基于近似最小一乘準則的Hammerstein-Wiener模型隨機梯度辨識
2022-02-15 10:07:02徐寶昌榮志超王雅欣董秀娟許立偉
化工自動化及儀表 2022年1期
關鍵詞:模型
徐寶昌 榮志超 王雅欣 董秀娟 許立偉
(1.中國石油大學(北京)信息科學與工程學院;2.國家管網集團北京管道有限公司)
日益復雜的化工過程中存在大量的非線性過程, 線性模型對工業過程的描述能力有限,采用非線性模型描述化工過程,其高質量的建模結果可直接提升化工生產過程的控制品質[1~5]。典型的非線性Hammerstein-Wiener(H-W)模型較適合表示化工過程中的大多數非線性過程。
H-W模型是一種塊連接模型,這種通過組合線性動態模塊和非線性靜態模塊的塊連接結構模型能夠有效地限制模型的靈活性[6~10]。 H-W模型已經成功應用到一些實際過程中,例如太陽能電池板[11]、聚合酶反應器[12]、地埋管換熱器[13]、燃料電池反應控制系統[14]及催化系統[15]等。 針對HW模型的辨識,Bai E W提出了兩階段辨識算法和盲辨識算法[16,17];Zhu Y C提出了松弛迭代法[18];Park H C等提出用4種特殊信號順序辨識H-W模型[19];李妍等提出了一種改進偏差補償辨識算法[20];Xu K K等基于極限學習機對H-W模型進行了辨識[21]。 這些算法針對相應的H-W模型都能成功進行參數辨識,但也都存在一定的問題[22~25],例如:盲辨識算法沒有顯式考慮廣泛存在于實際過程中的噪聲;兩階段辨識法和松弛迭代法的計算量都過大;特殊信號法在實際應用中很難使用人為設計的信號;極限學習機很大程度上依賴于初始值。 同時,目前關于H-W模型的辨識算法推導過程大多基于最小二乘準則,但是當隨機噪聲不滿足正態分布(系統存在尖峰噪聲或異常點)時,由于其目標函數中的平方項,數據存在很小的改變都會引起較大的波動,對辨識結果產生很大的影響[26,27]。
針對上述問題, 筆者提出一種形式簡單、易于計算并且更近似絕對值函數的新型確定性可導函數,構造近似最小一乘準則目標函數,在此基礎上推導基于近似最小一乘準則的隨機梯度辨識(Stochastic Gradient Algorithm Based on Approximate Least Absolute Deviation Criterion,ALADSG)算法。仿真實驗表明,ALADSG算法可以有效克服尖峰噪聲對辨識結果的影響,其辨識精度高、收斂速度快并且具有良好的魯棒性。
1 H-W模型描述
H-W模型的結構如圖1所示,其中,g[·]和h[·]分別為系統的輸入和輸出非線性模塊,設輸出非線性模塊h[·]可逆;G(z)是系統的動態線性模塊;u(k)是系統的輸入信號;x(k)是輸入非線性模塊的輸出,也是線性模塊的輸入;w(k)是線性模塊的輸出,也是輸出非線性模塊的輸入;r(k)是系統的真實輸出,與噪聲項v(k)疊加后得到系統的測量輸出y(k)。

圖1 H-W模型結構框圖
H-W模型輸出可以改寫為:

模型參數為:
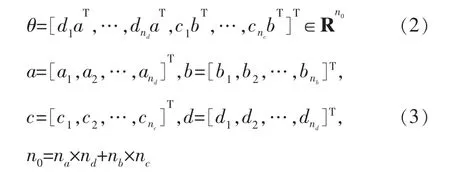
觀測數據矩陣為:

其中,φ(k)是觀測數據矩陣;θ是待辨識參數矩陣;a、b、c、d是待辨識參數;n是階次;ψ(k)是輸出模塊觀測矩陣;φ(k)是輸入模塊觀測矩陣;gs和hl分別代表輸入模塊、輸出模塊的多項式。
可以觀察到在待辨識參數矩陣θ中含有組合參數,為了便于參數分離,令c1和d1已知,采用平均值法進行參數ci和di的分離[28]。
2 ALADSG算法
文獻[29]提出了如下的對數函數近似絕對值函數:

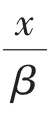
采用另一種絕對值函數的光滑近似函數[30]:

其中,μ是可控參數,當μ比較小時,可有效地等價為絕對值函數,本研究中取μ=0.01。
將f1(x)和f2(x)同時減去絕對值函數|x|,x取不同區間時的相對誤差見表1。

表1 x取不同區間時的相對誤差
由表1可得,函數f2(x)更接近絕對值函數,并且形式簡單、計算量更小。 因此,筆者基于函數f2(x)構造近似最小一乘準則。
取目標函數:

根據隨機梯度搜索原理可得:

其中,收斂因子μk>0。
將式(12)代入式(13)可得:

將式(14)代入式(11)可得:

其中,e(k)代表新息。
令:


根據式(17)、(18)極小化h(μk)可得最優解:

將μk代入式(14)可得:

令:


考慮對過去數據的遺忘性,為了加快收斂速度同時提高算法精度,引入遺忘因子λ,則有:

式(21)、(23)構成帶有遺忘因子的基于近似最小一乘準則的隨機梯度辨識算法, 與選取式(9)作為目標函數得到的算法進行運算速度的對比,均進行30萬次迭代,得到的結果見表2。

表2 兩種算法的運算時間對比ms
由表2可得,基于式(10)推導的隨機梯度算法相較于基于式(9)推導的隨機梯度算法計算量更少,速度提升約5.7%。
3 仿真實驗
Park H C等研究的pH中和系統[19]如圖2所示,V代表容積,其中濃度為0.02 mol/L 的醋酸(CH3COOH) 作為輸入流在連續攪拌釜反應器中通過濃度為0.5 mol/L的氫氧化鈉(NaOH)滴定流進行滴定。 滴定流分為vm和v,vm為恒定的,v由計算機信號u調節。

圖2 pH中和系統
該pH中和過程可近似建模為H-W模型,其中x(k)和w(k)分別表示為[19]:

線性模塊傳遞函數為:

為進行參數分離,令參數c1和d1已知。

3.1 不同遺忘因子的ALADSG算法
在模型辨識過程中加入尖峰噪聲概率為5%、幅值為白噪聲序列5倍的尖峰序列噪聲, 不同遺忘因子的H-W模型的參數辨識結果見表3,相對誤差曲線如圖3所示。

圖3 不同λ的相對誤差曲線

表3 不同λ取值的H-W模型參數辨識結果
根據表3和圖3可以得到如下結論:當λ=1時,即不引入遺忘因子,算法的辨識結果較差,無法估計出H-W模型的參數。當0.7<λ<0.9時,隨著遺忘因子λ的減小,δ下降的速度更快,同時辨識相對誤差更接近于0,即辨識的速度更快,精度也更高。 當λ≤0.5時,相對誤差曲線開始波動,最終辨識結果的精度也已開始下降。 所以不能一味減小λ來尋求更快的辨識速度,而要兼顧精度與穩定性。
3.2 ALADSG算法與LSSG算法對比
由3.1節可知,當λ=0.8時,辨識可以在保證穩定性的前提下收斂,較為準確地估計出H-W模型參數,故本節固定遺忘因子λ=0.8。
為驗證ALADSG算法的辨識性能, 分別加入不同概率和幅值的尖峰噪聲,同時加入基于最小二乘準則的隨機梯度算法 (Stochastic Gradient Algorithm Based on Least Square Criterion,LSSG)作為對比進行實驗。 令ε表示尖峰噪聲概率,A表示尖峰噪聲幅值相對于白噪聲幅值的倍數。 在不加入尖峰噪聲,加入ε=5%、A=5的尖峰噪聲,加入ε=10%、A=10的尖峰噪聲,3種情況下得到的仿真結果見表4,對應的相對誤差曲線如圖4所示。

圖4 加入不同尖峰噪聲時的相對誤差曲線

表4 不同尖峰噪聲時的仿真結果
從表4和圖4可知,當辨識過程中僅存在白噪聲時, 兩種算法都能準確估計出模型參數,但LSSG算法的速度更快,精度更高。因此,當干擾噪聲服從正態分布時,LSSG算法性能優于ALADSG算法,符合以往的研究結論。 在辨識過程中加入尖峰序列后,LSSG算法受尖峰噪聲影響較大,辨識精度明顯下降,當尖峰噪聲概率ε和幅值A較大時已不能精確辨識; 而ALADSG算法受尖峰噪聲影響較小,仍然可以保持較高的辨識精度。 說明在存在尖峰噪聲的情況下,ALADSG算法性能優于LSSG算法。
4 結束語
H-W模型能夠有效擬合化工過程中的大多數非線性過程,且能限制模型的靈活性,避免過擬合的問題。 但當模型辨識過程中存在尖峰噪聲時,傳統辨識方法不能進行有效辨識。 筆者針對該問題提出了ALADSG算法。 采用一種確定性可導函數近似最小一乘準則,解決了最小一乘準則函數不可求導的問題,降低了計算量。 仿真結果表明, 相較于LSSG算法,ALADSG算法能夠有效克服尖峰噪聲對H-W模型辨識結果的影響,提高了辨識結果的精度并具有良好的魯棒性,降低了辨識算法對測量數據質量的要求。 同時,選擇合適的遺忘因子可以增加辨識結果的精度、加快收斂速度。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
