一種混合采樣與膨脹卷積相結合的入侵檢測模型設計
2022-02-15 10:07:08劉興元繆祥華
化工自動化及儀表 2022年1期
劉興元 繆祥華
(昆明理工大學a.信息工程與自動化學院;b.云南省計算機技術應用重點實驗室)
隨著網絡范圍和規模的不斷擴大,網絡入侵的威脅逐漸加重。 傳統的網絡入侵檢測技術已經不能滿足日益增長的網絡安全保障需求,在這種情況下,具有主動防御功能的入侵檢測系統(Intrusion Detection System,IDS)應運而生。 IDS可以通過分析網絡中的實時數據包來判斷是否發生了入侵行為,并以此發出警報。
目前入侵檢測存在幾個問題。 首先,入侵檢測大部分采用KDD CUP 99數據集或20年前收集的NSL-KDD數據集進行測試。 隨著網絡技術的不斷發展,攻擊手段和類型也隨之變化,使用這些過時的流量數據不能完整地反映網絡入侵檢測在現代網絡中的實際表現。 其次,這些系統大部分采用數據集的一部分進行實驗,沒有考慮到該系統在現實大數據環境下的性能。 最后,沒有有效地解決類不平衡問題對分類效果的影響,這使得少數類別無法檢測或者檢測精度較低,顯著地降低了檢測準確率。
為了解決上述問題,筆者提出了一種基于混合采樣與膨脹卷積相結合的入侵檢測模型(SSGDCNN),該模型利用混合采樣(SSG)技術有效地解決數據不平衡問題,并與特征提取能力強的膨脹卷積相結合, 在UNSW-NB15數據集上對該模型進行多分類實驗,與傳統的機器學習方法進行了對比,證實筆者所提模型具有較高的準確率。
1 相關研究
入侵檢測技術是計算機網絡安全的重要組成部分。 在入侵檢測領域,已經有研究人員使用了許多機器學習方法, 如支持向量機(Support Vector Machine,SVM)[1,2]、隨機森林[3,4]及決策樹[5]等。然而隨著網絡規模和范圍的不斷擴大,網絡環境日益復雜, 網絡攻擊類別變得多樣化,傳統的機器學習技術等淺層學習已經不適合大規模網絡入侵檢測系統(Network Intrusion Detection System,NIDS)的要求。近年來,深度學習[6]以其全自動特征工程的優勢成為研究的熱點。 卷積神經網絡(CNN)[7~9]、多層感知器(MLP)[10]、遞歸神經網絡(RNN)[11]、深度神經網絡(DNN)[12]和深度置信網絡(DBN)[13]也逐漸在NIDS 中廣泛使用。 研究表明, 這些基于深度學習的NIDS 在處理大數據時可以獲得更好的性能。
在網絡流量特征中存在不平衡問題, 以致于某些類別的檢測精度偏低,影響分類算法的性能,降低了檢測準確率,特別是對于少數類,使檢測不具有代表性,所以Zhang X等提出了一種基于卷積神經網絡的入侵檢測模型[14]。 在CNN訓練之前,采用過采樣和欠采樣相結合的(SMOTE-ENN)算法來平衡網絡流量。 并且使用NSL-KDD數據集對模型進行評估。結果顯示,該模型具有很高的檢測準確率,尤其對U2R、R2L 等少數攻擊流量特征效果顯著。Jiang K Y 等提出了一種混合采樣和深度分層網絡相結合的網絡入侵檢測算法[15]。 首先,采用單邊選擇(OSS) 來減少大多數類別的噪聲樣本,然后利用合成少數類過采樣技術(Synthetic Minority Over-sampling Technique,SMOTE)來提高噪聲樣本的小波振幅從而建立一個平衡的數據集,使模型充分學習少數樣本的特征,大幅減少模型的訓練時間。 其次,采用卷積神經網絡提取空間特征,利用雙向長短期記憶(BiLSTM)提取時間特征在NSL-KDD 和UNSW-NB15 數據集上進行了實驗驗證,證明了該模型的可行性。 針對數據不平衡的問題,Zhang J 等提出了一種將ReliefF 算法和Borderline-SMOTE 過采樣技術相結合的新型兩級網絡入侵檢測模型[16],解決入侵檢測數據集中存在的數據分布不平衡的問題,并將3 種不同類型的基礎分類器KNN、C4.5 和NB成對組合,明顯提高了少數類別的檢測精度。
筆者提出了一種新的入侵檢測模型SSGDCNN,能有效解決數據不平衡問題,提高少數類別的檢測準確率和入侵檢測性能。
2 膨脹卷積入侵檢測模型框架
2.1 模型框架
筆者提出的SSG-DCNN網絡架構如圖1所示,該架構由4個主要模塊組成:數據預處理模塊、混合采樣模塊、 模型訓練模塊以及模型測試模塊。數據預處理模塊負責對原始數據進行數值化、特征縮減、數據標準化及特征選擇等操作,使數據更有利于模型的預測。 混合采樣模塊主要對訓練數據集進行混合采樣,以減輕原始數據集中的不平衡對實驗結果造成的偏差。

圖1 SSG-DCNN網絡架構
筆者提出了一種新的方法SSG, 它結合了過采樣和欠采樣,以實現一個完全平衡的訓練數據集。 SSG算法使用SVMSMOTE識別少數類, 基于GMM的欠采樣聚類識別多數類。隨之將混合采樣后的訓練集導入一維膨脹卷積入侵檢測模型,并將該模型訓練至收斂,最后用測試集來測試所提出模型的性能。
2.2 混合采樣
入侵檢測數據集中異常樣本的數量本來就很少,例如,UNSW-NB15數據集中的“蠕蟲”只有174個樣本,占整個數據集的0.006 85%,因此,單獨使用欠采樣是不合適的。 但僅使用過采樣會引入過多的冗余數據,并增加空間和時間成本。 筆者提出的SSG結合了SVMSMOTE和基于GMM的欠采樣聚類,將所有類別的樣本重新采樣到統一數量。
通過SVMSMOTE對數量小于N的樣本數進行過采樣,通過“合成”少數類樣本來增加少數類樣本的數量。 SVMSMOTE不是簡單地復制少數樣本,而是在彼此接近的少數樣本之間使用線性插值生成新的少數樣本, 以減少分類的不平衡,從而避免在建立分類模型的過程中出現過擬合。 對于樣本數量多于N的樣本, 運用基于GMM的聚類方法對其進行欠采樣,GMM是一個參數化的概率分布模型, 代表多個高斯分布函數的線性組合。通過SSG將所有類別的樣本重新采樣到同樣的數量N,N為:

其中,S為訓練集中樣本的總數,C是類的數量。
為保證測試模型的真實效果,本實驗只在訓練集T={Ti,i=1,2,…,K}上進行測試。 對于訓練集中的每一類數據Ti, 如果在Ti里的樣本數小于N,用SVMSMOTE過采樣Ti來平衡數據至N;如果在Ti里的樣本數大于N, 使用GMM欠采樣平衡數據數量到N。 然后隨機選擇每個集群的樣本N/C,并將它們合并到Ti′,這時,樣本在Ti′的數量平衡至N,以便獲得一個平衡的訓練集T′,SSG不僅避免了單獨使用過采樣帶來的過多時間和空間成本,還防止了隨機欠采樣丟失重要樣本,能顯著提高少數類別的檢出率。 SSG算法如下:

為了證明SSG混合采樣算法的有效性,用UNSW-NB15訓練集進行本次實驗。 表1列出了使用SSG混合采樣算法前、 后各數據類別所占的比例。 在使用混合采樣前, 其中Normal 占據了87.35%,其他許多類別不足1.00%,這將使得模型檢測精度不高,而采用SSG混合采樣算法之后,各類別的比例均處于10%, 使得每個類別都能平等地被模型檢測,有效解決了少數類別攻擊類型檢測不準確的問題。

表1 UNSW-NB15訓練集使用SSG算法前、后各數據類別所占比例%
2.3 膨脹卷積神經網絡
在傳統的卷積神經網絡中,會使用池化層來保持特征不變性并避免過度擬合,但是會大幅降低空間分辨率,丟失特征圖的空間信息。 當加深卷積神經網絡的層時, 網絡需要更多的參數,會導致更多的計算資源消耗。 Yu F和Koltun V提出的膨脹卷積[17]可以很好地解決這一問題。 膨脹卷積是一種卷積算子,它使用不同的膨脹因子在不同范圍使用相同的濾波器。 膨脹卷積能夠更有效地擴展感受野。 與傳統卷積相反,膨脹卷積的內核中存在孔,孔的大小為膨脹率。 一維普通卷積的公式如下:
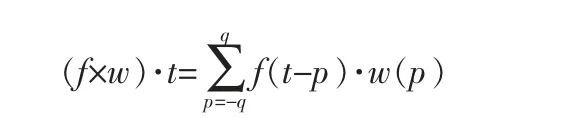
式中 f——輸入;
p——卷積的下限值;
q——卷積的上限值;
t——卷積核的大小;
w——卷積核。
如果是膨脹卷積,則一維膨脹卷積的公式如下:

其中l是膨脹率。
對輸入數據應用膨脹卷積時,與傳統卷積相比,感受野將得到擴展,但不會降低分辨率,能夠在不增加參數數量或計算量的情況下增大感受野。
利用膨脹卷積既可以擴大卷積核的感受野,也能減少模型的參數量。 在深度卷積網絡結構設計中,很多研究者采用了深度卷積神經網絡VGG中的3×3小卷積結構, 通過堆疊3個3×3卷積核來代替7×7卷積核,堆疊2個3×3的卷積核來代替5×5卷積核,在保證相同感受野的條件下,采用了多層非線性層增加網絡深度以確保學習到更復雜的特征模式, 進而提升深度卷積神經網絡的效果。 同時通過堆疊小卷積核替換大卷積核也可以減少深度模型的參數量。
疊加的膨脹卷積的膨脹率(Dilated Rate,DR)不能有大于1的公約數,否則就會產生柵格效應,文中的膨脹率設計成鋸齒狀結構 (如[1,2,5])。為了擴大卷積核的感受野, 筆者一次堆疊了DR=1、DR=2、DR=5的膨脹卷積來替換普通卷積,如圖2所示, 將膨脹卷積的感受野擴大到了19×19,使得模型能夠獲取更廣泛的數據。

圖2 膨脹卷積層
3 實驗分析
3.1 UNSW-NB15數據集描述
UNSW-NB15[18]數據集由澳大利亞網絡安全中心(ACCS)的安全研究小組收集和分發。該數據集總共包含254萬個網絡流量樣本,涉及9個攻擊類別。 每個樣本有49個特征,包含流量和基于數據包的特征,其中兩個是類別標簽特征。 這些特征進一步分為4個不同的類別,即:內容、基本、流程和時間。 最初,數據集被標記為兩個不同的流量標簽(攻擊和正常),隨后根據攻擊類型將攻擊類別進一步分為9種不同的類別類型。 該數據集具有嚴重的類不平衡性,其中正常流量占整個數據集的87.35%, 所有攻擊流量僅占數據集的12.65%。筆者在實驗中使用UNSW-NB15數據集的所有樣本, 并以7∶1∶2的比例劃分數據集進行訓練、驗證和測試,各類別的數據分布見表2。

表2 UNSW-NB15數據集每個類別的樣本數

(續表2)
3.2 數據預處理
數據預處理主要包含4個步驟:數據數值化、特征縮減、數據標準化和特征選擇(DAE)。
3.2.1 數據數值化
對數據的數值化操作采用獨熱編碼(onehot)算法,將UNSW-NB15數據集中原本的47維特征映射為208維。 采用獨熱編碼的好處在于:可以解決分類器不好處理屬性數據的問題:在一定程度上起到了擴充特征的作用。
3.2.2 特征縮減
進行數據數值化處理操作之后,刪除數據集中冗余和無意義的特征,刪除這些特征對于本研究的實驗結果沒有任何影響,卻可以有效地縮減模型的訓練時間。根據文獻[10]在UNSW-NB15數據集中刪除了6個特征, 分別是“srcip”、“sport”、“dsport”、“dstip”、“ltime”和“stime”,因此UNSWNB15數據集的真實維數從原來的208維減少到了現在的202維。
3.2.3 數據標準化
在數據集中,不同類別的數據值大小明顯不同,最大值的范圍變化很大。 為了便于算術處理和消除尺寸,采用數據標準化方法,在[0,1]區間內均勻且線性地映射每個特征的范圍。 用以下公式將數值標準化到[0,1]范圍內:

其中,max為樣本數據的最大值,min為樣本數據的最小值,x為原始數據,x*為標準化后的數據。
3.2.4 特征選擇
最后一步是執行特征選擇。對于UNSW-NB15數據集,筆者根據文獻[10]堆疊了一個帶去噪的自動編碼器(DAE),從剩余的202個要素中選擇權重最高的12個要素。
3.3 評價指標
筆者選取準確率 (Accuracy,ACC)、 精確率(Precision)、召回率(Recall)和F1分數作為評估模型性能的關鍵指標,計算式如下:

其中,TP表示攻擊類型被正確分類的個數;TN表示正常類型被正確分類的個數;FP表示正常類型被錯誤分類(誤報)的個數;FN表示攻擊類型被錯誤分類(漏報)的個數。
3.4 超參數選擇
筆者通過實驗確定了最優DCNN模型, 卷積層設置為3層, 每個卷積層的膨脹率分別為2、4、8,每層的卷積核分別為32、64、128。 使用了Adam優化算法,學習率設置為0.008,具體參數見表3。

表3 模型參數設置
4 實驗結果
筆者采用Python作為編程語言, 使用Tensor-Flow 1.14.0作為深度學習框架, 實現了所提出的入侵檢測系統模型,并在裝有Win10 64位操作系統的個人電腦上對UNSW-NB15數據集進行了實驗,以評估其檢測現代攻擊的有效性。 具體的系統環境參數如下:
操作系統 Win10
框架 Keras2.2.4
CPU i7-10750H
GPU RTX2060
內存 32GB
編程語言 Python 3.6
表4顯示SSG-DCNN模型在UNSW-NB15數據集的多分類結果, 結果表明通過混合采樣之后,各個小類別的召回率明顯提高。 隨之比較原始數據和4種數據平衡算法的準確率和F1分數, 結果顯示筆者提出的混合采樣方法均優于其他方法。

表4 UNSW-NB15數據集多分類中各類別召回率%
為了證明SSG算法和膨脹卷積模型的有效性, 將其與現在比較流行的4種混合采樣不平衡處理技術和2種現有的機器模型進行比較。 為了使得模型更好地擬合數據,本次實驗批處理的大小設置為512,循環迭代設置為200次,實驗結果詳見表5。

表5 3種模型在UNSW-NB15數據集進行多分類的性能比較%

(續表5)
由表5可知,不管采用什么模型,筆者所提出的混合采樣算法,均優于其他4種數據平衡算法。該算法應用在DNN模型時, 準確率、 精度、F1分數、 召回率分別達到了97.01%、97.96%、97.40%、97.01%;該算法應用在RF模型上時,準確率、精確率、F1分數、 召回率分別達到了96.58%、98.18%、97.14%、96.58%;當運用在DCNN模型上時,準確率、精確率、F1分數、召回率分別達到了97.04%、98.28%、97.43%、97.04%, 優于應用在RF模型和DNN模型上,獲得了最佳的整體性能。
為了展示筆者所提模型的優越性,與其他文獻所提出的4種不同模型進行了對比, 實驗結果見表6。

表6 UNSW-NB15數據集在不同模型下的準確率和F1分數%
通過表6可以發現,筆者所提SSG-DCNN模型在UNSW-NB15數據集進行訓練和測試時取得了很好的效果,相對于CLAIRE模型[19]而言,在檢測準確率上提升了3.52%, 在F1 分數上提升了2.03%;較CNN-1D模型[20],在檢測準確率提升了7.24%,在F1分數上提升了6.13%;較MDPCA-DBN模型[21],在準確率上提升了6.86%;在F1分數上提升了5.94%;對比ICVAE-DNN模型[22],在準確率上提升了7.96%,在F1分數上提升了6.82%。
5 結束語
針對現在入侵檢測數據集不平衡和檢測準確率低的問題,提出了一種混合采樣與膨脹卷積相結合的入侵檢測模型SSG-DCNN, 在UNSWNB15數據集上進行多分類實驗,首先使用混合采樣技術SSG平衡數據, 確定了DCNN的最佳模型。將SSG與4種平衡算法在3種模型上進行比較,證明了SSG-DCNN的優越性, 并和其他文獻所提模型進行了比較, 筆者所提出的SSG-DCNN模型都取得了很好的性能。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
