基于XLNet-BiLSTM 的中文電子病歷命名實體識別方法
2021-12-01 05:26:30沈宙鋒蘇前敏郭晶磊
智能計算機與應用 2021年8期
沈宙鋒,蘇前敏,郭晶磊
(1 上海工程技術大學 電子電氣工程學院,上海 201620;2 上海中醫藥大學 基礎醫學院,上海 201203)
0 引言
電子病歷(EMR,Electronic Medical Record)是計算機信息系統存儲、管理和傳輸的醫療記錄,包含醫務人員在為患者診療過程中記錄的關于患者病史、臨床表現、治療方法等數字化信息[1]。由于電子病歷大多是半結構化和非結構化的狀態,對其進行分析處理和數據挖掘受到嚴重制約。命名實體識別(named entity recognition,NER)是發現和識別自然文本中的專有名詞和有意義的詞語,并將其歸類到預定義的類別中,是自然語言處理(natural language processing,NLP)任務中的一項重要分支[2]。運用命名實體識別技術對電子病歷文本進行分析研究,目的是自動地識別并且分類電子病歷中的醫療命名實體。
傳統的電子病歷命名實體識別研究主要分為基于規則和基于機器學習兩種方法,基于規則的方法主要依靠領域專家構建的領域詞典進行識別,對于詞典中沒有出現的實體通過手工編輯的規則來識別醫療命名實體[3]。由于詞典構建和規則制定對領域專家的依賴性,基于機器學習電子病歷命名實體識別的方法被廣泛運用。近年來深度學習在語音識別、圖像識別和視頻分析等多個領域取得了重大進展,大量研究人員將深度學習運用到電子病歷實體識別領域,通過在大規模的標注數據中訓練與學習,可以更好地抽取上下文語義特征進行表示[4]。
基于深度神經網絡的命名實體識別方法,都需要通過詞嵌入方法將文本信息轉換成序列化向量,目前比較流行的詞嵌入方法是2013 年由Mikolov 等提出的Word2Vec,將傳統的詞的one-hot 表示轉換為低緯、稠密的向量,每個詞都由數十或數百個維度的實值向量表示[5]。但是Word2vec 訓練的詞向量是靜態的,即同樣的字在不同的語句中向量表示都是不變的,也就無法獲取相同詞匯的多種含義,且不能在訓練過程隨上下文來消除詞義的歧義[6]。電子病歷中通常存在一詞多義現象,如“疾”這個字在不同的詞語中意義不同,既可以是名詞疾病,也可以是形容詞劇烈;近年來,針對以上問題,學術界提出了許多與上下文有關的詞嵌入表示方法,比如ELMO(embeddings from language models)方法和OpenAI-GPT(generative pre-training)方法[7]。但是,上述兩種語言模型的語言表示都是單向的,無法同時獲取前后兩個方向電子病歷文本的語義信息。
為了解決上述問題,本研究擬采用雙向自回歸預訓練語言模型XLNet 引入電子病歷NER 任務中,提出了XLNet-BiLSTM-MHA-CRF 命名實體識別模型,并利用該模型對醫療電子病歷中預定義的疾病、癥狀、治療、檢查、身體部位5 類實體進行命名實體識別。實驗證明,使用預訓練語言模型構建詞嵌入,并在BiLSTM-CRF 中加入多頭注意力機制,多角度的提取文本特征,有效提高了命名實體識別的效果。本文所述算法在ccks2017 命名實體識別任務中取得F1 值為91.74%。
1 XLNet-BiLSTM-Attention-CRF 命名實體識別模型
XLNet-BiLSTM-MHA-CRF 命名實體識別模型的整體結構如圖1 所示。模型第一層為XLNet 詞嵌入層,通過XLNet 預訓練語言模型,運用低維的字向量對病歷中的每一個字進行表示,得到序列化文本輸入;第二層是BiLSTM 層,利用雙向長短時記憶神經網絡自動提取句子的前向特征和后向特征進行拼接輸入下一層;第三層是MHA 層,通過計算多角度的注意力概率獲得句子的長距離依賴特征,得到新的特征向量;第四層是CRF 層,通過計算對輸入的文本特征進行序列標注,輸出最優標簽。
1.1 XLNet 預訓練語言模型
XLNet 模型是CMU 與谷歌團隊在2019 年提出的一個基于Bert 優缺點的廣義自回歸預訓練方法,在傳統的自回歸語言模型上實現了雙向預測[8]。通過在transformer 模塊內部使用attention mask 方法得到輸入文本不同的排列組合,讓模型充分提取上下文信息進行訓練,克服了Bert 模型在Mask 機制下的有效信息缺失。XLNet 的掩碼機制示例如圖2所示,當模型輸入句子為[糖,尿,病,患,者],隨機生成的一組序列為[病,糖,患,者,尿],那么在計算重排列后的“糖”字來說就可以利用到“病”字的信息,所以在第一行只保留了第三個位置的信息(用實心表示),其他的位置的信息被遮掉(用空心表示)。再比如重排后的“尿”字位于最后一個位置,其余四字的信息都可以利用,即第二行除第二個位置外全部以實心表示。

圖2 XLNet 模型掩碼機制示例圖Fig.2 XLNet model mask mechanism example diagram
現有的預訓練語言模型大多數采用transformer架構,但是在捕捉長距離依賴關系上還存在不足[9]。為了解決這樣的問題,XLNet 采用引入循環機制(RNN)和相對位置編碼的transformer-xl 架構。通過RNN 提取上一片段隱狀態長距離依賴信息,存儲在片段之間的memory 單元,供下一片段的預測使用,充分捕捉長距離文本特征。片段之間的信息傳遞方式如圖3 所示,虛線框中表示前一片段提取的記憶信息,通過memory 單元傳遞給下一片段,實現了信息的傳遞。
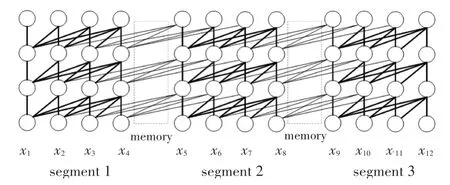
圖3 XLNet 循環機制片段信息傳遞圖Fig.3 XLNet cycle mechanism fragment information transfer diagram
在位置編碼方面,采用相對位置編碼替代絕對位置編碼,解決詞的多義性問題,增強文本特征提取的完整性,加入相對位置編碼后的self-attention 公式(1)如下:

其中,Exi,Exj分別表示i,j的文本向量;W代表權重矩陣;Ri-j代表i,j的相對位置;uT,vT是需要學習的參數;Wk,E,Wk,R分別為學習到基于內容的key向量和基于位置的key向量。
基于transformer-xl 的XLNet 預訓練語言模型,通過attention mask、循環機制和相對位置的編碼,克服了自回歸語言模型單項傳遞信息的不足,充分利用上下文的語義信息提取潛在的內部關系,訓練出特征更加完整的詞向量表示。
1.2 雙向長短時記憶網絡(BiLSTM)模型
針對傳統的循環神經網絡(RNN)在處理序列標注問題時出現梯度消失和梯度爆炸的現象,Hochreiter 和Schmidhuber 在1997 年提出長短時記憶網絡(long short term memory,LSTM)[10],該網絡是在RNN 的基礎上的改進,其單元結構如圖4 所示。通過設置遺忘門、輸入門和輸出門3 種門限機制看,選擇性的處理信息的遺忘和傳遞,以此來捕獲文本序列長距離依賴信息,有效解決了梯度消失的問題[11]。
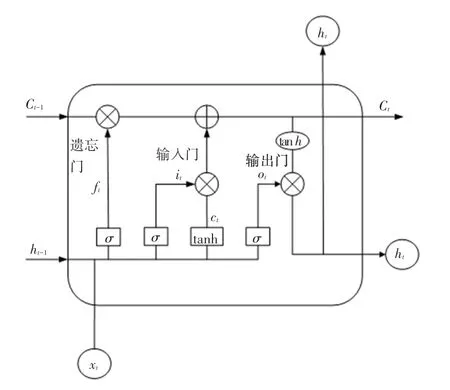
圖4 LSTM 單元結構圖Fig.4 LSTM unit structure diagram
LSTM 網絡一個單元的隱藏層運算過程如式(2)~式(7)所示:
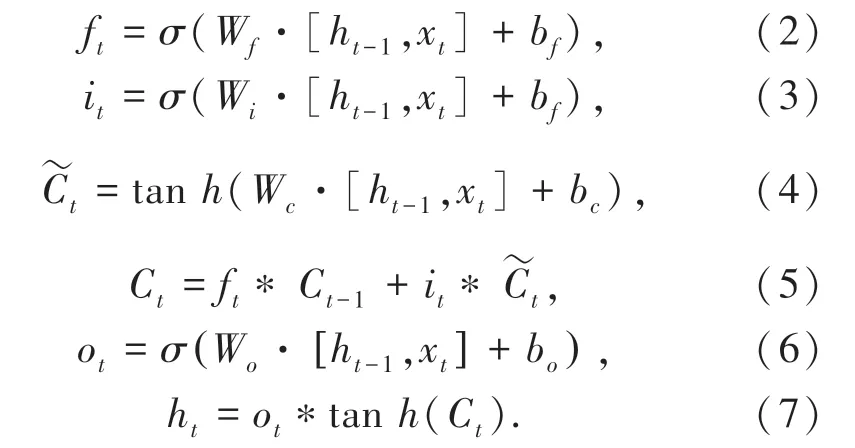
其中,ft、it、ot和Ct分別表示t時刻的遺忘門、輸入門、輸出門和記憶細胞;σ是sigmoid激活函數,tanh是雙曲正切激活函數;W、b分別表示連接兩層的權重矩陣和偏置向量;xt為輸入向量,ht-1為t-1時刻的輸出;ht則為t時刻的輸出;表示中間狀態。
由于LSTM 只能處理當前單元之前的信息而無法獲得之后的信息,于是提出雙向長短時記憶網絡,就是采用兩層LSTM,分別獲取文本序列的前向信息和后向信息進行拼接得到最終的隱藏層特征表示,充分捕捉上下文語義信息,有效提高命名實體識別的效果。
1.3 多頭注意力(MHA)模型
2017 年谷歌機器翻譯團隊將多個自注意力進行結合創造性提出多頭注意力模型(multi-head attention model)[12],具體結構模型如圖5 所示。將文本序列X =(X1,X2…,Xn)輸入BiLSTM 層,輸出的矩陣Y =(Y1,Y2,…,Yn)作為Q、K、V 的輸入,放縮點積注意力(scaled dot-product attention)單元共有h層,每一層的注意力計算如式(8)所示;將h個單頭注意力輸出進行拼接,同時做一個線性變換如式(9),得到的MHA為第t個字的h頭注意力權重輸出。多頭注意力模型在NER 任務中可以充分捕捉句子的長時序依賴關系,獲取全局特征。

圖5 多頭注意力模型Fig.5 The model of Multi-head attention

1.4 條件隨機場(CRF)模型
Lafferty 在2001 年提出線性條件隨機場(CRF)模型,計算給定隨機變量序列X =(X1,X2…,Xn)的條件下,隨機變量序列Y =(Y1,Y2,…Yn)的條件概率分布P(Y |X)[13]。模型假設隨機變量序列滿足馬爾可夫性,式(10):

式中,X表示輸入觀測序列,Y表示對應的狀態序列。
在電子病歷命名實體識別任務中,每個字的標簽與其相鄰的標簽都存在制約關系,例如O 標簽后面不會是I 標簽,I-DIS 不會跟B-BOD 后面。CRF能夠根據前一層網絡的輸出結果,結合上下文語義標簽信息得到每個字對應的標簽序列出現的最優概率。
設MHA 模型的輸出序列為X,其中一個預測序列為Y,則可以得出評估分數S(X,Y),式(11):

式中:Myi,yi+1表示從yi標簽到yi+1標簽的轉移概率;Pi,yi表示第i個字被標記為yi的概率;n為序列長度。
最后采用極大似然法求解最大后驗概率P(y |x),獲得模型的損失函數值,式(12):

2 實驗及結果分析
2.1 試驗數據與標注策略
本次實驗選取的是ccks-2017 任務二中400 份醫療標注數據作為數據集,并按照7 ∶2 ∶1 的方式分為訓練集、測試集、預測集。該數據集共包括39 539個實體,分為癥狀、疾病、治療、檢查、身體部位5 類,共7 183句話。本文采用BIOE 的標注方式,即B 代表實體首字;I 代表實體中間部分;E 代表實體尾字;O 代表該字不屬于規定的實體類別。各類別實體符號及數量見表1。

表1 醫療實體標注符號Tab.1 Medical entity notation
2.2 評價指標
實體識別和關系抽取實驗通常采用準確率、召回率和F1 值指標評價模型的優劣:

其中:TP表示測試集中的正例被正確預測為正例的個數;FP表示測試集中的負例被誤分類為正例的個數;FN表示測試集中的正例被誤分類為負例的個數。
2.3 實驗環境與參數設置
本文實驗的命名實體識別模型基于TensorFlow框架,具體實驗環境設置見表2。

表2 實驗環境Tab.2 Experimental environment
實驗參數具體設置:BiLSTM 模型的隱藏層大小為128,網絡層數為1,選取Relu 作為模型的激活函數。在訓練階段將Dropout 的比例設置為0.1,批次大小設置為16,最大序列長度為128,學習率設置為1e-5,丟失率為0.1,使用Adam 優化器進行訓練。
2.4 實驗結果分析
為了驗證本文提出XLNet-BiLSTM-MHA-CRF模型的性能,將其和以下3 組模型進行對比:
(1)BiLSTM-CRF 模型;
(2)Bert-BiLSTM-CRF 模型;
(3)XLNet-BiLSTM-CRF 模型。
不同模型的實驗對比結果見表3,可以看出XLNet-BiLSTM-MHA-CRF 模型的精確率、召回率和F1 值在癥狀、疾病、治療、檢查、身體部位5 類醫療實體上都是最高的,相比于BiLSTM 基線模型分別提高了3.46%、1.14%、2.31%。
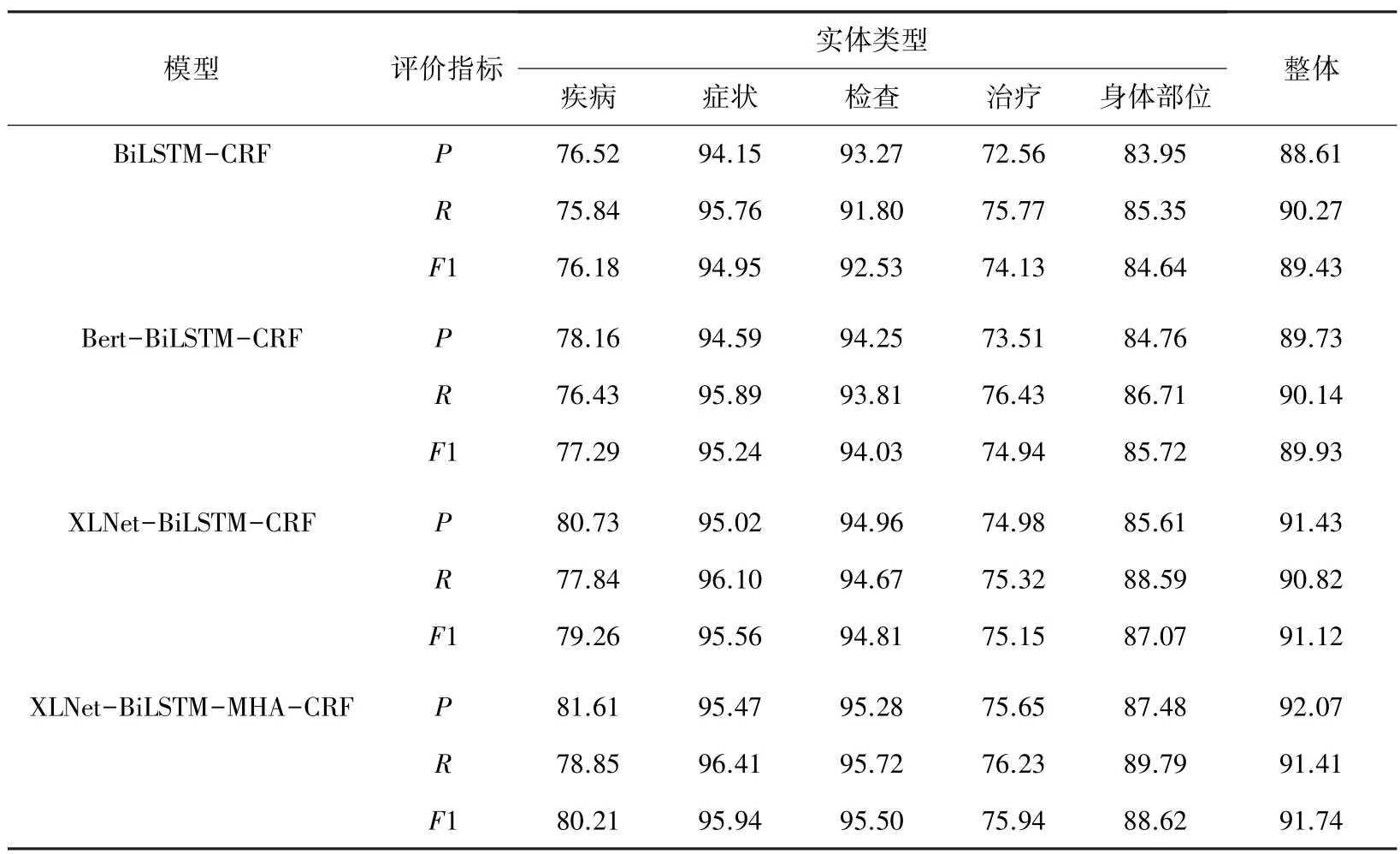
表3 各模型實驗對比結果Tab.3 The results of each model experiment were compared
在所有模型中,癥狀、檢查和身體部位3 個醫療實體的F1 值普遍較高,而疾病和治療的實體識別F1 值恰恰相反。通過分析發現這兩個類別的訓練數據量明顯過少,導致在模型訓練過程中出現嚴重的過擬合現象;另外,疾病實體和治療實體多為長詞結構,例如“左眼眶軟組織裂傷”、“左橈骨遠端骨折切開復位內固定術”等,而癥狀、檢查和身體部位的實體結構簡單且訓練數據量大,模型可以充分學習該類實體的文本特征。因此,在后期對電子病歷的實體識別中可以通過增加語料庫來提高模型的精度,同時可以進一步研究長詞實體的結構,挖掘更深層次的語義信息,例如引入詞典信息來增加語義特征,提高模型的泛化能力。
各模型實驗結果對比如圖6 所示。明顯可以看出,基于預訓練語言模型XLNet 和Bert 的模型的表現均比BiLSTM-CRF 模型的效果要好,主要是因為后者使用的是傳統的Word2vec 獲取的詞向量,無法解決一詞多義和同一詞的問題,同時也證明了預訓練語言模型構造的動態詞向量可以提高文本內在語義信息的表達能力;通過對比發現XLNet-BiLSTMCRF 模型比基于Bert 的模型表現高0.5%~2%,主要是因為XLNet 通過attention mask 和transformerxl 模塊彌補了Bert 的不足,導致識別效果的提升。本文提出的模型相比XLNet-BiLSTM-CRF 模型在精確率、召回率和F1 上面均有小幅提升,說明加入多頭注意力機制可以使文本信息表示更加完整。

圖6 各模型實驗結果對比圖Fig.6 Comparison of experimental results of each model
3 結束語
本文提出XLNet-BiLSTM-MHA-CRF 的醫療電子病歷命名實體識別模型,使用預訓練語言模型向量,在大規模語料中訓練得到的動態詞替代傳統的靜態詞向量,對電子病歷進行序列化表示,有效解決一詞多義等問題,讓上下文的語義表示更加準確;使用廣義自回歸預測模型XLNet 可以有效彌補Bert模型的不足;加入MHA 機制可以捕獲電子病歷文本中的長距離依賴特征。在ccks2017任務二數據集中實驗結果表明,基于XLNet-BiLSTM-MHACRF 模型F1 值為91.64%,相較于其他模型達到較好的識別效果,能夠較好地完成醫療電子病歷的命名實體識別任務,對醫學領域的實體識別研究具有一定參考價值。由于本實驗數據僅有400 份電子病歷數據,實體種類較少且實體數量不平衡,因此后期需要獲取更多的電子病歷數據來豐富模型的識別種類,為挖掘中文電子病歷中隱藏的醫療信息做準備。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
中外會展(2014年4期)2014-11-27 07:46:46
語文知識(2014年1期)2014-02-28 21:59:13
