基于多特征融合的Webshell惡意流量檢測方法
2022-01-18 08:25:12李源王運鵬李濤馬寶強
網絡與信息安全學報 2021年6期
李源,王運鵬,李濤,馬寶強
(四川大學網絡空間安全學院,四川 成都 610065)
1 引言
隨著Web應用的爆炸式增長,Web應用系統遭受攻擊的事件越來越多,帶來的損失和影響也越來越大。據中國產業互聯網發展聯盟公布的《2019中國主機安全服務報告》[1]顯示,2019年中國境內企業用戶服務器感染病毒木馬事件超過百萬起。其中Webshell惡意程序感染事件占73.27%。從攻擊者的角度看,植入Webshell是攻擊者進行持續滲透的基礎和前提。因此,為了保障Web服務器的安全,Webshell檢測顯得尤為重要。Apache是目前應用最普遍的Web應用系統[2],在Web應用方面具有最為廣泛的代表性,因此本文以Apache服務器上的Webshell檢測為研究和實驗對象。
針對Webshell的檢測主要有3個研究方向:基于文本的靜態檢測方法、基于Web日志的事后檢測以及基于通信流量的檢測[3]。在基于文本的靜態Webshell檢測研究中,研究者主要從代碼層面上對惡意程序進行檢測,常用的檢測方法是檢查程序中是否包含Webshell執行時所需的系統函數[4],此方法檢測效率高,但難以識別經過混淆加密后的Webshell。為了對抗混淆的Webshell惡意代碼,Ai等[5]提出使用PHP VLD插件獲得PHP程序編譯時產生的字節碼,并經N-gram分詞后生成的執行序列作為區分正常文件和Webshell文件的檢測特征,此模型對基于PHP語言的Webshell有較好的檢測效果,但對于其他語言編寫的Webshell,不能提取其編譯時的字節碼,因此無法檢測。崔艷鵬等[6]提出使用信息熵、最長單詞、重合指數、壓縮比等統計特征作為區分正常和惡意程序的特征,該方法能夠在一定限度上識別經過加密混淆后的Webshell文件,但通常需要配合其他方法一同檢測以防止產生誤報。Li等[7]提出使用神經網絡模型GRU代替人工提取特征,但該方法在對文件進行分詞時并未考慮代碼經過編后(如base64編碼)仍可能出現詞向量維度過大導致訓練難度增加、效率降低的問題;基于Web日志的事后檢測是在攻擊發生后通過對Web應用運行日志進行分析、溯源,以檢測Webshell通信行為[8],但由于Web日志本身屬于格式化處理后的文件,信息丟失較多,因而檢測效果有限;在基于通信流量的檢測研究上,研究者常采用對實時流量進行捕獲分析來挖掘通信過程中可能存在的Webshell惡意流量。2018年,Yang等[9]采用基于4-gram分詞的SVM算法對數據包中的URL請求路徑和請求體進行訓練以識別數據包中的惡意流量;Zhang等[10]選擇使用CNN+LSTM神經網絡組合模型對數據包整個請求包載荷的ASCII序列進行訓練生成分類模型,以實現對Webshell惡意流量的檢測,而由于在訓練過程中加入過多與流量識別無關的信息,因此檢測效率不高。此外,這兩種基于通信流量的檢測方法均只能完成對正常或惡意流量的二分類檢測,未能對Webshell惡意流量屬于何種攻擊類型做出判斷,不利于有針對性的Web防御和加固。
總的來說,以上3種檢測方法,難以高效、精確地對Webshell進行檢測和分類,并不能有效阻止通信過程中Webshell行為所造成的危害。因此本文從Web通信流量出發,以多源視角提取不同維度的靜態特征,并通過特征融合和算法集成的方式來挖掘網絡流量中可能存在的Webshell惡意通信行為。主要貢獻如下。
1) 提出了一種基于多特征融合的檢測方法,融合了不同維度的數據流特征,彌補了單一特征識別能力不足的問題,能夠在不同類型的Webshell的識別上都有較高的檢測能力,進一步細化不同種類的Webshell攻擊。
2) 提出基于集成學習的Webshell分類模型,通過結合不同學習器各自的優勢生成分類模型,降低模型在Webshell多分類情況下出現誤報的概率。
2 多特征融合檢測方法
2.1 檢測框架
Webshell惡意流量檢測模型的總體框架如圖1所示,包括數據預處理、特征提取和異常檢測3個階段。
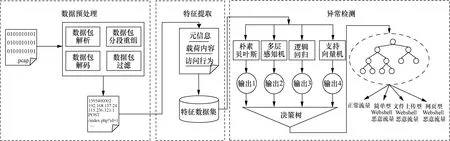
圖1 Webshell惡意流量檢測模型的總體框架Figure 1 Webshell malicious traffic detection model framework
(1)數據預處理
對采集到的原始流量進行解析后依次過濾非正常響應、媒體資源文件的數據包,并對通信過程中產生的分段數據包按五元組<源IP,源端口,目的IP,目的端口,協議>將相同的源和目的IP地址合并為一次的完整通信會話,并生成文本向量用于特征提取。
(2)特征提取
對原始流量進行預處理得到的文本向量,從數據包元信息、數據包載荷內容以及流量訪問行為3個維度提取特征,并將融合后的特征向量作為特征數據集。
(3)異常檢測
將融合后的特征數據集輸入至包含4個初級分類器和1個次級分類器的Stacking集成模型并保存模型參數,通過模型對未知流量進行識別分類,以實現對具體攻擊類型的分類。
2.2 數據預處理
數據預處理模塊主要由數據包解析、數據包分段重組、數據包解碼以及數據包過濾4部分組成。數據包解析主要完成對捕獲的二進制流量按網絡協議進行逐層解析,生成可讀的網絡封包的詳細信息以供特征提取階段使用;數據包分段重組主要完成對來自同一個數據包產生的分段數據包的重組;數據包解碼主要完成對編碼后的數據進行數據還原;數據包過濾主要采用文件頭標識來處理數據流中的多媒體資源文件,以避免其中的不可見字符對模型訓練造成干擾。
2.2.1數據包解析
本文主要使用基于Python編程語言的數據包解析工具Scapy庫[11]對采集的網絡流量進行處理。Scapy庫是一個功能強大的數據包處理工具,利用該工具可以輕松實現發送、嗅探、解析和偽造網絡數據包。本文使用Scapy解析并提取數據包字段(時間戳、請求類型、確認號、序列號、源IP地址、目的IP地址、有效載荷、數據包大小等)。對取值為離散值的字段需要其進行編碼,如請求類型字段為:GET、POST等,則對應編碼為GET=1,POST=2。
2.2.2數據包分段重組
當發送端發送的數據包長度大于通信雙方協商的每一個報文段所能承載的最大數據長度MSS(maximum segment size)時,需要對數據包進行分段傳輸,產生多個具有完整首部的TCP報文段。為了在接收端將來自同一個數據包產生的多個報文段進行重組還原,本文首先將捕獲到待重組報文段按照序列號由小到大排列得到[seqk1,seqk2,…, seqk n]。對于序列號為seqi的報文段,其TCP長度為TCP - payloadi,則下一個分片序列號為seqi+ TCP - payloadi。以此類推,可將所有來自相同數據包產生的報文段按順序拼接完成。
2.2.3數據包解碼
當發送端發送請求包中的請求地址字段包含特殊字符時,根據RFC 3986協議[12]規定,需要在數據傳輸前對其進行編碼,具體操作為使用百分號和對應的ASCII值進行替換。因此,對于經過編碼后的請求地址字段內容,如:“/index?id=shop%23name”,需要進行解碼得到原始請求字段內容為“index?id=shop#name”。
2.2.4數據包過濾
為了縮短模型在預處理階段所花的時間,同時避免數據流中的不可見字符影響模型訓練效果,需要對采集到的網絡流量依據數據類型進行過濾,其中一部分是頁面加載時的靜態資源文件(如html、js、css)等,另一部分主要是圖片、音視頻等非文本類型的數據。針對這兩部分數據,在數據包過濾時主要根據數據包中的請求資源定位符來過濾掉非PHP文件。但已有研究表明,存在將Webshell藏在圖片的末尾形成“圖片馬”以繞過目標服務器防護設備檢查的攻擊手段,因此對于PNG、JPEG等格式的圖片文件,主要通過文件頭尾標識符定位來處理。文件頭標識符是以二進制形式存于文件開頭一段區域的數據,該數據對應每一種文件類型。常見的多媒體資源文件同樣擁有獨一無二的文件頭信息,如PNG格式圖片的文件頭尾標識符分別為0x89 50 4E 47 0D 0A 1A 0A和0x49 45 4E 44 AE 42 60 82。因此,通過識別數據流中的文件標識符,進而定位到多媒體資源文件的首尾并對其中部分進行過濾,即可提取出插入文件末尾的Webshell,處理示意如圖2所示。
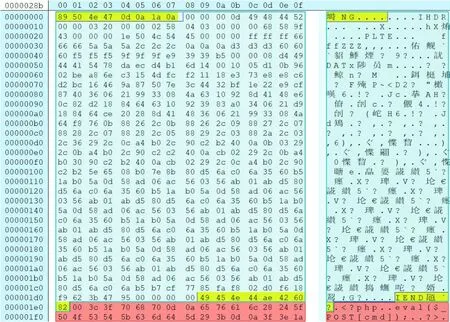
圖2 文件頭尾標識符處理“圖片馬”Figure 2 Use file header-tail identifier to process “picture horse”
2.3 特征提取
為了對不同類型的Webshell惡意流量進行準確識別,需要提取有關流量的各方面特征,并將其序列化表示輸入分類器中。按照業界對Webshell惡意程序的功能以及攻擊影響進行劃分,可分為3種類型。
定義1簡單型Webshell程序,俗稱“一句話木馬”程序,指僅提供基本命令執行功能的Webshell程序,代碼結構簡單。
定義2文件上傳型Webshell程序,俗稱“小馬”程序,指功能單一且不包含命令執行功能的惡意程序,通常作為跳板程序用于上傳其他惡意文件。
定義3網頁型Webshell程序,俗稱“大馬”程序,指具有人性化操作界面、包含多種攻擊手段的Webshell程序,代碼結構復雜,功能多樣。
具體而言,簡單型Webshell程序通常不包含其他功能代碼,命令執行時還需上傳完整的執行代碼,并由攻擊者通過HTTP直連或Webshell客戶端進行傳輸;文件上傳型Webshell程序通常被應用在目標服務器對上傳文件大小進行限制時,首先被上傳至服務器作為跳板程序,進而上傳其他包含惡意代碼的Webshell程序用以規避服務器審查;網頁型Webshell程序通常將所有的功能代碼整合到Webshell文件中,且包含大量頁面元素構成操作界面。針對各類型Webshell程序工作原理的不同,本文主要從數據包元信息、載荷內容和通信行為3個方面進行特征提取,提取的主要特征如下。
2.3.1數據包元信息
數據包元信息是指通信雙方在進行通信時需按照TCP/IP規定的方式構造網絡數據包,這些字段可直接從解析后的數據包中采集得到,本文利用第三方工具Scapy完成對數據包的解析,主要提取本文需要的相關字段信息如下。
1) 請求包載荷長度:該字段反映了源主機向目標主機發送請求報文時所攜帶的數據長度。在Webshell通信過程中,攻擊者在發送攻擊載荷時通常為了規避入侵檢測工具(IDS)等設備檢測,將請求載荷進行混淆加密處理進而導致載荷變長,因而當網絡中出現較長請求載荷時則可能存在Webshell惡意通信行為。
2) 請求包請求參數個數:該字段反映了攻擊者對請求載荷進行變換處理后,攻擊載荷被分割為多段,最后在攻擊載荷到達目標服務器后進行重組,此過程需要多個請求參數用于存儲和拼接請求載荷,因而導致請求包中請求參數個數增加。
2.3.2載荷內容特征
Webshell通信過程的本質是發送命令和執行命令,攻擊者發送給Webshell程序的危險命令通常存儲于數據包的有效載荷中,本文從請求、響應包的有效載荷中提取以下特征。
1)請求包命令執行函數:在基于PHP腳本語言編寫的Webshell程序中,由于攻擊載荷需要通過PHP腳本語言進行語法解析和編譯器執行,因而PHP語言中涉及危險系統命令的執行函數均可能成為攻擊者進行遠程命令執行所調用的函數[13],如在冰蝎Webshell客戶端中,當客戶端首次連接被植入PHP語言編寫的Webshell的受害服務器時,默認會執行phpinfo函數。表1給出PHP語言中的危險函數。
一般認為,當數據包請求載荷中出現了表1中的危險功能函數,則在一定限度上認為該網絡可能存在Webshell惡意通信行為。

表1 PHP語言中的危險功能函數Table 1 Unsafe PHP function details
2)請求包參數轉移概率系數:狀態轉移概率[14]是描述模型在各個狀態間轉換的概率。在正常業務中,為了方便程序維護,在各類表單請求參數時大多選取與業務相關且具有較高可讀性的參數。抽象成數學可以理解的語言,正常業務中的參數名轉移概率系數偏高,而在Webshell程序中程序變量名的選取較為隨機,因此轉移概率系數偏低。計算一個字符串觀測序列的概率分布如式(1)所示。
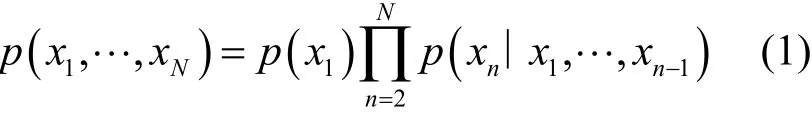
其中,p(1x)表示字符串中每一個字符出現的概率。當給定的字符串符合語言規律,則計算得到的轉移概率值較高,而不符合可讀性的概率則較低。因此,請求包中參數名的轉移概率系數大小可以作為區分正常流量與Webshell惡意流量的特征之一。
3)請求包載荷信息熵:信息熵的概念最初由香農提出,用于研究傳輸信息中的信息量大小。請求包載荷信息熵值反映了請求報文中載荷內容的混亂程度。在Webshell通信過程中,攻擊者往往對攻擊載荷進行填充、加密等變換,導致載荷的字符空間混亂程度增加即信息熵增大,因而通過計算請求載荷的信息熵大小是否偏離正常水平可在一定限度上認為該網絡中出現Webshell惡意通信行為。信息熵計算公式為
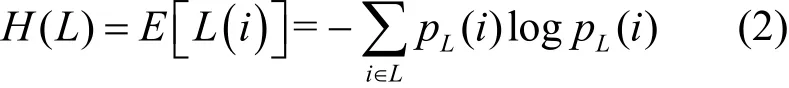
其中,L為請求包的載荷內容,p L(i)為載荷中每個字符發生的概率。當計算得到的信息熵值越大,則表明該載荷所包含的信息量越大,字符串呈現出無序、不確定性,因而被判定是攻擊載荷的可能性越高。
4) 響應包title標簽內容:通過對大量樣本進行分析,在網頁型Webshell程序中,由于這類惡意程序通常采用編程語言——HTML(hypertext markup language)來實現人性化操作界面,且在代碼的title標簽內包含該惡意程序的名稱(如WSO、b374k、r57等)。因此提取的響應包中的title標簽內容,也可作為區別正常業務流量和Webshell惡意流量的特征之一。
5) 響應包網頁標簽個數:正常業務通信的響應包中通常包含動態腳本程序生成的頁面,頁面主要由HTML語言中的標簽構成。而簡單型Webshell程序通常只包含腳本語言(如PHP編程語言)編寫的惡意代碼,在遠程執行命令過程中響應頁面不包含HTML標簽。因此,當網絡中出現不包含HTML標簽的響應內容時,則可認為網絡中可能存在Webshell惡意通信行為。
2.3.3 通信行為特征
正常HTTP請求與Webshell通信時存在明顯的行為差異,因為Web服務器中的正常業務均可被不同用戶訪問,但Webshell程序的資源訪問地址只由攻擊者可知,因而在訪問行為上呈現單一用戶短時間內頻繁訪問現象。因此,本文從通信行為角度提取如下特征。
1) 頁面對外開放度:該特征反映了某一URL地址在一段時間內被不同IP地址主機進行訪問的程度。對于采用B/S架構的Web應用程序而言,當正常業務被部署至互聯網中可被任何連接到互聯網中的主機進行訪問,因而該正常頁面的對外訪問度較高。而對于被植入服務器中的Webshell程序而言,通常該后門程序的訪問地址只由攻擊者已知,因而該后門程序的頁面對外開放度水平較低。因此,某一頁面的對外開放度可作為區分正常業務和惡意后門頁面的特征之一。
2) 頁面訪問頻率:該特征反映了某一URL地址在一段時間內被同一IP地址訪問的頻率大小。正常用戶訪問服務器上的資源文件時通常不會過長時間停留于單個頁面,且由于現在大部分正常頁面采用HTML配合JavaScript、CSS(cascading style sheets)等語言進行頁面優化,使得單次訪問中必不可少地有資源文件被訪問和下載。而攻擊者遠程連接Webshell惡意程序過程中由于只需要接收命令和執行命令,因而該Webshell頁面的訪問頻率高于正常水平。因此,某一頁面訪問頻率可作為區分正常業務訪問和Webshell惡意訪問的特征之一。
2.4 集成學習檢測模型
對上述提出的諸多特征,如果僅用單一學習器對特征構成的特征矩陣進行訓練,由于各決策器在設計之初存在各自優勢和缺點,可能訓練得到的分類器出現較高的偏差或方差的現象,并且在應對未知樣本時泛化性能較差。集成學習在實際生產環境下發揮重要作用,通過結合多個模型力圖在海量數據中獲得多樣且準確的模型[15]。并結合不同單一弱分類器在各類數據上的表現構造出強分類器,以獲得高檢測率和低誤報率,并且能夠用于檢測未知的Webshell惡意流量。
本文采用基于Stacking集成策略來構建分類模型,這是一種通用的通過訓練分類器來結合個體分類器的方法。此時,個體分類器被稱為初級學習器,結合器被稱為次級分類器。在本文中,初級學習器應該選取預測性能優秀的機器學習模型,更重要的還需要保證模型間的多樣性[16],在分析個體學習器的單獨預測能力,并全面比較個體學習器的組合效果后,本文從基于Python的Scikit-learn庫[17]所提供的封裝分類器中選取了4種典型機器學習算法:邏輯回歸(LR,logistic regression)、樸素貝葉斯(NB,naive bayes)、支持向量機(SVM,support vector machine)、和多層感知機(MLP,multilayer perceptron)算法作為初級分類器,次級學習器一般選取穩定性較好的簡單模型,起到整體提升模型性能的作用,本文選擇決策樹(DT,decision tree)算法作為次級分類器,并采用Stacking集成策略對各層學習器進行結合。本文中相關算法及參數設置如下。
1) LR:這是一種基于距離分類超平面的離散選擇模型,具體如式(3)。
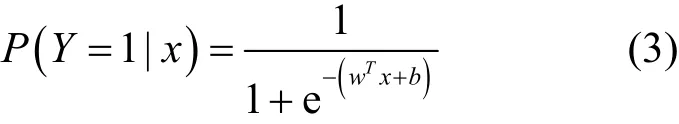
其用距離度量判斷該數據流是否為Webshell惡意流量的概率大小。在本文中懲罰項選擇L2,懲罰因子為1.0,損失函數優化算法選擇坐標軸下降法。
2) NB:對測試樣例x進行分類時,學習算法可構建概率模型來選取具有最大后驗概率值的y作為輸出,如式(4):
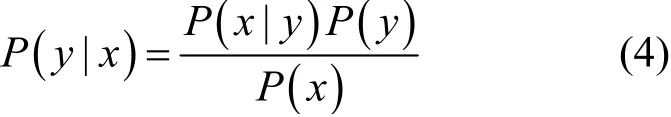
3) SVM:SVM分類器主要借助核函數將特征向量映射到高維線性可分空間,并依靠邊界樣本來建立需要的分離曲線。本文選擇的核函數徑向基函數(RBF),其中懲罰系數C為1.0,誤差精度0.01。
4) MLP:一種前饋神經網絡,模型通過定義多個前向反饋的隱藏層來克服單個感知器的局限性,本文的反饋函數是基于符號的函數σ(x) =[1+e-x]-1,具體如式(5)。

其中,權重參數ω和偏置參數b可通過訓練數據不斷訓練得到。本文隱藏層數量為2,神經元數量為50,使用擬牛頓方法(L-BFGS)來優化模型參數權重,正則化項參數0.000 1。
5) DT:通過特征選擇算法從訓練集中依次選擇最優特征來建立分裂點并逐步迭代生成樹。常見的決策樹算法有ID3、C4.5和CART等。本文次級學習器選擇使用Gini系數用于特征選擇的CART算法,其中構建樹的最大深度為6。
本文采用的基于Stacking集成策略實現方法如圖3所示,網絡輸入包含n個數據包的訓練集D= {(xi,y i) ,i=1,2,…,n}和m個數據包的測試集T={(xj,y j),j=1,2,…,m},其中,xi和xj表示數據包的特征向量,yi和yj為該數據包的真實標簽。為防止第一層初級分類器在訓練集上訓練模型導致過擬合問題,本文采用5折交叉驗證方法對訓練集隨機分成D1,D2,…,D5,定義Dk和表示第k折交叉驗證的驗證集和訓練集,對于每一個初級分類器l(l= 1,2,3,4),數據集被用于生成訓練模型對生成的模型在數據集Dk和測試集T上進行預測得到對每輪交叉驗證中驗證集Dk的預測值sil按行進行拼接生成用于次級分類器的訓練樣本si=( (si1,…,si n),yi),對每輪交叉驗證中測試集T的預測值sjl取平均值生成用于次級分類器的測試樣本最終利用l個初級分類器產生的訓練集和測試集訓練次級分類器得到最終的Webshell惡意流量集成模型。
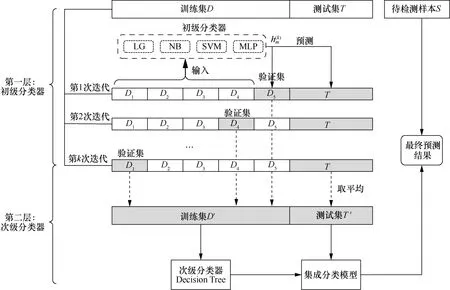
圖3 基于Stacking集成策略的實現方法Figure 3 Implementation method of ensemble learning structure based on Stacking
3 實驗與分析
3.1 實驗環境和實驗數據
本文實驗在四川大學網絡靶場進行。本文的數據集分為正常流量和惡意流量兩部分,并按照8:2的比例隨機劃分為訓練集和測試集。其中惡意流量的獲取主要來自網絡開源倉庫Github中下載量最高的11個倉庫(如tennc/webshell、ysrc/webshell-sample等),約2 000個惡意樣本按圖4所示的網絡拓撲結構部署后仿真采集得到。在采集到8萬條以上基于HTTP協議的惡意流量中,按照Webshell類型篩選出3萬條以上(不包括非正常響應以及媒體資源文件)確定具有惡意行為特征的數據分組。其中,簡單型木馬流量約占18%,網頁型木馬流量約占80%,文件上傳型木馬流量約占1.1%。正常流量的獲取來源于某安全公司的業務流量,經人工篩選后對數據打上正常標簽。仿真數據集具體信息如表2所示。

表2 仿真數據集Table 2 Simulation dataset
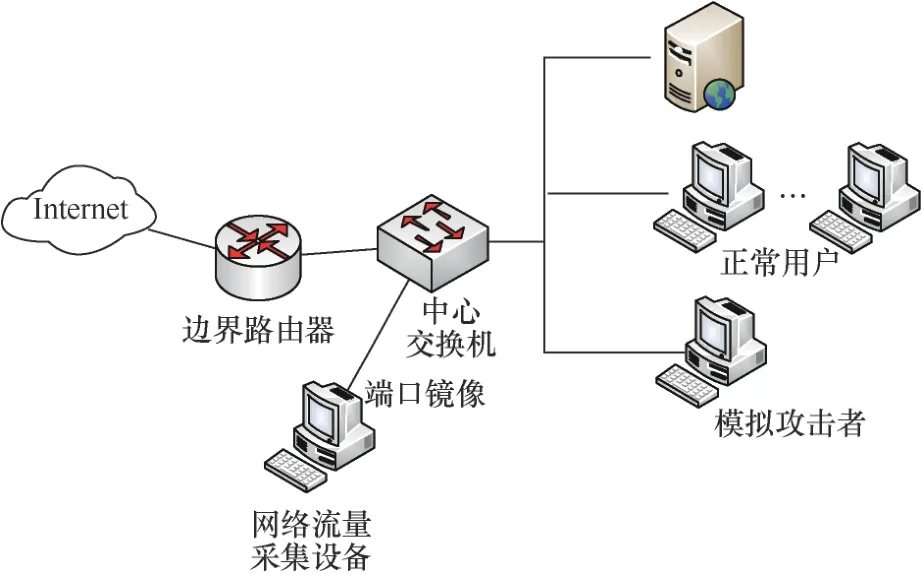
圖4 數據仿真環境Figure 4 Simulation environment topology
由于進行數據多分類實驗的數據集為不平衡數據集,文件上傳型Webshell與簡單型Webshell、網頁型Webshell的樣本數量差距較大,為增加實驗的合理性,在此采用SMOTE算法[18]進行隨機采樣至各類別比例接近1:1。
3.2 評價標準
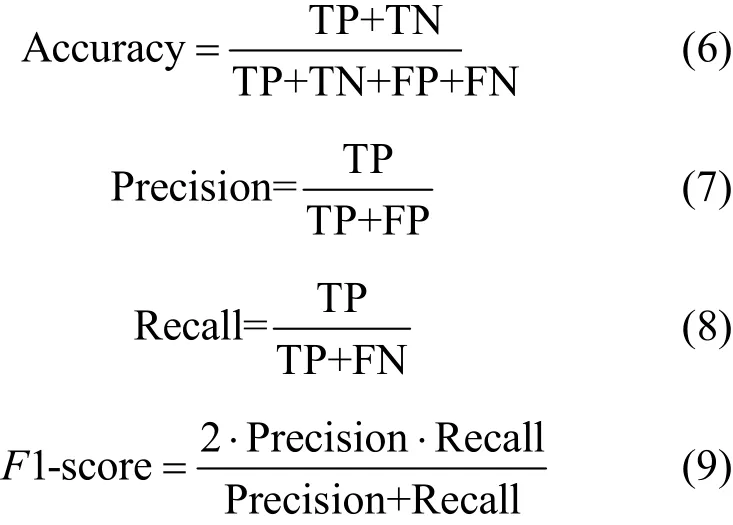
本文采用準確率(Accuracy)、精確率(Precision)、召回率(Recall)、F1值(F1-score)來評價二分類情況下分類器的性能,為了評估模型的檢測能力,首先定義二分類模型的預測結果與真實結果的4種情況。
(1)TP(true positive):預測當前流量是Webshell惡意流量,且實際上是Webshell惡意流量。
(2)FN(false negative):預測當前流量是正常流量,但實際上是Webshell惡意流量。
(3)FP(false positive):預測當前流量是Webshell惡意流量,但實際上是正常流量。
(4)TN(true negative):預測當前流量是正常流量,且實際是正常流量。
根據以上的判定結果,定義二分類下Webshell惡意流量檢測的評價指標如下。
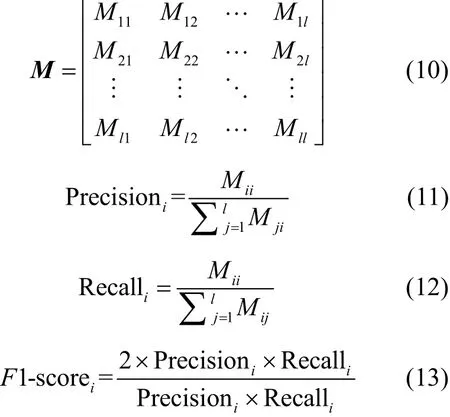
另外,由于本文需要對Webshell惡意流量的具體類別進行判定,故將二分類情況下的混淆矩陣(confusion matrix)推廣至多分類,得到式(10)所示的混淆矩陣Ml×l。其中,l為待檢測類別,M ii表示預測當前流量是第i個類別且實際上為第i個類別流量的個數,Mij表示預測當前流量是第i個類別但實際上是第j個類別流量的個數,計算第i個類別的精確率[19]、召回率[19]和F1值如下所示。
3.3 實驗結果分析
實驗預期要達到兩個分類:一是模型要能區分通信流量中的正常流量和惡意流量:二是模型能夠區分該惡意流量屬于何種類型的Webshell攻擊。本文主要從特征融合前后與現有同類研究方法兩方面進行評估,另外為證明分類器的有效性,在實驗過程中選擇了XGBoost、GBDT、AdaBoost等常見集成學習算法進行對比。
實驗1同類研究方法對比
第一組實驗對比同類型研究中基于通信流量的Webshell惡意檢測的各方面性能指標,由于文獻[9-10]中并未對惡意流量屬于何種攻擊類型做深入研究,故實驗主要針對正常惡意流量二分類情況進行對比。為避免實驗數據劃分不合理導致實驗結果的偶然性,本文采用十折交叉驗證對模型進行評估,實驗最終的性能指標取交叉驗證結果的平均值,如圖5所示。
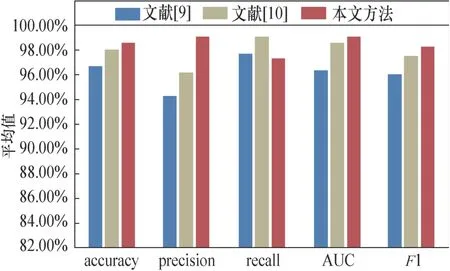
圖5 不同方法模型比較結果Figure 5 Comparison result of different method models
實驗結果表明,在相同的數據集下,本文提出的方法在正確率、精確率、ROC曲線的AUC面積以及F1指標上均達到最優,分別為98.65%、99.25%、99.07%、98.33%。這說明本文提出的方法能夠更準確地檢測Webshell惡意流量,并且模型更加穩定。召回率僅比文獻[9]低0.4%,比文獻[10]低1.8%。
除此之外,本文還對比了同類研究方法中的模型訓練以及模型檢測所需要的時間開銷。其中,一個完整的Webshell惡意流量檢測系統的檢測時間主要包括兩個部分。①使用Scapy等工具捕獲并解析未知網絡數據包;②訓練生成的模型對流量數據進行檢測。本文統一使用Scapy對數據包進行捕獲并解析,同時使用文獻[9-10]對原始數據集的20%數據進行檢測,平均消耗時間對比如表3所示。
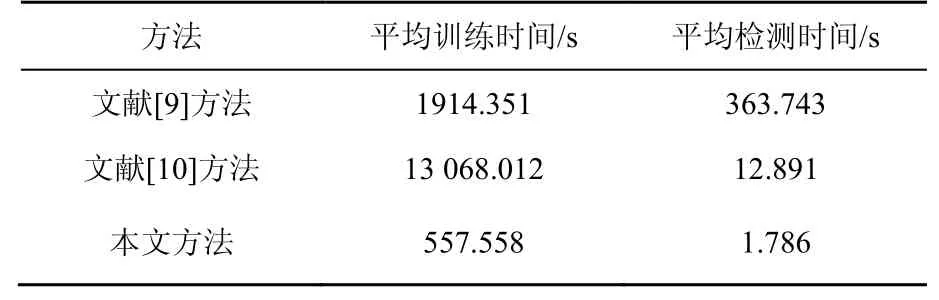
表3 平均消耗時間對比Table 3 Average elapsed time comparison
由表3可知,本文提出的方法與文獻[9]采用的CNN+LSTM構建分類模型相比,在訓練時間和檢測時間上減少了95.73%和86.14%。此外,在設置序列長度為1 500,與文獻[10]中采用4-gram+SVM算法相比,在訓練時間和檢測時間上減少了70.87%和99.51%。因此,本文提出的方法可大幅降低檢測器的訓練和檢測時間,滿足實際應用中快速檢測的要求。
實驗2特征融合前后對比
第二組實驗對比特征經過融合前后在不同類型的Webshell惡意流量上的識別效果。在實驗中選用數據集的80%數據進行訓練,20%的數據進行測試。同時,按照特征數據包元信息、數據包載荷內容以及流量訪問行為3個維度分為3組特征子集,并設置3組對比實驗分別為:未經過融合的第1組特征,只融合第1、2組特征,融合第1、2、3組特征。本實驗的目的是驗證本文提出的方法在改善單一特征對不同類型的Webshell惡意流量識別能力和模型魯棒性上的提升,識別結果如圖6~圖8所示。
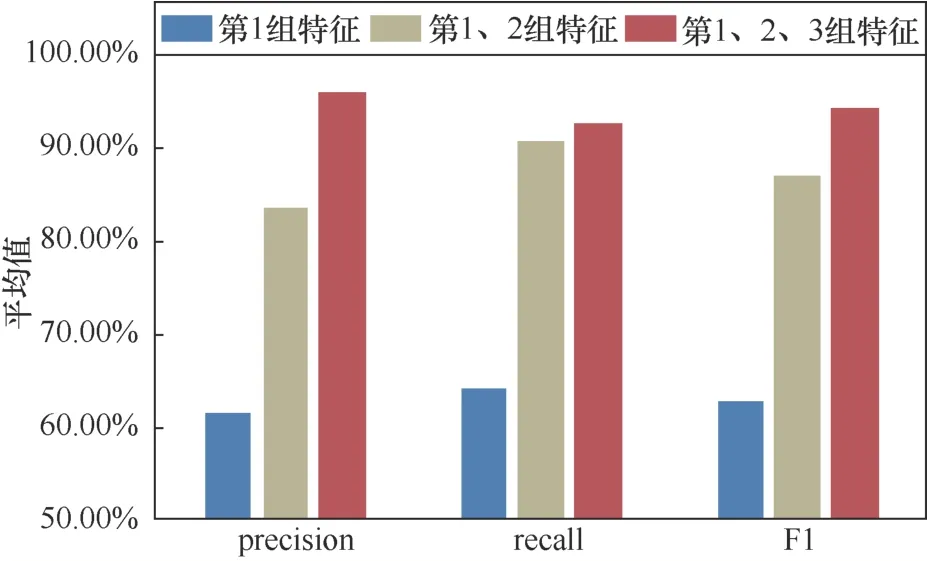
圖6 不同特征融合方案對簡單型Webshell識別效果對比Figure 6 Effect of different feature fusion schemes on simple Webshell
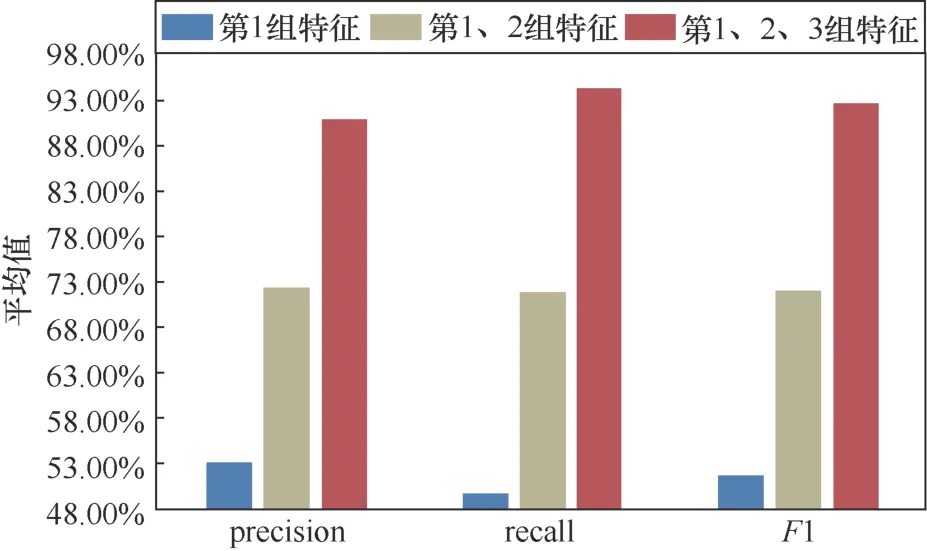
圖8 不同特征融合方案對網頁型Webshell識別效果對比Figure 8 Effect of different feature fusion schemes onweb-based Webshell
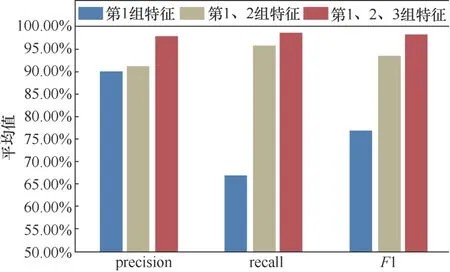
圖7 不同特征融合方案對文件上傳型Webshell識別效果對比Figure 7 Effect of different feature fusion schemes on file-upload Webshell
實驗結果表明,本文提出的多特征融合方法在識別不同類型的Webshell惡意流量上都要優于未經過特征融合以及特征融合不充分的情況,各類型識別精確率分別為95.66%、97.61%和90.86%。其中,對網頁型Webshell惡意流量的識別上效果提升明顯,精確率平均提升27.99%。這是因為網頁型Webshell惡意程序本質上仍然為一個Web應用,因而相較于具有較強特征的簡單型和文件上傳型,惡意流量上更容易被單一分類器識別為正常業務流量最終導致誤報。而本文通過集成的方式構建分類模型,在一定限度上提高了分類準確率,能夠更加有效地識別網頁型Webshell惡意流量。
實驗3不同集成算法對比
第三組實驗是對比不同集成學習算法在融合后的特征空間下的分類效果。在實驗中選定常見的集成學習模型:XGBoost、GBDT、AdaBoost算法與本文采用基于Stacking框架生成的分類模型進行比較。本實驗的目的是驗證基于Stacking框架的集成學習分類模型相比其他采用集成學習算法在多類型Webshell流量識別上,能夠取得更好的分類性能,實驗結果如圖9~圖11所示。
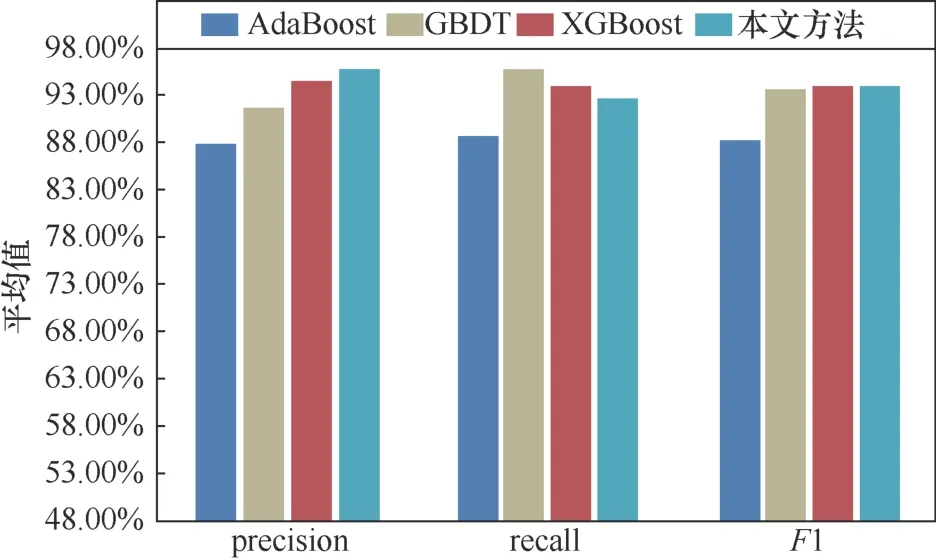
圖9 不同集成學習算法對簡單型Webshell識別效果對比Figure 9 Effect of different ensemble algorithms on simple Webshell
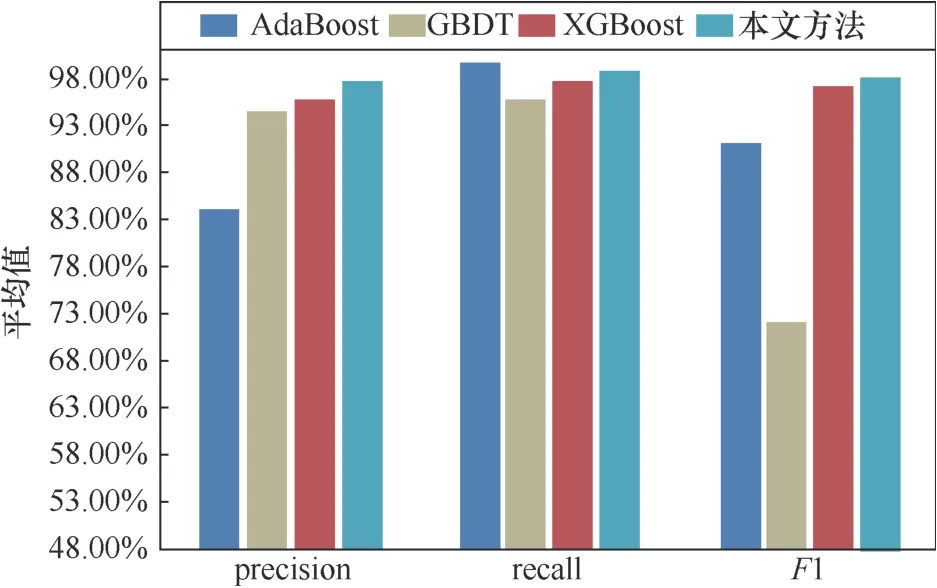
圖10 不同集成學習算法對文件上傳型Webshell識別效果對比Figure 10 Effect of different ensemble algorithms on file-upload Webshell
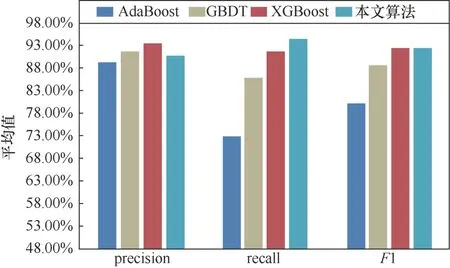
圖11 不同集成學習算法對網頁型Webshell識別效果對比Figure 11 Effect of different ensemble algorithms on web-based Webshell
實驗結果表明,在識別簡單Webshell惡意流量上,本文提出的算法在精確率和F1值上都要優于其他3種集成學習算法,達到95.66%和93.99%,召回率比采用XGBoost算法低1.34%,為92.37%。在識別文件上傳型Webshell惡意流量上,本文算法在精確率、召回率和F1值上整體優于其他3種集成學習算法,達到97.61%、98.3%、97.95%。在識別網頁型Webshell惡意流量上,本文提出的算法在召回率和F1值上都要優于其他3種集成學習算法,達到94.14%和92.47%,而精確率比采用XGBoost算法高2.44%,為90.86%。因此在整體的識別效果上,采用Stacking算法構建的分類模型相比其他基于集成算法在每個分類上的表現更加穩定。
4 結束語
本文提出了一種基于多特征融合的Webshell檢測方法,用來檢測網絡通信過程中可能存在的Webshell惡意流量,該方法從數據包元信息、數據包載荷內容以及流量訪問行為等提取流量特征,并將融合后的特征輸入基于集成學習策略的分類模型中檢測Webshell惡意流量。實驗結果表明,該方法不僅在正常與惡意流量的二分類上取得不錯效果,同時也能對惡意流量屬于何種Webshell攻擊做細分,為Web應用的進一步加固和防御提供精確的支撐。這一研究成果彌補了現有方法中未對惡意流量屬于何種攻擊類型進行研究的不足,以及訓練和檢測效率低的問題。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
