融合多種使用詞信息方法的命名實體識別研究
2021-10-19 13:16:22郭鵬劉俊南
現代信息科技 2021年6期
郭鵬 劉俊南


摘 ?要:文章對融合詞信息增強中文命名實體識別問題進行了研究,提出一種用于中文命名實體識別的融合詞信息神經網絡模型系統。首先使用預訓練語言模型Bert對字進行編碼得到字標識,然后使用SoftLexicon基于統計的方法將詞統計語義信息融合進入字表示中,之后使用設計的GraphLexicon根據文本內字、詞之間的交互關系圖結構,將字詞信息表示相互融合,達到較高的命名實體識別準確率。
關鍵字:中文命名實體識別;圖神經網絡;融合;詞信息;字詞交互;圖結構
中圖分類號:TP183 ? ? 文獻標識碼:A 文章編號:2096-4706(2021)06-0025-04
Research on Named Entity Recognition Based on Multiple Words Used
Information Methods
GUO Peng,LIU Junnan
(Innovem Technology (Tianjin)Co.,Ltd.,Tianjin ?300384,China)
Abstract:In this paper,the problem of enhancing Chinese named entity recognition by fusing word information is studied,and a neural network model system based on fusing word information for Chinese named entity recognition is proposed. First,the pre training language model Bert is used to encode the character to get the character identification,and then the statistic based approach SoftLexicon is used to fuse the word statistical semantic information into the character representation. Then,according to the structure of the interaction graph between characters and words in the text,the character and word information representation are fused to achieve a high accuracy of named entity recognition.
Keywords:Chinese named entity recognition;graph neural network;fuse;word information;character and word interaction;graph structure
0 ?引 ?言
中文命名實體(Named Entity Recognize,NER)[1]識別是指標記識別出輸入文本中特定的實體,并確定該識別類型,例如人名,地名,機構名稱,手術名稱,患病部位等。命名實體識別經常作為其他自然語言處理系統的預處理步驟,例如關系抽取,事件抽取,問答系統等。作為自然語言文本結構化系統的重要部分,為了構建結構化系統,提升中文命名實體識別的準確率是非常重要的。
早期的命名實體識別大多是基于規則的方法,但是由于語言結構本身具有不確定性,制定出統一完整的規則難度較大。現階段針對命名實體識別問題最有效的方法是機器學習的方法。傳統的機器學習的命名實體識別方法大多采用有監督的機器學習模型,如SVM、HMM、CRF等。最近幾年深度學習在自然語言處理上得到廣泛的應用,如循環神經網絡BiLSTM-CRF,卷積循環神經網絡BiLSTM-CNN-CRF,圖神經網絡模型GraphNN以及許多其他方案模型,如將命名實體識別作為問答解決的變體模型。谷歌在2018年發布預訓練語言模型BERT[2],將多項自然語言處理任務的結果精度推到了更高的精確度。
相對于英文命名實體識別,中文沒有明顯的詞邊界,因此直覺上會認為對于中文自然語言處理只使用字信息就足夠完成命名實體識別任務,雖然這樣會缺失詞信息。然而詞信息對于中文命名實體識別乃至其他中文自然語言處理任務都是十分有價值的,例如識別機構名“北京機場”時,如果輸入有詞“北京”“機場”的邊界信息和詞信息,會增加機構名的識別概率。
本文結構為:第一章介紹詞信息的命名實體識別相關工作,第二章介紹本文設計的模型結構,第三章通過實驗對比其他方法模型并進行分析,第四章對本文工作進行總結。
1 ?相關工作
由于引入詞信息可以增強命名實體識別準確率,出現了很多方法將詞信息融合到命名實體識別任務中,如:聯合學習中文分詞(Chinese word segment,CWS)和命名實體識別,但聯合學習方法需要詞邊界標注信息,需要花費大量精力進行額外的分詞標注。又如:使用word2vec,word2vec使用大量領域內文本進行訓練得到。Word2vec包含了詞邊界信息和詞語義信息。相對于聯合方案,word2vec更容易獲得,并且不需要額外的分詞標注,例如Lattice-LSTM將詞信息融合進入LSTM網絡結構中,FlatBert將詞信息和字信息展平,通過Attention模型進行注意力計算[3]。
然而融合詞信息的方法多種多樣,怎么有效的融合詞信息仍是一個開放挑戰,Lattice-LSTM為了融合詞信息,會將詞作為文本內的子序列,在字序列上為詞子序列增加大量額外鏈接,極大的加劇了訓練和推斷的時間,并且由于模型的復雜結構,導致該方法無法遷移使用到其他結構中。SoftLexicon通過使用BMES(begin,middle,end,single),在字序列上通過融合詞的不同交互位置的統計信息和詞語義信息,實現利用詞信息。這樣的方法使用了很多統計信息,而統計信息隨著訓練數據量的降低,會降低模型準確率。CGN(Collaborative Graph Network)[4]方法,構建字詞的多種不同的鄰接圖,然后通過圖神經網絡,將詞信息融合進入命名實體識別系統,該方案因為構建了多種圖結構,存在多次重復的交互計算,模型計算復雜,沒有充分利用圖神經網絡能力。
本文在CGN模型基礎上通過改進其鄰接圖的設計方法,融合其設計的不同的網絡結構,只構建一個鄰接圖。進一步利用SoftLexicon在領域數據上的詞統計信息的使用方法,構建一個多種利用詞信息的模型方法。經過在多個數據集上的測試,發現本文設計的方法達到當前最佳模型系統效果。
2 ?模型結構
本文設計的命名實體識別模型,利用兩種使用詞信息的方式,在不同角度上將詞信息和字詞關系融合進入字表示,來增強模型的命名實體識別性能。首先使用Bert[2]預訓練模型,對輸入字符進行編碼得到字表示,然后使用SoftLexicon得到的字對應的BMES詞表示,通過拼接方式融合到字表示中。然后改進CGN使用字詞交互信息的方式,通過GAT(Graphs Attention[5])層將字詞相關矩陣和詞信息融合進入字表示中,最后通過CRF層對編碼表示進行解碼,得到命名實體識別標簽序列。記本文設計的模型為Graph+Soft。
接下來,介紹模型詳細模塊結構,包括編碼模塊、SoftLexicon詞統計信息融合模塊和構建字詞相關關系圖和字詞交互圖注意力網絡模塊。
2.1 ?編碼
設輸入序列S={c1,c2,…,cn}為輸入文本,ci為輸入文本序列的第i個字,通過編碼器將輸入序列編碼為特征序列X={x1,x2,…,xn}。
2.2 ?SoftLexicon
SoftLexicon方法在領域文本內對詞典內詞進行詞頻統計,以用作將詞表示(word embedding)融合進入字表示的融合權重。首先,獲得輸入序列的每個字的字表示(char embedding)。然后,構建SoftLexicon特征,并拼接在字表示上,增強字表示。整體結構如圖1所示(圖中實線框表示字或詞,虛線框代表與該字具有BMES交互位置相關的詞)。
對詞在數據集文本內進行詞頻統計,z(w)代表詞w在數據集中的出現次數。注意,如果w被另外一個詞覆蓋,則這個樣本內w不進行計數。
對每個詞ci搜索獲得文本內對應的所有匹配詞W(ci),然后將W(ci)根據ci在詞w中的位置BMES(開始,中間,結束,單個)分成四類,構成四個詞序列WB(ci),WM(ci),WE(ci),WS(ci)。
獲得BMES序列后,以統計計數作為權重和詞表示,每個序列加權平均得到一個新的與字相關的融合表示,eW為詞向量表。BMES對應的字相關詞信息的計算公式為:
(1)
(2)
將字表示和詞統計語義信息在特征維度上進行拼接融合得到新的字表示:
(3)
2.3 ?GraphLexicon
在使用SoftLexicon方法通過BMES序列強化實體邊界和引入詞信息后,模型還通過字詞相關關系圖注意力網絡融合字詞信息,進一步利用詞信息,即將字詞信息按照字詞間的關系以圖方式進行交互,進而實現將字詞間關系和詞信息融合進入字序列表示。
CGN方法詳盡地描述了字詞之間的關系,但是由于每種關系分別進行圖注意力計算,導致計算冗余,三種關系結果的拼接融合信息利用不充分。
本文設計GraphLexicon模塊,修改CGN方法,通過合并多種關系圖結構,將字與其所有有關的字和詞都構建成為一個統一的相關關系圖,然后使用圖神經網絡通過該相關關系圖將字相關的字和詞信息融合到字序列中,實現字詞相關融合,減少冗余計算,不用拼接融合不同的信息,提升圖結構的使用效率,如圖2所示。
圖2中,字與字之間存在鄰接關系,字與詞之間存在鄰接關系、包含關系、邊界關系。這里實線代表字詞間的包含關系,虛線代表字詞間的鄰接關系,詞和字邊界的關系包含在了包含關系中,輸入字序列表示為Xci,長度為N,詞序列表示為XWi,長度為M,構建成展平的表示序列F={XC,XW},長度為L=N+M。此時特征序列表示為F={f1,f2,…,fN+M},根據字詞相關關系圖構建關系矩陣A,如果fi,fj存在關系,則Aij=1否則Aij=0 。
具體計算流程如式(4)~式(9)所示:
fih=Wfi ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? (4)
att1=Repeat(α1fih,n=L,dim=-1) ? ? ? ? ? ?(5)
att2=Repeat(α2fih,n=L,dim=-1) ? ? ? ? ? ?(6)
att=att1+att2 ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? (7)
(8)
(9)
W,α1,α2為可訓練參數,W將特征維度Fin變換為Fout,α1,α2將特征加權平均計算得到權值,Repeat()為復制操作,在dim維度上,復制n份。
此時G∈RFOUT×(N+M),保留了融合后的字表示和詞表示。通過切片操作最終只保留融合信息后的字表示Q=G[:,0:N]。
至此,將字詞相關關系和詞表示XW通過字詞相關關系Aij融合進入了字表示Xc中,經過一個殘差層,強化字表示R=W1Xc+W2Q。
2.4 ?解碼
本文使用標準的CRF層來進行序列標簽解碼,給定一個句子S={c1,c2,…,cn},CRF層的輸入是R={r1,r2,…,rn},真實標簽序列為Y={y1,y2,…,yn},其概率為:
(10)
其中,W yi為激發矩陣,T為轉移矩陣,使用Viterbi算法進行解碼,來獲得得分概率最高的標簽序列。
3 ?實驗
3.1 ?實驗設置
本文設置使用三個公開的中文命名實體識別數據集進行測試實驗,分別是Weibo NER,MSRA NER和Resume NER。其中Weibo是社交領域的命名實體識別數據集,MSRA和Resume都是新聞領域命名實體識別數據集。進行兩個對比實驗,分別實驗本文修改的GraphLexicon和Graph+Soft的準確率和性能。本文在評價模型進行命名實體識別任務的效果時,采取通用的查準率和召回率結合之后的F1值指標,F1值越大,說明模型識別的效果越好。
3.2 ?實驗結果及分析
為了方便對比,由于SoftLexicon和CGN在原論文實現中,沒有使用Bert作為字表示的編碼器,本文Bert作為編碼器重新實現得到SoftLexicon-bert和CGN-bert模型。
GraphLexicon是本文設計修改了CGN的方法,以Bert為編碼器。
表1顯示了GraphLexicon和本文提出的Graph+Soft在三個數據集上和其他方法的對比結果。在三個數據集上,本文修改的GraphLexicon方法,相對于原始CGN-bert方法F1(%)值都有提升,對應為3.63,0.62,0.08。本文提出的Graph+Soft,對比CGN-bert兩個方法F1(%)值分別提升5.03,1.76,0.05(CGN-bert)和4.55,1.90,0.39(SoftLexicon-bert)。結果顯示本文修改的GraphLexicon和本文提出的Graph+Soft命名實體識別模型結構,都達到了極高的準確率(為更直觀體現對比結果,表1中各項最高值加粗表示)。
表1 ?GraphLexicon和Graph+Soft與其他方法在NER
數據集上進行的對比實驗
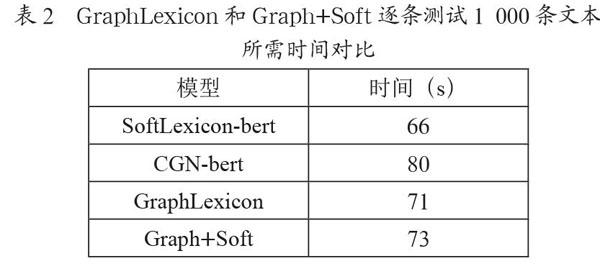
表2GraphLexicon和Graph+Soft逐條測試1 000條文本所需時間對比顯示,GraphLexicon相對CGN-bert識別速度提升11.25%。同時對比表1GraphLexicon和Graph+Soft與其他方法在NER數據集上進行的對比實驗中CGN-bert和GraphLexicon的實驗結果發現,CGN-Bert原始設計的三個鄰接矩陣需要對三個不同的字詞關系圖,進行三次字詞圖注意力網絡計算,耗時較大,并且識別結果交叉,說明計算性能不高,本文修改的使用統一的字詞相關關系圖進行一次圖注意力網絡計算,不僅提升了模型準確率,并且提升了模型效率。
表2 ?GraphLexicon和Graph+Soft逐條測試1 000條文本所需時間對比
4 ?結 ?論
在本文工作中,我們為了進一步利用詞信息,從兩個角度使用詞信息融合進入字表示中,并修改了CGN網絡方法,提升識別準確率的同時,提升了模型性能。本文提出的模型結構在詞信息的利用上簡單易用,后續可以輕易擴展到相關的自然語言處理任務上,例如信息抽取、事件抽取等序列標記任務。
參考文獻:
[1] DAVID N,SATOSHI S. A survey of named entity recognition and classification [J].Lingvistic Investigationes.International Journal of Linguistics and Language Resources,2007,30(1):3-26.
[2] DEVLIN J,CHANG M,KENTON L,et al. Bert:Pre-training of deep bidirectional transformers for language understanding.arXiv preprint arXiv:1810.04805.
[3] MA R,PENG M,ZHANG Q,WEI Z,et al. Simplify the Usage of Lexicon in Chinese NER [C]//Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics.2019:5951-5960.
[4] SUI D B,CHEN Y B,LIU K,et al. Leverage Lexical Knowledge for Chinese Named Entity Recognition via Collaborative Graph Network [C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing(EMNLP-IJCNLP).Hong Kong:Association for Computational Linguistics,2019:3830-3840.
[5] VELI?KOVI? P,CUCURULL G,CASANOVA A,et al. Graph Attention Networks [J/OL].arXiv:1710.10903v1 [stat.ML].(2018-02-04).https://arxiv.org/abs/1710.10903v1.
作者簡介:郭鵬(1988—),男,漢族,河南信陽人,總工程師,碩士研究生,研究方向:無線通信,人工智能;劉俊南(1990—),男,漢族,天津人,中級軟件工程師,本科,研究方向:語音識別,自然語言處理。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
中華手工(2017年2期)2017-06-06 23:00:31
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
中外會展(2014年4期)2014-11-27 07:46:46
祝您健康(1987年3期)1987-12-30 09:52:32
