考慮執行能力的云制造服務資源組合優化研究
2021-12-15 08:27:50謝程龍石宇強
西南科技大學學報 2021年2期
謝程龍 石宇強
(西南科技大學制造科學與工程學院 四川綿陽 621010)
云制造[1]是一種面向服務的、高效低耗和基于知識的網絡化、敏捷化制造模式[2],能夠有效整合服務資源,更快地響應市場需求,降低服務成本,提高服務效率。隨著云制造任務的日益復雜,使得單一的云制造服務已經難以滿足需求者的任務需求,因此云平臺通過云制造服務資源組合來滿足復雜的任務需求[3]。云制造服務資源組合優化是云制造中的關鍵技術之一,云制造任務分解為多個子任務,每個子任務匹配得到相應的服務資源集合,研究如何選擇服務資源,形成合適的服務組合方案來執行任務具有重要意義。
國內外文獻大多數以服務質量(Quality of Service,QoS)作為評價指標來進行云制造組合優化。Ding等[4]建立多層次制造服務組合評價模型,其中考慮的主要指標是時間、成本和信譽。李永湘等[5]將服務可靠性、可信性、組合復雜度、協同度、執行時間、執行費用相結合來構建QoS評價模型。Yuan等[6]結合時間、可組合性、質量、可用性、可靠性、成本等目標,提出服務組合的QoS指標體系,使用改進的模糊綜合評估法確定QoS評估中每個指標的權重。陳友玲等[7]構建面向云制造的多供應商協同生產任務分配優化模型。Zhao等[8]為了更準確地從復雜的服務網絡中找到個性化的制造服務組合,將組合優化與協同過濾相結合,通過使用具有服務質量約束的組合優化模型來選擇最佳服務組合。Ren等[9]針對制造服務的社會協作特點,提取出5類社會關系來計算協同效應,然后建立一種基于最大化整體協同效應的服務組合優化模型。Wu等[10]提出一種從經濟、環境和社會等方面評估云制造可持續性的綜合方法,從而建立組合優化模型。因為云制造組合優化問題是NP難問題,許多學者使用遺傳算法[11-12]、粒子群算法[13]、人工蜂群算法[14]等求解云制造服務組合優化問題。
上述研究在解決云制造組合優化問題時大多是關注任務需求,其中大多考慮的是成本、時間、質量等QoS指標,但是對于服務資源執行任務的歷史執行情況及其時效性考慮較少,使得服務資源對任務的執行能力是否可信或者可靠不得而知,具有不確定性。當執行能力可信度低的服務資源執行子任務時可能會出現更多突發問題,例如設備故障使得交貨期延長,成功執行子任務的概率將降低,最終可能會導致整個任務失敗,不但影響需求方利益同時也對云平臺利益及聲譽造成影響。因此,有必要同時考慮服務資源的QoS指標以及歷史執行情況來解決考慮執行能力的云制造服務組合優化問題。
1 問題描述
云平臺將需求方任務按規則分解為若干子任務,ST={STi|i=1,2,…n}表示分解后的子任務集合,n表示子任務數,STi表示第i項子任務。Si={Sij|j=1,2,…mi}表示STi的候選服務資源集合,mi表示Si中的服務資源數,Sij表示Si中的第j個服務資源。
需求方關注的是任務需求[11],即成本、時間、合格率等QoS指標,不同服務資源的QoS指標可能不同。云平臺更加關注任務是否可以順利完成,即云制造服務資源的執行能力是否可信。服務資源執行能力是否可信可以通過其歷史執行情況來判斷,而云制造服務資源的歷史執行情況會隨時間變化,具有不確定性。若在云制造服務資源組合優化決策過程中僅考慮成本、時間、合格率等QoS指標,忽略云制造服務資源的歷史執行情況,對服務方任務執行能力考慮不足,可能導致任務執行失敗。因此,應綜合考慮需求方所關注的成本、時間、合格率等QoS指標和云平臺所關注的服務資源歷史執行情況信息,進行服務資源組合優化,使組合方案達到最優。
2 組合優化模型
云制造需求方主要關注任務需求,即完成任務所需的成本、時間、合格率均達到最優。云平臺更多關注服務資源執行能力是否可信,而可靠性和可維護性能夠客觀反映服務資源在執行任務時的真實情況。可靠性是指服務資源成功執行任務次數與執行任務總次數之比[3];可維護性是指服務資源執行任務中成功處理意外的次數與意外發生的次數之比[15]。當服務資源可靠性和可維護性越大時,執行任務的穩定性越好,執行能力越可信。因此,本文以服務成本、時間、合格率、可靠性、可維護性為決策目標建立組合優化數學模型,并且考慮服務資源歷史執行情況信息的時效性,建立時間段權重衰減函數。
決策變量如下:
(1)
式中Xij為決策變量。
2.1 時間段權重
服務資源在不同時間段的歷史執行情況可能不同,考慮到服務資源歷史執行情況的時效性,建立時間段權重線性衰減函數為每個時間段賦予權重。越靠近當前時間點的時間段權重越大,越遠則時間段權重越小。H表示總時間間隔段數,即能對執行情況進行評價的時間段數。權重衰減函數公式如下:
(2)
式中:h表示時間段,假設云制造服務資源在每個時間段內均有執行任務;φh表示時間段h的權重。在該衰減函數中,云平臺可以根據自己需要對最大間隔數H和最遠時間段權重φH進行設置,其中H≥1,0≤φH≤1。
2.2 優化目標
總服務成本(C)決策目標如下:
(3)
式中:C表示服務組合方案的總服務成本;Cij表示Sij對STi的服務成本。
總服務時間(T)決策目標如下:
(4)
式中:T表示服務組合方案的總服務時間;Tij表示Sij對STi的服務時間。
合格率(Q)決策目標如下[16]:
(5)
式中:Q表示服務組合方案的平均合格率;Qij表示Sij對STi的合格率。
可靠性(SR)目標是使服務組合方案的平均可靠性最大。首先利用時間段權重,確定各服務資源可靠性,然后基于標準差[17]對可靠性進行獎懲修正。
可靠性決策目標如下:
(6)
(7)
(8)
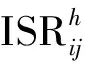
可維護性(SM)目標是使服務組合方案的平均可維護性最大。首先利用時間段權重,確定各服務資源可維護性,然后對可維護性進行獎懲修正。可維護性決策目標如下:
(9)
(10)
(11)
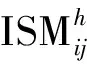
2.3 約束條件
組合優化模型約束條件如下:
(12)
式中:每個子任務由一個服務資源服務。
(13)
式中:Cmax表示可接受的最大總服務成本;Tmax表示可接受的最長總服務時間;Qmin表示可接受的最低合格率;SRmin表示可接受的最小可靠性;SMmin表示可接受的最小可維護性。
2.4 總目標
將各目標進行歸一化[7],總目標最小的服務資源組合方案則為最優組合。總目標公式如下:
minF=ω1·T*+ω2·C*+ω3·Q*+
ω4·SR*+ω5·SM*
(14)
(15)
式中:T*,C*,Q*,SR*,SM*分別表示歸一化后的服務時間、成本、合格率、可靠性、可維護性目標;ωe表示各子目標的權重值,E=5。
3 JADE算法求解
JADE算法[19]是DE算法[20]的變體,其優勢在于通過使用帶有外部歸檔的變異策略(DE/current-to-pbest/1 with archive)以及通過自適應方式對變異概率μF和交叉概率μCR進行更新來優化算法性能。本文在JADE算法的基礎上使用反向學習種群初始化并引入DE/rand/1變異策略。
3.1 種群初始化
首先產生初始種群,再產生反向種群[21]:
(16)
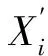
3.2 變異策略
針對個體變異概率Fi,標準JADE算法采用的是柯西分布生成,本文中Fi的生成方式調整為正態分布生成,具體公式如下:
Fi=randni(μF,0.1)
(17)
μF=(1-c)·μF+c·meanA(SF)
(18)
式中:Fi表示個體i的變異概率;μF為變異概率;Fi根據平均值為μF、標準差為0.1的正態分布產生;式(18)表示變異概率μF的更新方式,與交叉概率μCR更新方式相同;SF表示成功變異的個體對應的Fi組成的集合;meanA(SF)表示對SF集合中的參數取平均;c=0.1。
本文中將DE/rand/1策略和DE/current-to-pbest/1 with archive策略相結合來進行變異,具體公式如下:
(19)
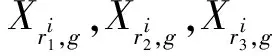
3.3 算法流程
算法流程如圖1所示。具體步驟如下:
Step 1:設置種群規模NP,個體維數Dim,個體取值范圍Xmax,Xmin,當前迭代數g,最大迭代數Gmax,初始化變異概率μF,交叉概率μCR,初始化外部存檔集合A=?等參數;基于反向學習的種群初始化;
Step 2:判斷是否滿足g>Gmax,若滿足,則輸出最優解;否則轉入Step 3;
Step 3:設置個體成功交叉所對應的交叉概率CRi組成的集合SCR=?,成功變異所對應的變異概率Fi組成的集合SF=?;
Step 4:為種群中個體i產生交叉概率CRi、變異概率Fi;
Step 5:為種群中個體選擇變異策略來進行變異操作;
Step 6:對種群中個體進行交叉操作;
Step 7:對種群中個體進行選擇操作和存檔操作,更新A,SCR,SF;
Step 8:更新交叉概率μCR和變異概率μF,g=g+1,轉到Step 2。
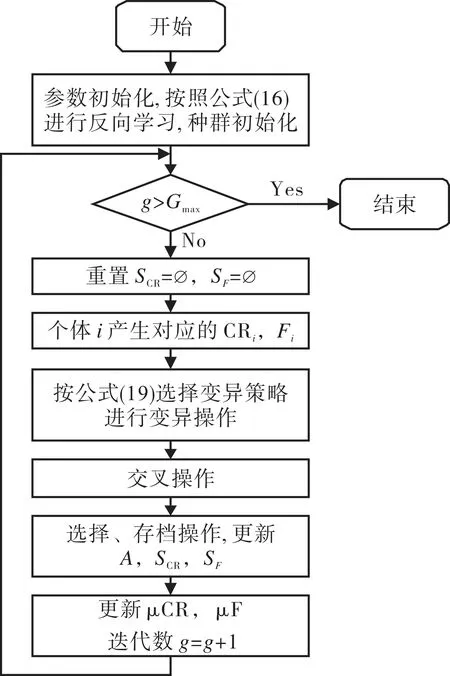
圖1 算法流程圖Fig.1 Algorithm flowchart
4 實驗仿真
假設某任務由云平臺分解為8項子任務,表示為{ST1,ST2,…ST8},各子任務的候選服務資源均為8個,子任務按順序執行,為各子任務選擇服務資源,形成最優組合方案。假設各服務資源成本取值范圍[1,6]萬元、時間取值范圍[3,12]天、合格率取值范圍[90%,99%]、各時間段可靠性取值范圍[0.80,1]、各時間段可維護性取值范圍[0.70,1]。設置兩組實驗,在實驗一中,只考慮時間、成本、合格率目標,權重均為1/3;在實驗二中,考慮時間、成本、合格率、可靠性、可維護性目標,權重均為0.2。部分云制造服務資源的QoS指標信息和各時段歷史執行情況信息分別如表1、表2所示。
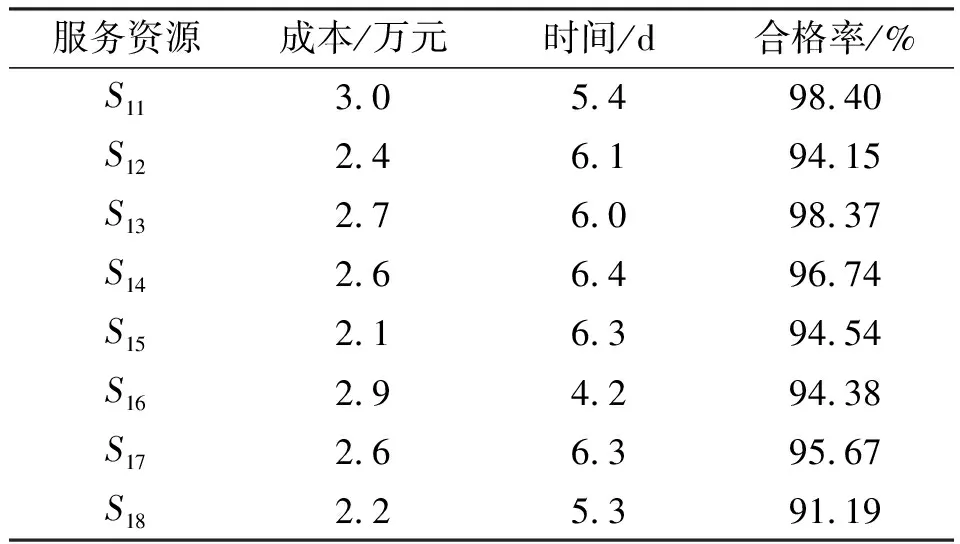
表1 部分服務資源QoS指標信息Table 1 QoS indicator information of some service resources
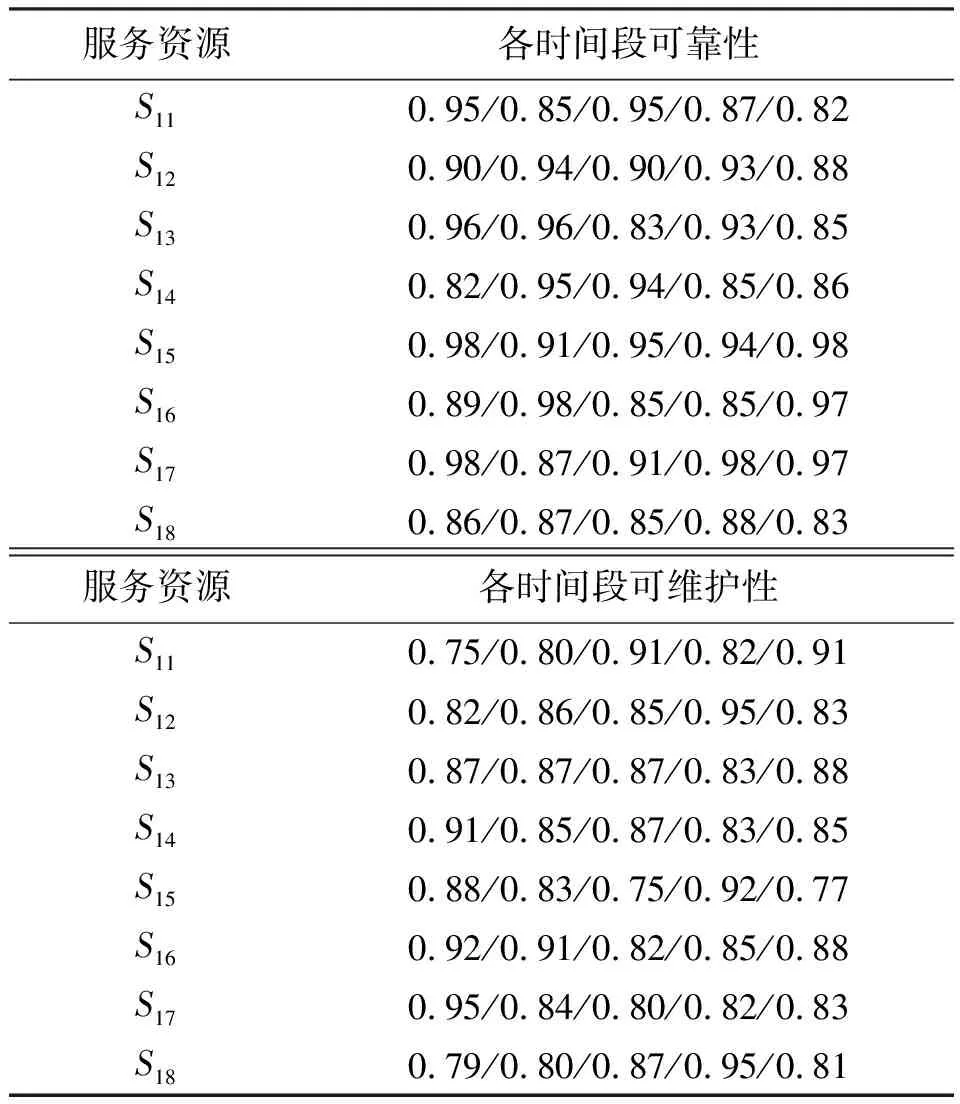
表2 部分服務資源歷史執行情況信息Table 2 Historical performance information of some service resources
模型參數設置:服務資源可靠性波動閾值λSR=0.05;修正后的可靠性范圍0.8≤SRij≤1;服務資源可維護性波動閾值λSM=0.05;修正后的可維護性范圍0.7≤SMij≤1。時間段最小權重φH=0.2,總間隔數H=5。約束設置:總成本C≤20萬元;總時間T≤45 d;合格率Q≥95%;可靠性SR≥90%;可維護性SM≥82%。
算法參數設置:種群規模NP=50、最大迭代次數Gmax=100、運行50次;JADE算法與本文改進的JADE算法初始交叉概率μCR=0.3,初始變異概率μF=0.5,適應度值占優比例p=0.1;不同變異策略種群比例q=0.3;粒子群(PSO)算法速度更新參數c1=0.5,c2=0.5,速度最大值Vmax=5,最小值Vmin=-5。將本文改進JADE算法與PSO算法、JADE算法進行對比,運行50次后,兩組實驗平均解迭代過程如圖2、圖3所示,算法結果對比如表3、表4所示。
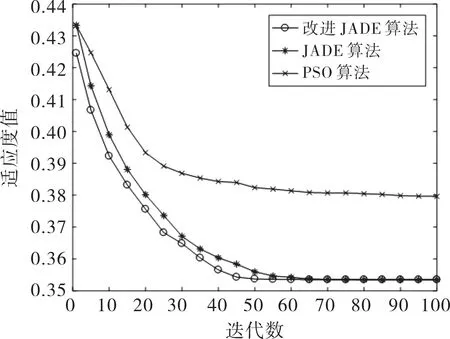
圖3 實驗二平均解迭代過程Fig.3 Experiment 2 average solution iteration
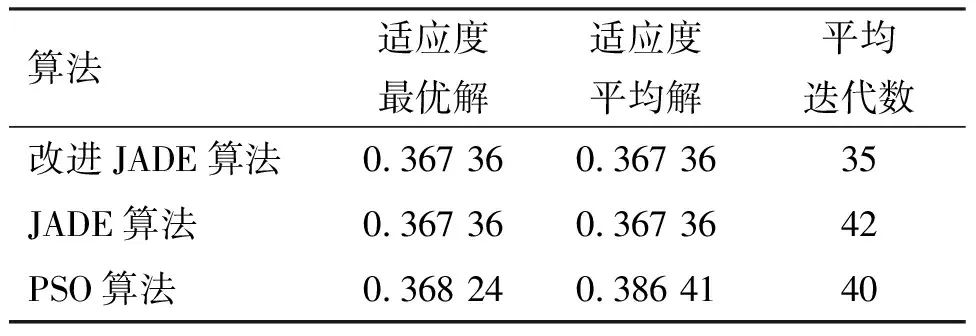
表3 實驗一運行結果對比Table 3 Comparison of experiment 1 running results
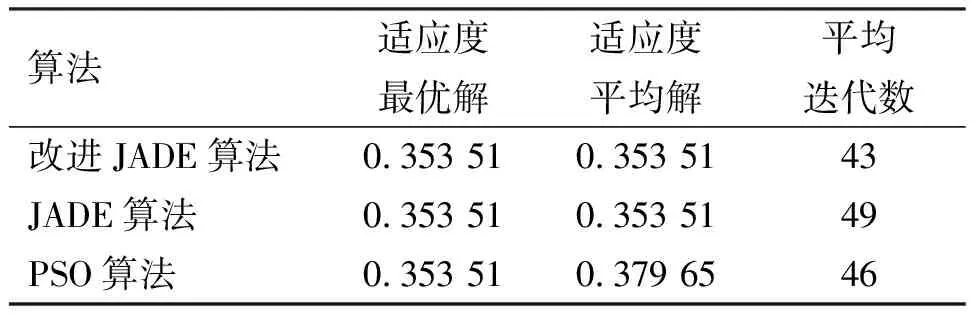
表4 實驗二運行結果對比Table 4 Comparison of experiment 2 running results
從圖2、圖3可以看出,采用反向學習的初始化種群,在迭代初期獲得的解更優,證明反向學習的有效性。同樣可以看出,本文改進的JADE算法相對于JADE算法收斂性更好。從表3、表4中可以看出,獨立運行50次后,本文改進JADE算法每次運行均能尋得相同最優解,而PSO算法適應度平均值大于其他兩種算法。在求得最優解的平均迭代數方面,本文改進的JADE算法在實驗一、二中分別比JADE算法少7代和6代,因此本文改進的JADE算法的收斂性較好。
兩組實驗最優組合方案的子目標值如表5所示,實驗一組合方案為[S13,S22,S36,S45,S54,S63,S78,S87],實驗二組合方案為[S15,S27,S36,S44,S51,S66,S72,S86]。對兩組實驗進行比較,當實驗一組合方案按實驗二中考慮的5目標并且各目標權重均為0.2的情況下進行計算時,可靠性為0.906 5,可維護性為0.823,適應度值為0.487 67,適應度值大于實驗二最優解。可靠性和可維護性能夠客觀反映服務資源在執行任務時的真實情況,即可靠性和可維護性越大時,其執行任務的穩定性越好,執行能力越可信。實驗二服務資源組合方案的可靠性和可維護性優于實驗一,則實驗二服務資源組合方案執行能力更可信,執行任務時穩定性更好。雖然實驗一服務資源組合方案的服務成本、時間、合格率優于實驗二,但是實驗一服務資源組合方案未按承諾完成任務的風險更高,一旦未按承諾完成任務,使得任務失敗將造成更大的損失。因此,為降低服務資源組合方案未按承諾完成任務的風險,選擇執行能力更可信的服務資源組合方案是有必要的。

表5 最優服務組合子目標值Table 5 Optimal service group target value
在不考慮對服務資源可靠性和可維護性進行獎懲修正的情況下,實驗二最優組合方案為[S15,S27,S36,S44,S53,S66,S72,S86],與考慮修正情況下的最優組合方案主要區別在于子任務ST5對于服務資源的選擇,服務資源S51,S53的可靠性和可維護性標準差如表6所示。從表6可以看出服務資源S51可靠性和可維護性標準差均低于服務資源S53,說明服務資源S51的可靠性和可維護性的波動相對于服務資源S53較小。通過對服務資源的可靠性和可維護性進行獎懲修正后,最終選擇的服務資源組合方案為[S15,S27,S36,S44,S51,S66,S72,S86]。

表6 S51,S53的可靠性和可維護性標準差Table 6 Standard deviation for reliability and maintainability Of S51 and S53
5 結論
本文針對云制造服務資源組合優化中服務資源執行能力存在不確定性等問題,建立一種考慮需求方所關注的QoS指標和云平臺所關注的服務資源執行能力的組合優化模型。結果表明考慮服務資源執行能力的組合優化方法所選擇的組合方案在執行任務時的執行能力更可信,且改進的JADE算法在兩組實驗中收斂性相比原算法更好。在下一步的研究中,將考慮面向多任務以及多任務之間存在優先級關系的云制造服務組合優化,運用多目標優化算法進行最優組合方案的選擇。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
房地產導刊(2022年5期)2022-06-01 06:20:14
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
資源再生(2017年3期)2017-06-01 12:20:59
