基于SVM的糧食霉變預測分類方法研究
2021-11-12 00:55:46苑江浩趙會義
中國糧油學報 2021年9期
苑江浩 常 青 趙會義 唐 芳
(國家糧食和物資儲備局科學研究院,北京 100037)
糧食霉變在糧食儲藏過程中極易發生,是影響糧食品質的一項重要因素,據統計,我國因糧食霉變造成的產后損失占總產量的4.2%[1]。為降低糧食損失,國內外研究者從糧食霉菌生長規律、糧食霉變快速檢測、儲糧安全和糧情預測等方向開展研究。Genkawa等[2]研究了不同水分的稻谷儲藏過程中霉菌數量的變化;唐芳等[3-6]從實驗室和實倉的角度開展了儲糧危害真菌生長及演替規律的研究;劉慧等[7]以安全水分稻谷為研究對象,開展在不同儲藏溫、濕度中的霉菌生長規律研究,并建立生長動力學模型;蔡靜平等[8-11]開展了不同糧食品種在儲藏過程中霉菌活動特性差異性研究。亦有研究者通過電子鼻技術[12, 13]、機器視覺技術[14]、高光譜技術[15, 16]等開展了糧食霉變無損快速檢測的研究。同時,很多研究者[17-20]從儲糧安全和糧情預測角度出發,建立儲糧安全風險預警模型,結合糧堆溫度、濕度、水分和CO2等因素,用于分析檢測糧食霉變的可能性,以保證儲糧安全。而針對霉變預測的方法較少,鄧玉睿等[21, 22]研究了基于樸素貝葉斯和BP神經網絡進行霉變預測技術的研究,但其僅針對稻谷進行了初步探索,且建模所需的訓練樣本集較大,面臨小樣本時,準確率較低。
支持向量機[23, 24](Support Vector Machine, SVM)算法簡單,且魯棒性較好,可有效解決非線性分類等問題,其主要應用于分類預測研究,特別是在小樣本分類預測領域應用效果很好,目前該算法已在圖像識別[25, 26]、文本分類[27, 28]等領域得到廣泛應用。該算法在糧食領域內亦得到廣泛應用,鄭沫利等[29]通過SVM對數據建模,以對糧食在儲藏過程中的損耗智能評估;段珊珊等[30]利用SVM建立糧堆表層平均溫度預測模型,通過氣象8因素預測糧堆表層平均溫度;呂俊[31]利用海量的糧食通風控制數據訓練SVM模型,以用于糧食通風控制的預測。本文將該算法應用到糧食霉變預測分類中,克服現有技術存在的主要問題,為糧食霉變預測提供新思路。
1 材料與方法
1.1 實驗設備
HPS-250生化培養箱,PL3002-IC電子分析天平,HG-9246A型電熱恒溫鼓風干燥箱,SMART顯微鏡,DJSFM-1糧食水分測試粉碎磨。
1.2 實驗樣品數據的獲取
將不同含水量的稻谷、小麥樣品密封分別置于不同儲藏溫度(10、15、20、25、30、35 ℃)的生化培養箱模擬儲藏180 d,每10 d取樣檢測水分和真菌孢子數。其中水分的檢測方法參照GB 5009.3—2016《食品安全國家標準 食品中水分的測定》[32]中直接干燥法檢測,真菌孢子數參照LS/T 6132—2018《糧油檢測儲糧真菌的檢測 孢子計數法》[33]計算。
2 模型建立與分析
2.1 支持向量機理論
設訓練樣本集D={(x1,y1),(x2,y2),…,(xm,ym)},yi∈{-1,1},SVM最基本的思想是基于訓練集D找到一個劃分的超平面,從而將不同類別樣本分開。即存在如下劃分超平面:
ωTx+b=0
(1)
式中:ω=(ω1;ω2;…;ωd)為法向量,b為偏置項。此時分類的最大間隔為:
(2)
為更好地解決這個凸二次規劃問題,引入拉格朗日乘子法(αi≥0)得到其“對偶問題”。
(3)
在實際的應用中,會存在大量線性不可分問題,原始樣本空間中并不存在一個合理的超平面,以保證樣本的正確劃分。為解決該問題,引入核函數概念,以代替對偶問題和非線性映射后的點積運算,常見的核函數[14]有線性核、多項式核、高斯核、拉普拉斯核、Sigmoid核。同時為了克服無法完成嚴格分類、過擬合等問題,引入懲罰因子C和松弛變量g兩個參數。
2.2 SVM建模與參數優化
本研究使用的SVM模型總體框架如圖1所示。數據預處理:將原始數據集參照LS/T 6132—2018中的附錄C儲糧安全評價參考表[33]進行數據處理,詳見表1。將“Ⅲ級-危害”確定為是否發生霉變的標準(以對糧食造成危害為標準),劃分數據類別。
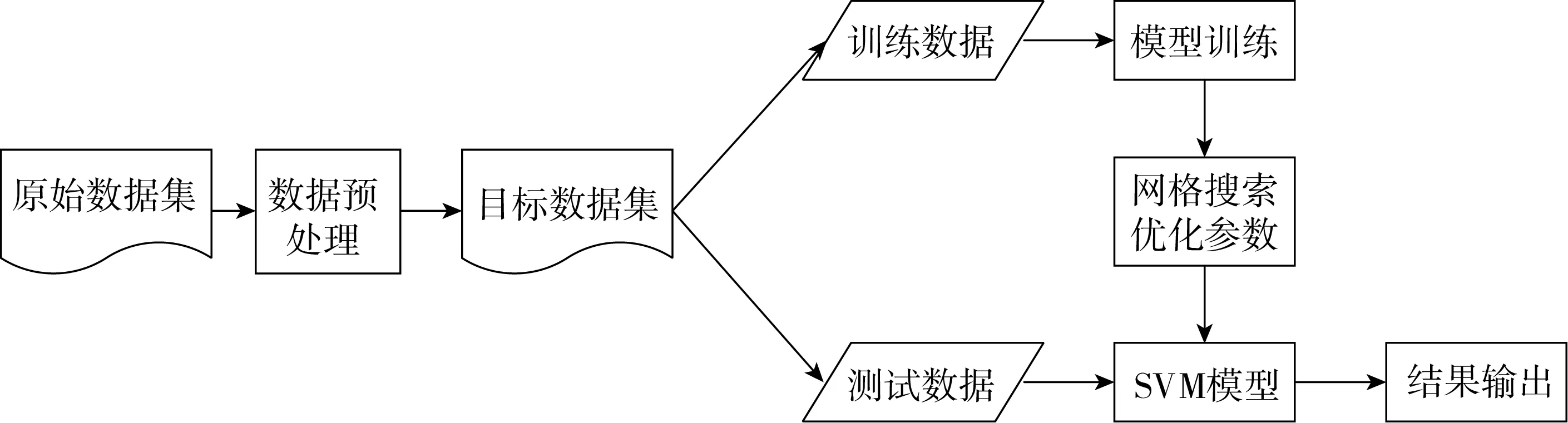
圖1 SVM模型總體框架圖

表1 儲糧安全評價參考表
參數優化:在SVM的建模過程中,懲罰因子C和松弛變量g兩個參數是影響模型精準度的主要因素[34],為了提升模型的準確度,保證參數最優化,本文采用網格搜索(Grid Search)方法優化參數,尋求最適應模型。其基本原理是通過遍歷網格內所有的點進行取值,得到一組令訓練集分類準確率最高的C和g的值作為最優參數。
2.3 實驗設計與分析
實驗針對稻谷和小麥兩種糧食品種分別采用經網格搜索尋優參數后的SVM模型處理,若糧食已發生霉變,以“1”標識,若未發生霉變,以“-1”標識。實驗結果將預測值與實際值進行求差運算后取絕對值,如值為0,則表示預測值與實際值相符,預測分類正確;如值為2,則表示預測值與實際值不符,預測分類錯誤。實驗結果評定標準如表2所示。

表2 實驗結果評定標準表
2.3.1 稻谷霉變預測分類
稻谷樣品數據共計2 592組,實驗隨機選取2 492組數據作為訓練數據,100組數據作為測試數據。經多次實驗驗證得到,SVM建模后預測分類準確率可達98%,平均準確率在96%以上。預測分類結果如圖2所示,此時SVM選用的核函數為高斯核RBF網絡,懲罰因子C=45。該模型預測分類準確率與文獻[22]中基于BP神經網絡模型的預測準確率基本一致。
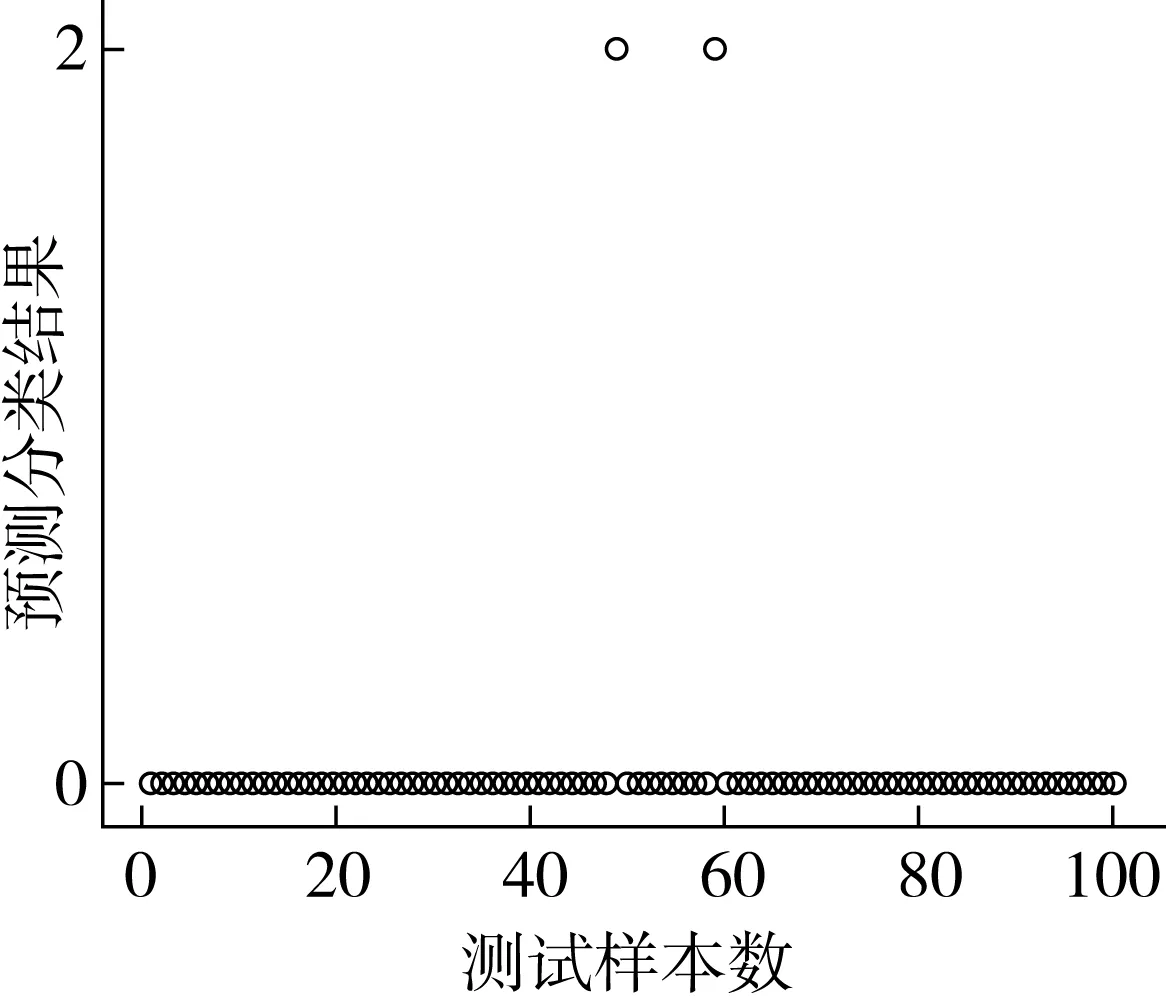
圖2 基于SVM模型的稻谷霉變預測分類結果圖
2.3.2 小麥霉變預測分類
小麥樣品數據共計876條,實驗選取776條數據作為訓練數據,100條數據作為測試數據。經多次實驗驗證得到,SVM建模后預測分類準確率可達94%,平均準確率在92%以上。預測分類結果如圖3所示,此時SVM選用的核函數為高斯核RBF網絡,懲罰因子C=60。
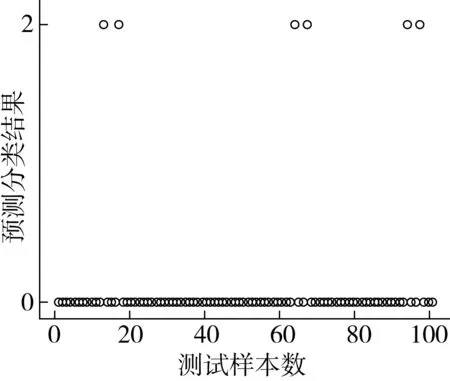
圖3 基于SVM模型的小麥霉變預測分類結果圖
本研究通過復現文獻[22]的實驗程序,并應用于小麥樣品的預測分類中,依然選取776條數據作為訓練數據,100條數據作為測試數據。其預測結果如圖4所示。經過多次實驗驗證,預測準確率為82%~91%,其穩定性較差,平均準確率僅為86%。
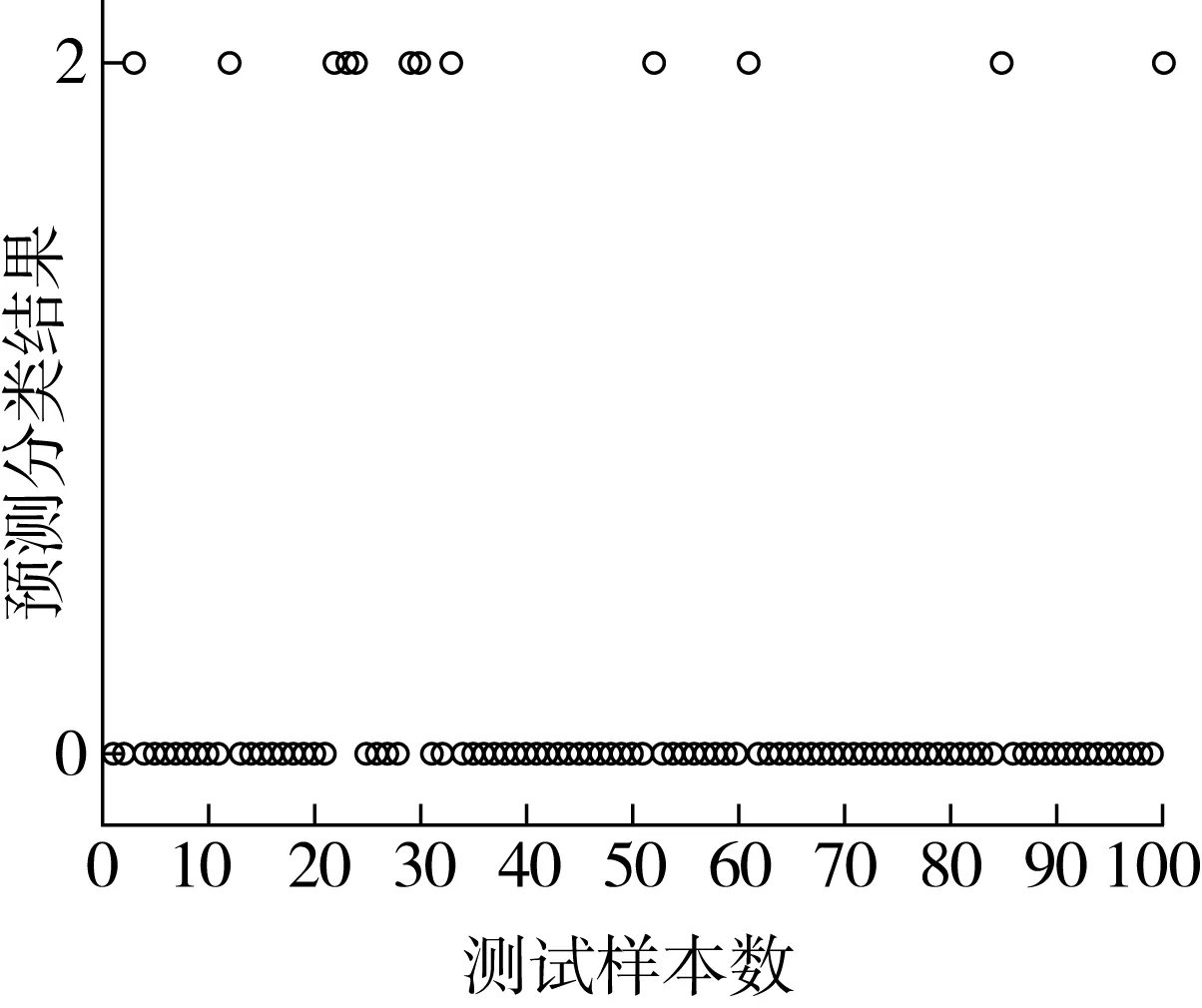
圖4 基于BP神經網絡的小麥霉變預測結果圖
2.3.1和2.3.2證明SVM模型可以有效預測分類糧食是否發生霉變。并且在小麥的預測上更具有優勢,推斷可能原因是小麥的訓練樣本集較小,SVM發揮其自身小樣本的優越性。因此,本研究為驗證SVM針對于小樣本的預測分類能力,通過不同規模的訓練樣本集進行SVM小樣本預測分類實驗。
2.3.3 SVM小樣本預測分類
實驗數據集與2.3.1和2.3.2保持一致,分別采取SVM模型與文獻[22]中的BP神經網絡模型兩種模型進行,隨機選取400、200組數據作為訓練數據,剩余數據作為測試數據開展實驗。
2.3.3.1 稻谷
采用SVM模型進行實驗,預測分類結果如圖5所示。實驗結果表明,當訓練數據為400組時,預測分類平均準確率約為91.97%;當訓練數據為200組時,預測分類平均準確率約為90.76%。

圖5 基于SVM的稻谷小樣本預測分類結果圖
采用BP神經網絡模型進行實驗,預測分類結果如圖6所示。實驗結果表明,當訓練數據為400組時,預測分類平均準確率約為86.34%,當訓練數據為200組時,預測分類平均準確率約為71.47%。
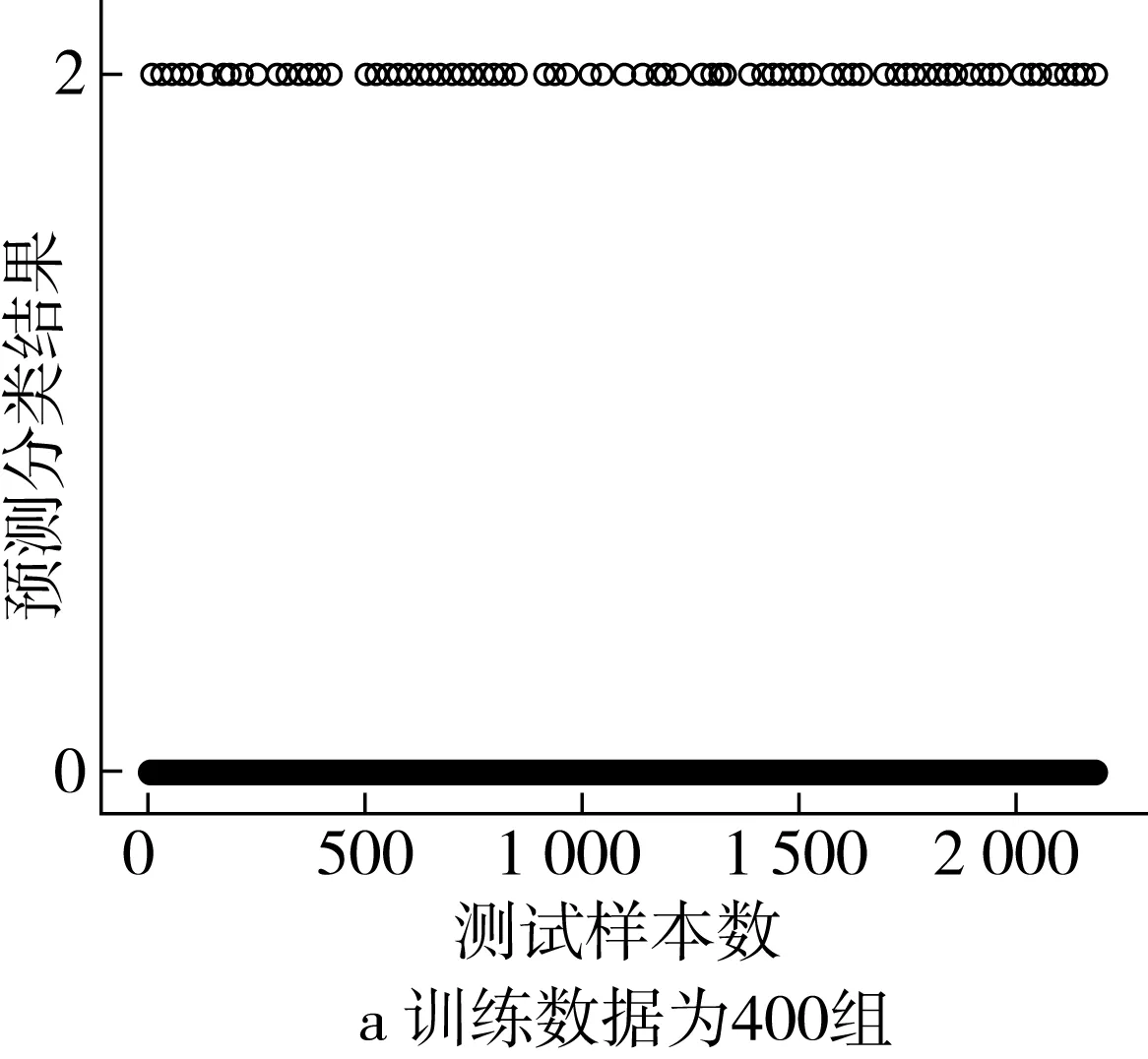
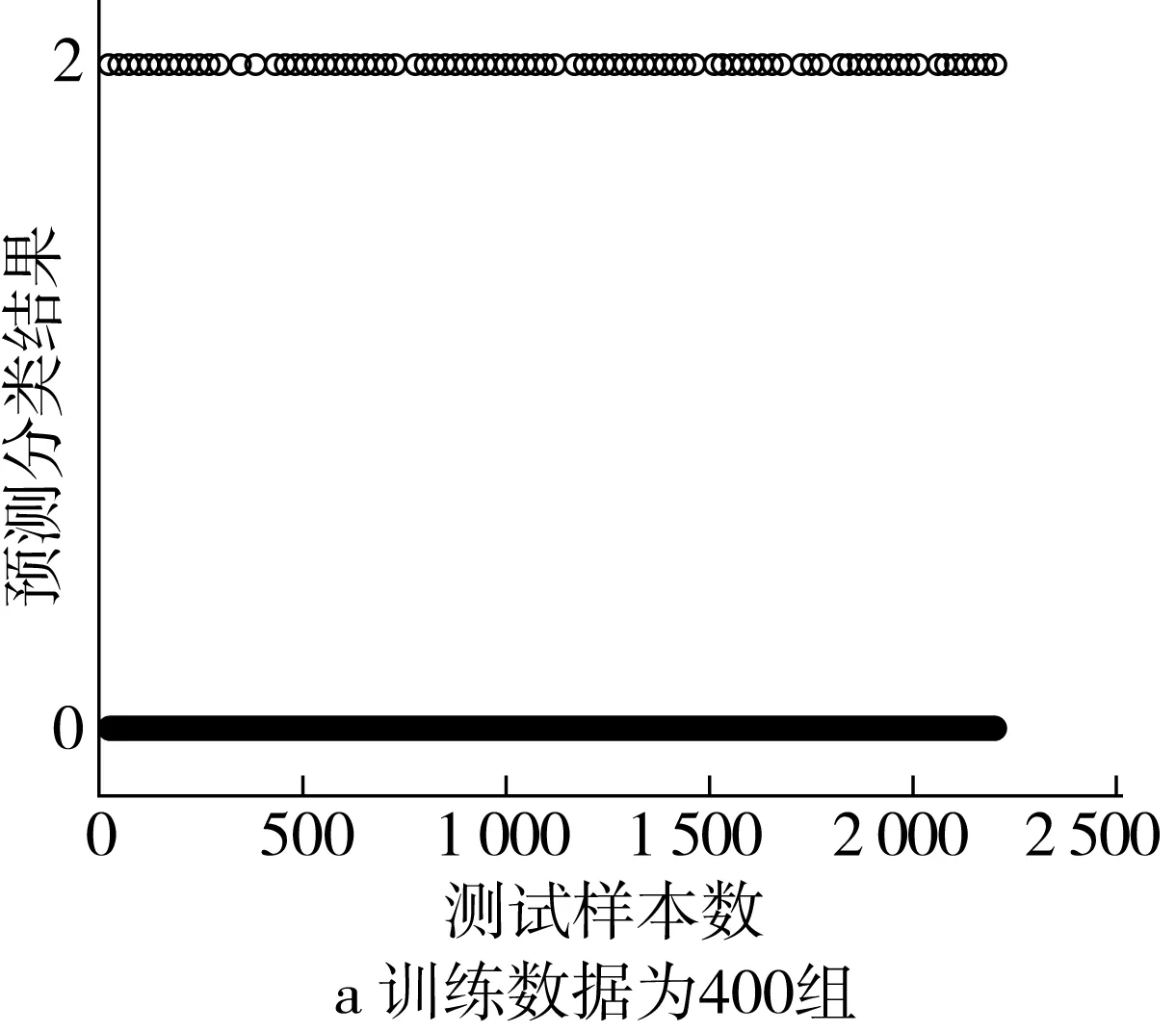
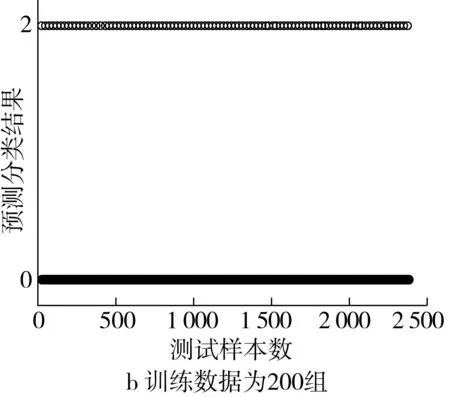
圖6 基于BP神經網絡的稻谷小樣本預測分類結果圖
2.3.3.2 小麥
采用SVM模型進行實驗,預測結果如圖7所示。實驗結果表明,當訓練數據為400組時,預測分類平均準確率約為88.1%,當訓練數據為200組時,預測分類平均準確率約為86.55%。

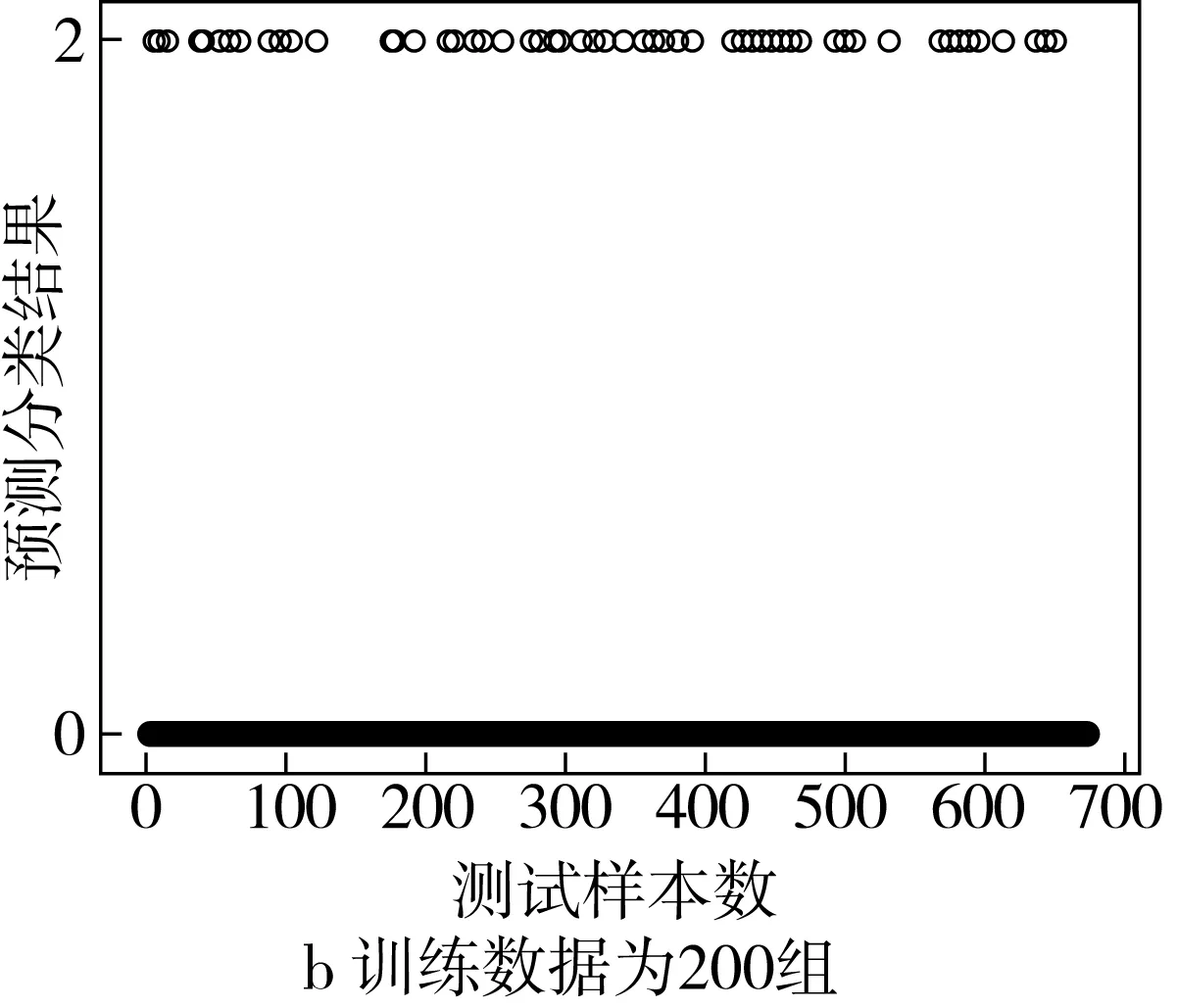
圖7 基于SVM的小麥小樣本預測分類結果圖
采用BP神經網絡模型進行實驗,預測結果如圖8所示。實驗結果表明,當訓練數據為400組時,預測分類平均準確率約為84.45%,當訓練數據為200組時,預測分類平均準確率約為70.76%。
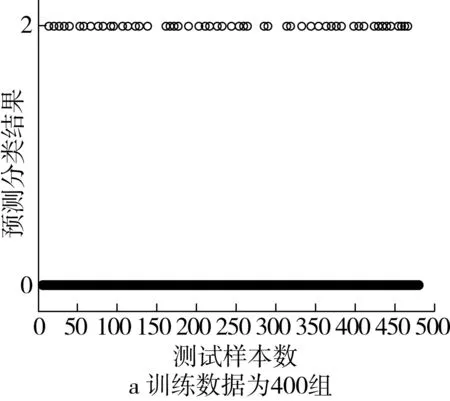
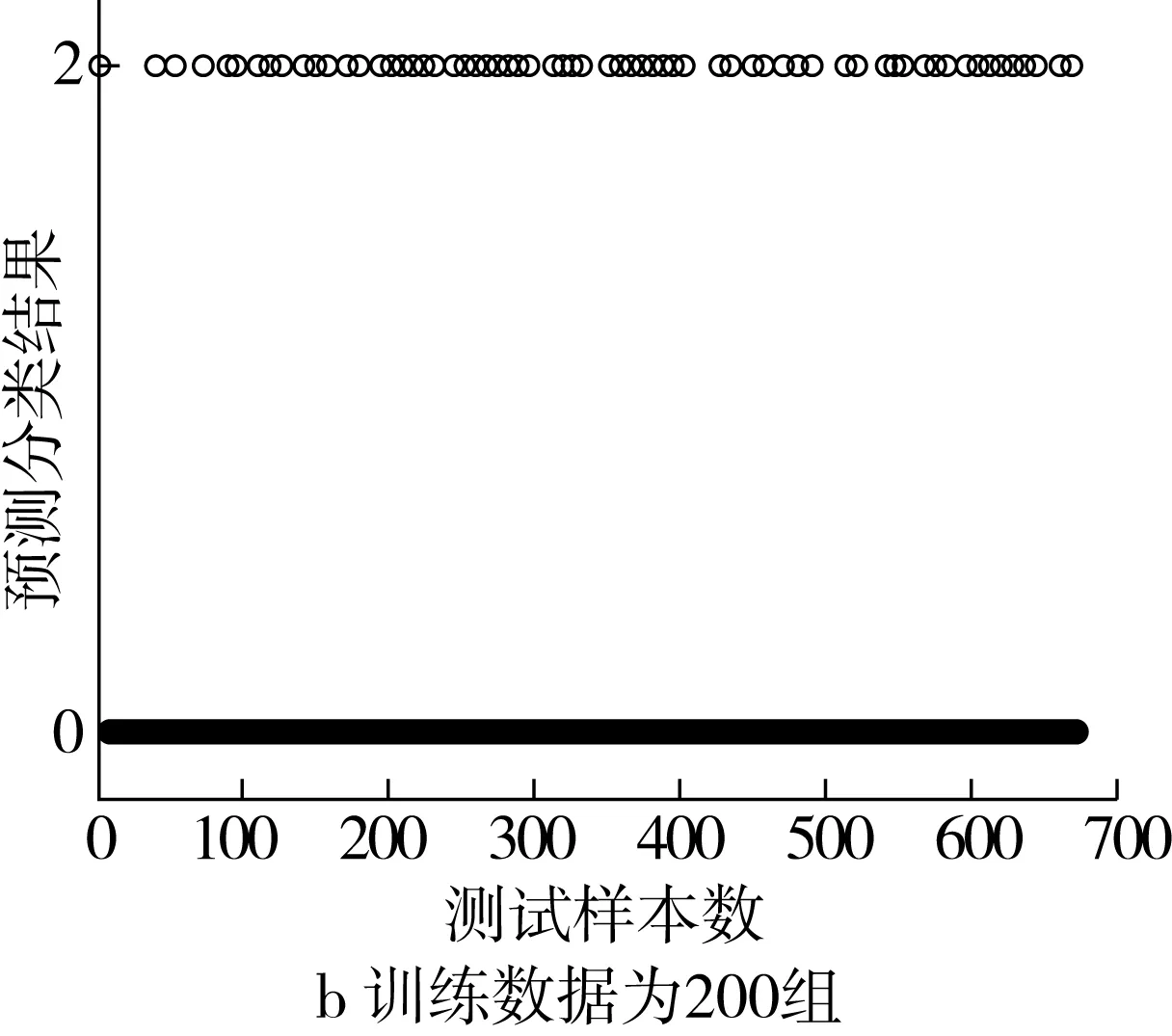
圖8 基于BP神經網絡的小麥小樣本預測分類結果圖
由實驗數據可知,當樣本訓練集較大時,SVM模型和BP神經網絡模型準確率相當,但當降低樣本訓練集后,SVM模型表現出較為突出的優勢,尤其是當樣本訓練集僅為200組數據時,準確率相差較大。因此,當測試樣本數為小樣本時,SVM模型準確率更高,效果更好,能夠為預測分類提供更為可靠的支撐。2.3.1、2.3.2和2.3.3中的平均準確率對比情況見表3。

表3 預測分類平均準確率對比表
3 結論
本研究利用python建立了基于SVM的糧食霉變預測分類模型,通過稻谷的2 592組數據和小麥的876組數據進行實驗,分別選用不同規模的數據量作為訓練樣本集建立模型,預測平均準確率分別為96%和92%,該實驗結果證明SVM模型可以有效分類預測糧食是否發生霉變。同時本研究復現BP神經網絡模型,將SVM模型預測結果與其對比,發現針對于大量樣本進行訓練后,兩種模型準確率基本一致。針對小樣本進行訓練后,SVM模型表現良好,準確率高,且表現穩定,明顯優于BP神經網絡模型。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
品牌研究(2022年26期)2022-09-19 05:54:48
快樂語文(2021年36期)2022-01-18 05:49:06
小天使·一年級語數英綜合(2021年10期)2021-10-20 02:41:35
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中國糧食經濟(2018年11期)2018-12-27 08:58:42
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
