基于FCM的簇內欠采樣算法
2021-12-16 11:50:26劉稀文段隆振段文影
南昌大學學報(理科版) 2021年5期
關鍵詞:分類
劉稀文,段隆振,段文影
(南昌大學信息工程學院,江西 南昌 330031)
分類技術一直是機器學習和數據挖掘領域的研究重點和熱點,在理論研究和工程實踐領域都有著廣泛的應用。傳統的分類算法如KNN、SVM和決策樹等在平衡數據集上通常表現很好,但在樣本類別分布不均衡時,會出現分類面偏倚的現象,少數類的樣本更容易被誤判,得不到好的分類結果。例如,網絡入侵檢測[1]、信用卡欺詐檢測[2]、垃圾郵件過濾[3]、自閉癥診斷[4]等問題就是典型的類別不平衡問題,在互聯網入侵檢測的樣本數據中,入侵的樣本數遠遠少于正常的樣本數,如果將傳統的分類器直接應用于這些類別不平衡的樣本上,模型會傾向于多數類,忽略少數類樣本,從而降低了對少數類樣本的分類能力,甚至會出現把全部樣本都判為多數類的情況,這樣的分類結果是沒有意義的。針對類別不平衡的分類問題,已有很多有效的算法被提出,主要體現在兩個層面:算法層面和數據層面。
算法層面是對標準的分類算法進行改進,或者提出新的應用在不平衡數據集上的分類算法。算法層面典型的解決方法有代價敏感算法和集成學習方法。代價敏感學習[5]是在訓練模型時以整體誤分代價的最小化取代樣本的整體誤差最小化作為訓練目標,通過引入代價矩陣,賦予少數類樣本更大的代價權重,以降低分類器在少數類樣本上的錯分率。集成學習方法的思想是將多個基分類器組合成一個強分類器,以提高分類性能。集成學習有兩種經典的范式:Bagging[6]和Boosting[7]。
數據層面主要包含過采樣和欠采樣算法。過采樣方法中最簡單的是隨機過采樣,但這種方法容易導致過擬合。Chawla等人[8]提出了少類樣本合成過采樣技術(synthetic-minority-over-sampling-technique,SMOTE),根據樣本分布對少數類別樣本進行分析模擬,在少數類樣本的鄰域間插入人工合成的新少數類樣本,在一定程度上避免了隨機過采樣法易于陷入過擬合的問題。此外還有在SMOTE算法基礎上進行了改進的Borderline-SMOTE[9]算法、ADASYN[10]算法等。
在欠采樣方法中,最簡單的方法是隨機欠采樣(Random Under Sampling,RUS),隨機刪除多數類中的部分樣本,形成新的平衡數據集。但這種方法存在隨機性,容易刪除一些有代表性的樣本數據,導致多數類樣本丟失一些重要信息,分類器不能學習到完整的分類規則。為了克服這一缺點,很多研究者都提出了其他的欠采樣方法。Zhang等[11]提出基于KNN的4種欠采樣方法:NearMiss-1,NearMiss-2,NearMiss-3和MostDistant。思路是利用K近鄰信息挑選具有代表性的多數類樣本,實驗表明NearMiss-2算法具有較好的不平衡數據的分類能力。李春雪等人[12]使用聚類算法,令每次聚類的簇數取不同的值,對多數類樣本進行多次聚類,把聚類中心作為新的多數類樣本參與訓練,提高了分類結果的G-mean值。但該方法需要生成很多份不同不平衡比率的訓練集,然后在這些訓練集上分別訓練分類模型,其時間復雜度較大。Kocyigit 等人[13]使用FCM算法對全部樣本進行聚類,得到若干個簇,重復進行50次聚類,每次聚類指定不同的簇數,選擇與聚類中心最近鄰的多數類樣本加入候選集,然后用t檢驗從候選集中選出與少數類樣本相等數量的多數類樣本,與少數類樣本合并得到平衡的訓練集。該算法提高了分類器的分類性能,而且算法的獨立性較好。Lin等人[14]提出了兩種基于聚類的欠采樣方法:Clustering-based undersampling(CBUS),令多數類的聚類簇數等于少數類樣本的個數。 在方法1中,對樣本中的多數類使用kmeans聚類算法,將聚類中心作為新的多數類樣本與少數類樣本合并,得到新的平衡樣本集,此類方法較為經典,其它的研究人員[15]也使用了這種方法。在方法2中,先對多數類樣本進行kmeans聚類,然后選擇每個聚類中心的最近鄰樣本作為新的多數類樣本與少數類樣本合并。這兩種方法都有效地改善了傳統的分類算法在不平衡數據集上的分類效果。但此類方法也存在一些不足,不能保證聚類簇數等于少數類樣本數時的G-mean值一定最大,而且如果少數類的樣本非常多,則要求多數類的簇數也要同樣多,聚類的時間會相應地成倍增加。另外,這些方法只是考慮了類間不平衡問題,沒有考慮到類內不平衡問題。
為了克服傳統分類器在不平衡數據上的性能缺陷,本文借鑒基于聚類的欠采樣方法,結合模糊聚類和集成學習理論,提出基于FCM的簇內欠采樣算法(Fuzzy C-means clustering based undersampling in clusters),提高不平衡數據的分類性能。
1 相關工作
1.1 模糊 C-均值聚類算法(Fuzzy C-means
clustering,FCM)
在聚類問題的研究工作中,研究者應用均方逼近理論構造帶約束的非線性規劃函數,將聚類問題的求解轉化為非線性目標規劃問題,此時的目標函數是類內平方誤差和J1。Dunn[16]基于模糊劃分理論把每個樣本與全部聚類中心的距離用其隸屬度平方加權,把J1推廣到類內加權平均誤差和函數J2。后來,Bezdek等人[17]引入參數m,把J2推廣到一個目標函數的無限簇,并提出了交替優化算法,形成了FCM 算法。
FCM算法的優化目標函數是:
(1)
其中,D是樣本總數,N是聚類簇數,uij表示元素xi對第j類的隸屬度,cj是第j個簇的簇心,m是權重指數,控制著聚類矩陣的模糊程度,m的值大于1,且m越大,聚類的模糊程度越高,m越小,則聚類越接近于硬C均值聚類。在實際應用中,m的缺省值為2。
FCM 算法的算法步驟如下:
初始化:設X是由d個元素構成的集合,X={x1,x2,…,xd},給定聚類類別數N,2 ≤N≤d,迭代停止閾值ε,初始聚類中心C0,迭代計數器b=0;
步驟1用下式計算或者更新劃分矩陣Ub=Uij:
(2)
步驟2根據公式(3)更新聚類中心Cb+1:
(3)
步驟3如果‖Ub+1-Ub‖≤ε或者算法達到指定的迭代次數,則算法停止并輸出劃分矩陣和聚類中心,否則令b=b+1,轉為執行步驟一。
1.2 K近鄰(k-nearest neighbor,K-NN)分類器
KNN算法[18]是一個廣泛使用的分類算法,其思路是:對于某個待分類的樣本,若在該樣本的K個最近鄰的樣本中大多數屬于某個類,就將該樣本判為這個類別。關于k值的選擇,一般令k為較小的奇數,可以采用交叉驗證法來確定。樣本間的距離通常選用歐式距離、曼哈頓距離、馬氏距離、余弦距離、漢明距離等公式來度量,本文使用歐氏距離。對于兩個樣本A、B,假設A=(x1,x2,…,xn),B=(y1,y2,…,yn),則它們之間的歐氏距離為:
(4)
1.3 隨機森林(Random Forest,RF)
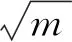
構建隨機森林的算法步驟如下:
算法1隨機森林的構建算法
輸入:訓練集N,訓練集N的總數n,隨機森林的規模k,每個決策樹選擇的特征數m。
輸出:隨機森林分類器RF。
1.初始化:RF=?;
2.Fori=1:k
3.使用Bootstrap抽樣法對訓練集N重復n次抽樣,得到第i個決策樹treei的訓練集Ti和treei的袋外樣本OOBi;
4.在訓練集Ti上隨機選擇m個特征,訓練決策樹treei;
5.使用treei對OOBi進行預測;
6.將第i棵決策樹納入RF模型,RF=RF∪treei。
7.End for
隨機森林算法具備了Bagging 算法與隨機子空間算法的特點,能很好地處理在訓練模型時可能存在的特征遺失現象,由于樣本隨機和特征隨機的二重隨機性,模型不易陷入過擬合,而且由于袋外數據的存在,使用袋外數據可以在建模的過程中得到真實誤差的無偏估計,不需要另外留出驗證集對模型進行評估,袋外數據誤差估計與同訓練集一樣大小的測試集得到的精度一樣,可以用袋外誤差估計取代測試集的誤差估計。
2 基于FCM的簇內欠采樣算法
2.1 相關概念
不平衡數據集是指在數據集中不同類別的樣本在數量上具有很大差別的數據集。其中,樣本數較多的一類樣本被稱為多數類樣本,也叫負類樣本,樣本數較少的一類樣本稱為少數類樣本,也叫正類樣本。多數類樣本數與少數類樣本數之比稱為不平衡比率(imbalanced ratio,IR)。數據集的IR值越大,分類難度也就越大。為了降低數據集的不平衡比率,需要以合適的采樣倍率對數據集進行重采樣,采樣倍率是一個系數,例如少數類(或多數類)樣本的數量為m,采樣倍率為n,則重采樣后的少數類(或多數類)樣本數為m*n。
2.2 算法過程
基于FCM的簇內欠采樣算法(Fuzzy C-means clustering based undersampling in clusters,FCMUSIC)主要有兩個過程:首先,利用 FCM算法對多數類樣本進行聚類欠采樣 ,設定聚類簇數n的值,n的選擇通過層次聚類算法初步確定,然后用交叉驗證法嘗試比較多個n值。在得到聚類劃分的n個簇后,對每個簇進行欠采樣,在每個簇內,按照采樣倍率不放回地隨機抽取一定數量的樣本代表多數類,得到新的多數類樣本,和少數類樣本合并,形成平衡樣本集。其次 ,在得到的平衡數據集上訓練分類器 ,并進行多次分類實驗。本文在欠采樣后的平衡數據集上結合單個分類器和集成分類器進行訓練,以檢測在不同的分類器上的提升效果。
FCMUSIC在欠采樣階段的算法描述如下:
算法2FCMUSIC算法
輸入:不平衡數據集S,聚類簇數n。
輸出:平衡數據集S′。
1.初始化:S′=φ;
2.將數據集S劃分為多數類N-和少數類N+,計算數據集S的不平衡比率IR;
3.使用FCM算法將多數類樣本N-劃分為n個簇,N-={C1,C2,…Cn};
4.Fori=1:n;
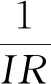
6.S′=S′∪Di;
7.End for
8.返回S′。
關于聚類簇數n的值,本文使用層次聚類算法來進行選擇。層次聚類可以把數據劃分到不同的組群,聚類的結果是樹狀結構, 可以被直觀地展示出來,然后人為地觀察來確定聚類的簇數。關于層次聚類的更多介紹可以參閱文獻[19]。層次聚類的結果如圖1所示,每個子節點上的數據可以被分到同一個簇。
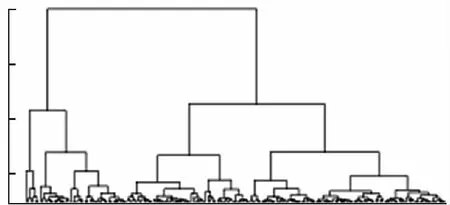
圖1 層次聚類的結果可視化
數據不平衡不僅體現在多數類與少數類之間的比例不平衡,也體現在同一類別的數據內部。如圖2所示,多數類樣本分布在major1和major2兩個不同的區域,major2是小析取項。這兩個區域互不相鄰,而且在樣本數量上也有很大的差異。major2偏離樣本空間太遠,卻又與少數類樣本空間相鄰,而且包含的樣本數量稀少,容易被當成噪聲樣本處理,或者被直接忽略,導致沒有利用到這部分樣本的信息。FCMUSIC算法對多數類樣本進行聚類可以找出小析取項的簇,然后在這些簇內抽樣,避免出現小析取項樣本沒被利用的情況。
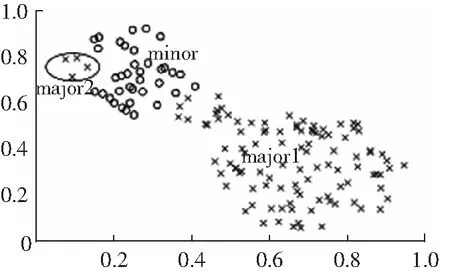
圖2 樣本集的類內分布
FCMUSIC算法減少了多數類樣本的數量,獲得了平衡的訓練集。原始不平衡樣本集和經過FCMUSIC算法處理后的樣本集的樣本分布分別如圖3和圖4所示。其中,類別1為多數類,類別2為少數類。FCMUSIC算法在每個簇內都選取了一定數量樣本,使得抽取的樣本來自于原始樣本集分布空間的各個方向,保留了多數類樣本原有的分布特征,從而在保證了欠采樣后樣本的多樣性和全面性。
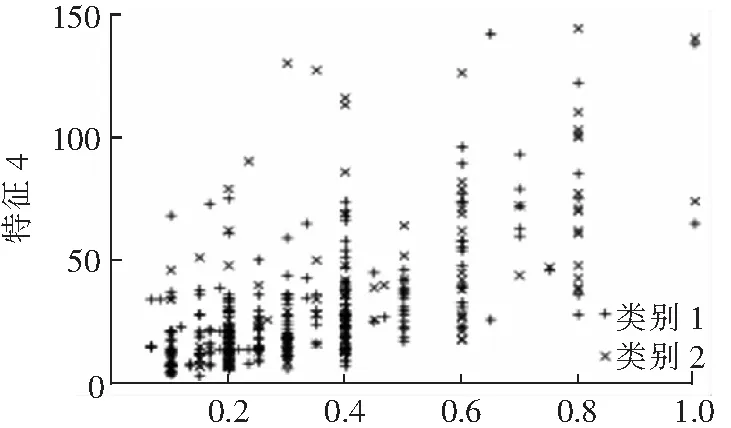
特征2圖3 原始樣本分布
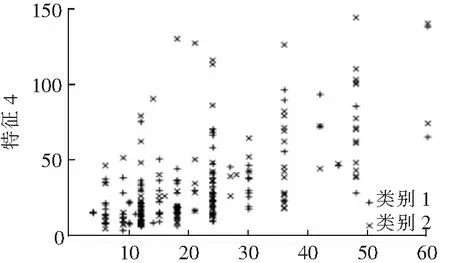
特征2圖4 經FCMUSIC算法處理后的樣本分布
3 實驗分析
3.1 實驗數據集
為了檢驗FCMUSIC算法的分類性能,選取UCI(https://archive.ics.uci.edu/ml/index.php)和KEEl(http://www.keel.es)上的五組不平衡數據集進行實驗,分別是pima、yeast1、haberman、segment0和German Credit Data(以下簡稱german)。5組數據的具體信息如表1所示。
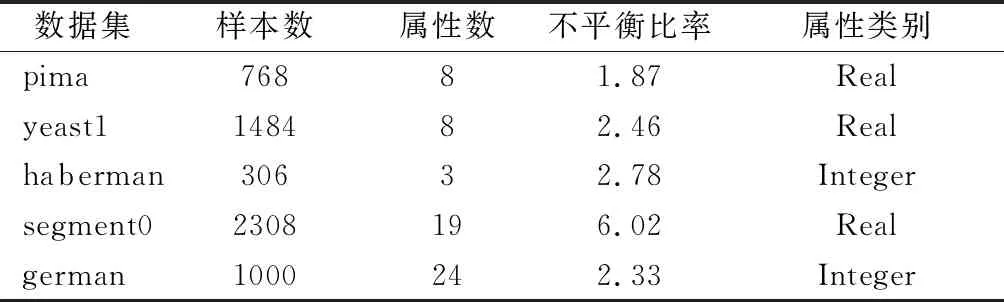
表1 5組數據的具體信息
3.2 實驗環境
實驗環境為64位Windows10 操作系統,Intel Core i5處理器,8GB內存,512G固態硬盤,開發工具使用開源軟件R3.6.0。
3.3 實驗評價指標
性能評價測度是對模型分類效果的一種量度,最為常用的一個測度就是分類正確率,即為分類模型對測試集樣本分類正確的數量與測試集樣本總數之比。對于平衡數據集的分類,分類正確率可以很好地反映出模型的性能,但在不平衡的數據集上,就很難反映出模型的性能高低。假設有一個包含100個樣本的數據集,有90個屬于多數類樣本和10個少數類樣本,分類器只要把這個數據集全部判別為多數類就能保證90%的正確率,但是很顯然,這樣分類沒有識別出少數類樣本,分類表現非常差。因此,對于不平衡數據集,需要采用其它的性能測度來反映分類模型的質量。被廣泛采用的性能測度有查準率Precision 、召回率Recall 、真正率TPR、F-measure,G-mean和 AUC值。
在二分類問題中,分類器對樣本的分類結果有四種情況,通過混淆矩陣展示,如表2所示。

表2 二分類問題的混淆矩陣
根據模糊矩陣,可以計算出對于分類器的性能測度:
分類精度的計算如公式(5)所示:
(5)
分類器的查準率Precision:
(6)
召回率Recall:
(7)
真負率:
(8)
F1度量是對Precision和Recall兩者的一種平衡,如果分類器分類后的Precision和Recall都比較高,F1才會比較高。
(9)
真正率TPR和真負率TNR代表分類器在正類與負類樣本各自的分類精度,G-mean可以來平衡這二者的關系:
(10)
G-mean是TPR和Recall的幾何均值,如果TPR很大但TNR很小,或者TNR很大TPR很小,G-mean都不能取得較大的值,只有當TPR和TNR都較高的時候,G-mean才能取得較大的值,因此,G-mean能較為全面地評價分類器的性能。
ROC 是以假正率 FPR 為 x 軸 ,真正率 TPR為 y 軸繪制的曲線。AUC即為ROC曲線下的面積。AUC 值常用于評價分類器性能,如果AUC值越高,代表著分類器的分類效果越好 。本文采用F1、G-mean、AUC 3種度量作為分類器的評價指標。
3.4 實驗結果分析
為了驗證FCMUSIC算法的綜合性能,采用原始數據直接建模、隨機欠采樣算法RUS、CBUS1算法作為對比組,使用KNN分類器、RF分類器結合欠采樣處理后的平衡數據集進行分類,并設置以下對比組,分別是:不經處理的原始數據、經隨機欠采樣算法(RUS)處理后的數據、文獻[14]中的第一種基于聚類的欠采樣算法CBUS1處理后的數據(CBUS1算法對多數類樣本應用kmeans聚類,并設置聚類簇數等于少數類樣本數,將聚類中心作為欠采樣后的多數類樣本)。然后結合KNN分類器和RF分類器進行分類。KNN的臨近數k值通過交叉驗證法來選擇,先根據經驗指導,選擇比較小的奇數作為k值,然后進行交叉驗證,最終選擇分類結果最好的情況下使用的k值。
關于聚類簇數n的選擇,先使用層次聚類初步確定n可能的取值,觀察得到適合的一個或多個值作為待選的n值,然后把多數類樣本按照不同的n值進行聚類,選擇使分類表現較好的n值。聚類簇數n對實驗結果的影響較大,以pima數據集為例,當聚類簇數取不同的值時,F1、G-mean和AUC的值如圖4到圖6所示。聚類簇數n值的范圍是從2到少數類樣本數。從圖中可以看出,隨著n的增加,F1和G-mean值呈現下降趨勢,AUC的變化總體平緩。在本實驗中,數據集pima、yeast1、haberman、segment0和german各自的n的取值為:8、27、5、3和9。
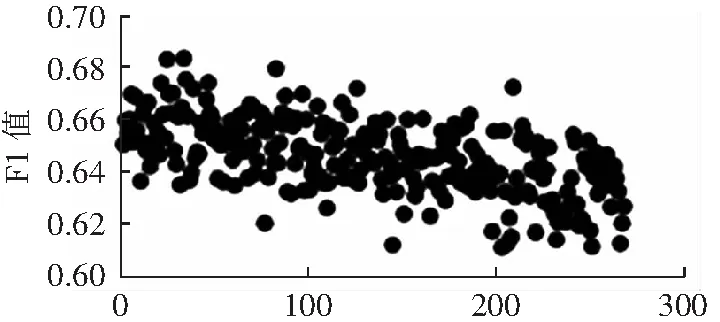
聚類簇數圖5 不同聚類簇數下的F1值
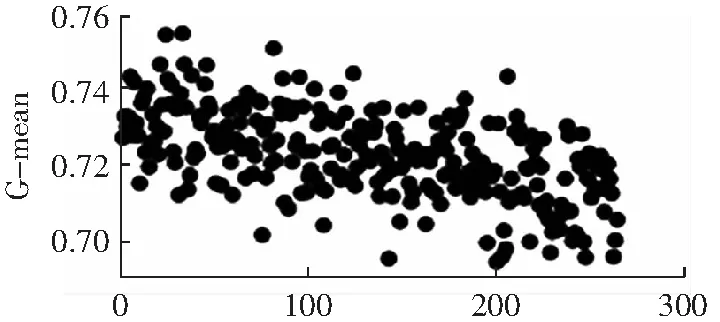
聚類簇數圖6 不同聚類簇數下的G-mean值
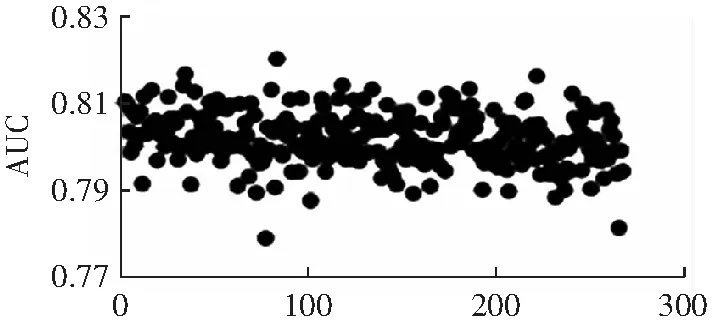
聚類簇數圖7 不同聚類簇數下的AUC值
為了避免偶然性對實驗結果的影響,對各個算法重復進行10次5折交叉驗證并取平均值作為最終的實驗結果。實驗結果如表3和表4所示,每個數據集對應的評價指標的最優值用黑體標出。
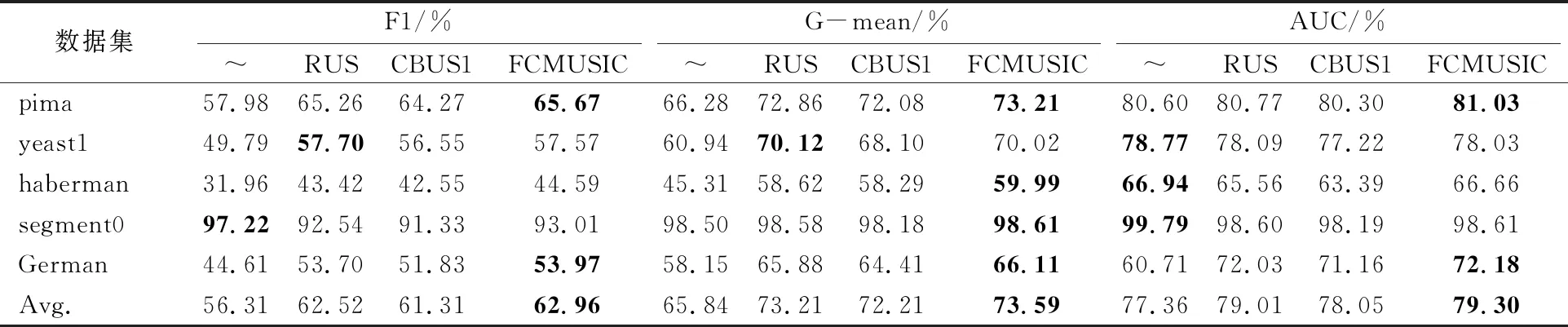
表3 各算法與KNN分類器結合時的分類表現
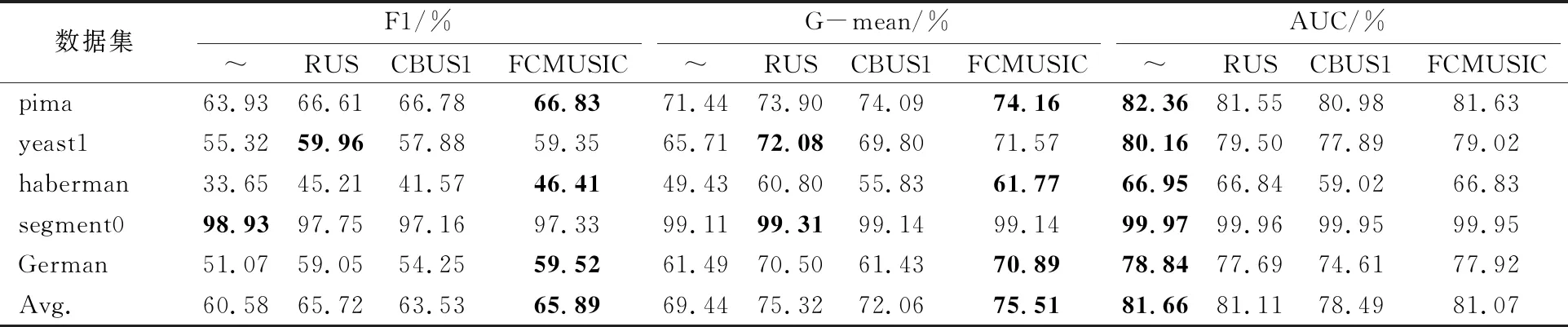
表4 各算法與Random Forest分類器結合時的分類表現
通過比較各個算法的F1、G-mean、AUC值發現,在五組數據的分類度量指標的平均值上,當使用KNN分類器時,FCMUSIC算法的F1值平均提高了6.65%,G-mean值平均提高了7.75%,AUC值平均提高了1.96%;RUS算法在對應指標上分別提高了6.21%、7.37%和1.94%;CBUS1算法分別提高了 5%、6.37%和0.69%。在這些算法中,FCMUSIC算法的提升幅度最大,這也證明了FUCMSIC算法的有效性。 具體表現在對于pima、yeast1、haberman和german四個數據集,FCMUSIC算法和RUS算法、CBUS1算法的整體性能都比原始不平衡數據集有明顯提高,而在segment0數據集上, FCMUSIC算法和其他的欠采樣算法都比直接在初始的不平衡數據集上訓練分類器的總體表現要差,特別是F1值有較大的下降,分析下降的原因,與樣本的分布有關,segment0數據集的多數類和少數類樣本的空間分布具有明顯的區別,傳統的分類器可以直接在不平衡數據集上找到精準的分類超平面,由于segment0數據集的不平衡比率較大,欠采樣的方法會不可避免地丟失多數類的部分信息,使得分類性能有所下降。但FCMUSIC算法比其他算法下降的幅度要小。這也表明FCMUSIC算法具有一定的穩定性。
當各個算法與RF分類器結合時,FCMUSIC算法在各個數據集上的F1值平均提高了5.31%,G-mean值平均提高了6.07%,AUC值則平均下降了0.59%,RUS算法在F1和G-mean值上分別提高了5.14%和5.88%,AUC下降了0.55%,CBUS1算法在F1和G-mean值上分別提高了2.95%,2.62%,AUC下降了3.17%。欠采樣算法比原始數據集建模的AUC值有所下降,但整體分類性能仍然有不同程度的提高。在各個數據集上,FCMUSIC算法的G-mean值比CBUS1算法要高。 FCMUSIC算法的分類結果也表明了該算法具有良好的分類性能。
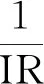
根據實驗結果可以看出,FCMUSIC算法與KNN和RF分類器結合,都提高了分類器的分類性能,表明FCMUSIC算法具有一定的獨立性,不依賴于特定的分類器。就分類器而言,與KNN分類器結合時的提升幅度更大,與RF分類器結合時的分類表現更好。就評價指標而言,在F1和G-mean值上的提升幅度更大。
4 結語
針對傳統分類器在不平衡數據集上分類性能降低的情況,本文結合聚類算法,提出了基于FCM的簇內欠采樣算法——FCMUSIC。FCMUSIC算法能夠有效提升分類器的分類性能,特別是F1值和G-mean值。通過與不同的分類器結合,驗證了FCMUSIC算法的獨立性,與其它欠采樣算法進行對比,驗證了FCMUSIC算法的有效性,表明FCMUSIC算法能夠作為一種有效的欠采樣算法,用來提高分類器對不平衡數據集的分類性能。
猜你喜歡
西北民族大學學報(自然科學版)(2021年4期)2021-12-29 02:54:24
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
學生天地(2019年32期)2019-08-25 08:55:22
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級語數英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
