藜麥SPP 基因家族全基因組鑒定及表達模式分析
2022-02-08 14:34:28陳紫巖張豪杰魏真真余希文吳傳萬
江西農業學報 2022年10期
關鍵詞:分析
陳紫巖,林 參,2,尹 航,張豪杰,魏真真,余希文,吳傳萬*,李 茹
(1.江蘇徐淮地區淮陰農業科學研究所,江蘇 淮安 223000;2.江蘇天豐種業有限公司,江蘇 淮安 223000;3.四川省農業科學院 植物保護研究所,四川 成都 610066;4.蘇州市農業科學院,江蘇 蘇州 215000)
蔗糖是高等植物光合作用的主要最終產物,同時其作為主要形式參與植物體內碳水化合物的長距離運輸[4]。蔗糖代謝在植物對非生物脅迫(如干旱、高溫等脅迫)中扮演重要角色,對植物生長和產量形成有重要影響[5]。高等植物中蔗糖的生物合成由2步反應組成:第一步蔗糖磷酸合成酶(Sucrose Phosphate Synthase,SPS;EC 2.4.1.14)催化尿苷二磷酸葡萄糖和6-磷酸果糖形成蔗糖-6-磷酸;第二步則是磷酸蔗糖磷酸酶(Sucrose Phosphate Phosphatase,SPP;EC 3.1.3.24)進一步水解蔗糖-6-磷酸形成蔗糖[6]。人們在對于SPP基因的研究日益深入的同時,對于SPP家族基因報道卻少之又少[7]。前期的研究已經證明,SPP相關家族基因可以影響光合碳在不同儲能物質間的分配[8]。2005年,研究者用RNAi技術降低煙草中SPP基因的表達水平,結果顯示隨著SPP基因表達水平的下降,植株中各類糖的含量大幅下降[9]。作為蔗糖合成的關鍵基因,有關SPPs參與藜麥發育的研究十分欠缺。
為了進一步研究調控藜麥蔗糖代謝的分子機制,本研究利用藜麥基因組數據庫,首先鑒定出SPP基因家族全部4個成員,然后對其蛋白的理化性質、模體、啟動子元件、基因結構、進化以及表達模式等進行了分析,以期為后續的藜麥育種工作提供新的思路。
1 材料與方法
1.1 藜麥SPP基因家族成員的鑒定
通過藜麥基因組數據庫(https://www.cbrc.kaust. edu.sa/chenopodiumdb)下載藜麥基因組數據及注釋文件。從Pfam數據庫(http://pfam.xfam.org)下 載S6PP結 構 域(PF05116)和S6PP_C結 構 域(PF08472)的隱馬爾科夫模型(.hmm)文件[10-11],并通過HMMER軟件對藜麥的蛋白序列進行比對,獲得同時擁有S6PP結構域和S6PP_C結構域的候選序列。手動剔除冗余序列后,將獲得的候選序列提交至NCBI網站的CDD軟件(https://www.ncbi.nlm.nih.gov/Structure/bwrpsb/bwrpsb.cgi)進行結構域驗證。
1.2 藜麥SPP基因蛋白的二級結構和理化性質分析
使用在線分析網站SOPMA(https://npsa-prabi.ibcp.fr/cgi-bin/npsa_automat.pl?page= npsa_sopma.html)對藜麥SPP蛋白序列進行二級結構分析[12]。使用ExPASy 網站的在線預測工具(https://web.expasy.org/protparam/)對藜麥SPP家族成員蛋白質的分子量、理論等電點和親水性等理化性質進行預測[13]。
1.3 藜麥SPP基因的亞細胞定位和跨膜結構域預測
使用在線工具PlantmPLoc(http://www.csbio.sjtu.edu.cn/cgi-bin/PlantmPLoc.cgi)進行亞細胞定位預測[14]。使用在線工具TMHMM-2.0(https://services.healthtech.dtu.dk/)進行蛋白跨膜結構域預測[15]。
1.4 藜麥SPP家族染色體定位、基因結構和蛋白保守基序分析
利用TBtools對CqSPP家族的染色體定位及基因結構進行可視化處理,處理后得到圖片[16]。利用MEME(https://meme-suite.org/meme/doc/meme.html?man_type=web)網站對SPP家族的蛋白保守基序進行分析,獲得的結果用TBtools進行可視化[17]。
1.5 6個物種SPP基因家族的系統發育分析
為了闡述藜麥SPP基因家族各成員的系統進化關系,將獲得的6個物種(擬南芥、番茄、藜麥、水稻、高粱和玉米)的基因的候選序列存為Fasta格式,使用ClustalW軟件對其進行氨基酸序列比對,然后利用軟件MEGA 7.0 將多序列比對結果選用鄰接法(neighbor-joining, NJ)構建系統發育樹,其中bootstrap設置為1000,其余參數設置為默認參數。
1.6 藜麥SPP基因啟動子分析
取各成員基因序列中轉錄起始點上游2000 bp序列,將其儲存為Fasta格式,使用PlantCARE進行順式轉錄元件預測。預測結果用TBtools進行可視化。
兩組在進行治療過后,臨床癥狀都得到一定改善,但觀察組的改善程度高于對照組,據統計觀察組的有效率為96.00%,對照組有效率為76.00%,兩組差異具有統計學意義(P<0.05),詳見表1。
1.7 藜麥SPP基因表達的組織特異性分析
藜麥花、葉片、種子、幼苗和莖的RNA-seq數據下載于NCBI轉錄組數據庫(項目號:PRJNA 394651),以此來分析藜麥各組織的表達情況[18]。使用TBtools軟件繪制藜麥SPP基因表達的熱圖(表達量取log2FPKM 值)。
1.8 藜麥SPP基因在逆境脅迫下的表達
供試藜麥品種為蘇藜1號。對出苗30 d的藜麥幼苗進行逆境脅迫處理,設置3種試驗處理:T1為幼苗噴施5.0 mg/L ABA后置于常溫下種植;T2為將幼苗置于4 ℃培養箱中模擬冷處理;T3為幼苗噴施200 mmol/L濃度甘露醇模擬干旱處理。處理48 h后,取葉片進行qPCR檢測,內參選取藜麥基因EF1-a,引物信息見表1。設3次重復,試驗數據用2-ΔΔCt法處理。試驗完成后,用Graphpad 8.0軟件繪制柱狀圖。

表1 qPCR試驗中用到的引物信息
2 結果與分析
2.1 藜麥SPP基因家族全基因組鑒定及編碼蛋白基本理化性質分析
通過Hmmer軟件從藜麥基因組中共鑒定到4個SPP家族成員,按隱馬爾科夫模型匹配度分別命名為CqSPP1、CqSPP2、CqSPP3和CqSPP4 (表2)。其氨基酸數目在399~623之間;分子量介于45.24 ~70.77 kDa之間;理論等電點在5.64~6.93之間,均小于7,顯酸性;不穩定指數介于35.25~41.73,除CqSPP3外均為大于40的不穩定蛋白。利用ProtScale在線工具分析藜麥SPP蛋白氨基酸序列的親/疏水性,發現4個SPP家族蛋白均有多個達-2以下的親水峰,且大于1的疏水峰較少,同時每個SPP家族蛋白親水性氨基酸數量多于疏水性氨基酸數目,因此判斷藜麥SPP家族蛋白表現為親水性(圖1)。
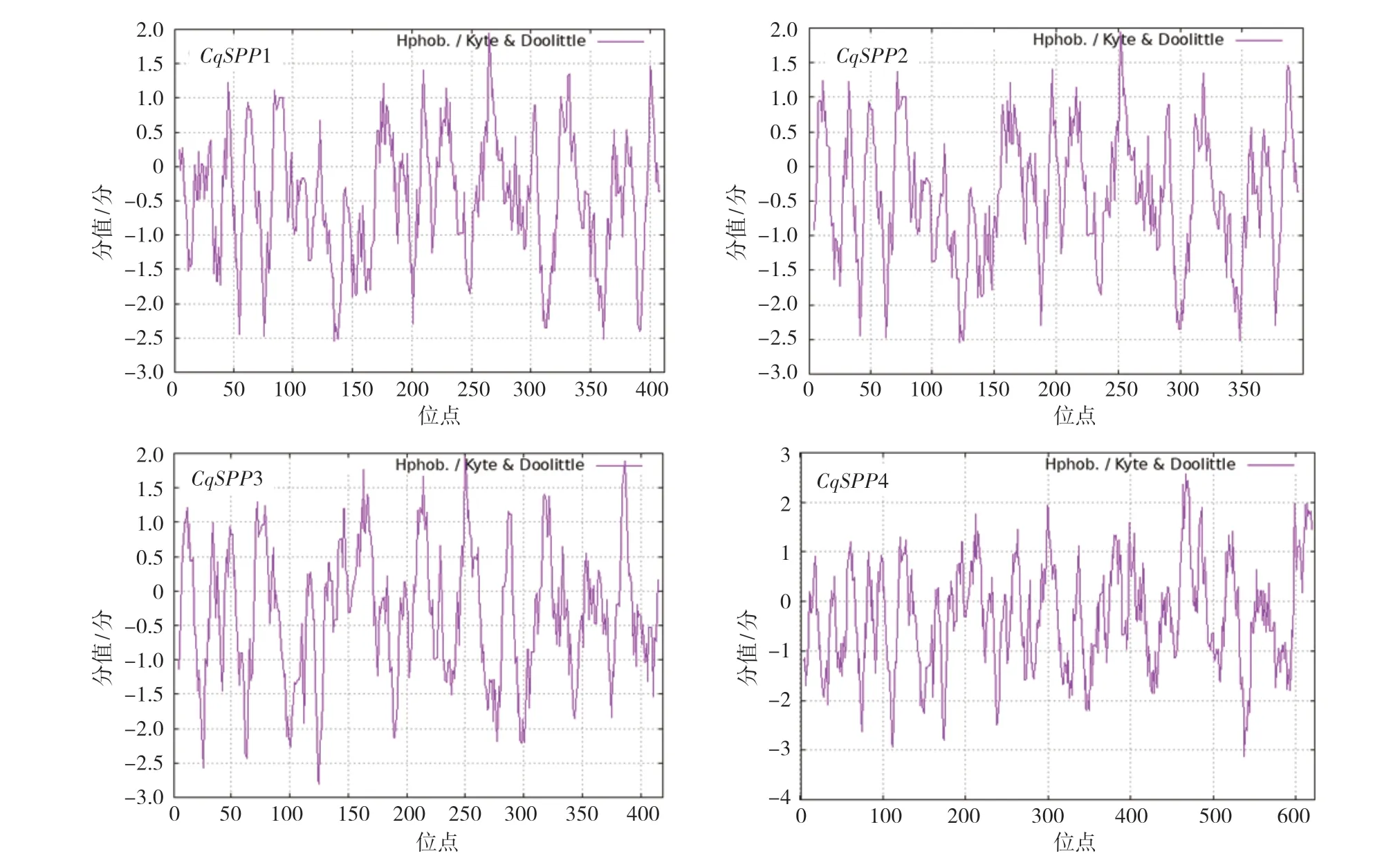
圖1 藜麥SPP蛋白的親水性預測結果

表2 藜麥SPP基因家族成員的基本信息和理化性質
2.2 藜麥SPP基因家族蛋白序列的結構分析
利用在線網站Swiss-model和SOPMA對藜麥SPP蛋白序列進行結構建模與分析,結果(圖2、表3)顯示,藜麥SPP基因家族蛋白都含有α-螺旋、β-轉角、無規則卷曲及延伸鏈等部分,但各部分所占比例明顯不同。藜麥SPP蛋白主要由無規則卷曲以及α-螺旋組成,兩者之和超過空間結構總數的70%;其次為延伸鏈,而β-轉角所占比例最低,在4個蛋白中占比均不超過10%。
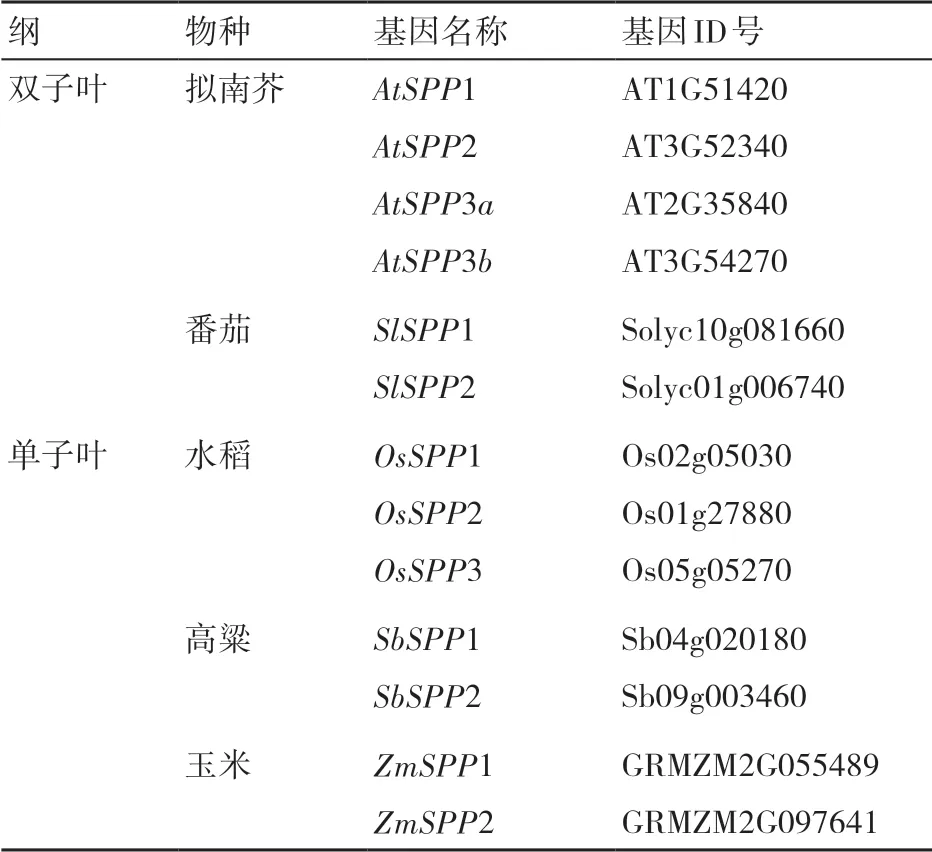
表3 擬南芥、番茄、水稻、高粱和玉米SPPs的命名
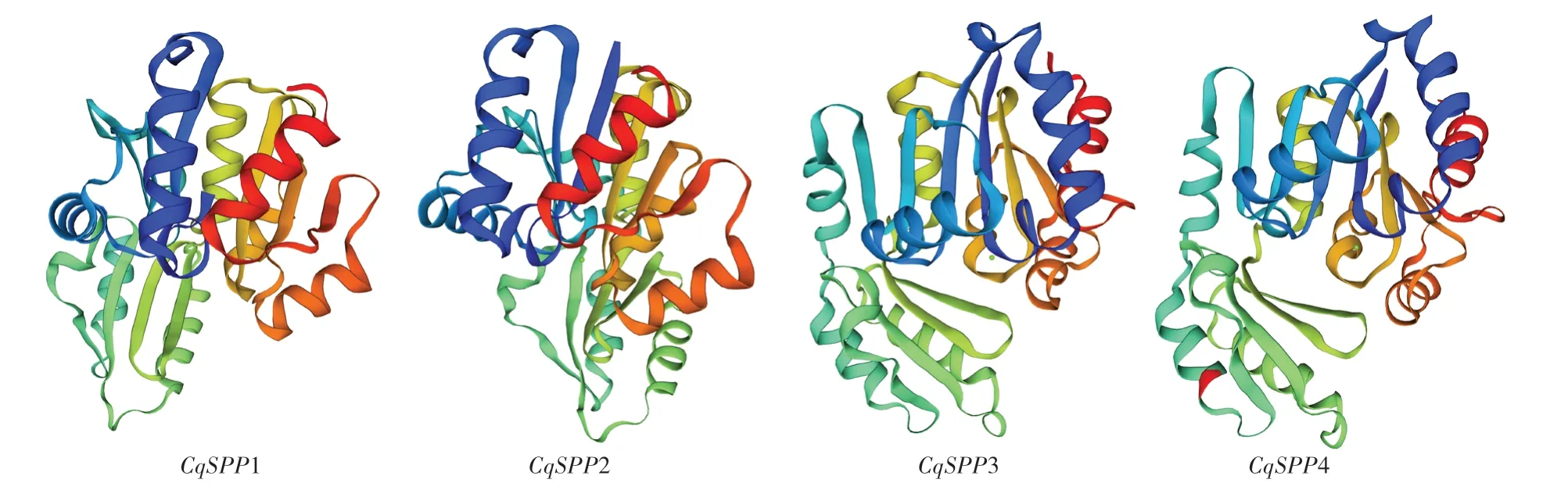
圖2 藜麥SPP蛋白三維結構的預測結果
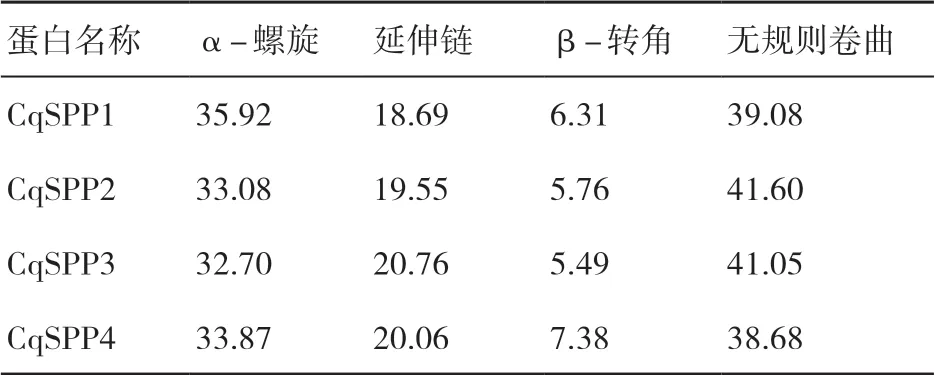
表3 藜麥SPP蛋白的二級結構 %
2.3 藜麥SPP基因家族染色體定位分析
利用TBtools軟件繪制基因在染色體上的位置(圖3),4個CqSPP基因分別定位于4條不同的染色體上。

圖3 藜麥SPP基因家族染色體定位結果
2.4 藜麥SPP基因家族蛋白亞細胞定位及跨膜結構域分析
通過在線軟件Plant-mPLoc對藜麥SPP基因家族4個成員的氨基酸序列進行亞細胞定位預測。結果顯示,除了藜麥SPP2蛋白預測結果為不確定外,其余蛋白主要定位在葉綠體上(表4),這與預測的調控蔗糖合成功能是相吻合的。利用TMHMM在線工具對藜麥SPP蛋白的跨膜結構進行分析,結果表明藜麥SPP家族蛋白中只有CqSPP4蛋白存在跨膜結構域。

表4 藜麥SPP基因亞細胞定位及蛋白跨膜結構域預測
2.5 藜麥SPP家族的基因結構和模體分析
利用TBtools對CqSPP家族的基因結構作圖(圖4),結果顯示,4個CqSPP基因均由外顯子和內含子組成,并且每個基因所含的數量各不相同。其中CqSPP4的外顯子數量最多,為11個,內含子數量為10個。對CqSPP家族模體分析發現(圖5、圖6),4個CqSPP蛋白均有8個排列順序相同的模體,CqSPP1、CqSPP2、CqSPP這3個蛋白在模體2之前多了1個模體9,CqSPP3和CqSPP4蛋白在模體8后面多了1個模體10。
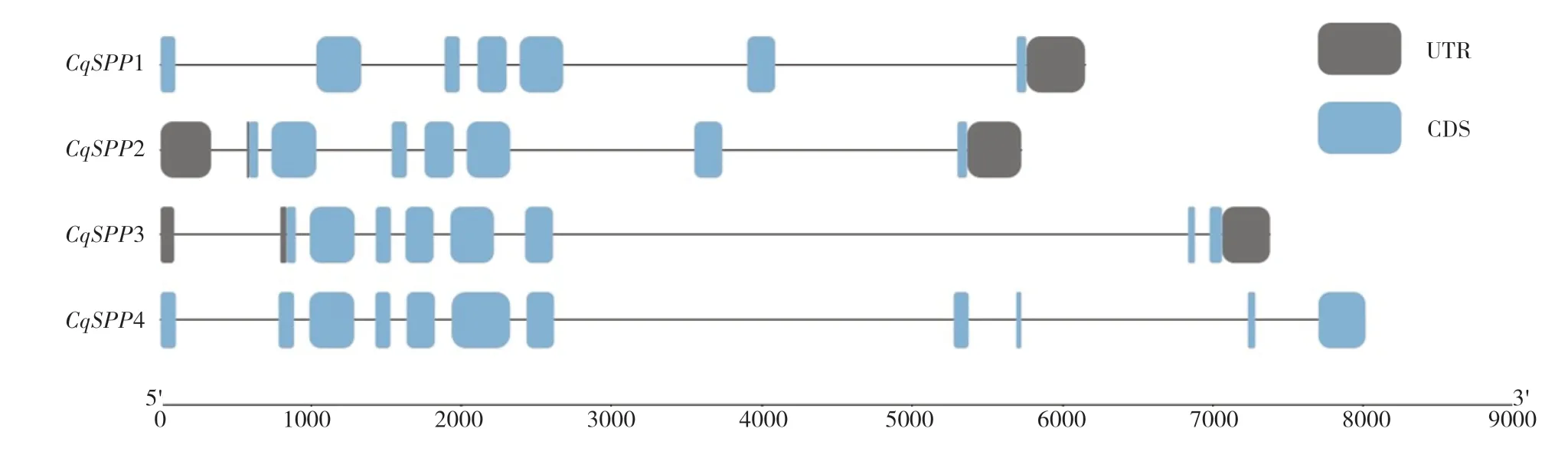
圖4 藜麥SPP基因家族的基因結構
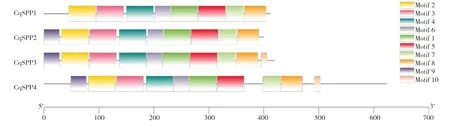
圖5 藜麥SPP基因家族的模體

圖6 模體信息
2.6 藜麥SPP系統發育分析
為了分析CqSPP與其他植物SPP基因(表5)之間的進化關系,我們構建了藜麥SPP家族與其他物種SPP基因的進化樹(圖7),結果表明,植物SPP基因可分為5個組,4個CqSPP成員被聚類到2個組,其中CqSPP1和CqSPP2被聚類到第5組(該家族包含最多的SPP成員),這2個基因與擬南芥AtSPP1、AtSPP2以及AtSPP3a的親緣關系最近;CqSPP3和CqSPP4被聚到第4組,其與擬南芥AtSPP3b聚類在一起。系統發育樹顯示藜麥SPP家族基因與擬南芥相關基因的親緣關系更接近。

圖7 SPP基因家族的進化樹
2.7 藜麥SPP基因啟動子上順式轉錄元件分析
本研究根據公開的基因組數據,獲取SPP各成員轉錄起始點上游2000 bp的序列進行分析(圖8)。結果表明,各成員啟動子上均有多個與逆境響應相關的順式轉錄元件,如MYB、MYC、G-BOX等。從數量上來看,CqSPP4啟動子上的逆境響應轉錄元件明顯比其他成員要多,這也預示著CqSPP4可能與其他成員有著完全不同的逆境響應模式。

圖8 SPP基因的啟動子分析結果
2.8 藜麥SPP基因的表達模式分析
本研究利用藜麥的RNA測序數據分析藜麥SPP基因的表達模式。以熱圖(Heatmap)表示CqSPP基因在5個不同部位的表達情況。CqSPP家族基因表達模式迥異(圖9)。CqSPP1在所有測試組織中的表達量均較高,而CqSPP4的表達量則相對較低。CqSPP1、CqSPP2和CqSPP3這3個基因表現出相同的表達模式,即在種子(Seed)中表達量最高,這可能與SPP家族基因主要控制蔗糖合成的功能有關。

圖9 藜麥CqSPP基因在不同組織中的表達模式
2.9 藜麥SPP基因在逆境脅迫下的表達
本研究分析了藜麥SPP基因在ABA處理、低溫處理和模擬干旱處理下葉片的表達水平(圖10),結果顯示:藜麥葉片中的SPP基因在受到不同脅迫時,表現出不同的響應模式。SPP家族基因在受到ABA脅迫時,表達量均有所下調。而當受到冷害脅迫時,CqSPP1和CqSPP2的表達量上調,CqSPP4的表達量下降,CqSPP3的表達量并未發生明顯變化。在模擬干旱實驗中,CqSPP1和CqSPP3的表達量下降,CqSPP2和CqSPP4則表現為上調。
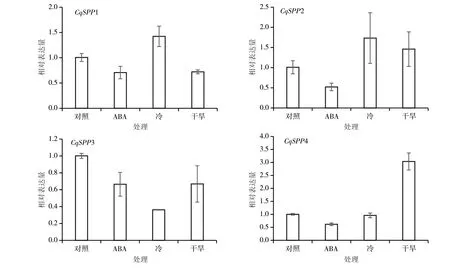
圖10 藜麥CqSPP基因在不同逆境脅迫下的表達量
3 討論
2017年藜麥高質量基因組數據的公布,為藜麥基因家族鑒定、功能基因挖掘和研究提供了便利。本研究通過生物信息學分析,共鑒定出4個藜麥SPP蛋白,多于已報道的水稻、玉米等作物的[19-20]。在4個藜麥SPP蛋白中,CqSPP1、CqSPP2、CqSPP3擁有類似的分子量等理化性質,而CqSPP4則顯得有些特殊:其序列長度、分子量比其他的家族成員均更長、更大,但在各組織中的表達水平上明顯低于其他成員。這可能是因為家族成員在執行功能上存在一定的分化。除CqSPP2外,其余SPP基因家族成員亞細胞定位均位于葉綠體上,這與在玉米、甜菜等作物上的研究結論定位在細胞質上有所不同[21]。這意味著藜麥SPP家族成員在調控蔗糖合成時與其他植物的功能模式并不相同。
對系統進化樹進行分析發現,源自6種植物的17個SPP家族基因被分為1~5組。其中第1、2組包含單子葉植物水稻、玉米和高粱,第3~5組為雙子葉植物藜麥、擬南芥和番茄。這樣的結果證實了被子植物自單雙子葉分化后,SPP家族發生了基因的擴張。同時,在結構上有著相似保守基序的序列分布在同一支上,從側面也證明了本研究所建系統發育樹的可靠性。
通過分析藜麥SPP基因家族在不同組織中的表達數據,發現藜麥SPP家族的基因在花、葉、種子、苗期和莖中均有表達,并且在種子中的表達量高于其他部位。這樣的結果與先前其他植物的報道類似,也從側面驗證了SPP家族調控種子蔗糖合成的重要作用。同時,CqSPP1基因的表達量明顯高于其他家族成員,推測其在調控蔗糖合成中發揮重要作用。
植物的蔗糖合成受不同的內、外在因素的影響。本研究分析藜麥SPP家族各成員的啟動子序列發現,在轉錄起始點上游存在大量與環境響應有關的順式轉錄元件,這預示著各成員的表達可能受外界環境的影響。隨后對藜麥幼苗進行了不同類型的脅迫處理,發現:在受到ABA的影響后,SPP基因均表現出表達量下調的情況,這與脫落酸影響植物光合作用的認知是相符的。而當幼苗受到低溫和干旱影響時,SPP基因家族成員表現出各不相同的響應模式,這從側面說明了SPP基因在執行生物學功能上并不完全相同。后續擬通過過表達、基因敲除以及染色質共沉淀等體內、外的驗證方式更加深入地研究該基因家族成員的功能。
猜你喜歡
現代畜牧科技(2021年9期)2021-10-13 06:39:14
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
電子制作(2018年18期)2018-11-14 01:48:24
山東工業技術(2016年15期)2016-12-01 05:31:22
當代經濟研究(2016年5期)2016-12-01 03:12:05
現代農業(2016年5期)2016-02-28 18:42:46
出版與印刷(2016年3期)2016-02-02 01:20:11
中國中醫藥現代遠程教育(2014年11期)2014-08-08 13:23:44
華北水利水電大學學報(社會科學版)(2014年3期)2014-04-16 04:38:31
終身教育研究(2014年5期)2014-02-28 01:23:06
