改進的YOLOv4 紅外圖像行人檢測算法
2021-12-01 05:26:12史健婷張貴強吳林皓
智能計算機與應用 2021年8期
史健婷,張貴強,陶 金,吳林皓
(1 黑龍江科技大學 計算機與信息工程學院,哈爾濱 150022;2 黑龍江科技大學 研究生學院,哈爾濱 150022)
0 引言
行人檢測技術結合了數字圖像處理、模式識別、計算機視覺和其他相關技術,無論是在智慧交通,還是在自動駕駛、人體行為分析等領域有著廣闊的發展前景[1]。行人檢測技術,是研究和判斷所給的圖像或在每幀視頻序列中,是否存在要檢測的行人目標。近年來,道路安全問題頻繁發生,在尋找降低交通事故發生方法的同時,行人檢測技術也受到人們的廣泛關注[2-3]。
行人檢測算法可分為傳統的算法和基于深度學習的算法。傳統的行人檢測算法有:Haar 小波特征[4]、HOG+SVM[5]、DPM[6]等等。傳統的行人檢測主要通過人工設計方法,對圖像特征進行提取,進行目標識別和檢測,但算法設計復雜,權值參數難以得到較準確的數值,泛化能力不強。
基于深度學習的算法,如卷積神經網絡(Convolutional Neural network,CNN)[7],通過大量的數據,能自動學習出目標的原始表征,相較于手工設計的特征而言,具有更強的判別能力和泛化能力[8]。之后出現了一系列改進算法,包括Fast RCNN[9-11]、Faster RCNN[12]、SSD[13]、YOLO[14]等算法。其中,YOLOv4網絡結構簡單高效,具有易部署、運用場景廣泛的特性。特別是針對紅外圖像下的小目標檢測,有很大的應用前景[15]。雖然YOLOv4 網絡采用多尺度進行預測,能夠結合更好的分類器,但是還存在識別物體的精準性差、召回率低等缺點。因此,本文對YOLOv4 算法進行了改進。通過與原YOLOv4 算法進行比較,將對紅外圖像行人的檢測精準度(MAP)提高了0.04%。
1 YOLOv4 算法
1.1 YOLOv4 網絡結構
YOLOv4 算法以CSPDarknet53 作為主干網絡,在采用ResNet 短跳連接的同時,增加輸入輸出的維度拼接,更好的實現了深淺層特征的結合,在主干網絡的頂端,加入了SPP 模塊。采用1?1、5?5、9?9、13?13 最大池化的方式,進行多尺度特征融合。該模塊和PAN 結構相結合,使分辨率為76?76 的淺層特征向上傳播,保證每個檢測頭都可以接受淺層特征,極大的增加了網絡對小目標特征的表達能力。YOLOv4 的網絡結構如圖1 所示。

圖1 YOLOv4 網絡結構圖Fig.1 YOLOv4 network structure diagram
除了對主干網絡的改進之外,YOLOv4 還引入了其它tricks 來提升網絡性能。在激活函數方面,引入Mish激活函數,如公式(1)所示:

函數圖像如圖2 所示。

圖2 Mish 激活函數圖像Fig.2 Mish activation function
可以看出,Mish激活函數在x =0 處也是光滑可導的,具有較好的泛化能力和結果的有效優化能力。在數據增強方面,采用Mosaic 數據增強方式,對多張圖片以隨機縮放、隨機剪裁和隨機排布的方式進行拼接,大大豐富了數據集,可以讓網絡直接計算多張圖片的數據,增加模型泛化能力。

式中:D2表示預測框和目標框中心點距離,DC為最小外接矩形C的對角線距離。
1.2 注意力機制
注意力機制(Attention Mechanism)在文本分析、行人檢測、外界語音處理等方面有廣泛的使用。注意力機制就像人類注意力觀察一樣,通過相應的空間、通道等方面,從軟注意力和強注意力兩方面進行分析和處理。
2017 年,Jie Hu 等人通過研究,提出了一種新的框架結構——SENet(Squeeze- and- Excitation Network,即“壓縮和激勵”SE 塊)。SENet 通過加強所要研究的重要區域,把所要輸入的圖像進行卷積,然后得到feature map 進行分析,設計出一個一維向量,作為分數來進行評價。與所要研究的圖像通道一樣,該向量的每個評價分數采用乘法加權方式,得到原通道的大小,這樣處理提高了研究的重要區域。SE 模塊的結構圖如圖3 所示。

圖3 SE 模塊結構圖Fig.3 Se module structure diagram
2 改進的YOLOv4 紅外行人檢測算法
在YOLOv4 中,主要采用3x3 大小的標準卷積進行特征提取操作。標準卷積由于其感受野的形狀和大小均為固定,在對小目標進行檢測時,同樣會對非目標區域進行特征提取操作,會導致最后卷積所提取到的特征中干擾因素較多,對檢測器的預測造成較多的干擾影響。因此,基于YOLOv4 的標準卷積思想,利用形變卷積為核心組件,構建形變特征提取模塊,提升對于目標特征提取的有效性。
形變卷積與標準卷積相比,具有3 點優勢:
(1)感受野有效性的提升,即特征圖在映射目標信息時針對性更高;
(2)卷積核能夠適配目標位置進行采樣,所提取到的特征信息與目標更匹配;
(3)由于形變卷積經過特征提取時,能夠有效針對目標所在區域進行提取,使得特征圖在網絡中傳遞時,其穩定性(即權值參數不會突變)優于標準卷積。
形變卷積與標準卷積在進行特征提取操作時的區別如圖4 所示。

圖4 形變卷積與標準卷積特征提取對比Fig.4 Comparison of feature extraction between deformation convolution and standard convolution
為了增強對于目標位置信息的復用,針對YOLOv4 的注意力機制思想,在每個尺寸的特征圖,經由形變特征提取模塊組后,加入Coordinate 坐標注意力機制模塊,對坐標信息進行加強。Coordinate坐標注意力機制模塊基于SE 通道注意力機制進行優化,提取出了特征圖橫向與縱向的特征權值信息,再通過聚合,以達到精確的目標位置坐標顯著性標記。Coordinate 坐標注意力機制模塊結構如圖5 所示。

圖5 Coordinate 坐標注意力機制模塊Fig.5 Coordinate attention mechanism module
在圖5 中,模塊的工作流程主要分為兩步:一是提取特征圖上X軸與Y軸的特征信息;二是對提取的特征信息進行激活加權。首先,輸入到模塊的特征圖由全局池化分解出兩個方向上的一維特征,該過程基于SE注意力機制壓縮操作進行優化。
標準全局池化計算過程為:
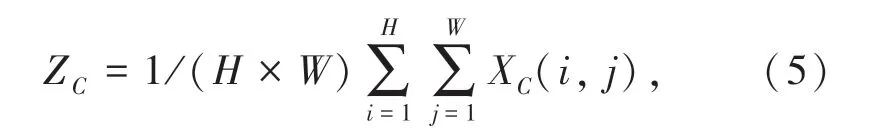
式中:Zc為全局池化輸出;H為特征圖的高;W為特征圖的寬;Xc為全局池化輸入。
Coordinate坐標注意力機制則將全局池化分解為:

完成分解后,再對兩個方向的特征圖進行聚合,以此獲得帶有坐標信息的特征圖。之后,將該特征圖分別由兩個二維卷積進行特征提取與激活加權計算,得到兩個坐標方向的加權特征信息。將該特征信息映射到特征圖中,即可反映目標在特征圖中的坐標信息。
對于影響網絡定位準確性的因素,最直觀的表現為YOLOv4 檢測器中的anchors 組件。檢測器通過anchors 判定目標是否存在及目標的位置,即anchors 能夠對特征圖的某個區域是否存在目標進行判定,同時預測目標位置。由于目標的形態大小具有不確定性,即通過手動設定的anchors 尺寸無法準確適配目標的位置,致使在檢測時存在一定的偏差。為優化anchor 的定位準確性,在YOLOv4 檢測層中加入“Guided Anchoring”機制,通過網絡自適應生成anchors,來提高anchors 及候選區域的質量。
不同于常規anchors 操作,在一個坐標點上對一組anchor 的尺寸進行預測并挑出最符合大小的一個,其值對一個anchor 的尺寸進行預測,使得對于不規則目標的擬合性更強,召回率也更高。本文設計的網絡命名為YOLO-sd。
3 實驗結果與分析
本設計實驗環境配置為:軟件層次上,操作系統為Ubuntu 18.04,神經網絡框架為Darknet,CUDA 版本為10.0,cuDNN 加速包為7.6.4;在硬件層次上主要使用了RTX2080ti 型號的GPU 進行卷積計算加速。
關于紅外行人檢測算法評價的相關性能指標包括:交并比IOU、精度(precision)、召回率(recall)等。

式中:S1為紅外圖像預測的行人區域;S2為標注的行人區域;TP為紅外圖像下行人區域,預測為行人正確情況;FN為紅外圖像下行人區域,預測為不是行人錯誤情況;FP為實際不是行人區域,但是預測此區域有行人情況。
所采用的數據集來自OSU Thermal Pedestrian Database,通過數據清洗、預處理等操作,構成2 100張訓練集和500 張的測試集。將改進后的模型YOLO-sd 與YOLOv3、YOLOv4 以及SSD 算法進行對比測試,測試結果見表1。

表1 模型檢測性能對比Tab.1 Performance comparison of models
通過對比結果可以看出,本文提出的YOLO-sd算法,整體魯棒性要優于YOLOv3 和YOLOv4;在召回率的對比中,YOLO-sd 優于YOLOv3 和YOLOv4,說明對于目標的查全率更好,且IOU數值也更優。YOLO-sd 與SSD 對比,YOLO-sd 的精度、平均準確率(map)、F2-1Score 要優于SSD;其它指標,召回率和交并比略低于SSD,綜合反映了對于主干網絡及檢測網絡部分的優化,在提升網絡性能方面有巨大幫助。網絡優化性能pr 曲線如圖6 所示。

圖6 pr 曲線對比Fig.6 Comparison of PR curves
利用YOLO-sd 的實際測試結果如圖7 所示。

圖7 測試結果Fig.7 Test result
4 結束語
本文提出了一種基于YOLOv4 改進的紅外圖像行人檢測算法YOLO-sd,優化后的YOLO-sd 針對于灰度圖及小目標的檢測能力有明顯提升,提高了紅外檢測的實用性。該算法主要應用于低像素及小目標的檢測環境,主要采用形變卷積為核心組件,構建形變特征提取模塊提升對于目標特征提取的有效性,同時針對于形變卷積對特征提取網絡模塊進行優化,增強了特征信息的傳遞能力。經測試,優化后的YOLO-sd 在針對于紅外小目標的檢測場景下檢測精度有明顯的提高。整體精度提升1.05%,達到83.09%。本文的網絡對于夜間來往的行人、駕駛的車輛來說,有輔助參考價值,有助于提高安全性。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
海峽科技與產業(2016年3期)2016-05-17 04:32:12
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
