基于改進BERT的景點評論情感分析
2022-02-24 07:07:52劉宇澤葉青劉建平
傳感器世界 2022年12期
劉宇澤 葉青 劉建平
長沙理工大學電氣與信息工程學院,長沙 410114
0 前言
隨著社會經濟和旅游業的發展,游客選擇旅游景點時依賴于該景點的評論信息。評價信息既可以分析消費者的旅游感受,又可以影響其他潛在游客的景點選擇,而如何有效地分析景點評論的情感成為了一項非常有意義的任務。
情感分析是指通過分析用戶形容某件事件的文本而確定用戶對該事情的看法和評估。基于支持向量機、樸素貝葉斯、最大熵、K鄰近等傳統的機器學習方法都可以用來解決情感分析問題[1]。PANG B等人[2]采用樸素貝葉斯分類的方法來計算文本的情感極性。LI D等人[3]研究了長短期記憶網絡在文本情感分類任務中的效果。PENGHUA Z等人[4]通過結合BiGRU和注意力機制并將其應用于情感分類任務,獲得了良好的分類結果。與以往的神經網絡比較,預訓練模型在許多 NLP任務中都有較好的作用。ELMo[5]、Transformer[6]、基于轉換器的雙向編碼表征BERT[7]等豐富的預訓練模型接踵舉出。堪志群等人[8]將BERT與BiLSTM結合,BERT模型采用了一種特殊的調整方案,可以在學習過程中不斷地學習領域的知識,并通過神經網絡的反饋對原有的模型進行參數的更正,在微博數據的觀點分析方面獲得了不錯的成效。胡任遠等人[9]提出了多層次語義協同模型,在不同數據集上驗證了該模型的優越性。上述文獻對語篇序列情感極性的研究表明,BERT模型難以對文本情感進行多角度的分析學習,在語句級別的文本情感分類中,BERT自身就是多層神經網絡結構,與傳統神經網絡結合易出現退化的問題。
因此,本文提出一種將連結殘差網絡與BERT模型相結合的模型,該模型由不同維度的卷積神經網絡通過殘差連接組成,可以使每一維的語義特點都包括原始文本信息,并且特征信息互不相同,再結合雙向長短期記憶網絡,從而使模型學習更全面的語義信息。
1 相關工作
1.1 BERT預訓練網絡
1.1.1 BERT模型
傳統的產生詞向量工具(如Word2vec)都是建立在淺層網絡模型基礎上,而 BERT則是將模型整合到下游工作中,并能根據具體的任務進行改動。BERT是一種基于雙向轉換模式的雙向轉換編碼器,它的運算主要選取代碼模塊,如圖1所示。使用MLM遮蔽語言模型進行建模,使其輸出序列能夠更完全地了解各個方面的文字信息,利于為后續的更改選取更好的參數。

1.1.2 Transformer
Transformer模型的編碼部分由多頭注意力機制(Multi-Head Attention)和一個完全連接的前向神經網絡組成,兩個模塊都對數據進行了規范化處理。為了處理神經網絡的退化問題,模型中各子模塊都加入殘差相接。基于Seq2Seq結構的 Transformer模型,它變化了傳統的Encoder-Decoder結構,只使用注意力機制和完全連通的神經網絡,利用位置編碼和單詞內嵌,學習了文本序列之間的位置關系,并利用多頭自注意力機制,探索文字間的語義,如圖2所示。
虛線為殘差連接,能使前面信息準確傳送到后面一層,其中注意力的計算如式(1)和式(2)所示。
其中,注意力層的輸入為Q,K,V,通過隨機初始化來取值,歸一化函數中用來調整模型大小。
其中,W0作用使模型學習更多的特征信息,將每個head學習到的注意力矩陣進行拼接。
1.2 長短期記憶網絡
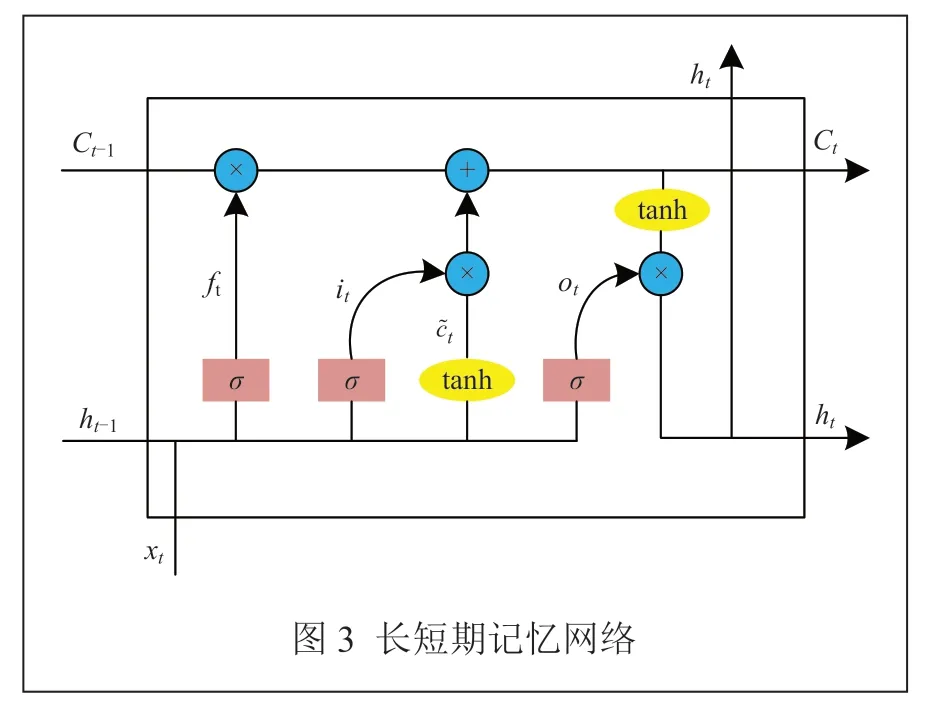
1997年,HOCHREITER S等人[10]提出了一個新型網絡——LSTM。該網絡是針對RNN算法的一種改進,它可以有效地克服RNN在訓練時的梯度消失現象,通過采取單元狀態和門控機制,將上一階段的數據存儲,并將接收到的數據進行下一步傳遞,如圖3所示。
LSTM的計算如下式所示:
其中,i、o、f分別為輸入門、輸出門和遺忘門;c記載細胞狀態的改變;t時網絡接收到當前輸入xt和上一時間點信息向量ht-1作為3個門的輸入;it、ot、ft分別為輸入門、輸出門、遺忘門在t時間點計算得出。σ為非線性激活函數sigmoid();tanh為非線性激活函數tanh();圖中Wf、Wi、Wo、Wc和Uf、Ui、Uo、Uc分別為遺忘門、輸入門、輸出門和記憶細胞所對應的權重矩陣;bf、bi、bo、bc是偏置量,通過實驗得到。
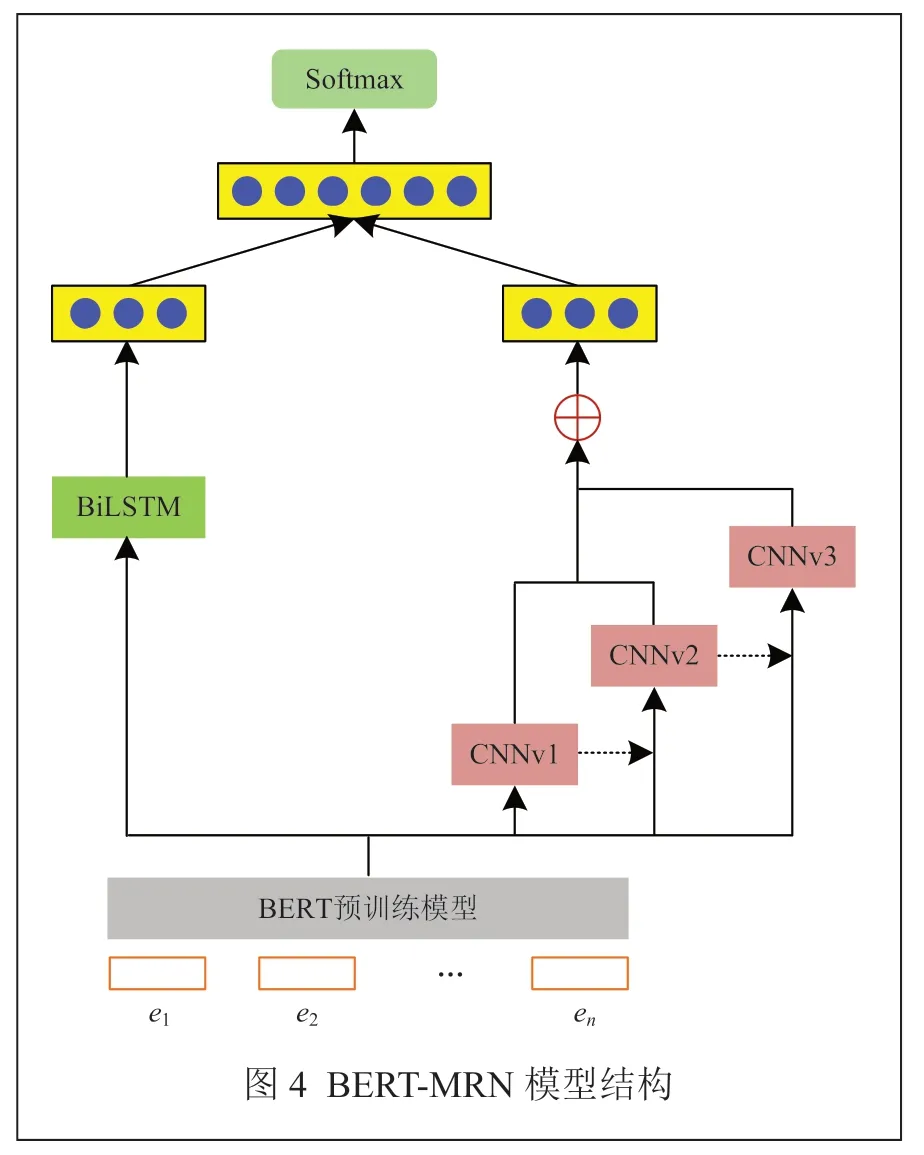
2 改進的BERT模型(BERT-MRN)
本文在 BERT基礎上搭建了一個多頭殘差網絡模型,如圖4所示。為了克服BERT模型在情緒分析方面的不足,利用 BiLSTM來獲取上下文關系,該模型能從多個角度學習序列中的情緒特點,并且阻止深度神經網絡出現信息丟失的情況,最后通過特征融合,克服了由于網絡深度造成的梯度消失、信息丟失等問題。本文所確立的BERT-MRN模型能夠區別情感分類問題中的序列關系和各種程度的情感,從而更適宜于對文本情感分類。
2.1 BERT-MRN模型結構
該模型利用多個卷積核的一維卷積神經網絡CNN構成了多頭殘差結構的語義學習器,能夠選擇合適數量的殘差結構,能夠更好地學習文本句子的情感特征,使用殘差連接避免了序列結構中的深度神經網絡的梯度消失。
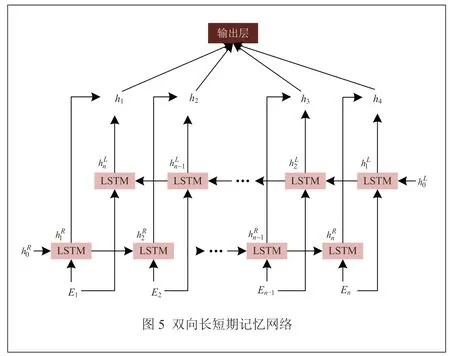
雙向長短期記憶網絡BiLSTM能夠兼顧全文從上至下的語境,把所收到的信號傳遞給兩個反向時序的 LSTM網絡,獲得上下文的信息,再使用向量拼接獲得最后序列的隱含表達。在每個迭代進程中,對隱藏層中的局部神經元進行隨機削減,從而得到一定的正則化效應,其組成如圖5所示。將E1,E2,…,En作為輸入,通過BiLSTM的正向和反向網絡得到hL和hR,如公式(9)和公式(10)所示:
將hL和hR進行拼接后計算出hi(i=1, 2, …,n)。
該模型能夠從多個層面上對情緒態度進行研究,因此,本模型能夠應用于各種語料庫的情緒分類。
2.2 模型訓練
該模型經過特征融合層的輸出,使用sigmoid激活函數得出需要進行情感分類的情感極性,如式(11)所示:
其中,W為權重矩陣;b為偏置量;x為拼接后的輸出數據;為 網絡模型的預估輸出。本文選取了反向傳播來訓練網絡模型,情感分類的函數選擇交叉熵函數,如式(12)所示,y為實際結果。
3 實驗結果與分析
3.1 實驗數據
本文選擇旅行網站作為評論數據的出處,通過爬蟲爬取旅行網站的400個景點評論信息,在數據庫中整理數據集,首先對數據集進行預處理,削減評論信息中的無用評論和特有的、無意義的符號,經過預處理后得到4,000條評論,其中正向評論2,600條,負向評論1,400條。
3.2 輸入層
開始先刪除中文文字數據中的停用詞和無意義的符號,然后選取情感分析方面最常見的詞來制定詞典,生成相應的序列輸入。BERT模型中的輸入是詞向量、段向量、位置向量加權求和的矩陣。位置向量是指在不同位置出現的詞語所具備的語義信息(例如“風景很好”、“很好風景”),所以BERT模型會將其各自加入到差別的向量中,如圖6所示。
3.3 模型參數設置
實驗選擇控制變量法,選擇不同優化器優化函數,使用專門針對中文的預訓練BERT模型。通過多次比較實驗,發現取表1參數時,BERTMRN分類能力最好。
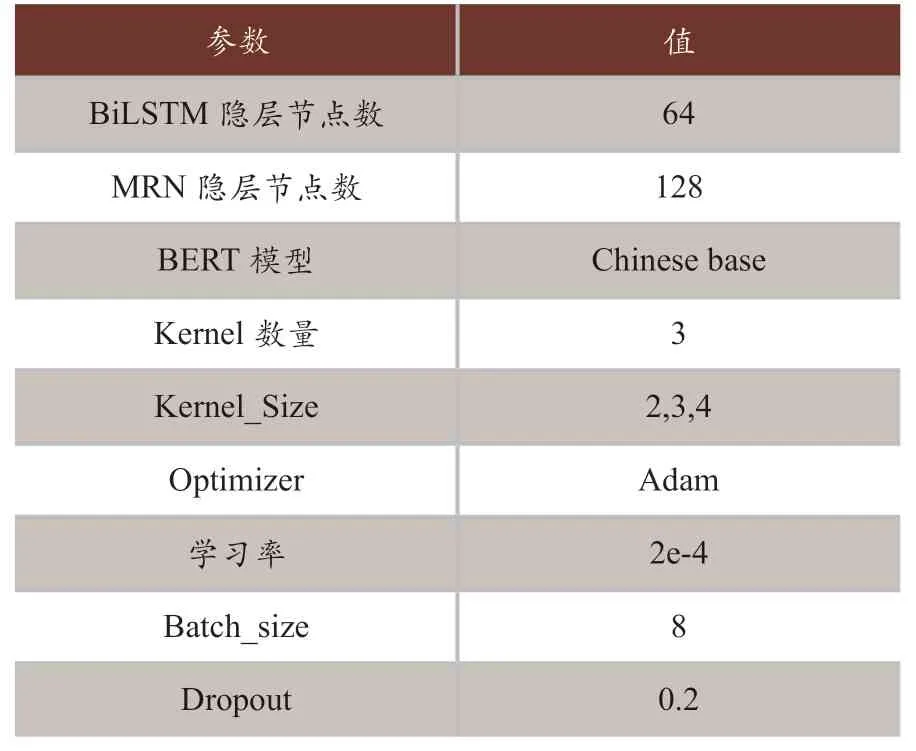
表1 參數設置
3.4 評價標準
本文采用的評估指標包括:精確率、召回率、F1分數。其中精確率是表示預測為正的樣本中實際的正樣本的數量所占比例,召回率是實際為正的樣本被判斷為正樣本的比例。文中將綜合度量指數F1作為評估模型的一個評估準則,如下方公式(13)~公式(15)所示:
其中,TP(True Positive)表示正樣本判定為正的個數;FP(False Positive)表示負樣本判定為正的個數;FN(False Negative)表示正樣本判定為負的個數。

3.5 實驗結果與分析
通過對預處理后的景點評論進行中文文本情感分析,在不同種模型的對比試驗中,驗證本文方法的可行性,實驗結果如表2所示。

表2 對比試驗
本文模型能夠較好地分析景點評論的情感極性,在對比傳統模型和BERT模型中,均有不錯的表現。其中對比BERT模型,F1分數增加了8個百分點。
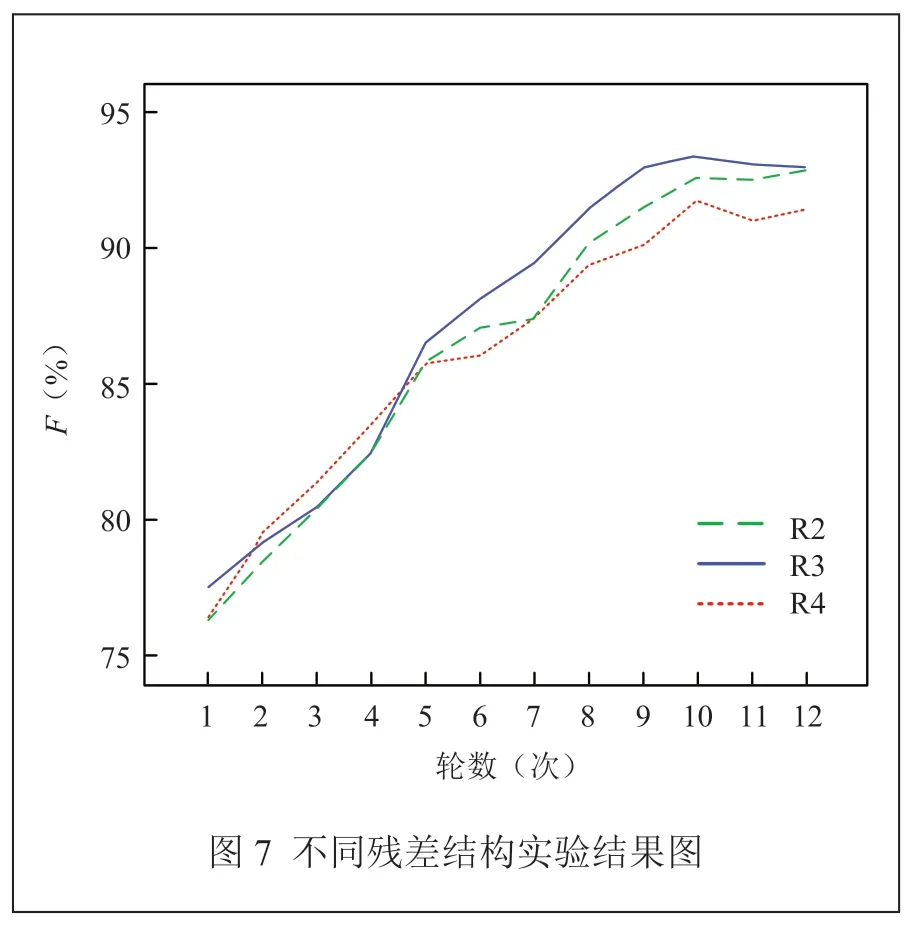
同時,本文對MRN中的殘差結構進行對比選擇實驗,如圖7所示。分別使用雙殘差、三殘差和四殘差結構進行實驗,其中,三殘差結構的F1分數最高,得出殘差結構多會使模型的時間成本變多,模型分類效果不會有明顯增加,而殘差結構少會影響模型的分類結果的可靠性,故本文選取三殘差結構來提取評論情感特征。
4 結束語
本文介紹了BERT模型和BiLSTM,針對景點情感分析領域中深度學習神經網絡模型BERT與傳統網絡結合容易出現網絡退化的問題,提出了多頭殘差網絡模型。通過和傳統神經網絡模型以及一部分基于遷移學習思想的模型在情感分類任務中比較,驗證了BERT-MRN模型具備不錯的情感分類能力,能夠更好地分析景點評論情感,在景點推薦領域有好的應用價值,對于游客選擇景點出行有著輔助意義。本文研究的實驗內容主要指二分類問題,后續要針對多分類問題進一步探究該模型的適用性。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中國生殖健康(2018年5期)2018-11-06 07:15:40
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
