基于改進YOLOv3模型的道路車輛多目標檢測方法
2021-11-16 01:53:06馬麗萍馬文哲張宏偉
西安工程大學學報 2021年5期
馬麗萍,贠 鑫,馬文哲,張宏偉
(西安工程大學 電子信息學院,陜西 西安 710048)
0 引 言
道路車輛檢測[1]作為智能交通系統數據前端采集的重要環節[2],一直以來都是該領域的研究熱點。而車輛檢測算法對同視景中道路近、遠端目標車輛的檢測能力,將直接影響道路交通攝像頭的使用效率[3]。因此,提高同幀圖像內近、遠端目標檢測精度是智能交通系統中基于機器學習的目標檢測算法的重要研究課題之一[4-5]。
基于機器學習的傳統目標檢測算法中[6],文獻[7]使用梯度直方圖特征(histogram of oriented gradient, HOG)提取局部區域的邊緣和梯度特征,再結合支持向量機(support vector machine, SVM)進行車輛檢測;文獻[8]采用哈爾特征提取圖像的邊緣、線性、中心和對角線特征,再利用SVM進行人臉檢測;文獻[9]提出將類哈爾特征與Adaboost分類器融合的識別算法,實現了對前方車輛的準確識別。但是,傳統的目標檢測方法主要依賴于人工獲取有關的目標特征信息,人工特征提取階段提取的特征優劣將直接影響整個算法的檢測性能。而人工提取的特征只能描述目標的表象和形狀,無法表達深層特征信息,且候選目標框數量較多,導致模型的泛化能力差,普適性低,計算量大,且在復雜多變的背景下,模型的魯棒性較弱,限制了實際應用[10]。
基于深度學習的目標檢測方法[11],最早是文獻[12]通過借鑒傳統目標檢測中的滑動窗口思想,提出的基于選擇搜索的R-CNN目標檢測框架。早期的目標檢測算法均為Tow-stage目標檢測算法,都是將目標檢測問題分為候選區域提取和候選區域位置及類別預測2個階段。這類算法的典型代表是R-CNN系列算法,如:R-CNN、Fast R-CNN[13]、Faster R-CNN[14]等,此類方法雖然檢測精度高,但由于在提取候選網絡上耗費的時間較長,因此在速度上并不能滿足實時檢測的要求。隨后出現的One-stage目標檢測算法,主要有SSD[15]和YOLO[16-18]系列算法,此類算法不需要使用區域候選網絡,直接通過卷積神經網絡提取特征來產生目標的位置和類別信息,是一種端到端的目標檢測算法,具有更快的檢測速度。其中,YOLOv3因其良好的檢測精度和速度,在車輛檢測任務中得到了廣泛應用[19-21]。
綜上,本文引入YOLOv3模型進行道路車輛的多目標檢測方法研究。針對近、遠端目標車輛在交通視頻中不同特征、特點造成的檢測精度低,甚至漏檢等問題,提出了YOLOv3-Y模型。YOLOv3-Y模型在YOLOv3采用的多尺度特征檢測思想的基礎上,增加一個檢測層,將檢測尺度擴展到4種;再利用K-means算法在自制的車輛數據集上對先驗框進行重新聚類,得出適用于本文所用車輛數據集的先驗框;最后用GIOU[22]代替IOU作為坐標誤差損失函數,增強對目標物體尺寸的敏感度,加快模型擬合預測框與真實框的位置關系,提高模型的預測精度。
1 基于YOLOv3的多目標檢測模型
1.1 YOLOv3網絡結構
YOLOv3的核心思想是將整張圖片作為神經網絡的輸入,并在最后輸出層直接輸出回歸的目標框位置和類別信息[23]。YOLOv3的網絡結構主要分為Darknet-53特征提取網絡和特征圖預測識別2部分:Darknet-53特征提取網絡,共包含53個卷積層,交替使用1×1和3×3的濾波器進行卷積;采用步長為2的卷積核對輸入圖像進行5次降采樣,在最后3次降采樣中對目標進行預測識別。同時YOLOv3借鑒了ResNet[24]網絡中的殘差塊結構和跳躍連接機制,解決了由網絡加深導致的梯度彌散和梯度爆炸問題。Darknet-53中包含了5個大殘差塊,這5個大殘差塊中分別包含1、2、8、8、4個小殘差單元。通過輸入與2個DBL單元進行殘差操作,構成殘差單元,其中,DBL單元包含卷積、批歸一化和leaky ReLU激活函數。
檢測階段YOLOv3使用多尺度特征[25]進行預測,將Darknet-53網絡中后3次降采樣得到的52×52、26×26、13×13等3個尺度上的特征圖分別通過全卷積特征提取器(Convolutional Set)處理。獲得處理結果后,一部分根據置信度大小對結果進行回歸,得到最終的預測結果;另一部分通過上采樣與對應的上一特征層進行融合,實現3個不同尺度的跨層檢測。
1.2 網絡結構的改進
由于道路中不同車輛與攝像頭之間的距離差異,在獲得的圖像中,遠端車輛會呈現小目標的特性[26],如在圖片中所占像素少、特征不明顯,與近端大目標相比遠端車輛在檢測中會存在檢測率低、虛警率高等問題。因此,為了改善遠端小目標車輛的檢測效果,本文改進模型在YOLOv3網絡結構的基礎上增加了網絡的檢測尺度,改進后的網絡結構如圖1所示。
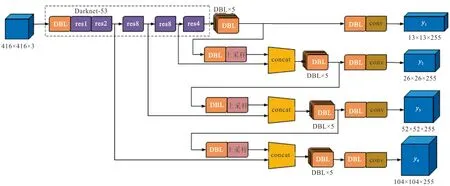
圖1 改進的YOLOv3網絡結構Fig.1 Improved YOLOv3 network structure
圖1在YOLOv3的3個檢測層基礎上增加了尺度為104×104的檢測層。對特征提取網絡輸出的52×52尺度的8倍降采樣特征圖進行2倍上采樣,使其變為104×104尺度的特征圖,再將得到的特征圖與網絡中第2個殘差塊輸出的104×104尺度的4倍降采樣特征圖進行拼接,建立輸出為4倍降采樣的特征融合目標檢測層。相較于其他尺度檢測層,104×104尺度的檢測層將圖像劃分成了更精細的單元格,提升了對小目標的檢測效果。隨后對數據集真實框進行聚類分析,將得到的候選框尺寸分別應用到4個(104×104、52×52、26×26、13×13)不同尺度的檢測層上,并將該網絡模型稱為YOLOv3-DL4。
1.3 基于K-means聚類的先驗框重選取
YOLOv3沿用YOLOv2中的先驗框思想,使用9個不同先驗框代替YOLOv2中的5個先驗框。先驗框是針對不同尺度網絡層確定的具有固定寬度和高度的初始候選框,用來邏輯回歸邊界框。故先驗框選擇的優劣會影響檢測器的性能,對最終的檢測結果有直接的影響。
YOLOv3使用K-means算法對輸出的3個尺度特征圖在COCO數據集上聚類出9個不同尺寸的先驗框,每個尺度根據感受野對應3個固定尺寸的先驗框。YOLOv3輸出的3個特征圖尺度分別為:52×52、26×26、13×13。其中,52×52尺度的特征圖感受野較小,對小目標相對敏感,選用尺寸較小的先驗框(10, 13)、(16, 30)和(33, 23)來檢測較小的目標;26×26尺度的特征圖具有中等感受野,選用尺寸中等的先驗框(30, 61)、(62, 45)和(59, 119)來檢測中等大小的目標;而較小的13×13尺度的特征圖感受野較大,對大目標相對敏感,選用尺寸較大的先驗框(116, 90)、(156, 198)和(373, 326)來檢測大目標。同時,YOLOv3采用與標簽尺寸大小無關的平均IOU作為度量標簽相似性的指標,對訓練集所有目標使用K-means聚類獲得先驗框的大小。
在COCO數據集中有80類目標,這些目標物體尺寸不一,大小差距較大,聚類出來的先驗框形狀不一。由于本文的檢測目標只是車輛,在車輛目標數據集中,多數的先驗框的形狀是寬大于高的,用于本文實際道路車輛數據集時部分先驗框不合理。所以,對于本文數據集進行重新聚類,獲得適合本文道路車輛數據集的先驗框,提高近、遠端車輛目標的檢出率。
YOLOv3-DL4模型的檢測網絡共包含4個不同尺度的檢測層,每個檢測尺度分配3組先驗框,故共需12組先驗框。因此采用K-means算法聚類出12組先驗框,再根據檢測尺度大小的不同,將得到的先驗框分別應用到不同尺度的檢測層中,分配結果如表1所示。
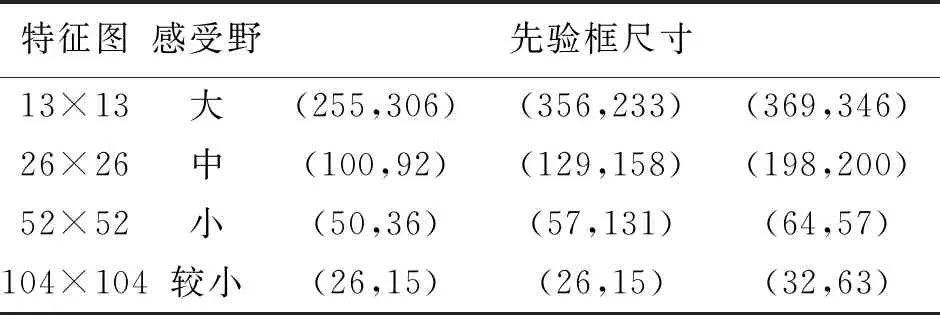
表1 不同尺度特征圖對應的先驗框尺寸Tab.1 The size of the anchor corresponding to the feature map of different scales
1.4 邊界框檢測Loss的改進
IOU是目標檢測中最常用的測量指標,可表示為
(1)
式中:A為預測框;B為真實框。
IOU表示預測框與真實框交集與并集的比值,所以,常用的先驗框回歸損失優化和IOU優化不完全等價。GIOU作為距離度量標準,其滿足非負性、不可分的同一性、對稱性和三角不等性。GIOU值是比值,對目標框尺度并不敏感,具有尺度不變性。由于GIOU引入了包含A和B最小凸集C,當A、B2個框不重合時,依然可以進行梯度優化,在保留了IOU原始性質的同時弱化了它的缺點。所以本文在YOLOv3-DL4模型的基礎上,引入GIOU來解決IOU無法直接優化非重疊部分的問題,并將引入GIOU后的模型稱為YOLOv3-Y。
2 實驗結果及分析
實驗使用的工作站設備型號為容天SCW4750,顯卡為NVIDIA GTX 1080TI 11 GiB,8個16 GiB內存,處理器為Intel i7-6800 CPU,操作系統為Ubuntu16.04,深度神經網絡參數配置平臺為Darknet框架,并同時安裝了CUDA(compute unified device architecture) 9.0、CUDNN(CUDA deep neural network library) 7.0.4以支持GPU的使用。
2.1 樣本數據
為保證數據多樣性,分時段對同一目標路段進行圖像采集,保證不同時段的樣本數據中包含車型種類、顏色具有可比較性,采集時長共560 min,有效實際道路圖像30 000幀,經數據增強操作后獲得樣本圖像120 000幀,隨機選取部分數據樣本,如圖2所示。使用LabelImg對采集到的數據集內的車輛進行標注,對應car、van、truck、bus 4種常見車型,標注完成后生成對應的XML文件。數據集中將訓練樣本按70%和30%的比例隨機分開,用于模型的訓練和模型性能的驗證。

圖2 部分數據樣本Fig.2 Part of the data sample
2.2 模型驗證結果分析
基于2.1節搭建的實驗平臺,對YOLOv3、YOLOv3-DL4和YOLOv3-Y模型分別進行訓練。初始訓練階段的衰減系數、動量參數和學習率分別設置為0.000 5、0.9和0.001,并選擇steps模式更新學習率,訓練迭代次數達到16 000和18 000時,學習率分別降低至初始學習率的10%和1%,使損失函數進一步收斂,比較得到的車輛多目標檢測結果。3種模型在實驗室實際道路車輛數據集上的平均準確度AP和平均精度均值mAP如表2所示,其中,“×”表示模型沒有加入該項,“√”表示模型加入了該項。

表2 不同網絡模型檢測結果比較Tab.2 Comparison of detection results of different network models
從表2可以看出,YOLOv3在增加了檢測層并重新計算先驗框尺寸后,模型中的先驗框更適合于本文構建的車輛數據集,且對近、遠端車輛目標更加敏感。因此YOLOv3-DL4模型相較于YOLOv3模型對4種車型的檢測效果均有小幅度提升,總體檢測平均準確率提高了5.35%。使用GIOU損失提高檢測準確率的效果明顯,相比YOLOv3網絡模型,平均準確率提高了11.05%。以上3個模型的檢測對比結果如圖3所示。
如圖3(a)、(b)、(c)分別是YOLOv3、YOLOv3-DL4及YOLOv3-Y迭代20 000 次得到的模型對實際道路交通場景下的車輛檢測結果,圖中粉色框表示該車輛識別為“car”類,紅色框表示識別為“van”類,綠色框表示識別為“bus”類,藍色框表示識別為“truck”類。從圖3(a)中可以發現a1、a2、a3均沒有檢測出左上角距離較遠的小目標車輛,a4中未檢測出左下角距離較近的“bus”類車輛,a5在右上角出現了將“truck”類錯檢為“van”類、a6中左上角出現了將“van”類錯檢為“car”類的情況。對比子圖(b),YOLOv3-DL4改善了a1、a3、a4的漏檢及a5、a6的錯檢情況,但b2中右上角處仍存在漏檢情況。圖3(c)中,改進的YOLOv3-Y模型消除了上述YOLOv3及YOLOv3-DL4模型檢測結果中的漏檢和錯檢現象。通過實驗,可以發現YOLOv3-Y算法能夠精確檢測出更多的車輛,在一定程度上緩解了對小目標的漏檢、錯檢情況,對同幀圖像中近、遠端目標均具有較好的適應性,能夠提高網絡模型的檢測效果。

(a) YOLOv3模型
2.3 YOLOv3-Y車型識別結果與分析
在車型識別的實驗中,將YOLOv3-Y模型與YOLOv2、YOLOv2-voc、YOLOv2-tiny、YOLOv3、YOLOv3-tiny 5種經典模型進行了對比,對比結果如表3所示。

表3 不同模型檢測的平均精度均值及平均精度值Tab.3 mAP and AP values detected by different models 單位:%
從表3可知,YOLOv3-Y模型的mAP較YOLOv3模型提高了11.05%,達到84.30%,其余4種模型的mAP值均低于80%。4種車型識別效果中:由于“van”類車輛的特征較難被識別,6種模型對“van”類車輛識別的平均準確率均偏低,除YOLOv3-Y模型外,其余5種模型的AP值均低于60%,YOLOv3-Y模型將“van”類車輛的AP值提高到了62.23%。對于其他3種車型檢測的平均準確率,除YOLOv3-Y外,YOLOv3-tiny獲得“car”和“bus”類車輛識別最優AP值分別為88.82%和92.27%,YOLOv2獲得“truck”類的識別最優AP值89.04%,本文模型對“car”“bus”“truck”類型車輛識別的平均準確率在最高值的基礎上分別提高了3.04%,0.81%和1.01%。該網絡模型通過利用殘差思想和上采樣操作融合了多級特征圖,讓更細粒度的特征參與車輛檢測,從而解決了該數據集中車輛目標多尺度和遠端小目標的檢測問題,提高了對近、遠端車輛目標的檢測效果。
為了進一步準確的評估改進模型的識別效果,計算6種模型被檢目標的準確率P、召回率R以及F1分數,其中F1分數為精確率和召回率的調和平均數,能同時兼顧模型的精確度和召回率,取值在0~1之間,F1越大,模型效果越好。識別結果如表4所示。
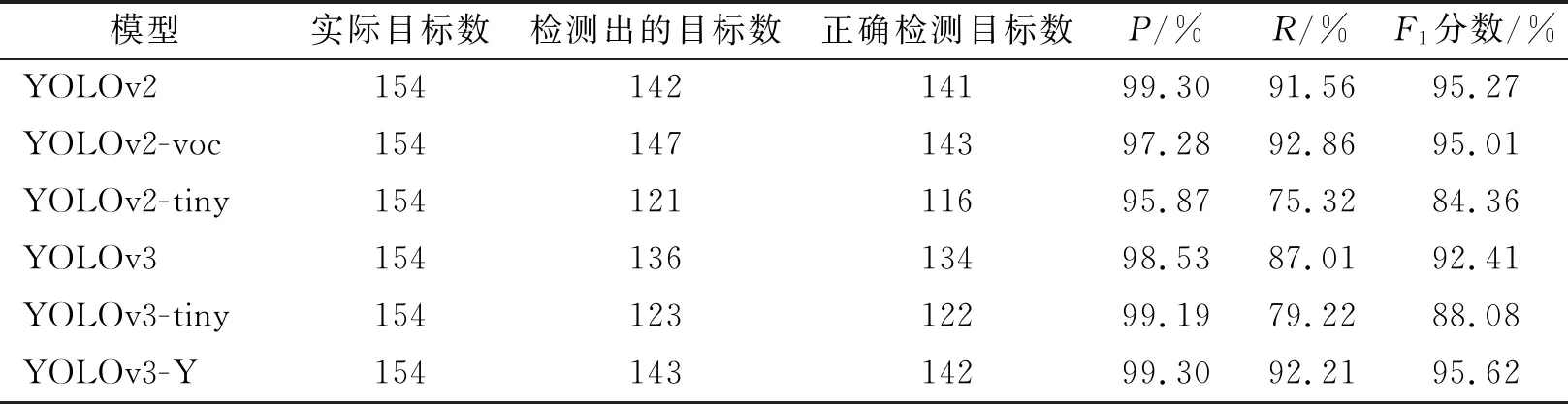
表4 不同模型的識別結果Tab.4 Recognition results of different models
(2)
式中:NTP為模型正確檢測出來的目標數量;NFP為模型誤檢的目標數量;NFN為模型漏檢的目標數量。
從表4可知,在驗證154個目標時,6個模型在精度方面均表現良好,在召回率方面YOLOv2-tiny、YOLOv3和YOLOv3-tiny模型的召回率均低于90%,與其余3個模型相比,正確率偏低,效果較差。對比6個模型的F1分數,除YOLOv3-Y模型外,YOLOv2模型獲得最高F1分數95.27%,能準確檢測出142個車輛目標,正確識別出141個車輛目標,準確率達到了99.30%,召回率達到了91.56%。本文模型對4種類型車輛目標識別的精確度與最高值齊平,召回率及F1分數在最高值的基礎上分別提高了0.65%和0.35%,分別達到了99.30%、92.21%和95.62%。
YOLOv2、YOLOv2-voc、YOLOv2-tiny、YOLOv3、YOLOv3-tiny和YOLOv3-Y模型的交并比、召回率及精確度曲線如圖4所示。
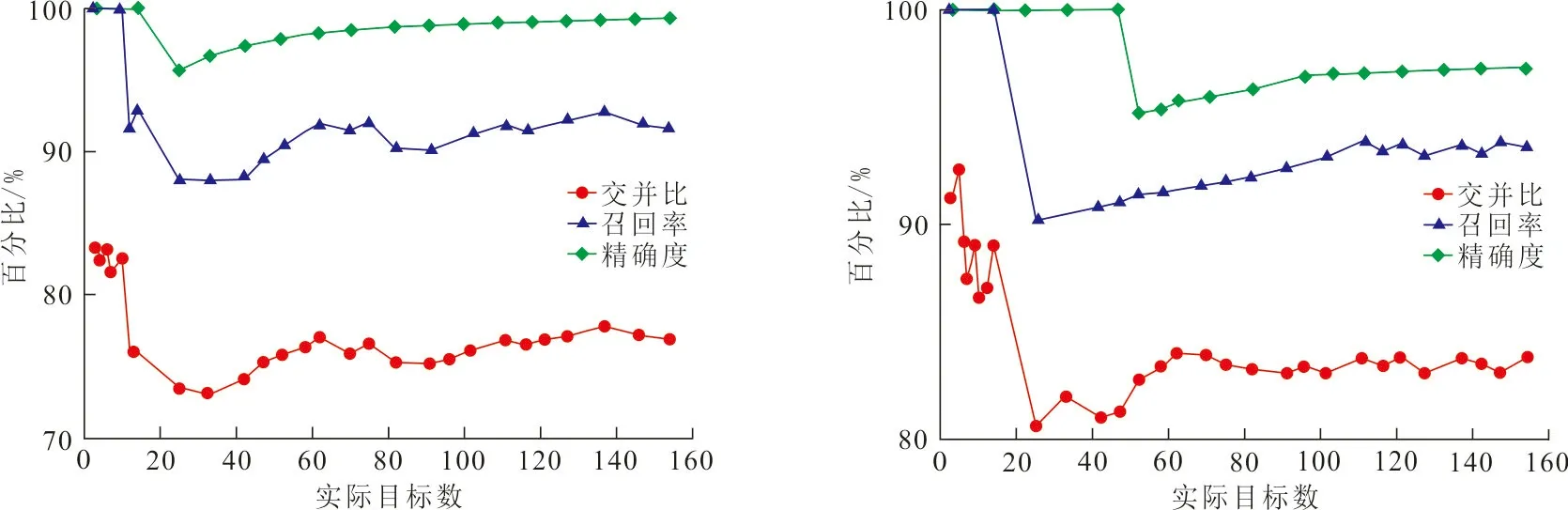
(a) YOLOv2 (b) YOLOv2-voc
圖4中,6個模型的召回率在初始時都出現了較大波動,隨著檢測的目標數增加逐漸趨于穩定,YOLOv2模型和YOLOv2-voc模型的召回率逐漸穩定在91%,YOLOv2-tiny模型的召回率逐漸穩定在75%,YOLOv3模型趨于87%,YOLOv3-tiny模型召回率逐漸趨于80%,YOLOv3-Y模型的召回率始終保持在90%以上,說明在實際交通背景下YOLOv3-Y模型具有較高的正確率,而YOLOv2-tiny和YOLOv3-tiny的正確率較低;在精度方面,YOLOv2和YOLOv2-voc模型在開始階段,出現較大的跳變,但隨著目標數的增加,模型的精度趨于穩定。6個模型中,YOLOv2-voc和YOLOv2-tiny模型的精度相對較低,其他4種模型的精度均表現良好,其中YOLOv3-Y模型的精度達到了99.3%,為最優,表明改進后的模型保持了很高的精確度和穩定性;同時對比6種模型的交并比曲線可以看出,6種模型均出現了不同幅度的波動,YOLOv2模型的IOU在0.75左右波動,YOLOv2-voc模型的IOU較YOLOv2有所提高,維持在0.83左右。
YOLOv2-tiny模型和YOLOv3模型的交并比值分別在0.5~0.6和0.65~0.73之間波動,波動范圍相對較大,穩定性低;而YOLOv3-tiny模型和YOLOv3-Y模型的交并比值分別在0.45~0.5和0.78~0.82之間波動,波動范圍小,曲線較平滑,有較好的穩定性,但YOLOv3-tiny模型交并比值較低。綜上,YOLOv3-Y模型在以上3方面均表現突出,具有較高的精確度和穩定性。
圖5為上述6種模型分別在訓練集上訓練20 000次獲得的權重模型,在驗證集上得到的檢測結果。

(a) YOLOv2模型 (b) YOLOv2-voc模型
圖5(a)、(b)中YOLOv2模型和YOLOv2-voc模型對遠端小目標出現了嚴重的漏檢;圖5(c)中的漏檢情況有所改善,檢測出了1、2中的所有目標,但3、4中仍存在對小目標的漏檢;圖5(d)中,1未檢測出左上角小目標,3中出現將“truck”誤檢為“van”類的情況,4中漏檢了距離較遠的“car”類車輛及距離較近的“van”類車輛;圖5(e)中4張結果圖中均存在對小目標的漏檢;在圖5(f)中,消除了上述的漏檢現象,并正確檢測出了3中的“truck”。綜上所述,YOLOv3-Y模型對實際交通道路下的車輛目標檢測效果最好,并解決了其余模型對近、遠端車輛檢測與識別結果中存在的漏檢、錯檢問題。
3 結 語
本文分析了現有YOLO深度學習方法在真實道路環境下車輛目標檢測與識別中存在的問題,即對于同一幀圖像近端和遠端目標車輛檢測不能同時獲得較好的檢測效率。為此,在YOLOv3模型的基礎上進行了改進,首先,增加了輸出為4倍降采樣的特征融合目標檢測層,通過提取4種不同尺度的特征圖,為目標預測模塊提供更加豐富的細節信息,增強網絡對遠、近端目標車輛的檢測能力;其次,使用K-means聚類算法重新確定適合本文車輛數據集的先驗框尺寸,使模型更符合車輛目標的檢測,提高模型預測目標位置的能力;然后引入GIOU損失函數對IOU損失函數進行了優化,提高模型的定位能力;最后,將得到的YOLOv3-Y模型與YOLOv2、YOLOv2-voc、YOLOv2-tiny、YOLOv3及YOLOv3-tiny 5種經典模型在實驗室實際道路車輛數據集上進行對比。實驗結果表明,改進的YOLOv3-Y模型在實際交通場景中車輛目標檢測任務的平均精度均值達到了84.30%,相較于原始的YOLOv3算法提高了11.05%,對同幀圖像中近、遠端車輛目標均具有較好的檢測性能。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
