基于度量學習的意圖識別和槽填充方法
2021-12-01 05:26:52衣景龍趙鐵軍
智能計算機與應用 2021年8期
衣景龍,趙鐵軍
(1 哈爾濱工業(yè)大學 計算機科學與技術(shù)學院,哈爾濱 150001;2 哈爾濱工業(yè)大學 機器智能與翻譯實驗室,哈爾濱 150001)
0 引言
近年來,深度學習方法被廣泛應用于計算機視覺以及人機對話等人工智能的多個領(lǐng)域[1],并極大地推動了這些領(lǐng)域的發(fā)展。但目前的深度學習方法都需要大量的標注訓練數(shù)據(jù),而在工業(yè)界應用的過程中,很難獲得大規(guī)模標注好的數(shù)據(jù)。以任務型對話系統(tǒng)為例,在系統(tǒng)研發(fā)時很難獲得大量的用戶對話語料,若獲取了大量的對話數(shù)據(jù),也面臨著人工標注成本高昂的窘境。同時,像任務型對話系統(tǒng)等類似的線上應用如百度的小度[2],用戶的需求往往變化比較頻繁,會導致數(shù)據(jù)標注和模型訓練反復進行。因此,小樣本場景下對自然語言理解技術(shù)的研究,成為本課題的重中之重。在目前的人機對話系統(tǒng)研究中,意圖識別和槽填充任務的效果往往是影響人機對話系統(tǒng)性能的關(guān)鍵。小樣本場景下的意圖識別和槽填充任務面臨著許多挑戰(zhàn):由于樣本量不足,模型往往難以學到足夠的語言知識;現(xiàn)有的基于原型向量的小樣本下的分類方法,往往會損失信息。另外,還涉及到意圖識別和槽識別任務如何結(jié)合等問題。
目前,小樣本場景中的自然語言理解方法已經(jīng)取得了不錯的進展,文獻[3]中提出了基于原型向量計算的非參學習的閾值調(diào)整方法用于小樣本下的多意圖分類,取得了較好的實驗效果。阿里巴巴團隊提出基于BERT 的預訓練聯(lián)合識別模型[4],用BERT 動態(tài)表征詞的多義性,解決一詞多義的問題,在ATIS 數(shù)據(jù)集上意圖識別的準確率達到了97.5%,槽填充的F1 值達到了96.1%的結(jié)果。本文提出了加入預訓練語言模型Fine-tune 方法和膠囊網(wǎng)絡動態(tài)計算原型向量的方法,有效改善了小樣本場景下的自然語言理解效果。
1 Fine-tune 方法
以BERT 為代表的預訓練模型[5]是在海量數(shù)據(jù)上訓練得到的,雖然含有大量的先驗語言知識,可以在小樣本場景下提高小樣本學習的性能,但當應用于不同的數(shù)據(jù)集時,往往需要微調(diào),來使表征向量更為貼合新數(shù)據(jù)集的語義。
由于BERT 的預訓練過程與本文的模型訓練過程不一致,BERT 中CLS向量雖然被視為句子的表示向量,但其在訓練過程中,卻是用來對句子對之前是否是順序關(guān)系做判斷,這與本文在訓練過程中對句子進行分類過程并不一致。當面臨多任務時,預訓練過程與訓練過程不一致導致的誤差會被放大。對此,本研究對模型進行了微調(diào),在BERT 后,鏈接兩個全連接輸出層,一個接在CLS向量之后,用以進行意圖分類,一個接在token向量之后用以進行槽填充。具體實現(xiàn)過程如下:
(1)在海量數(shù)據(jù)集(wiki)上訓練出BERT 模型(也可直接調(diào)用已經(jīng)訓練好的)。
(2)在改進的BERT 后加一個全連接層,其參數(shù)隨機初始化生成,直接調(diào)用CLS向量和各個詞向量進行意圖和槽的分類,進行Fine tune。
(3)丟棄第二步中的全連接層,將現(xiàn)在的BERT作為新的模型的編碼器,后面接入小樣本的意圖識別和槽填充模型。
整體模型框架如圖1 所示。
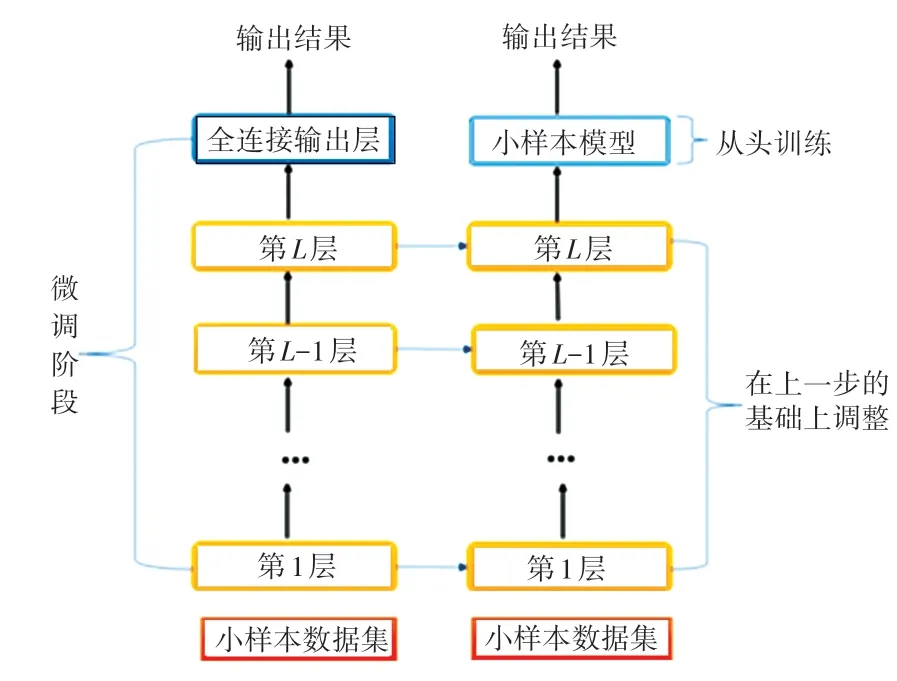
圖1 預訓練過程圖Fig.1 Pre-training process
在本文中,源模型采用哈爾濱工業(yè)大學社會信息與檢索團隊預訓練的中文語言模型,將該模型進行改進,在其后直接加一個全連接層進行分類,依次來彌合小樣本數(shù)據(jù)與源預訓練數(shù)據(jù)的分布誤差后,舍棄掉全連接層,在其后加入小樣本訓練模型,用于原型向量的計算和匹配分類。因為在Fine tune 方法中可能會存在“災難性遺忘”問題,因此在訓練時可以固定BERT 編碼器的參數(shù),只訓練小樣本模型。當選擇Fine tune 編碼器時,還采用了學習率預熱方法warm up,即在訓練開始時使用一個較小的學習率,訓練了一定的epoch 或者step 之后,再修改為原來設(shè)置的學習率來進行學習。這是因為最開始的時候,若學習率較大,模型可能不穩(wěn)定,通過warm up的方式,可以在一定程度上避免模型震蕩。
2 基于度量學習方法的意圖識別和槽填充
通過BERT 編碼器,提取出句子和字的表示向量,在Support Set 中將不同的意圖標簽和槽標簽所對應的向量通過取平均等方式作為原型向量ci,同時利用BERT 編碼器獲取Ouery Set 中語句和字的表示向量與原型向量計算相似度,通過最近鄰的思想來確定每個語句的意圖標簽和每個字的槽標簽。
最初求原型向量的做法是對每個意圖或槽所對應的向量直接取平均[6],但在每個句子中可能存在一些與意圖無關(guān)的干擾信息,如果直接加和或者取平均的方式很容易導致這些與意圖或者槽無關(guān)的干擾信息累加,影響最終的效果。因此,本課題采用了膠囊網(wǎng)絡的方式,去除從樣本表示計算類別過程中的無關(guān)信息[7]。其模型架構(gòu)如圖2 所示。
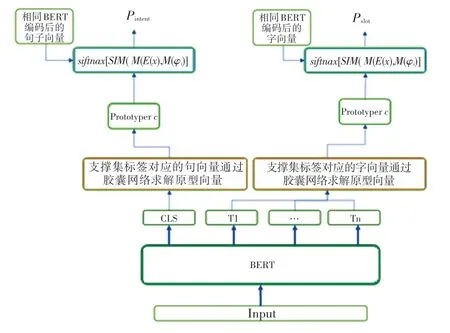
圖2 模型架構(gòu)圖Fig.2 Model architecture diagram
將支撐集的樣本通過BERT 編碼表示為向量之后,將這些表示向量視為輸入的膠囊,輸出的膠囊視為類別的語義特征表示,從輸入膠囊到輸出膠囊的過程中采取動態(tài)路由算法。
首先是對所有的句子(字)表示向量接一個前饋神經(jīng)網(wǎng)絡,這等同于做了一次矩陣轉(zhuǎn)化,其意義在于從樣本表示的語義空間轉(zhuǎn)換到類比表示的語義空間。

式中,eij表示類別i中第j個樣本的句子(詞)向量表示,是轉(zhuǎn)換后的表示。然后采用動態(tài)路由算法來過濾無關(guān)信息,提取類別的表示特征。在每次路由迭代的過程中,將其權(quán)重因子輸入到softmax函數(shù),確保其加和為1。
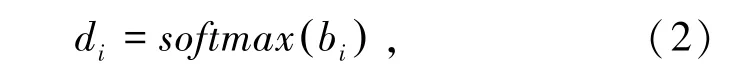
其中,bi為連接系數(shù),初始化為0,等同于在最開始的時候采用平均化的操作。每一類的類別向量,是其轉(zhuǎn)后候選類向量的加權(quán)之和。

為了保證每個類的向量模長不超過1,使用一個非線性的squash函數(shù)來對其進行處理。
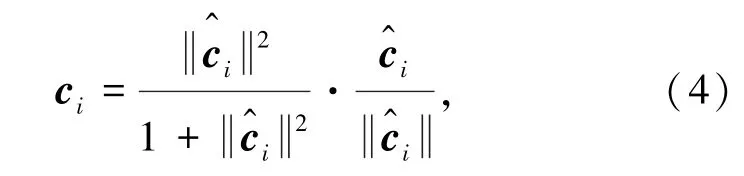
每次迭代結(jié)束后,通過路由協(xié)議來調(diào)整不同膠囊之間的連接權(quán)重。如果產(chǎn)生類別表示的向量ci與該樣本的候選向量在向量空間中較為相近,則增大該連接權(quán)重,否則減小該連接權(quán)重。

在本文模型中,經(jīng)過實驗,迭代次數(shù)設(shè)置為3次。
3 實驗
3.1 實驗數(shù)據(jù)
本文的實驗數(shù)據(jù)為小樣本數(shù)據(jù)集,數(shù)據(jù)來源主要有兩個途徑:一是SMP2020 中文人機對話技術(shù)評測(ECDT)TASK1;此外,少部分數(shù)據(jù)來源于SNIP 等公開數(shù)據(jù)集上進行翻譯,設(shè)計腳本,抽取出小樣本所需要的樣本組織形式。數(shù)據(jù)規(guī)模為:
(1)訓練集:查詢城市、APP 問答、詢問價格、翻譯、查詢天氣、航班預訂等在內(nèi)的45 個領(lǐng)域。
(2)開發(fā)集:單詞查詢、垃圾分類、笑話、假期、溫度查詢5 個領(lǐng)域。
(3)測試集:時間規(guī)劃、講故事、虛擬查詢、星座問答、戲劇問答等在內(nèi)的9 個領(lǐng)域。共計:6 694 個句子,143 個意圖及205 個槽位。
格式如下:


其中,text 是要查詢的文本;domain 是領(lǐng)域;intent 是文本意圖;slots 是文本中存在的詞槽。本課題抽取了3-shot 和5-shot 的數(shù)據(jù)集進行研究。
3.2 實驗結(jié)果
對于小樣本意圖分類任務,采用準確率(Accuracy)作為評價指標。對于小樣本語義槽填充任務,采用F1- score作為評價指標,當預測槽位的一個槽和其值組合與標準答案的一個槽和槽值組合完全一致,視為一個正確預測。用句子準確率作為二者聯(lián)合訓練的評價指標。只要當該句子的意圖識別和槽填充全部正確時,該樣本才算一個正確樣本。
實驗結(jié)果見表1~表3。
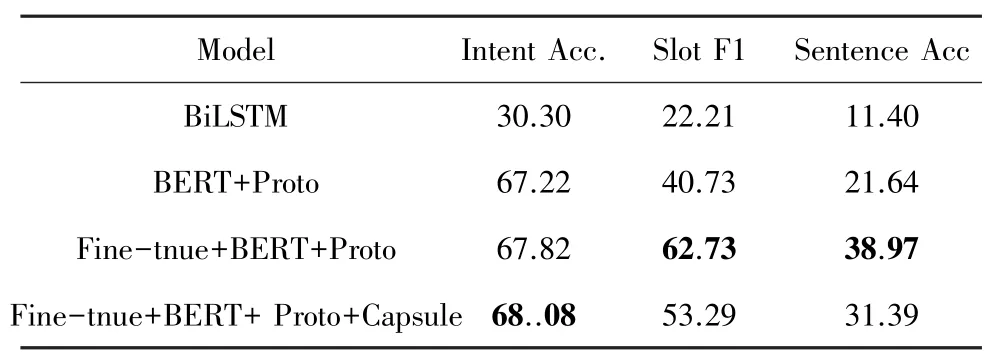
表1 在3-shot 數(shù)據(jù)集上聯(lián)合學習實驗結(jié)果Tab.1 Joint learning experiment results on 3-shot dataset

表2 意圖識別實驗結(jié)果Tab.2 Intent detection experimental results

表3 槽填充實驗結(jié)果Tab.3 Slot filling experimental results
由表1 可知,當意圖識別和槽填充任務聯(lián)合訓練時,F(xiàn)ine-tune 的方法對槽識別任務效果提升明顯。而膠囊網(wǎng)絡的引入,雖然提高了意圖識別的效果,但也造成了槽填充任務的效果下降。針對此,本文單獨以膠囊網(wǎng)絡對槽填充和意圖識別的影響做了消融實驗。
由表2 和表3 可以看出,膠囊網(wǎng)絡對意圖識別實驗有明顯的提升作用,但是在槽填充任務上并沒有獲得提升效果。其原因可能是對于細粒度的詞級分類而言,并沒有太多的無關(guān)信息,而膠囊網(wǎng)絡的引入反而使最終的原型向量與對應的類別中特征平緩的單詞更為相像,反而引入了誤差和偏置;而對意圖識別任務而言,其粒度是句子級,可能由于表述習慣不同,或者無關(guān)單詞較多等原因,含有較多的與意圖類別無關(guān)的干擾信息,此時引入膠囊網(wǎng)絡,可以起到一個很好的消除干擾信息的作用。
4 結(jié)束語
本文對人機對話中的小樣本學習場景下的意圖識別和槽填充展開了研究,采用了基于度量學習(Metric based)的方法[8]。度量學習方法通過計算query set 中的樣本與support set 中樣本的距離,尋找距離最近的類別樣本作為分類標簽,同時將兩個任務聯(lián)合進行訓練,用以提升模型的效果。從實驗結(jié)果中可以得出,本文的Fine-tune 方法對意圖識別和槽填充任務都有一定的幫助和提升,膠囊網(wǎng)絡在意圖識別中也起到了不錯的效果,可以幫助去除一部分無關(guān)信息,但對槽填充任務的幫助不明顯。因此下一步可以繼續(xù)研究在詞級別的原型向量計算上是否有更好的改進方法,能更準確的表征槽的類別向量,同時在Metric based 的小樣本學習方法中可以看出,主要的改進方向有兩個:一是對樣本語義表征向量的計算;二是對原型向量的計算,這對以后的研究也是一個好的啟發(fā)。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
