預測工業經濟的指標選擇
2022-02-28 03:40:02曹秋雯王子杰
現代工業經濟和信息化 2022年12期
曹秋雯,王 凱,王子杰
(鄭州大學數學與統計學院,河南 鄭州 450001)
引言
工業經濟對國民經濟發展的重要作用不可替代。工業是全面建成小康社會和建設現代化強國的基礎支撐;是推動經濟持續健康發展的重要力量;是國際貿易與投資的關鍵支撐;是新技術與新模式創新的重要載體;是帶動落后地區經濟發展的重要動力。預測工業增加值可以幫助政府和企業提前制定策略以應對未來經濟變化。
現如今,越來越多的學者利用各種模型對工業經濟進行預測,例如吾彥軍、邱斌、王占峰、嚴慶江探究了大數據技術在工業經濟統計與預測中的應用[1];朱云英論述了統計指標和景氣指數對工業經濟預測的意義,其中企業景氣指數對工業經濟預測在建立模型預測工業增加值時具有信息可靠、前瞻性強、預測性強的特點,同時也說明了工業統計指標對于工業經濟預測的重要性[2]。本文在先前學者論述的基礎上創新性的從建立模型所需要選取的指標的角度來說明不同指標建立的BP神經網絡模型在預測同一地區的工業增加值的準確性不同,相同指標建立的BP神經網絡模型預測不同地區工業增加值的準確性不同;進而得出結論:預測不同地區的工業增加值時,不能用相同的指標建立的模型進行預測。
1 預測工業增加值相關因素的選取
1.1 地域的選取
根據統計局數據,河南省2020年的生產總值產業結構為:第一產業占比9.4%,第二產業占比41.6%,第三產業占比48.7%;黑龍江省2020年的生產總值產業結構為:第一產業占比25.1%,第二產業占比25.4%,第三產業占比49.5%;海南省2020年的生產總值產業結構為:第一產業占比20.5%,第二產業占比19.1%,第三產業占比60.4%[3]。河南省,黑龍江省和海南省的產業結構顯著不同,為了說明選用相同的指標建立模型分別預測不同省份的工業增加值的準確性不同,選擇這三個省份來進行建模分析。
1.2 指標及數據的選取
在預測工業增加值時,首先需要選取適當的指標。對影響工業增加值的指標進行分析,將影響工業增加值的指標分為自然因素指標和社會因素指標。自然因素主要指自然災害、溫度、氣候等。大的自然災害如火山噴發、地震等必然會對工業產生負影響,溫度和氣候的變化一定程度上會影響工業的投入成本。但是這些因素對工業增加值的影響是短期的,且這些指標難以量化,在預測工業增加值的具體數據的時候就會造成困難,因此在選擇預測工業增加值的指標時不考慮自然因素。
影響工業增加值的社會因素有勞動力人口總數,規模以上企業個數、GDP、社會用電量,居民消費價格指數、稅收、利潤、社會用水量等。為了獲取數據的方便,選擇國家統計局或者地方統計局中已統計的指標。由于國家政策的改變,規模以上工業企業虧損企業單位數,規模以上工業企業主營業務收入,規模以上工業企業主營業成本,規模以上工業企業利息支出,規模以上工業企業營業利潤等指標的數據在2018年之后不被國家統計局公布;而營業收入,營業成本,營業利潤等指標在2018年之前沒有被國家統計局公布;因此為了方便建模,選擇2019—2021年的數據進行建模分析。在預測工業增加值時,首先要對選擇的指標進行相關性分析,對于相關系數r;當>0.95時,顯著性相關;當>=0.8時,高度相關;當0.5≤<0.8;中度相關;當0.3≤<0.5時,低度相關;當<0.3時,弱相關[4]。當相關系數大于0.5時認為兩組數據之間的相關性較大。將統計局中各省份的指標與相應的工業增加值做相關性分析,指標與各省份工業增加值的相關系數如下頁表1所示。
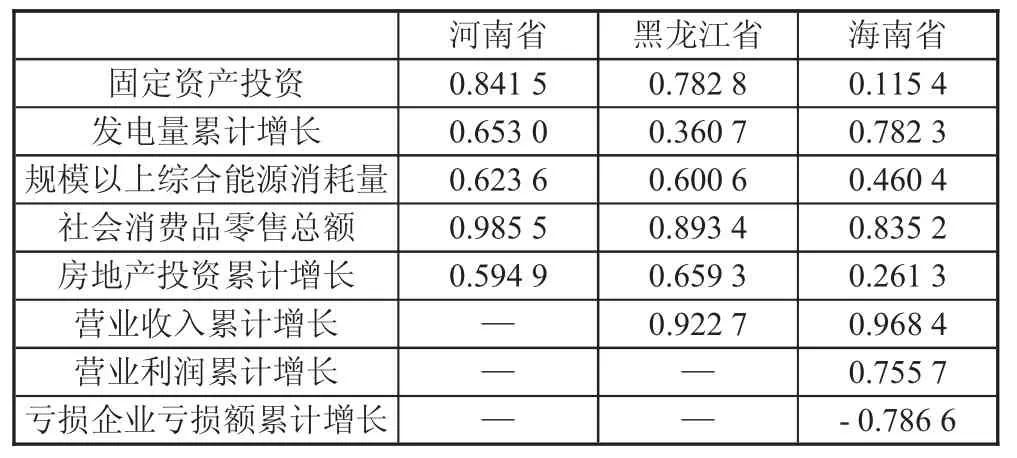
表1 指標與各省份工業增加值的相關系數[5]
2 工業增加值預測
使用BP神經網絡模型,將2019年1月—2021年5月的數據作為訓練集,2021年6—11月的數據作為測試集,以固定資產投資、發電量累計增長、社會消費品零售總額、規模以上綜合能源消耗量和房地產累計投資增長五個指標的數據建立BP神經網絡模型,預測河南省、黑龍江省和海南省的工業增加值;再以固定資產投資,營業收入累計增長,房地產投資累計增長,社會消費品零售總額,規模以上綜合能源消耗量這五個指標建立BP神經網絡模型二對黑龍江省工業增加值進行預測,以發電量累計增長、社會消費品零售總額、營業收入累計增長、營業利潤累計增長和虧損企業虧損額累計增長這五個指標建立BP神經網絡三對海南省的工業增加值進行預測。結果顯示:模型一可以很好地預測河南省的工業增加值,預測黑龍江省的工業增加值時誤差較大,預測海南省的工業增加值時誤差特別大,無法顯示預測結果;模型二預測黑龍江省的工業增加值的誤差小于用模型一預測時的誤差;模型三可與預測出海南省的工業增加值。
2.1 數據的來源與處理
以工業增加值累計增長值作為觀測指標,以固定資產投資、發電量累計增長、社會消費品零售總額、規模以上綜合能源消耗量、房地產累計投資增長、營業收入累計增長,營業利潤累計增長和虧損企業虧損額累計增長作為建模指標;數據來源于國家統計局網站與地方統計局網站。各指標的累計增長值可以從統計局中得到,但是缺失一月份的數據,因而需要對數據進行處理;具體處理方法為:以當年2月—12月數據的平均值作為該指標的一月份數據,2021年為2月—11月數據的平均值作為一月份的數據。
2.2 BP神經網絡模型的建立
人工神經網絡(Artificial Neural Networks,簡寫為ANNs)是模擬人的形象思維建立起來的。神經網絡的拓撲結構分為三層,即輸入層、隱藏層、輸出層。在BP神經網絡提出之前很長一段時間里沒有找到隱藏層的連接權值調整問題的有效算法,BP神經網絡的提出解決了這一問題[6]。
BP神經網絡屬于傳統神經網絡,是一種求解權重w的算法。通常分為兩步[7]:FP:信號正向傳遞(FP)求損失;BP:損失反向回傳(BP)。
BP(Back Propagation)神經網絡算法的學習過程主要由信號的正向傳播和誤差的反向傳播兩個過程組成。原始數據從輸入層輸入,經隱藏層處理以后,傳向輸出層。如果輸出層的實際輸出和期望輸出不符合,就進入誤差的反向傳播階段。誤差反向傳播是將輸出誤差以某種形式通過隱層向輸入層反向傳播,并將誤差分攤給各層的所有單元,從而獲得各層單元的誤差信號,這個誤差信號就作為修正個單元權值的依據。直到輸出的誤差滿足一定條件或者迭代次數達到一定次數便停止迭代。BP神經網絡的層與層之間為全連接,同一層之間沒有連接,其結構模型如圖1所示。
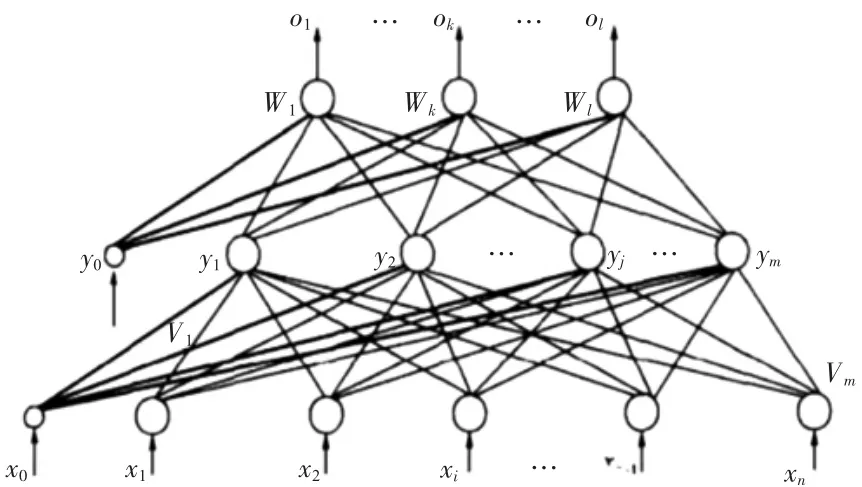
圖1 BP神經網絡結構模型
輸入向量為x=(x1,x2,…,xn),其中圖中x0為隱藏神經元引入閾值設置的;隱層輸出向量為y=(y1,y2,…,yn),其中圖中y0為輸出神經元引入閾值設置的;最終輸出向量為o=(o1,o2,…,ol),W1,…,Wk,…,Wl為隱藏層到輸出層的權值。即輸出層的輸入是隱層的輸出,隱層的輸入是輸入層的輸出。
BP神經網絡輸入和輸出層的節點數是固定的,不論是回歸還是分類任務,選擇合適的層數以及隱藏層節點數,在很大程度上都會影響神經網絡的性能。在建立模型時設定的參數為:輸入層節點數為5;輸出層節點數為1;隱藏層節點數為7;最大訓練次數為20 000;學習效率為0.001。
選取Sigmoid函數作為激活函數,交叉熵代價函數(Cross-Entropycost function)作為損失(代價)函數。將2019年1月—2021年5月的數據作為訓練集,2021年6月—11月的數據作為測試集,建立BP神經網絡模型。
2.3 BP神經網絡模型的預測結果
基于固定資產投資,發電量累計增長值,房地產投資累計增長,社會消費品零售總額,規模以上綜合能源消耗量這五個標建立模型一對工業增加值進行預測。各省份的絕對誤差如下頁表2所示。
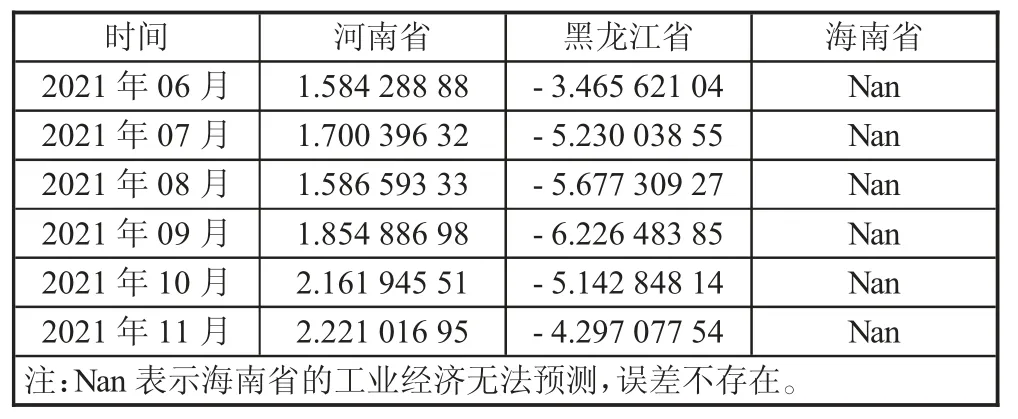
表2 模型一預測各省份的工業增加值時的絕對值
用模型一與模型二預測黑龍江省的工業增加值的絕對誤差,用模型一與模型三預測海南省的工業增加值的絕對誤差如表3所示。
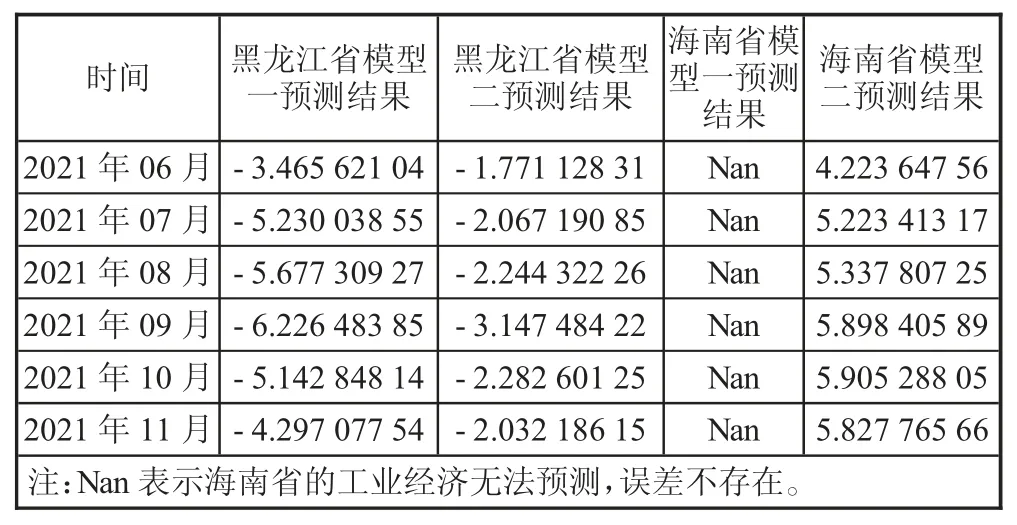
表3 黑龍江省和海南省分別兩次建模的絕對誤差
3 結論與啟示
本文通過建立BP神經網絡模型預測各省份的工業增加值;橫向對比模型一分別預測河南省、黑龍江省和海南省的工業增加值的絕對誤差,可以得出結論:同一模型在預測不同地區的工業增加值時,準確性不同。縱向對比模型一預測黑龍江省的工業增加值的絕對誤差與模型二預測黑龍江省的工業增加值的絕對誤差;模型一預測海南省的工業增加值的絕對誤差與模型三預測海南省的工業增加值的絕對誤差,得出結論:與工業增加值的相關性越大的指標建立的模型,對工業增加值的預測效果越好。
在當今信息化時代大背景下,預測未來經濟發展,提前做好應對措施是所有國家,企業保證自身經濟平穩發展的必要舉措。本文淺顯地論述了在預測工業經濟時不同地區要建立不同的模型,以防止用同一個模型預測不同地區的工業經濟時產生遠偏離實際的結果,導致管理人員做出錯誤的決策。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
新教育(2022年16期)2022-06-22 07:04:04
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
成都信息工程大學學報(2017年4期)2018-01-22 02:08:33
中國衛生(2016年12期)2016-11-23 01:09:50
光學精密工程(2016年6期)2016-11-07 09:07:19
中學歷史教學(2015年7期)2015-11-11 07:08:26
核科學與工程(2015年4期)2015-09-26 11:59:03
中國工程咨詢(2015年2期)2015-02-14 02:59:28
