基于結構熵約束的圖聚類方法
2022-01-18 08:26:16張志穎田有亮
網(wǎng)絡與信息安全學報 2021年6期
張志穎,田有亮,3
(1. 貴州大學計算機科學與技術學院,貴州 貴陽 550025;2. 貴州省公共大數(shù)據(jù)重點實驗室,貴州 貴陽 550025;3. 貴州大學密碼學與數(shù)據(jù)安全研究所,貴州 貴陽 550025)
1 引言
在大數(shù)據(jù)和5G時代的環(huán)境下,云計算、大數(shù)據(jù)和物聯(lián)網(wǎng)等為代表的信息技術得到了前所未有的飛速發(fā)展[1-2]。新技術的不斷涌現(xiàn)和發(fā)展,讓人們意識到數(shù)據(jù)的價值和開放共享[3]的重要性。例如,在物聯(lián)網(wǎng)的大數(shù)據(jù)社交電子商務中,智能設備通過感知用戶的偏好和瀏覽足跡,為用戶提供精準的商品和便捷的服務[4]。因此,在大型網(wǎng)絡圖中,迫切需要利用一種方法來發(fā)現(xiàn)網(wǎng)絡圖中的真實結構和相關程度。
圖聚類是一種針對圖中節(jié)點間的某種相近或相似性的劃分方式[5],發(fā)現(xiàn)圖中各節(jié)點數(shù)據(jù)間的相關關系,并通過聚類效果為智能設備提供有效的服務。近年來,圖聚類在社交網(wǎng)絡[6]、醫(yī)學圖像[7]和生物數(shù)據(jù)網(wǎng)絡[8]等應用領域得到了廣泛的發(fā)展。因此,根據(jù)網(wǎng)絡圖生成一個無向無權圖,可以通過結構熵[9]來檢測圖結構中的真實結構,進而更有效地挖掘出圖中節(jié)點的關聯(lián)程度。
目前,研究者對共享和挖掘圖結構中數(shù)據(jù)的興趣不斷增長,對社交網(wǎng)絡中隱私數(shù)據(jù)的保護力度也在逐漸加大。Keyvanpour等[10]在隱私保護數(shù)據(jù)挖掘中提出了一種新的自定義隱私模型。進一步擴展了有向無環(huán)圖的隱私模型和討論了發(fā)布社交網(wǎng)絡時的隱私風險[11],當數(shù)據(jù)挖掘算法應用于真實數(shù)據(jù)集時,可被惡意數(shù)據(jù)挖掘者用來威脅社交網(wǎng)絡用戶的隱私。Al-Saggaf等[12]在社交網(wǎng)絡上下文中使用決策森林數(shù)據(jù)挖掘算法,該算法不僅構建了決策樹,而且還建立了一個森林,允許從數(shù)據(jù)集中探索更多的邏輯規(guī)則。數(shù)據(jù)集的龐大,導致數(shù)據(jù)集中存在敏感信息。并且這項技術在信息提取、數(shù)據(jù)縮減和隱私方面也面臨著巨大的技術挑戰(zhàn)。G?rnerup等[13]提出了一種從大量蜂窩網(wǎng)絡數(shù)據(jù)中挖掘路線信息的復合方法,該方法可通過分布式集群有效減少序列數(shù)據(jù)來解決可伸縮性問題,以及通過將原始數(shù)據(jù)分組到聚合中之后,在需要時對有關聚合的統(tǒng)計進行擾動以實現(xiàn)進一步的隱私保護。
為了平衡網(wǎng)絡的效用和隱私,周藝華等[14]針對如何在保證隱私安全的前提下,挖掘出有效知識的問題,提出了一種基于聚類的社交網(wǎng)絡隱私保護方法,該方法有效地減少了信息損失,提高了數(shù)據(jù)有效性。Yan等[15]提出了一種細粒度的差分隱私機制,用于在線社交網(wǎng)絡中的數(shù)據(jù)挖掘。還考慮了針對差分隱私的共謀攻擊,提出了保護隱私數(shù)據(jù)挖掘的對策。Tian等[16]介紹了一種用于將不確定性注入社區(qū)以生成不確定性圖的隱私保護方法。關鍵思想是混淆原始圖形的一部分,以實現(xiàn)隱私保護和有效地提高數(shù)據(jù)的實用性,并使用公開的真實數(shù)據(jù)集評估生成的不確定圖的實用性。
針對網(wǎng)絡數(shù)據(jù)挖掘研究成果中存在高冗余和不安全的問題。Jiang等[17]提出了一種基于Apriori算法的網(wǎng)絡隱私數(shù)據(jù)挖掘方法,基于結合數(shù)據(jù)冗余分析、過濾和偽裝,采用優(yōu)化的TS Apriori算法對偽裝后的數(shù)據(jù)集進行挖掘。實驗結果表明,該方法存在冗余度低、安全性強和挖掘精度高等優(yōu)點。Reza等[18]提出了一種3LP+(three layers of protection)隱私保護技術,以保護用戶的敏感信息泄露,將3LP +應用于合成生成的在線社交網(wǎng)絡數(shù)據(jù)集,并證明3LP +優(yōu)于現(xiàn)有的隱私保護技術。為了分析和查看人們對在線商人、社交網(wǎng)絡和其他數(shù)字媒體的隱私和安全。Alshaikh等[19]使用最廣泛的社交網(wǎng)絡之一Twitter,以分析Twitter用戶之間的交互,為了提取有意義的數(shù)據(jù)以幫助確定用戶對數(shù)字世界的隱私和安全的感知。然而以上研究方法并不能檢測出圖結構中數(shù)據(jù)結構的真實信息,從而在挖掘圖結構中關聯(lián)信息時可能會存在一定的誤差。
因此,本文需要解碼出網(wǎng)絡結構的真實結構,進一步地挖掘出圖結構的關聯(lián)信息。Li等[20]定義了圖的結構熵的概念,以度量圖中嵌入的信息,并確定和解碼圖的基本結構。Li等[21-23]首先提出了一種通過網(wǎng)絡結構熵的度量方法來尋找社區(qū)的算法。他們發(fā)現(xiàn),社區(qū)檢測算法可以準確識別幾乎所有自然選擇產(chǎn)生的網(wǎng)絡社區(qū)。隨后提出了圖的抵抗力的概念,使用一個伴隨結構熵的概念來度量圖抵抗策略性病毒攻擊的級聯(lián)失敗的能力。進一步提出了一種利用結構信息理論的快速且無歸一化的算法來解碼染色體域。Liu等[24]提出了一種基于社區(qū)的結構熵來表達由社區(qū)結構揭示的信息量。通過利用用戶賬戶的社區(qū)隸屬關系,攻擊者可以推斷出敏感的用戶屬性。這就提出了社區(qū)結構欺騙的問題,并著重于在在線社交網(wǎng)絡中披露社區(qū)結構的隱私風險。
基于以上研究,本文針對大規(guī)模動態(tài)數(shù)據(jù)之間的關聯(lián)程度,提出了一種基于結構熵約束的圖聚類方法。相比已有工作,該方法通過引入結構熵來度量動態(tài)復雜網(wǎng)絡,解碼出網(wǎng)絡的真實結構信息,解決了現(xiàn)有文獻對動態(tài)復雜網(wǎng)絡中信息關聯(lián)刻畫不足的問題。具體而言,本文的貢獻如下。
1) 提出了利用二維結構信息的求解算法和熵減原則的聚類算法。通過算法將圖結構中節(jié)點進行劃分,關聯(lián)程度強的劃分為一個模塊,從而挖掘出圖結構中關聯(lián)程度強弱的模塊隱私信息。
2) 提出了K維結構信息的求解算法。通過算法將已劃分的模塊做進一步的劃分,得到圖中所有節(jié)點的關聯(lián)程度。同時結構熵可以解碼出在大規(guī)模噪聲結構中圖結構的信息,這個信息能區(qū)分圖結構中的規(guī)律和噪聲,從而挖掘出圖結構中節(jié)點的實質(zhì)結構。
3) 通過實例分析和實驗評估表明,所提出的圖聚類方法不僅能夠有效地反映圖結構的真實結構,而且還能有效地挖掘出圖結構中節(jié)點之間的關聯(lián)程度。與其他3種聚類方法相比,該方法在執(zhí)行時間上具有更高的效率,并且保證了聚類結果的可靠性。
2 相關概念定義
定義1(圖的編碼樹[20-25])設圖G=(V,E),圖的編碼樹T,使得圖中的每個節(jié)點都在編碼樹中,存在頂點集V的子集Tα,并且以下屬性成立。
對于根節(jié)點λ,定義一個集合Tλ=V。
對于每個節(jié)點α?T,α?〈j〉表示α的子節(jié)點,j是1到自然數(shù)N從左到右遞增。每個內(nèi)部節(jié)點至少有兩個直接后繼節(jié)點,因此當i<j時,α?〈i〉在α?〈j〉左邊。
對于α?T,都有一個與α相關的子集Tα?V,對于α,β。α表示β的父節(jié)點,如果α≠λ,α-表示α的父節(jié)點。
對于每一個i,{Tα|h(α)=i}是V的一個分區(qū),其中h(α)是α的高度,根節(jié)點的高度為0,當α≠λ時,h(α) =h(α-)+1。
對于每個節(jié)點α,Tα是Tβ對所有β的聯(lián)合,β-=α,因此Tα=∪β-=αTβ。
對于T的每個葉子節(jié)點α,Tα是一個單例。因此Tα包含V中的單個節(jié)點。
對于每個節(jié)點α?T,如果Tα=X為一組頂點X,則α是X的碼字,記c(X)=α,X是α的標記,記M(α)=X。
定義2(結構熵[20])設圖G=(V,E),根據(jù)圖G的不同維度得到一維結構熵、二維結構熵和K維結構熵。將不同維度的結構熵的最小值定義為圖在不同維度下的結構信息。
定義3(一維結構信息[20])假設G=(V,E)是一個n個頂點m條邊的無向連通圖,對于每個頂點i? { 1,2,…,n}。用di表示G中頂點i的度,m為圖邊的數(shù)量,設Qi=di/2m。然后用概率向量Q=(Q1,Q2,…,Qn)來描述圖G中頂點的平穩(wěn)分布。由此可定義圖G的一維結構信息:
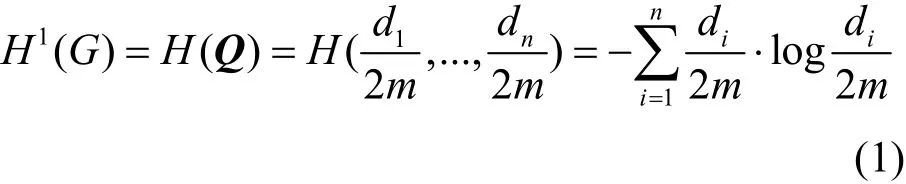
定義4(二維結構信息[20])給定一個無向連通圖G=(V,E),假設P= (X1,X2,…,XL)是V的一個分區(qū),稱Xj為一個模塊或者社區(qū)。通過P定義圖G的結構信息如下:
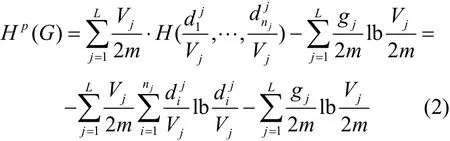
其中,L是分區(qū)P中的模塊數(shù),n j是模塊Xj中的節(jié)點數(shù),是Xi中第i個節(jié)點的度,V j是模塊Xj的體積,也就是模塊Xj中所有節(jié)點的度之和。gj是模塊中Xj只有一個端點的邊的數(shù)量。
因此可以定義圖G的二維結構信息,也稱之為模塊熵:
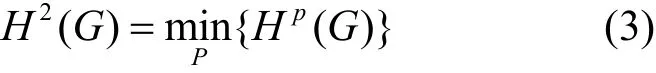
其中,P是圖G中所有可能劃分出的分區(qū)模塊。
定義5(圖聚類[26])根據(jù)節(jié)點間的某種相近或相似性,利用聚類方法將圖中所有節(jié)點劃分成一些聚類,這個過程被稱為圖聚類。
為了更好地理解圖聚類,本文將圖聚類表示為社交網(wǎng)絡圖G上的一種映射關系φ:(v1,v2,…,vn)→(X1,X2,…,Xm),φ滿足以下兩個條件。
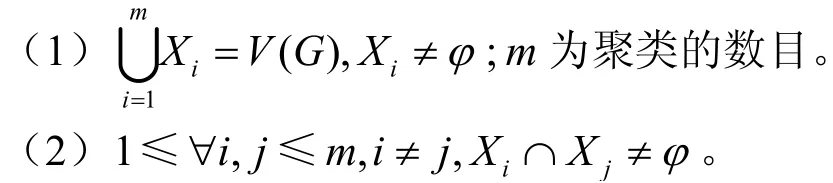
3 問題描述
3.1 方案模型
結構熵被用來度量嵌入圖結構中的不確定性,結構熵的最小化是解碼圖結構中真實結構的一種直觀的方法。通過圖結構的結構熵最小化,將圖結構的隨機變化和噪聲引起的擾動減小到最小,并且在比較圖結構的節(jié)點模塊合并前后結構熵的差異程度過程中,可反映出圖結構中節(jié)點之間的關聯(lián)程度。如圖1所示,在圖結構交互過程中如何有效地挖掘出它們之間的關聯(lián)程度是本文所要考慮的新問題。針對這一問題,可以用圖的二維結構熵度量圖中的結構信息。對于圖中的每一個節(jié)點模塊,在模塊的生成過程中,任意兩個節(jié)點模塊的合并必須滿足熵減原則,也就是說兩個節(jié)點合并后的模塊熵較合并之前減少的越多,表示模塊合并后的不確定性越低,其圖結構的二維結構熵也越小。這就反映了網(wǎng)絡結構中本質(zhì)的真實結構信息,即網(wǎng)絡結構的結構熵越小,模塊中的節(jié)點關聯(lián)程度越強。
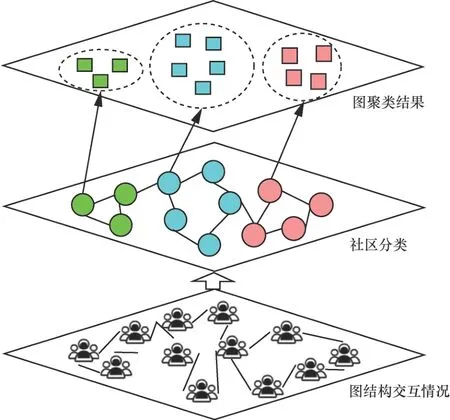
圖1 圖結構節(jié)點聚類模型Figure 1 Graph structure node clustering model
3.2 算法設計
為了能從大規(guī)模噪聲結構中挖掘出圖結構的隱私信息,必須利用結構熵的最小值來解碼圖結構的真實結構,從而更好地反映出圖結構中任意兩個節(jié)點的關聯(lián)程度。在此,本文提出利用二維結構熵最小值的計算算法和熵減原則的模塊分區(qū)算法來得出圖結構中節(jié)點的關聯(lián)性。
為了解決網(wǎng)絡結構中數(shù)據(jù)的高精度問題需要一個新的信息度量,能度量嵌入在復雜系統(tǒng)中的信息,這個信息能區(qū)分網(wǎng)絡結構中數(shù)據(jù)的規(guī)律和噪聲,從而解碼出嵌入在大規(guī)模噪音結構中的規(guī)律。因此需要設計算法1。
算法1二維結構信息最小值求解算法
輸入一個n個頂點m條邊的無向連通圖G=(V,E)
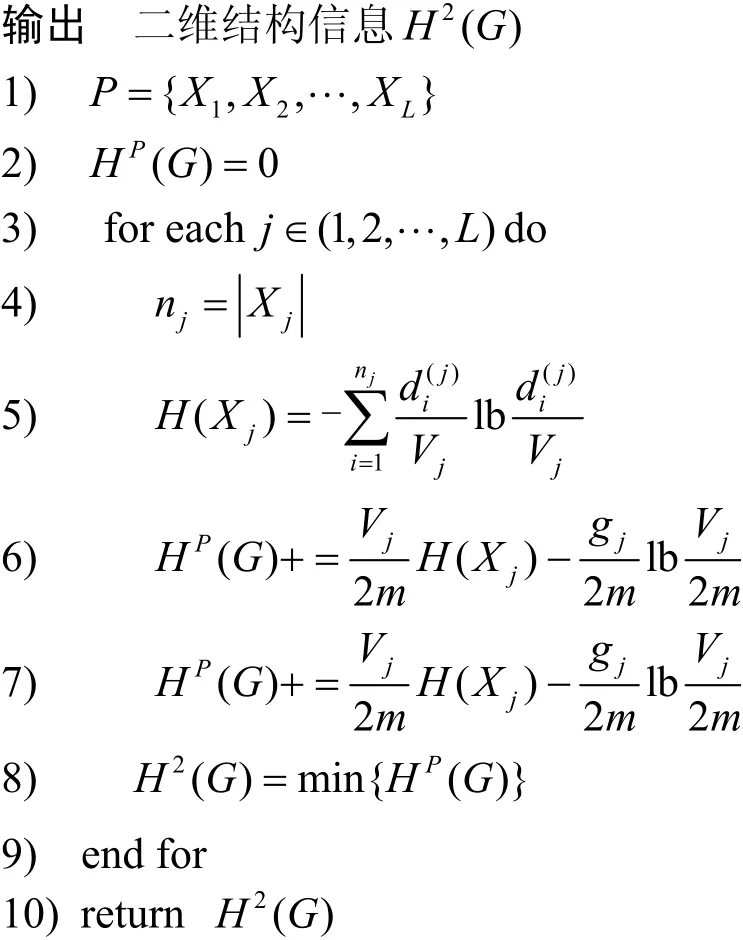
算法1可計算出一個n個頂點和m條邊的無向連通圖G的二維結構信息,圖G的二維結構信息就是圖所能劃分的所有模塊熵的最小值。設圖的二維結構熵在最小值時所對應節(jié)點的劃分為分區(qū)P,P= {X1,X2,…,XL}。其中,分區(qū)P是對所有節(jié)點的一個劃分,X i(i= 1,2,…,L)是劃分P下的一個模塊或者說是一個社區(qū),模塊是由部分節(jié)點組成的集合。然而針對不同的劃分結果,計算出圖的二維結構信息也不同。只有當圖的二維結構信息取值為模塊熵的最小值的時候,對應的圖中節(jié)點分區(qū)P才能體現(xiàn)出該圖的節(jié)點關聯(lián)程度的最優(yōu)結果。也就是當圖的二維結構信息最小時,模塊中節(jié)點的不確定性最小,節(jié)點的關聯(lián)程度最強。
然而在計算二維結構信息時,為了得到模塊熵的最小值,只能通過不同的分區(qū)和計算進行比較。然而無法快速地通過計算對比來減少計算成本,從而無法更有效地確定圖中的頂點的劃分結果是否完善。因此,進一步地利用二維結構信息和熵減原則來有效提高本文獲取模塊分區(qū)的結果。為了能夠?qū)D中節(jié)點有效分區(qū),得到節(jié)點模塊之間的關聯(lián)程度設計了算法2。
算法2網(wǎng)絡節(jié)點模塊分區(qū)算法
輸入一個n個頂點m條邊的無向連通圖G=(V,E)
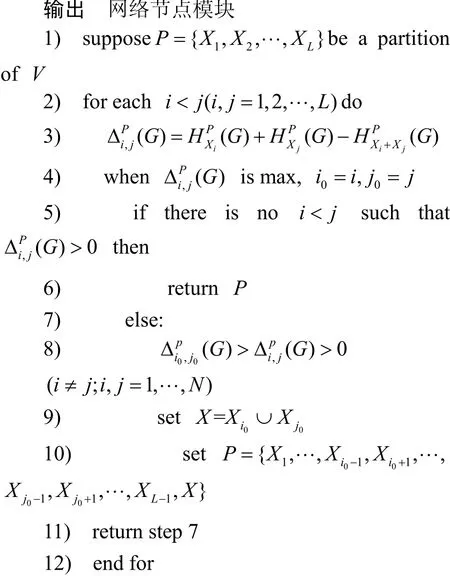
該算法的節(jié)點模塊劃分方法的主要過程如下:假設v1,v2,…,vn是節(jié)點集合V中所有按順序排列出的節(jié)點。將Xi設置為所有i的單例{vi},構成了所有節(jié)點集V的初始劃分模塊。如果不存在滿足i<j這樣的,則返回分區(qū)P。否則,有i0,j0使得是所有i,j在上的最大值,得到其中,表達式如下:
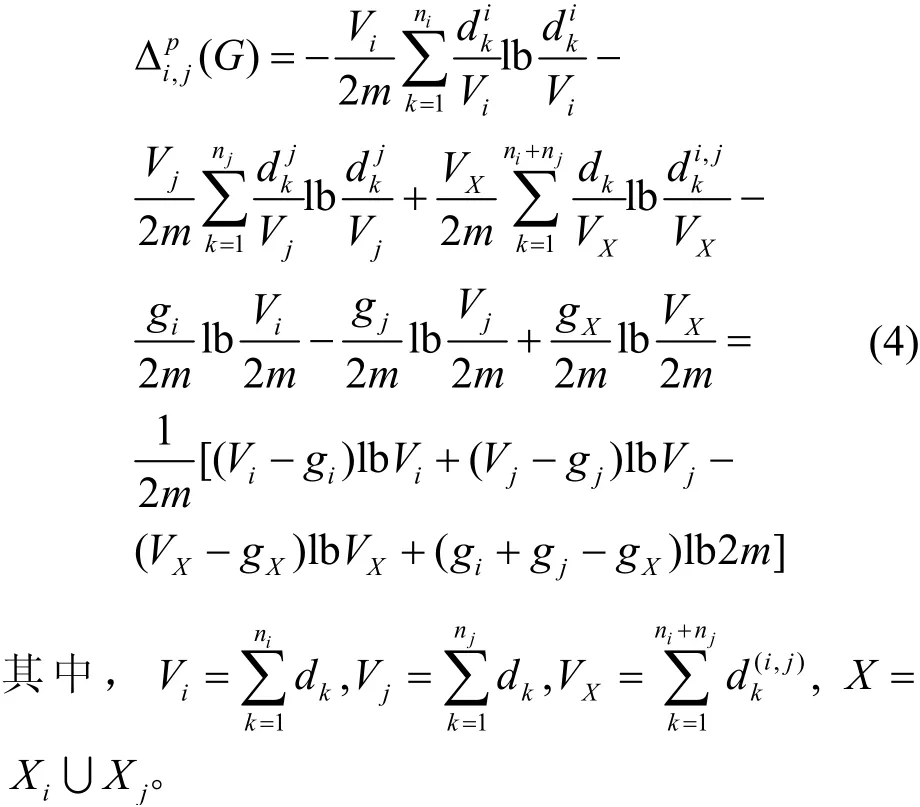
根據(jù)二維結構信息最小值求解算法和網(wǎng)絡節(jié)點模塊分區(qū)算法可以有效地處理圖的結構信息數(shù)據(jù),從大規(guī)模噪聲結構中解碼出圖節(jié)點之間的關聯(lián)程度,既不需要改變原始數(shù)據(jù)也不需要選擇參數(shù)。這就排除了在歸一化或在參數(shù)選擇中可能產(chǎn)生噪聲的影響。
本節(jié)使用了一種基于結構信息理論的圖節(jié)點分區(qū)算法。通過節(jié)點的劃分模塊和整體的劃分分區(qū),用結構熵的最小值來獲取圖中節(jié)點隨機游動發(fā)生的不確定性,從而更好地反映出圖節(jié)點之間的關聯(lián)程度。因此,網(wǎng)絡節(jié)點分區(qū)算法的本質(zhì)是固定結構不確定性最大的網(wǎng)絡節(jié)點,合并網(wǎng)絡中連接緊密程度高的節(jié)點模塊。節(jié)點的分區(qū)算法不僅挖掘出了使整個網(wǎng)絡的不確定性最小化的基本結構,而且從模塊分區(qū)結果中反映出網(wǎng)絡中連接緊密程度最高的節(jié)點模塊。
4 K維結構信息的聚類算法
網(wǎng)絡表現(xiàn)為特定群體中多個個體及它們之間相互聯(lián)系組成的集合,最適合用圖來表示。其中,節(jié)點表示個體,邊表示個體間的聯(lián)系。常見的網(wǎng)絡圖結構模型為簡單的圖模型G=(V,E),在圖G中,V= {v1,v2,…,vn}為圖中節(jié)點集,E= {(vi,vj)| 1≤i,j≤n,i≠j}為邊集。圖中任何邊(vi,vj)表示節(jié)點之間的聯(lián)系,為結構邊。根據(jù)實際網(wǎng)絡中個體之間聯(lián)系的緊密程度不同,結構邊的權值不同。本文假設給定的是一個無向無權的連通圖,結構邊具有相等的權值,均為1。
為了發(fā)現(xiàn)圖中的簇,把圖分割成若干塊。每一塊是一個簇,使得簇內(nèi)的節(jié)點能夠以利益最大化的方式有效地連接,而不同簇內(nèi)的節(jié)點之間以較弱的方式連接。因此,本文通過利用結構熵能檢測圖結構的真實結構來更有效地對圖中節(jié)點進行劃分。其主要特點都是聚類,將圖中所有節(jié)點劃分為模塊子集的過程,使得圖中相似度最高的節(jié)點形成一個簇,簇內(nèi)的節(jié)點與其他簇內(nèi)的節(jié)點相似度最低。
圖聚類問題的實質(zhì)就是圖劃分問題,聚類的過程其實就是對圖劃分過程的優(yōu)化。優(yōu)化的目的是使劃分的模塊間的相似度變小,模塊內(nèi)的節(jié)點相似度變大。然而對于如何度量嵌入大規(guī)模噪聲結構中的整體圖結構的信息,僅是二維結構信息是遠遠不夠的。因此,利用K維結構信息來作為圖聚類的一種方法,也就是在二維結構信息和熵減原則的基礎上,進一步地計算出圖結構的最小結構熵,從而更有效地反映圖結構的真實結構。為了更加針對性地對圖中節(jié)點間的關聯(lián)程度做出有效的挖掘,設計了算法3。
算法3K維結構信息求解算法

定義6(K維結構信息[20])對于一個無向連通圖G=(V,E),假設T是圖G的分區(qū)樹。通過T定義圖G的結構信息如下:
對于任意頂點α?T,如果α≠λ,λ為樹T的根節(jié)點,那么定義頂點α的結構信息為其中,gα是從Tα中的節(jié)點到Tα之外節(jié)點的邊數(shù),Vα是集合Tα的體積。
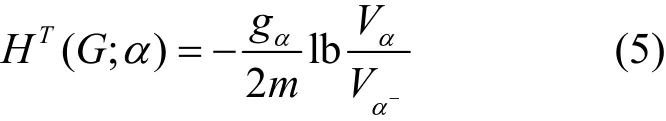
通過分區(qū)樹T定義圖G的結構信息如下:
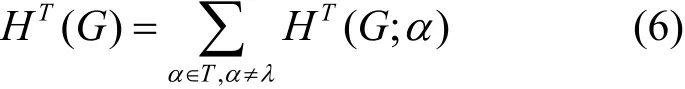
圖G的K維結構信息定義如下:
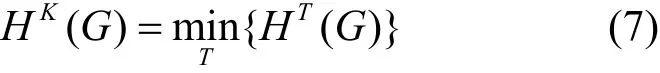
其中,T覆蓋圖G的所有分區(qū)樹,K表示T的高度。算法3計算出圖結構的整體K維結構信息,K維結構信息能挖掘嵌入在圖結構中的信息,這個信息能區(qū)分圖結構的規(guī)律和噪聲,從而解碼出嵌入在大規(guī)模噪聲結構中的規(guī)律,進一步?jīng)Q定并解碼出該圖結構的真實結構。通過在二維結構信息的基礎上加入merge和combine兩個算法,將圖結構由高度為2的分區(qū)樹轉化為高度為K的分區(qū)樹,從而進一步地劃分圖結構中節(jié)點的關聯(lián)程度。因此,當K維結構熵越小時,越能反映出圖結構中單個節(jié)點間的關聯(lián)程度。
聚類分析可以對網(wǎng)絡中節(jié)點實行分組管理,使得組內(nèi)的節(jié)點具有非常相似的特性或者需求,這有利于應用在智能設備中更好地服務用戶和加強對用戶信息的保護。利用結構信息的最小化將復雜的網(wǎng)絡抽象成一個圖,不僅對分析整體網(wǎng)絡的結構信息有著重要的幫助,而且還能對網(wǎng)絡中用戶的隱私信息進行挖掘和保護有著重要的意義。具體來說,根據(jù)模塊熵和熵減原則,對圖中節(jié)點進行合并得到不同的模塊,進一步根據(jù)圖的K維結構熵的最小值K維結構信息,最終得到對所有圖節(jié)點的關聯(lián)聚類。此時,結構熵能度量出圖在大規(guī)模噪聲結構中的信息,所得到的信息也反映了圖的真實結構。其中節(jié)點的模塊分區(qū)就表示圖結構在挖掘圖中關聯(lián)信息條件下的聚類結果,便可將圖中隱私信息關聯(lián)程度緊密的節(jié)點劃分為一個模塊,而模塊間節(jié)點隱私信息的關聯(lián)程度遠遠小于模塊內(nèi)節(jié)點的關聯(lián)程度。
5 實驗評估與分析
本節(jié)通過實驗來評估本文所提出的方法,并給出詳細的實驗結果和討論與其他方法的優(yōu)缺點。
5.1 實驗評估
本文隨機生成一個15個頂點60條邊的無向無權的網(wǎng)絡模型圖。如圖2所示。

圖2 隨機生成圖Figure 2 Randomly generated graph
首先通過算法1和算法2對圖進行模塊劃分,計算出圖的二維結構信息H2(G)3.23= 。由此可見,通過二維結構信息和熵減原則算法,將圖劃分為大小不同的模塊,并計算不同模塊的結構熵H P(G),最終得出圖的二維結構信息H2(G) =min{H P(G)},此時模塊P的劃分結果便是圖中節(jié)點屬性相關程度大的為一個模塊。因此,如圖3所示,利用算法1和算法2將圖劃分為模塊P={X1,X2,X3,X4},且X1={A,E,H},X2={B,F,G,I,L},X3={C,D,K,M,O},X4={J,N}。
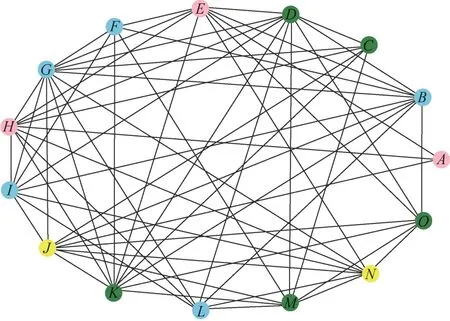
圖3 模塊熵的關聯(lián)節(jié)點Figure 3 Associated node of module entropy
然后將圖劃分的模塊P轉化為高度2的分區(qū)樹,引入根節(jié)點λ,模塊P中每一個子模塊X i(i= 1,2,3,4)為樹節(jié)點,每個子模塊中的節(jié)點為該樹節(jié)點下的葉子節(jié)點。二維分區(qū)樹如圖4所示。
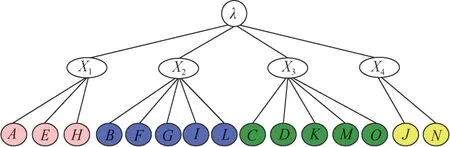
圖4 二維分區(qū)樹Figure 4 Two-dimensional partition tree
最后將以模塊P的最優(yōu)劃分結果通過算法3做進一步的節(jié)點聚類,并計算出圖的K維結構信息H K(G)= 3.07。因此,通過K維結構信息聚類算法,將所有的模塊P生成的二維分區(qū)樹轉化成高度為K的分區(qū)樹,并計算出不同的K維分區(qū)樹的結構熵H T(G),最終得出圖的K維結構信息H K(G) =min{H T(G)},此時所得到的分區(qū)樹便是將圖中每個節(jié)點屬性關聯(lián)程度最大的聚類在一起。如圖5所示,從圖3中可以看出,利用算法3將模塊中的節(jié)點再一次進行劃分,得到劃分結果更為詳細。因此,可以得到在模塊X1中節(jié)點A、E關聯(lián)程度更大,模塊X2和X3中節(jié)點進一步得出兩兩關聯(lián)程度:X2:((G,(B,L)),(F,I)),X3:((K,(C,M)),(D,O)),模塊X4中的關聯(lián)程度沒有變化。
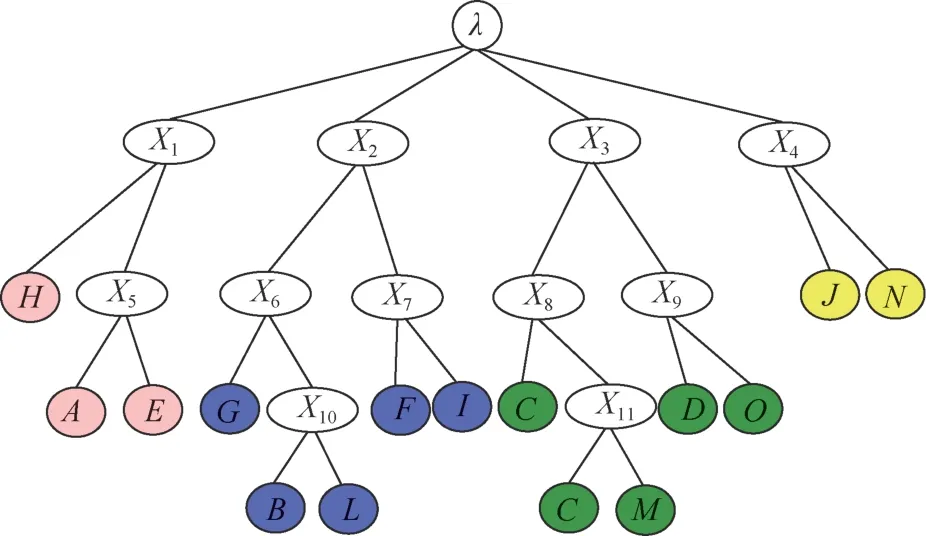
圖5 K維分區(qū)樹Figure 5 K-dimensional partition tree
當圖中頂點和邊的數(shù)量在不斷變化時,圖結構的本質(zhì)信息也會改變,從而導致圖的劃分結果也會隨之變化,如表1所示。隨機生成4個不同大小的網(wǎng)絡圖,通過二維結構信息的劃分方法將圖中相似度高的節(jié)點分成一個模塊,再通過K維結構熵最小值的原理將模塊中的節(jié)點進一步劃分,最終得到圖中所有節(jié)點間的關聯(lián)程度。所以,本文通過結構熵挖掘出圖中節(jié)點關聯(lián)程度大的節(jié)點都屬于一個模塊,而節(jié)點之間關聯(lián)程度小的則被劃分在不同的模塊中。因此可以利用結構熵的最小值來體現(xiàn)網(wǎng)絡節(jié)點的關聯(lián)程度,從而挖掘出網(wǎng)絡結構中節(jié)點之間的交互信息以及其他相關信息。

表1 不同網(wǎng)絡圖的聚類效果Table 1 Clustering result of different network graphs
5.2 有效性比較與分析
對數(shù)據(jù)挖掘的研究領域中,聚類往往可以直接或者間接地描述數(shù)據(jù)的關聯(lián)程度,從而能夠有效地分析數(shù)據(jù)的相關特性。因此聚類分析算法是探索數(shù)據(jù)分析的關鍵要素,其中K均值算法因其易于實現(xiàn)、可并行性強和計算成本相對較低而成為最受歡迎的方法。然而正如文獻[27]提出的K均值對初始條件的高度依賴,以及在大規(guī)模數(shù)據(jù)集中可能無法很好地擴展。文獻[27]提出了一個遞歸并行逼近K均值算法,該算法在不影響逼近質(zhì)量的情況下,能很好地根據(jù)問題實例的數(shù)量進行縮放。但是該算法在遞歸次數(shù)和計算開銷方面都消耗較大,無法有效地分析社交網(wǎng)絡或圖等結構化網(wǎng)絡圖中所嵌入的信息。
劃分和層次方法旨在發(fā)現(xiàn)球狀簇,對于給定的數(shù)據(jù)很難發(fā)現(xiàn)任意形狀的簇。然而為了發(fā)現(xiàn)任意形狀的簇,可以把簇看作數(shù)據(jù)空間中被稀疏區(qū)域分開的稠密,從而可以發(fā)現(xiàn)任意非球狀的簇。基于密度的噪聲應用空間聚類(DBSCAN,
density-based spatial clustering of applications with noise)是基于密度的聚類算法,也是主要的聚類范式之一。盡管DBSCAN算法已被廣泛應用,但算法本身依然存在一定的缺點。DBSCAN算法的輸入?yún)?shù)包括掃描半徑ε和閾值MinPts,在聚類的過程中需要計算每個數(shù)據(jù)點的密度。數(shù)據(jù)點的密度與從該點到其他所有點的距離有關,使得聚類過程中存在很多冗余的距離計算,復雜度高,效率低。因此,該算法同樣不適用于大規(guī)模數(shù)據(jù)和高維數(shù)據(jù)。Li等[28]對DBSCAN的聚類原理進行了深入的分析和研究,發(fā)現(xiàn)DBSCAN的核心問題是尋找每個點的最近鄰,然后通過三角不等式提出了一種基于最近鄰相似的快速密度算法,并且利用覆蓋樹對每個并行點的領域進行檢索,可以有效減少聚類過程中距離計算的次數(shù),提高聚類效率。但是,該算法的不足在于只基于最近距離來分析每個節(jié)點的相似度,忽略了網(wǎng)絡的自組織原理與網(wǎng)絡節(jié)點所嵌入的結構信息對圖聚類的影響。
圖聚類主要是針對圖的一種聚類方法,用來搜索圖找出節(jié)點間某種相似的特性形成一個簇。網(wǎng)絡結構聚類算法(SCAN,structural clustering algorithm for networks)在處理大型網(wǎng)絡圖時,其時間復雜性關于邊數(shù)是線性的,具有良好的可伸縮性。SCAN是一種快速高效的集群技術,用于查找隱藏的社區(qū)并隔離網(wǎng)絡中的集線器或異常值。然而,對于大型網(wǎng)絡仍然需要相當多的時間。Stovall等[29]提出了一種基于計算統(tǒng)一設備架構(CUDA,computer unified device architecture)的SCAN并行實現(xiàn)(GPUSCAN,graphic processing unit structural clustering algorithm for networks)。SCAN的計算步驟經(jīng)過仔細的重新設計,通過將SCAN轉化為一系列高度規(guī)則和獨立的并發(fā)操作,使其在圖形處理單元(GPU,graphic processing unit)上高效運行。通過GPUSCAN,可以將大型網(wǎng)絡或一批不相交的網(wǎng)絡卸載到GPU,以進行非常快速且高效的結構聚類。GPUSCAN是在考慮CUDA的情況下開發(fā)的,啟用CUDA的GPU充當了并行分布式系統(tǒng)的縮影。由于GPUSCAN專注于合并和本地資源訪問方法,因此具有可伸縮性,并且可以輕松地適應并發(fā)或分布式環(huán)境。相比之下,SCAN基于廣度優(yōu)先搜索,盡管計算效率高,但往往需要高頻率的隨機資源訪問,并迅速成為超大型網(wǎng)絡的I / O綁定。GPUSCAN當前受GPU上可用的設備內(nèi)存量的限制。雖然可以通過將復雜的計算分布在多個連接的GPU上,從而可以輕松地擴大規(guī)模,但其開銷仍是一個難以解決的問題。
因此,表2對以上3種聚類方法與本文所提出的基于結構熵的圖聚類方法進行了比較。從表2可以看出,文獻[27]所提方法的時間復雜度為O(nkt),因此,該方法在計算大規(guī)模數(shù)據(jù)集時,將消耗大量的計算時間和計算開銷。文獻[28]所提方法的時間復雜度為logn+ MinPts2]),該算法在聚類過程中具有許多冗余計算,導致效率低和復雜度較高的問題。文獻[29]所提方法的時間復雜度為O(n2),該方法的計算效率與本文方法存在很小的差距,但該方法受GPU上可用的設備內(nèi)存限制,將會增加聚類過程中的開銷問題。由于圖的結構信息能夠度量出圖結構中所嵌入的信息,這個信息量可以更好地反映出圖結構的真實結構。因此,可以在大規(guī)模噪聲結構中解碼出網(wǎng)絡結構的真實結構信息的情況下,利用結構熵更有利于對圖結構中節(jié)點的關聯(lián)信息的挖掘,從而將達到節(jié)點屬性有效地聚類。因此,無論是在處理大規(guī)模數(shù)據(jù)集時,還是在動態(tài)復雜的網(wǎng)絡結構中,本文方法在計算規(guī)模、計算開銷以及計算效率等方面都優(yōu)于其他方法。

表2 聚類功能對比Table 2 clustering function comparison
5.3 仿真分析
本文實驗環(huán)境是一臺CPU為Intel (R)Core(TM) i5-7500,內(nèi)存為8 GB,操作系統(tǒng)為64位Windows 10的計算機。選用Python作為編程語言,模擬運行熵減原則圖劃分算法和圖節(jié)點的聚類算法。如圖6所示,本文使用0~10 000的不同節(jié)點數(shù)量運行6個實驗,比較了本文所提出的二維結構信息和熵減原則下的圖劃分算法與K維結構信息對圖節(jié)點的相似聚類算法的執(zhí)行時間。
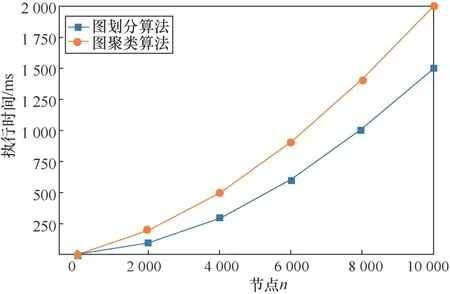
圖6 不同網(wǎng)絡節(jié)點圖劃分與圖聚類的執(zhí)行時間Figure 6 The execution time of graph division and graph clustering of different network nodes
結果表明,隨著節(jié)點數(shù)量的增大,算法的執(zhí)行時間在不斷增加。在執(zhí)行時間上,圖結構的節(jié)點聚類算法的執(zhí)行時間總是多于圖結構的節(jié)點劃分算法。然而,圖聚類與圖劃分相比,聚類整個圖結構中節(jié)點關聯(lián)信息的成本更高,但圖聚類算法對圖結構中節(jié)點聚類的效果更好。因此,圖節(jié)點的聚類算法是在圖劃分算法的基礎上進行的。也就是在得到圖中節(jié)點的模塊劃分之后,進一步為了得出節(jié)點之間的關聯(lián)程度,利用K維結構熵的最小值對已劃分的模塊做進一步的聚類,從而有效地得出整體圖結構中節(jié)點之間的關聯(lián)程度。
4種節(jié)點聚類方案的執(zhí)行時間如圖7所示。結果顯示,本文方法與其他3種方法在執(zhí)行小規(guī)模數(shù)據(jù)時,執(zhí)行時間和成本開銷相差較小。然而在執(zhí)行大規(guī)模數(shù)據(jù)時,本文所提出的聚類方法有較短的執(zhí)行時間。從而反映了本文方法能夠有效地執(zhí)行大規(guī)模的動態(tài)數(shù)據(jù),縮短聚類時間和減小聚類成本。對于文獻[27]方法而言,隨著數(shù)據(jù)集的增加,K-means算法的執(zhí)行時間大大增加,導致計算開銷也隨之增加。文獻[28]方法,在數(shù)據(jù)集中選擇的參數(shù)均為eps = 0.1,minPts = 10。隨著數(shù)據(jù)集的變化,DBSCAN算法的執(zhí)行時間也有較大幅度的上升。相對于文獻[29]方法而言,由于本文不需要計算分布在多個GPU上來擴大規(guī)模,因此縮短了計算時間,同時也存在相對較小的開銷成本問題,極大程度上提高了本文方法對圖結構中節(jié)點關聯(lián)信息的聚類效率。
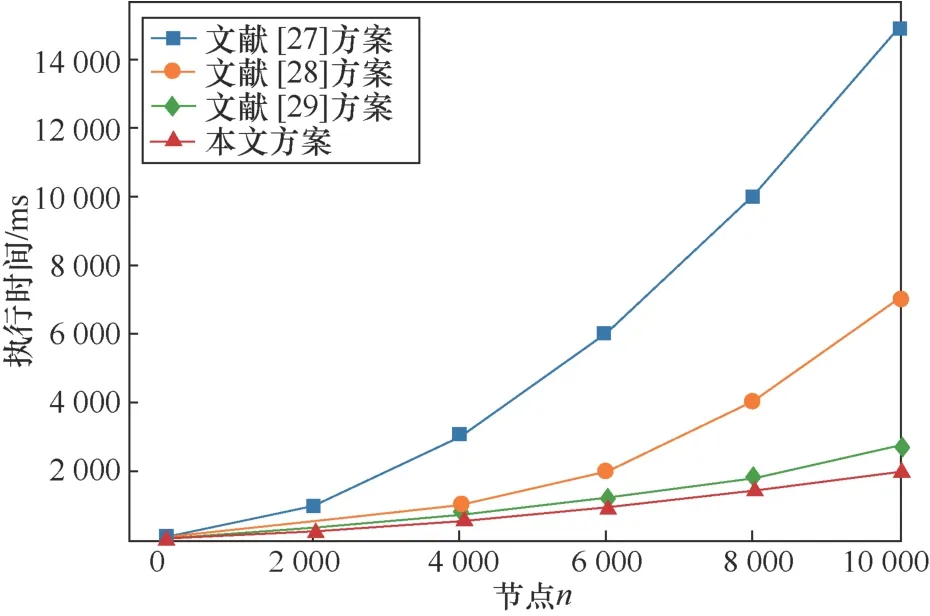
圖7 不同網(wǎng)絡節(jié)點4種聚類方案的執(zhí)行時間Figure 7 The execution time of the four clustering schemes for different network nodes
為了實現(xiàn)一個高效的動態(tài)聚類方法,本文利用結構熵的最小值來反映圖結構節(jié)點的最優(yōu)聚類效果。圖8為模擬網(wǎng)絡節(jié)點的數(shù)目在100~500變化的情況下進行的節(jié)點聚類所得到二維結構熵和K維結構熵的最小值。從圖8中可以看出,隨著節(jié)點數(shù)目的增大,結構熵的值也增大。然而在相同節(jié)點下,K維結構熵總是小于二維結構熵。因此更好地說明K維結構信息能夠有效地反映圖結構的真實信息,從而有利于針對圖結構中節(jié)點得出最優(yōu)的聚類結果。同時結構熵可以用來度量嵌入在一個圖中的高維信息或深度信息,并且在度量結構信息的同時解碼出原始圖結構的實質(zhì)結構。因此,可以將結構熵的最小值K維結構信息看作是解碼圖結構中節(jié)點真實信息的衡量標準,有效地反映了圖結構中節(jié)點之間的聚類效果。
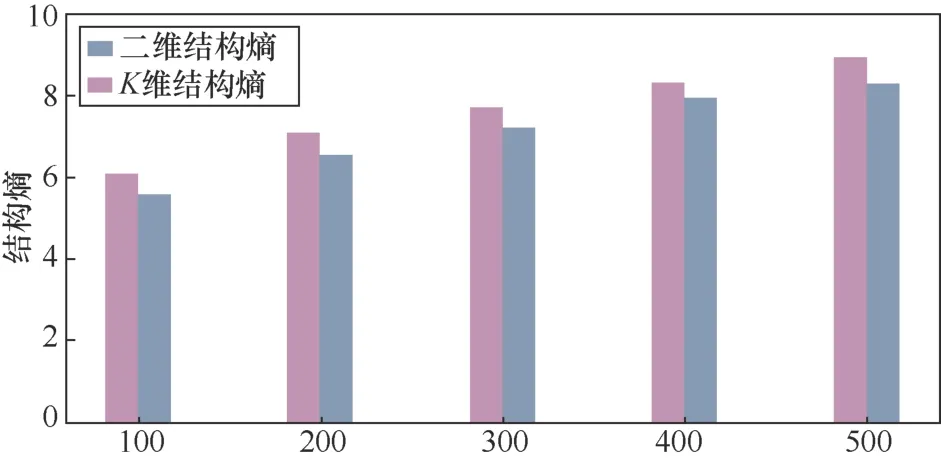
圖8 不同網(wǎng)絡圖的熵值對比Figure 8 Comparison of entropy values of different network diagrams
6 結束語
本文基于結構熵的聚類方法提出了對圖結構中節(jié)點的劃分。該方法主要是檢測出圖結構中的真實結構信息,同時挖掘出圖結構中節(jié)點之間的關聯(lián)信息。具體來說,本文方法不僅適用于大規(guī)模的網(wǎng)絡圖結構,而且還在保證聚類結果可靠性的同時,有效地提高了計算效率,減少了開銷。在未來的工作中,將進一步研究當無向無權圖擴展到有向加權圖時,如何挖掘圖結構中的關聯(lián)信息,以及如何有效地保護挖掘出來的結構信息和原始圖結構中的隱私信息。
猜你喜歡
當代陜西(2021年17期)2021-11-06 03:21:36
哲學評論(2021年2期)2021-08-22 01:53:34
中華詩詞(2019年7期)2019-11-25 01:43:04
學苑創(chuàng)造·A版(2018年11期)2018-02-01 06:29:20
中華手工(2017年2期)2017-06-06 23:00:31
讀者(2017年5期)2017-02-15 18:04:18
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
現(xiàn)代企業(yè)(2015年9期)2015-02-28 18:56:50
中外會展(2014年4期)2014-11-27 07:46:46
當代修辭學(2011年2期)2011-01-23 06:39:12
