基于SPSO+SVM 的水稻葉部病害識別方法研究
2022-01-04 02:12:08楊化龍
上海農業學報 2021年6期
關鍵詞:水稻
陳 宇,路 陽*,蔡 娣,姜 峰,楊化龍,2
(1 黑龍江八一農墾大學電氣與信息學院,大慶 163319;2 雞西市公安局,雞西 158100)
北方是我國水稻主要產區,水稻種植過程中常常會出現各種病害,其中以稻瘟病、紋枯病、白葉枯病造成的影響最為嚴重。 這些病害造成水稻品質下降、減產,給種植戶帶來嚴重的經濟損失。 為有效降低損失,需要對病害進行高效正確的識別。 傳統診斷方法主要依靠植物保護專家的經驗,肉眼觀察,存在專家數量不足、主觀性強等缺點。
基于機器學習的水稻病害識別方法目前主要有兩類。 一類方法是基于圖像分割提取病斑特征,通常通過對水稻病斑圖像進行預處理、病斑分割和特征提取實現分類識別,比較典型的方法有增長法[1]、自適應閾值分類法[2]、非監督的顏色聚類識別法[3]、水平集分割法[4]等。 此類方法以水稻病斑的顏色、大小和形態差異為基準,對于光線、圖片質量要求較高,在實用性等方面不強。 另一類方法是基于深度學習的水稻病斑分類識別。 通過深度學習提取水稻病斑的特征,排除了人工提取特征的步驟,對復雜環境下的識別適應性更強。 但基于深度學習的病斑識別準確度與初始訓練樣本的數量和質量成正比,且很難在短期內構建大樣本病害圖像庫。 支持向量機(Support vector machine,SVM)的理論和算法成熟,實用性強,其在語音識別、故障診斷、數據預測等方面取得了一定進展。 支持向量機能夠處理非線性可分數據,具有受非支持向量影響小、泛化能力較好等優點,廣泛應用在農作物病害識別等領域[5-8]。
本試驗以北方寒地采集的水稻葉部病害圖像為研究對象,采用方向梯度直方圖(Histograms of oriented gradient,HOG)提取水稻病害多種特征,并使用交換粒子群算法(Switching particle swarm optimization,SPSO)尋找支持向量機最優參數,最后在matlabR2018a 環境下構建SPSO-SVM 模型并訓練和測試樣本,以提高識別速率和準確性,彌補傳統識別方法的不足。
1 材料與方法
選取3 種危害較大的水稻稻瘟病、紋枯病、白葉枯病作為研究對象。 水稻病害葉片均在自然光下使用手機拍攝,照片像素為1 312 px×1 104 px。 每種病害選擇100 幅圖像作為樣本,每幅圖像采用JPG 格式存儲。 采集的原始水稻病害圖像如圖1 所示。

圖1 3 種水稻葉部病害圖像Fig.1 Images of 3 kinds of rice leaf diseases
2 水稻葉部病害圖像預處理
水稻病害圖像采集的過程會受到各種因素影響,導致樣本圖像有噪聲、病斑邊緣部分模糊等問題。中值濾波是基于排序統計理論的一種能有效抑制噪聲的非線性信號處理技術[9-10]。 其原理是把數字圖像或數字序列中一點的值用該點的一個鄰域中各點值的中值代替,從而消除孤立的噪聲點。 二維中值濾波輸出為:

其中,f(x,y)、g(x,y)分別為原始圖像和處理后圖像,W為二維模板。 本試驗用5 ×5 的二維滑動模板,模板內像素按照單調上升排序,濾波降噪后圖像如圖2 所示。

圖2 3 種水稻葉片病害分割的病斑Fig.2 Disease spot segmentation of 3 kinds of rice leaf diseases
3 水稻病斑特征提取
方向梯度直方圖(HOG),是用梯度的方向密度來描述圖像局部特征。 通過計算和統計圖像局部區域的梯度方向直方圖來構成特征,具有幾何和光學形變的不變性[11-13]。 本試驗中提取HOG 特征步驟如下:
(1)對圖像進行gamma 校正,歸一化圖像。 由于圖像的顏色信息對于方向梯度直方圖特征沒有影響,因此對濾波后的灰度圖像進行平方根gamma 壓縮,歸一化特征向量。 這種壓縮處理有效降低了圖像局部的陰影和光照變化。
(2)求出圖像水平垂直梯度分量。 首先用一維離散微分模板[-1,0,1]及其轉置分別對gamma 校正過的水稻葉部圖像進行卷積運算,得到水平方向的梯度分量以及垂直方向的梯度分量。 通過像素點的垂直梯度和水平梯度,計算當前像素點的梯度幅值和梯度方向,如公式(2)—(5)所示。

其中,Gx(x,y)、Gy(x,y)、H(x,y)分別表示當前像素點的水平梯度、垂直梯度和像素值。G(x,y)、α(x,y)分別為當前像素點的梯度幅值和梯度方向。
(3)建立梯度方向直方圖。 對尺寸為64 px×128 px 的水稻葉部病害圖像進行分割,分為8 ×16 個網格,每個網格的像素為8 px×8 px。 梯度方向范圍為[0,π],平均分成9 個區間梯度方向,20°為一個區間,加權投影每個像素梯度直方圖,建立每個網格對應的9 維向量。
(4)合成塊,歸一化塊內梯度直方圖。 每兩個2 ×2 網格合成一個塊,每個塊對應36 維特征向量。 水稻葉部病害圖像的光照變化以及前后背景對比度差異,會導致梯度強度變化范圍巨大,需要消除負面影響,最后進行歸一化處理,如公式(6)所示。

其中,v是未經歸一化的描述子向量,是v的2 范數,ε是一個極小的常數。
(5)特征收集。 如圖3 所示,使用滑動窗口法對水稻葉部病害圖像進行掃描,以1 個網格為1 個掃描步長,8 ×16 個網格需要7 個水平方向掃描窗口和15 個垂直方向掃描窗口,塊之間會產生重疊,串聯所有歸一化后的塊,最后得到36 ×7 ×15 =3 780 維特征向量。
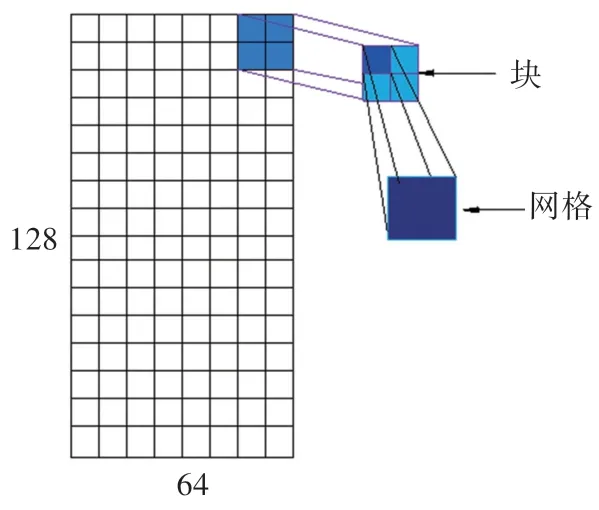
圖3 HOG 特征提取Fig.3 HOG feature extraction
4 基于支持向量機的水稻病害識別
水稻葉部病害特征復雜,特征維數大大多于樣本數,樣本數據線性可分。 因此,本試驗采用基于核函數支持向量機(SVM)進行訓練和分類識別。 支持向量機算法的基本思想是在特征空間中找到最優的分離超平面,使訓練集上的正負樣本間隔最大化。 假設訓練樣本集T={(xi,yi),i=1,2,…,N},其中xi∈Rn,yi∈R,N是訓練樣本的大小,超平面的描述如下:

其中ω為權向量,b為偏移向量,偏移向量決定了超平面與原點平面的距離。 引入松弛變量ξi和定義優化問題如下:
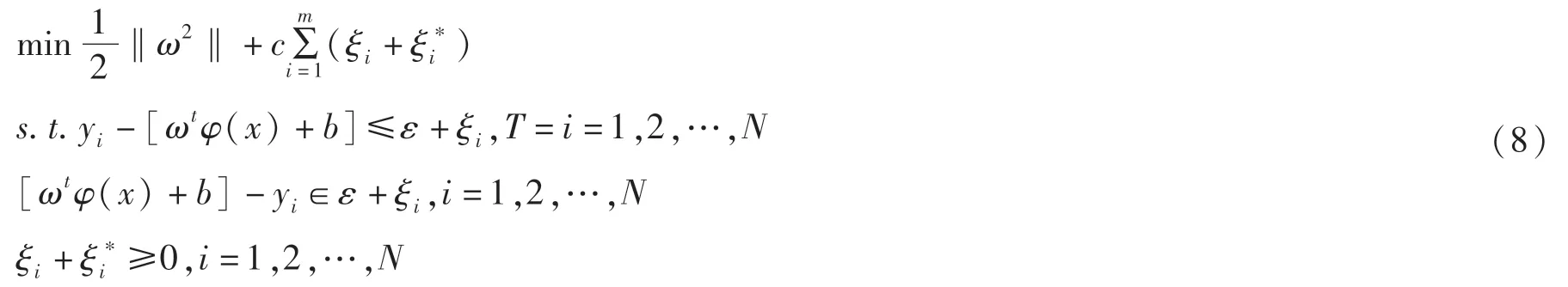
其中,c是懲罰參數,ξi和是非負松弛變量。 通過引入拉格朗日乘數,將公式(8)轉化為二元形式,具體如下:


為了避免空間災難問題,通常將核函數φ(xi)φ(xj)替換為k(xi,yi)的radial 核函數,核函數的基本作用就是接受兩個低維空間里的向量,能夠計算出經過某個變換后在高維空間里的向量內積值。 本試驗采用radial 核函數,即徑向基核函數,公式為:

5 交換粒子群算法對支持向量機參數進行優化
粒子群優化算法(Particle swarm optimization,PSO)源于對鳥群捕食的研究,其基本思路為:通過群體中個體之間的相互協作和信息共享來尋求最優解。 PSO 的優勢在于簡單容易實現并且沒有過多參數的調節。 目前廣泛應用于函數優化等各種領域[14]。 粒子群算法通過一群初始化隨機粒子,通過迭代尋找最優解,粒子通過公式(13)、(14)進行速度更新和位置更新:

式中:i=1,2,…,N,N是粒子總數。υi是粒子的速度。 rand():介于(0,1)之間的隨機數。xi:粒子當前位置。c1,c2:學習因子,通常c1=c2=2。υi的最大值為υmax(大于 0),如果vi大于vmax,則vi=vmax。 以公式(13)、(14)為基礎形成粒子群算法標準公式,如公式(15)所示:
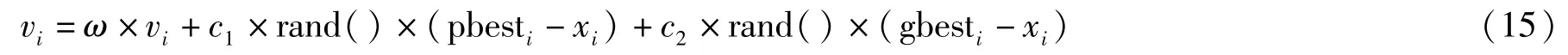
ω為慣性因子,其值較大時,全局尋優能力強,局部尋優能力弱;其值較小時,全局尋優能力弱,局部尋優能力強。 動態ω能獲得比固定值更好的尋優結果。
PSO 算法具有在執行優化任務時易于實現和快速收斂等優點,但存在早熟收斂、不一致收斂到全局最優問題,為了克服這一局限性,本試驗采用改進算法:交換粒子群算法對支持向量機的參數進行優化。
支持向量機中比較重要的參數有兩個:c和γ,c是懲罰因子,即對誤差的寬容度,可與任意核函數搭配,c系數越高,表示不能允許誤差出現,但是容易過擬合;c系數越小越容易出現欠擬合。c過大或者過小都會導致SVM 泛化能力變差。γ是徑向基核函數自帶的一個參數,隱含地決定了當數據被映射到新的特征空間后的分布,當γ值較小,支持向量較多,當γ值較大,支持向量則較少。 支持向量的多少會大大影響支持向量機的訓練和預測速度[15]。
在交換粒子群算法中,通過引入具有馬爾可夫交換參數的模式相關速度更新方程,以克服局部搜索和全局搜索之間的矛盾。 通常在搜索早期,群體中的粒子保持其獨立性和群體多樣性,這樣有助于擴大搜索范圍并避免過早收斂到局部最優。 在搜索過程的后期,所有群可能會收斂到最佳粒子,以獲得更準確的解決方案。 粒子的速度和位置根據公式(16)、(17)更新:
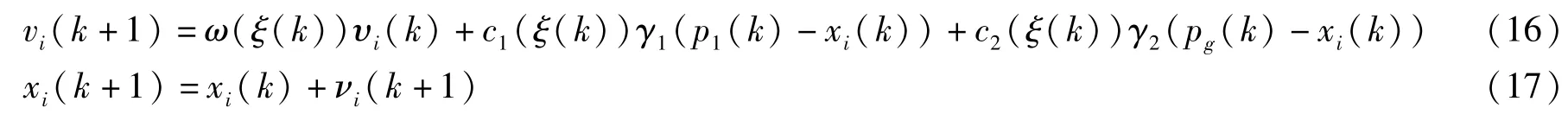
式中,ω(ξ(k))、c1(ξ(k))和c2(ξ(k))是慣性權重和加速度系數,都依賴于馬爾可夫鏈。 設ξ(k)為馬爾可夫鏈,它在有限狀態空間S={1,2,…,N}中具有概率轉移矩陣即從i到j的轉移速率和可以通過當前搜索信息進行調整,以平衡全局和局部搜索能力,如公式(18)所示:

其中,S為群大小,|L|為搜索空間中最長對角線的長度,D為目標問題的維數,xid為第i個粒子的第d個值為整個群中平均點ˉx的第d個值,可通過公式(19)計算:

利用交換PSO 優化算法對SVM 兩個重要參數求解最優值,優化流程為:首先初始化粒子群位置與速度,設定核函數參數的初始參數數值,計算每個粒子的適應度,根據適應度更新當前Pbest、Gbest,更新粒子的位置和速度,直到找到粒子最優解Pbest 和種群最優解Gbest,最后最優解Gbest 即為需要的最優參數。 交換PSO 偽代碼見表1,交換PSO 優化SVM 參數流程如圖4 所示。
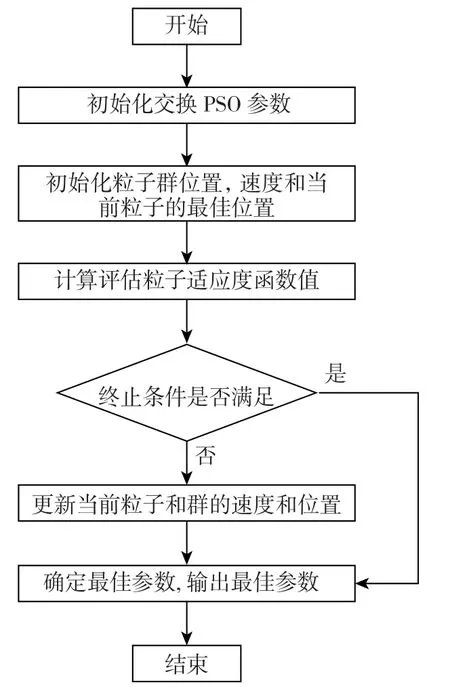
圖4 交換PSO 算法優化SVM 參數流程Fig.4 Optimization of SVM parameters flow by switching PSO algorithm

表1 交換PSO 偽代碼Table 1 Switching PSO pseudo code
6 試驗與分析
對于3 種常見水稻葉部病害稻瘟病、紋枯病、白葉枯病,每種病害各取100 幅圖像進行病害識別,取其前70 幅總計210 幅圖像作為訓練圖像集,剩余圖像作為測試圖像集。 對樣本的圖像進行預處理,使用HOG 進行特征提取。
定義交換 PSO 參數:交換 PSO 粒子數設置為20個,最大迭代次數設置為50,學習因子c1設置為1.6,c2設置為1.5,慣性權重ω 設置為0.6,懲罰參數與核函數參數范圍為[0.1,1 000]。 迭代結果如圖5 所示。 構建SVM 模型,使用HOG 提取的特征構造訓練集進行訓練和識別,水稻葉部3 種病害的識別結果如表2 所示。
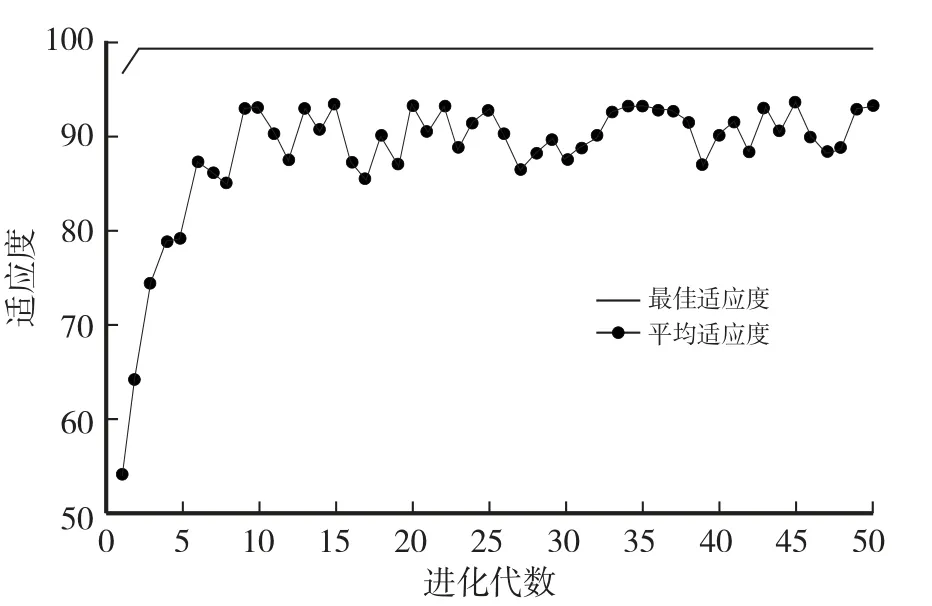
圖5 SPSO 優化結果Fig.5 SPSO optimization results

表2 3 種水稻葉部病害識別結果Table 2 Identification results of 3 kinds of rice leaf diseases
從表2 可以看出,當定義SVM 模型參數c和γ值為78 和0.3,3 種水稻葉部病害平均識別率為88.2%,訓練時間為1 084 s。 利用PSO 算法優化SVM 模型參數得到c和γ值為100 和0.7,此時參數c達到最優,3 種水稻葉部病害平均識別率為89.3%,訓練時間減少323 s。 利用SPSO 算法優化SVM 模型參數得到c和γ的最優值為100 和0.4,不僅3 種水稻葉部病害平均識別率最高,達到93.2%,而且訓練時間最少,僅為459 s。
7 結論
基于交換粒子群算法優化后的支持向量機對3 種水稻葉部病害進行識別,取得了較好的識別效果。首先采用中值濾波對3 種水稻葉部病害樣本圖像進行預處理,并采用方向梯度直方圖構建特征向量數據庫,然后構建支持向量機,利用交換粒子群算法選取最優支持向量機參數,通過驗證,平均識別率為93.2%。 該算法與不進行優化的支持向量機和僅用基本粒子群優化的SVM 相比,訓練速度更快,泛化能力更強,而且所需的訓練樣本需求數量遠遠小于深度學習方法,可為水稻病害識別診斷提供新的思路。
猜你喜歡
幼兒100(2023年39期)2023-10-23 11:36:32
青少年科技博覽(中學版)(2022年6期)2022-12-27 19:44:27
中國土壤與肥料(2021年5期)2021-12-12 02:02:11
今日農業(2021年21期)2021-11-26 05:07:00
軍事文摘(2021年22期)2021-11-26 00:43:51
今日農業(2021年14期)2021-10-14 08:35:40
金橋(2021年7期)2021-07-22 01:55:38
今日農業(2020年20期)2020-11-26 06:09:10
文苑(2020年6期)2020-06-22 08:41:52
文苑(2019年22期)2019-12-07 05:29:00
