深度生成式對抗網(wǎng)絡(luò)的超分辨率圖像修復(fù)與重建
2021-11-16 01:53:06李云紅朱耀麟蘇雪平謝蓉蓉
西安工程大學(xué)學(xué)報 2021年5期
李云紅,穆 興,朱耀麟,湯 汶,蘇雪平,謝蓉蓉
(西安工程大學(xué) 電子信息學(xué)院,陜西 西安 710048)
0 引 言
圖像修復(fù)指的是利用圖像修復(fù)算法將圖像破損或殘缺區(qū)域補全或填充。目前主流的圖像修復(fù)算法以深度學(xué)習(xí)算法[1]為主,包括基于連貫語義注意的圖像修復(fù)方法[2]、基于前景感知的圖像修復(fù)方法[3]、基于卷積自編碼的圖像修復(fù)方法[4]、基于循環(huán)神經(jīng)網(wǎng)絡(luò)的圖像修復(fù)方法[5]。生成式對抗網(wǎng)絡(luò)(generative adversarial networks,GAN)[6]作為生成網(wǎng)絡(luò)通過數(shù)據(jù)樣本和弱標(biāo)簽的聯(lián)合概率分布能充分挖掘深層網(wǎng)絡(luò)的表達能力,但是該網(wǎng)絡(luò)訓(xùn)練不穩(wěn)定容易產(chǎn)生梯度消失或模型崩潰,使修復(fù)圖像模糊不清晰。GULRAJANI等提出改進的瓦瑟斯坦生成式對抗網(wǎng)絡(luò)(wasserstein generative adversarial networks,WGAN)[7],利用懲罰梯度構(gòu)造損失函數(shù),增加了樣本生成的多樣性,但其優(yōu)化難度大,對于小樣本數(shù)據(jù)集,修復(fù)圖像容易產(chǎn)生模糊現(xiàn)象。DOSOVITSKIY等通過解碼器網(wǎng)絡(luò)反向表達深度卷積網(wǎng)絡(luò)的特征信息對圖像細(xì)節(jié)進行重建和修復(fù)[8],對圖像大面積缺失紋理生成精度不高。文獻[9]提出自變分編碼器(variationl auto-encoder,VAE),通過學(xué)習(xí)數(shù)據(jù)生成分布,隨機抽取樣本并對隨機樣本進行解碼,生成具有高斯似然分布的圖像,一定程度上提高了圖像的局部真實性,但是生成的部分圖像仍然存在語義不連貫問題。YU等提出一種基于深度生成模型的方法[10],該方法利用上下文信息生成圖像缺失區(qū)域的輪廓結(jié)構(gòu),對結(jié)構(gòu)簡單的圖像修復(fù)效果較好,而對大面積缺失、紋理結(jié)構(gòu)復(fù)雜的圖像容易產(chǎn)生視覺上的不連續(xù),對非紋理圖像其補全區(qū)域會產(chǎn)生扭曲或模糊紋理現(xiàn)象。ZHANG等提出一種基于漸進生成網(wǎng)絡(luò)的語義修復(fù)方法[11],該方法利用端到端的漸進生成網(wǎng)絡(luò)結(jié)合語義信息,能對圖像小空洞的缺失進行準(zhǔn)確定位,修復(fù)效果能達到視覺感知的一致性。ZHENG等提出一種基于多元化路徑的圖像修復(fù)方法[12],該方法利用圖像真實邊緣得到缺失部分的先驗分布和重構(gòu)路徑概率分布重建原始圖像,但修復(fù)得到的圖像結(jié)構(gòu)相似度較差,達不到與原圖相匹配的圖像物理結(jié)構(gòu)。
針對以上圖像修復(fù)方法中存在的圖像大面積缺失、修復(fù)精度差、分辨率低等問題,提出一種深度生成式對抗網(wǎng)絡(luò)的超分辨圖像修復(fù)與重建方法,該方法能準(zhǔn)確的建立修復(fù)圖像低分辨率(low resolution,LR)和高分辨(high resolution,HR)函數(shù)之間的映射關(guān)系,同時結(jié)合圖像空間特征的變換、邊緣生成信息,填補圖像缺少精細(xì)細(xì)節(jié)的區(qū)域,實現(xiàn)圖像超分辨率[13]修復(fù)與重建。
1 生成式對抗網(wǎng)絡(luò)模型
GAN受到博弈論中2人零和博弈的啟發(fā),將生成器和判別器2個網(wǎng)絡(luò)模塊的訓(xùn)練視為2人的互相對抗博弈,生成器用于生成數(shù)據(jù),判別器用于判別數(shù)據(jù)的真假。生成式對抗網(wǎng)絡(luò)結(jié)構(gòu)如圖1所示。
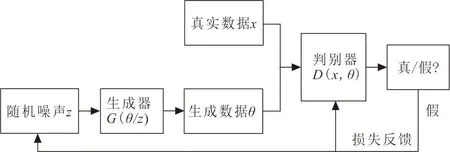
圖1 生成式對抗網(wǎng)絡(luò)結(jié)構(gòu)圖Fig.1 Schematic diagram of generative adversarial network
圖1中,整個GAN網(wǎng)絡(luò)主要由生成器G(θ|z)和判別器D(x,θ)組成,其中:z為隨機噪聲(一般符合均勻分布或高斯分布);x為真實數(shù)據(jù);θ為生成數(shù)據(jù)。生成器和判別器均為深層網(wǎng)絡(luò)結(jié)構(gòu),兩者交替迭代訓(xùn)練直到達到一個納什均衡[14],此時意味著生成器生成的數(shù)據(jù)足以以假亂真,與真實數(shù)據(jù)高度相似。
生成式對抗網(wǎng)絡(luò)的目標(biāo)函數(shù)可表示為
Ez~pz(z)[lb(1-D(G(θ|z)))]
(1)
式中:x~pd(x)為真實數(shù)據(jù)x服從真實圖像的概率分布pd(x);z~pz(z)為隨機噪聲z服從的正態(tài)分布;E()為數(shù)學(xué)期望。
目標(biāo)函數(shù)可得到最優(yōu)解,使數(shù)據(jù)的訓(xùn)練過程快速收斂。設(shè)生成器的分布為pg(x),盡可能使pg(x)收斂到生成數(shù)據(jù)的高斯分布(或均勻分布),交替訓(xùn)練生成器和判別器時,最終,生成器能估測出樣本數(shù)據(jù)分布,在最優(yōu)解的情況下,生成器G(θ|z)的最優(yōu)解為生成數(shù)據(jù)的分布與真實數(shù)據(jù)分布一致,即
pd(x)=pg(x)
(2)
(3)
當(dāng)GAN網(wǎng)絡(luò)模型已達到納什均衡,此時生成模型G(θ|z)刻畫了訓(xùn)練數(shù)據(jù)的分布,判別器D(x,θ)的準(zhǔn)確率為0.5,生成樣本數(shù)據(jù)符合要求。
2 深度生成式對抗網(wǎng)絡(luò)
DSRGAN網(wǎng)絡(luò)利用文獻[15]模型的訓(xùn)練優(yōu)勢,避免訓(xùn)練時出現(xiàn)梯度爆炸、梯度消失、模型崩潰的情況,平衡生成器和判別器的迭代更新,提升圖像樣本數(shù)據(jù)生成的多樣性和視覺質(zhì)量[16],利用隨機梯度下降的算法訓(xùn)練DSRGAN網(wǎng)絡(luò),能夠確保訓(xùn)練的穩(wěn)定使該模型具有文獻[15]模型的收斂性和均衡性。結(jié)合超分辨率重建[17-18],構(gòu)建新的生成器和判別器并利用損失函數(shù)確立LR像素和HR像素之間的映射關(guān)系,準(zhǔn)確定位待修復(fù)像素信息,實現(xiàn)圖像LR到HR修復(fù)的逼真效果。
2.1 生成器
DenseNet具有跳躍連接特性,有助于梯度的反向傳播,加快了訓(xùn)練過程,生成器采用改進的DenseNet[19-20]結(jié)構(gòu),能增強模型性能和減少迭代計算的復(fù)雜度,如圖2所示。

圖2 生成器網(wǎng)絡(luò)結(jié)構(gòu)Fig.2 Generator network structure
圖2中,與傳統(tǒng)DenseNet網(wǎng)絡(luò)不同,該方法將網(wǎng)絡(luò)的批量歸一化層(batch normalization,BN)去掉,同時將部分激活函數(shù)ReLU替換為Leaky-ReLU。
由于BN層在訓(xùn)練期間使用批次的均值和方差對特征進行歸一化,在測試期間使用的是整個訓(xùn)練數(shù)據(jù)集的估計均值和方差。當(dāng)訓(xùn)練數(shù)據(jù)集和測試數(shù)據(jù)集的統(tǒng)計數(shù)據(jù)差異很大時,對于深層網(wǎng)絡(luò)而言,BN層往往引入不適的偽影,限制了泛化能力,導(dǎo)致模型訓(xùn)練不穩(wěn)定。因此,為了訓(xùn)練穩(wěn)定和一致性去掉BN層,能增強DSRGAN網(wǎng)絡(luò)的性能減少計算的復(fù)雜度和去除圖像模糊[21]的偽影,而生成器DenseNet網(wǎng)絡(luò)采用稠密鏈接機制,稠密鏈接主要由Dense Block稠密塊和Transition Layer過渡層組成,將所有的Layers連接起來,Dense Block內(nèi)部的網(wǎng)絡(luò)連接為強梯度流,形成一種隱含的深度監(jiān)督,能夠保持圖像修復(fù)中像素信息的前饋特性,提高了圖像修復(fù)的視覺連貫性使修復(fù)后的圖像紋理清晰。其次,稠密塊與過渡層連接,過渡層是1×1的卷積核,起到降低Dense Block模塊的輸出維度,使生成器模型復(fù)雜度降低,在圖像修復(fù)中促進破損像素點的修復(fù)。
2.2 相對條件判別器
相對條件判別器不同于標(biāo)準(zhǔn)的判別器,其能夠估算一個輸入真實圖像和生成圖像的可能性,并且能預(yù)測真實圖像的概率xr比假圖像的概率xf更真實的概率。為了平衡生成式對抗網(wǎng)絡(luò),文中提出相對條件判別器代替實驗中的標(biāo)準(zhǔn)判別器,其模型如圖3所示。

圖3 相對條件判別器模型Fig.3 Relative condition discriminator model
圖3中,相對條件判別器判別函數(shù)表示為DRa(),標(biāo)椎判GAN別器表示為D()。其中:σ為sigmoid函數(shù);C()為非變換判別器的輸出;E()為在批處理中對所有假數(shù)據(jù)取平均值的操作。
2.3 損失函數(shù)
損失函數(shù)由判別器損失函數(shù)和生成器損失函數(shù)構(gòu)成,生成器損失函數(shù)包含對抗損失函數(shù)、內(nèi)容損失函數(shù)、感知損失函數(shù)。
1) 判別器損失函數(shù)。提出的相對條件判別器能通過簡單的數(shù)據(jù)計算預(yù)測真實圖像和生成圖像的概率分布,同時能對生成器做出信息反饋,降低了判別真假的復(fù)雜度,同時對LR圖像和HR圖像的維度分布做出甄別,以獲取所需要的生成圖像,整體上提升了修復(fù)模型的學(xué)習(xí)能力,節(jié)省了訓(xùn)練時間,加速了模型收斂。判別器損失函數(shù)可表示為
LD=-Ex,r[lb(DRa(xr,xf))]-
Ex,f[lb(1-DRa(xf,xr))]
(4)
2) 對抗損失函數(shù)可表示為
La=-Ex,r[lb(1-DRa(xr,xf))]-
Ex,f[lb(DRa(xf,xr))]
(5)
DSRGAN方法中判別器和生成器采用一種對稱的形式,起到信息反饋的作用,所以判別器的模態(tài)化能預(yù)測生成樣本圖像邊緣輪廓、紋理細(xì)節(jié),生成器也更適合對抗訓(xùn)練中生成數(shù)據(jù)和真實數(shù)據(jù)的漸變,兩者的互相博弈可以實現(xiàn)圖像修復(fù)的LR到HR的目的。
3) 內(nèi)容損失函數(shù)。設(shè)計內(nèi)容損失函數(shù),通過圖像殘損區(qū)域的邊緣信息與未損壞區(qū)域建立函數(shù)映射,為了使圖像的破損區(qū)域修復(fù)后盡可能地與真實圖像相匹配,未破損的區(qū)域更清晰,保持圖像修復(fù)后能達到HR效果,使用1-范數(shù)距離來衡量生成器生成的圖像的未破損區(qū)域和真實樣本中未破損區(qū)域的差別。引入W為圖像掩膜,其與輸入圖像尺寸大小相同,其中當(dāng)W為0時,代表圖像中部分破損的像素點,W為1時代表圖像部分未破損像素點。內(nèi)容損失函數(shù)可表示為
Lg=IExi‖W×G(xi)-y‖1
(6)
式中:G(xi)為生成接近于真實樣本數(shù)據(jù)矩陣;y為生成的假樣本數(shù)據(jù)矩陣;I為圖像像素點矩陣。
4)感知損失函數(shù)。有效的感知損失Lp,在圖像修復(fù)中,通過激活前約束特征,可以降低模型訓(xùn)練的復(fù)雜度,本實驗提出的感知損失在激活層之前使用特征,將克服2個缺點:一是被激活函數(shù)的特征是非常稀疏的,特別是在深層網(wǎng)絡(luò)之后,稀疏激活函數(shù)提供弱監(jiān)督,從而導(dǎo)致性能較差;二是使用激活后的特征會造成修復(fù)后的圖像和真實圖像對比度不一致。其中感知損失函數(shù)可表示為
(7)
生成器完整的損失函數(shù)包括對抗損失、內(nèi)容損失以及感知損失3部分,可表示為
LG=Lp+λLa+Lg
(8)
式中:Lg=η1L1+η2L2+η3L3+η4L4。本實驗中生成器由4個Dense Block網(wǎng)絡(luò),所以L1到L4為其內(nèi)容損失,λ、η1、η2、η3、η4為平衡不同損失的系數(shù)設(shè)置,該系數(shù)經(jīng)過不斷的測試獲得其最優(yōu)值,其中訓(xùn)練參數(shù)學(xué)習(xí)率為0.002,λ為0.5,η1、η2、η3、η4分別為0.2、0.4、0.6、0.9。
2.4 DSRGAN算法實現(xiàn)流程
算法初始化采用SGD算法訓(xùn)練模型,設(shè)置超參數(shù)M,迭代次數(shù)N,批量大小m。當(dāng)前迭代次數(shù)小于最大迭代次數(shù),當(dāng)前更新次數(shù)小于最大更新次數(shù)。
1) 從真實圖像中采集服從數(shù)據(jù)分布pd(x)的m個樣本{x(1),x(2),x(3),…,x(m)};
2) 將選取的m個圖像樣本數(shù)據(jù)添加掩膜{N1,N2,N3…,Nm};
3) 計算判別器網(wǎng)絡(luò)模型的損失函數(shù)LD;
5) 原始圖像數(shù)據(jù)集中采樣服從噪聲分布pg(z)的m個樣本{z(1),z(2),z(3),…,z(m)};
6) 計算生成器網(wǎng)絡(luò)模型的損失函數(shù)LG;
8) 不斷循環(huán)進行上面步驟,直到整個數(shù)據(jù)集訓(xùn)練完成。其中,?θdJ(θ)為判別網(wǎng)絡(luò)的SGD的值,?θgJ(θ)為生成網(wǎng)絡(luò)SGD的值。
3 結(jié)果與分析
本實驗從CelebA數(shù)據(jù)集獲取10 000張人臉圖像來訓(xùn)練圖像修復(fù)模型,取其中8 000張作為訓(xùn)練集,2 000張為測試集。為了測試模型的廣泛性、準(zhǔn)確性和視覺真實性,實驗將收集5 000張古代殘損紡織物圖像作為數(shù)據(jù)集,在Places2取10 000張圖像作為本實驗修復(fù)模型的訓(xùn)練集,使模型具有良好的泛化能力。
實驗采用近年來基于深度學(xué)習(xí)的圖像修復(fù)方法效果較好的GCA方法[10],SI方法[11],PIC方法[12]與DSRGAN方法進行對比,分別在CelebA、Places2、殘損紡織物3個數(shù)據(jù)集測試上測試,分別得到圖4、5、6的效果圖。
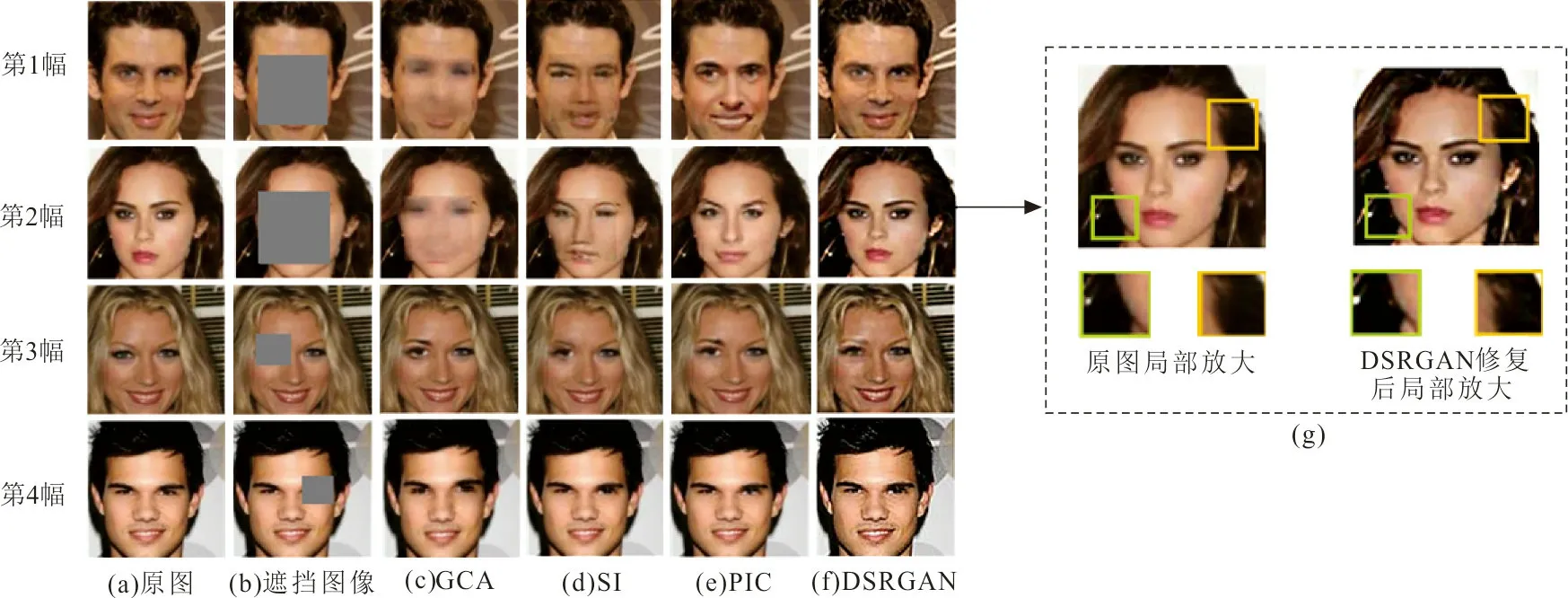
圖4 CelebA數(shù)據(jù)集修復(fù)效果比較Fig.4 Inpainting effects comparison of celebA dataset
圖4為不同面積的遮擋區(qū)域,從第1幅到第4幅遮擋面積逐漸減小,可以直觀看出其他對比方法存在大面積缺失修復(fù)后模糊、全局一致性差的問題。如圖4(g)所示為本文DSRGAN方法,局部修復(fù)效果放大,克服了以上其他方法存在的問題,并且在細(xì)節(jié)和分辨率修復(fù)上有了明顯的提升。圖5為相同遮擋面積的修復(fù),其效果圖可以直觀的看出,所提方法修復(fù)的圖像紋理細(xì)節(jié)更加清晰、圖像輪廓更加真實。

圖5 Places2數(shù)據(jù)集上的修復(fù)效果圖Fig.5 An inpainting rendering images on the Places2 dataset
為了客觀評價DSRGAN修復(fù)方法的優(yōu)越性,采用峰值信噪比(peak signal-to-noise ratio,PSNR)來衡量修復(fù)圖像和原始圖像之間的差距,PSNR值越大圖像修復(fù)效果越好;同時為了體現(xiàn)圖像修復(fù)方法在圖像修復(fù)結(jié)構(gòu)上的準(zhǔn)確性,利用結(jié)構(gòu)相似性(structural similarity index,SSIM)來評價圖像的修復(fù)質(zhì)量,SSIM值越接近于1,結(jié)構(gòu)越相似,圖像的修復(fù)質(zhì)量就越好。
設(shè)2幅單色圖像的大小為m×n,如果2幅圖的噪聲近似,那么它們的均方誤差可表示為
(9)
PSNR可表示為
(10)
式中:imax為圖像像素點顏色的最大值,如果每采樣點用8位表示,最大像素值為255。
SSIM是一種評價原始圖像和修復(fù)圖像之間相似度的指標(biāo),可表示為
(11)
式中:c1、c2為正整數(shù)。
利用PSNR和SSIM對圖像修復(fù)質(zhì)量進行評價,如表1、2所示,其中,加粗字體為最優(yōu)值。
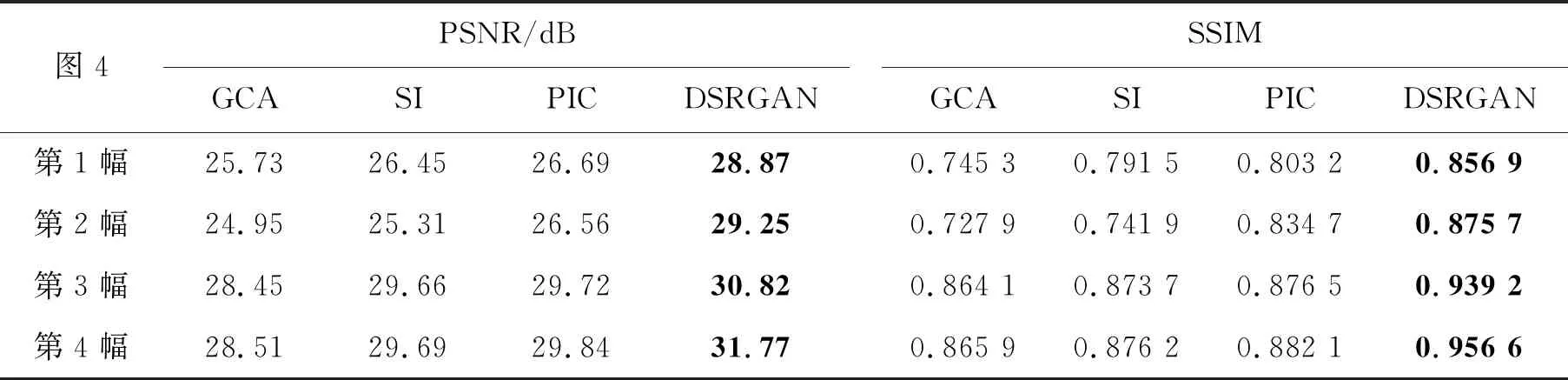
表1 CelebA數(shù)據(jù)集測試的PSNR和SSIMTab.1 PSNR and SSIM of CelebA dataset test
從表1可知,本文提出的DSRGAN方法的PSNR平均提高了2.57 dB,SSIM平均提高了0.083 5,表明該方法不論在大面積人臉遮擋修復(fù)上,還是小面積人臉遮擋修復(fù)上都具有較高的PSNR和SSIM。從表2可知,DSRGAN方法的PSNR平均提高了3.17 dB,SSIM平均提高了0.148 1,表明了相較所列舉的對比方法,該方法在圖像大面積缺失的修復(fù)效果更加良好。
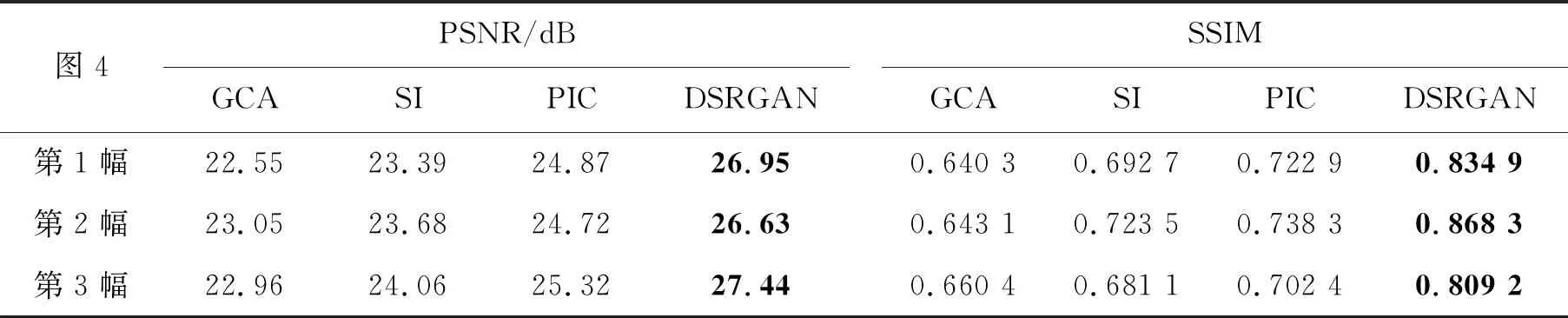
表2 Places2數(shù)據(jù)集測試的PSNR和SSIMTab.2 PSNR and SSIM of Places2 dataset test
為進一步驗證DSRGAN模型圖像修復(fù)的普遍性,利用古代殘損紡織物圖像進行測試,與GCA、SI、PIC模型圖像修復(fù)結(jié)果進行對比,如圖6和表3所示。

圖6 殘損紡織物數(shù)據(jù)集效果Fig.6 Renderings of damaged textile dataset
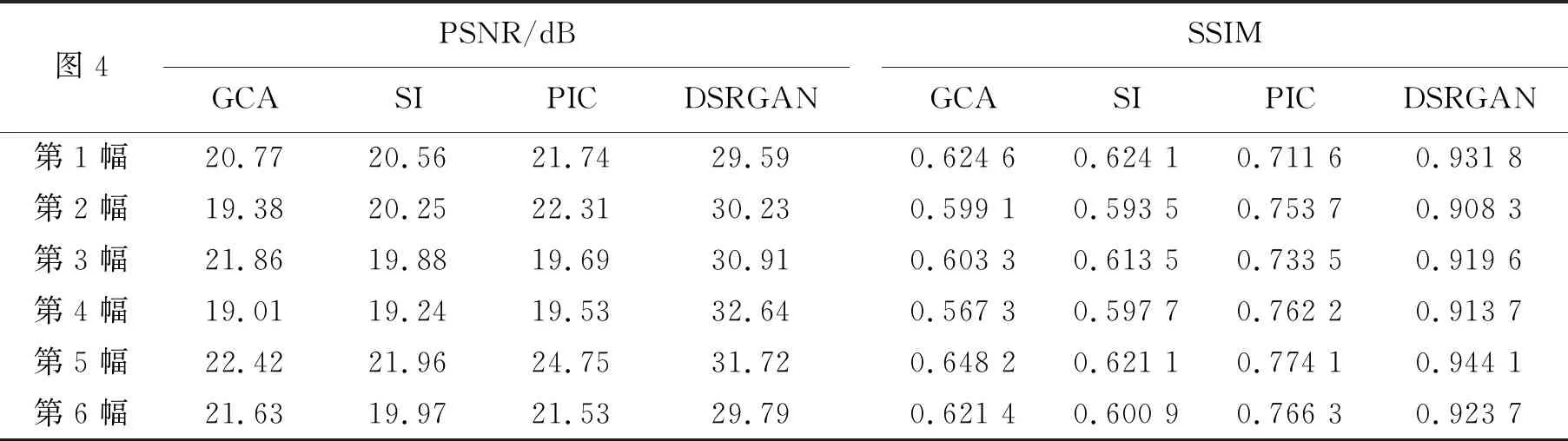
表3 殘損紡織物測試的PSNR和SSIMTab.3 PSNR and SSIM for testing of damaged textiles
從表3可看出,PSNR平均提高了5.89 dB,SSIM平均提高0.264 1,表明本文提出的DSRGAN方法在圖像超分辨率修復(fù)上,對圖像的紋理細(xì)節(jié)、語義信息等的修復(fù)有良好的適應(yīng)性,由視覺效果可以看出圖像修復(fù)后的分辨率明顯提高,圖像的視覺細(xì)節(jié)更加清晰明了。
4 結(jié) 語
針對圖像大面積缺失修復(fù)視覺不連貫、分辨率低等問題,本文提出的DSRGAN圖像修復(fù)方法,利用改進的DenseNet網(wǎng)絡(luò),加深了網(wǎng)絡(luò)層數(shù)并提升了模型泛化能力,使圖像數(shù)據(jù)生成分布更加多樣化,可根據(jù)不同類型的圖像自動生成函數(shù)映射,能更準(zhǔn)確的聯(lián)系上下文像素點,精確捕捉圖像的局部信息,改善圖像修復(fù)效果。在CelebA、Places2及殘損紡織物3個數(shù)據(jù)集上測試,通過主觀效果和客觀實驗結(jié)果對比,表明DSRGAN方法提升了圖像修復(fù)的質(zhì)量和精度,增強的修復(fù)圖像的分辨率,消除了輪廓模糊、紋理不清晰的現(xiàn)象,修復(fù)后的圖像滿足視覺的整體一致性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
