基于YOLO v3的有軌電車(chē)在途障礙物檢測(cè)方法
2021-11-30 14:47:16馬永剛謝文斌
鐵路通信信號(hào)工程技術(shù) 2021年11期
馬永剛,吳 凱,謝文斌
(通號(hào)萬(wàn)全信號(hào)設(shè)備有限公司,杭州 310018)
我國(guó)城市化進(jìn)程不斷加速,城市發(fā)展逐年加快,與此同時(shí),城市交通壓力也在不斷增加,為減輕交通壓力,各大中型城市都在著力發(fā)展公共交通。在現(xiàn)有的主要公共交通手段中,有軌電車(chē)作為一種高效、便捷的公共交通方式,由于其成本相對(duì)較低、建設(shè)周期短,且準(zhǔn)時(shí)性較高、運(yùn)力有保障,故而逐漸受到各大城市的關(guān)注[1]。區(qū)別于高鐵、地鐵等具有獨(dú)立路權(quán)的高運(yùn)力公共交通方式,有軌電車(chē)往往采用混合路權(quán),相對(duì)而言增加了危險(xiǎn)發(fā)生的可能性。目前,有軌電車(chē)主要采用軋道車(chē)、專(zhuān)人定時(shí)巡線(xiàn)與司機(jī)自主防范的方式,盡量確保突發(fā)狀況下的行車(chē)安全。然而,混合路權(quán)情況下,發(fā)生突發(fā)性事件的可能性較高,且當(dāng)突發(fā)狀況產(chǎn)生時(shí),最主要的防范方式依舊是依賴(lài)于司機(jī)的臨時(shí)反應(yīng),所以更加需要一種輔助手段,在危險(xiǎn)發(fā)生前發(fā)出預(yù)警,幫助司機(jī)規(guī)避危險(xiǎn)。此時(shí),一種準(zhǔn)確高效的障礙物檢測(cè)手段便顯得尤為重要。
有軌電車(chē)在途障礙物檢測(cè)研究中,存在著大量有待檢測(cè)與研究的目標(biāo),社會(huì)車(chē)輛構(gòu)成了其重要組成部分。由于目標(biāo)多、場(chǎng)景復(fù)雜、目標(biāo)尺度不統(tǒng)一,且一般都與有軌電車(chē)存在較大的相對(duì)運(yùn)動(dòng)速度,一定程度上增加了目標(biāo)檢測(cè)難度。初期,傳統(tǒng)的基于圖像的障礙物目標(biāo)檢測(cè)手段主要依賴(lài)于人工提取目標(biāo)特征,再對(duì)特征進(jìn)行分類(lèi)。其中,郭磊提出的基于單目雷達(dá)的目標(biāo)檢測(cè)方法,通過(guò)提取目標(biāo)周邊陰影及有效邊緣特征,結(jié)合雷達(dá)檢測(cè)數(shù)據(jù),有效提升識(shí)別準(zhǔn)確率[2]。同時(shí),外國(guó)學(xué)者Jazayeri A等人通過(guò)提取視頻數(shù)據(jù)中的幾何特征并將其連續(xù)投射到一維平面的方式,有效地對(duì)視頻中的運(yùn)動(dòng)物體進(jìn)行概率建模,配合已有的前期場(chǎng)景建模,完成了對(duì)運(yùn)動(dòng)目標(biāo)的實(shí)時(shí)檢測(cè)[3]。Tehrani等學(xué)者也提出了使用HOG特征和SVM分類(lèi)器的在途目標(biāo)檢測(cè)方案[4],該方案能夠同時(shí)兼顧準(zhǔn)確率與檢測(cè)速率,識(shí)別效果相對(duì)優(yōu)異。
然而,在傳統(tǒng)目標(biāo)檢測(cè)手段中,人工提取的特征信息相對(duì)固定,且特征信息往往過(guò)于“潛在”[5],無(wú)法適用于較為復(fù)雜多變的檢測(cè)場(chǎng)景,尤其當(dāng)被檢測(cè)目標(biāo)種類(lèi)較多、尺度變化較大時(shí),檢測(cè)效果將大打折扣。20世紀(jì)80年代以來(lái),卷積神經(jīng)網(wǎng)絡(luò)(CNN)的提出,以及隨后研究者們對(duì)其網(wǎng)絡(luò)結(jié)構(gòu)的不斷優(yōu)化[6],為圖像目標(biāo)檢測(cè)提供了新的解決方案。CNN能夠有效的提取目標(biāo)的“深層次”特征,在復(fù)雜場(chǎng)景下亦能準(zhǔn)確提取有效特征,實(shí)現(xiàn)目標(biāo)檢測(cè)[7-8]。其中,劉敦強(qiáng)采用多尺度預(yù)測(cè)分支的方式,對(duì)Faster R-CNN網(wǎng)絡(luò)進(jìn)行了優(yōu)化,提升了網(wǎng)絡(luò)對(duì)特征數(shù)據(jù)的挖掘能力,從而大幅提升了網(wǎng)絡(luò)的檢測(cè)精度[9]。王宇寧以道路監(jiān)控視頻為樣本,采用YOLO卷積神經(jīng)網(wǎng)絡(luò)對(duì)其進(jìn)行識(shí)別分類(lèi),準(zhǔn)確率可達(dá)89.3%。準(zhǔn)確率提升的同時(shí),CNN的目標(biāo)檢測(cè)速率也在不斷提升[10]。為了解決CNN普遍存在的檢測(cè)速率較慢問(wèn)題,卞山峰采用目標(biāo)框維度聚類(lèi)優(yōu)化等方式,對(duì)YOLO v2卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)進(jìn)行了優(yōu)化,在保證準(zhǔn)確率的同時(shí)極大程度提升了該網(wǎng)絡(luò)的檢測(cè)速率。經(jīng)實(shí)驗(yàn)驗(yàn)證,優(yōu)化后的網(wǎng)絡(luò)模型可以做到實(shí)時(shí)檢測(cè)樣本視頻中的待檢測(cè)目標(biāo)[11]。
可以發(fā)現(xiàn),CNN對(duì)有軌電車(chē)行車(chē)過(guò)程中可能遇到的多目標(biāo)及復(fù)雜場(chǎng)景均有一定的魯棒性。因此,本文旨在利用YOLO v3卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)特點(diǎn),通過(guò)對(duì)其網(wǎng)絡(luò)結(jié)構(gòu)的優(yōu)化,使其更加契合有軌電車(chē)障礙物檢測(cè)使用場(chǎng)景,從而提出一種基于YOLO v3的有軌電車(chē)在途障礙物檢測(cè)方法。
1 方法提出
1.1 YOLO v3卷積神經(jīng)網(wǎng)絡(luò)介紹
YOLO v3卷積神經(jīng)網(wǎng)絡(luò),沿用了目前性能較為優(yōu)異的DarkNet網(wǎng)絡(luò)架構(gòu)[12],并使用結(jié)構(gòu)更為復(fù)雜的DarkNet-53模型替代了原有的DarkNet-19模型。由于網(wǎng)絡(luò)結(jié)構(gòu)更為復(fù)雜,故而可以提取到更深層次的特征信息,增加準(zhǔn)確率[13-14]。同時(shí),該網(wǎng)絡(luò)引入了多尺度預(yù)測(cè)的概念,通過(guò)先驗(yàn)框在3個(gè)不同尺度上對(duì)樣本進(jìn)行采樣,大幅降低了網(wǎng)絡(luò)的漏檢率,提升網(wǎng)絡(luò)對(duì)不同尺度的指定目標(biāo)的識(shí)別準(zhǔn)確度。其主要網(wǎng)絡(luò)結(jié)構(gòu)如圖1所示[15]。

圖1 YOLO v3網(wǎng)絡(luò)結(jié)構(gòu)示意Fig.1 Schematic diagram of YOLO v3 network structure
如圖1可見(jiàn),該結(jié)構(gòu)主要采用1×1和3×3兩種形式的卷積核對(duì)樣本做特征采樣,輸出時(shí),有3種不同特征尺度,分別為8倍、16倍和32倍,低倍率采樣特征會(huì)向上進(jìn)行上采樣,以防止特征信息丟失,從而保證網(wǎng)絡(luò)可以對(duì)不同尺度特征進(jìn)行提取的同時(shí),識(shí)別率同樣能得到保證。并且,由于使用DarkNet-53模型替代了原有的DarkNet-19模型,模型深度更深,為防止梯度丟失,模型中加入了多個(gè)殘差模塊,以確保檢測(cè)的準(zhǔn)確度。區(qū)別于之前版本的網(wǎng)絡(luò),YOLO v3的Convolutional由卷積層、BN層和LeakyReLU層構(gòu)成[16]。
1.2 YOLO v3的損失函數(shù)
YOLO v3的核心網(wǎng)絡(luò)架構(gòu)從屬于DarkNet-53模型,一般而言,其損失函數(shù)由以下兩部分構(gòu)成。
1)置信度損失模塊:即計(jì)算先驗(yàn)框內(nèi)包含被檢測(cè)目標(biāo)的概率,若概率大于某一既定閾值,則認(rèn)為其中包含被檢測(cè)目標(biāo)。否則認(rèn)為先驗(yàn)框內(nèi)僅包含背景信息。
2)類(lèi)別損失模塊:為防止由于某一特征同時(shí)從屬于兩種類(lèi)別時(shí),產(chǎn)生的錯(cuò)誤預(yù)判,YOLO v3使用二分類(lèi)的交叉熵公式,計(jì)算損失值,其公式(1)如下:

通過(guò)使用公式(1),將原有的類(lèi)別鑒別問(wèn)題轉(zhuǎn)化為一個(gè)二分類(lèi)問(wèn)題,從而有效降低網(wǎng)絡(luò)的漏檢率。
1.3 損失函數(shù)優(yōu)化
目標(biāo)位置判斷是目標(biāo)檢測(cè)的重要功能之一,同時(shí)對(duì)有軌電車(chē)障礙物檢測(cè)具有重要意義。檢測(cè)到目標(biāo)后,需要判定目標(biāo)邊緣與軌行區(qū)域是否重合,從而預(yù)測(cè)該目標(biāo)是否會(huì)對(duì)行車(chē)構(gòu)成威脅。因此,對(duì)損失函數(shù)的優(yōu)化,不僅能夠提升網(wǎng)絡(luò)檢測(cè)能力,亦能夠增強(qiáng)本方法對(duì)司機(jī)的輔助能力。
假設(shè),某一樣本圖片包含一個(gè)待檢測(cè)目標(biāo),在標(biāo)注過(guò)程中,針對(duì)該目標(biāo)人工標(biāo)定給出的準(zhǔn)確位置信息為A。網(wǎng)絡(luò)訓(xùn)練過(guò)程中,網(wǎng)絡(luò)某次迭代完成后,網(wǎng)絡(luò)通過(guò)公式(1)計(jì)算后得到該目標(biāo)的最可信位置信息為B,A與B之間存在著一定的位置誤差,即A與B并非完全重合。那么,在YOLO v3網(wǎng)絡(luò)中,會(huì)使用IoU值來(lái)描述該誤差,IoU可由公式(2)表示:

可以看出,IoU的值越大,則B與A的契合程度就越高,網(wǎng)絡(luò)的檢測(cè)準(zhǔn)確度就越高。一般而言,在網(wǎng)絡(luò)訓(xùn)練過(guò)程中,隨著迭代次數(shù)的不斷增大,IoU會(huì)逐漸趨近于某一穩(wěn)定的最佳數(shù)值。然而,公式(2)僅描述了A與B的重合面積,并未描述A與B的重疊方式,容易導(dǎo)致訓(xùn)練過(guò)程中,收斂速度慢,邊框位置不準(zhǔn)確等問(wèn)題。
為盡量減少該問(wèn)題發(fā)生,本文引入了新的IoU計(jì)算方法[17],用以?xún)?yōu)化IoU數(shù)值的求取過(guò)程,其數(shù)值可由公式(3)表示:

其中,NIoU表示經(jīng)本文引入的方法優(yōu)化后的IoU值,C表示同時(shí)包含A與B的最小閉合區(qū)域的面積。由于引入了最小閉合區(qū)域C,NIoU可以更好的描述A與B的重合度以及重疊方式,從而增加最終輸出位置結(jié)果的準(zhǔn)確性。
2 實(shí)驗(yàn)驗(yàn)證
2.1 數(shù)據(jù)集準(zhǔn)備
為驗(yàn)證網(wǎng)絡(luò)的適用性以及優(yōu)化后的網(wǎng)絡(luò)性能是否有所提升,使用車(chē)載視覺(jué)傳感器在天水有軌電車(chē)T1線(xiàn)現(xiàn)場(chǎng)采集了10 000幀有軌電車(chē)運(yùn)行視頻。其中,約9 500幀圖片包含待識(shí)別目標(biāo)(暫時(shí)選用社會(huì)車(chē)輛作為識(shí)別目標(biāo))。選用其中隨機(jī)9 000張作為樣本,剩余1 000張作為測(cè)試樣本,分別采用官網(wǎng)給出的YOLO v3網(wǎng)絡(luò)模型和優(yōu)化后的YOLO v3網(wǎng)絡(luò)(簡(jiǎn)稱(chēng)NYOLO)做對(duì)比測(cè)試。訓(xùn)練過(guò)程中,為契合有軌電車(chē)車(chē)載硬件條件,選取TensorFlow-1.13.1-gpu作為網(wǎng)絡(luò)搭建平臺(tái)[18],設(shè)置batch_size為6,迭代次數(shù)為10 000次。
2.2 實(shí)驗(yàn)結(jié)果
使用兩種網(wǎng)絡(luò)分別對(duì)樣本進(jìn)行學(xué)習(xí)后,使用測(cè)試集做對(duì)比測(cè)試,測(cè)試結(jié)果如表1所示。
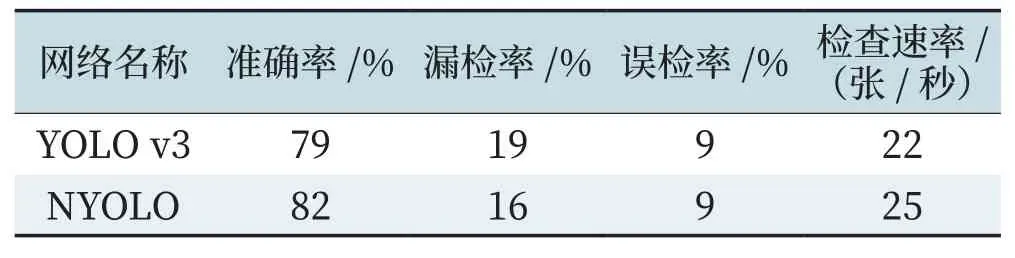
表1 優(yōu)化后YOLO v3網(wǎng)絡(luò)與原網(wǎng)絡(luò)識(shí)別效率對(duì)照Tab.1 Comparison table of the identification efficiency between optimized YOLO v3 network and original network
其識(shí)別效果如圖2所示。

圖2 優(yōu)化后的YOLO v3網(wǎng)絡(luò)障礙物識(shí)別效果Fig.2 Optimized obstacle identification effect diagram of YOLO v3 network
如表1與圖2所示,優(yōu)化后的網(wǎng)絡(luò)能很好的描繪目標(biāo)邊緣,對(duì)于重疊目標(biāo)也有一定的分辨能力,是一種較為適用的網(wǎng)絡(luò)模型。由于采用了優(yōu)化的損失評(píng)價(jià)函數(shù),一定程度上提升了網(wǎng)絡(luò)識(shí)別準(zhǔn)確率和識(shí)別效率。但是,整體而言網(wǎng)絡(luò)的識(shí)別準(zhǔn)確率在80%左右,數(shù)值相對(duì)較低,主要原因是車(chē)載視覺(jué)傳感器成像質(zhì)量不佳造成的。后期可通過(guò)更換高清攝像頭,或?qū)υ紙D片做增強(qiáng)處理等手段提高識(shí)別準(zhǔn)確率。同時(shí),由于現(xiàn)場(chǎng)天氣狀況多變,亦可加入一定的除霧等預(yù)處理手段,以確保識(shí)別率穩(wěn)定。
3 結(jié)語(yǔ)
本文以YOLO v3卷積神經(jīng)網(wǎng)絡(luò)為基礎(chǔ),提出一種有軌電車(chē)在途障礙物檢測(cè)方法,并通過(guò)對(duì)YOLO v3網(wǎng)絡(luò)結(jié)構(gòu)的優(yōu)化,提升網(wǎng)絡(luò)的識(shí)別能力,得出以下主要結(jié)論:
1) 對(duì)比官網(wǎng)YOLO v3網(wǎng)絡(luò)和優(yōu)化后YOLO v3網(wǎng)絡(luò),發(fā)現(xiàn)優(yōu)化后的YOLO v3網(wǎng)絡(luò)在準(zhǔn)確率及漏檢率都有大幅的提升和降低;
2) 實(shí)驗(yàn)證明YOLO v3網(wǎng)絡(luò)具有較好的適用性和魯棒性,是一種較優(yōu)的有軌電車(chē)在途障礙物檢測(cè)方法。
猜你喜歡
房地產(chǎn)導(dǎo)刊(2022年5期)2022-06-01 06:20:14
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
建材發(fā)展導(dǎo)向(2021年12期)2021-07-22 08:06:48
建材發(fā)展導(dǎo)向(2021年7期)2021-07-16 07:07:52
中學(xué)生數(shù)理化(高中版.高二數(shù)學(xué))(2021年12期)2021-04-26 07:43:48
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
