機器學習XGBoost算法在醫學領域的應用研究進展
2021-10-23 02:16:24齊巧娜陳霽暉劉昕竹張津源崔夢璇謝藝萌王則遠
分子影像學雜志 2021年5期
齊巧娜,劉 艷,陳霽暉,劉昕竹,楊 銳,張津源,崔夢璇,謝藝萌,王則遠,于 澤,高 飛,張 健
1北京諾道醫學認知科技有限公司,北京 100161;2上海交通大學醫學院附屬新華醫院臨床藥學部,上海200092
隨著醫療信息化的飛速發展,醫療大數據呈爆炸式增長。醫療大數據包含患者在疾病診療過程中產生的全部數據,包括醫生處方、電子病歷、生命體征、醫學成像、檢驗檢查、藥物治療、醫療保險等數據。通過對醫療大數據的深入挖掘,可促進個性化醫療、優化診療手段和提高診療效率[1-3]。人工智能作為計算機科學的一個新的技術分支,它試圖通過獲取、表示和使用知識來不斷改善性能和自我完善,而賦予計算機類似于人類的學習能力[4-5]。機器學習是人工智能的主要實現途徑,并且是人工智能研究中發展最快的領域之一[6]。現代醫療領域已經配備醫療數據的采集及存儲系統,并且能夠在大容量的信息系統中實現集成和分享。應用機器學習對醫療大數據進行挖掘,以總結、獲取新的知識,相比常規的臨床研究和傳統統計學,具有更強的數據處理和知識獲取能力[7-8]。
Boosting也稱為增強學習或提升法,是集成學習技術中重要的框架之一,其應用十分廣泛。2014年陳天奇博士提出XGBoost 算法,XGBoost 是“極端梯度上升”的簡稱,它類似于梯度上升框架,但是兼具線性模型求解器和樹學習算法算法,作為一種新型高效的Boosting算法,在基礎算法上加以優化改進,提高了精度,其關注度和應用價值越來越高[9],已廣泛地運用于醫療保健、金融、教育、制造等領域的數據分析中。在醫藥學領域,XGBoost已應用于疾病診斷以及疾病發生風險、轉歸與預后、合理安全用藥和藥物研發的數據分析,在這些方面XGBoost 均表現出了強大性能和較高精度。本文針對XGBoost 算法的原理、優勢及其在醫藥學領域的應用研究進行綜述。
1 XGBoost算法
1.1 XGBoost算法原理簡介
XGBoost作為一種新型機器學習算法,其算法運行過程分為學習和推理兩部分[9]。其中,學習機的目標是使得損失函數最小化,即在決策樹復雜度盡可能低的情況下要求預測誤差盡可能小。決策樹的構建過程,首先通過貪心法枚舉所有符合條件的樹結構方案,并結合Gain 值和自定義閾值作為節點分裂依據進行分裂或剪枝終止分裂;其次,計算所有方案中葉節點的分數以及決策樹得分,更新決策樹序列;最后,計算各個樣本的預測結果,即每棵決策樹的得分之和,得到樣本屬于各個類別的概率。
而推理機是基于學習機得出的決策樹序列。首先,代入樣本信息依次從決策樹序列的根節點到葉節點進行邏輯判斷,如果不是葉節點,判斷該樣本屬于左/右子節點,反之則計算葉節點分數并輸入下一顆決策樹進行判斷;其次,對所有決策樹給出的預測值進行求和,得到該樣本分類為1的概率并根據閾值函數判斷樣本最終所屬分類(圖1)。
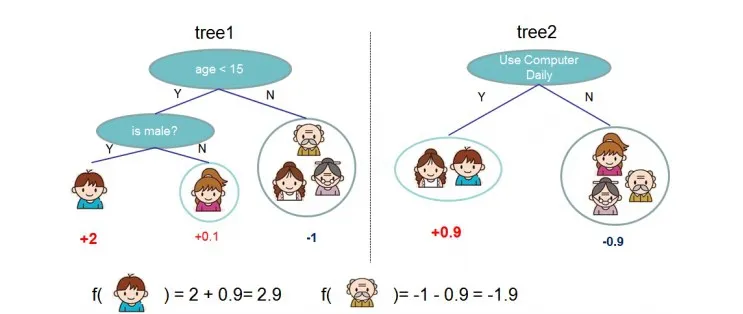
圖1 決策樹分類原理整體模型—對于給定的示例,最后的預測是每棵樹的預測之和[9]Fig.1 Tree ensemble model-The final prediction for a given example is the sum of predictions from each tree[9].
1.2 XGBoost 應用于醫學數據挖掘的優勢
醫學數據的類型、屬性、表達方式是錯綜復雜的。其特點包括:資源龐大,過程復雜,可能存在大量的冗余數據;數據類型多樣,包括文字、影像、信號等;數據稀疏性強,比如病案往往并未包含某種疾病的全部信息或者患者的化驗結果由于各種原因,導致大量數據缺失[10-12]。然而,許多常用的機器學習算法需要完整的數據集(沒有丟失的數據),臨床分析方法通常需要一個輸入程序來“填補”丟失的數據。管理缺失數據最常用的兩種策略是輸入或刪除值,前者可能導致偏差,而后者可能導致偏差和統計能力的損失[13-15]。
而XGBoost 算法在處理這些問題上顯示出獨特的優勢:以并行運算著稱,可快速運行大規模數據;可自動優化分裂節點,擅長處理異常值和缺失值較多的無規則數據;可進行自主學習,模型具有可解釋性和靈活性[9]。
2 XGBoost在醫學領域中的應用研究
2.1 疾病診斷
XGBoost算法常用于影像學診斷。比如,基于癲癇患者MRI的神經生理學特征數據,對癲癇病灶區進行識別[16]。該研究可輔助醫生在術前判斷病灶區域從而準確地進行病灶切除。此外,XGBoost 和貝葉斯優化可用于對肺結節計算機輔助診斷,有學者采集了肺結節(62位肺癌患者及37位良性肺結節患者)患者的CT影像數據,抽取影像特征后采用支持向量機(SVM)和XGBoost算法對特征向量及對應標簽進行預測學習,其中將TPE作為SVM和XGBoost參數的貝葉斯優化方法,得到的曲線下面積(AUC)值分別為0.850和0.896,XGBoost算法的預測效果總體優于SVM算法[17]。
此外,還有一些疾病的診斷也應用了XGBoost算法。如有研究使用機器學習方法構建了尿路感染診斷預測模型,通過提取人口統計資料、生命體征、化驗結果、用藥等數據,驗證和比較了6種機器學習算法用于構建尿路感染診斷預測模型(AUC=0.826~0.904),發現XGBoost 模型是最佳表現算法,顯著提高了尿路感染預測中的特異性和敏感度[18]。另有研究采用電感耦合等離子體場質譜對36例帕金森病患者和42例年齡匹配的對照患者腦脊液樣本進行分析,共量化了28種不同元素,將XGBoost、隨機森林(RF)等不同算法應用于數據集,以識別一組新元素指紋圖譜作為生物標志物進行帕金森病患者的診斷。該研究確定了一個可識別帕金森病患者的元素指紋簇(Se、Fe、As、Ni、Mg、Sr),XGBoost 算法在識別帕金森病中顯示出了很高特異性(78.6%)和敏感度(83.3%),其中Se 和Fe被認為是該簇中標志性最強的元素。經前瞻性驗證,該元素指紋可能成為帕金森病診斷標志物[19]。有學者使用來自cfDNA的染色體臂水平拷貝數變異作為肺癌診斷生物標志物,采用XGBoost算法進行癌癥預測[20]。研究基于Z評分分析手臂級拷貝數變異分布,結果發現3q、8q、12p和7q染色體有擴增的趨勢。22q、3p、5q、16q、10q和15q染色體上經常檢測到缺失。實驗組應用經過訓練的XGBoost分類器,特異性和敏感度最終達到100%。此外,5次交叉驗證驗證了模型的穩定性。結果表明整合4個臂級拷貝數變異和cfDNA濃度到訓練的XGBoost分類器中,可以為檢測肺癌提供一種潛在的方法。
2.2 疾病風險、轉歸及預后的預測
XGBoost算法在疾病風險、轉歸及預后預測方面也有著廣泛的應用。有學者運用美國緬因州電子健康記錄數據庫,采集了823 627位患者的數據,構建了在未來1年內發生原發性高血壓的風險預測模型。該研究在特征選擇和模型構建過程中采用了XGBoost算法,其中在回顧性和前瞻性隊列中的AUC分別為0.917和0.870,計算風險評分將患者分為5個風險級別,并得出各類別下一年內的生存曲線(圖3)[21]。2型糖尿病、脂質紊亂、心血管疾病、精神疾病、臨床使用指標和社會經濟決定因素被認為是原發性高血壓的驅動或相關特征。高風險人群主要包括患有多種慢性病的老年人(>50歲),特別是接受精神障礙藥物治療的人群。同時發現高血壓與社會經濟因素存在關聯。
另有研究首次建立了一種miRNA-疾病關聯的XGBoost模型(EGBMMDA),并證明了模型的可信度與穩定性[22]。運用EGBMMDA模型預測了與miRNAs 潛在相關的結腸腫瘤、淋巴瘤、前列腺腫瘤、乳腺腫瘤和食管腫瘤。結果表明,5 種疾病的預測中,EGBMMDA 的準確率均高于98%。有學者用機器學習XGBoost分析整個外顯子組測序數據,用于識別精神分裂癥高危人群。運用XGBoost模型學習不同基因的突變模式,模型推理得出的前50個基因能夠更好地預測精神分裂癥的發病[23]。
還有機器學習與影像資料的結合。有學者利用冠狀動脈計算機斷層掃描(CCTA)讀數中的16段冠狀動脈狹窄和斑塊信息數據,通過XGBoost構建風險分層預測模型,以優化常規CCTA對于疑似冠心病患者的風險評分[24]。分析表明,與常規CCTA風險評分相比,基于XGBoost的風險分層模型可以最大限度地整合來自CCTA的斑塊信息,進一步對疑似冠心病患者的風險進行評估。有學者基于急性腦卒中患者的MRI影像數據構建XGBoost腦梗死預測模型,將灌注參數作為急性腦卒中梗死預測的重要因素,準確預測急性缺血性腦卒中[25]。
風險預測或生存分析模型的研究也越來越多的應用了機器學習方法。有研究利用機器學習生成風險模型,對心衰患者的意外入院進行預測。納入至少18月的心衰患者數據,使用XGBoost、RF和梯度提升算法建立風險預測模型,并結合多元邏輯回歸(LR)模型得出心衰風險評分。該模型正確預測了84%心衰患者的意外入院情況[26]。有學者構建了基于卷積神經網絡和XGBoost的兩階段補丁的卷積神經網絡模型,能夠預測腦瘤患者的整體生存時間。首先通過訓練卷積神經網絡模型提取的高度抽象的成像特征,然后通過XGBoost和后處理程序進一步細化分割不同的腫瘤及其亞區域(非腫瘤和3個腫瘤區域),實現了在小樣本量情況下對腦瘤患者生存時間的準確預測[27]。有研究采用LR、RF、SVM和XGBoost機器學習技術,對帕金森病患者跌倒臨床結果進行分類預測。研究表明,對比其他方法,SVM和XGBoost技術為帕金森病患者的跌倒提供了更可靠的臨床結果預測,分類準確度70%~80%[28]。此外,也有研究在機器學習框架基礎上,通過XGBoost、RF和梯度提升決策樹3種機器學習算法進行變量選擇,并使用逐步Cox回歸得出一個改進的評分系統,來優化現有的基于臨床數據的ICC分期策略。該研究表明基于機器學習的EHBH-ICC評分系統不但能有效地評價切除后的ICC預后,而且可以應用于臨床實踐[29]。
2.3 合理安全用藥
2.3.1 藥物不良反應預警 在藥物不良反應預警方面,XGBoost不僅可以從真實世界數據中挖掘風險因素之間復雜且高度相關的關系,還可以提供充分的適用于臨床工作者的可解釋性數據結果。
有學者使用了XGBoost算法從電子病歷中挖掘數據,找出重要特征變量,建立模型以預測鎮痛藥對骨關節炎患者的副作用[30]。在骨關節患者的藥物治療中,鎮痛藥的使用可能會使心血管疾病的風險增加20%~50%,而相關的用藥副作用的風險預測模型研究則較少。此外,大多數預測模型沒有提供適用于臨床用藥的可解釋性來解釋其預測背后的推理過程。而XGBoost建立的預測模型擁有優秀的準確性和可解釋性,能夠有效地幫助骨關節炎患者預防藥物副作用。在該研究中,XGBoost模型與SVM、LR、DT等經典的監督機器學習模型進行了預測性能的比較。研究顯示:不論是在ROC曲線還是precision-recall曲線中,XGBoost都擁有最好的性能(AUC分別為0.92和0.89)。XGBoost預測模型的可解釋性主要取決于特征變量重要性的選擇。研究從超過300個危險特征集中,利用XGBoost算法計算出所有特征的重要性排名,選取了前20個重要特征變量納入模型,以支持該預測模型在臨床應用上的可解釋性。例如,危險特征變量排名位居前列的有“做過腿部動脈搭橋手術”,這意味著這些患者術后需使用大量鎮痛藥,極大增加了藥物副作用發生的可能性。
依那西普作為常用的腫瘤壞死因子抑制劑,長期使用可能導致注射部位的感染和疼痛等不良反應。有學者建立了依那西普在幼年特發性關節炎患者中的不良反應預測模型[31]。研究采用5種機器學習算法進行建模并比較預測性能,最終XGBoost生成的模型預測效果最好(敏感度75%、特異性66.67%、準確性72.22%、AUC 79.17%)。臨床醫生和藥師可以使用這個簡單而準確的模型來早期預測幼年特發性關節炎患者對依那西普的反應,可以有效避免藥物不良反應的發生。
有學者采集了2213名接受國藥、阿斯利康、輝瑞生物科技公司等疫苗接種的受試者信息,使用機器學習技術建立模型預測疫苗副作用的嚴重程度[32]。其中,基于疫苗類型、人口統計學和副作用相關數據,XGBoost給出了很高的準確性(0.79)和科恩Kappa值(0.70)。在這項研究中,XGBoost可根據輸入數據預測副作用的嚴重程度,從而提前預判出可能會發生嚴重不良反應的受試者,給予該類人群特殊關注。
2.3.2 個體化用藥劑量預測與傳統PKPD模型相比,XGBoost在個體化用藥劑量預測方面表現出較好的性能,為藥物計算的發展提供了更多可能。
有學者開發了一種基于XGBoost算法的機器學習模型,用來預測葉黃素酯、玉米黃質、黑醋栗提取物、菊花和枸杞的藥物組合對眼疲勞患者的最佳劑量[33]。研究者從303名受試者中收集了504項特征,包括人口統計學、人體測量學、眼睛相關指標、血液生物標志物和飲食習慣等。XGBoost 算法使用基線的所有特征來預測干預后45 d的視覺健康評分,以顯示眼睛疲勞的改善,然后根據預測的視覺健康評分選擇組合的最佳劑量。經過特征選擇和參數優化后,Pearson相關系數分別為0.649、0.638和0.685。在去除了侵入性血液測試和昂貴的光學相干斷層掃描收集的特征后,模型仍然保持良好的性能。在測試和驗證集中的58名受試者中,39名應采取最高劑量作為最佳選擇,17名可能采取較低劑量,而2名不能從組合中受益。結果表明該模型可以成功預測組合的最佳劑量,為眼疲勞患者提供個性化的營養解決方案。
有學者基于高維數據、建議變量工程和機器學習方法,開發了一種模型,來預測萬古霉素的最佳給藥劑量[34]。研究采用極端梯度上升算法對自變量和交互變量進行了初步的檢查,然后基于導出的變量建立萬古霉素劑量預測模型。基于驗證隊列中對模型性能的評估,該算法占萬古霉素劑量變化的67.5%。亞組分析顯示,中、高體質量(理想預測百分比分別為72.7%和73.7%)、血清肌酐中、低水平(理想預測百分比分別為77.8%和73.1%)的患者表現更好。
2.3.3 治療藥物濃度預測與傳統藥代動力學模型相比,機器學習模型在模型擬合、預測精度上也體現了較好的效果。
有學者采用機器學習建立預測萬古霉素谷濃度模型,研究納入407名兒科患者(年齡<18歲),整個數據集(n=407)按照8:2的比例分為訓練組(n=325)和測試組(n=82)。萬古霉素谷濃度被視為目標變量,并使用8種不同的算法進行預測性能比較。最終選擇了5種高R2(R2=0.657、0.514、0.468、0.425、0.450)的算法(XGBoost、GBRT、Bagging、Extra Tree、Decision Tree),并進一步集成,建立最優模型(R2=0.614、MAE=3.32、MSE=24.39、RMSE=4.94、預測精度=51.22%)。與傳統藥代動力學模型(R2=0.3)相比,機器學習模型在模型擬合方面效果更好,預測精度更高[35]。
有學者基于XGBoost、logVd、人工神經網絡建立了包含典型人體藥代動力學參數的Rb預測模型[36],為289種化合物編制了實驗Rb值,通過擴展適用范圍提供可靠的預測。研究利用血漿藥物濃度計算出的人體藥代動力學參數(包括分布容積、清除率、平均停留時間和血漿蛋白結合率),以及2702種分子描述符,構建定量結構-藥代動力學關系的Rb模型。在評估的藥代動力學參數中,log Vd與Rb 的相關性最好(相關系數為0.47)。使用6個分子描述符和logVd進行優化后,該模型的相關系數為0.64,均方根誤差為0.205,優于先前報道的其他Rb 預測模型。
有研究基于肺炎克雷伯菌臨床分離株的全基因組序列數據搭建了XGBoost的機器學習模型,該模型可準確預測20種抗生素的最低抑菌濃度(MIC)[37]。研究提供了一種在未知基因序列的情況下預測分離菌株MIC的方法,并為構建其他致病細菌的MIC預測模型提供了框架。當患者被診斷出患有感染時,根據該模型的MIC預測可合理快速地選擇治療方案。有學者基于人口統計、社會因素、健康史等建立機器學習模型,評估大數據在預測OTP結果方面的潛力,模型收集分析樣本超過3萬人次,通過比較LR、RF和XGBoost等方法,最終結果顯示XGBoost構建的模型結果最佳,能較準確識別阿片類藥物治療方案有效的患者[38]。還有學者在數據集NCI-ALMANAC 基礎上,利用RF 和XGBoost兩種機器學習技術建模,通過預測大型復合庫中所有可能組合中哪些是協調的工具,擴大相應搜索,以較高地準確性預測未知藥物組合對癌癥治療的協同作用[39]。該研究納入了5000多對藥物組合、60個細胞系、4種模型、5種化學特征等進行預測分析,研究顯示XGBoost模型比RF有更好的性能。
2.4 藥物研發
在藥物研發方面,有學者采用XGBoost算法構建了一個集成用于定量結構活動關系模型各種工作流的計算機平臺,快速篩選對人類ether-à-go-go相關基因(hERG)的藥物封鎖,用于藥物合成和開發過程中藥物對心臟毒性預測的研究[40]。該預測模型可定性和定量預測hERG的IC50值,在評估hERG通道藥物阻斷的大型數據集時,具有較高的靈敏度和預測能力。有學者運用XGBoost對化合物生物活性進行預測,可用于新藥開發中的藥物評估[41]。基于化合物分子結構的定量描述,XGBoost在預測生物活性方面優于其他機器學習算法。除了可以在高度不平衡的數據集中檢測少數群體活動的能力之外,它在高多樣性和低多樣性數據集中都表現出顯著的性能。有學者開發了一種基于LINCSL1000擾動信號的自編碼—極端梯度上升(算法SAEXGBoost)細胞活性預測模型。研究通過細胞活性與藥物基因組學之間的關聯,結合隨機游走—極端梯度上升算法預測藥物誘導下的細胞活性,建立藥物敏感性預測模型。與其他方法相比,該模型取得了良好效果,有助于發現新型有效的抗癌藥物,為精準醫療提供幫助[42]。
除此之外,有學者提出了一種命名為基本蛋白質預測的基于XGboost的框架,用于識別基本蛋白質,在藥物設計研究和生物學中可發揮重要作用[43]。本框架基于XGBoost算法,其中包括一種名為替代擴充縮小的模型融合方法,此法可獲得更有效的預測模型。與其他方法比較,該框架在預測必需蛋白質的準確性方面具有很大的優勢。此外,有學者利用特征提取、特征選擇和機器學習算法開發了蛋白質線粒體定位預測模型,基于SubMito-XGBoost算法的三步法預測模型,在交叉驗證數據集中預測ACC分別為97.65%和98.94%,又利用獨立數據集評價SubMito-XGBoost 模型的預測能力,ACC為94.83%,顯著高于其他算法,精準預測蛋白質線粒體定位,為探索人類疾病分子水平新藥的發病機制、診斷和開發提供了理論基礎[44]。
2.5 其他臨床輔助決策支持
臨床輔助決策支持系統(CDSS)的開發和使用在過去的幾年里取得了巨大的進步。CDSS是一個基于人機交互的醫療信息技術應用系統,旨在為醫生和其他衛生從業人員提供臨床決策支持,通過數據、模型等輔助完成臨床決策。CDSS能夠通過降低漏診率、誤診率以及規范化診療行為與過程達到提高醫療衛生機構醫療服務質量的目的[45]。有學者介紹了構建醫療預測的決策支持系統的基本內容。其中包含臨床DSS 的重要流程、不同參數及其預測能力,比較了各種運算方法應用于DSS的適用性[46]。此外評估了GBM與XGBoost 算法分別及集成地應用于臨床預測模型的性能,不同參數下的GBM+XGBoost集成模型能夠達到最高的精確度。
CDSS在臨床上也取得了廣泛的應用。有學者提出了一種CDSS心臟病預測模型[47]。該模型利用2個公開可用的數據集(Statlog和Cleveland)建立模型,由基于密度的噪聲應用空間聚類來檢測和消除離群點,混合合成少數過采樣技術-近鄰來平衡訓練數據分布和基于XGBoost模型的機器算法來預測心臟病,并與其他模型以及先前的研究結果進行比較。結果表明,該模型數據集上為95.90%,準確率優于其他模型。
此外,有學者首次在EMR 的基礎上,采用基于XGBoost的機器學習方法建立了幼年特發性關節炎患者對甲氨蝶呤用藥反應的2個早期預測模型。研究納入了治療的362例幼年特發性關節炎患者的甲氨蝶呤單治療資料。采用DAS44/ESR-3簡化標準對甲氨蝶呤響應進行了評價。通過比較各種運算方法應用于DSS的適用性,證實了XGBoost可有效地避免過擬合,預測甲氨蝶呤的療效優于其他模型,醫生在治療前后制定或調整治療方案提供了有力的決策支持[48]。
膿毒癥是住院死亡的一個重要原因,特別是ICU患者。對于早期預測敗血癥,及時和適當的治療可以提高生存結果。有研究利用XGboost開發一種機器學習方法來預測MIMIC-III膿毒癥-3患者的30 d死亡率,研究共納入膿毒癥-3患者4559例,其中死亡889例,30 d內存活3670例。通過對接收機工作特性曲線和決策曲線分析的AUCs對logistic回歸模型、SAPS-II評分預測模型和XGBoost 算法模型的性能進行測試和比較。最后,利用列線圖和臨床影響曲線對模型進行了驗證。3種模型的AUCs和決策曲線分析結果顯示XGboost模型表現最好[49]。風險列線圖和臨床影響曲線驗證了XGboost模型具有顯著的預測價值,可以幫助臨床醫生對膿毒癥3患者進行量身定做的精確管理和治療。
3 結語
本文介紹了XGBoost算法在醫藥領域中的應用,在所述研究方向中,XGBoost算法展現了較強的性能:可為缺失值或者指定值指定分支的默認方向,大大提升算法的效率;在處理大型數據集時,XGBoost算法能夠模擬非線性效應,具有較高的效率和準確性。但是XGBoost算法也存在一定的限制因素,例如XGBoost算法更適合處理中低維、結構化數據,數據樣本量較大時,比較耗時。
XGBoost算法相較某些機器學習算法調參簡單,但想要獲取更好的結果,還需要提升藥學與算法、信息化等多學科的結合能力。這對醫務人員來說,無疑是一個很大挑戰,希望本文能夠給醫藥領域的研究人員帶來更多的獲益與思考。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
天津外國語大學學報(2021年3期)2021-08-13 08:32:18
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
汽車工程學報(2017年2期)2017-07-05 08:13:02
光學精密工程(2016年6期)2016-11-07 09:07:19