基于深度學習的物流服務交易群智推薦算法的研究
2022-01-26 05:09:56李蒙李文敬
現代計算機 2021年34期
李蒙,李文敬
(1.南寧師范大學計算機信息工程學院,南寧 530000;2.南寧師范大學物流管理與工程學院,南寧 530000)
0 引言
2021年全國社會物流總額達到300萬億元,表示著我國物流需求在不斷擴大。但是,目前海量的物流交易量主要依賴人工查找或配對網上的物流需求信息來完成。存在物流人工成本高,查找匹對的物流需求信息難、獲取精準的物流需求信息慢,物流產業效率、效益偏低等問題。為此我們融合了多目標粒子群算法和深度學習算法,解決物流需求精準的匹配與推薦,實現物流服務交易的智能化,具有重要的科學意義和應用前景。
1 相關工作
1.1 深度學習及其在物流交易的應用研究
深度學習在物流領域的應用主要是圖像處理、無人駕駛與無人機配送。經過深度學習后的模型對大量的表單內容進行識別,對文檔掃描件或圖片中的印章進行識別,以及識別手寫文字、數字等,大幅避免人工輸單。在倉儲上替代人工管理,可以快速識別子庫區、庫區汽車數量、車輛所在車位號與系統進行實時對比,如果不吻合將會報警。
在深度學習和推薦算法相結合的應用上,王若夕等[1]提出了一種Deep&Cross Network(DCN)框架,用來解決廣告點擊率的預測問題。Heng-Tze Cheng等[2]提出了一種Wide&Deep Learning的方法,首次應用到了推薦系統當中,并成功的將其應用到了谷歌應用商店的推薦當中。Maxim Naumov等人[3]通過將深度學習結合協同過濾算法和預測分析,提供了目前推薦系統與深度學習結合的最優效果。郭華峰等人[4]研發了DeepFM神經網絡框架,將FM與DNN相結合,可以同時學習高階和低階的組合特征,使學習模型要比學習單一方面特征模型更加優秀。由何湘南等人[5]提出神經協同過濾算法,將用戶的隱式反饋作為特征進行建模,證明了非線性的引入將會讓深度學習模型的效果變好。而李國祥等人[6]利用深度學習技術,對區域物流需求進行預測,并獲得了較好的結果。Alex等人[7]最早將深度學習應用于圖像處理方向,并奠定了用于圖像識別的深度神經網絡發展基礎[7]。He等人[8]借鑒門閥控制流的思想,改善了學習目標和難度。谷歌是最早將無人汽車上路實測的公司,探討了無人汽車上路的可能性[9]。緊隨其后的就是特斯拉公司,其“Autopilot”技術取得了重大的突破,使得無人駕駛汽車在某些特定情況下,汽車已經基本實現自動駕駛[10]。王凌霄等人[11]探討了農村“最后一公里”無人機配送的可能性。郭興軍[12]對“最后一公里”的任務分配和路徑規劃進行優化,并取得了良好的結果。
1.2 精準匹配相關技術
雙邊匹配問題可以簡單的概括為根據供需雙方的需求信息,尋找出匹配雙方一對一、一對多、多對多的穩定組合方式。雙邊匹配的目的是使匹配雙方最大化找到滿意的對方。目前,雙邊匹配應用最廣泛的領域就是在未婚男女的婚姻匹配方面。雙邊匹配的開端源于Gale和Shapley(1962)提出的“高考入學和穩定婚姻問題”,他們對穩定匹配的存在性、最優穩定匹配、遞延接受算法和匹配問題的線性規劃等進行了開創性的研究[13]。在實際研究中,張海燕等人[14]根據數據包洛分析法的基本原理,將不同的方法結合起來進行評價,從而對物流供應商進行篩選,使得選擇的結果會更加的科學、合理和有效。牛志強等人[15]利用一個多智能體的框架,來模擬物流配送中不同配送波次策略下的訂單交付過程,表明了不同的網絡購物需求對應著不同的配送波次策略。Mehrdad Rostami等人[16]使用了基于群體智能的各類算法,應用到了特征選擇上,并與傳統的SI algorithm方法相比較,獲得了更好的結果。袁鐸寧等[17]對手術醫生和擇期手術患者這類一對多的雙邊匹配問題,構建了滿足期望水平的醫患穩定匹配方案的多目標優化模型。孔德財等[18]針對貨車司機和貨主的匹配關系,以雙方滿意度最大為目的,雙目標精準匹配優化模型。
雖然精準匹配技術已經在某些行業種進行應用,并取得了一些成果,但目前尚未見關于客戶和物流服務商的穩定匹配研究。因此,關于物流行業中客戶和物流服務商的穩定匹配研究具有一定的理論意義和實際價值。基于此,本文在穩定匹配的理論基礎上,提出一種考慮物流需求約束的物流精準穩定匹配方法。
1.3 群智推薦算法
推薦算法在電子商務領域的應用較為廣泛,推薦算法的廣義定義是,通過一些數字算法,推測出用戶可能喜歡的事物。目前,推薦算法可以大致的分為三類,基于內容的推薦算法、協同過濾推薦算法和混合推薦算法。基于內容的推薦,是利用事物的內容信息做出推薦,不需要用戶的評價意見,這種方法可以獲得更好的推薦精度,但因為基于事物的內容推薦,會產生冷啟動問題。協同過濾推薦算法使目前應用最廣泛的推薦算法,它是利用和目標用戶相似喜好的鄰近用戶的喜好來進行推薦,這樣做的好處是能有效的利用內容,發掘用戶的潛在偏好。混合推薦算法,由于不同推薦算法有不同的缺點和優點,所以在實際中經常被采用多種推薦算法組合使用。群體智能是模仿大自然某些生物的社會行為,應用到了計算機系統當中。相比于其他算法,群體智能算法在解決優化問題上優勢更大。群體智能,自1991年意大利學者Dorigo提出蟻群優化理論開始,群體智能作為一個理論被正式提出[19]。任帥等[20]將蟻群聚類應用到協同過濾的推薦算法中,用于改善算法收斂難、冷啟動的問題。劉嬌[21]為改善協同過濾推薦算法的種種弊端,引入了群體智能中的布谷鳥搜索算法,并獲得了較大的成功。王靜[22]使用協同過濾推薦算法應用于學習資源的推薦,為了取得更好的效果,采用群體智能中的蟻群算法作為優化策略。
1.4 存在的問題及解決的基本思路
綜上,目前尚缺少針對物流服務交易群智推薦算法的研究成果。為了解決物流服務交易中,查找匹對的物流需求信息難、獲取精準的物流需求信息慢的問題。本文解決的基本思路是:第一步、分析研究物流交易信息的快速查找與精準匹配算法,第二步進行智能預測和群智推薦算法的研究。
2 物流服務交易信息匹配模型的構建
2.1 物流服務交易流程分析
物流服務交易流程是指在復雜的互聯網環境下,由多物流服務交易平臺提供的物流服務商發布的物流服務信息,客戶發布的物流的需求信息。然后,由供求雙方根據發布的信息與滿足自身需求的物流服務商或客戶進行聯系、商談、議價和達成交易,最后由物流服務商完成物流服務。傳統的物流服務交易流程如圖1所示。
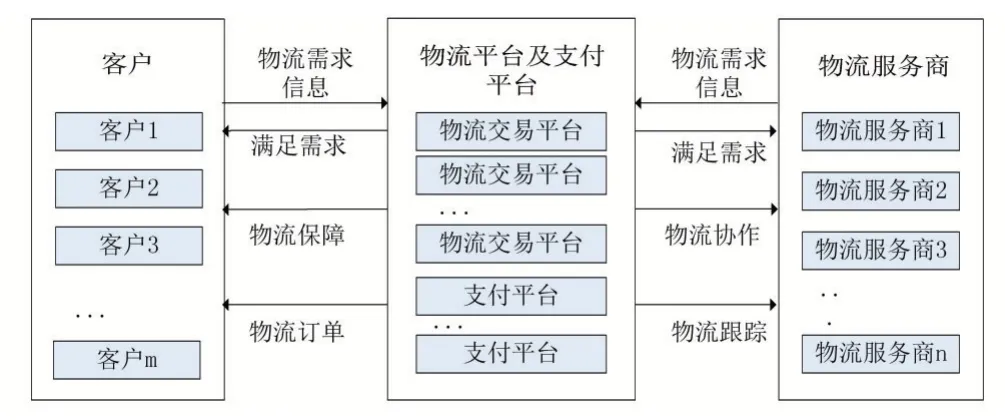
圖1 傳統的物流服務交易流程
在圖1中客戶和物流服務商根據自身需求,通過互聯網查找到相應的服務信息,客戶通過平臺獲得對應物流服務商的物流訂單,物流服務商也可以通過平臺對相應的物流進行跟蹤。客戶和物流服務商之間的付款方式通過第三方支付平臺。平臺可以將雙方需求可視化,對在這條供應鏈上的物流服務進行優化。人工精準匹配方法有時會稱為主觀經驗法,該方法是依靠決策者的主觀分析和判斷,在匹配過程中充分發揮人的智慧作用,主要包括評分法、分等級、加權平均法等。雖然這些方法具有簡單直觀、易于使用的優點,但評價結果很大程度上依賴于專家的水平和對客戶或物流服務商的認知程度。
2.2 物流信息的查找
物流信息一般伴隨著物流活動的產生而產生,包括包裝、倉儲、裝卸、運輸等各方面的信息。導致物流信息進行爆炸式增長,如何從物流信息中針對用戶的需求信息,檢索到符合用戶要求的物流服務商,成為亟待解決的問題[23]。文獻[23]中,首先從需求信息文本中提取出地點、供應、需求屬性,根據提取出來的屬性值,尋找最優路徑,并推送給相應的客戶。
2.3 影響物流交易信息精度匹配的因素
物流服務一般可以根據物流時間、物流費用、物流效率來進行衡量,在物流服務中需要減少物流時間、降低物流成本、提高物流效率。根據網絡上所發布的信息,一般客戶和物流服務商主要關注物流價格、物流載重、物流時間、物流冷鏈等方面。不論是物流價格,還是其他需求屬性,每個需求屬性所受到的影響因素也不盡相同,匹配雙方對需求屬性的定義也不盡相同。比如說物流價格,物流服務商一般希望這個價格越高越好,而客戶更希望這個價格越低越好,雙方都有一個價格接受區間,物流成本一般受到天氣、人工、距離等因素的影響,其他需求屬性同理。隨著科技的發展,有些冷鮮類食物要求需要冷鏈進行運輸,相比普通的運輸方式,冷鏈運輸的成本會更高,影響因素更為復雜。
2.4 物流交易信息多目標匹配優化和分析
單目標優化因為只有一個目標,可以根據該目標比較解的好壞。多目標優化一般指的是情境中,需要達成多個目標,由于多個目標間容易存在沖突,很難得出唯一最優解,所以在目標之間做出折衷和協調處理,使總體的目標盡可能達到最優。由于精準匹配雙方一般會有多個需求信息進行匹配,每個需求信息對匹配雙方的定義不同,并且需求屬性間甚至會存在內在沖突,這點恰好與多目標優化進行對應。根據已有研究,本文在求解精準匹配問題時考慮的需求屬性有:價格(fa1)、服務所需時間(f a2)、載重(fa3)、含有冷鏈(fa4)。通過對精準匹配屬性分析,將其分為三種類型,根據類型不同進行求解,形成最優的匹配關系。多目標優化視角下精準匹配模型構建為:

約束條件:
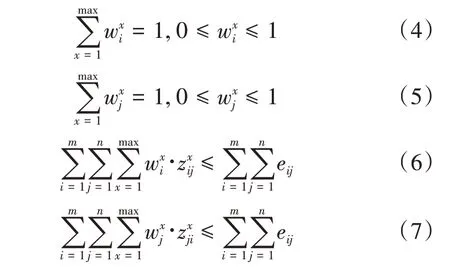
設m為甲方個體數,n為乙方個體數,假設甲乙雙方需求條件數都為x,和分別表示甲方和乙方的對應需求條件的權重值,和分別是下位所求出對應的滿意度。上述模型中,式(1)表示匹配雙方滿意度平均值的最大值。式(2)表示甲乙雙方達成匹配的匹配對數量的最大值。式(3)表示一方個體i與另一方個體j是否達成匹配。式(4)表示甲方各需求條件權重比例之和為1,且各需求條件比重大于0。式(5)表示乙方各需求條件權重比例之和為1,且各需求條件比重大于0。式(6)表示甲方個體總需求條件滿意度之和不超過匹配對個數。式(7)表示乙方個體總需求條件滿意度之和不超過匹配對個數。
2.5 物流交易信息匹配模型
物流交易匹配模型大體如圖1所示。
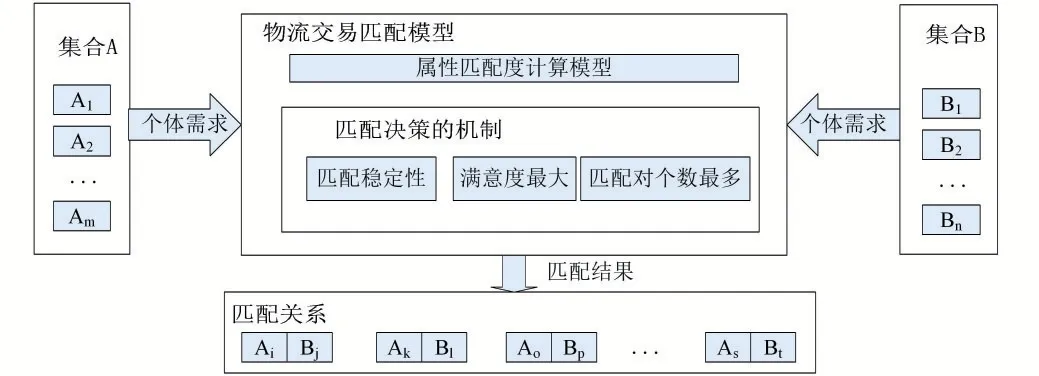
圖2 物流交易匹配模型
從精準匹配角度來看,匹配公式如式(1)、(2)、(3)所示。
3 基于粒子群算法的物流交易信息群智匹配算法
3.1 算法設計
基于2.3中的原則和需求,構建群智匹配算法。將群體智能和精準匹配相結合,使用群體智能中的多目標粒子群優化算法,對群智匹配算法的求解過程進行優化,讓其更快找到最優解。約束條件設為每個客戶只能與一個物流服務商進行配對。本文對粒子群算法的慣性權重進行改進,使粒子能夠較快的收斂于全局最優值。將z ij作為粒子群的目標函數,隨機初始化粒子群的粒子,找到使z ij最大的時的匹配對,并輸出該條件下的匹配對。粒子位置xi更新公式不變,速度vi更新公式調整為:
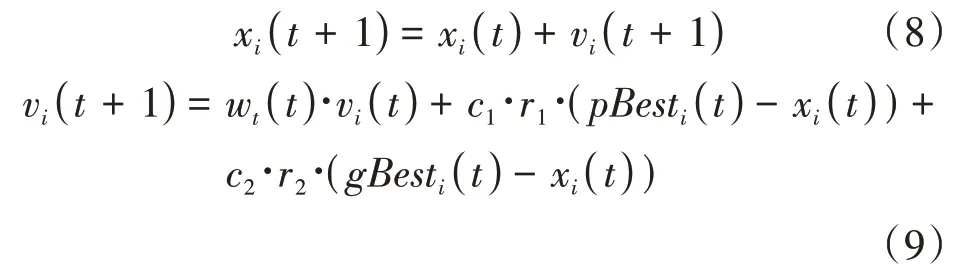
其中,t為算法的迭代次數,r1、r2是分布在[ 0,1]的隨機數,c1,c2為常數,pBest i(t)為第t代單個粒子找到的個體極值,g Best i(t)為第t代整個粒子群目前找到的全局極值,wt為慣性權重。由于粒子群算法搜索方案是用粒子在整個空間進行搜索,需要在開始搜索階段,是慣性權重較大,結束搜索階段,慣性權重較小,即慣性權重隨著迭代次數的增加而逐漸減少,其數學描述如式(12)所示:
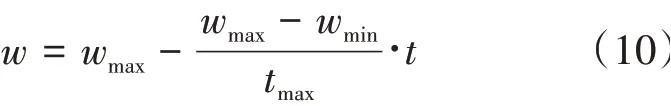
通過上述的改進,可得如下算法:
算法1改進粒子群算法
輸入:初始化后客戶和物流服務商的需求信息。
輸出:每個客戶和每個對應的物流服務商的滿意度。
Begin:
步驟1 初始化粒子群中各粒子的位置和速度,設定粒子群的各項參數。
步驟2 計算種群中每個粒子的適應度值,初始化種群個體最優值和全局最優值,將目前各粒子的的位置信息和適應度值存儲在pi中,將目前所有粒子的中適應度值最優的給位置和適應度值存儲進p g中。
步驟3 根據式(12)對慣性權值進行更新。
步驟4 根據式(10)和(11)對各粒子的位置和速度信息進行更新。
步驟5 各粒子適應度值與其經過的最好位置進行比較,以更新粒子當前的個體最優值。
步驟6 各粒子適應度值和種群全局最優值進行比較,以更新粒子當前的全局最優值。
步驟7 找到使f(M k)最小的值,就是所找到了最優匹配方案(相對于客戶)。
步驟8 若迭代次數達到最大值,則退出程序,否則,轉至步驟3。
End.
3.2 物流交易信息的雙邊匹配
雙邊匹配問題,假設在供需雙方數量充足的情況下,客戶集合為A={A1,A2,…,Am} (m≥2),其中Ai表示第i個客戶,i=1,2,…,m;物流服務商集合為B={B1,B2,…,B n}(n≥2),其中B j表示第j個物流服務商,j=1,2,…,n。則I={1 ,2,…,m},J={1 ,2,…,n}。由于物流服務交易流程中雙方主體的需求屬性是多種多樣的,為了選擇出最適合客戶的物流服務商,設Ai個體期望需求條件為,B j個體實際需求條件為,f axi表示第i個客戶的需求條件,表示第j個物流服務商的需求條件,max表示最多的需求條件。客戶選擇物流服務商,根據客戶和物流服務商的需求屬性的匹配度來衡量雙方主體的匹配程度,記為z xij。M k={ (i,j)|i∈m,j∈n}是客戶和物流服務商之間其中一個有效匹配,M={M1,M2,…,M k}是所有有效匹配的集合。根據不同需求屬性類型,定義不同的匹配度函數。
(1)收益型屬性。收益型屬性表示屬性越大越好,定義函數為客戶對物流服務商的屬性x的匹配度:
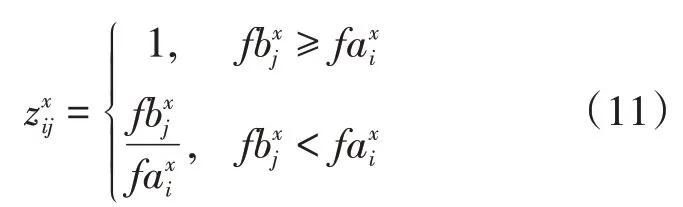
(2)成本型屬性。成本型屬性表示越小越好的屬性,定義函數為客戶對物流服務商的屬性x的匹配度。
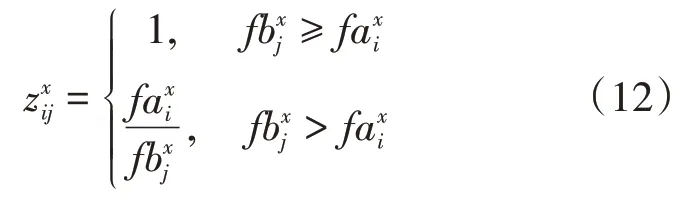
(3)硬約束和區間型屬性。硬約束是指必須滿足等號約束條件,區間型屬性是指要求屬性符合某個區間。

客戶對不同的需求條件有著不同的喜好和偏愛,此時應給所有需求條件賦予偏好權值,用來表示客戶對不同需求條件的需求程度不同,用wxi來表示。滿足條件
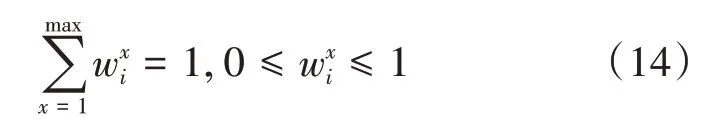
則客戶個體Ai的總滿意度Asi為:
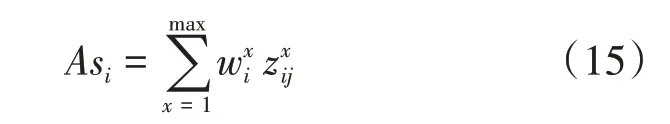
客戶將所有物流服務商按照Asi的大小進行排序,從而得到客戶Ai對所有物流服務商的滿意度排序。標記序號為Ai(B j),表明物流服務商B j在客戶Ai滿意度排序中的排列序號。定義M k的匹配函數為:
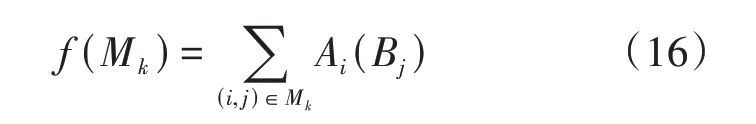
由于本文優先考慮對客戶而言,所以若滿足min[f(M k),M k∈M],且M k是穩定匹配,則M k為客戶優先的情況下最優穩定匹配。
3.3 多目標粒子群物流服務交易信息群智匹配算法
本文針對該流程中的雙方選擇階段,將選擇匹配的過程交給機器,避免效率低下的人工選擇方式。利用粒子群算法的尋優優勢,與雙邊匹配相結合,找尋最優匹配方案。多目標粒子群物流交易信息群智匹配要求匹配雙方需求信息有一個或多個重合點才能進行匹配。該算法流程如圖3所示。
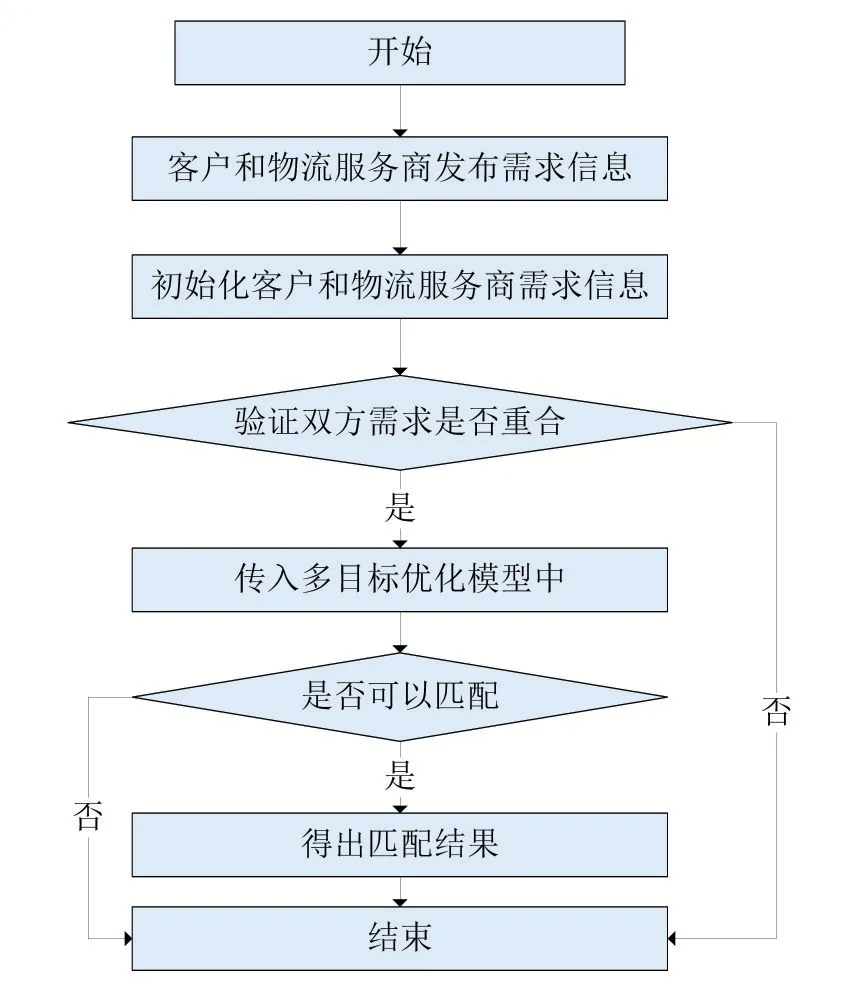
圖3 多目標粒子群物流服務交易信息群智匹配算法
本節將多目標粒子群物流服務交易信息群智匹配算法流程詳細列舉出來,通過客戶和物流服務商的需求信息,找到所有可能的匹配方案,最后使用群體智能當中的粒子群算法,尋找匹配方案中的最優解。
算法2多目標粒子群物流服務交易信息群智匹配算法
步驟1 初始化客戶和物流服務商需求信息
步驟2 將步驟1的初始化信息傳入算法1當中
步驟3 運行算法1并輸出最優解。
步驟4 結束算法
4 物流交易信息分類的Deep FM學習模型
4.1 Deep FM學習模型的優勢
廣告點擊率預測問題(CTR),是推薦系統中一個重要問題,其目的是估計用戶點擊推薦項目的概率。通過對客戶點擊行為背后隱含的特征交互對解決CTR問題有重要意義。例如,在物流服務交易中,每次到了需發貨的時間段,物流服務商的瀏覽量都會增加,這表明時間會和實際工作存在著交互作用。根據文獻[2],同時考慮低階和高階交互比單獨考慮兩者的情況有更多的改善。
4.2 基本Deep FM學習模型的物流交易信息分類
物流信息既包含貨物體積、貨物重量等連續型變量,也包含如是否含有冷鏈這一類的非連續型變量。一般而言,用于模型訓練的原始特征總是高度稀疏的、超高維的、連續和不連續混合的,這種類型數據是無法直接輸入進網絡中進行訓練。需要一個嵌入層將這些輸入向量壓縮成一個低維的、密集的向量,然后在進一步輸入進第一個隱藏層當中。根據模型文獻[4]的DeepFM模型,對其進行改進并運用到物流行業中,測試效果。模型使用因子分解機(FM)來學習低階特征交互,深度神經網絡(DNN)來學習高階特征交互,將FM和DNN并行結合隱式的交互這些特征。不論是連續型變量還是非連續型變量都可以輸入進網絡中,對其進行分類。最后,輸出預測結果,并展示給用戶。
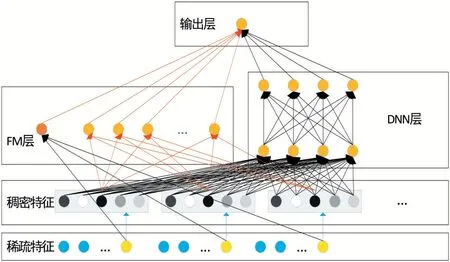
圖4 Deep FM模型架構
從圖中可以很明顯的看出FM層與中間層是并行關系,它們共享輸入的稠密特征,所以deepFM的預測結果就可以認為是:
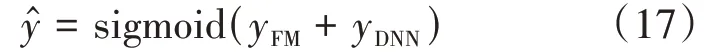
其中,?∈(0,1)用來預測是否會選擇哪些物流服務商,yFM就是FM的輸出部分,yDNN則是中間層的輸出部分。
4.3 因子分解機
因子分解機(factorization machine,FM)是Steffen Rendle提出的一種基于矩陣分解的機器學習算法[24]。在推薦系統中,用戶和項目之間一般不僅僅是線性關系,還包含一些非線性關系,所以采用FM框架來學習特征之間的線性關系,以及使用潛在向量的內積表示特征與特征之間交互作用。
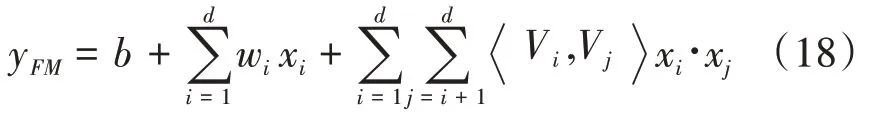
FM可以有效的捕捉二階特征交互,特別是在數據集較為稀疏的情況下。在以往的方法中,使用線性回歸的方法只能用來表示特征與特征之間的線性關系,沒有考慮到特征與特征之間的交互關系。在引入特征之間交互關系后,如果數據集中成對成對的特征沒有交互,將會影響最終模型的效果。而在FM模型中特征之間的交叉關系使用潛在矩陣的內積來表示,可以將沒有關聯的特征之間的交互關系進行隱式表達。所以,如果訓練數據中從未出現或很少出現數據交互的情況下,用FM是一個很好的解決方案。
4.4 深度神經網絡
在模型中,深度部分是一個多層的前饋神經網絡組成。一般在推薦系統中所收集的原始特征是高維且稀疏的,而深度神經網絡要求數據是低維且密集的,否則會導致網絡難以訓練。需在數據進入到網絡前對數據進行預處理,對數據進行特征工程,采用嵌入層將稀疏特征映射成稠密特征。具體來說,嵌入可以將每個one-hot向量ei(第i個位置為1,其他位置為0的稀疏矩陣)通過查找來獲得相應的行向量。嵌入層的輸出表達:
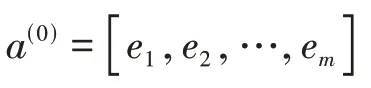
其中,m表示共有多少數據。然后,前饋神經網絡的表達式為:
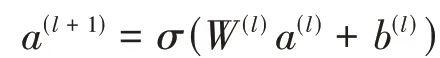
其中,l是層數,σ是激活函數,a(l)是l層的輸出,W(l)是模型權重,b(l)是第l層的偏置。最后,輸出一個特征函數,使用激活函數來進行多分類。
由于FM部分和DNN部分共享嵌入層的輸入,使整個網絡直接從原始數據當中學習低階和高階特征,模型可以不用在使用特征工程預處理數據集了。
4.5 算法比較
許多基于深度學習的推薦系統使用相似的基本思路處理數據集中的稀疏特征。谷歌公司更是提證明了推薦模型學習兩種特征是要優于只學習一種特征模型。例如,FNN,PNN以及Wide and Deep等。FNN是一種使用因子分解機的前饋神經網絡,該網絡只能學習高階特征和特征之間的交互,無法學習低階特征。PNN與FNN恰恰相反,它可以學習高階特征,而忽視低階特征。Wide and Deep既可以學習高階特征也可以學習低階特征,但是需要特征工程來對數據進行預處理。DeepFM不僅能學習高階特征和低階特征而且可以學習特征之間的交互關系,不需要特征工程,直接從原始特征當中進行學習,DeepFM模型與其他模型的比較如表1所示。
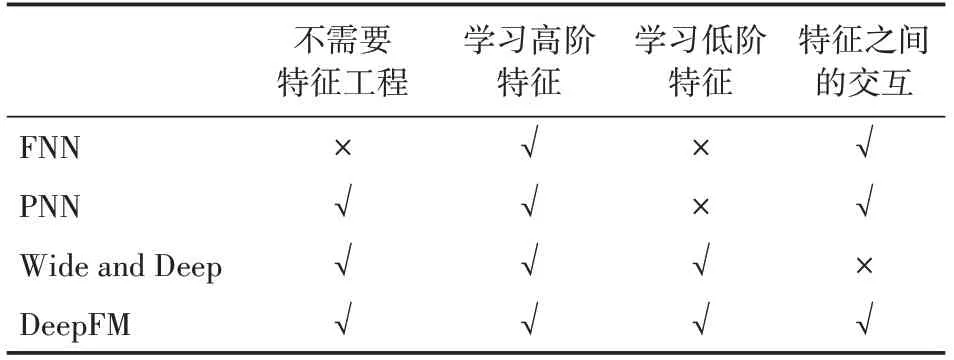
表1 與其他深度模型的比較
4.6 數據
為了保證模型測量的準確性,測試模型的整體性能,需要創建和獲取用于實現的數據集以供測試。本實驗采用了經典數據集criteo,該數據集是由13個連續型特征和26個離散型特征組成,訓練集有4000萬行,測試集有600萬行。但該數據集沒有提供各個特征所代表的名稱,我們無法了解到具體特征含義。
5 物流服務交易群智推薦算法
為構建物流服務交易群智推薦算法,提高物流服務交易效率,本文將群體智能、深度學習以及匹配推薦等技術綜合應用起來。其中,群體智能采用的是粒子群算法,深度學習運用的是DeepFM模型。粒子群算法(PSO)是群體智能中使用最普遍的一種智能算法,具有快速的搜索能力、易于理解的算法結構和易于實現的算法思想等優點,但該算法在搜索過程中局部搜索能力較差、搜索精度不高,不利于種群跳出局部最優解,針對復雜問題,算法又可能收斂不到全局最優解。DeepFM模型是在谷歌的Wide&Deep模型基礎上進一步改進提出的模型,有效的解決了低階特征和高階特征在模型中進行交互的問題,完全避免了特征工程,但該模型依然需要龐大的數據來完成訓練。
算法3物流服務交易群智推薦算法
步驟1 初始化客戶和物流服務商雙方需求信息。
步驟2 將初始化后的信息輸入進多目標粒子群物流服務交易信息群智匹配算法當中。
步驟3 運行算法2并輸出結果。
步驟4 收集數據集,并進行歸并整理,選出部分作為訓練集,另一部分作為測試集。
步驟5對DeepFM模型使用訓練集進行訓練,并用測試集檢驗模型的性能。
步驟6 將步驟3里的內容輸入進模型,進行預測,得出預測結果。根據預測結果進行相應的推薦。
6 實驗結果與分析
6.1 應用實例
為驗證本文提出的改進粒子群算法應用多屬性匹配中的有效性,在多個模擬仿真平臺上進行實驗。假設某物流平臺有如下物流交易意向信息:有10個客戶(A1,A2,…,A10)需要物流服務,10個物流服務商(B1,B2,…,B10)提供物流服務。假設雙方主體由4種需求屬性,分別是價格(fa1)、服務所需時間(fa2)、載重(fa3)、是否有冷鏈(fa4),其中價格為成本型屬性,服務所需時間為區間型屬性,載重為效益性屬性,而最后冷鏈為硬約束屬性。相應的權重系數分別為w1=0.5、w2=0.3、w3=0.1、w4=0.1。假設一個客戶只能選擇一個物流服務商。客戶和物流服務商的交易意向如表1、表2所示。
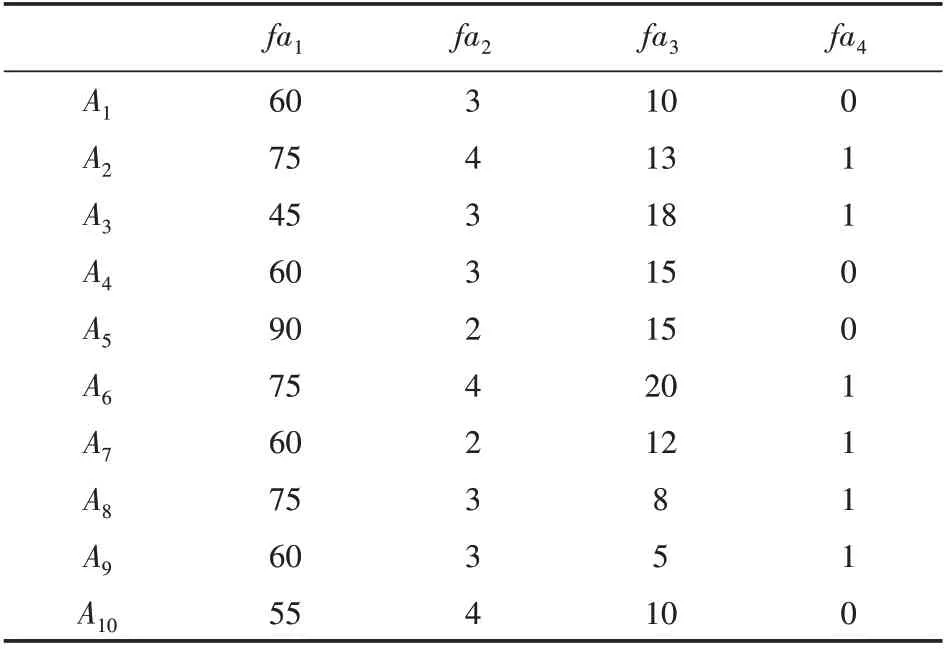
表2 客戶交易意向信息
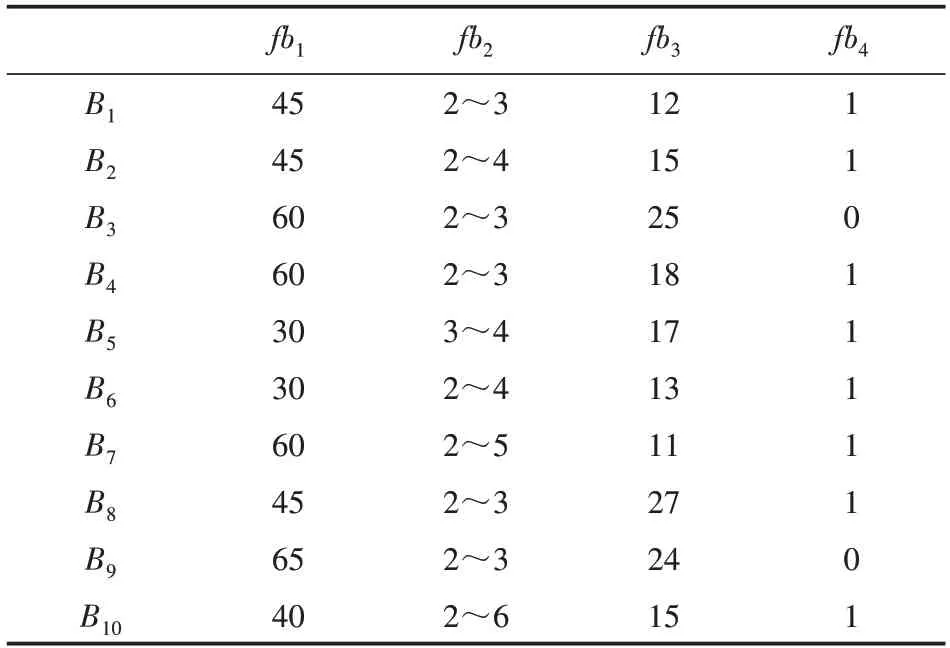
表3 物流服務商交易意向信息
數據集是由實例(X,y)組成,其中X通常記錄了一對客戶和物流服務商,以及y∈{ }0,1是指客戶選擇物流服務商的行為,其中y=1時表示客戶選擇了該物流服務商,否側y=0。數據集使用的Criteo數據集包含了4500萬用戶記錄,共有13個連續特征和26個非連續特征,將該數據集分為兩份,80%用于訓練,其余20%用于測試。在該模型中各項參數設置為:①dropout參數:0.5。②大致的網絡結構:400-400-400。③優化器:Adam。④激活函數:ReLU。
6.2 實驗環境與實驗參數
為驗證本文提出算法的有效性,在多平臺物流系統中進行模擬仿真實驗。使用python語言編寫算法,并在多個模擬平臺中加入該算法,進行模擬仿真實驗。
實驗測試計算機硬件環境如下:處理器Intel Core i5-9400F,顯卡GeForce GTX 1660,內存8 GB,采用的計算機軟件環境,是在Pycharm中的Python環境中運行所有實驗,使用Tensorflow工具包來搭建、訓練和測試DeepFM模型
6.3 實驗結果
匹配結果如表4所示。
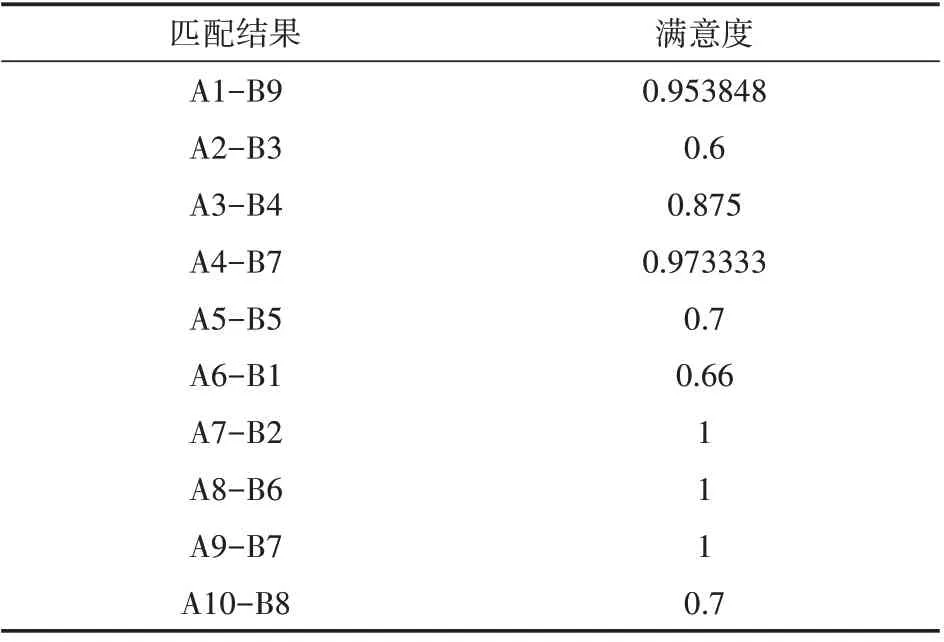
表4 匹配結果及總體滿意度
由于無法直觀的觀察到改善后的粒子群算法的性能,所以在相同參數下,對改進粒子群算法和傳統粒子群算法進行300此迭代后性能對比,改進粒子群算法和傳統粒子群算法的對比如圖5和圖6所示。
由圖5和圖6的對比可以發現,改進粒子群算法相比于傳統粒子群算法可以更快的收斂于最優值,比傳統粒子群算法效率更高。
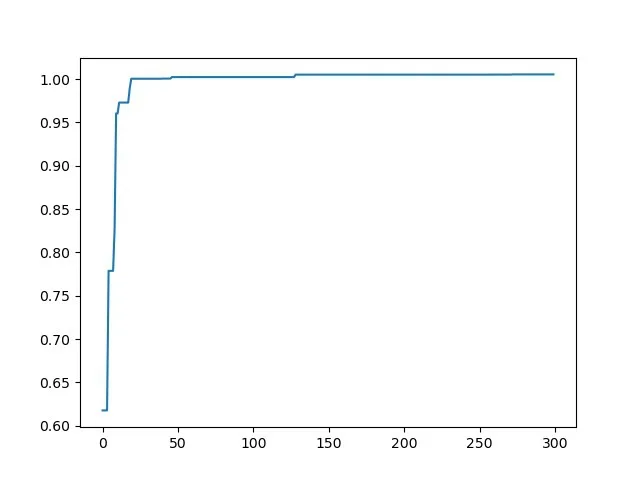
圖5 傳統粒子群算法
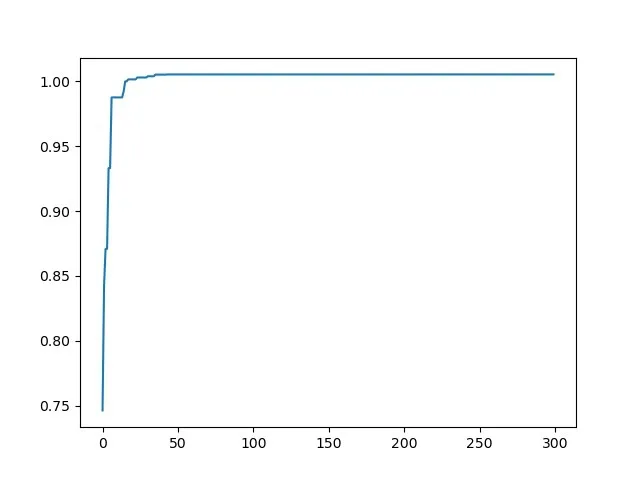
圖6 改進粒子群算法
為了測試本文中運用DeepFM模型所取得的效果,通過準確率和損失函數來評估模型的性能。都采用相同的數據集,將其他四種模型與DeepFM進行對比,對比結果如表5所示。相比于其他模型,DeepFM的準確率提升了1%左右,而損失函數降低了2%左右。
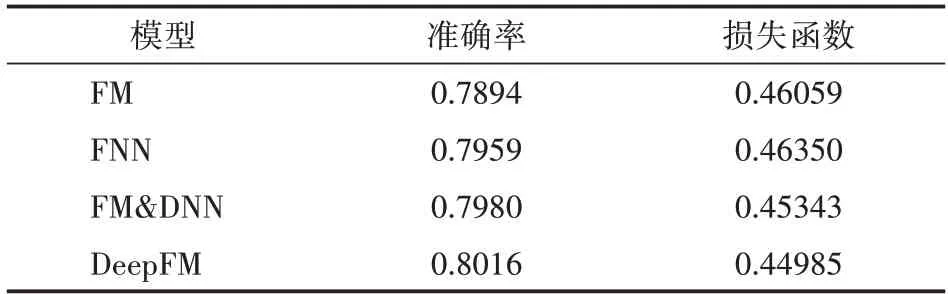
表5 各模型的性能對比
6.4 實驗結果分析
從圖5和圖6的對比可以發現,改進粒子群算法相比于傳統粒子群算法可以更快收斂到最優值上,明確的表現了改進粒子群算法相比于傳統粒子群算法的優勢。
從表5可以看出,學習特征之間的交互提高了DeepFM的性能。同時學習低階和高階特征交互,再次提高了模型的性能,相比于只學習低階特征交互或高階特征交互的模型,DeepFM達到了最好的學習效率。同時學習高階和低階特征交互以及高階和低階特征交互特征提高了模型的性能。DeepFM要優于只學習單獨特征交互的模型。總體而言,DeepFM模型相比于其他深度學習模型有明顯提升改善。
7 結語
本文提出了雙邊匹配和群體智能結合的方法,用于解決客戶和物流服務商之間的多屬性交易匹配問題,使用改進后的粒子群算法進行尋優,有效地提升了傳統粒子群算法收斂速度慢的問題。深度學習及推薦算法的結合,預測客戶是否會選擇匹配的物流服務商,仿真實驗表明,該預測方法可以達到80%的準確率。通過該論文發現,客戶和物流服務商之間的交易不單單指本文所列出的屬性,也包含其他屬性,依然有不少問題亟待研究,因此,依然需要我們深入探索,進一步研究出更好的解決方案。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
物流技術與應用(2019年8期)2019-09-04 03:29:56
當代陜西(2019年10期)2019-06-03 10:12:04
汽車觀察(2018年12期)2018-12-26 01:05:44
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
現代企業(2015年2期)2015-02-28 18:45:09
中外會展(2014年4期)2014-11-27 07:46:46
商界(2014年12期)2014-04-29 00:44:03
河南科技(2014年23期)2014-02-27 14:19:15
