性越好,反之亦然。針對多樣性和圖像質量都需要考慮的場景,以互信息特性設計GAN 評價指標。為簡化計算添加了指數項,最終IS數學表達形式被定義為:
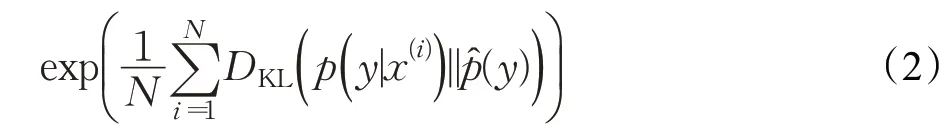
2.1.2 IS的缺陷
IS作為生成對抗網絡模型主流的評價指標,在圖像生成方面已具備成熟的評價機制,但也存在一些不可忽視的問題和缺陷,如下所述:
(1)對GAN過擬合狀態無法檢測。
(2)對數據集ImageNet的圖像獨具青睞。
(3)對崩潰問題無法檢測。
(4)忽略了真實數據集的分布。
(5)是一種偽度量。
上述內容分析了IS指標的優劣情況,其缺陷方面的問題限制了其通用性,故以下內容介紹了IS幾種改進形式的指標,繼承其優點改進其缺點,促進了IS指標的推廣與應用。
2.1.3 修正的Inception分數
修正的Inception 分數(Modifified Inception Score,M-IS)也是IS的改進版本之一,它重點關注了評價多樣性問題中產生的類內模式崩潰問題。M-IS對于同一類樣本的標簽引入了交叉熵進行計算,將類內交叉熵融入IS可得M-IS,即:
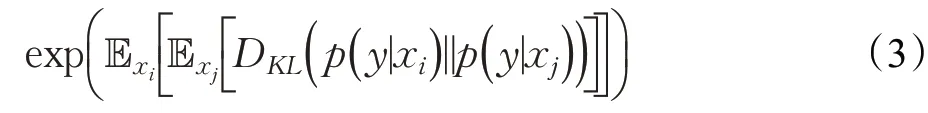
M-IS的關注點集中在GAN模型生成質量和類內多樣性。M-IS得分與GAN生成性能成正相關。
2.1.4 激活最大化分數(AMS)
激活最大化分數(Activation Maximization Score,AMS)關注了IS 評價指標在數據類別分布不均勻時的不合理性,通過引入訓練數據集和生成數據集的差異度量參數來改善此問題。AMS的表達式為:
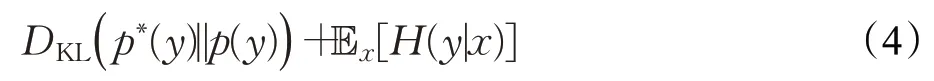
顯然,AMS分數與生成性能之間存在反比關系,即GAN生成性能越差AMS的得分越大,反之亦然。
2.2 Mode分數
Mode分數(Mode Score,MS)主要解決IS缺陷之一即忽視了訓練數據集的標簽信息,并在關注此條件時滿足IS的計算要求。MS定義為:

與IS的定義式相比較,MS不僅在生成數據上進行了計算,而且在訓練數據集上也參與了計算。
2.3 Fréchet Inception Distance
Fréchet Inception Distance(FID)計算了真實樣本與生成樣本在特征空間高斯分布的弗雷歇距離,此距離則代表了FID的值:
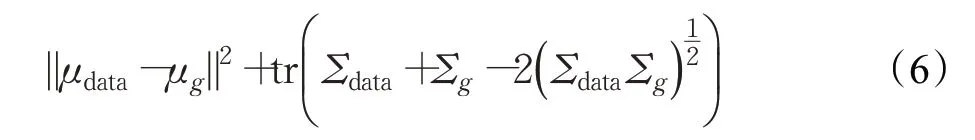
FID的數值決定了兩個高斯分布之間的親疏關系,并與GAN生成性能成反比,即FID數值越大,另個分布關系越疏遠,GAN性能越差,反之亦然。
如圖3 是在同一數據集ImageNet 上IS 與FID 兩種指標的實驗得分情況,其中圖像尺寸都為128×128。
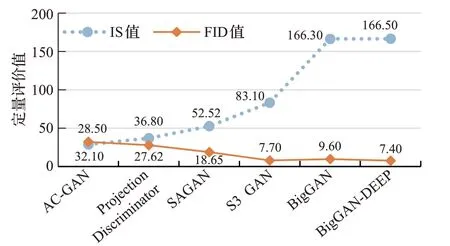
圖3 同一數據集不同指標定量得分情況Fig.3 Quantitative scores of different indicators in the same dataset
在各種應用中,噪聲魯棒性較好以及生成圖像評價分數符合人類感知兩個特點是FID 相比其他標準的顯著區別,另外計算復雜度也較低,但其高斯分布的簡化假設是其理論上的不足之處。
2.4 最大均值差異(MMD)
最大均值差異(Maximum Mean Discrepancy,MMD)是在希爾伯特空間度量兩個分布差異的一種方法,其常被應用于遷移學習。相比FID的設計思路,將求解弗雷歇距離的方法替換為MMD方法,兩個分布產生的距離即可作為GAN的評價指標。在這里MMD距離與GAN生成性能成反比,即距離越大生成性能越差,其訓練數據集和生成數據非分布越疏遠。
2.5 Wasserstein距離
Wasserstein 距離(Wasserstein Distance)將GAN 評價指標的距離表示更換為Wasserstein距離形式,其距離值也與GAN 性能成反比,與FID 的距離衡量結果類似。Wasserstein 距離評價指標優點是可對模型的簡單記憶與模式奔潰問題進行識別,而且計算速度很快;缺點是因為訓練過程過度依賴判別器和訓練數據集,限制了其只能應用在特定訓練集訓練的GAN場景。
2.6 1-最近鄰分類器(1-NN)
1-最近鄰分類器(1-Nearest Neighbor classifier,1-NN)的具體實現為:利用比較思維,期望計算出訓練數據集與生成數據集的概率分布進行比較。若二者結果相等則GAN生成性能優越,若差異較大則性能較差,此類方法通常采用準確率來作為評價指標。
如圖4 所示,展示了任意測試樣本在1-NN 上的正確率變化,差異越大正確率越高,即可反映GAN 生成性能。
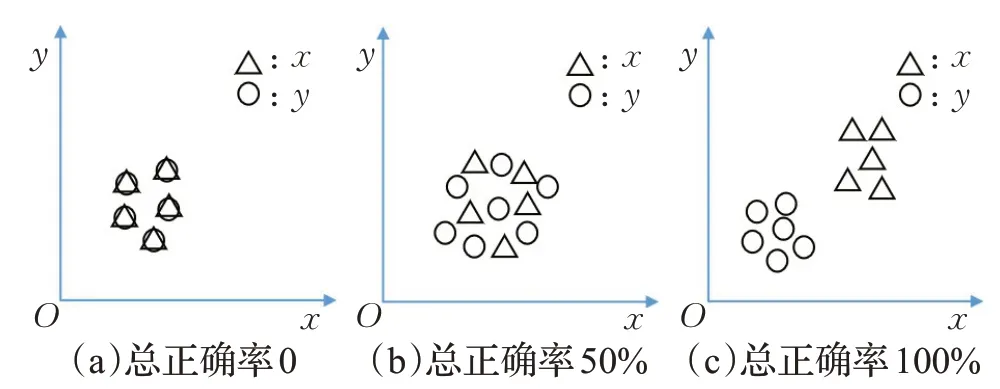
圖4 總正確率對比Fig.4 Comparison of total accuracy
2.7 GANtrain和GANtest方法
對于GANtrain和GANtest方法,它的設計思路是:計算給定的準確率并進行對比分析,從而評價能夠生成多類樣本GAN 的性能。定義:GANbase 代表驗證集上計算的準確率值,此時分類器在訓練集上訓練;GANtrain代表驗證集上計算的準確率值,此時分類器在生成集上訓練;GANtest 代表生成集上計算的準確率值,此時分類器在訓練集上訓練。
在理想情況下,GANbase和GANtest的數值應該趨于一致,但出現以下幾種情況時,說明GAN模型出現了異常:若GANtest 過高,則可能GAN 產生了過擬合、簡單記憶的問題;若GANtest過低,則可能GAN數據集分布欠佳,圖像質量較差。
2.8 歸一化相對鑒別分數(NRDS)
歸一化相對鑒別分數(Normalized Relative Discriminative Score,NRDS),此方法設計思路是:根據實踐經驗的分類器特性,若有足夠多的epoch,則可以得到一個能夠將訓練集和生成集兩類樣本完全區分開的分類器C,分類結果用1和0分別表示訓練集的樣本和GAN生成的樣本,此類方法的實質是把握分類器的epoch次數,通過觀察具體的epoch 變化就可衡量GAN 的生成性能。如圖5所示描述了單個epoch的訓練邏輯。
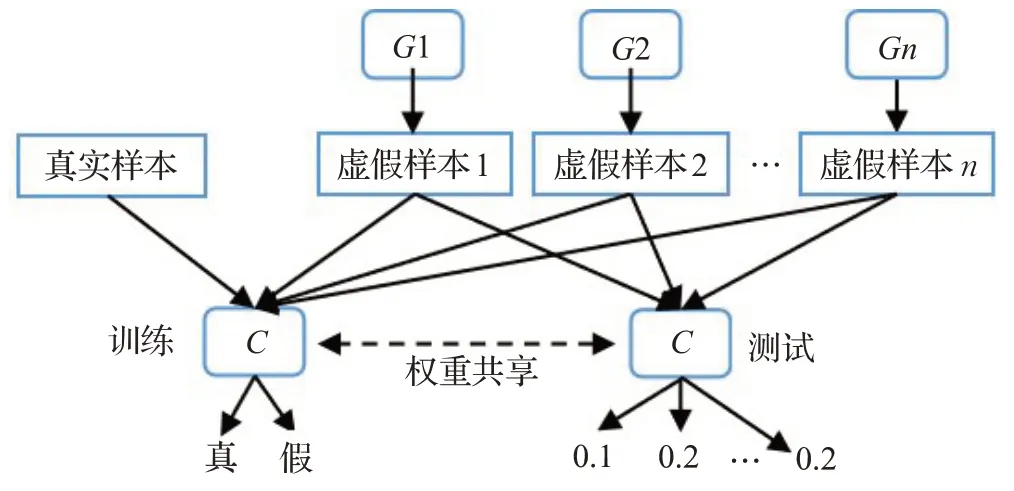
圖5 單個epoch訓練示意圖Fig.5 Schematic diagram of single epoch training
2.9 Image Quality Measures
針對圖像質量的量化方法,相比IS 等指標區別明顯,該類評價指標更關注圖像本身的質量,而非借助已訓練好的神經網絡等方法來確定模型生成表現能力。
2.9.1 結構相似性(SSIM)
結構相似性(Structural SIMilarity,SSIM)的設計思路是關注圖像的3 個特征:亮度l(x,y)、對比度c(x,y)、結構s(x,y)。從兩幅圖像相似度的角度思考,圖像樣本x與y之間通過以上3點特征進行比較衡量,以此來確定評價指標SSIM。王曙燕等人[39]在驗證生成對抗樣本模型的性能時,以SSIM指標計算,驗證了圖像多樣性與SSIM指標的關系。可依次在圖像上取N×N大小的以x或y為中心的圖像塊,計算3個參數并求解:
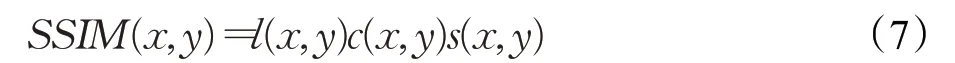
2.9.2 峰值信噪比(PSNR)
峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)作為評價圖像質量的客觀標準指標之一,通過對不同PSNR值的對比來評價條件生成對抗網絡的性能。若為彩色圖像有兩種計算方法:一是計算RGB 三通道的PSNR然后取均值;二為計算三通道MSE并除以3,再計算PSNR。綜上述所,顯然PSNR 的值與兩張圖像差異成反比,即PSNR越小,圖像之間的差異越大,則生成性能越差進而影響生成圖像質量較差。彭晏飛等人[40]利用SSIM和PSNR評價方法,實現了基于GAN的單圖像超分辨率重建法。
2.9.3 銳度差異(SD)
銳度差異(Sharpness Difference,SD)和PSNR 指標具有相似的計算方式,但其更關注銳度信息的差異。首先計算其銳度誤差,然后計算SD為:其中,符號的定義與PSNR 的數學表述一致。顯然,SD值也與生成圖像的質量成負相關,即SD 值越大圖像之間的銳度差別越小。

2.10 Average Log-likelihood
鑒于GAN 的初始設計架構,以上評價方法都將生成器視為黑盒子,即未將設計視角聚焦于生成器的概率密度函數。平均對數似然方法的提出解決了該問題,它的步驟為:假設概率密度函數pg的表達式關系存在,則評價指標的設計思路可為:計算訓練集的樣本在pg下的對數似然函數,原理等價于KL散度,但采用對數似然函數形式更加簡單。
但大量實踐經驗表明其評價效果欠佳,尤其在遇到高維分布的情況時,非參數對概率密度函數的估計存在誤差。另外,對數似然函數與樣本的質量依賴關系較差,即可能會出現GAN給出對數似然值很高,但樣本質量依舊很差的情況。
基于以上論述可以看到,不同的指標側重評價GAN 模型的關注點各異。針對實際應用中豐富的場景,應該盡可能在保持模型性能的前提下,多樣化地設計評價指標。
3 生成對抗網絡的變體研究及熱點應用
大數據賦能深度學習算法使其實現了快速發展,目前最先進的GAN 能夠生成不同類別的高保真自然圖像[41],且經過適當的訓練,它能夠從標準數據分布中合成語義上有意義的數據。Huang等人[42]和Goodfellow等人[43]討論并對比了GAN模型及其變體在生成樣本方面的重要性,Creswell等人[44]對GAN的評估方法和訓練問題進行了調查總結。這些通用的圖像生成調查報告,討論了GAN 的一般內容,沒有考慮每個模型的構造細節及優缺點。表1整理了近幾年發表的一些GAN不同應用綜述文章[45-58]。值得一提的是,GAN 自身伴隨著3 個重要的挑戰問題[54]待解決。
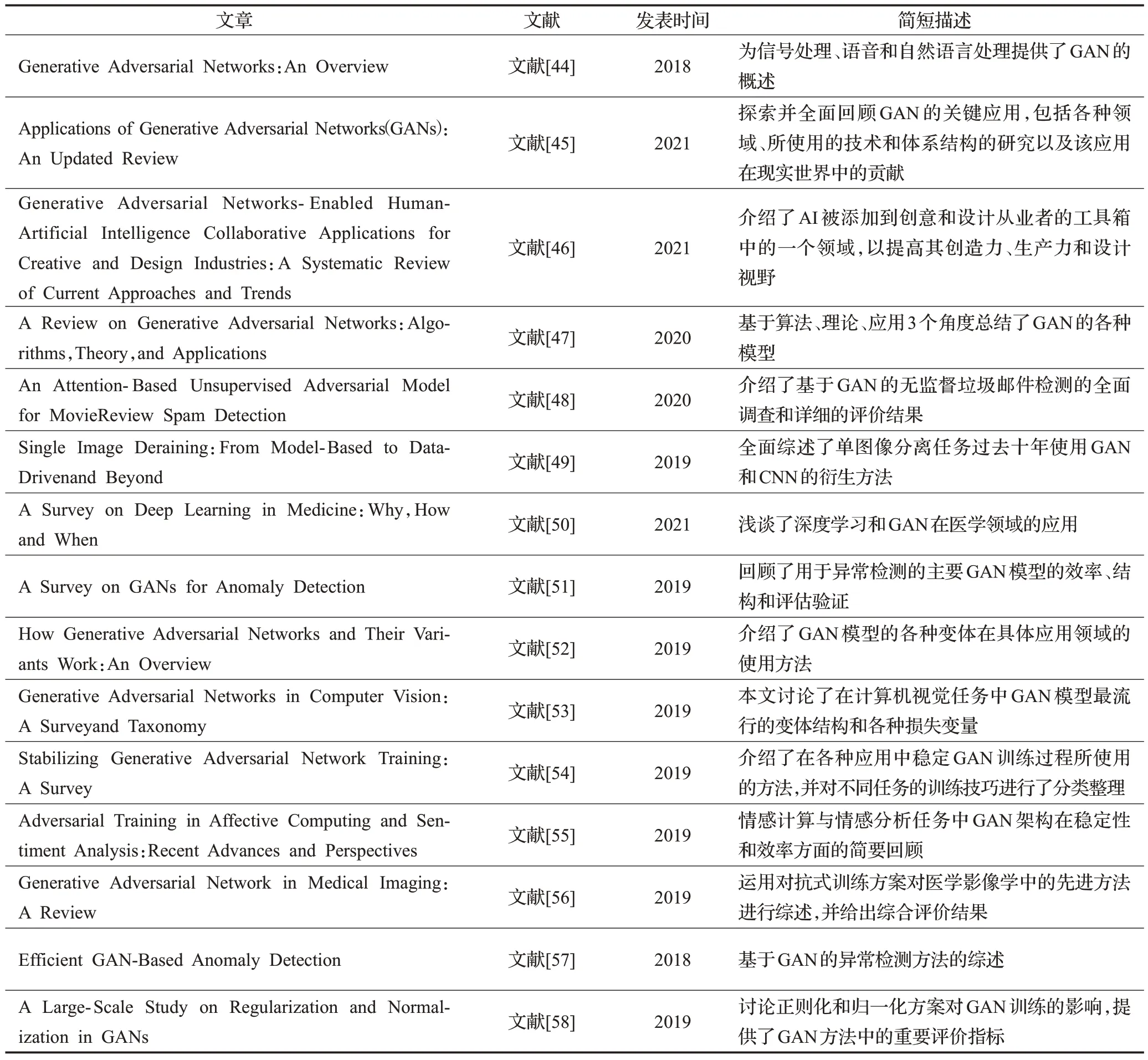
表1 近年來不同GAN應用的綜述總結Table 1 Summary of GAN surveys for different applications in recent years
(1)模式崩塌:關注并不局限于達到平衡的過程。GAN 最常見的故障之一是便是模式崩潰,當G將各種不同的輸入映射到相同的輸出時,就會發生這種情況。
(2)梯度消失:一個訓練良好的D將損失函數壓縮到0,因此,梯度近似為0,這將向G提供少量的反饋,導致學習放緩或完全停止。同樣,不準確的D會產生錯誤的反饋,從而誤導G。
(3)收斂性:盡管理論上已經證明了全局納什均衡的存在,但要達到這個均衡并非易事。GAN 經常會產生振蕩或循環行為,并傾向于收斂到局部納什均衡,這在主觀上可能遠離全局均衡。
文獻[44,59]表明,目前關于GAN 結構和性能的綜述論文很少,其他的研究工作主要集中在不同類型GANs架構的性能驗證上。由于基準數據集不能很好地反映多樣性,這些工作對于GAN 的綜合論述是有限的。因此,研究任務多集中在生成圖像質量的評價上,而這種結果導向也會降低GAN生成不同圖像的有效性。
基于以上觀察,首先介紹了GAN 的發展體系來解決它的3 個挑戰問題,并回顧了GAN 相關網絡結構在合成圖像的生成和識別方面的技術。其次,重點討論了GAN的各種應用,包括圖像轉換、圖像生成、視頻生成、文本生成、圖像超分辨率及其他領域等內容。
3.1 GAN模型的衍化及改進
針對各種應用需求而誕生的不同GAN 變體,衍化改進的方向主要是基于結構作出的改變和設計不同的損失函數。
為了設計GAN的初代架構,G和D[12]都使用了全連接(Fully Connected,FC)神經網絡,基于Toronto Face Dataset、MNIST[60]和CIFAR-10[61]數據集來生成假圖像。Chen 等人[62]提出了一種基于FC 層而建模的GAN框架,該框架僅在少數幾組數據分布上表現出高性能。從基于FC 的建模思想到基于卷積神經網絡(CNN)的建模思想,實驗證明后者更加適合處理圖像類數據,但會引入額外的計算復雜度問題,主要原因有5 個:不收斂;梯度減小;生成器和鑒別器不平衡;模式坍塌;超參數選擇。
其中一種解決方案是引入對抗網絡的拉普拉斯金字塔方法[63],在模型中將真實的圖像轉換為多尺度的金字塔式分層圖像,訓練卷積GAN 生成多尺度多層次的特征圖,并將所有特征圖結合到最終的特征圖以此來降低計算難度。在文獻[13]中提出的深度卷積GAN 模型能夠平滑生成器與鑒別器的訓練過程,為提高穩定性做了一定貢獻。對于3D合成數據的生成,Wu等人[64]提出使用自動編碼器和內容信息直接從2D 輸入圖像重建3D 目標的架構,但這種方法存在很高的計算成本問題。
接著,便是文獻[65]所提出的CGAN來解決圖像到圖像的翻譯問題,這種方法不僅學習了輸入圖像到輸出圖像的映射,還采用了損失函數來訓練這種映射。與其他GAN架構[66-67,20]相比,條件GAN在多模態數據上有顯著的性能。
另一方面,InfoGAN使用了一小部分潛在變量之間的互信息來獲取語義信息的結構,該模型可以應用于以一種無監督的方式確定不同的對象。Odena等人[68]提出了架構類似InfoGAN 的分類器ACGAN,損失函數的優化提高了其分類的性能。在文獻[69]中,提出了一種使用BAGAN的數據增強框架,在隱空間中應用類條件作用來運行面向目標類的生成過程。BAGAN 的結構與InfoGAN和ACGAN相似,但BAGAN只產生一個輸出,InfoGAN和ACGAN有兩種輸出。
在文獻[70]中,提出了DCGAN模型,其優勢來自于作為條件變量的語義布局和場景屬性。這種方法能夠在不同的情況下產生真實的圖像,具有清晰的對象邊緣。吳春梅等人[71]利用了DCGAN的優勢并結合了沙漏網絡,實現了有效的人體姿態識別。在文獻[72]中,建議將自動編碼器網絡(auto-encoder)與GAN[12]相結合,整合兩模型的優點:GAN 可以產生清晰的圖像但會損失部分特征,而auto-encoder 生成的圖像模糊但模型有效且準確。
接下來介紹的便是漸進式GAN 和輔助分類器GAN,前者主要用來解決訓練穩定性的問題,后者主要用來解決模式坍塌問題,各自分類的領域都有不少佳作。漸進GAN 擴展了標準網絡結構,其思想是從漸進神經網絡中提取[73]。此類模型性能表現良好,可以廣泛應用于提取復雜的特征是漸進網絡的特點,在訓練過程中逐漸增加D與G,所有的變量都可以參與訓練,這種漸進式的策略幫助網絡取得了穩定的學習率。最近,文獻[74-75]中的GAN 結構采用了這種訓練策略,來提高其模型的整體表現能力。
為了提高GAN 的半監督學習性能,文獻[68,76]提出在鑒別器中增加一個額外的精確輔助分類器。實驗結果表明,輔助分類器GAN 能夠生成更清晰對象邊緣的圖像,并能較好地處理模式坍塌問題,且帶有輔助分類器的GAN在諸如圖像到圖像轉換[68]和文本到圖像合成等應用中具有顯著的性能。
在對抗域適應研究領域,非配對圖像到圖像的轉換模型最近在不同的域適應任務上都有很好的性能。圖6展示了CycleGAN 和DCGAN[13]基于訓練損失的實驗性能。最近,有一種針對非配對圖像的新模型CoGAN,提出使用兩個共享權重生成器來產生帶有隨機噪聲的兩個域的圖像。所有這些模型在大量的圖像到圖像轉換任務中都有令人信服的視覺結果,但是,大范圍域的變化可能會降低這些方法生成大規模訓練數據的能力。表2 總結了最經典的十多種基于GAN 改進、衍化的模型,并整理對比了其改進點、優缺點與各自的使用場景。
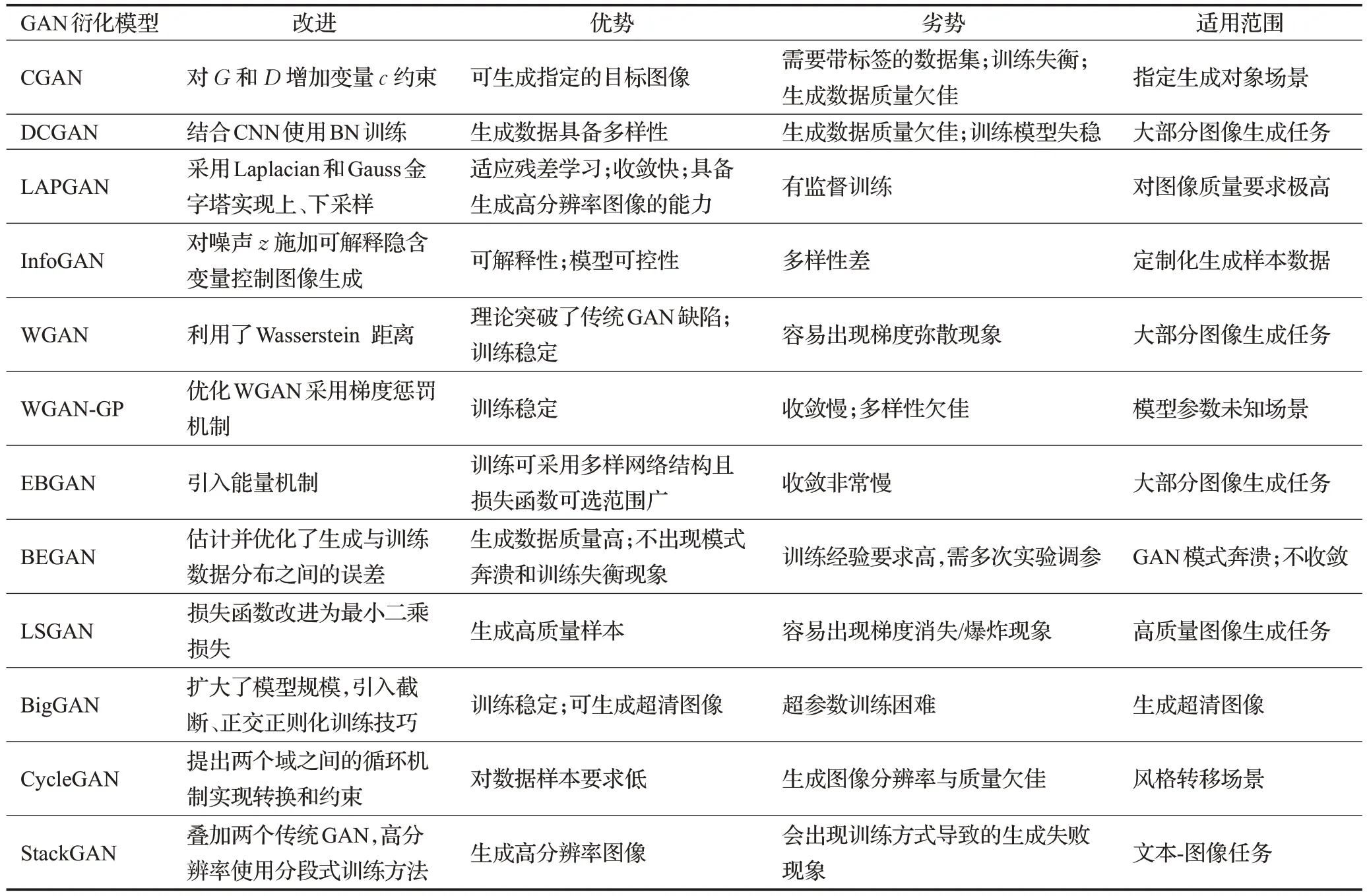
表2 經典GAN改進模型的總結與對比Table 2 Summary and comparison of classical improved GAN models
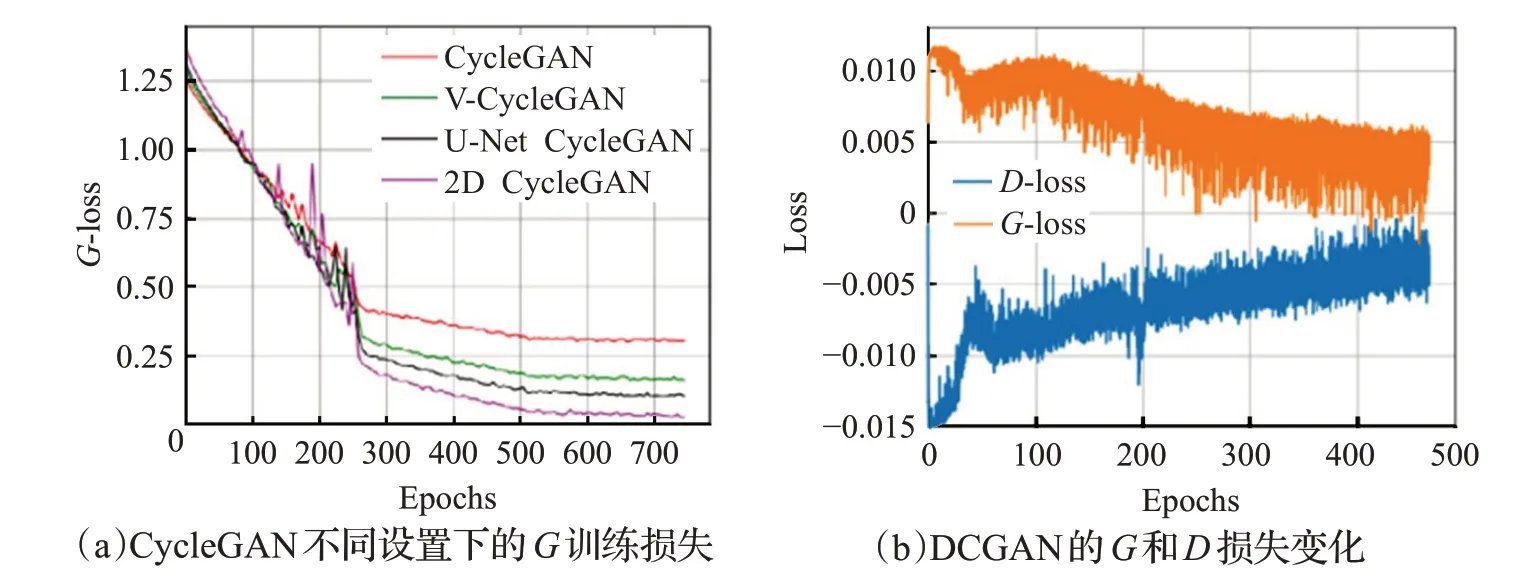
圖6 CycleGAN和DCGAN模型在flickr數據集上基于各自訓練損失的性能評估Fig.6 Performance evaluation of CycleGAN and DCGAN models based on their respective training losses on flickr dataset
3.2 生成對抗網絡的熱點應用
3.2.1 圖像轉換
大多數計算機視覺問題可以視為圖像到圖像的轉換問題,即從一個域映射到另一個不同域的圖像。圖7展示了貓及其姿態轉換為其他物種的結果。

圖7 貓到其他物種的轉換結果Fig.7 Cat to other species translation results
圖像到圖像的轉換還類似于風格轉換[77],作為輸入的是一幅風格圖像和一幅內容圖像,而模型輸出的是一個包含內容和風格的圖像,它不僅傳遞圖像的樣式,還控制了目標對象的特征。
圖像到圖像的轉換問題可分為監督學習和無監督學習兩種。在監督方法中,不同領域的成對圖像[65]可以使用。在無監督模型中,只有兩組分離的圖像,一組由一個域的圖像組成,另一組由其他不同域的圖像組成,沒有成對的樣本來表示一幅圖像如何轉換成不同域的對應圖像。
3.2.2 圖像生成
本節主要討論生成對抗網絡在圖像生成任務中的3個應用領域:醫學成像、三維重構、圖像融合。而對此類任務中合成數據的方法具有以下要求:(1)有效。產生有意義的和充分的數據樣本。(2)可感知任務。創建有助于目標網絡更好性能的樣本。(3)現實的。產生有助于最小化領域差距和增強泛化的現實樣本。圖8 展示了BEGAN、CGAN、LSGAN、StarGAN、DA-GAN模型在MNIST、FashionMNIST、CelebA、CIFAR-10 圖像數據集上樣本生成的實驗結果。

圖8 不同GAN模型在不同圖像數據集上樣本生成結果Fig.8 Different GAN models generate sample results on different image datasets
(1)醫學成像
一般來說,在醫學成像中使用GAN有兩種方法:第一種集中在生成階段,這有助于實現訓練數據的基本結構,以創建真實的圖像,使得GAN能夠更好地處理數據稀缺性和患者隱私問題[78-82]。第二種集中在判別階段,其中判別器可以被認為是未處理圖像的先驗學習,因此可以作為偽生成圖像的檢測器。
生成階段:Sandfort等人[83]提出了一種基于CycleGAN的數據增強模型,以提高CT 分割中的泛化性。Han 等人[84]提出了一種基于GAN 的兩階段無監督異常檢測MRI 掃描方法。在文獻[85]中,通過將創建的合成MR圖像與真實圖像進行比較,討論了兩種無監督GAN 模型(CycleGAN和UNIT)的表現結果。
判別階段:Tang等人[86]提出了一種基于疊加生成對抗網絡的CT圖像分割方法,網絡第一層減少CT圖像中的噪聲,第二層創建具有增強邊界的更高分辨率圖像。在文獻[87]中,提出了一種基于無監督學習的GAN 方法,能夠識別異常圖像。該模型包含了新數據到GAN潛在空間的快速映射技術,且這種映射是基于一個訓練效果良好的編碼器。Dou等人[88]提出了用于MRI和CT的GAN,通過以無監督方式支持源域和目標域的特征空間來處理高效的域轉移。
(2)三維重構
GAN 在三維空間上對物體的立體形狀補全或重構,是對三維重構技術的完善和擴展。Wang 等人[27]提出了一種混合結構,使用遞歸卷積網絡(LRCN)的3D-ED-GAN模型。圖9展示了3D-ED-GAN通過LRCN時的低分辨率形狀完成或重建結果。Wu等人[64]提出了3D-VAE-GAN模型,該模型利用體積卷積網絡和生成對抗網絡最新的研究理論從概率空間生成3D對象。在文獻[89]中,介紹了一種新的GAN訓練模型來實現物體詳細的三維形狀。該模型采用帶梯度懲罰的Wasserstein歸一化訓練,提高了圖像的真實感,這種架構甚至可以從2D圖像中重建3D形狀并完成形狀補全。

圖9 現實世界物品掃描的3D形狀完成效果Fig.9 3D completion results on real-world scans
Yang 等人[90]提出了一種3D-RecGAN 模型,該模型從一個隨機深度視圖重建指定對象的完整三維結構。在文獻[91]中,提出了一種迭代的GAN 模型,它根據物體的幾何形狀和外觀,迭代地將輸入圖像轉換為輸出圖像。Hermoza和Siiran[92]在GAN結構上提出了一種編碼器-解碼器3D 深度神經網絡,結合了兩個目標損失:用于3D 物體重建的損失和改進的Wasserstein GAN 損失。文獻[68]提出了用于語義部件編輯、形狀類比和形狀插值以及三維物體形狀補全的代數操作和深度自動編碼器GAN(AE-EMD)。
(3)圖像融合
從一組輸入圖像中生成新圖像的技術是GAN架構系統中一個有趣的研究領域,該技術被稱為圖像融合。在文獻[36]中,提出了一個基于GAN 的框架,稱為FusionGAN,它通過控制兩個輸入圖像來生成融合圖像。實驗證明,融合方法能夠改變輸入圖像的形狀和特征,生成新的圖像,同時保留輸入圖像的主要內容。Zhan等人[35]提出了一種新的融合方法SF-GAN,將前景物體和背景圖像合成真實圖像,通過一系列的實驗證明了該模型的有效性。此外,想關文獻[34,37,93-94]還提出了幾種使用GAN 體系結構的方法,以便將輸入轉換為所需的形狀,并提高融合性能。
3.2.3 視頻生成
視頻可通過逐幀分解理解為多張圖片的組合,故而在GAN 生成圖像的基礎上,實現視頻的生成和預測[89]。視頻一般而言是由相對靜止的背景色和動態的物體運動組成的,VGAN[6]考慮了這一點,使用雙流生成器以3D CNN 的移動前景生成器預測下一幀,而使用2D CNN 的靜態背景生成器使背景保持靜止。Pose-GAN[7]采用混合VAE 和GAN 方法,它使用VAE 方法在當前的物體姿態和過去姿態隱藏的表示來估計未來的物體運動。
基于視頻的GAN 不僅需要考慮空間建模,還需要考慮時間建模,即視頻序列中每個相鄰幀之間的運動。MoCoGAN[5]被提出以無監督的方式學習運動和內容,它將圖像的潛在空間劃分為內容空間和運動空間。DVD-GAN[95]能夠基于BigGAN 架構生成更長、更高分辨率的視頻,同時引入可擴展的、視頻專用的生成器和鑒別器架構。
3.2.4 圖像修復
圖像補全是一種傳統的圖像修復處理任務,其目的是填補圖像中內容缺失或被遮蓋的部分,在目前的生產生活環境中此類任務得到廣泛的現實應用。大多數補全方法[96]都是基于低級線索,從圖像的鄰近區域中尋找小塊,并創建與小塊相似的合成內容。王海涌等人[97]借助此原理,實現了局部遮擋情況下的人臉表情識別,識別效率較高。與現有的尋找補全塊進行合成的模型不同,文獻[98]提出的模型基于CNN 生成缺失區域的內容。該算法采用重構損失函數、兩個對抗性損失函數和一個語義解析損失函數進行訓練,以保證像素質量和局部-全局內容的穩定性。
在文獻[99]中,為了完成圖像補全,引入了融合塊來生成靈活的Alpha 合成圖,用于組合已知和未知區域。融合塊不僅提供了恢復和現有內容之間的平滑融合,而且提供了一個注意力機制,使網絡更多地關注未知像素。然而,該模型在CelebA數據集上表現良好,但在高分辨率圖像上表現不佳然而,如圖10所示。

圖10 圖像補全應用的生成效果Fig.10 Generating effect of image completion application
3.2.5 文本生成
GAN 在圖像上的性能表現,讓眾多研究者在文本生成領域也提出了基于GAN 的一些模型。SeqGAN 與強化學習結合,避免了一般GAN 模型不能生成離散序列,且可在生成離散數據時能夠返回模型的梯度值,此類方法可用于生成語音數據、機器翻譯等場景。研究提出的MaskGAN[100]模型,引入了Actor-Critic 架構,可根據上下文內容填補缺失的文本信息。
除了圖像生成文本的應用,StackGAN[28]可實現通過輸入文本信息來產生相應的文本所描述的圖像且圖像具有高分辨率,此模型實現了文本與圖像的交互生成。此外CookGAN從圖像因果鏈的角度實現了基于文本生成圖像菜單的方法,而TiVGAN則實現了通過文本來產生連續性視頻序列的構想。
3.2.6 圖像超分辨率
圖像超分辨率技術主要解決將低分辨率的圖像在不失真的前提下轉變為高分辨率的問題,且需要在準確性和速度方面保持優越性能,此外超分辨率技術可解決例如醫學診斷、視頻監控、衛星遙感等場景的部分行業痛點問題,應用此技術產生的社會實際價值不可估量。文獻[101]概括了基于深度學習的圖像超分辨技術,并將其分為有監督、無監督、特定應用領域3種類型,提供了系統性的超分辨理論與實踐方法。文獻[25]提出的SR-GAN模型將參數化的殘差網絡代替生成器,而判別器則選用了VGG 網絡,其損失函數通過內容損失和對抗損失的加權組合,相比其他深度卷積網絡等模型在超分辨精度和速度上得到了改進,將圖像紋理細節的學習表征較好,故而在超分辨領域取得了不俗的效果。
3.2.7 其他領域
CaloGAN和LAGAN被應用于物理學,試圖生成粒子圖像來代表能量分布。Shin等人[102]將GAN框架擴展到持續學習,使其通過一個稱為深度生成重放的GAN框架解決了學習遺忘問題。文獻[103]提出了一個能夠用于破譯密碼的框架,使GAN 能應用于密碼破譯。除以上領域,生成對抗網絡還在其他方向成功應用,如:域適應、序列生成、半監督學習、語義分割、對抗攻擊、機器翻譯、自動駕駛等。
4 討論與展望
生成對抗網絡在如今的學術與工業界研究不斷升溫,集中在圖像生成領域的研究也是如火如荼,出現了各種各樣的GAN 模型。但在應用過程中它所面臨的3個挑戰[61]:模型坍塌、梯度消失及全局收斂問題也逐漸表現出來。
首先,值得關注GAN 研究領域的重點問題之一圖像生成質量與多樣性,盡管現有的技術可以實現圖像高質量生成,但伴隨著以上挑戰的不斷重現,在生成圖像多樣性的技術發展上卻展現出較多的困境,其受限于圖像的大小及尺寸、模型的結構設計及復雜度等因素。其次,需要討論的是為追求產生高質量和多樣性皆佳的圖像而出現的模型訓練效率低下問題,一般而言模型性能和訓練效率正相關,即效果越好的模型訓練時間就會越長。此外,在主觀和客觀評價標準上未形成通用且成熟的GAN 模型評價體系,導致在應用場景數據集上表現良好而遷移至其他領域時出現不適用的情況。
通過對生成對抗網絡的熱點應用的歸納及對現有GAN 網絡因其自身缺陷所導致的發展問題討論梳理,未來研究生成對抗網絡的潛在突破口應主要集中在以下幾個方面。
4.1 理論探索
理論研究的目的主要是解決GAN模型的自身缺陷問題,但現有的方法都以調整訓練參數和修正訓練過程為主,而對GAN 自身缺陷的理論探索還不夠深入。因此,關注對基礎算法的結構設計和以應用目標為導向的損失函數設計等角度進行理論突破。如可關注對傳統結構的變體CGAN等網絡結合現有算法的優勢,對模型的架構進行改進,并設計出通用且合理的約束條件,可保證在模型穩定情況下,關注在保持圖像生成質量和多樣性具佳的損失函數設計。
4.2 內部機理透明化
相比機器學習,深度學習由于其模型復雜度成量級增長,訓練和計算過程“隱蔽”且無法溯源,使得研究模型的內部工作機制變得尤為重要。使用合適的工具,實現模型內部信息流工作機理的透明化研究,可以從根源上發現影響模型穩定性和訓練過程的問題,然后對其分析解決以此突破模型的性能瓶頸。尤其對于解決GAN模型是如何生成圖像的表征問題及生成器與鑒別器達到全局收斂的可視化問題迫在眉睫。此外,生成網絡的可控性問題也尚沒有完全攻克,只取得了特定場景的實驗效果而未能達到控制效果的不同場景通用性。
4.3 規范評價標準
在圖像生成領域的模型評價方法中,雖然對常見的評價尺度作了一定的介紹,但如何綜合且客觀地評價不同的模型,仍然沒有一個準確嚴謹的定論。因此,在未來的研究工作中,借助神經網絡強大的擬合能力是否可以設計根據場景來定義評價標準的搜索空間,并設計合適的搜索策略,在綜合且恰當的評價指標下自動找到該場景適用的最佳模型。實現這一方法,不免會持續關注生成對抗網絡的科學性評價標準,此方向仍有巨大的突破潛力及研究價值。
4.4 領域擴展
以生成方法為理論基礎的GAN 模型,本身具有很強的可擴展性,在研究過程中可以考慮引入其他學科理論知識來提升模型的表現能力,如信息論、生物科學、認知科學等的理論融合。
模型的泛化能力、魯棒性是GAN 可移植于不同場景的重要參考指標,關注二者可將其擴展到其他領域來挖掘更加有價值的應用場景。因此,結合應用領域的知識,拓展其豐富的應用場景也將是未來的研究熱點之一。
總的來說,生成對抗網絡在理論和應用方面具有重要的研究意義,是一個具有挑戰性的研究問題。
5 結束語
本文首先依托極大似然原理介紹了生成模型,并討論了似然理論框架下的生成對抗網絡。其次,重點介紹了生成對抗網絡的各種評價標準,分析了之間的聯系與區別,并介紹了GAN模型在數據生成方面的熱點應用,包括:圖像轉換、圖像生成、視頻生成、圖像修復、文本生成、圖像超分辨率等。然后對生成對抗網絡潛在的研究突破口進行了梳理,即GAN 的理論探索、內部機理、評價方法、領域擴展等,最后對全文進行了概括總結。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
石油瀝青(2021年4期)2021-10-14 08:50:44
世界科學技術-中醫藥現代化(2021年10期)2021-03-02 05:52:06
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
中國工程咨詢(2015年2期)2015-02-14 02:59:26
俄羅斯問題研究(2012年1期)2012-03-25 09:54:51
