基于協同時空建模的視頻行為識別算法
2021-12-07 03:38:10鄭陽張旭東
智能計算機與應用 2021年7期
鄭陽 張旭東


摘 要: 行為識別是計算機視覺領域的一個重要研究方向,已被廣泛應用于視頻監控、人群分析、人機交互、虛擬現實等領域。而時空建模是視頻行為識別的一個重要部分,有效地進行時空建模可以極大地提高行為識別的精度。現有的先進算法采用3D CNN學習強大的時空表示,但在計算上是復雜的,這也使得相關部署昂貴;此外,改進的具有時間遷移操作的2D CNN算法也被用來進行時空建模,這種算法通過沿時間維度移動一部分特征通道用以進行高效的時序建模。然而,時間遷移操作不允許自適應地重新加權時空特征。以前的工作沒有考慮將這兩種方法結合利用起來,取長補短,以便更好地建模時空特征。本文提出了一個協作網絡用以有效地結合3D CNN和2D卷積形式的時間遷移模塊。特別是一個新的嵌入注意力機制的協同時空模塊(Collaborative Spatial-temporal module,CSTM)被提出用以有效的學習時空特征。本文在與時序相關的數據集(Something-Something v1,v2,Jester)上驗證了該算法的有效性,并且獲得了競爭性的性能。
關鍵詞: 行為識別; 時空建模; 3D CNN; 時間遷移
文章編號: 2095-2163(2021)07-0043-07中圖分類號:TP391.41文獻標志碼: A
Collaborative spatial-temporal networks for action recognition
ZHENG Yang, ZHANG Xudong
(School of Computer Science and Information Engineering, Hefei University of Technology, Hefei 230601, China)
【Abstract】Action recognition is an important research direction in the field of computer vision. It is widely used in video surveillance, crowd analysis, human-computer interaction, virtual reality and other fields. Spatial-temporal modeling is an important part of video action recognition, which could greatly improve the accuracy of behavior recognition. 3D CNNs can learn powerful spatial-temporal representations but are computationally intensive, which make them expensive to deploy; Improved 2D CNNs with a temporal shift can efficiently perform temporal modeling by shifting the feature map along the temporal dimension. However, temporal shift does not allow for the adaptively reweighting spatial-temporal features. Previous works have not explored the combination of the two types of methods to better modeling spatial-temporal information. This paper? proposes a collaborative network that effectively combines a 3D CNN and 2D temporal shift. In particular, a new collaborative spatial-temporal module (CSTM) is introduced to learn spatial-temporal features jointly to integrate attention mechanism. And the paper verifies the effectiveness of CSTM on temporal-related datasets (i.e., Something-Something v1, v2, Jester) and obtains superior results compared to the existing state-of-the-art methods.
【Key words】action recognition; spatial-temporal modeling; 3D CNN; temporal shift
0 引 言
行為識別旨在識別視頻中的人類動作。以前的行為識別方法[1-2]只使用靜態信息就獲得良好的結果,這通常通過從稀疏采樣幀中觀察狀態變化以推斷出動作類別。然而,現實生活中的視頻數據包含時序信息。因此,時空特征對行為識別具有重要意義。時空特征編碼了不同時間空間特征之間的關系[1,3-4]。
基于手工制作的行為識別方法被開發已久,主要包括幾種不同的時空特征檢測器。其中,The Improved Trajectories[2]被認為是當下最有效的傳統算法,能沿著光流引導的軌跡提取局部特征。然而,低級別的手工制作的特征對細粒度的動作類別缺乏很強的代表性和識別能力。
卷積神經網絡(Convolutional neural networks, CNNs)在行為識別[1-2,4]上取得了相當大的成功。與傳統的方法相比,這些方法的識別精度提升很大[5-6]。 在這些方法中,Sudhakaran等人[7]提出了一種Gate-shift模塊(GSM),該模塊使用分組門控和時間移位來學習時空表示。時間移位在文獻[8]中提出,就是通過在信道維度上移動特征,以實現相鄰視頻幀間的特征交互。此外,時間位移模塊可以區分具有相似外觀的動作類別[7]。在以前的方法中,時空特征通常是使用單一類型的卷積來捕獲的,即vanilla 2D CNN、3D CNN、或改進的具有時間位移操作的2D CNN。這意味著以前的方法不能做出依賴于數據的決策、進而有選擇地使特征通過不同的卷積結構。本次研究的目的是基于時空特征設計不同的卷積操作。例如,某些特征可以更好地用3D特征提取,另一些可以更好地用改進的2D CNN表示。
在本文中,提出了一種新的協同時空特征學習模塊(CSTM),其中結合了3D CNN和時間位移操作來共同獲得空間和時間特征。時間位移分支通過沿時間維度移動信道與相鄰幀交換信息。3D CNN分支基于滑動窗口[9]對輸入視頻的短期時間上下文進行建模。基于SENet[10]中,提出了一種協同注意力機制用以有效地融合來自3D CNN和時間位移分支的特征。該算法可以增強重要特征并減弱無關特征。和之前方法不同的是,本文的方法可以更有效地學習時空信息,從而自動地學習一種選擇策略。3D CNN分支學習動作狀態變化較大的動作類別;時間位移分支區分具有相似外觀的動作類別。
總結本文的貢獻如下:
(1)文中將3D CNN和時間位移操作結合起來,在一個統一的框架中編碼互補的時空特征。
(2)文中提出了一種新的具有嵌入式注意機制的協作時空學習模塊,用以融合從3D CNN和時間位移獲得的響應。
(3)與現有的最先進的方法相比,本文的方法在幾個時間相關的數據集上取得了競爭性的性能,包括一些Something-Something v1、v2、Jester。
1 相關工作
(1)2D CNN。在之前的工作中,2D CNNs被用于視頻動作識別,并取得了較好的效果[5-6,11]。Simonyan等人[6]首先提出了一個針對RGB輸入(空間流)和一個光流輸入(時間流)的雙流CNN。Wang等人[5]提出了一種針對雙流結構的稀疏時間采樣策略,并通過加權平均融合了2個流(temporal segment network;TSN)。 Feichtenhofer等人[12]探索了2個流的融合方法來學習時空特征。盡管上述方法是高效和輕量級的,卻只是使用加權平均或平均池化來融合特征,而忽略了時間順序或更復雜的時間關系。為了克服這個缺點,Zhou等人[13]提出了一個時間關系網絡(TRN)來學習視頻幀之間的時間依賴關系。Wang等人[14]提出了一種non-local神經網絡來建模遠程依賴。Lin等人[8]提出了一種基于TSN的時間位移模塊,可通過沿時間維度移動特征通道用以進行時空建模。這些方法都是基于2D CNN+后融合,且被認為是建模時空關系的有效方法。
(2)3D CNN。學習幀間時空特征的另一種方法是使用3D CNN[1,4]。Tran等人[1]使用3D卷積(C3D)從一序列密集幀中提取時空特征。Tran等人[4]進一步將3D卷積引入ResNet結構,對C3D進行了改進。SlowFast[12]包括捕獲空間語義的慢路徑和以一個細粒的時間分辨率捕獲運動信息的快速路徑。然而,3D CNN包含了大量的參數,也很難在現實世界加以部署。因此,本文的工作只在特定的幾個網絡層使用三維卷積來學習時空信息。這將使計算量最小化,同時也確保了較高的效率。
(3)2D CNN+3D CNN。有幾項工作已經研究了有效性和計算成本之間的權衡。Zolfaghari等人[9]在一個2D的時間融合網絡后,增加了一個3D殘差網絡。Luo等人[15]提出了利用2D和3D卷積的時空交互建模方法。這些方法的性能有所提升,同時減少了參數的數量。文中的模型是基于混合2D和3D CNN,即使用2D和3D CNN同時提取時空信息。特別是,文中的網絡包含了基于數據的決策策略,即根據特征選擇不同的卷積結構。此外,文中的模型只使用RGB稀疏幀作為輸入,而不是RGB幀和光流的組合。
2 方法
受啟發于Gate-Shift模塊(GSM)[7],本文提出一種創新的協同時空模塊(CSTM)。在本節,首先描述GSM的構成細節。之后,將詳解剖析本次研發設計的模塊。
2.1 Gate-Shift模塊
Gate-Shift模塊融合了GST[15]和TSM[8]用以構建高效的時空特征提取器。圖1(a)展示了GSM的概念圖。其中具備一個學習的空間門控單元。這個門控單元通過時間遷移操作選擇性地通過部分特征信息。圖1(b)闡述了GSM詳細的組成結構。具體由一個分組門控單元和一個前后時間遷移操作組成。其中,分組門控單元是用一個三維卷積和一個tanh激活層實現。因為文中的網絡結構是基于GSM做進一步改進,所以詳細描述GSM有助讀者能全面了解文中的網絡結構。文中以向量X表示GSM的輸入,大小為C×T×H×W。這里C表示通道數量,W、H、T分別表示特征圖的寬、高和時間維度。X沿著時間維度被分為2組,即[X1,X2],W包含2個C/2×3×3×3大小的門控核。[Z1,Z2]表示輸出。整個模塊的計算過程如下:
其中,‘*表示卷積;‘⊙表示Hadamard點乘;shift_fw和shift_bw分別表示前向和后向的位移操作。公式(3)和公式(5)也可以分別表示為Z2=shift_bw(Y2)+R2和Z1=X1+R1,這種表示方法和ResNet[11]中的殘差結構類似。
2.2 協同時空模塊
本文提出的協同時空模塊(CSTM)的結構如圖2所示。在協同時空模塊中,為了進行交互,3D CNN支路和時間遷移支路交叉加權彼此的中間特征。首先,2D卷積對網絡初始輸入進行處理得到時空特征。然后得到的特征輸出通過分組門控單元得到門控特征。門控特征隨即被分別傳遞到3D CNN支路和時間遷移支路。其中,時間遷移支路是來自于GSM,將沿著時序維度位移一部分特征圖。
基于SENet[10],文中設計一種協同通道注意力模塊用以有效地融合3D CNN支路和時間遷移支路。這個模塊由一個3D平均池化操作、2個全連接層和最后連接的一個通道級的縮放操作。3D平均池操作將全局空間信息壓縮成信道描述符,以便于利用全局感受野中的上下文信息。2個全連接層目的在于完全捕獲通道間的依賴關系。通道注意力模塊動態地對通道級的特征進行重新校準。并經常被用于需要鑒別細粒度特征的任務中。這里將在下面的篇幅中介紹通道注意力模塊地工作原理。首先,3D CNN支路的輸出(o1)、遷移支路的輸出(o2)將分別通過通道注意力模塊。由上一步獲得的特征將與o1和o2進行通道級的相乘。輸出Y=[Y1,Y2]的計算過程如下:
其中,‘⊙表示Hadamard乘;δ1表示ReLU函數;δ2表示sigmoid函數;W1,W2分別表示2個全連接層。
最后,2個分支的特征響應被進一步連接并簡化為更緊湊的表示。
本文設計的協同時空模塊被插入到BN-Inception和InceptionV3骨干網絡中,如圖3所示。因為Inception單元的其它支路中空間卷積的卷積核尺寸都很大,這嚴重影響到本文網絡對空間特征的學習能力。所以研究中僅僅將協同時空模塊插入到Inception單元中含有最少卷積數量的支路。
2.3 網絡結構
整體的網絡框架如圖4所示。視頻被分成N個相同大小的片段。從每個數據段中采樣一個幀。 文中采用BN-Inception和InceptionV3作為骨干網絡。CSTM隨后插入到Inception單元中最少數量的卷積層分支中,以提取時空特征并進行時間融合。文中使用TSN[5]作為基礎的框架結構,并且采用BN-Inception[16]和InceptionV3[17]作為文中的骨干網絡。本章提出一種新的時空模塊(Collaborative Spatial-Temporal Module,CSTM)進行視頻中的時空建模。文中提出的模塊能和任意的2D卷積結合。后續的實驗是將設計的模塊插入到BN-Inception和InceptionV3中。
最終的預測結果是對每個幀的結果進行一種簡單的平均池化操作。我們證明了在實驗中采用的平均池化的融合方法的性能比與需要在網絡高層上進行復雜融合的方法優越。原因是本文設計的模塊在網絡的中間層已經將時空特征進行了不斷的融合。
3 實驗和結果
3.1 數據集
研究中在3個公開的數據集上評估了本文的網絡。對此擬做闡述分述如下。
(1)Something-Something v1[18],v2[19]。Something-Something是人與物體交互的視頻數據集。共包含108 499個視頻,174個類別。需要廣泛的時間建模來區分這些細粒度類別。Something-Something v2是第二個版本,其中含有220 847個視頻,并且顯著降低了標簽噪聲。
(2)Jester[20]。Jester是手勢識別的數據集。其中包含148 092個視頻,27個類別。
3.2 實驗細節
實驗中所用的工作站配置CPU為Intel Xeon(R) E5-2620v2@2.1 GHz x 15,顯卡為2 × NVIDIA GTX2080Ti 12 G,內存為128 G,系統為Ubuntu 16.04LTS,使用編譯軟件為Python 3.6,使用深度學習框架為Pytorch[21]。整個網絡使用隨機梯度下降算法(Stochastic Gradient Descent,SGD)端到端進行訓練。實驗使用余弦學習率策略(cosine learning rate schedule),初始的學習率設置為0.01。動量(Momentum)設置為0.9,權重衰減(Weight Decay)設置為0.000 5,dropout設置為0.25,批尺寸(Batch size)設置為32。實驗是在Something-Something v1&v2和Jester三個數據集上進行訓練,訓練的最大迭代次數為60個周期(epoch)。這里將采用BN-Inception和InceptionV3作為實驗中的骨干網絡,其輸入圖片的尺寸大小分別為224 × 224 和229 × 229。
訓練使用交叉損失作為損失函數,如公式(9)所示:
其中,m為批大小(batch_size);總的類別數為n;真實分布為yji;網絡輸出分布為y[WT5]^[WT7]ji。
3.3 對比實驗
在本節中,在Something-Something v2數據集的驗證集上進行了對比實驗。為了驗證文中模型的有效性,使用BN-Inception作為骨干網絡,以8個視頻幀作為網絡的輸入。下面將分別對協同時空模塊的影響、注意力融合機制的有效性問題進行實驗分析。最后,分別在Something-Something v1 & v2和Jester三個數據集上與當下先進的行為識別方法進行對比。研究過程詳見如下。
3.3.1 協同時空模塊的影響
在本小節,研究的目的是驗證協同時空模塊的有效性。首先,結合3D CNN和時間遷移模塊。接下來進行實驗以驗證3D CNN能夠學習到互補的時空特征信息。然而,實驗中結合3D CNN和時間遷移模塊的簡單的加法融合方式并沒有帶來實驗結果上的明顯提升。文中將這種使用簡單的加法融合方式的模型命名為3D_shift_sum,并且以此作為基準。后續內容將進一步闡述了本文提出的融合策略有效地提升了模型性能。
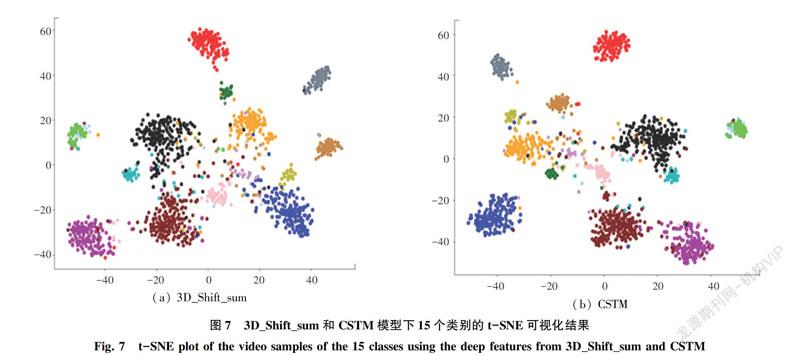
研究展示了3D CNN在文中框架上的效果。這里將其與原始的GSM的結果對比見表1。表1中,加粗表示最優性能。由表1可知,與GSM相比,3D_Shift_sum和協同時空模塊(CSTM)分別實現0.42%和2.22%的top-1準確率提升。這個結果表明了簡單地對3D CNN和時間遷移模塊(3D_Shift_sum)進行融合只能帶來微小的性能提升。而本文設計的協同時空模塊展現出了顯著的效果。協同時空模塊使用交互的注意力機制用于融合3D CNN和時間遷移模塊的特征信息。并能夠很好地區分出細粒度的行為類別。研究中展示的一小部分行為類別的top-1準確率如圖5所示。分析時注意到文中的模型在給定視頻級的行為標簽下能夠學習到行為的狀態變化。Something-Something v2數據集中抽樣幀如圖6所示。在圖6中,“pulling something from onto something”、“pulling something from right to left” and “pulling two ends of something so that it gets stretched”屬于相同的粗粒度標簽。然而,卻在每個時間段展現出不同的狀態變化。文中提出的協同時空模塊足夠有效地捕捉到了視頻中行為的狀態變化信息。
圖7展示了3D_Shift_sum和CSTM模型下15個類別的t-SNE可視化結果。由圖7可以得出結論:本文的網絡可以區分出細粒度的行為標簽,比如“Poking a stack of something without the stack collapsing”、“Trying to pour something into something, but missing so it spills next to it” and “Pulling two ends of something so that it gets stretched”。而且,本文的網絡可以學習到狀態變化。
另外,“Taking something from somewhere”、“Moving part of something” and “Pulling something out of something”等行為類別的準確率只有大約20%。這些表現較差的行為類別呈現出行為在視頻中的持續時間較短和變化較為緩慢的共同特點。本文的方法在這些行為類別上表現出短板。因此,設計一個更加細粒度的網絡用以挖掘時空特征信息是未來的研究方向。
3.3.2 注意力融合機制的有效性
在前面融合3D CNN和時間遷移模塊用以提取特征信息之后,文中提出了一種基于通道注意力機制的融合策略。為了驗證本文提出的融合策略對所提出的模型來說是最合適的,本文結合通道注意力機制與GSM,并且對比了其與本文設計的協同時空模塊。結果展示見表2。表2中,加粗表示最優性能。協同時空模塊實現了1.32%的top-1準確率提升;這顯然清楚表明了協同時空模塊的優越性能。注意力機制與原始的GSM結合時并沒有取得最優的結果;相反,將其與本文的網絡結合時實現了比較優越的結果。
3.3.3 與先進方法的對比
本文在Something-Something v1&v2和Jester三個數據集上與當下先進的方法的行為識別算法進行了對比。表3是在這三個數據集上的定量結果。為了公平起見,僅考慮在RGB輸入下的結果。表3中,加粗表示最優性能。
在Something-Something v1&v2數據集上,本文的模型在僅有8個幀輸入的情況下比絕大多數先進的方法都要優越。本文的方法優于后期融合方法TSN和TRN,因為能更好地編碼空間和時間特征。在Something-Something v1數據集上,本文的模型在使用更少的幀的情況下表現出比S3D[3]更好的結果。在Something-Something v2數據集上,本文的模型在TSN基礎上則又提升了35.65% top-1準確率和31.19% top-5準確率。盡管本文的模型僅僅使用RGB視頻幀作為輸入,但是獲得了優越的結果。
4 結束語
在本文中,提出了一種有效的用于行為識別任務的網絡,稱之為協同時空模塊(CSTM)。設計上有效地結合了三維卷積和時間遷移模塊,并且可以互補地學習視頻數據中的時空特征。實驗中在幾個與時間相關的數據集(Something-Something v1 & v2和Jester)上評估了本文提出的網絡,均展現了競爭性的性能。此外,本文設計的網絡模型在僅使用RGB輸入的情況下獲得了與現有先進方法相比更好的結果。
參考文獻
[1]TRAN D, BOURDEV L, FERGUS R, et al. Learning spatiotemporal features with 3d convolutional networks[C]//Proceedings of the IEEE International Conference on Computer Vision. Santiago, Chile:IEEE ,2015: 4489-4497.
[2]WANG Heng, SCHMID C. Action recognition with improved trajectories[C]//Proceedings of the IEEE International Conference on Computer Vision. Sydney, NSW, Australia :IEEE, 2013: 3551-3558.
[3]XIE Saining , SUN Chen, Huang J , et al. Rethinking spatiotemporal feature learning: Speed-accuracy trade-offs in video classification[J]. arXiv preprint arXiv:1712.04851,2017.
[4]TRAN D, RAY J, SHOU Z, et al.Convnet architecture search for spatiotemporal feature learning[J]. arXiv preprint arXiv:1708.05038, 2017.
[5]WANG Limin, XIONG Yuanjun, WANG Zhe, et al. Temporal segment networks: Towards good practices for deep action recognition[M]// LEIBE B, MATAS J, SEBE N, et al. Computer Vision-ECCV 2016. Lecture Notes in Computer Science. Cham:Springer, 2016,9912: 20-36.
[6]SIMONYAN K, ZISSERMAN A. Two-Stream Convolutional Networks for Action Recognition in Videos[J]. Advances in Neural Information Processing Systems, 2014, 1.
[7]SUDHAKARAN S, ESCALERA S, LANZ O. Gate-shift networks for video action recognition[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, Washington:IEEE,2020: 1102-1111.
[8]LIN J, GAN C, HAN S. Temporal shift module for efficient video understanding[J]. CoRR abs/1811.08383 ,2018.
[9]ZOLFAGHARI M, SINGH K, BROX T, etal. Eco: Efficient convolutional network for online video understanding[C]//Proceedings of the European Conference on Computer Vision (ECCV). Munich, Germany:Springer Science+Business Media,2018 :695-712.
[10]HU Jie, LI Shen, Albanie S, et al. Squeeze-and-excitation networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(8):2011-2023.
[11]CHRISTOPH R, PINZ F A. Spatiotemporal residual networks for video action recognition[C]//Advances in Neural Information Processing Systems. London,England:The MIT Press, 2016: 3468-3476.
[12]FEICHTENHOFER C, FAN H, MALIK J, et al.Slowfast networks for video recognition[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul, South Korea:IEEE,2019:6202-6211.
[13]ZHOU B , ANDONIAN A , OLIVA A , et al. Temporal relational reasoning in videos[M]// FERRARI V, HEBERT M, SMINCHISESCU C, et al. Computer Vision-ECCV 2018. Lecture Notes in Computer Science. Cham:Springer, Cham,2018,11205:831-846.
[14]WANG X , GIRSHICK R , GUPTA A , et al. Non-local Neural Networks[J]. arXiv preprint arXiv:1711.07971,2017.
[15]LUO C, YUILLE A L. Grouped spatial-temporal aggregation for efficient action recognition[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul, South Korea:IEEE,2019: 5512-5521.
[16]IOFFE S, SZEGEDY C. Batch normalization: Accelerating deep network training by reducing internal covariate shift[C]//International Conference on Machine Learning. Miami, Florida, USA :PMLR, 2015: 448-456.
[17]SZEGEDY C, VANHOUCKE V, IOFFE S, et al. Rethinking the inception architecture for computer vision[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. LasVegas,NV, USA:IEEE,2016: 2818-2826.
[18]GOYAL R , KAHOU S E , MICHALSKI V , et al. The "somethingsomething" video database for learning and evaluating visual common sense[C]// 2017 IEEE International Conference on Computer Vision (ICCV).Venice, Italy:IEEE, 2017:5843-5851.
[19]MAHDISOLTANI F, BERGER G, GHARBIEH W, et al. Fine-grained video classification and captioning[J]. arXiv preprint arXiv:1804.09235, 2018.
[20]MATERZYNSKA J , BERGER G , BAX I , et al. The Jester dataset: A large-scale video dataset of human gestures[C]// 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW).Seoul, Korea (South) :IEEE, 2019:2874-2882.
[21]PASZKE A, GROSS S, MASSA F, et al.Pytorch: An imperative style, high-performance deep learning library[J]. arXiv preprint arXiv:1912.01703,2019.
[22]JIANG Boyuan , WANG Mengmeng , GAN Weihao, et al. STM: SpatioTemporal and motion encoding for action recognition[C]// 2019 IEEE/CVF International Conference on Computer Vision (ICCV). Seoul, Korea (South) :IEEE, 2019:2000-2009.
基金項目: 國家自然科學基金(61876057,61971177)。
作者簡介: 鄭 陽(1996-),男,碩士研究生,主要研究方向:計算機視覺; 張旭東(1966-),男,博士,教授,主要研究方向:計算機視覺、模式識別。
通訊作者: 鄭 陽Email : zhengyangjuly@163.com
收稿日期: 2021-03-11
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
無線電工程(2020年11期)2020-10-29 01:25:46
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
