基于無監(jiān)督學習算法的系統(tǒng)異常檢測算法平臺實現(xiàn)
2021-10-25 03:13:16張國軍劉子莘呂品陳明霍超
科技信息·學術版 2021年19期
張國軍 劉子莘 呂品 陳明 霍超


摘要:一方面,隨著服務器數(shù)量和業(yè)務量的增加,系統(tǒng)的運行情況變的越來越復雜,不易被發(fā)現(xiàn)的潛在風險越來越多,傳統(tǒng)的通過設置某些指標的閾值對系統(tǒng)進行異常檢測的方式已慢慢顯示出弊端。另一方面,服務器每天會產(chǎn)生大量的系統(tǒng)日志和各項指標,如何更好的分析和利用這些日志和指標成為了一個值得思考的問題。基于以上兩個問題,通過無監(jiān)督學習算法對系統(tǒng)日志和各項指標進行分析,再將結果直觀的展示給系統(tǒng)管理員提醒管理員系統(tǒng)存在的潛在風險,是一件很有意義的事情。
本文闡述了基于無監(jiān)督學習算法搭建異常檢測算法平臺進行系統(tǒng)異常檢測的設計與實現(xiàn)流程。介紹了項目組所使用的相關技術以及實現(xiàn)過程中使用到的解決方案。相關技術包括ELK平臺、pyod算法庫、詞向量模型BERT。在設計階段,對算法建模及異常檢測和日志數(shù)據(jù)傳輸流程和架構進行了設計。在實現(xiàn)階段,使用pyod算法庫對FeatureBagging和IForest算法分別進行了建模和使用,通過檢測結果進行對比最終選定與場景契合度較高的算法。
一、相關技術
ELK平臺:ELK平臺由Elasticsearch(開源分布式搜索引擎)、Logstash(日志收集、過濾工具)、Kibana(日志圖形化工具)、kafka(大吞吐日志消息中間件)、beat(生產(chǎn)端日志發(fā)送工具)組成。用于日志收集、分析、展示。
異常檢測算法庫pyod:pyod提供了約20種異常檢測算法,可以找到與“主要數(shù)據(jù)分布”不同的異常值。
詞向量模型BERT:BERT是一種基于transformer的雙向編碼語言模型,用于將文本轉化為向量,是目前NLP的主流模型。
FeatureBagging算法:此算法屬于集成方法的一種,基本思想與bagging相似。集成的主要步驟為選擇基檢測器和分類標準化、組合方法。
IForest(孤獨森林)算法:此算法屬于非參數(shù)和無監(jiān)督的算法,是機器學習中專門針對異常檢測設計的算法之一,算法特點為時間效率高、能有效處理高維數(shù)據(jù)和海量數(shù)據(jù)。
二、系統(tǒng)異常檢測算法平臺設計
基于無監(jiān)督學習算法的系統(tǒng)異常檢測平臺主要是通過將日志及系統(tǒng)指標收集起來,通過算法進行建模,再對新產(chǎn)生的數(shù)據(jù)進行分析。基于此目的,在本階段對日志及系統(tǒng)指標收集流程和算法建模及異常檢測流程分別進行了設計。
1.日志及系統(tǒng)指標收集流程
通過ELK日志平臺獲取系統(tǒng)日志及指標數(shù)據(jù)。ELK平臺的架構為第一步用beat從服務器實時獲取數(shù)據(jù),其中filebeat用于收集日志數(shù)據(jù),metricbeat用于收集指標類數(shù)據(jù)。第二步層采用Kafka對日志收集進行緩沖,并按日志內(nèi)容進行主題分類,以便后續(xù)的分類管理與檢索。第三步Logstash對日志數(shù)據(jù)進行過濾解析,包括時間的校對、日志字段的分詞、字段類型的轉換和導出索引的設定。第四步Logstash將日志發(fā)送到ElasticSearch(ES),在ES中建立索引數(shù)據(jù),進行索引模板和生命周期的管理。最終使用Kibana組件對日志數(shù)據(jù)進行可視化展現(xiàn)。由于kibana中展示的數(shù)據(jù)是為了讓人進行閱讀和使用,故這些數(shù)據(jù)的機器可讀性較差。為了提高機器的可讀性,在ELK的第三步搭建專屬的logstash通道對kafka中的數(shù)據(jù)進行處理,使其成為機器易讀的數(shù)據(jù)格式,并在數(shù)據(jù)處理后將其發(fā)送到異常檢測算法平臺。日志數(shù)據(jù)傳輸流程圖,如圖1所示。
2.算法建模及異常檢測流程
在本部分使用pyod庫搭建異常檢測算法平臺。當一定量的系統(tǒng)日志及指標輸入到本平臺后對其進行數(shù)據(jù)降維、文本特征向量處理等數(shù)據(jù)預處理方法后進行算法建模,訓練出異常檢測模型,后續(xù)通過異常檢測模型判斷后續(xù)輸入的數(shù)據(jù)是否為異常值。由于日志分析是多維向量,故在算法選擇時初步選定了FeatureBagging和IForest兩個多維向量檢測算法。日志數(shù)據(jù)傳輸流程圖,如圖2所示。
三、系統(tǒng)異常檢測算法實現(xiàn)
在本部分以TongGTP的異常檢測為案例闡述實現(xiàn)過程。TongGTP(以下簡稱gtp)是一個文件傳輸中間件,可以實現(xiàn)不同系統(tǒng)間的文件傳輸功能,在數(shù)據(jù)交換平臺和批量場景中使用廣泛,由于每個時間點發(fā)送的數(shù)據(jù)量沒有特定規(guī)律,所以基于閾值的異常檢測方法失效。gtp的數(shù)據(jù)指標分為四類gtp_send_succ、gtp_send_fail、gtp_recv_succ、gtp_recv_fail。beat每小時會在生產(chǎn)端采集一次數(shù)據(jù)并發(fā)送、存儲在Elasticsearch,之后異常檢測平臺從Elasticsearch獲取數(shù)據(jù)。gtp異常檢測場景要通過四類指標的值分析出哪個時間點的gtp發(fā)送或接收存在問題。例如,通常每天9:00的gtp_send_succ為0,但某一天9:00的gtp_send_succ為1,則應該判斷出gtp可能有問題,并告知管理員此風險。具體實現(xiàn)步驟介紹如下,
1.數(shù)據(jù)獲取。由于gtp_send_succ、gtp_send_fail、gtp_recv_succ、gtp_recv_fail四個指標無法直接獲得并且gtp的默認日志中也沒有,所以先將這些指標寫入日志文件gtp_filebeat.log再通過filebeat進行采集,創(chuàng)建gtplog主題匯入ELK平臺,經(jīng)過logstash格式化,Elasticsearch持久化后,送入異常檢測算法平臺。
2.數(shù)據(jù)預處理。該場景涉及到的向量包括timestamp、numtype、gtpnum。其中,timestamp的格式為Month day,year @ hour:minute:second,此格式數(shù)據(jù)機器無法識別,通過strptime將其轉化為1970年到當前的秒數(shù)。numtype為簡單文本,通過數(shù)據(jù)字典將其轉化為[0,1,2,3]的特征向量。
3.數(shù)據(jù)建模。分別使用FeatureBagging和IForest算法對數(shù)據(jù)進行訓練,得到模型。
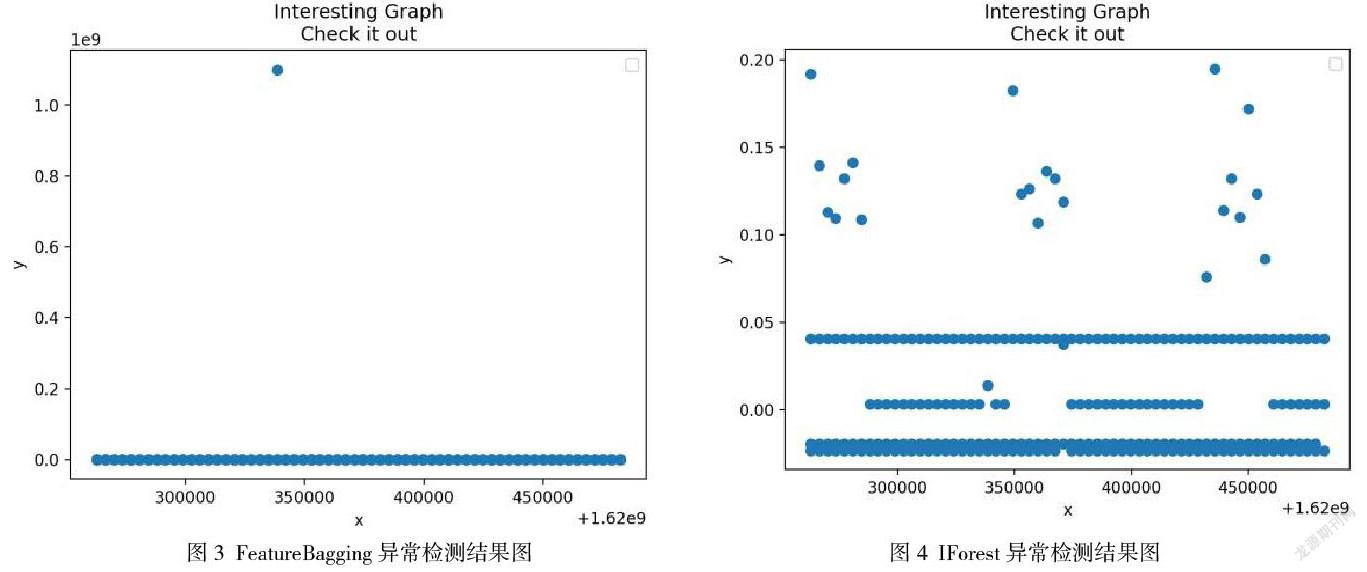
4.異常檢測。將測試數(shù)據(jù)輸入不同的模型得到異常檢測結果。FeatureBagging的檢測結果如圖3所示。IForest的檢測結果如圖4所示。根據(jù)結果顯示,F(xiàn)eatureBagging的結果較集中,存在突出的異常點且異常值較大,IForest的結果較分散,異常值均比較低。將FeatureBagging的異常點信息提取出來并聯(lián)系系統(tǒng)管理員對當時的情況進行分析,發(fā)現(xiàn)此點確實為異常點。根據(jù)分析,確定FeatureBagging算法較適用于gtp異常檢測場景。
5.結果分析。通過對異常檢測結果的分析對于gtp異常檢測場景最終選定了FeatureBagging算法來訓練其模型。通過該異常檢測算法平臺可以檢測到無法觸發(fā)閾值告警的gtp異常點。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
工業(yè)設計(2022年8期)2022-09-09 07:43:20
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
軍民兩用技術與產(chǎn)品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
家庭影院技術(2017年9期)2017-09-26 03:41:45
