面向數字加工監控的邊云工藝協同遷移
2022-02-13 14:39:02曹新城賀王鵬陳彬強
西安電子科技大學學報 2022年6期
曹新城,姚 斌,賀王鵬,陳彬強,卿 濤
(1.廈門大學 航空航天學院,福建 廈門 361005;2.西安電子科技大學 空間科學與技術學院,陜西 西安 710071)
智能制造作為制造業的高階發展形態,已成為我國制造業轉型升級的重要突破口[1-2]。在數字化制造裝備中,傳感網絡逐漸完備,信息采集的維度和密度不斷提升,作為智能制造系統的核心板塊,裝備運維進入大數據時代[3]。由于環境開放、工藝多變、機理復雜等技術瓶頸,裝備運維很大程度上仍然依靠從業者的主觀決策。從工業大數據中挖掘隱含知識,建立監測數據向運維決策的映射模型,實現裝備智能運維,成為智能制造實踐推廣的研究熱點[4]。
人工智能的快速發展為數據驅動的裝備智能運維提供了技術支撐。支持向量機[5]、隨機森林[6]等機器學習算法能夠基于數據樣本對裝備退化過程進行建模,相比于閾值判定更具預先性和非線性。隨著監測信息的維度不斷增加,深度學習技術提取隱含特征的優勢更加凸顯。自動編碼機以及卷積編碼機以其無需標簽監督的優勢在深度特征工程中得到廣泛認可,結合淺層的模式識別網絡實現了成功應用[7]。深度卷積網絡以其稀疏的網絡鏈接大幅度降低了深度模型對計算資源的需求,在處理振動、噪聲等高采樣頻率的數據時表現出特別的優勢[8]。深度學習技術與先進信號處理技術的融合實現了更高的時效性,能夠在噪聲環境下實現可靠的設備健康評估[9]。深度學習技術在設備智能運維的應用層出不窮[10-12],但大都基于充足的實驗數據,樣本集需要覆蓋監測對象各種可能的故障模式。然而,制造現場難以允許設備在故障狀態下運行,故障狀態的數據樣本難以獲取。另一方面,歷史數據不能反映裝備在新工藝方案下的退化模式。綜合以上客觀因素,能夠用于訓練智能運維模型的工業數據是稀缺的。歷史數據知識在新工藝方案下的可靠應用成為裝備智能運維的技術關鍵。
遷移學習正是將已存有的知識應用于不同但相似場景的人工智能方法,已經在圖像識別[13]、自然語言處理[14]、文本識別[15]等領域成功應用。基于歷史數據訓練的智能運維模型在新的運行環境下直接應用,必然會導致設備健康評估偏差,使用現場采集的少量數據樣本微調模型的部分參數,能夠提升準確率并縮短訓練數據準備周期[16]。配合適當的數據預處理方法,甚至可以將機器視覺領域的知識遷移應用于機械設備故障診斷,解決訓練數據不足的問題[17-18]。基于特征重構表示的深度遷移學習具備更強的跨領域能力,被應用于不同工藝方案間[19]、不同運行環境間[20]的知識遷移。這些案例表明,遷移學習能夠顯著提升智能運維模型對實際應用條件的適應性。但是,遷移學習在實際應用于制造產線時卻面臨計算資源難題。監測信號的維度和采樣頻率不斷提升,為了避免數據傳輸時延和丟包風險,設備運維系統往往采用邊緣計算的模式。但是邊緣設備的計算能力有限,難以支撐深度模型的遷移學習。云計算與邊緣計算各自的優勢與不足已經引起物聯網和計算服務領域的注意,云邊協同計算逐漸得到研究者的關注[21-23]。因此,開發一種新型的遷移學習實施范式,提升模型的進化速度,是遷移學習落實于裝備智能運維的關鍵。
為了提升智能運維模型對工藝調整的響應速度,文中提出了一種邊云協同的工藝知識遷移方法。首先,提出了一種并行多尺度深度卷積網絡(Parallel Multi-scale Convolutional Neural Network,PMsCNN),從云端歷史數據中提取跨工藝的裝備健康評估知識,建立云端設備運維基準模型;然后,提出了一種考慮樣本類別不均衡的改進型最大均值差異,驅動PMsCNN依據新工藝方案下的無標簽樣本開展遷移學習;最后,將進化后適應新工藝方案的PMsCNN部署應用到邊緣設備實施在線智能運維。
1 工藝知識遷移問題描述
在離散型智能制造系統中,由于裝備結構的復雜性,難以建立描述其退化過程的物理模型。深度學習通過端到端的訓練構建監測數據與設備健康狀態的隱式模型成為可行的替代方案。假設X={x1,x2,…,xm}為原始監測數據的樣本空間,服從邊緣概率分布P(x),對應的設備狀態標簽為{y1,y2,…,ym}。使用深度學習技術對設備健康監測問題進行建模,即

(1)

(2)
通過誤差反向傳播逐層優化模型參數,最終獲得準確的g(·)和f(·),實現設備健康狀態的可靠識別。
式(2)中的E[·]表示統計預測標簽與真實標簽的誤差期望。g(·)和f(·)中的結構參數即為歷史數據中提取出的隱含裝備運維知識。然而,離散型制造裝備需要執行不同的工藝方案,導致數據樣本的分布發生變化。如果使用既有的g(·)提取深度特征,則f(·)的判別準確率必然下降。在新的工藝方案下采集數據重新訓練深度模型需要冗長的準備時間,在小批量定制化的智能制造中更難以收集到充足的樣本。因此,設備運維知識的跨工藝遷移復用成為設備智能運維實踐應用的關鍵瓶頸。

(3)
其中,θg表示深度特征映射g(·)中的全部參數,d(·,·)為估計兩個樣本分布差異的度量函數。
2 基于邊云工藝協同遷移的設備智能運維
2.1 邊云協同工藝知識遷移方法
當新的工藝方案投入生產,既有的設備智能運維模型失效,需要開展DTL推進模型的適應性進化。為了兼顧設備智能運維對邊緣現場計算的需求和DTL對云端計算資源的需求,提出一種邊云協同遷移復用工藝知識的智能監控模型,框架如圖1所示。所提方法的核心功能載體是一個并行多尺度卷積神經網絡PMsCNN,在監督學習-知識遷移-服役應用的循環中不斷學習進化。
首先,PMsCNN利用云端充足的計算資源,在歷史數據的人工標簽的監督下開展學習,構建監測數據向設備健康狀態的深度映射,實現設備智能運維知識的抽象提取。歷史數據樣本來自多樣化的工藝方案,使得所構建的智能運維基準面對新的工藝方案具備一定的泛化能力,為遷移進化奠定基礎。然后,訓練好的PMsCNN部署應用到邊緣端。傳感網絡將實時采集的監測數據就近傳輸給邊緣計算設備,PMsCNN在設備現場開展分析推理,識別設備及其關鍵零部件的健康狀態,給出運維建議。同時,監測數據在邊緣端暫存打包后上傳云端服務器,并記錄PMsCNN識別的狀態標簽。再次,當新的工藝方案應用于生產,既有的PMsCNN失效而停止使用。監測數據樣本在邊緣端暫存,由設備操作人員設定標簽后上傳云端。PMsCNN在云端利用新工藝方案下有限的數據樣本和充足的歷史數據樣本開展工藝方案間的遷移學習。使用改進型最大均值差異驅動深度特征映射優化調整,使新工藝方案下的數據樣本與歷史數據樣本在深度空間對齊分布,實現PMsCNN的進化演進。最后,遷移學習完成后的PMsCNN重新下載到邊緣端設備開展運維服務,實時評估設備及其關鍵零部件的健康狀態和服役性能,給出運維建議。在服役的同時,可以利用邊緣數據庫暫存的數據樣本對PMsCNN中少量的參數進行微調優化,以適應監測對象零部件更換產生的差異。

圖1 面向裝備智能運維的邊云協同工藝知識遷移方法框架
2.2 并行多尺度卷積網絡PMsCNN
智能制造對加工精度的要求越來越高,數字化裝備對零部件的性能退化也越來越敏感。高采樣率地監測振動、噪聲、電流等信號的方案應用越來越廣泛,對監測模型的計算效率也提出更高的要求。為此,文中提出一種基于空洞卷積運算的并行多尺度卷積網絡PMsCNN,用以執行深度特征提取與模式識別任務。PMsCNN的架構如圖2所示,包括深度特征提取器(Deep Feature Extractor,DFE)和多層感知分類器(MuLtilayer Perceptual Classifier,MLPC)。DEF由4個串聯的卷積模塊組成,其中前兩個卷積模塊使用空洞卷積并聯組成的并行多尺度卷積模塊,用以融合淺層特征圖中的多尺度特征。特征提取器輸出的二維特征圖經攤平操作成為一維特征向量后輸入MLPC,MLPC由兩個全連接層組成。

圖2 并行多尺度卷積網絡
卷積運算已被證明是從圖像、語音等密集數據樣本中提取深度特征的有效工具。卷積核共享減少了模型參數,特征圖降采樣實現了不同尺寸的感受野。但是,降采樣會導致小尺度特征的丟失。另一方面,原始輸入中不同尺度的特征被分隔在不同的層中,阻礙了模型學習不同尺度特征之間的關聯。空洞算法[24]為不同尺度特征的同層融合提供了思路。向卷積核中插入空洞,在不增加計算量的前提下擴張了卷積核的感受野,從而提取更大尺度的特征。文獻[25-26]從神經網絡原理方面論證了稀疏卷積的可行性,Fisher成功將稀疏卷積應用于多尺度特征的融合[27]。結合振動、噪聲等高采樣率監測信號的特點,文中并行配置稀疏卷積層構建并行多尺度卷積模塊,如圖3所示。

圖3 并行多尺度卷積模塊
所使用的并行多尺度卷積模塊由4種不同膨脹率的稀疏卷積核并聯組成,提取特征圖中不同尺度的特征并融合。膨脹率改變了卷積核的感受野,為了使不同尺度的特征圖保持相同的尺寸,對輸入特征圖采取鏡像擴充策略,使輸出特征圖與輸入特征圖保持相同的尺寸。不同膨脹率的卷積核分別作為輸出特征圖的不同通道,然后使用1×1卷積核降維融合不同尺度的特征圖,并進行池化降采樣。1×1卷積和池化分別從不同的維度縮小特征圖的尺寸,減少計算,提升模型非線性擬合能力。
2.3 改進型分布差異損失函數

(4)

(5)

制造現場不允許裝備或零部件在性能退化的狀態下長期運行,采集到的數據樣本大部分處于健康或退化初期,不同種類的樣本數量嚴重不均衡。為此,提出一種改進型最大均值差異,借助PMsCNN在為新工藝方案預測的軟標簽進行修正,克服數據不均衡造成的干擾。

(6)
(7)
(8)
式(5)對所有的樣本進行無差別的統計,急劇磨損階段的樣本對全局的影響將被淡化,使得遷移進化后的PMsCNN不能準確地識別急劇退化的樣本。
由式(6)可知,提出的改進型MMD由兩項組成,第1項是經典的MMD,第2次項是使用目標域樣本預測標簽估計的同類樣本MMD的平均值。如式(8)所定義,類內MMD估計在式(5)的基礎上為各項添加了權重系數,是為兩個樣本各自歸屬于類別c的概率之積。只有當這兩個樣本同屬于類別c時,才會對hc(Z1,Z2)產生影響,因而∑hc(Z1,Z2)統計的是第c類樣本的分布差異。
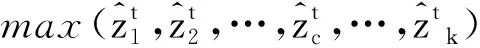
2.4 多任務的遷移學習策略

(9)

(10)

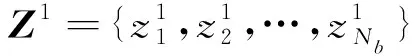
(11)
其中,α和β是調節模型學習過程的權重系數,可以隨著訓練迭代而調整。在訓練過程中,首先將源域樣本輸入模型,根據輸出結果和真實標簽計算損失L2;然后將目標域樣本輸入模型,使用式(10)估計偽標簽向量計算損失L3;再根據源域的深度特征向量和目標域的深度特征向量計算損失L1;最后根據式(11)計算綜合損失,進而使用誤差反向傳遞算法更新模型參數。
3 精密零部件的邊云協同監控實驗
為了評估所提出的邊云協同工藝知識遷移方法在工業應用中的先進性,以精密切削刀具的智能運維為案例開展實驗研究。在航空制造、燃氣輪機等領域,刀具磨損退化,崩刃破損難以預測,嚴重影響加工質量和生產連續性[30]。刀具智能運維成為切削加工產線降本提效的關鍵手段[31-32],但是刀具性能相關信號首要受工藝參數的影響,工藝知識遷移對于可靠的刀具智能運維尤為重要。
開展模具鋼快速銑削實驗,設置多種不同的工藝方案,使用振動傳感器采集主軸的振動信號。首先,對部分工藝方案下的數據樣本進行人工標注訓練PMsCNN基準模型;然后,采集新工藝方案下少量的數據樣本,在云端開展遷移學習;最后,使用遷移進化后的PMsCNN在新工藝方案下執行下刀具服役狀態在線評估,實現維護預警。
3.1 實驗設置
銑削實驗在一臺立式三軸加工中心上開展,采用某國產品牌的機夾式快速進給銑刀,4片刀片等角分布,側刃最大直徑為25 mm。工件材料為退火的Cr12模具鋼,銑削過程使用微量噴霧潤滑。使用加速度傳感器采集主軸振動信號,采樣頻率為25.6 kHz。每銑削完一個平面,就使用工具顯微鏡測量后刀面的磨損量。實驗現場如圖4所示。

圖4 Cr12模具鋼快速進給銑削刀具狀態監測實驗現場
使用不同的切削工藝參數開展實驗,如表1所示。每組工藝參數下試驗10組刀片,當其中一個刀片出現嚴重破損后停止實驗,更換刀片重新進行試驗。

表1 快速進給銑削工藝參數表
3.2 基于雙樹復小波的數據預處理
隨著刀具逐漸磨損,刀具與工件材料的交互作用發生變化,刀刃鈍化致使切入沖擊模糊化,后刀面與工件的摩擦加劇,產生更多的振動雜波。為了獲得完整的主軸振動信息,采用25.6 kHz的采樣頻率進行高頻率采樣,但是深度學習模型直接處理高采樣率的時序樣本會導致計算爆炸。為此,使用雙樹復小波包分解對數據進行預處理,預處理過程如下:
步驟1 對時間長度為1 s原始振動信號片段進行雙樹復小波包分解,分解層數設為4。重構獲得8個帶寬為1.6 kHz的子信號。
步驟2 對子信號進行希爾伯特包絡解調,得到瞬時包絡幅值曲線。
步驟3 對子信號的包絡幅值曲線進行快速傅里葉分解,得到子信號的包絡解調譜。
步驟4 取子信號包絡解調譜[1,256]Hz頻段的幅值數據,并聯組成單一時刻的初級刀具狀態數據。
步驟5 以當前時刻為基準向后追溯歷史,每隔1 min提取1個單一時刻初級刀具狀態數據。如此,從每5 min的原始監測數據中提取一個刀具狀態二維數據樣本,尺寸為40×256。
數字實驗在一臺配備Intel Core i7中央處理器的臺式計算機上開展。實驗表明,處理一個數據樣本的平均時耗約為1.3 s,基本滿足工業現場的時效性要求。二維樣本的第1個維度代表了不同的共振頻段和采樣時間,第2個維度為包絡解調譜的頻率坐標。相應地,PMsCNN只對第2個維度使用了稀疏卷積。
3.3 PMsCNN工藝知識遷移性能分析
將刀具的全壽命分為穩定磨損、急劇磨損和破損失效3個階段。以a、b、c為歷史工藝方案,以d為新工藝方案開展DTL試驗。圖5展示了新工藝方案樣本的分類精度和改進型MMD兩個觀測指標的變化過程,反映了模型的學習過程。
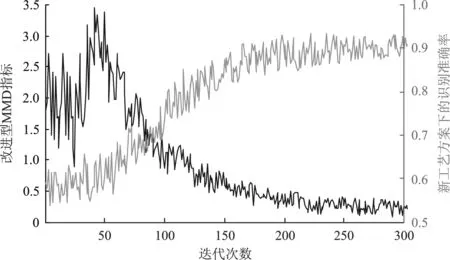
圖5 PMsCNN的深度遷移學習過程
在實驗中,d工藝方案下的真實銑刀磨損標簽不參與訓練,但是被用于在每次迭代后檢驗模型在新工藝方案下的識別準確率,如圖中淺灰色曲線所示,對應右側縱軸。圖中深黑曲線展示了改進型MMD指標的變化過程。值得注意的是,改進型MMD指標在訓練初始階段波動劇烈,并明顯上升。筆者分析,這是因為目標域偽標簽聚類問題的優化難度明顯低于樣本分布深度對齊問題。在訓練的初始階段,新工藝數據樣本在深度空間逐漸聚類,相比于初始的隨機分布狀態,新工藝數據與歷史數據的分布差異進一步擴大。而后,特征映射g(·)在MMD損失的約束下進化調整,使得新工藝數據與歷史數據的深度特征分布差異逐漸縮小,相應的新工藝數據樣本的識別準確率也開始上升,最終達到了約92%。

圖6 不同工藝方案組合下所提方法在新工藝方案下實現的識別準確率
文中設置了6個不同的任務,測試所提方法的有效性。每個任務的歷史數據不同,PMsCNN應用的新工藝方案也不同。文中所提算法在不同任務中實現的準確率如圖6所示。其中柱狀圖展示了6折交叉實驗的平均準確率,誤差棒展示了最佳成績和最差成績。作為參考,使用新工藝方案下的數據重新訓練PMsCNN。不論應用場景是單一工藝方案還是多個工藝方案的組合,PMsCNN都實現了90%以上的準確率。但是,既有模型直接應用于新工藝方案時精度嚴重下降。基于單一歷史數據訓練的模型退化更為嚴重,如c→d和b→d兩個任務。這表明用于訓練深度模型的數據應該盡量增廣。數據多樣性越高,學習到的知識的泛化性能越好。進一步對比這兩種組合,b→d的識別準確率更低一些,c和d的差異在于每齒進給量不同,b和d的主軸轉速以及徑向切削深度都不同。因而b和d的工藝差別更大,知識遷移的難度也更大。
表2列舉了所提工藝知識遷移方法在不同任務中實現的準確率提升,其中第1行是基于歷史數據訓練的PMsCNN直接應用于新工藝方案時實現的最佳準確率;第file:///C:/Users/Administrator/Desktop/%E6%95%B0%E6%8D%AE%E5%8A%A0%E5%B7%A5/XDKD202206/XDKD202206.ebook/images/2da9bb2c771d8ea61996cfe403bf09370.jpg2行是遷移學習后PMsCNN在新工藝方案下實現的最佳準確率。在a/b/c→d和b/c/d→a兩個任務中,源域數據更豐富,在新工藝方案下的識別準確率達到了約92%。在后4個任務中,新工藝方案與歷史工藝方案相差較大,PMsCNN直接應用的效果很差,所提出的工藝知識遷移方法使PMsCNN的準確率提升了20%以上。

表2 工藝知識遷移對PMsCNN識別準確率的提升 %
使用t-SNE算法對判別器的第1個全連接層輸出的深度特征進行降維,并使用三維散點圖進行可視化,如圖7所示。對比圖7(b)和圖7(a)可見,模型經過預訓練之后,在源域提取的深度特征聚類非常緊密,類簇之間距離充足,在真實標簽的監督下,可以實現很高的分類準確率。但是當預訓練模型直接應用于目標域,深度特征變得散亂,空間分布也出現明顯偏移,導致預訓練分類器性能下降。對比圖7(d)和圖7(c),經過多任務深度域自適應訓練后,模型在兩個域提取的深度特征的分布差異明顯縮小,基于源域訓練的分類器在目標域也就能實現更準確的分類。

圖7 工藝知識遷移深度特征可視化
3.4 與現有方法對比分析
為進一步驗證所提方法的優越性,這一節開展與現有遷移學習方法的對比研究。PENG等提出了一種基于生成對抗網絡的參數遷移學習(Parameter Transfer Learning,PTL)方法,在缺乏故障狀態數據樣本的條件下,提升設備狀態評估準確率[33]。XU等提出了一種遷移成分分析(Transfer Component Analysis,TCA)方法,遷移應用基于歷史數據的特征提取模型,在新工況下監測設備狀態[34]。WANG等提出了一種概率遷移因子分析(Probabilistic Transfer Factor Analysis,PTFA)方法,在多樣化的運行工況間尋找折中的特征空間[35]。CAO等提出了一種多任務學習網絡(Multi-Task Networks,MTN),遷移應用既有特征提取器,從未標注的新工況數據樣本中提取深度特征[36]。李聰波等推薦了一種領域自適應的稀疏編碼機(Domain-Adaptive Sparse AutoEncoder,DASAE),將基于實驗室數據訓練的模型遷移應用于實際生產,預警裝備故障[20]。

表3 不同知識遷移方法監測設備健康狀態的性能 %
表3列舉了各遷移學習方法在新工藝方案下識別銑刀磨損狀態的平均準確率。相比于既有模型直接應用,各種遷移學習方法都實現了明顯的提升。TCA和FTFA兩種基于遷移成分分析的方法性能較差,但是在a/b/c→d和b/c/d→a兩個歷史數據豐富的任務中也實現了85%以上的識別準確率。這兩種方法在本案例中實現的測試準確率低于文獻記錄,可能原因有二:一是相比于軸承和齒輪故障診斷,銑削過程產生的振動噪聲更為復雜,工藝參數對設備狀態的影響也更嚴重;二是這兩種方法并沒有針對數據不均衡提出相應策略,本案例中破損失效樣本顯著少于正常磨損樣本,遷移成分分析算法性能下降。PTL方法針對數據不均衡問題提出了一種鑒別器稀疏優化策略,在任務a/b/c→d中準確率達到了約90%。MTN應用經典MMD在深度特征空間縮小歷史數據和新工藝數據的分布差異,在難度最高的任務b→d中也實現了80%以上的準確率,體現了深度分布對齊這一方法的優越性。文中提出了一種改進型的MMD,面對不均衡樣本的正則化能力更強,更有效地驅動特征提取器優化調整,實現了最高的識別準確率。
綜合以上實驗結果分析,證明了工藝知識遷移對于設備狀態監測的重要性,驗證了文中所提方法利用新工藝條件下有限且不均衡的數據樣本優化調整深度模型,開展邊云協同工藝知識遷移的先進性。
4 結束語
針對多變的工藝方案使裝備智能運維模型應用性能退化的難題,文中提出了一種云邊協同的工藝知識遷移方法。搭建了一種PMsCNN深度模型,并提出多任務訓練方法,在無監督的條件下構建適應新工藝方案的深度特征提取器,縮小新數據樣本與歷史數據樣本在深度空間的分布差異,提升設備零部件服役性能的識別準確率。論文的主要結論如下:① 使用不同膨脹率的稀疏卷積運算,并行多尺度卷積神經網絡可以有效融合特征圖中不同尺度的特征,實現零部件運行狀態的可靠識別;② 所提出的改進型最大均值差異在不均衡的數據集上仍然有效,能夠驅動特征提取器的迭代優化,在深度特征空間消除不同工藝方案的樣本的分布差異;③ 基于歷史數據的監督學習維持了判別器的識別精度,偽標簽學習提升了新數據樣本的深度特征的聚類可分度;④ 實驗結果表明,所提出的云邊協同工藝知識遷移方法可以使PMsCNN在新工藝方案下的識別準確率提升20%以上。另外,歷史數據的工藝方案越多,識別準確率越高,所提方法應用于實際生產時仍應廣泛的積累數據。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
山東冶金(2019年6期)2020-01-06 07:45:54
世界農藥(2019年2期)2019-07-13 05:55:12
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
光學精密工程(2016年6期)2016-11-07 09:07:19
