神經(jīng)網(wǎng)絡(luò)架構(gòu)搜索發(fā)展綜述
2022-02-02 08:47:08潘曉英戚玉濤
西安郵電大學(xué)學(xué)報 2022年4期
潘曉英,曹 園,賈 蓉,戚玉濤
(1.西安郵電大學(xué) 計算機學(xué)院,陜西 西安 710121;2.西安郵電大學(xué) 陜西省網(wǎng)絡(luò)數(shù)據(jù)分析與智能處理重點實驗室,陜西 西安 710121;3.西安電子科技大學(xué) 計算機學(xué)院,陜西 西安 710071)
近年來,在人工智能產(chǎn)業(yè)的興起和快速發(fā)展的背景下,機器學(xué)習(xí)領(lǐng)域成為當(dāng)下研究熱點。機器學(xué)習(xí)研究領(lǐng)域主要包括統(tǒng)計機器學(xué)習(xí)[1]和深度學(xué)習(xí)[2]兩方面內(nèi)容。統(tǒng)計機器學(xué)習(xí)在數(shù)據(jù)預(yù)處理、特征工程和模型選擇等方面需要人工搭建網(wǎng)絡(luò)才能完成。在深度學(xué)習(xí)領(lǐng)域中,所需要的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)通常情況下也是人工設(shè)計,為了得到一個性能較好的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),需要耗費大量計算資源,因此出現(xiàn)自動化機器學(xué)習(xí)[3](Automated Machine Learning,AutoML)用以解決此類問題。AutoML的研究目標(biāo)是機器自動學(xué)習(xí)并對神經(jīng)網(wǎng)絡(luò)架構(gòu)搜索(Neural Architecture Search,NAS)數(shù)據(jù)訓(xùn)練和超參數(shù)優(yōu)化等做出相應(yīng)的決策,以獲取最佳方案。
自動化深度學(xué)習(xí)作為AutoML的分支,其目標(biāo)是通過元學(xué)習(xí)[3]的方法讓機器學(xué)會自動調(diào)參優(yōu)化,不僅受到機器學(xué)習(xí)研究方面的關(guān)注,而且還在計算機視覺[4]、數(shù)據(jù)挖掘[5]、圖像分割[6]和自然語言處理[7]等方面有著廣泛應(yīng)用。NAS作為自動化深度學(xué)習(xí)的研究前沿,具有廣闊的前景,其研究重點是根據(jù)當(dāng)前問題的特點,通過機器自動搜索網(wǎng)絡(luò)中性能更好、表現(xiàn)最優(yōu)的結(jié)構(gòu),與傳統(tǒng)人工設(shè)計網(wǎng)絡(luò)相比可以降低花費的時間和人力成本等,并可以進一步提高搜索效率和神經(jīng)網(wǎng)絡(luò)的性能。擬以發(fā)展時間為線,簡述神經(jīng)網(wǎng)絡(luò)架構(gòu)搜索發(fā)展過程,結(jié)合算法所需的實驗條件,對各種算法進行整理歸納,從多角度探討NAS的發(fā)展變化,著重分析典型神經(jīng)網(wǎng)絡(luò)架構(gòu)搜索算法的特點和不足,并對研究內(nèi)容進行總結(jié),探討神經(jīng)架構(gòu)搜索技術(shù)未來發(fā)展趨勢。
1 神經(jīng)網(wǎng)絡(luò)架構(gòu)搜索簡述
在深度學(xué)習(xí)領(lǐng)域的研究歷程中,網(wǎng)絡(luò)結(jié)構(gòu)總是由簡單到復(fù)雜,由淺顯到深入,從最初的LeNet[8]到AlexNet[9]、VGGNet[10](Visual Geometry Group Network)、GoogLeNet[11]以及深度殘差網(wǎng)絡(luò)[12](Deep Residual Network,ResNet)。隨著網(wǎng)絡(luò)深度加深,模型結(jié)構(gòu)也變得越來越復(fù)雜。盡管這些網(wǎng)絡(luò)模型表現(xiàn)良好,但人工設(shè)計的網(wǎng)絡(luò)模型調(diào)參優(yōu)化工作非常耗費人力物力。網(wǎng)絡(luò)結(jié)構(gòu)參數(shù)以及眾多的超參數(shù)形成的爆炸性組合使得優(yōu)化難度呈指數(shù)型增長。因此,構(gòu)建高效的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)以及進行高效的網(wǎng)絡(luò)搜索對網(wǎng)絡(luò)模型十分重要。
NAS的機制是在特定的數(shù)據(jù)集上從零開始采用一定的策略自動構(gòu)建性能良好的網(wǎng)絡(luò)模型。一般NAS問題可以被定義為搜索空間、搜索策略和性能評估等3個子問題。通過搜索空間構(gòu)建網(wǎng)絡(luò)框架,采用相應(yīng)的搜索策略進行網(wǎng)絡(luò)結(jié)構(gòu)搜索,并對搜索得到的網(wǎng)絡(luò)進行評估,根據(jù)評估結(jié)果進行反饋更新搜索策略。NAS結(jié)構(gòu)示意圖如圖1所示。

圖1 NAS結(jié)構(gòu)示意圖
以基于循環(huán)神經(jīng)網(wǎng)絡(luò)(Recurrent Neural Network,RNN)的神經(jīng)架構(gòu)搜索為例,神經(jīng)網(wǎng)絡(luò)架構(gòu)算法根據(jù)數(shù)據(jù)集生成特定的“子網(wǎng)絡(luò)”,并對子網(wǎng)絡(luò)進行訓(xùn)練,得到該子網(wǎng)絡(luò)在驗證集上的準確度,將該準確度作為反饋信號,計算策略梯度更新RNN控制器。在下一次迭代中,控制器為具有更高準確率的網(wǎng)絡(luò)結(jié)構(gòu)提供更高的概率,即控制器將學(xué)習(xí)如何隨著時間改進其搜索網(wǎng)絡(luò)空間。
搜索空間構(gòu)建是網(wǎng)絡(luò)框架的主要部分,搜索空間的設(shè)計是實現(xiàn)網(wǎng)絡(luò)性能高低的關(guān)鍵因素。傳統(tǒng)的網(wǎng)絡(luò)結(jié)構(gòu)以鏈式為主,在網(wǎng)絡(luò)結(jié)構(gòu)多樣性方面有所欠缺。2016年Zoph等[13]首次使用強化學(xué)習(xí)機制自動產(chǎn)生了一個最優(yōu)的神經(jīng)網(wǎng)絡(luò),開啟了機器自動搜索神經(jīng)網(wǎng)絡(luò)架構(gòu)的新領(lǐng)域,通過一個可變長度的String連接網(wǎng)絡(luò)的結(jié)構(gòu)和循環(huán)體內(nèi)部。在此基礎(chǔ)上,Zoph等[14]基于Cell單元結(jié)構(gòu)設(shè)計了NASNet。NASNet搜索空間在空間多樣性和可遷移性方面有了較大的提升,以適用于更大的數(shù)據(jù)集。由此,搜索空間的設(shè)計從前期的以鏈式結(jié)構(gòu),發(fā)展為現(xiàn)在主要以Cell單元結(jié)構(gòu)為主。
搜索策略主要是解決用高效的方法搜索出性能更佳的網(wǎng)絡(luò)。NAS最早是使用強化學(xué)習(xí)[15]進行搜索。除強化學(xué)習(xí)外,2017年Real等[16]首次將進化算法引入用來解決NAS問題,并被證明了在數(shù)據(jù)集上具有較高的精度。同時,貝葉斯優(yōu)化和基于梯度的方法也被引用到解決神經(jīng)架構(gòu)參數(shù)優(yōu)化問題中,取得了一定的成果。
性能評估主要是采用一定的方法和改進策略,提升計算效率并且降低資源消耗,加速搜索最佳網(wǎng)絡(luò)的進程。2017年Brock等[17]提出SMASH(One-Shot Model Architecture Search through Hypernetworks),利用超網(wǎng)生成權(quán)重,訓(xùn)練整個網(wǎng)絡(luò)。為了加快單樣本的學(xué)習(xí)能力,2018年Bender 等[19]對One-shot模型進行了詳細的研究。同年,Pham等[18]采用權(quán)值共享的方法,對神經(jīng)架構(gòu)進行訓(xùn)練。Liu 等[20]采用代理模型指導(dǎo)結(jié)構(gòu)空間搜索。2019年Liu等[21]提出基于可微分的方式將分散空間進行連續(xù)性表示,采用梯度下降的方式搜索結(jié)構(gòu)。目前,神經(jīng)網(wǎng)絡(luò)架構(gòu)搜索涉及的研究重點內(nèi)容主要是搜索空間、搜索策略和性能評估等3方面,下面將從這3個方面對神經(jīng)網(wǎng)絡(luò)架構(gòu)搜索問題進行詳細的描述,并對不同的策略和算法進行討論總結(jié)。
2 搜索空間
搜索空間是由網(wǎng)絡(luò)結(jié)構(gòu)的深度、操作的類型、連接的類型、核的大小和過濾器數(shù)量等參數(shù)構(gòu)成的網(wǎng)絡(luò)集合,在集合內(nèi)組合各種操作產(chǎn)生網(wǎng)絡(luò)架構(gòu)。不同的操作會產(chǎn)生不同的網(wǎng)絡(luò)架構(gòu),因此構(gòu)建一個合適的搜索空間,便于高效找到最佳的網(wǎng)絡(luò)結(jié)構(gòu)。
搜索空間根據(jù)空間單元結(jié)構(gòu)可以分為宏(marco)搜索空間和微(micro)搜索空間。宏(marco)搜索空間指的是在給定的空間下進行搜索,網(wǎng)絡(luò)深度是固定的,由人為設(shè)定搜索空間,在人為設(shè)定網(wǎng)絡(luò)層數(shù)的基礎(chǔ)上進行網(wǎng)絡(luò)訓(xùn)練和參數(shù)優(yōu)化。從最初設(shè)計只有5層的LeNet[8],到20層的GoogleLeNet[11],再到引入152層的ResNet[12],人工設(shè)計的神經(jīng)網(wǎng)絡(luò)多采用鏈式結(jié)構(gòu)或者多分支結(jié)構(gòu),隨著網(wǎng)絡(luò)深度的不斷加深,產(chǎn)生的參數(shù)也越來越多,消耗了大量的人力物力。于是,微(micro)搜索空間被提出,其將搜索空間設(shè)計成一個Cell單元結(jié)構(gòu)作為基本的空間單元,Cell單元內(nèi)包含若干選擇塊,不同功能的選擇塊代表塊內(nèi)不同的操作。Cell單元結(jié)構(gòu)示意圖[16]如圖2所示。
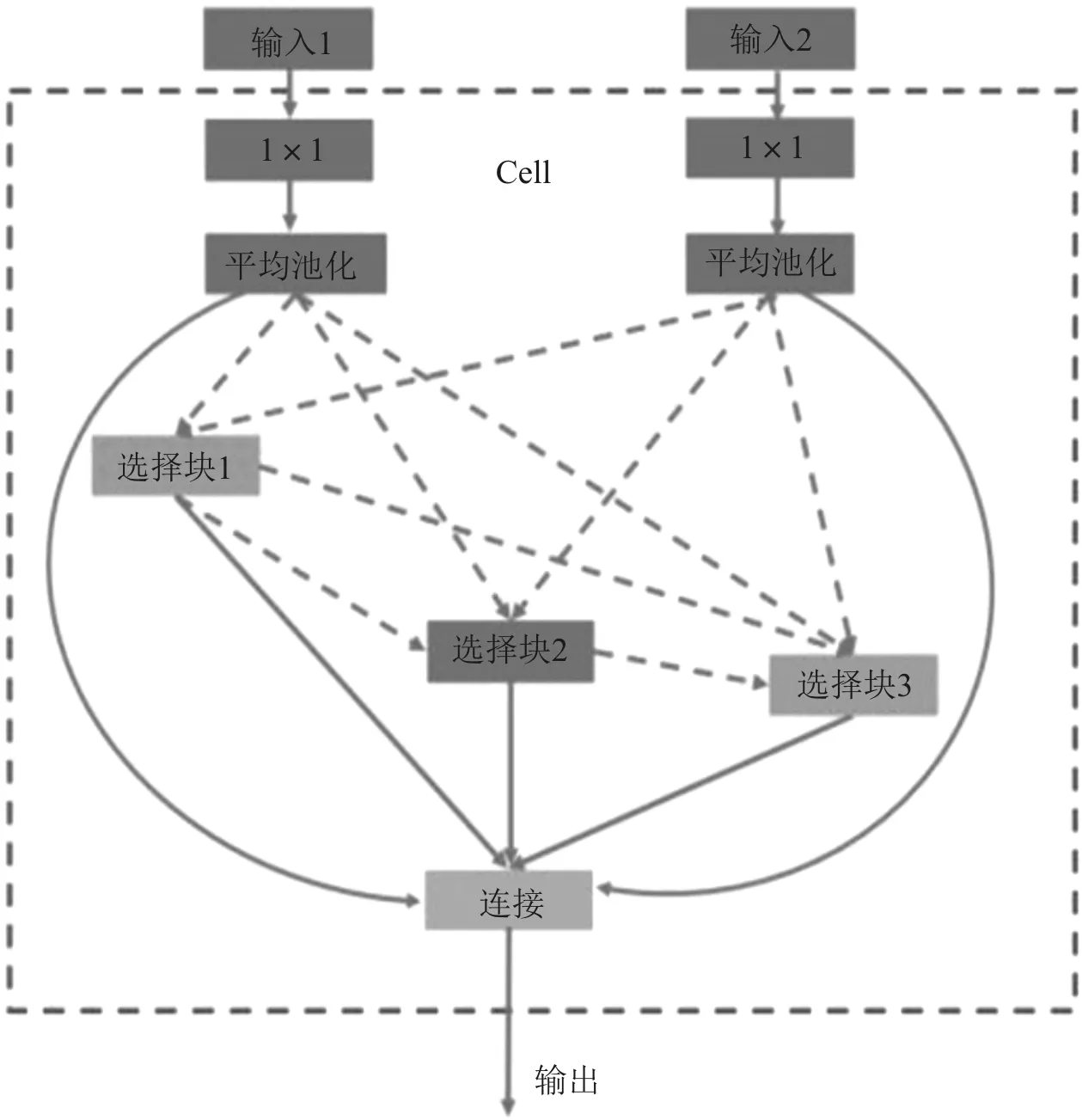
圖2 Cell單元結(jié)構(gòu)示意圖
使用Cell作為空間堆疊的基本單元,在搜索過程中降低了搜索成本,同時增加了搜索空間的空間多樣性。Zoph等[14]在NASNet中間設(shè)計中采用Cell-based結(jié)構(gòu)進行網(wǎng)絡(luò)堆疊,后續(xù)的SMASH[17]以及One-shot模型等也相繼采用Cell單元結(jié)構(gòu)進行網(wǎng)絡(luò)構(gòu)建。目前,搜索空間的研究內(nèi)容主要是鏈式結(jié)構(gòu)、多分支結(jié)構(gòu)以及基于Cell-based結(jié)構(gòu)。
2.1 鏈式結(jié)構(gòu)
鏈式結(jié)構(gòu)是目前較為常見的一種網(wǎng)絡(luò)架構(gòu),LeNet[8]、AlexNet[9]和VGGNet[10]等都采用鏈式結(jié)構(gòu),網(wǎng)絡(luò)的每一層和相鄰的操作層相連,其結(jié)構(gòu)示意圖如圖3所示,L0…Ln為每層的操作,卷積或池化。

圖3 鏈式網(wǎng)絡(luò)結(jié)構(gòu)示意圖
鏈式網(wǎng)絡(luò)結(jié)構(gòu)采用N層順序結(jié)構(gòu),每一層提供卷積和池化等可供選擇的操作算子,每種操作算子中包含卷積尺寸大小和卷積步長大小等超參數(shù)。在網(wǎng)絡(luò)訓(xùn)練的過程中,隨著網(wǎng)絡(luò)深度的加深,網(wǎng)絡(luò)結(jié)構(gòu)更加復(fù)雜,容易出現(xiàn)梯度消失等問題。
2.2 多分支結(jié)構(gòu)
隨著研究者對網(wǎng)絡(luò)結(jié)構(gòu)的研究,發(fā)現(xiàn)網(wǎng)絡(luò)結(jié)構(gòu)的深度達到一定程度后,再進行增加層數(shù)的操作,并不能進一步提高分類性能,反而會造成網(wǎng)絡(luò)收斂變得更慢、梯度消失等問題。為了緩解梯度消失的問題,便出現(xiàn)了人工手動設(shè)計的網(wǎng)絡(luò)架構(gòu),用以研究帶有多分支的網(wǎng)絡(luò),其結(jié)構(gòu)示意如圖4所示。
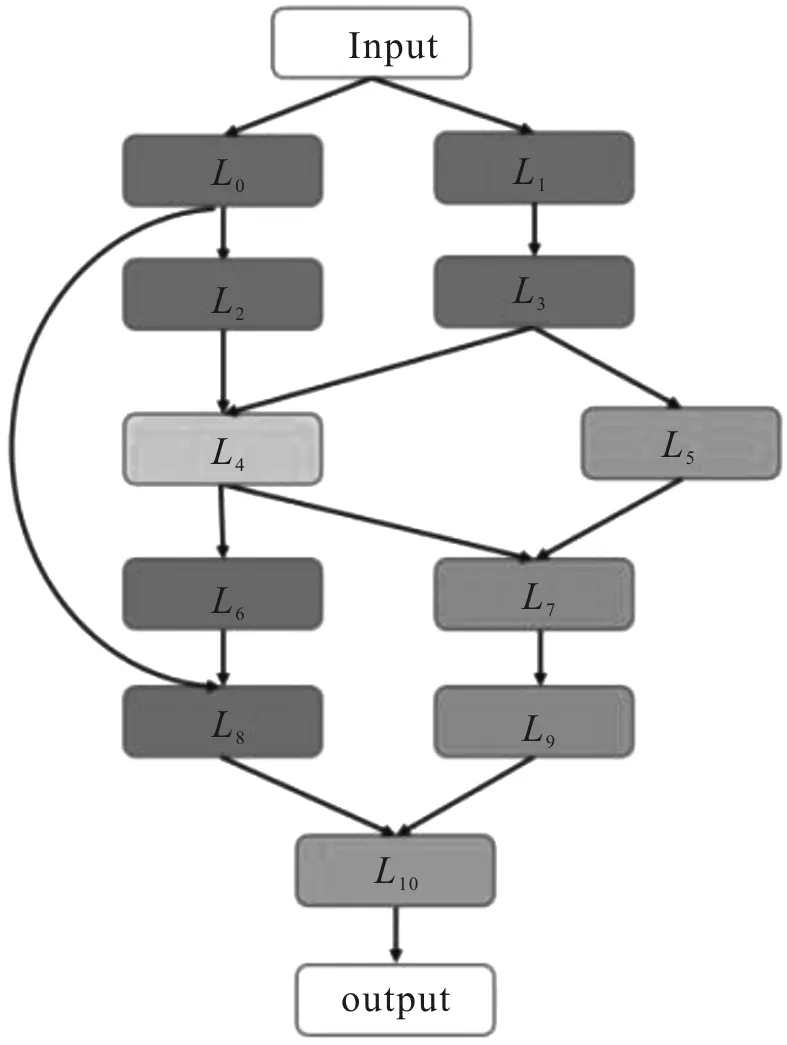
圖4 多分支網(wǎng)絡(luò)結(jié)構(gòu)示意圖
GoogleLeNet[11]引入多分支結(jié)構(gòu),增加了網(wǎng)絡(luò)的深度和寬度。ResNet[12]引入Skip-connection操作,該操作被用來解決網(wǎng)絡(luò)層數(shù)比較深的情況下梯度消失的問題,同時有助于梯度的反向傳播以達到加快訓(xùn)練的效果,并且可以用以構(gòu)建更為復(fù)雜的網(wǎng)絡(luò)結(jié)構(gòu)。DenseNet[22]在此基礎(chǔ)上構(gòu)建網(wǎng)絡(luò),網(wǎng)絡(luò)中的每一層輸入來自前面所有層的輸出,減輕了梯度消失問題,構(gòu)建的網(wǎng)絡(luò)特征傳遞更加有效,網(wǎng)絡(luò)更容易訓(xùn)練。
2.3 基于Cell單元搜索空間
基于Cell單元是通過重復(fù)堆疊固定的Cell單元進行網(wǎng)絡(luò)構(gòu)建,這樣的架構(gòu)一般是較小的單元結(jié)構(gòu)堆疊起來形成較大的網(wǎng)絡(luò)架構(gòu)。這些重復(fù)堆疊的結(jié)構(gòu)被稱為單元(Cell)或選擇塊(Block),單元或者選擇塊內(nèi)包含一些計算操作,比如卷積(Conv)、平均池化(Avgpool)、最大池化(Maxpool)和跳躍連接(Skip-connection)等。目前,很多的深層卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network,CNN)或RNN架構(gòu)中都有類似Cell堆疊的網(wǎng)絡(luò)結(jié)構(gòu),其示意圖如圖5所示,虛線框表示一個Cell單元,Cell內(nèi)的選擇快可以是同一類操作拼接,也可以是不同類操作拼接。盡管網(wǎng)絡(luò)結(jié)構(gòu)很深,但是主體結(jié)構(gòu)還是由Cell單元重復(fù)堆疊形成,將Cell單元結(jié)構(gòu)單獨抽象出來之后進行研究,可以使得復(fù)雜的網(wǎng)絡(luò)結(jié)構(gòu)變簡單,這樣操作的目的一方面可以減少需要優(yōu)化變量的數(shù)目,在另一方面具有同等結(jié)構(gòu)的Cell單元可以在不同任務(wù)之間進行遷移訓(xùn)練。

圖5 Cell堆疊的網(wǎng)絡(luò)結(jié)構(gòu)示意圖
NASNet[14]采用基于Cell單元搜索空間結(jié)構(gòu),通過在預(yù)先定義的排列中重復(fù)Cell單元結(jié)構(gòu)構(gòu)建網(wǎng)絡(luò)。為了構(gòu)建可擴展的神經(jīng)網(wǎng)絡(luò)架構(gòu),當(dāng)使用某個特征圖作為輸入時,有兩種類型的卷積單元:1)正常采樣單元(Normal Cell),不改變特征圖的大小;2)半采樣單元(Reduction Cell),將特征圖的長度和寬度各降低為原來的一半。NASNet使用強化學(xué)習(xí)的方法不斷迭代產(chǎn)生參數(shù),用以更新RNN控制器,搜索在不同數(shù)據(jù)集上,由Normal Cell和Reduction Cell堆疊生成的網(wǎng)絡(luò)結(jié)構(gòu),NASNet彌補了前期基于RNN循環(huán)體的NAS的不足,適用于更大的數(shù)據(jù)集,比如ImageNet、PTB(Penn Tree Bank)等,使其具有更好的遷移性。NASNet[14]在CIFAR-10數(shù)據(jù)集和ImageNet數(shù)據(jù)集上的搜索結(jié)果示例如圖6所示。

圖6 NASNet在數(shù)據(jù)集上的搜索結(jié)果示例
雖然NASNet設(shè)計的網(wǎng)絡(luò)結(jié)構(gòu)取得了不錯的效果,網(wǎng)絡(luò)結(jié)構(gòu)更加密集,但是網(wǎng)絡(luò)結(jié)構(gòu)中關(guān)于Normal Cell和Reduction Cell的位置和數(shù)量以及大量參數(shù)都是人為設(shè)計的,即在人為設(shè)定的框架下進行“自動”搜索,對于自動搜索的研究還是有待提高。2018年,Pham等[18]提出使用一個有向無環(huán)圖表示搜索空間,選取其中不同的操作實現(xiàn)不同的Cell結(jié)構(gòu),即高效神經(jīng)架構(gòu)搜索(Efficient Neural Architecture Search,ENAS),其最大的特點就是參數(shù)共享,選擇子網(wǎng)后在已訓(xùn)練的模型上繼續(xù)訓(xùn)練,節(jié)約了大量的計算時間。如果將Cell作為一個層次,那么組合成的Cell結(jié)構(gòu)也可以被看做一個層次,因此,基于Cell結(jié)構(gòu)的方法提出的基于分層(Hierarchical)思想,極大減少了冗余空間的搜索[23]。漸進式神經(jīng)架構(gòu)搜索[20](Progressive Neural Architecture Search,PNAS)繼承了NASNet的方法,以Cell作為基本的網(wǎng)絡(luò)架構(gòu),在Cell內(nèi)選擇塊(Block)作為基本單位,使用漸進式搜索的方式,從最小的結(jié)構(gòu)開始進行迭代搜索,采用遞增式的增加Cell參數(shù)規(guī)模,使用Surrogate函數(shù)選擇表現(xiàn)最好的Cell結(jié)構(gòu),具有更好的效果。和前期NASNet不同的是,PNAS沒有規(guī)定Normal Cell與Reduction Cell用來調(diào)節(jié)降低搜索空間大小,而是使用步長減少搜索空間。在NASNet基礎(chǔ)上提出的基于可微分架構(gòu)搜索[21](Differentiable Architecture Search,DARTS)將分散空間進行連續(xù)性表示,節(jié)點通過超網(wǎng)絡(luò)的形式構(gòu)建一個大圖,通過梯度下降選取網(wǎng)絡(luò)邊中操作概率最大的操作,形成了一個有向無環(huán)圖,在網(wǎng)絡(luò)結(jié)構(gòu)中1/3和2/3處采用半采樣單元(Reduction Cell),在其他部分采用正常采樣單元(Normal Cell)構(gòu)建完成網(wǎng)絡(luò)架構(gòu)。但是,DARTS在CIFAR-10數(shù)據(jù)集上的網(wǎng)絡(luò)結(jié)構(gòu)設(shè)定為20個Cell單元堆疊形成,并在特定的位置添加正常采樣單元和半采樣單元用來調(diào)節(jié)空間大小,能否通過增加Cell更多的數(shù)量獲得效果更好的結(jié)構(gòu)還有待研究。
實驗表明[14],在深度網(wǎng)絡(luò)結(jié)構(gòu)中,基于Cell結(jié)構(gòu)的網(wǎng)絡(luò)在復(fù)雜度和準確度方面更具有優(yōu)勢,同時遷移學(xué)習(xí)效果更好,同時適用于大型數(shù)據(jù)集。
從網(wǎng)絡(luò)發(fā)展之初的單鏈接網(wǎng)絡(luò)到現(xiàn)在以Cell單元為網(wǎng)絡(luò)基本單元的網(wǎng)絡(luò),Cell單元更適合構(gòu)建更復(fù)雜的空間,空間維度更加靈活,空間容量將會呈指數(shù)型增長,空間結(jié)構(gòu)更加豐富且更加靈活。但是,現(xiàn)有的神經(jīng)架構(gòu)網(wǎng)絡(luò)結(jié)構(gòu)很多都是在人為設(shè)定的框架下進行,存在一定的局限性。隨著搜索空間的研究邁入更高階的維度,構(gòu)建簡單的基本單元和搜索復(fù)雜度高的網(wǎng)絡(luò)成為搜索空間的現(xiàn)狀和研究未來。
3 搜索策略
搜索策略的目標(biāo)便是使用效果最好的搜索算法,對網(wǎng)絡(luò)結(jié)構(gòu)進行搜索,高效、準確地找到網(wǎng)絡(luò)結(jié)構(gòu)的最優(yōu)組合,并對涉及的超參數(shù)進行優(yōu)化,以便搜索最佳的網(wǎng)絡(luò)結(jié)構(gòu)。目前研究的搜索策略主要是基于強化學(xué)習(xí)的策略、基于進化算法的策略、貝葉斯優(yōu)化以及基于梯度的策略。
3.1 基于強化學(xué)習(xí)的搜索策略
強化學(xué)習(xí)主要采取“嘗試”的學(xué)習(xí)機制進行學(xué)習(xí),通過與環(huán)境交流得到反饋后指導(dǎo)下一步學(xué)習(xí)行為。強化學(xué)習(xí)主體由智能體和環(huán)境兩部分組成,智能體同時充當(dāng)著學(xué)習(xí)者和決策者的角色,通過和環(huán)境交流實現(xiàn)目標(biāo)。在t時刻,智能體基于當(dāng)前狀態(tài)St發(fā)出動作At,環(huán)境做出反應(yīng),生成新的狀態(tài)St+1和新的獎勵值Rt+1,通過循環(huán)執(zhí)行,獲取最大的累計獎勵值。強化學(xué)習(xí)交互過程示意圖如圖7所示。

圖7 強化學(xué)習(xí)交互過程示意圖
基于強化學(xué)習(xí)的策略是神經(jīng)架構(gòu)搜索的重點研究內(nèi)容之一,眾多研究者在強化學(xué)習(xí)的基礎(chǔ)上采用不同的優(yōu)化策略研究出很多優(yōu)秀的算法。作為NAS的經(jīng)典算法之一, Zoph等[13]在2016年提出使用一個RNN循環(huán)控制器作為智能體,在搜索空間中先搜索一個初級的網(wǎng)絡(luò)結(jié)構(gòu),然后在數(shù)據(jù)集上對該網(wǎng)絡(luò)進行訓(xùn)練,并在驗證集上進行驗證獲取準確率R,把這個準確率R進行反饋,RNN控制器得到反饋后對網(wǎng)絡(luò)繼續(xù)優(yōu)化得到新的網(wǎng)絡(luò)結(jié)構(gòu),反復(fù)進行優(yōu)化操作直到得到最優(yōu)的網(wǎng)絡(luò)結(jié)構(gòu)。基于強化學(xué)習(xí)的策略首次使用循環(huán)控制體進行網(wǎng)絡(luò)搜索的算法,為后續(xù)研究者提供了思路,但存在一定的不足,以高昂的算力為代價換取網(wǎng)絡(luò)結(jié)構(gòu),在Cifar-10數(shù)據(jù)集上需要使用800個圖形處理器(Graphics Processing Unit,GPU)同時訓(xùn)練,在PTB數(shù)據(jù)集上需要使用400個GPU訓(xùn)練。訓(xùn)練過程中使用分布式訓(xùn)練和異步參數(shù)更新加速控制器的學(xué)習(xí)效果,可以說強大的算力保障是基于強化學(xué)習(xí)神經(jīng)架構(gòu)搜索的基礎(chǔ)。基于強化學(xué)習(xí)NAS示意圖[13]如圖8所示。
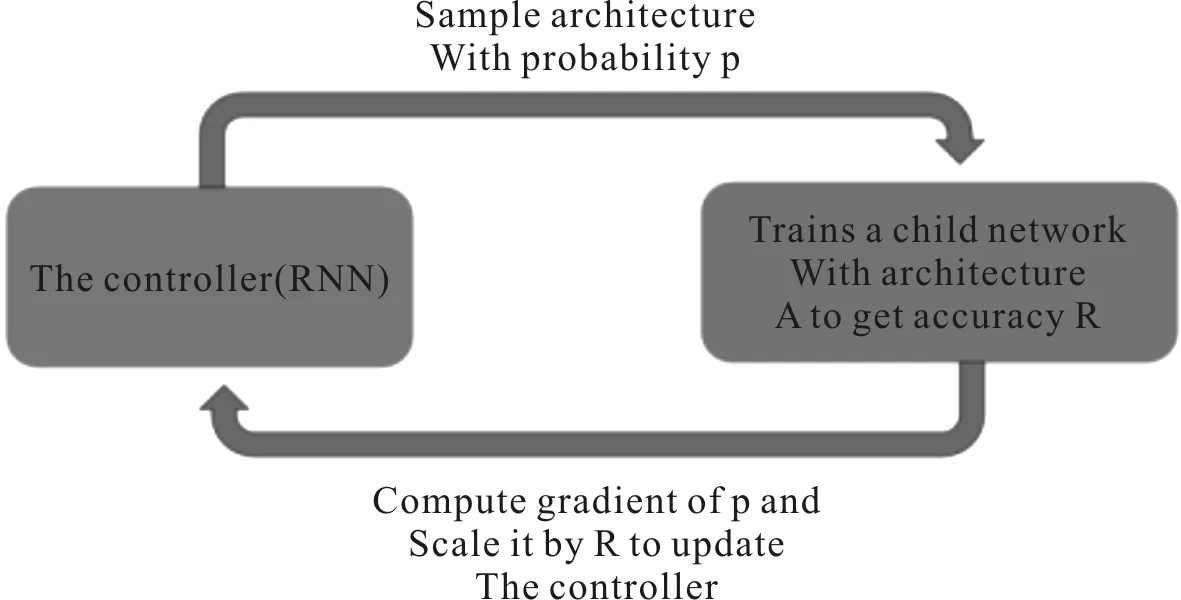
圖8 基于強化學(xué)習(xí)NAS示意圖
傳統(tǒng)的神經(jīng)網(wǎng)絡(luò)模型都是由許多的卷積單元按照一定順序堆疊在一起形成的,該鏈接方式限制了網(wǎng)絡(luò)的深度,隨后ResNet和Inception等帶有特殊鏈接的網(wǎng)絡(luò)模型被提出,其不僅可以構(gòu)造很深的網(wǎng)絡(luò),而且可以改善過擬合的問題。強化學(xué)習(xí)中存在過度探索可能會導(dǎo)致收斂變慢的問題,使得收斂到局部最優(yōu)而非全局最優(yōu),為此,Baker等[24]在2017年引入了MetaQNN網(wǎng)絡(luò)結(jié)構(gòu),該網(wǎng)絡(luò)結(jié)構(gòu)基于Q-Learning算法進行搜索。通過借鑒馬爾可夫決策過程,使用代理選擇可能的路徑構(gòu)造網(wǎng)絡(luò)。MetaQNN的設(shè)計靈感主要是通過減少卷積層的定義數(shù)量簡化參數(shù),定義代理能夠選擇的集合,使得結(jié)構(gòu)靈活,保持搜索空間和模型容量的大小關(guān)系,使用代理進行收斂,可降低模型參數(shù)數(shù)量。與NAS方法不同的是,MetaQNN將優(yōu)化范圍縮小到某一層上,搜索過程簡化很多,搜索時間降低,使用10個GPU訓(xùn)練時間為100 GPU days,加速240倍,相比RNN的強化學(xué)習(xí)實驗條件成本大幅降低。從結(jié)果可以看出搜索出來的網(wǎng)絡(luò)結(jié)構(gòu)較為簡單,人為約束條件較多,沒有殘差連接和并行層。在NASNet的搜索空間中,前兩個低網(wǎng)絡(luò)層中的兩個單元的輸出或輸入,作為下一層每個單元中兩個初始隱藏狀態(tài)hi和hi-1的輸入,在給定這兩個初始隱藏狀態(tài)的情況下,同時使用強化學(xué)習(xí)進行搜索,控制器RNN采用遞歸方式預(yù)測卷積單元的其余結(jié)構(gòu),其搜索過程示意圖如圖9所示。
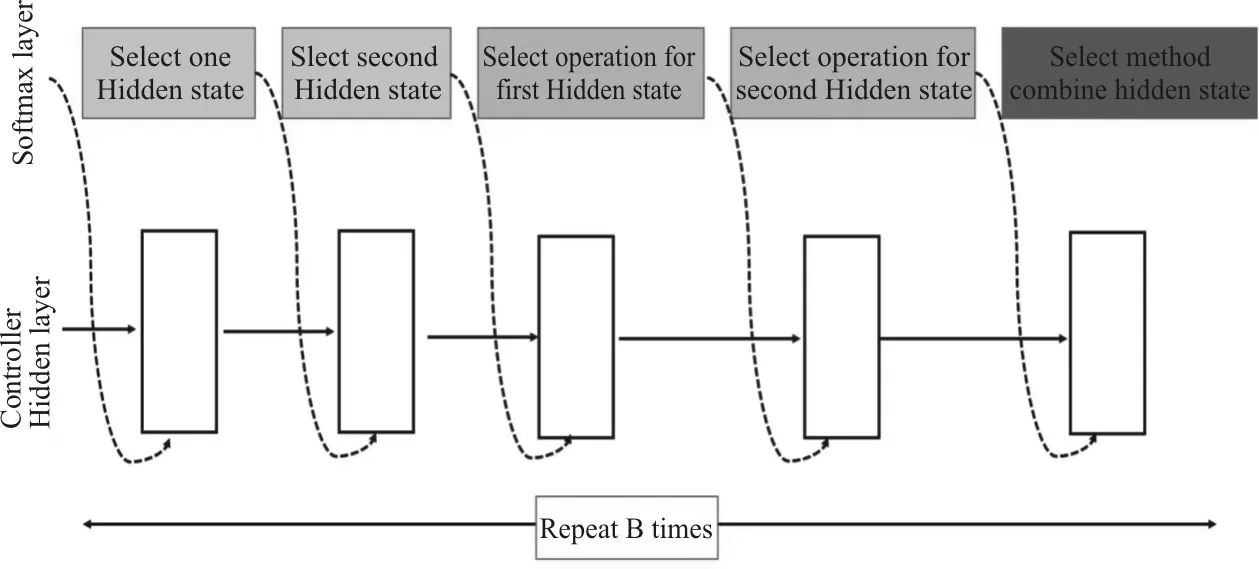
圖9 NASNet搜索過程示意圖
NASNet使用的搜索策略是近端策略優(yōu)化(Proximal Policy Optimization,PPO),在NASNet中使用DropPath避免過擬合,但是效果并不是很好。所需實驗條件為500個GPU,相比之前使用了更快的硬件設(shè)備,最終效率提高了7倍,可以看出實驗條件在NAS的研究中起到了十分關(guān)鍵的作用。
Zhong等[25]在2018年提出了基于強化學(xué)習(xí)的BlockQNN結(jié)構(gòu),該結(jié)構(gòu)把當(dāng)前神經(jīng)網(wǎng)絡(luò)層定義為強化學(xué)習(xí)中的現(xiàn)階段狀態(tài)(Current State),而下一層結(jié)構(gòu)的決策定義為強化學(xué)習(xí)中的動作(Action),強化學(xué)習(xí)算法通過優(yōu)化尋獲最優(yōu)的動作決策序列。BlockQNN網(wǎng)絡(luò)結(jié)構(gòu)采用基于Epsilon-greedy搜索策略的Q-Learning范式方法自動構(gòu)建高性能網(wǎng)絡(luò)。在構(gòu)建結(jié)構(gòu)過程中引用BlockQNN結(jié)構(gòu)設(shè)計,降低了構(gòu)建網(wǎng)絡(luò)的搜索空間大小,可快速構(gòu)建網(wǎng)絡(luò)結(jié)構(gòu)。考慮到Block結(jié)構(gòu)本身具備很強的泛化性,在不同的數(shù)據(jù)集上只需要疊加不同個數(shù)的Block結(jié)構(gòu)就可以生成相應(yīng)的網(wǎng)絡(luò)結(jié)構(gòu)。同時,BlockQNN結(jié)構(gòu)具有以下優(yōu)點:1)與傳統(tǒng)人工構(gòu)建的網(wǎng)絡(luò)相比,網(wǎng)絡(luò)性能更優(yōu);2)模型設(shè)計的搜索空間規(guī)模減少,訓(xùn)練時間大幅減少;3)可以遷移到更大的數(shù)據(jù)集,取得了良好的效果。BlockQNN將研究思路從整體網(wǎng)絡(luò)轉(zhuǎn)變?yōu)锽lock模塊,使用了分布式框架同時采用早停技術(shù),在32個GPU(TitanX)的計算資源下將搜索時間降低到3天,相比前面的大幅降低搜索時間。
Pham等[18]在2018年提出了高效的神經(jīng)架構(gòu)搜索(Efficient Neural Architecture Search,ENAS),其基于強化學(xué)習(xí)使用權(quán)重共享策略,避免沖突開始訓(xùn)練,節(jié)約了計算成本。ENAS實現(xiàn)了可以在單個GPU(1080 Ti)上進行架構(gòu)搜索,具有十分重大的意義,使低成本下的NAS研究成為了可能。ENAS的成功主要是采用權(quán)重共享策略,還有一個原因便是只采用了3×3和5×5的卷積進行搜索空間構(gòu)建,簡化了搜索空間,大幅降低搜索時間。Yang等[27]在2018年提出了一種稱為NetAdapt的算法,該算法在給定資源預(yù)算的情況下,可以自動地將預(yù)先訓(xùn)練好的深層神經(jīng)網(wǎng)絡(luò)架構(gòu)應(yīng)用于移動平臺,是一種自動約束網(wǎng)絡(luò)優(yōu)化算法,在滿足約束條件(資源預(yù)算)的條件下,生成一系列簡單網(wǎng)絡(luò),實現(xiàn)網(wǎng)絡(luò)的動態(tài)選擇和進一步優(yōu)化。但是,NetAdapt計算消耗大,產(chǎn)生的子結(jié)構(gòu)過多,導(dǎo)致裁剪所用時間過多,針對小規(guī)模的模型效果更好。NetAdapt在Samsung Galaxy S8進行實驗,開啟了NAS應(yīng)用在移動領(lǐng)域新紀元。2019年,Hu等[28]提出了Petridish算法,以迭代的方式將快捷連接添加到現(xiàn)有的網(wǎng)絡(luò)層,能夠在增強層上使梯度增強。為了減少可能的連接組合的試驗次數(shù),在每個生長階段聯(lián)合訓(xùn)練所有可能的連接,同時,利用特征選擇技術(shù)選擇其中的一個子集。實驗證明這個過程將是一種高效的前向架構(gòu)搜索算法,可以找到在可重復(fù)的搜索空間中占用GPU時間最少的競爭模型網(wǎng)絡(luò)模塊(單元搜索)和常規(guī)網(wǎng)絡(luò)空間(宏搜索)。在Cifar-10數(shù)據(jù)集上使用兩個3×3卷積操作,在實驗設(shè)備GTX 1080的條件下,Petridish算法可以達到2.87±0.13%的錯誤率,在錯誤率方面優(yōu)于DARTS算法,但是搜索時間較長并且參數(shù)量過大。Ying等[29]為了解決NAS消耗計算資源,難以復(fù)現(xiàn)的問題,通過引入NAS-Bench-101數(shù)據(jù)集改善了這些問題。在NAS-Bench-101數(shù)據(jù)集上構(gòu)建了結(jié)構(gòu)豐富的網(wǎng)絡(luò)空間架構(gòu),訓(xùn)練并評估了這些架構(gòu),同時在CIFAR-10數(shù)據(jù)集上多次訓(xùn)練并將結(jié)果編譯成一個超過500萬種訓(xùn)練有素的模型。該方法提高了模型精度,通過查詢預(yù)計運算數(shù)據(jù)集,用以評估各種模型的質(zhì)量。在谷歌張量處理單元(Tensor Processing Unit,TPU) v2上進行訓(xùn)練實驗,其成本較高。同年,Tan等[30]提出MnasNet方法,目的是搜索出一個在精度和延遲之間達到平衡狀態(tài)并且擁有表現(xiàn)良好的模型,進一步達到靈活性和搜索空間大小之間更加平衡的狀態(tài)。MnasNet系統(tǒng)地研究了平衡網(wǎng)絡(luò)的深度、寬度和分辨率之間的關(guān)系,通過改變?nèi)咧g關(guān)系可以提高性能。實驗在64個TPUv2上進行,花費了4.5天,實驗條件相比較NASNet和MobileNetV2性能要求更高。
隨著網(wǎng)絡(luò)結(jié)構(gòu)的研究,移動設(shè)備設(shè)計CNN仍然是一個挑戰(zhàn),因為移動模型需要小而快,對準確度有較高要求。Tan等[26]通過系統(tǒng)地研究模型縮放方法,發(fā)現(xiàn)網(wǎng)絡(luò)的深度、寬度和分辨率三者達到平衡狀態(tài)可以提高網(wǎng)絡(luò)性能,在此基礎(chǔ)上提出了新的標(biāo)度用以統(tǒng)一縮放所有大小的方法,構(gòu)成簡單有效的復(fù)合系數(shù)。使用設(shè)計新的基準構(gòu)建網(wǎng)絡(luò)結(jié)構(gòu),并且擴大規(guī)模形成EfficientNets。該實驗在Intel Xeon CPU E5-2690上進行,網(wǎng)絡(luò)運行速度比ResNet-152快5.7倍,比GPipe快6.1倍。
神經(jīng)網(wǎng)絡(luò)架構(gòu)自動搜索到的網(wǎng)絡(luò)與傳統(tǒng)的卷積網(wǎng)絡(luò)相比,網(wǎng)絡(luò)性能和準確度更高。2020年,Real等[31]設(shè)計了一個新的框架,將基本的數(shù)學(xué)運算作為構(gòu)建塊的機器學(xué)習(xí)算法,使其可以自動搜索并發(fā)現(xiàn)完整神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)。該框架設(shè)計的搜索空間減少了偏見,針對搜索空間過大的問題,使用進化算法搜索發(fā)現(xiàn)新網(wǎng)絡(luò),并通過反向傳播訓(xùn)練的兩層神經(jīng)網(wǎng)絡(luò),最終構(gòu)建針對特定任務(wù)的網(wǎng)絡(luò)結(jié)構(gòu)。Luo等[32]為了解決對控制器進行培訓(xùn)既需要大量高質(zhì)量的架構(gòu),也需要保證其準確性,而評估架構(gòu)并獲得其準確性則需要付出高昂的代價等問題,提出了SemiNAS,一種半監(jiān)督的NAS方法。SemiNAS具有兩個優(yōu)點:1)在相同的精度保證下降低了計算成本;2)在相同的計算成本下達到更高的精度。SemiNAS在4個P40顯卡、NASBench-101基準數(shù)據(jù)集上進行實驗,其在評估了大約300種架構(gòu)后發(fā)現(xiàn)了0.01%的頂級架構(gòu),而與正則化的進化和基于梯度的方法相比,計算成本僅為1/7。在ImageNet上可以實現(xiàn)最先進的Top-1錯誤率(在移動設(shè)置下)為23.5%,訓(xùn)練時間降低為4天。Guo等[33]在對抗攻擊的最新進展中揭示了現(xiàn)代深度神經(jīng)網(wǎng)絡(luò)的內(nèi)在脆弱性,通過專門的學(xué)習(xí)算法和損失函數(shù)增強深度網(wǎng)絡(luò)的魯棒性研究,提出的RobNet網(wǎng)絡(luò)從架構(gòu)的角度研究了可抵抗對抗攻擊的網(wǎng)絡(luò)架構(gòu)模式,只保留3個操作算子構(gòu)建搜索空間,同時采用“免費”對抗訓(xùn)練方案加快訓(xùn)練速度。Lin[34]等研究了在基于微控制器單元(Microcontroller Unit,MCU)的微型物聯(lián)網(wǎng)(Internet of Things,IoT)設(shè)備上的機器學(xué)習(xí),提出了MCUNet結(jié)構(gòu),該結(jié)構(gòu)可以共同設(shè)計高效的神經(jīng)體系結(jié)構(gòu)(TinyNAS)和輕量級推理引擎(TinyEngine),從而在微控制器上實現(xiàn)ImageNet數(shù)據(jù)集的推理。TinyNAS采用了兩個階段對神經(jīng)體系結(jié)構(gòu)進行搜索,第一階段是優(yōu)化搜索空間以適應(yīng)資源限制,第二階段在優(yōu)化的搜索空間中專門研究網(wǎng)絡(luò)體系結(jié)構(gòu)。TinyNAS具有在搜索成本比較低的條件下可以自動處理設(shè)備、延遲、能源和內(nèi)存等各種約束條件的優(yōu)點。
強化學(xué)習(xí)在神經(jīng)結(jié)構(gòu)搜索中相比于人工設(shè)計的網(wǎng)絡(luò)極具優(yōu)勢,但是基于強化學(xué)習(xí)的NAS大部分情況下都需要強大的計算資源支持。隨著計算能力的提升,基于強化學(xué)習(xí)的NAS訓(xùn)練時間已經(jīng)從二十多天減少為幾天,時間效率有所提高,未來將在圖形分割、圖像識別以及自然語言處理等方面發(fā)揮優(yōu)勢。
3.2 基于進化算法的NAS搜索策略
進化算法(Evolutionary Algorithm) 實現(xiàn)結(jié)構(gòu)搜索原理是通過對生物界的種種生物現(xiàn)象進行借鑒和模擬完成,其操作過程主要包括對基因編碼、種群初始化、交叉變異算子和保留機制等操作[35]。在初期隨機初始化一個種群,然后按一定順序執(zhí)行選擇算子、交叉算子以及變異算子,根據(jù)當(dāng)前適應(yīng)度的評價結(jié)果,再次選擇“初代種群”,進行迭代進化,直到適應(yīng)度滿足條件,循環(huán)過程示意圖如圖10所示。
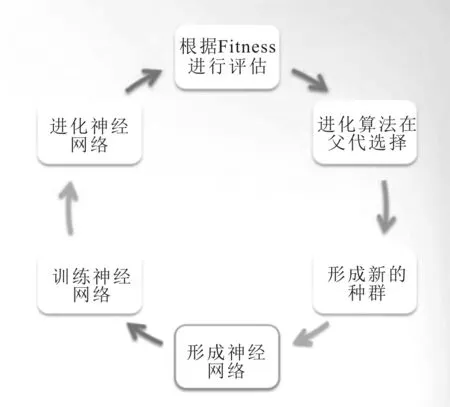
圖10 神經(jīng)網(wǎng)絡(luò)的基本循環(huán)過程示意圖
遺傳算法作為進化算法的分支則是以自然界中生物的進化規(guī)律為基本準則,以種群中的所有個體為對象,利用模擬自然進化技術(shù)指導(dǎo)對被編碼的空間進行高效搜索,選擇最優(yōu)化的解。采用遺傳算法的神經(jīng)架構(gòu)搜索主要是通過對產(chǎn)生的子網(wǎng)絡(luò)結(jié)構(gòu)采用二進制編碼方式,運行算法得到神經(jīng)網(wǎng)絡(luò)在驗證集上精度(適應(yīng)度)最大的值,該值對應(yīng)的該網(wǎng)絡(luò)結(jié)構(gòu)便是最佳結(jié)構(gòu)。
Real等[16]在2017年引用進化算法用來解決NAS相關(guān)問題,設(shè)計的進化算法是從沒有進行過任何卷積操作的最簡單的模型開始進化,初期的神經(jīng)網(wǎng)絡(luò)架構(gòu)的深度并不固定,隨著搜索空間的不斷擴大,運行算法的時間變得越來越長,網(wǎng)絡(luò)結(jié)構(gòu)深度越深。實驗訓(xùn)練和驗證都在TensorFlow框架上進行,為了完成實驗自行開發(fā)了一個大規(guī)模并行同時無鎖的設(shè)備,每個實驗都分布在250個并行的設(shè)備上,實驗成本較高。2017年,Poulsen等[36]提出了將神經(jīng)進化與CNN的圖像特征識別融合的方法,利用CNN網(wǎng)絡(luò)進行圖像識別操作,對識別后的圖像采用特征表示的方式進行轉(zhuǎn)換,最后將經(jīng)過算法處理的圖像傳遞給優(yōu)化過的神經(jīng)網(wǎng)絡(luò)。該方法雖然能夠有效地提取圖像特征,但是結(jié)果是否有效在很大程度上依賴于特征表示的質(zhì)量。隨后,Real等[37]在2018年提出了錦標(biāo)賽選擇的變體aging evolution,依據(jù)進化得到代數(shù)和進化所用時間去選擇比較年輕的模型,經(jīng)過搜索得出的最優(yōu)網(wǎng)絡(luò)結(jié)構(gòu)被稱為AmoebaNet。實驗候選操作有9個操作,在450個K40 GPU上運行,搜索時間和搜索成本比較高。2019年,Real等[37]對進化算法進行改進,采用一種正則化形式,根據(jù)訓(xùn)練時間早晚,選擇移除了訓(xùn)練時間最早的神經(jīng)網(wǎng)絡(luò)(無論性能有多好),而不是移除訓(xùn)練中結(jié)構(gòu)最差的神經(jīng)網(wǎng)絡(luò)。通過改進,在面對任務(wù)優(yōu)化發(fā)生變化的時候能夠提高穩(wěn)健性,最終得到了準確度高且損失最低的網(wǎng)絡(luò)。考慮到使用該方法結(jié)構(gòu)權(quán)重不能夠繼承,因此所有的網(wǎng)絡(luò)必須從開始進行重新訓(xùn)練。雖然該方法有一定的進步,但是在訓(xùn)練過程中存在的噪聲會使得同樣架構(gòu)準確率的情況下產(chǎn)生不同的結(jié)構(gòu),得到準確度更高的模型概率降低。
Saravanan等[38]提出了細粒度的神經(jīng)進化(Evolving Neural Networks through Augmenting Topologies,NEAT)算法,該算法通過網(wǎng)絡(luò)結(jié)構(gòu)自己搜索需要使用多少連接,以這種方式忽略那些不重要的連接,生成的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)較小,運行速度加快。NEAT通過突變和無損重組直接編碼的兩種方式生成網(wǎng)絡(luò)結(jié)構(gòu),使其具有結(jié)構(gòu)簡單和同步能力強的特點。2002年,Stanley等[39]在NEAT基礎(chǔ)上提出了一種新型的神經(jīng)網(wǎng)絡(luò)進化方法,稱為“神經(jīng)進化的增強拓撲”,旨在利用網(wǎng)絡(luò)結(jié)構(gòu)作為最小化搜索空間維度的方法。盡管神經(jīng)網(wǎng)絡(luò)隨著發(fā)展越來越完善,但和自然大腦還有不小的差距。為了縮小神經(jīng)網(wǎng)絡(luò)與自然大腦之間的差距,Stanley等[40]又于2009年提出HyperNEAT算法,HyperNEAT是NEAT的變體,采用了一種連接合成模式構(gòu)建網(wǎng)絡(luò)(Connective compositional Pattern-Producing Networks,CPPNs)的間接編碼,產(chǎn)生具有對稱性和重復(fù)基序的連接模式。該算法將任務(wù)的規(guī)則映射到網(wǎng)絡(luò)的拓撲結(jié)構(gòu),利用任務(wù)的幾何結(jié)構(gòu),從而將問題的難度從高維遷移到低維的問題結(jié)構(gòu)上,開辟了將神經(jīng)進化應(yīng)用到處理復(fù)雜高維任務(wù)的研究領(lǐng)域。2010年,Risi等[41]在HyperNEAT的基礎(chǔ)上提出ES-HyperNEAT,通過改進使得在信息質(zhì)量比較高的區(qū)域采用更密集基底的網(wǎng)絡(luò)(Compositional Pattern Producing Networks,CPPN)。為了確定隱藏節(jié)點的密度和位置,ES-HyperNEAT通過使用四叉樹狀結(jié)構(gòu)的方法實現(xiàn)。實驗對比得出,ES-HyperNEAT在相關(guān)測試中的表現(xiàn)比傳統(tǒng)的HyperNEAT表現(xiàn)更強。2014年,Hausknecht等[42]引入神經(jīng)進化的方法學(xué)習(xí)Atari游戲,將CNE、CMA-ES、NEAT和HyperNEAT等4種算法在61種Atari游戲中進行評估對比。測試結(jié)果證明了神經(jīng)進化在通用視頻游戲的實驗中極具潛力,同時也顯示在空間有限的情況下直接編碼表現(xiàn)效果最好,在更高維的維度中可以用間接編碼對結(jié)構(gòu)進行表示。
DeepNEAT算法作為NEAT算法的延伸,也取得十足的發(fā)展。兩個算法的主要有兩個區(qū)別,第一個區(qū)別是運行的單元不一致,NEAT算法的運行單元是由神經(jīng)元(Neuron)構(gòu)成,而DeepNEAT 算法中的操作節(jié)點則是一個深度神經(jīng)網(wǎng)絡(luò)(Deep Neural Networks,DNN)的層(Layer),其中每一個節(jié)點包含實數(shù)編碼和二進制編碼兩種編碼方式。第二個區(qū)別是鏈接(Link)的代表意義不一致,在NEAT算法中連接代表的是權(quán)重值(Weight),而在DeepNEAT算法中則代表鏈接關(guān)系與鏈接方向。
Miikkulainen等[43]在2017年提出Coevolution DeepNEAT(CoDeepNEAT) 新算法,該算法在增加網(wǎng)絡(luò)結(jié)構(gòu)復(fù)用性的同時可以簡化網(wǎng)絡(luò)結(jié)構(gòu)。CoDeepNEAT算法主要涉及模塊和藍圖兩個新的概念。模塊表示的是一個小的DNN網(wǎng)絡(luò)結(jié)構(gòu),藍圖表示的是一個圖,即其中每個節(jié)點包含指向特定模塊的值。CoDeepNEAT算法采用共同進化方法對兩組藍圖和模塊進行同時進化,通過采用以相應(yīng)的模塊代替藍圖節(jié)點的方法,將模塊和藍圖組進行組合形成一個大型的網(wǎng)絡(luò)結(jié)構(gòu),稱為集合網(wǎng)絡(luò)(Assembled Networks)。2019年,Liang等[44]在CoDeepNEAT進化算法的基礎(chǔ)上,提出了功能強大的自動機器學(xué)習(xí)框架Leaf,即Algorithm Layer、System Layer和Problem-domain Layer。在該框架中不僅可以實現(xiàn)訓(xùn)練和修改網(wǎng)絡(luò)結(jié)構(gòu)的權(quán)值功能,并在此基礎(chǔ)上可以修改網(wǎng)絡(luò)的拓撲結(jié)構(gòu),通過新增節(jié)點和刪除節(jié)點等操作進行修改,經(jīng)過實驗對比,該框架顯示了強大的優(yōu)越性。
進化算法作為神經(jīng)架構(gòu)搜索中最重要的研究內(nèi)容之一,取得了十分顯著的研究成果。2019年,Stanley等[45]對現(xiàn)代神經(jīng)進化發(fā)展的進行總結(jié)和回顧,簡述了神經(jīng)進化在大規(guī)模計算、結(jié)構(gòu)新穎性和多樣性的好處、間接編碼的優(yōu)勢等方面以及該領(lǐng)域?qū)Y(jié)構(gòu)搜索的重大貢獻,并指出未來神經(jīng)進化將成為追求人工智能的關(guān)鍵工具。使用進化算法的優(yōu)勢就是只要進化代數(shù)足夠多,就可以得到全局最優(yōu)解,但是這也是非常消耗算力的一個過程。基于進化算法的NAS研究,不僅依靠算法設(shè)計層面,也對實驗條件有了更高的要求,空間操作數(shù)量越多,迭代次數(shù)越多,需要的實驗條件就越苛刻。總體來看,目前采用分布式計算提高進化效率是有效的解決辦法之一。
3.3 貝葉斯優(yōu)化
基于貝葉斯優(yōu)化[46]的搜索策略(Bayesian Optimization,BO)是目前用于進行超參數(shù)優(yōu)化的主要的方法之一,其內(nèi)容采用基于高斯過程(Gaussian Processes)和基于核方法(Kernel Trick)對于高維優(yōu)化問題進行優(yōu)化,優(yōu)化過程中采用樹模型或者隨機森林。對于低維空間的問題優(yōu)化,貝葉斯優(yōu)化具有良好的效果。考慮到神經(jīng)網(wǎng)絡(luò)存在很多的超參數(shù),為了找到最優(yōu)的參數(shù)組合,需要對參數(shù)組合進行搜索比對。傳統(tǒng)的網(wǎng)格搜索耗時長、速度慢,貝葉斯優(yōu)化可以用來指導(dǎo)參數(shù)優(yōu)化,Domhan等[47]提出了將貝葉斯優(yōu)化應(yīng)用于神經(jīng)架構(gòu)搜索。2012年,Hutter等[48]提出基于序列模型的優(yōu)化(Sequential Model-Based Optimization,SMBO)方法,序列的含義是指一個接一個地進行試驗,每次都應(yīng)用貝葉斯進行模型推理,同時更新概率模型嘗試找到更好的超參數(shù)。在SMBO的基礎(chǔ)上基于序列模型的算法(Sequential Model-based Algorithm Configuration,SMAC)方法被提出,其是基于模型選擇而不是隨機選擇。2013年,Bergstra等[49]提出了一個元建模方法支持自動超參數(shù)優(yōu)化,目的是提供實用的工具,用一個可重復(fù)和無偏的優(yōu)化過程代替手動調(diào)整。Swersky等[50]在2014年為條件參數(shù)空間定義了一個新內(nèi)核,該內(nèi)核明確包含給定結(jié)構(gòu)中的參數(shù)相關(guān)的信息,通過共享信息提高深度神經(jīng)網(wǎng)絡(luò)的性能。2017年,Liu等[20]在SMBO的基礎(chǔ)上學(xué)習(xí)構(gòu)建CNN的結(jié)構(gòu),引入漸進式思想設(shè)計出漸進式神經(jīng)網(wǎng)絡(luò)架構(gòu)搜索算法,逐漸增減空間復(fù)雜度。實驗的候選操作為8個,針對大型數(shù)據(jù)集需要100個P100型號GPU。2018年,Jin等[51]提出一種全新架構(gòu),使用貝葉斯優(yōu)化引導(dǎo)網(wǎng)絡(luò)變形,同時使用一個神經(jīng)網(wǎng)絡(luò)核(Neural Network Kernel)以及一個生成樹結(jié)構(gòu)的優(yōu)化算法高效探索搜索空間,以提升神經(jīng)架構(gòu)搜索效率。同年,Kandasamy等[52]提出了神經(jīng)結(jié)構(gòu)搜索框架NASBOT(BO Algorithm For Neural Architecture Search),該框架基于高斯過程,同時結(jié)合基于GP的BO方法,為架構(gòu)搜索空間推導(dǎo)了核函數(shù),并給出了一種優(yōu)化神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)獲取函數(shù)的方法,采用進化算法對獲取函數(shù)進行優(yōu)化。2019年,Perez-Rua等[53]以多模態(tài)分類為基礎(chǔ),提出了一個新的搜索空間,利用SMBO進行多模態(tài)融合,尋找最優(yōu)的多模態(tài)融合架構(gòu)。
3.4 基于梯度下降的搜索策略
基于梯度(Gradient-based)的方法是機器學(xué)習(xí)領(lǐng)域最經(jīng)典的方法。基于強化學(xué)習(xí)和進化算法的方法在搜索空間的問題上,本質(zhì)上都屬于在離散的空間中進行搜索,為黑箱優(yōu)化。相比于黑箱優(yōu)化方法,梯度法的搜索速度更快,能夠節(jié)約訓(xùn)練時間。在搜索空間連續(xù)且目標(biāo)函數(shù)可微的情況下,基于梯度的方法效率更高。2019年,Liu等[21]提出的DARTS方法將搜索空間弱化為一個連續(xù)的空間結(jié)構(gòu),以此可以使用梯度下降進行性能優(yōu)化。DARTS能夠在豐富的搜索空間中搜索到一種具有復(fù)雜圖形拓撲結(jié)構(gòu)的高性能框架。同年,Luo等[54]提出一種新方法,即先在一個連續(xù)的空間中將網(wǎng)絡(luò)結(jié)構(gòu)進行嵌入(Embedding)操作,該連續(xù)空間中的每一個點相對應(yīng)一個網(wǎng)絡(luò)結(jié)構(gòu),在此空間中定義準確率的預(yù)測函數(shù)。對照目標(biāo)函數(shù)進行梯度優(yōu)化,找到最佳網(wǎng)絡(luò)結(jié)構(gòu)的嵌入表征,優(yōu)化完成后,再將這個嵌入表征映射回網(wǎng)絡(luò)結(jié)構(gòu),找到最優(yōu)的網(wǎng)絡(luò)結(jié)構(gòu)。該類方法的優(yōu)點之一就是搜索效率高,同時采用權(quán)重共享等加速手段,快速減少了訓(xùn)練所需時間。Cai等[55]提出了一種不使用代理任務(wù)的方法ProxylessNAS,能夠直接在大規(guī)模的目標(biāo)任務(wù)上搜索結(jié)構(gòu),解決NAS方法GPU高內(nèi)存占用和計算耗時過長的問題。通過二值化的手段將內(nèi)存消耗降低了一個量級,給出了一個基于梯度的方法(延遲正則化損失)約束硬件指標(biāo)。基于ProxyTasks的NAS方法并沒有考慮Latency性能的影響,現(xiàn)有的NAS方法采用的是使用堆疊Block構(gòu)成最終的網(wǎng)絡(luò),但實際的網(wǎng)絡(luò)中是可以存在不同種類的Block。DARTS巧妙地將搜索空間轉(zhuǎn)化為可微的形式,把結(jié)構(gòu)和權(quán)重聯(lián)聯(lián)合優(yōu)化,但DARTS基于ProxyTasks,在計算堆疊Block的過程中仍然占用大量的GPU資源。Hundt[56]等對DARTS進行了改進,提出了sharpDARTS,利用余弦功率退火學(xué)習(xí)率進行優(yōu)化。Chen等[57]提出P-DARTS,用漸進地增加搜索網(wǎng)絡(luò)的深度解決深度差異的問題。采用漸進增加搜索網(wǎng)絡(luò)深度的策略是因為可以用這種方式逐漸地縮小搜索空間,也就是候選操作的種類,從而保持顯存消耗在一個合理的水平。同時,在搜索空間近似的前提下,可以根據(jù)每個階段學(xué)習(xí)到的網(wǎng)絡(luò)結(jié)構(gòu)參數(shù)漸進地減少候選操作的種類,從而降低顯存和時間消耗。Xu等[58]提出PC-DARTS采用通道采樣(Channel Sampling)的技術(shù),降低搜索時間開銷和內(nèi)存開銷,同時提出了邊標(biāo)準化方法(Edge Normalization)。邊界標(biāo)準化用于確定指向一個結(jié)點的兩條邊,通過給每條邊再增加一個系數(shù),在確定邊時對系數(shù)取值,用這種方法可以改善搜索的穩(wěn)定性。Zheng等[59]提出了一種基于多項式分布估計快速NAS算法(MdeNAS),其將搜索空間視為一個多項式分布,可以通過采樣-分布估計優(yōu)化該分布,從而將NAS的訓(xùn)練轉(zhuǎn)換為分布估計/學(xué)習(xí)(Multinomial Distribution Learning,DL)。除此之外,還提出并證明了一種保序精度排序假設(shè),進一步加速學(xué)習(xí)過程。在CIFAR-10上,使用該方法搜索的結(jié)構(gòu)實現(xiàn)了2.55%的測試誤差,在實驗設(shè)備單個GTX1080Ti上僅需4個GPU小時。在ImageNet上,實現(xiàn)了75.2%的Top1準確度。2020年,Guo等[33]在提出的RobNet網(wǎng)絡(luò)中,使用投影梯度下降生成對抗性示例并在訓(xùn)練期間增加數(shù)據(jù),使得網(wǎng)絡(luò)魯棒性得到了顯著提高。
從傳統(tǒng)的隨機策略到最初的強化學(xué)習(xí),再到引入進化算法、使用梯度下降和貝葉斯優(yōu)化等方法,搜索策略的發(fā)展從最初的隨機選擇,到指導(dǎo)性的學(xué)習(xí)優(yōu)化,以及現(xiàn)在更加智能化的優(yōu)化,策略的選擇范圍更加廣泛,搜索效果也更加優(yōu)秀,策略的選擇越來越自動化、智能化。
4 性能評估
神經(jīng)架構(gòu)搜索的效果在很大程度上依賴于訓(xùn)練數(shù)據(jù)的規(guī)模,規(guī)模越大學(xué)習(xí)的效果越好,但是大規(guī)模數(shù)據(jù)上訓(xùn)練模型的時間非常久,對訓(xùn)練結(jié)果的評估將會非常耗時,所以為了盡快找到最優(yōu)網(wǎng)絡(luò)會使用一些方法去近似的評估架構(gòu)性能和策略效率,進一步降低訓(xùn)練成本。為了減少這樣的計算量,基于各種模型的搜索方案被提出,通過搜索加速提升網(wǎng)絡(luò)模型性能。下面將對常見的評估策略以及加速方案進行總結(jié)。
4.1 低保真度
低保真度方法指的是使用減少訓(xùn)練的時間,減少訓(xùn)練子集的數(shù)量、減少網(wǎng)絡(luò)層數(shù),以及使用較低分辨率的圖像等方法提升訓(xùn)練效果,近似預(yù)估網(wǎng)絡(luò)性能。雖然低保真度在一定程度上降低了計算成本,但也有一定的缺點。由于性能通常會被低估,驗證的過程中會引入偏差,導(dǎo)致評估的網(wǎng)絡(luò)并不是最優(yōu)。在通常情況下只要不同結(jié)構(gòu)相對排名較為穩(wěn)定時,性能低估不會影響結(jié)構(gòu)變化。但是,最近的一些研究結(jié)果表明當(dāng)采用低保真度方法后與完全評估的結(jié)果之間的差異太大時,這種相對排名就會發(fā)生顯著變化。為了加速超參數(shù)優(yōu)化,Klein等[60]于2016年提出了一個驗證誤差隨訓(xùn)練集大小變化的生成模型。該模型在優(yōu)化過程中學(xué)習(xí),通過外推到完整數(shù)據(jù)集,可以探索小子集上的初始配置,并構(gòu)造了一個貝葉斯優(yōu)化過程將其命名為Fabolas。該過程將損失和訓(xùn)練時間作為數(shù)據(jù)集大小的函數(shù)進行建模,并自動權(quán)衡全局最優(yōu)解的高信息增益和計算開銷。2019年,Hu等[61]提出了一種無導(dǎo)數(shù)優(yōu)化框架,使用多逼真度評估的自動機器學(xué)習(xí)。對小型數(shù)據(jù)子集使用許多低保真度評估,而對整個數(shù)據(jù)集使用很少的高保真度評估。對于低保真度評估可能會產(chǎn)生嚴重偏差的問題,使用非常低的成本即進行校正予以解決。
4.2 早停及學(xué)習(xí)曲線方法
2016年,Domhan等[62]提出觀察學(xué)習(xí)曲線(Learning Curve,LC) 的方法,通過學(xué)習(xí)曲線概率模型進行推斷,對預(yù)測性能表現(xiàn)不好的網(wǎng)絡(luò)架構(gòu)停止搜索。另外,一些研究者則通過預(yù)測哪些部分學(xué)習(xí)曲線最有希望進行參數(shù)優(yōu)化。Klein等[63]利用學(xué)習(xí)曲線概率模型用來優(yōu)化超參數(shù),提出在貝葉斯神經(jīng)網(wǎng)絡(luò)中通過專門的學(xué)習(xí)曲線層提高網(wǎng)絡(luò)的性能。早停是在網(wǎng)絡(luò)完全收斂的時候就停止訓(xùn)練,防止在通過基于梯度的優(yōu)化訓(xùn)練過程中模型的泛化性能過差。早停法主要是訓(xùn)練時間和泛化錯誤之間達到一種平衡狀態(tài)。2017年,Mahsereci等[64]提出了提前停止準則,基于快速計算局部數(shù)據(jù)的方法計算梯度的梯度,并完全地消除了對臨時驗證集的需求。
4.3 搜索加速方案
考慮到搜索過程耗費時間和計算資源,為了進一步加快搜索過程,需要在相對較小搜索空間進行評估,并在較大的搜索空間中進行良好的預(yù)測,由此各種加速方案被提出,用來提高搜索效率。
4.3.1 權(quán)值共享法
權(quán)值共享法是減少參數(shù)個數(shù)的方法。2018年,HieuPham等[65]提出的ENAS是用于自動化網(wǎng)絡(luò)模型設(shè)計的方法,該方法快速有效且資源耗費低。ENAS是對NAS的改進,各個子網(wǎng)模型采用共享權(quán)重方法提升計算效率,從而避免低效率的從頭訓(xùn)練。ENAS的控制器通過在大型數(shù)據(jù)集內(nèi)搜索最優(yōu)的子圖表示神經(jīng)網(wǎng)絡(luò)架構(gòu),根據(jù)梯度對網(wǎng)絡(luò)進行訓(xùn)練,以選擇一個子網(wǎng)絡(luò),以使驗證集上的準確度最大化。子網(wǎng)絡(luò)之間共享參數(shù)能夠讓ENAS提供強大的性能,共享權(quán)值的方法使得模型同時訓(xùn)練占用GPU的時間與當(dāng)時其他的自動模型訓(xùn)練時間少得多,并且與標(biāo)準的神經(jīng)架構(gòu)搜索相比,計算成本顯著降低。2019年,Liam等[66]提出了NAS主要是以超參數(shù)優(yōu)化問題為主和隨機搜索是超參數(shù)優(yōu)化的競爭標(biāo)準兩個新的NAS標(biāo)準。以這兩個標(biāo)準為基礎(chǔ),在PTB和CIFAR-10數(shù)據(jù)集上評估了具有早停功能的隨機搜索和具有權(quán)重共享算法的新型隨機搜索。實驗結(jié)果表明,采用權(quán)重共享的隨機搜索結(jié)果比具有早期停止功能的隨機搜索的結(jié)果更好,在PTB和CIFAR-10上同時獲得了最優(yōu)的結(jié)果。同年,Zhang等[67]提出了直接稀疏優(yōu)化NAS(Direct Sparse Optimization NAS,DSO-NAS)方法。在DSO-NAS中,建立了一種新的模型修剪NAS問題的視圖。從完全連接塊入手,引入縮放因子縮放之間的信息流操作,使用稀疏正則化以修剪無用的連接在建筑中。該方法同時具有可區(qū)分性和效率,因此可以直接應(yīng)用于ImageNet這類的大型數(shù)據(jù)集。
4.3.2 超網(wǎng)的應(yīng)用
神經(jīng)架構(gòu)搜索可以看作一個內(nèi)外循環(huán)優(yōu)化的問題,內(nèi)循環(huán)用于查找給定架訓(xùn)練損失的最優(yōu)參數(shù),外循環(huán)用于查找驗證損失的最優(yōu)架構(gòu)。針對神經(jīng)架構(gòu)搜索計算成本過高的問題,提出一種圖超網(wǎng)絡(luò)分攤搜索成本。由圖神經(jīng)網(wǎng)絡(luò)和超網(wǎng)絡(luò)(HyperNetwork)組成的網(wǎng)絡(luò)接收計算機圖作為輸入,并在圖中生成所有節(jié)點的結(jié)構(gòu)參數(shù),用于評估隨機采樣架構(gòu)的適用性,然后根據(jù)驗證集的準確率選擇性能最優(yōu)的架構(gòu)。Brock等[1]在2017年提出一種將網(wǎng)絡(luò)結(jié)構(gòu)配置與其在驗證集上的表現(xiàn)一起排名的搜索方法,網(wǎng)絡(luò)的參數(shù)是通過一個輔助網(wǎng)絡(luò)生成。在每一次訓(xùn)練開始時,隨機取樣一個網(wǎng)絡(luò)結(jié)構(gòu)并使用超網(wǎng)絡(luò)生成網(wǎng)絡(luò)的權(quán)重值,之后訓(xùn)練整個網(wǎng)絡(luò),訓(xùn)練結(jié)束后隨機取樣一定數(shù)量的網(wǎng)絡(luò)機構(gòu)并評估其在驗證集上的表現(xiàn),權(quán)重仍然使用超網(wǎng)絡(luò)生成的權(quán)重值,最后選擇在驗證集上表現(xiàn)最好的網(wǎng)絡(luò),正常訓(xùn)練得到網(wǎng)絡(luò)權(quán)重值。
4.3.3 基于One-Shot模型的加速方案
One-Shot模型主要研究的是單樣本的學(xué)習(xí)能力,當(dāng)類別訓(xùn)練樣本只有一個或者很少時,依然可以分類。基于One-Shot模型的神經(jīng)網(wǎng)絡(luò)架構(gòu)搜索受到了NAS和SMASH的啟發(fā),NAS主要依靠一個NAS控制器隨著時間反復(fù)迭代更新網(wǎng)絡(luò)的結(jié)構(gòu),而SMASH在使用控制器迭代網(wǎng)絡(luò)結(jié)構(gòu)的基礎(chǔ)上試圖減小網(wǎng)絡(luò)的計算量,引入超網(wǎng)生成主網(wǎng)絡(luò)所需的權(quán)重值W。NAS和SMASH搜索視為一個黑盒優(yōu)化問題,One-Shot架構(gòu)搜索過程視為從一個十分復(fù)雜的網(wǎng)絡(luò)結(jié)構(gòu)開始,逐步對網(wǎng)絡(luò)進行修剪,修剪到作業(yè)較小的部分。將One-Shot模型搜索到的網(wǎng)絡(luò)訓(xùn)練完成后,使用這個模型對候選結(jié)構(gòu)在驗證集上的表現(xiàn)進行評估,選擇方法可以是進化算法或強化學(xué)習(xí)算法,One-Shot架構(gòu)搜索的輸出結(jié)果是一系列根據(jù)One-Shot正確率排列的網(wǎng)絡(luò)結(jié)構(gòu),訓(xùn)練完成后,可以重新訓(xùn)練最佳的結(jié)構(gòu)。2018年,Bender等[19]對One-Shot模型原理進行詳細的介紹,從搜索空間、操作的選擇、網(wǎng)絡(luò)架構(gòu)的構(gòu)建以及搜索流程進行了詳細講解,同時對One-Shot模型中的權(quán)重共享機制進行了詳細說明。
基于One-Shot架構(gòu)搜索方法解決了計算量的問題,但仍帶來一些問題。使用超網(wǎng)生成的權(quán)重W在優(yōu)化過程中會變得深度耦合,在對網(wǎng)絡(luò)的結(jié)構(gòu)a和權(quán)重W的優(yōu)化過程中,由于部分缺乏訓(xùn)練,使不同結(jié)構(gòu)不具有可比性,誤導(dǎo)了搜索結(jié)構(gòu)。為了解決這種問題,單路徑網(wǎng)絡(luò)被提出。單路徑首先改變的是權(quán)重W的優(yōu)化策略,超網(wǎng)絡(luò)的權(quán)重對于搜索空間中的所有架構(gòu)同時優(yōu)化,在超網(wǎng)絡(luò)的每一步優(yōu)化過程中,隨機選取一個子網(wǎng)絡(luò),只有這個子網(wǎng)絡(luò)的權(quán)重被更新。為了解決耦合問題,網(wǎng)絡(luò)搜索空間被簡化成一個單路徑結(jié)構(gòu),其示意圖如圖11所示。
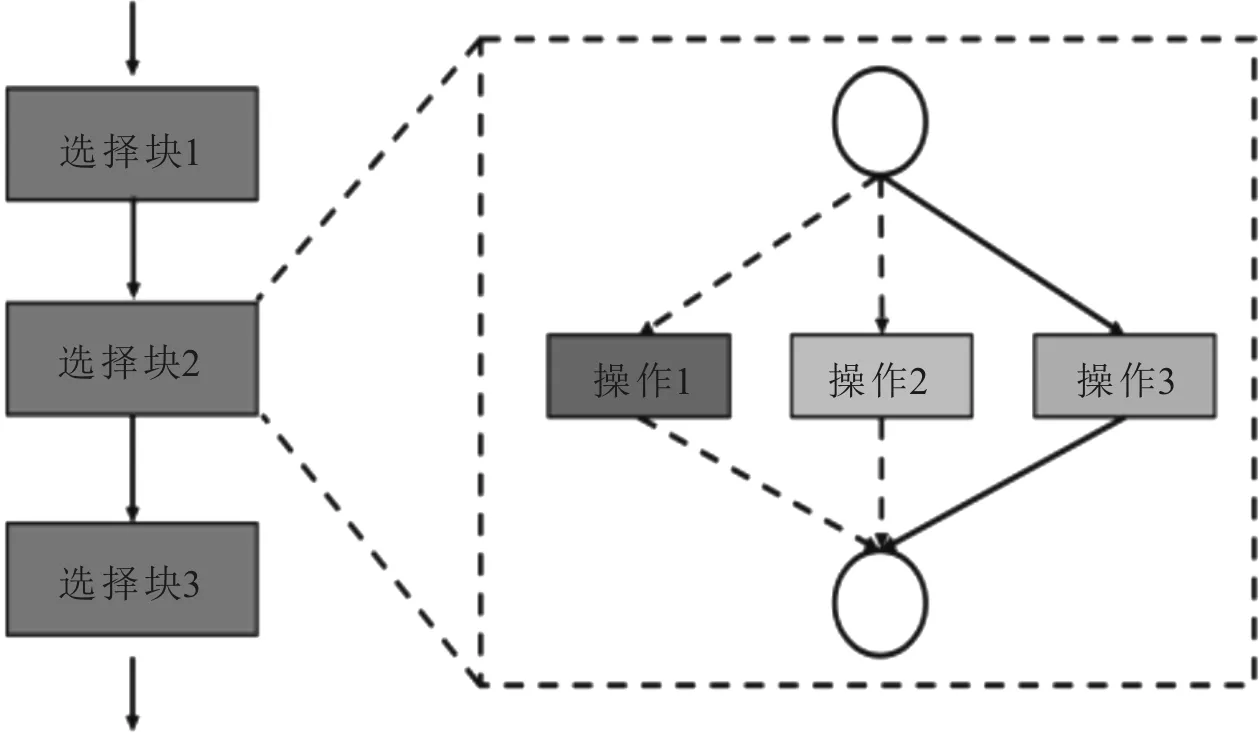
圖11 Block結(jié)構(gòu)示意圖
使用“選擇模塊”構(gòu)建網(wǎng)絡(luò)結(jié)構(gòu),選擇模塊是由多種選擇操作組成,每個選擇模塊在一個時刻只能選擇其中一種操作。對選擇塊中操作的選擇目前有兩種的方法,一種是使用通道數(shù)搜索,每一個選擇模塊目的是選擇出卷積層的通道數(shù),主要思路是從最大數(shù)量的通道數(shù)開始,在超網(wǎng)絡(luò)的訓(xùn)練過程中隨機選擇并通過下一層的反饋進行修剪。另一種方法是混合精度量化搜索,選擇塊用來搜索卷積層權(quán)重值和特征的量化精度。
2019年,Guo等[68]提出了單路徑模型以解決訓(xùn)練中遇到的問題,其主要思想是構(gòu)建一個單路徑超網(wǎng)絡(luò)模型,該網(wǎng)絡(luò)采用均勻采樣方法選擇一個子網(wǎng)絡(luò)進行訓(xùn)練,所有的網(wǎng)絡(luò)架構(gòu)及其權(quán)重局均采用平等的訓(xùn)練,然后使用進化算法高效地搜索出最佳的體系結(jié)構(gòu)。經(jīng)過實驗證明該方法效率高、易于訓(xùn)練且搜索效率高。同年,Cheng等[69]提出了InstaNAS,即一種實例感知NAS框架。該框架設(shè)計思路是控制器在數(shù)據(jù)集上搜索“架構(gòu)的分布”而不是僅僅單個架構(gòu)。InstaNAS由One-Shot模型和控制器組成,使用One-Shot架構(gòu)搜索用來降低搜索成本,加速搜索過程,針對輸入的實例進行訓(xùn)練,對結(jié)構(gòu)目標(biāo)和準確性目標(biāo)進行同時優(yōu)化,自動權(quán)衡兩個目標(biāo),生成適用于實例的網(wǎng)絡(luò)架構(gòu)。2020年,Chu等[70]提出訓(xùn)練多路徑超級網(wǎng)絡(luò)以準確評估候選架構(gòu),通過研究發(fā)現(xiàn)在搜索空間中,從多個路徑求和的特征向量幾乎是單個路徑的特征向量的倍數(shù),擾亂了超網(wǎng)訓(xùn)練及其排名能力。在基于批處理[71](Batch Normalization,BN)的基礎(chǔ)上提出了一種稱為“影子批歸一化”的機制,以對不同的特征統(tǒng)計量進行正則化。同年,Lu等[72]提出了神經(jīng)體系結(jié)構(gòu)轉(zhuǎn)移(Neural Architecture Transfer,NAT),NAT旨在有效地生成特定于任務(wù)的自定義模型,即使在多個相互沖突的目標(biāo)下,也具有競爭力。該方法的關(guān)鍵是集成在線遷移學(xué)習(xí)和多目標(biāo)進化搜索過程,在搜索特定任務(wù)的子網(wǎng)的同時迭代地調(diào)整了預(yù)訓(xùn)練的超級網(wǎng)絡(luò)。小規(guī)模的細粒度數(shù)據(jù)集從NAT中受益最大,同時架構(gòu)搜索和傳輸?shù)男时痊F(xiàn)有NAS方法高幾個數(shù)量級。Huang等[73]提出了GreedyNAS,在訓(xùn)練過程中不覆蓋所有的路徑,而是通過評估超級網(wǎng)中潛在性能更好的路徑,緩解超級網(wǎng)的負擔(dān),使用驗證數(shù)據(jù)的代理項部分。Zela等[74]為One-Shot模型的NAS引入了一個通用框架,該框架可以實例化為許多最近引入的變體,并引入了一個通用基準框架,該框架借鑒了最新的數(shù)據(jù)集 NAS-Bench-101對One-Shot模型的NAS進行低成本隨時評估。Li等[75]提出了一種新方法引導(dǎo)參數(shù)后驗向其真實分布。盡管基于One-Shot模型的NAS通過權(quán)重共享顯著提高了計算效率,但是在超網(wǎng)訓(xùn)練(架構(gòu)搜索階段)期間引入了多模型訓(xùn)練,該過程會使得前面的訓(xùn)練架構(gòu)出現(xiàn)性能下降的問題。為了克服這種問題,Zhang等[76]假設(shè)在聯(lián)合優(yōu)化后進行驗證時的共享權(quán)重為最佳權(quán)重,將One-Shot-NAS中的超網(wǎng)訓(xùn)練表述為持續(xù)學(xué)習(xí)的約束優(yōu)化問題,即當(dāng)前架構(gòu)的學(xué)習(xí)不應(yīng)在超網(wǎng)訓(xùn)練期間降低先前架構(gòu)的性能。同時,設(shè)計了一種新穎性的搜索方法找到最具代表性的子集用來規(guī)范超網(wǎng)訓(xùn)練。2021年,Hu等[77]提出了一個收縮和擴展的超網(wǎng)絡(luò),通過減少權(quán)重共享的程度解耦共享參數(shù),避免了不穩(wěn)定和不準確的性能估計。同年,Huang等[78]提出了一種漸進式一次性神經(jīng)架構(gòu)搜索(Progressive One-Shot Neural Architecture Search,PONAS)方法,以實現(xiàn)對各種硬件約束的非常有效的模型搜索。在搜索架構(gòu)空間時,通過構(gòu)建一個表來存儲所有層的所有候選塊的驗證準確性。對于更嚴格的硬件約束,可以根據(jù)該表通過選擇產(chǎn)生最小精度損失的最佳候選塊有效地確定專用網(wǎng)絡(luò)的架構(gòu)。PONAS方法以結(jié)合漸進式NAS和一次性方法的優(yōu)點,給出了包括元訓(xùn)練階段和微調(diào)階段的兩階段訓(xùn)練方案,使搜索過程高效穩(wěn)定。在搜索過程中,評估不同層中的候選塊并構(gòu)建一個用于架構(gòu)搜索的準確度表,用該表評估完整網(wǎng)絡(luò)的性能。
4.3.4 代理模型
代理模型就是用來代替某個模型的模型,核心思想為訓(xùn)練并利用一個計算成本較低的模型去模擬原本計算成本較高的那個模型的預(yù)測結(jié)果,從而避開大型模型的計算。
代理模型進行優(yōu)化過程主要分為抽樣選擇(也被稱為順序設(shè)計或主動學(xué)習(xí))、建立代理模型模式和優(yōu)化模型參數(shù),以及代理模型準確性評估等3個方面。
基于SMBO策略的新方法,以結(jié)構(gòu)復(fù)雜度增加的順序為網(wǎng)絡(luò)結(jié)構(gòu)的搜索順序,同時使用代理模型指導(dǎo)網(wǎng)絡(luò)結(jié)構(gòu)空間搜索。在搜索空間方面,搜索算法的目標(biāo)是搜索表現(xiàn)性能良好的卷積單元(Cell),而不是整個的CNN網(wǎng)絡(luò)結(jié)構(gòu)。使用啟發(fā)式搜索的方法搜索單元結(jié)構(gòu)的空間,由簡單的模型開始,逐步發(fā)展為復(fù)雜的模型,并在進行過程中修剪掉沒有希望的結(jié)構(gòu)。Deng等[1]提出在訓(xùn)練之前基于網(wǎng)絡(luò)的體系結(jié)構(gòu)預(yù)測網(wǎng)絡(luò)的性能,開發(fā)了一種統(tǒng)一的方法將各個層編碼為向量,并組合在一起以通過長短期記憶(Long Short-Tern Memory,LSTM)形成一個完整的描述。該方法利用循環(huán)網(wǎng)絡(luò)的強大表達能力,可以可靠地預(yù)測各種網(wǎng)絡(luò)體系結(jié)構(gòu)的性能。
4.3.5 可微分神經(jīng)架構(gòu)模型加速方案
DARTS與網(wǎng)絡(luò)結(jié)構(gòu)的壓縮有關(guān),目前是利用現(xiàn)有的神經(jīng)網(wǎng)絡(luò),減少參數(shù)數(shù)量和計算成本,同時對模型的預(yù)測精度影響最小。DARTS主要針對卷積網(wǎng)絡(luò)進行操作,包括每個卷積層、搜索過濾器大小、通道數(shù)量和分組卷積。通過訓(xùn)練與最大體系結(jié)構(gòu)大致相同的單個模型獲取更好的效果,而不需要訓(xùn)練大量不同的模型達到類似的性能水平。
DARTS將離散的搜索空間轉(zhuǎn)變成連續(xù)松弛的搜索空間,然后使用梯度下降的方法有效地搜索體系結(jié)構(gòu)。DARTS的關(guān)鍵在于是使用Softmax函數(shù)對候選操作進行混合操作。將原有離散的搜索空間通過一定的操作變成了連續(xù)空間,將目標(biāo)函數(shù)變成為了可微函數(shù),然后使用梯度下降的方法找到最優(yōu)結(jié)構(gòu)。該方法的搜索空間設(shè)計基于NASNet結(jié)構(gòu),相比其他搜索空間結(jié)構(gòu)大小不設(shè)限制,可微分搜索方法在數(shù)據(jù)集上的結(jié)構(gòu)層數(shù)進行了固定,雖然搜索效果很好,但是該方法的搜索過程有一定局限性,搜索結(jié)構(gòu)不夠豐富。Hundt等[56]對DARTS進行了改進,提出了sharpDARTS。Chen等[57]又在DARTS改進提出P-DARTS,用漸進地增加搜索網(wǎng)絡(luò)的深度解決深度差異的問題。采用漸進增加搜索網(wǎng)絡(luò)深度的策略是因為可以用這種方式逐漸地縮小搜索空間,也就是候選操作的種類,從而保持顯存消耗在一個合理的水平。2019年,Xu等[58]提出的PC-DARTS都是在DARTS的基礎(chǔ)上進行改進,降低搜索時間開銷和內(nèi)存開銷。Xie等[79]提出了隨機神經(jīng)體系結(jié)構(gòu)搜索(Stochastic Neural Architecture Search,SNAS),該方法可以在同一輪反向傳播的同時優(yōu)化訓(xùn)練神經(jīng)操作參數(shù)和網(wǎng)絡(luò)結(jié)構(gòu)分布參數(shù),并且保持完整性和可區(qū)分性。為了在一般可微分損失中利用梯度信息進行體系結(jié)構(gòu)搜索,一種新的搜索梯度被提出,與基于強化學(xué)習(xí)的NAS相比可以更有效地反饋結(jié)果并進行決策。在CIFAR-10上進行的實驗中,SNAS花費更少的時間找到具有最新精度的單元架構(gòu)。
DNAS在設(shè)計最先進的高效神經(jīng)網(wǎng)絡(luò)方面已展示出巨大的成功。與其他搜索方法相比,基于DARTS的DNAS的搜索空間很小,因為必須在內(nèi)存中實例化所有候選網(wǎng)絡(luò)層,導(dǎo)致搜索空間規(guī)模有限。為了解決這個瓶頸, Wan等[81]于2020年提出了一種內(nèi)存有效且計算效率高的DNAS變體:DMaskingNAS。與傳統(tǒng)的DNAS相比,該算法對搜索空間進行了擴大,從而支持了空間和通道尺寸上的搜索,并且提出了一種掩蔽機制用于特征圖重用,隨著搜索空間規(guī)模的不斷擴大,運行內(nèi)存消耗和計算成本消耗可以保持不變。采用有效的方式傳遞最大化每個參數(shù)的精度,與所有以前的體系結(jié)構(gòu)相比,可以搜索到的FBNetV2具有最先進的性能。
4.3.6 基于網(wǎng)絡(luò)態(tài)射法和迂回爬山的方案
網(wǎng)絡(luò)態(tài)射法(Network Morphing)的核心思想是通過態(tài)射的手段去避免重復(fù)訓(xùn)練,從而在速度上取得優(yōu)勢。兩個不同的神經(jīng)網(wǎng)絡(luò)A和B,滿足功能相同而結(jié)構(gòu)不同,那么可以稱神經(jīng)網(wǎng)絡(luò)A和B互為網(wǎng)絡(luò)態(tài)射,即功能相同,結(jié)構(gòu)不同的神經(jīng)網(wǎng)絡(luò)互為網(wǎng)絡(luò)態(tài)射,子網(wǎng)絡(luò)從父網(wǎng)絡(luò)繼承知識,具有潛力發(fā)展為更強大的網(wǎng)絡(luò)。基于網(wǎng)絡(luò)態(tài)射結(jié)構(gòu)方法能夠盡可能的保留原網(wǎng)絡(luò)的優(yōu)點,并在原有的網(wǎng)絡(luò)結(jié)構(gòu)基礎(chǔ)上進行修改,通過一定的變換方式可以還原網(wǎng)絡(luò),同時與原網(wǎng)絡(luò)相比,新網(wǎng)絡(luò)的性能更好。迂回爬山法是指把當(dāng)前的問題狀態(tài)經(jīng)過評估后,在相應(yīng)條件的限制下,不采用縮小差異的方法,而是采用擴大評估狀態(tài)與最終目標(biāo)狀態(tài)之間差異的方法,采用迂回前進,最終實現(xiàn)總目標(biāo),基于爬山法最大的缺點在于非常容易陷入局部最優(yōu)解。
用于神經(jīng)架構(gòu)的爬山法(Neural Architecture Search by Hill-climbing,NASH)是基于簡單的爬山過程自動搜索性能良好的CNN架構(gòu),其每一次會在臨近空間中選擇最優(yōu)解作為當(dāng)前解,該算法應(yīng)用網(wǎng)絡(luò)態(tài)射,通過余弦退火對學(xué)習(xí)率進行優(yōu)化。構(gòu)建網(wǎng)絡(luò)常用的方法是先設(shè)計出一個網(wǎng)絡(luò)結(jié)構(gòu),緊接著對網(wǎng)絡(luò)進行訓(xùn)練,并在驗證集上驗證該網(wǎng)絡(luò)性能,如果性能表現(xiàn)較差,則重新設(shè)計一個網(wǎng)絡(luò),但是這樣的過程會耗費大量時間。于是,Elsken等[82]于2017年提出了基于網(wǎng)絡(luò)態(tài)射(Network Morphism)的搜索方法。在搜索空間上使用爬山法,從臨近的點中選擇對應(yīng)解最優(yōu)的個體,使之替代原來的個體,并不斷的重復(fù)這一過程,然后使用余弦退火對學(xué)習(xí)率進行迭代更新。Verma等[83]于2020年提出基于爬山法的新型神經(jīng)架構(gòu)搜索框架,利用梯度更新射態(tài)操作的方案,通過增加梯度漸變擴展結(jié)構(gòu),選擇射態(tài)節(jié)點和增加操作減少時間,獲得更高的準確性。
5 實驗條件發(fā)展
神經(jīng)架構(gòu)搜索的開啟便是借助于強大的算力搜索盡可能多的網(wǎng)絡(luò)并找到最佳的網(wǎng)絡(luò)。計算設(shè)備的發(fā)展加速了NAS的研究,從最開始的只依賴CPU計算,到利用GPU進行計算加速,再到利用更強大的網(wǎng)絡(luò)矩陣服務(wù)器。同時計算設(shè)備數(shù)量從最開始的上千個降低到單個設(shè)備。
計算設(shè)備隨著發(fā)展從CPU到GPU,再到現(xiàn)在的TPU,計算方法和計算效率大幅提升,3種設(shè)備的工作原理及性能對比如表1所示。
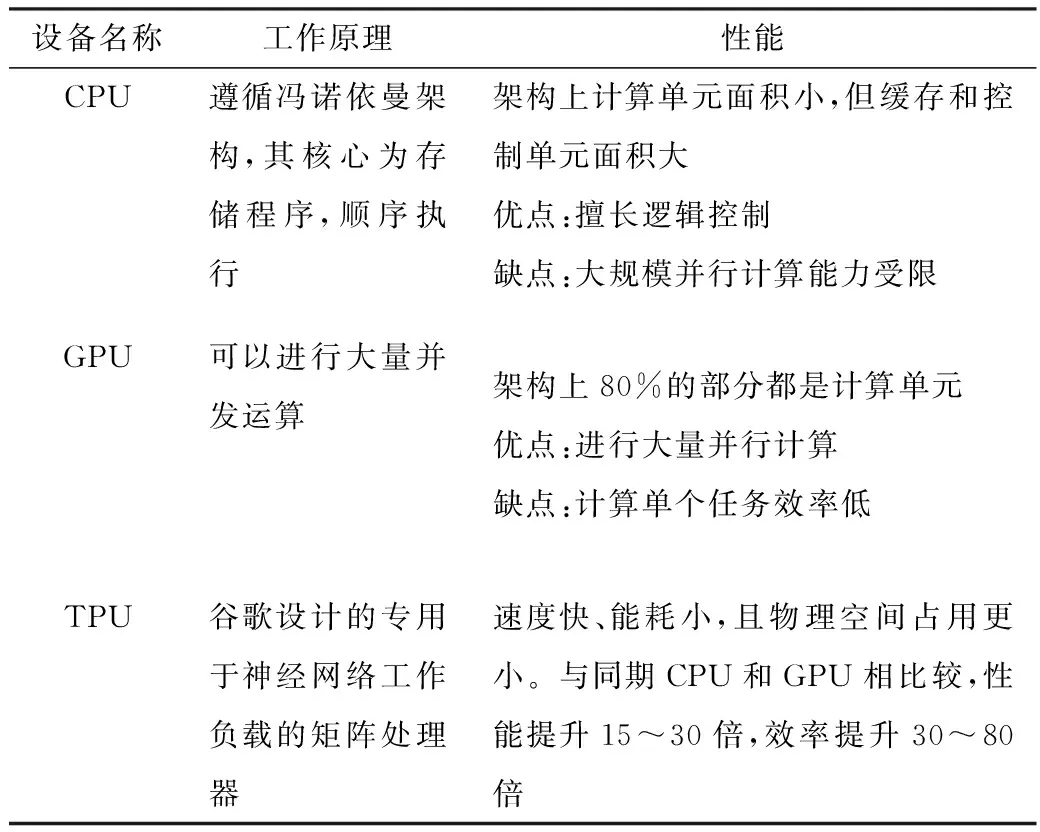
表1 3種設(shè)備的工作原理及性能對比
NAS需要進行大量參數(shù)計算的研究,目前主流的設(shè)備還是以GPU為主。未來隨著計算架構(gòu)的迭代發(fā)展,會出現(xiàn)更多性能更優(yōu)的計算設(shè)備,屆時NAS的研究發(fā)展將會邁向更高的臺階,部分神經(jīng)架構(gòu)算法實驗條件如表2所示。
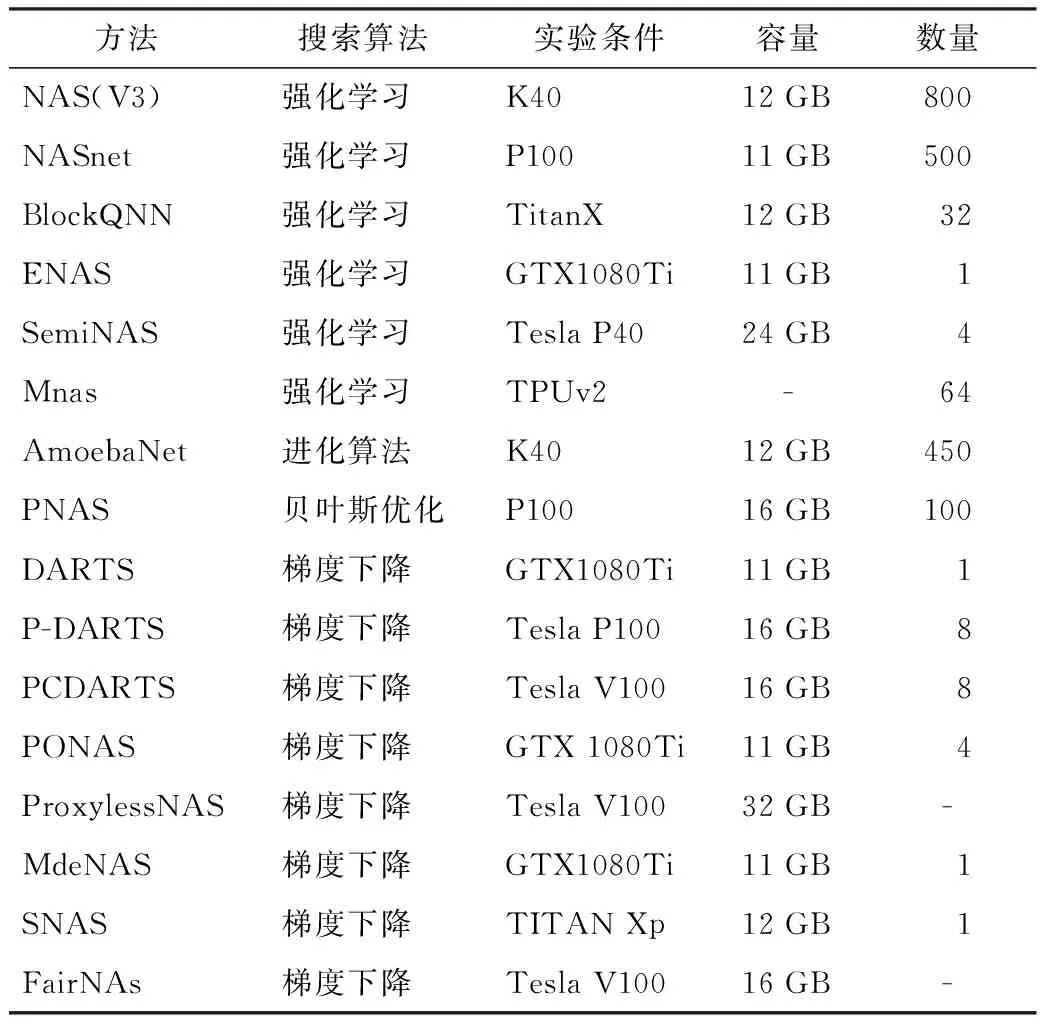
表2 部分神經(jīng)架構(gòu)算法實驗條件
從表2可以看出,隨著研究的深入,神經(jīng)架構(gòu)搜索所需要的實驗條件逐漸降低,同時網(wǎng)絡(luò)準確率的不斷提升。神經(jīng)架構(gòu)搜索在近年取得巨大的發(fā)展,除了搜索空間的改進和搜索策略的提升以及參數(shù)的優(yōu)化等3個方面,最大的變化就是與之匹配的實驗設(shè)備。
從搜索空間來看,基于Cell結(jié)構(gòu)的網(wǎng)絡(luò)結(jié)構(gòu)在空間多樣性和復(fù)雜度方面滿足要求的同時對計算資源的消耗需求降低,空間大小和網(wǎng)絡(luò)層數(shù)成為影響算力的關(guān)鍵因素。單個GPU計算條件下,在搜索空間設(shè)計上進行了簡化,從最多的13個候選操作減少為2~3個主要的操作,構(gòu)建網(wǎng)絡(luò)的層數(shù)也相對較少,整個搜索空間所需要的計算內(nèi)存較少,單個GPU計算條件下的NAS研究,成為了研究輕量型NAS的新方向。
從搜索策略來看,隨機搜索策略作為初代策略,簡單直接的進行搜索,沒有策略導(dǎo)向,隨機性高,對計算資源需求大。強化學(xué)習(xí)作為神經(jīng)架構(gòu)搜索,首先使用“交互型”算法,搜索空間的設(shè)計上空間復(fù)雜度較高,需要通過不斷“試錯”找到最佳網(wǎng)絡(luò),相比較隨機搜索策略,強化學(xué)習(xí)更加智能,能夠根據(jù)反饋進行改進,提高搜索效率。在實驗設(shè)備使用上,基于強化學(xué)習(xí)的NAS設(shè)備利用率更高,需要強大的計算資源做支撐。基于進化算法的策略是一種偏導(dǎo)向的策略,在給定的方向下進行迭代,對搜索空間和實驗設(shè)備要求沒有基于強化學(xué)習(xí)的高,更多側(cè)重算法層面的優(yōu)化,快速找到性能較好的網(wǎng)絡(luò)。隨著研究的深入,貝葉斯優(yōu)化、梯度下降等方法的相繼引入,與強化學(xué)習(xí)和進化算法不同的是,貝葉斯優(yōu)化和梯度下降是有針對性的策略,局部范圍內(nèi)進行改進,一般搜索空間相對較小,在同等準確率的情況下,搜索效率更高,搜索時間更短。
性能評估在NAS初期對實驗條件要求高,在搜索過程中產(chǎn)生的大量參數(shù)需要的高性能設(shè)備資源去計算。得益于算法的改進,采用權(quán)重共享、模型加速和早停等方法降低參數(shù)量及模型數(shù)量,提高搜索過程中對網(wǎng)絡(luò)性能的評估效率。通過對評估方法的改進和創(chuàng)新,對搜索空間的進行裁剪和路徑選擇,并采用更高效的搜索策略,在搜索過程中降低內(nèi)存消耗,以實現(xiàn)快速評估。
從NAS誕生以來,實驗條件成為衡量NAS復(fù)雜度的一個標(biāo)準,出現(xiàn)了NAS空間結(jié)構(gòu)和搜索策略越復(fù)雜,需要的計算條件越高的情況。隨著NAS的研究方向更加精細化,搜索空間簡單、搜索策略高效和評估更快的NAS成為了研究的熱點,實驗條件正朝著低成本的方向發(fā)展。
6 結(jié)論
經(jīng)過近些年的發(fā)展,神經(jīng)架構(gòu)搜索包含的搜索空間、搜索策略和性能評估等3方面內(nèi)容有了很大的進展,取得了很多成績。神經(jīng)網(wǎng)絡(luò)構(gòu)建的模型從簡單到復(fù)雜,搜索空間相比人工設(shè)計的鏈式網(wǎng)絡(luò)結(jié)構(gòu),在空間復(fù)雜度方面有了很大的發(fā)展,空間結(jié)構(gòu)設(shè)計多元化,在一定程度上可以設(shè)計出準確率更高的空間。搜索策略從簡單的隨機搜索,發(fā)展到現(xiàn)在多樣的策略,越來越多的算法思想被引用到神經(jīng)架構(gòu)搜索的研究中,搜索策略更加的靈活,在很復(fù)雜的搜索空間中可以高效地搜索出最佳的網(wǎng)絡(luò)結(jié)構(gòu),效率極大提高,時間成本大幅降低。性能評估不在局限于邊訓(xùn)練、邊評估這種耗時耗力的方法,轉(zhuǎn)變研究思路,采取近似估計以及搜索加速的辦法,節(jié)約計算成本和訓(xùn)練時間。
傳統(tǒng)的NAS主要基于搜索空間、搜索策略和性能評估等3個方面研究,隨著研究的深入,神經(jīng)架構(gòu)搜索可以概括為網(wǎng)絡(luò)結(jié)構(gòu)優(yōu)化和參數(shù)優(yōu)化兩個互相優(yōu)化的部分,NAS優(yōu)化示意圖如圖12所示。

圖12 NAS優(yōu)化示意圖
神經(jīng)架構(gòu)搜索的目標(biāo)是搜索最佳的網(wǎng)絡(luò)結(jié)構(gòu),在一定程度上可以轉(zhuǎn)換為網(wǎng)絡(luò)結(jié)構(gòu)優(yōu)化和參數(shù)優(yōu)化的雙優(yōu)化問題,兩個部分的循環(huán)更新以達到最優(yōu)的效果。網(wǎng)絡(luò)結(jié)構(gòu)由搜索空間構(gòu)成,參數(shù)優(yōu)化又是在搜索空間上進行優(yōu)化,搜索空間的設(shè)計可以說是整個神經(jīng)架構(gòu)搜索過程各項工作的基礎(chǔ),也是實現(xiàn)突破的重點。從現(xiàn)在的方法來看,以NASNet搜索空間為基礎(chǔ),衍生了很多方法,例如ENAS、MNAS等,DRATS是在ENAS的基礎(chǔ)上進行改進和優(yōu)化方法創(chuàng)新,P-DARTS和PC-DARTS又是在DARTS基礎(chǔ)上進一步改進,主要是對搜索策略的改進和參數(shù)優(yōu)化,在搜索空間上的創(chuàng)新較少。在未來的工作中,搜索空間的設(shè)計將會是影響神經(jīng)架構(gòu)搜索的關(guān)鍵因素之一。同時,網(wǎng)絡(luò)在搜索過程中會產(chǎn)生大量的參數(shù),參數(shù)優(yōu)化是一個十分艱難的過程,受制于算法和算力,很多方法的參數(shù)規(guī)模無法進一步壓縮,導(dǎo)致在計算過程中會大量占據(jù)內(nèi)存空間,消耗計算資源,參數(shù)優(yōu)化的設(shè)計和改進需要進一步研究。
雖然神經(jīng)架構(gòu)搜索在時間成本上相比以往有很大降低,但是目前時間成本仍然較高,未來可以通過改進大幅降低搜索時間。同時,神經(jīng)架構(gòu)搜索對實驗環(huán)境要求較高,實驗機器等采購成本過高,不利于普惠性推廣,未來可以通過對策略以及評估等方面進行研究,降低神經(jīng)架構(gòu)搜索的成本消耗。
NAS的評價數(shù)據(jù)集基本以CIFAR-10[84]、CIFAR-100、ImageNet[85]和PTB[86]數(shù)據(jù)集為主,最新的適用數(shù)據(jù)集出現(xiàn)了COCO[87]、DIV2K[88]等數(shù)據(jù)集用以檢測算法的效果,一直以來使用同一數(shù)據(jù)集檢驗不同算法效果,將得到的準確率作為判別標(biāo)準。但是,在任意數(shù)據(jù)集上的表現(xiàn),仍有待觀察和實驗,神經(jīng)架構(gòu)搜索的外拓性需要進一步提高。
自2015年NAS被提出來,NAS迎來了井噴式發(fā)展,越來越多的研究者投身于NAS的研究。部分典型神經(jīng)架構(gòu)算法實驗結(jié)果對比如表3所示。

表3 典型神經(jīng)架構(gòu)算法實驗結(jié)果
由表3可以看出,在不同的搜索策略下,算法的誤差率逐步下降。從時間維度上,NAS的研究重點在策略方面從最初強化學(xué)習(xí)到現(xiàn)在的進化和梯度下降等,凸顯了NAS的研究更加多元、策略化,不再依靠強大的計算資源進行遍歷搜索,而是采用更巧妙的方法進行“快捷”搜索。
目前,神經(jīng)架構(gòu)搜索的衡量標(biāo)準只能做到“局部統(tǒng)一”,即在同等的搜索策略下,對數(shù)據(jù)集誤差率和準確率進行對比。神經(jīng)架構(gòu)搜索也可以說是一個組合優(yōu)化問題,使用不同的方法進行相應(yīng)的組合,在同等策略的條件下進行縱向比較,會有一定的進步和創(chuàng)新。但是整個NAS的橫向比較中,以數(shù)據(jù)集的誤差率和準確率作為“統(tǒng)一”標(biāo)準來看,提升的效果不是很明顯。NAS作為一個開放性的研究領(lǐng)域,目前缺乏一個共識性的統(tǒng)一標(biāo)準衡量所有方法的優(yōu)劣。
7 展望
神經(jīng)架構(gòu)搜索已經(jīng)被證明在未來具有巨大的前景,目前NAS主要還是在理論研究,受制于理論空間設(shè)計等因素,NAS所涉及的實際場景應(yīng)用較少,未來經(jīng)過改進的NAS在圖像識別、數(shù)據(jù)處理和視頻處理等方面將會是強有力的競爭者。
在研究內(nèi)容上,搜索空間和搜索策略將會在現(xiàn)有的基礎(chǔ)上更加完善,性能評估將會在參數(shù)優(yōu)化方面迎來更大的發(fā)展,多方法融合的策略將會成為推動NAS研究的動力之一。在實驗條件上,隨著計算機體系結(jié)構(gòu)的研究發(fā)展,將會出現(xiàn)更多性能高、低功耗的實驗室設(shè)備,支持和加速NAS的研究發(fā)展,NAS的性能相比較目前的水平,將會有一個更大幅度的提升。在應(yīng)用方向上,超大數(shù)據(jù)模型網(wǎng)絡(luò)以及移動端網(wǎng)絡(luò)將會成為神經(jīng)架構(gòu)搜索研究的重點。超大型數(shù)據(jù)模型網(wǎng)絡(luò),比如圖像識別分割以及數(shù)據(jù)分析領(lǐng)域,對大型公司而言,不用在分地區(qū)、分類別進行分析甄別,神經(jīng)架構(gòu)搜索將會針對以億為單位的數(shù)據(jù)集自動搜索得出最適于數(shù)據(jù)集的網(wǎng)絡(luò),以先共性后個性原則,分析數(shù)據(jù)的特點,最終呈現(xiàn)出以前分割狀態(tài)下難以發(fā)現(xiàn)的數(shù)據(jù)規(guī)律,其算法的準確度和性能將會比利用現(xiàn)存的網(wǎng)絡(luò)模型的結(jié)果更優(yōu)秀。移動端將會產(chǎn)生大量數(shù)據(jù),移動端的神經(jīng)架構(gòu)搜索以輕量化為主,以極小的時間得到最佳的結(jié)果。在數(shù)據(jù)集應(yīng)用上,隨著未來研究的深入,更多適用的NAS數(shù)據(jù)集會產(chǎn)生,NAS可以被應(yīng)用于廣泛的實驗驗證以及理論研究當(dāng)中。神經(jīng)架構(gòu)搜索將會成為未來人工智能的主流,推動各個領(lǐng)域發(fā)展。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產(chǎn)導(dǎo)刊(2022年5期)2022-06-01 06:20:14
建材發(fā)展導(dǎo)向(2021年12期)2021-07-22 08:06:48
建材發(fā)展導(dǎo)向(2021年7期)2021-07-16 07:07:52
中學(xué)生數(shù)理化(高中版.高二數(shù)學(xué))(2021年12期)2021-04-26 07:43:48
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
