基于Python網絡爬蟲和數據可視化技術的某招聘網站數據采集與分析
2021-10-21 08:51:30接輝
科技信息·學術版 2021年15期
接輝
隨著信息技術的深入發(fā)展和廣泛應用,網絡平臺成為各類信息發(fā)布和收集的主要渠道。網絡爬蟲作為網絡數據采集的重要技術手段,已廣泛應用于各個領域。本文使用基于Selenium 技術的網絡爬蟲,從某招聘網站采集到北京、上海、深圳、南昌四個城市IT行業(yè)招聘信息,使用數據可視化技術進行分析研究,得出了一些有益的結論。本文采用的數據采集和可視化分析方法對于一般研究工作具有普遍的借鑒意義。
一、相關技術
1.網絡爬蟲
網絡爬蟲是按一定規(guī)則自動抓取互聯網信息的程序或腳本。在大數據時代,網絡爬蟲是進行數據收集的有效手段。目前網絡爬蟲一般使用Python語言調用Requests、BeatifulSoups、Selenium等類庫實現。
2.Selenium
Selenium是一款開源的Web應用程序測試工具,可以在瀏覽器中模擬用戶請求網頁服務,很難被網站檢測到,能有效規(guī)避各種反爬蟲策略。
3.SQLite數據庫
SQLite是一款輕型數據庫,占用資源少,支持主流操作系統,支持ODBC接口。與一般數據庫不同,SQLite引擎嵌入在程序中,整個數據庫系統存儲在單一文件中。在很多應用場景,它的處理速度優(yōu)于MySQL、PostgreSQL等數據庫。
二、目標網站分析
本文以某招聘網站為目標,通過觀察法分析出網站頁面間的邏輯關系。
1.首頁與登錄頁
使用FireFox瀏覽器打開網站首頁(https://www.zhaopin.com/),找到用戶注冊登錄頁面(https://passport.zhaopin.com/login)。注冊后返回首頁,選擇用戶名、密碼方式登錄。
2.職位搜索頁
登錄后,進入“職位搜索”頁,可以輸入關鍵詞搜索職位,還可以選擇不同的城市、職位類別、公司行業(yè)以及列表的頁碼等。本文選擇自己關心的城市、行業(yè)和頁碼,發(fā)現隨著選擇的不同地址欄中鏈接的參數也會發(fā)生變化。比如城市選擇南昌時jl=691,行業(yè)選擇電子商務時in=100020000,頁面選擇第2頁p=2,瀏覽器地址欄中的鏈接變?yōu)閔ttps://sou.zhaopin.com/?jl=691&in=100020000&p=3。
3.職位詳情頁
在職位搜索頁列表中,可以看到職位名稱、公司名稱、工資待遇、崗位要求等基本信息。查看職位詳細信息需要進入詳情頁。在職位搜索列表頁,使用瀏覽器檢查工具可以找到詳情頁的鏈接地址信息(https://jobs.zhaopin.com/后加一個無規(guī)律的html文件名)。
在詳情頁中,右鍵點擊詳細信息進入“檢查”菜單,可以找到職位描述等文字信息所在的頁面元素。
三、系統設計與實現
根據對網站的分析,系統可分為頁面解析、數據采集與存儲、數據可視化分析三個模塊。
1.頁面解析模塊
在這個模塊中,主要實現網頁加載和頁面結構解析與元素定位。
通過前文分析可知,我們需要加載和解析的頁面主要是登錄頁、職位搜索頁和職位詳情頁,相關頁面的鏈接在分析中已經獲取。我們可以使用browser = selenium.webdriver.Firefox()方法加載火狐瀏覽器的驅動程序,然后通過其browser.get(url)方法,獲取鏈接url對應的頁面。
首先實現頁面自動登錄。通過browser.get(“https://passport.zhaopin.com/login”),獲取登錄頁。在登錄頁的中,分別找到用戶名、密碼所在的位置點擊鼠標右鍵,選擇“檢查”菜單;在檢查頁面中相應的頁面元素上點擊右鍵,復制XPath;將復制的XPath作為參數,通過 browser.find_elements_by_xpath(XPath)方法獲取輸入用戶名、密碼的網頁元素,調用sendkeys()方法將用戶名、密碼分別傳送給瀏覽器,模擬用戶輸入用戶名和密碼;再用同樣的方法獲取“登錄”按鈕所在的網頁元素,調用click()方法模擬用戶點擊登錄。登錄時,如遇圖片滑塊驗證,可手動操作(只需在爬蟲開始運行時操作一次)。
用同樣的方法可以獲取職位搜素列表頁和職位詳情頁。
2.數據采集與存儲模塊
完成網頁解析后,使用Selenium類庫函數定位到需要的網頁元素,訪問其text屬性即可獲取相應的數據。通過這種方式可獲取職位名稱、公司名稱、工資待遇、崗位職責、技能要求、詳細描述等信息。
在進行數據存儲時,使用sqlite3.connect()方法獲取數據庫連接,再調用其cursor().execute(sql)方法,執(zhí)行相應的sql語句即可。
程序執(zhí)行時,容易被網頁錯誤、數據庫錯誤打斷,影響數據采集效率。可將網頁獲取、數據庫讀寫操作放在try...except語句中,對產生的異常進行處理;同時將try...except語句塊放在循環(huán)語句中,循環(huán)重試若干次后如仍異常則記錄錯誤并跳過當前頁面,繼續(xù)采集后續(xù)頁面。
3.可視化分析模塊
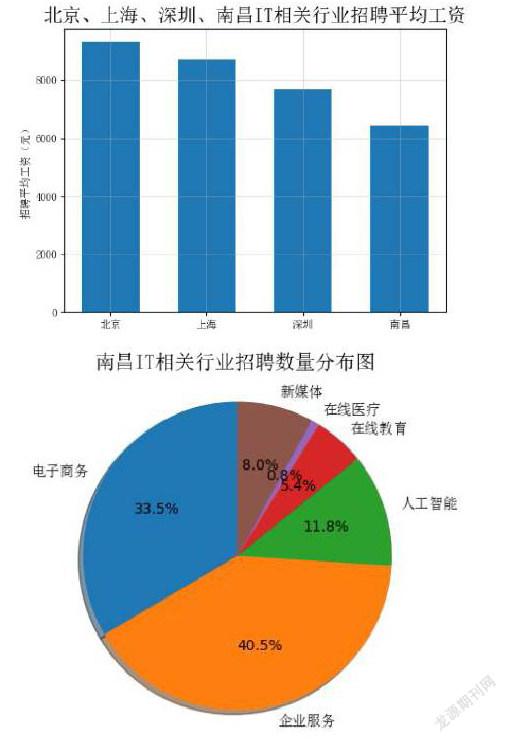
筆者發(fā)現,因網站限制,每個細分行業(yè)只能查詢到34頁共1020條招聘信息。北京、上海、深圳的實際數據超過了這個數量,不適合進行招聘職位的行業(yè)分布分析;南昌沒有達到這個限額,不受影響。
在工資收入方面,一般來說招聘信息中的下限值比較接近真實收入情況。
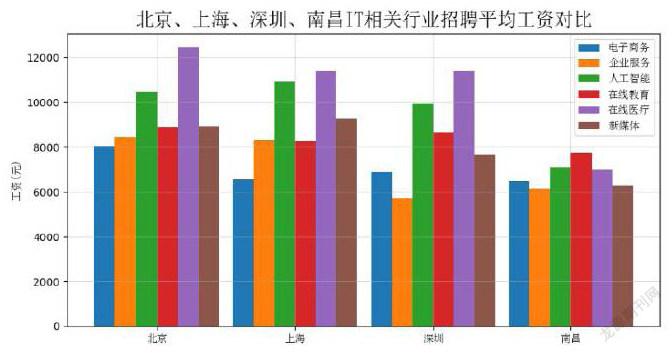
根據上述特點,本文從四個城市的行業(yè)平均工資、招聘數量行業(yè)分布、職位平均工資三個方面,使用Python的matplotlib類庫的數據可視化方法,分別以下列條形圖、餅狀圖的形式進行展示。
四、總結
根據上述分析,可以得出以下結論:
1.南昌IT行業(yè)總體工資水平和行業(yè)間差異低于北京、上海和深圳等一線城市。這與南昌社會經濟情況是一致的。
2.南昌IT行業(yè)中,企業(yè)服務和電子商務方向就業(yè)機會最多、工資水平較低。說明這兩個方向發(fā)展成熟、運行平穩(wěn)。
3.一線城市在線醫(yī)療、人工智能方向收入較高,但在南昌工資優(yōu)勢不明顯且招聘數量不多。說明南昌這兩個方向發(fā)展較弱。
4.在線教育方向城市間收入差距較小。說明教育是剛性需求,在一般城市在線教育行業(yè)同樣有較好的發(fā)展機會。
猜你喜歡
大灰狼畫報·益智版(2024年3期)2024-12-09 00:00:00
保健醫(yī)苑(2022年1期)2022-08-30 08:39:14
世界科學技術-中醫(yī)藥現代化(2022年3期)2022-08-22 00:32:50
云南化工(2021年8期)2021-12-21 06:37:54
海洋信息技術與應用(2020年1期)2020-06-11 12:43:56
傳媒評論(2019年4期)2019-07-13 05:49:14
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
