基于OpenMP 的多機集群并行計算系統(tǒng)架構(gòu)設(shè)計
2022-03-02 12:42:56李曉琳高獻偉韓妍妍
北京電子科技學(xué)院學(xué)報 2022年4期
關(guān)鍵詞:服務(wù)
李曉琳 高獻偉 韓妍妍
北京電子科技學(xué)院,北京市 100070
引言
進入21 世紀以來,物聯(lián)網(wǎng)、大數(shù)據(jù)等信息技術(shù)得到迅猛發(fā)展,引發(fā)重大的技術(shù)革新。 同時,信息資源等也變得十分復(fù)雜,導(dǎo)致信息化系統(tǒng)不斷變得龐大、復(fù)雜,隨之而來的是海量、巨大的信息量和計算量。 截至當(dāng)前,數(shù)據(jù)量已經(jīng)從TB 躍升到PB、EB 甚至ZB 的級別,數(shù)據(jù)的爆炸式增長以及其蘊含的巨大價值將對企業(yè)未來的發(fā)展產(chǎn)生深遠的影響,在此背景下,系統(tǒng)對數(shù)據(jù)的處理規(guī)模越來越大,傳統(tǒng)的軟件計算已經(jīng)無法滿足如此龐大數(shù)據(jù)處理規(guī)模,如何對數(shù)據(jù)進行快速、高效的處理是未來信息技術(shù)發(fā)展道路上關(guān)注的重點。
隨著現(xiàn)代科技和經(jīng)濟的發(fā)展,基于多核處理器的高性能計算機出現(xiàn)在許多大型工程、科學(xué)實驗的研究中,通過網(wǎng)絡(luò)將大量的服務(wù)器連接起來,具有超強的計算能力,能夠滿足大量計算的需求。 雖然如此,傳統(tǒng)的單機串行軟件編程方式無法充分利用多核處理器資源,計算機的性能無法得到充分地利用。 應(yīng)用程序要想充分發(fā)揮多核處理器的性能,必須采用并行計算的方式,提高軟件系統(tǒng)的運行效率[1]。
近幾年來,國外許多高校和科研機構(gòu)對并行算法進行設(shè)計、分析和實現(xiàn),并在并行優(yōu)化編譯、高性能I/O、通信技術(shù)等方面開展研究。 國內(nèi)一些高校和研究院投入了一些力量開展并行計算軟件應(yīng)用理論和方法的研究,并取得了一定的成果,到目前為止,并行計算技術(shù)已經(jīng)廣泛地應(yīng)用于計算數(shù)學(xué)、數(shù)字模擬、機械制造等領(lǐng)域。
本文基于《天地一體化網(wǎng)絡(luò)密碼按需服務(wù)關(guān)鍵技術(shù)及系統(tǒng)》,它是《天地一體化網(wǎng)絡(luò)信息安全保障技術(shù)的研究》中的一個子課題,它對天地一體化信息網(wǎng)絡(luò)中密碼資源跨域管理、海量密碼數(shù)據(jù)存儲等關(guān)鍵技術(shù)進行研究[2]。 由于天地一體化網(wǎng)絡(luò)具有復(fù)雜、多樣、異構(gòu)的特點,并包含多種多樣的密碼設(shè)備和資源,因此產(chǎn)生了海量的數(shù)據(jù),如何高效地處理海量的數(shù)據(jù)成為天地一體化信息網(wǎng)絡(luò)建設(shè)中研究的關(guān)鍵課題之一。
本文根據(jù)天地一體化跨域分層密碼按需服務(wù)的總體技術(shù)要求,基于OpenMP 技術(shù)開展多核并行程序設(shè)計方法的研究,并在此基礎(chǔ)上設(shè)計了一種多機集群并行計算系統(tǒng),旨在充分利用計算機性能,提高數(shù)據(jù)處理和計算的效率,解決天地一體化信息網(wǎng)絡(luò)對海量數(shù)據(jù)處理的需求。
1 關(guān)鍵技術(shù)研究
1.1 并行計算技術(shù)研究現(xiàn)狀
目前主流的并行計算技術(shù)主要有OpenMP、MPI(信息傳遞接口)和Spark(計算引擎)技術(shù),針對這幾種技術(shù)進行了調(diào)研分析對比。
(1)OpenMP
OpenMP 是一種基于共享內(nèi)存多處理器體系結(jié)構(gòu)的多線程并行編程模型,也是在共享存儲下編寫并行程序的一組API。 OpenMP 的規(guī)范由SGI 提出,獲得了微軟、Sun、Intel、IBM、HP 等軟硬件行業(yè)巨頭的認可和支持,目前支持的語言是C/C++和Fortran。
OpenMP1.0 標(biāo)準(zhǔn)誕生于1997 年。 2005 年,OpenMP 的結(jié)構(gòu)審議會(Architecture Review Board,ARB),推出了OpenMP2.5 標(biāo)準(zhǔn)。 2008年,OpenMP3.0 標(biāo)準(zhǔn)被退出,但目前使用最廣泛的還是2.5 標(biāo)準(zhǔn)。
OpenMP 中,CPU 中的多個處理單元(核)共享同一個內(nèi)存設(shè)備,所有的CPU 處理單元訪問相同的內(nèi)存空間地址,這些處理單元通過共享的內(nèi)存變量進行通信。 OpenMP 編程方式十分方便,現(xiàn)已成為一個工業(yè)標(biāo)準(zhǔn),支持多種平臺,包括大多數(shù)的類UNIX 系統(tǒng)和幾乎所有的Windows NT 系統(tǒng)等。 OpenMP 具有開發(fā)簡單、抽象度高、通用性好、可擴充性和可移植性強、支持并行的增量開發(fā)和數(shù)據(jù)并行等優(yōu)點,廣泛應(yīng)用于多核PC 環(huán)境下的并行程序設(shè)計。
(2)MPI
MPI 是一個庫,一種標(biāo)準(zhǔn)或規(guī)范的代表,一種消息傳遞編程模型。 MPI 是目前分布式內(nèi)存體系結(jié)構(gòu)中開發(fā)高性能計算應(yīng)用的標(biāo)準(zhǔn)。 它支持C,C++和Fortran 語言。 它采用將同一程序運行在眾多進程上的方式,這些進程不僅可以處于同一個共享內(nèi)存架構(gòu)的計算機中,也可以運行在眾多進程上的方式來實現(xiàn)。 每個進程都擁有各自的數(shù)據(jù),在不需要通訊時,各個進程異步地運行相同的代碼,對不同的數(shù)據(jù)進行相似的處理,在需要訪問其他進程上的數(shù)據(jù)時,通過MPI 標(biāo)準(zhǔn)中定義的數(shù)據(jù)通訊函數(shù)對數(shù)據(jù)進行遷移和處理,也可以對操作進行同步[3]。
MPI 是利用集群實現(xiàn)多節(jié)點并行計算,通過劃分任務(wù)進程,達到數(shù)據(jù)并行處理的目的。 MPI是在網(wǎng)格計算中使用的較為傳統(tǒng)并行方法,主要應(yīng)用在對于通訊效率要求低,通訊數(shù)據(jù)的數(shù)量較小,利用MPI 來進行集群并行計算。 相比于MPI 來說,OpenMP 是運行在進程上的并行處理模式,它將一個進程劃分為多個線程并實現(xiàn)線程同步執(zhí)行,實現(xiàn)可視化的并行處理。
MPI 提供了可移植性、標(biāo)準(zhǔn)化包括點對點消息傳遞和集體的操作,所有的范圍用戶指定的組的過程。 MPI 提供了一個實體集編寫、調(diào)試、測試和性能分步程序庫。 MPI 庫通常用于并行編程中集群系統(tǒng),因為它是一個消息傳遞編程語言。
(3)Spark
美國加州大學(xué)伯克利分校AMP 實驗室研發(fā)了Spark。 Spark 的性能可以超過Hadoop10 倍以上。 Spark 是基于Hadoop 的,并且構(gòu)建在HDFS之上,同時保留了MapReduce 的可擴展性和容錯性,但是,Spark MapReduce 不完全等同于Hadoop MapReduce。 Spark 主要由兩部分組成:第一部分是有很多執(zhí)行器的調(diào)度器,它可以進行任務(wù)調(diào)度、任務(wù)監(jiān)控以及故障處理。 第二部分是執(zhí)行器,執(zhí)行實際的計算和數(shù)據(jù)處理任務(wù)[4]。
Hadoop MapReduce 是一種大規(guī)模數(shù)據(jù)處理的并行計算模型。 Hadoop 是一個Master--Slave架構(gòu)模式,由一臺主節(jié)點和若干臺Slave 節(jié)點組成。 其中主節(jié)點負責(zé)管理和監(jiān)控各個Slave 節(jié)點的任務(wù)執(zhí)行情況,包含一個Master 服務(wù)Job-Tracker(作業(yè)服務(wù)器)用于接收Job,它的任務(wù)是將作業(yè)分配給等待的節(jié)點。 Slave 節(jié)點負責(zé)具體的任務(wù)執(zhí)行,包含一個Slave 服務(wù)TaskTrack(任務(wù)服務(wù)器),它負責(zé)與JaoTracker 通信并接收作業(yè),再根據(jù)每個節(jié)點的拆分數(shù)據(jù),進行Map 和Reduce。 每個Slave 節(jié)點是并行執(zhí)行,提高了計算效率。 簡單而言可以將MapReduce 編程模型抽象成“Map(映射)”和“Reduce(化簡)”兩個過程,Hadoop MapReduce 計算模式的流程圖見圖1[5-6]。
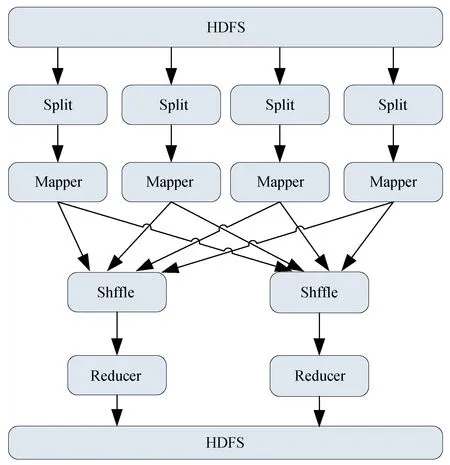
圖1 Hadoop MapReduce 計算模式的流程圖
具體過程為:程序從分布式文件系統(tǒng)讀入大數(shù)據(jù)集,并切分為Split(分片),Map 函數(shù)處理Split 并輸出中間結(jié)果,通過Shuffle 把中間結(jié)果分區(qū)排序整理后發(fā)送給Reduce 函數(shù),Reduce 完成具體計算任務(wù)并將最終結(jié)果寫入文件系統(tǒng)。
1.2 技術(shù)可行性分析
OpenMP 集成在C++中,與系統(tǒng)適配性好,開發(fā)簡單,對軟件系統(tǒng)改造十分方便,可移植性強,但是OpenMP 只支持單機并行計算,而且通過線程實現(xiàn)通信,多線程間資源共享;MPI 支持多機并行計算,通過進程實現(xiàn)并行計算,具備資源隔離特點;但是通訊效率要求低,通迅數(shù)據(jù)量較小;Spark 支持多機并行計算,可抗展性和容錯能力強,但是計算性能有待提高。
通過綜合分析,OpenMP、MPI、Spark 都能夠?qū)崿F(xiàn)并行計算,但是均不滿足海量數(shù)據(jù)的處理和計算的需求。 在天地一體化網(wǎng)絡(luò)中,網(wǎng)絡(luò)之間的數(shù)據(jù)通信量在百兆以上,而且數(shù)據(jù)的種類多,MPI 和Spark 技術(shù)均無法實現(xiàn),因此,在單機OpenMP 并行計算的基礎(chǔ)上開展多機集群并行計算架構(gòu)設(shè)計,既能夠滿足大數(shù)據(jù)通信,又能夠保證計算性能。
2 平臺架構(gòu)設(shè)計
2.1 總體架構(gòu)設(shè)計
并行集群計算系統(tǒng)可部署在普通計算機或服務(wù)器上,支持在多種架構(gòu)CPU、多種操作系統(tǒng)上運行,并行計算系統(tǒng)由并行計算服務(wù)中心、計算節(jié)點和客戶端模塊組成[7-8]。 本文中,在傳統(tǒng)單機OpenMP 并行計算的基礎(chǔ)上,擴展了多個計算節(jié)點,通過統(tǒng)一的計算服務(wù)中心控制,開展多機集群計算。 并行計算系統(tǒng)中只有一個計算服務(wù)中心,可以有多個計算節(jié)點,每個計算節(jié)點中包含計算程序,負責(zé)具體的計算任務(wù),在計算程序中增加OpenMP 指令設(shè)置,運行中支持多核多線程并行計算。 計算服務(wù)中心負責(zé)接收客戶端發(fā)起的計算請求,通過監(jiān)控各計算節(jié)點的工作狀態(tài)向計算節(jié)點分配計算任務(wù),各節(jié)點完成計算任務(wù)后,將計算結(jié)果發(fā)送到計算服務(wù)中心,所有的計算結(jié)果數(shù)據(jù)整理后,發(fā)送給客戶端。 客戶端、并行計算服務(wù)中心、計算節(jié)點間采用TCP 和UDP 通信。 并行計算系統(tǒng)總體架構(gòu)見圖2。
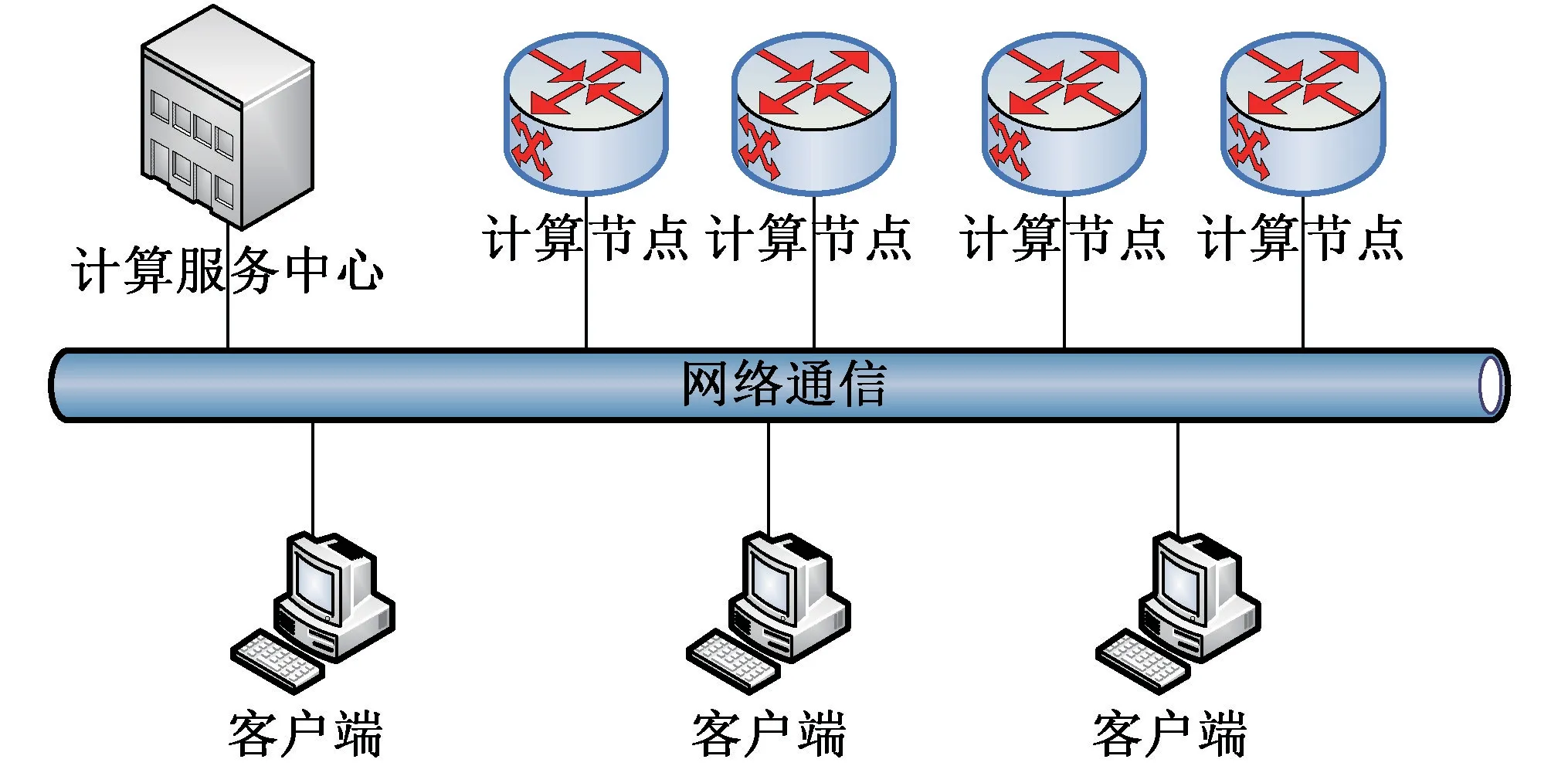
圖2 并行計算系統(tǒng)總體架構(gòu)圖
計算服務(wù)中心可以為多個計算用戶服務(wù),計算用戶通過配置集群服務(wù)地址獲取計算服務(wù)心跳報文,從中得到TCP 通信網(wǎng)址和端口號,使用TCP 通信方式加入計算服務(wù)中心,通過已經(jīng)建立的TCP 通信鏈路向并行計算服務(wù)中心發(fā)送計算請求報文,計算服務(wù)中心完成計算后,通過TCP 通信鏈路向計算用戶發(fā)送計算結(jié)果報文。計算服務(wù)中心可以控制多個計算節(jié)點進行計算,每個計算節(jié)點以UDP 組播的方式向指定組播地址發(fā)送計算節(jié)點狀態(tài)報文,計算服務(wù)中心通過該報文掌握各個計算節(jié)點的工作狀態(tài),同時計算節(jié)點與計算服務(wù)中心建立TCP 通信鏈路,計算服務(wù)中心通過該TCP 通信鏈路向計算節(jié)點發(fā)送計算命令報文,計算節(jié)點接收到計算命令報文后,開始進行計算,完成計算后,通過TCP 通信鏈路向計算服務(wù)中心發(fā)送計算結(jié)果報文。
2.2 計算服務(wù)中心設(shè)計
計算服務(wù)中心由計算服務(wù)分配處理模塊、顯示控制模塊、計算服務(wù)狀態(tài)發(fā)布模塊、計算節(jié)點狀態(tài)監(jiān)控模塊、計算用戶通信服務(wù)、計算節(jié)點通信服務(wù)6 部分組成。 計算服務(wù)中心組成關(guān)系如圖3 所示。

圖3 計算服務(wù)中心組成關(guān)系圖
計算服務(wù)分配處理模塊實現(xiàn)計算服務(wù)計算量評估、計算服務(wù)管理、計算節(jié)點計算結(jié)果管理、計享節(jié)點異常監(jiān)控及處理等功能。 計算服務(wù)分配處理模塊接收到計算用戶的請求后,進行計算服務(wù)計算量評估,再根據(jù)當(dāng)前計算節(jié)點狀態(tài),向計算節(jié)點發(fā)送計算命令,等待收集到完整的計算節(jié)點數(shù)據(jù)后,整理計算結(jié)果,通過計算用戶通信服務(wù)將計算結(jié)果發(fā)送給計算用戶。
顯示控制模塊實現(xiàn)并行計算服務(wù)中心啟動/停上控制、實時顯示計算節(jié)點工作狀態(tài),實時顯示計算服務(wù)狀態(tài)等功能。
計算服務(wù)狀態(tài)發(fā)布模塊實現(xiàn)計算服務(wù)通信參數(shù)發(fā)布、計算節(jié)點通信參數(shù)發(fā)布等功能。
計算節(jié)點狀態(tài)監(jiān)控模塊實現(xiàn)UDP 組播通信初始化、計算節(jié)點狀態(tài)監(jiān)控處理等功能。
計算用戶通信服務(wù)實現(xiàn)TCP 通信初化、TCP通信服務(wù)管理、TCP 數(shù)據(jù)接收處理、TCP 數(shù)據(jù)發(fā)送處理等功能。
計算節(jié)點通信服務(wù)實現(xiàn)TCP 通信初始化、TCP 通信服務(wù)管理、TCP 數(shù)據(jù)接收處理、TCP 數(shù)據(jù)發(fā)送處理等功能。
2.3 計算節(jié)點設(shè)計
計算節(jié)點有計算節(jié)點通信參數(shù)處理模塊、通信處理模塊、計算處理模塊、顯示控制模塊、計算節(jié)點狀態(tài)處理模塊5 部分組成。 計算節(jié)點組成關(guān)系圖見圖4。
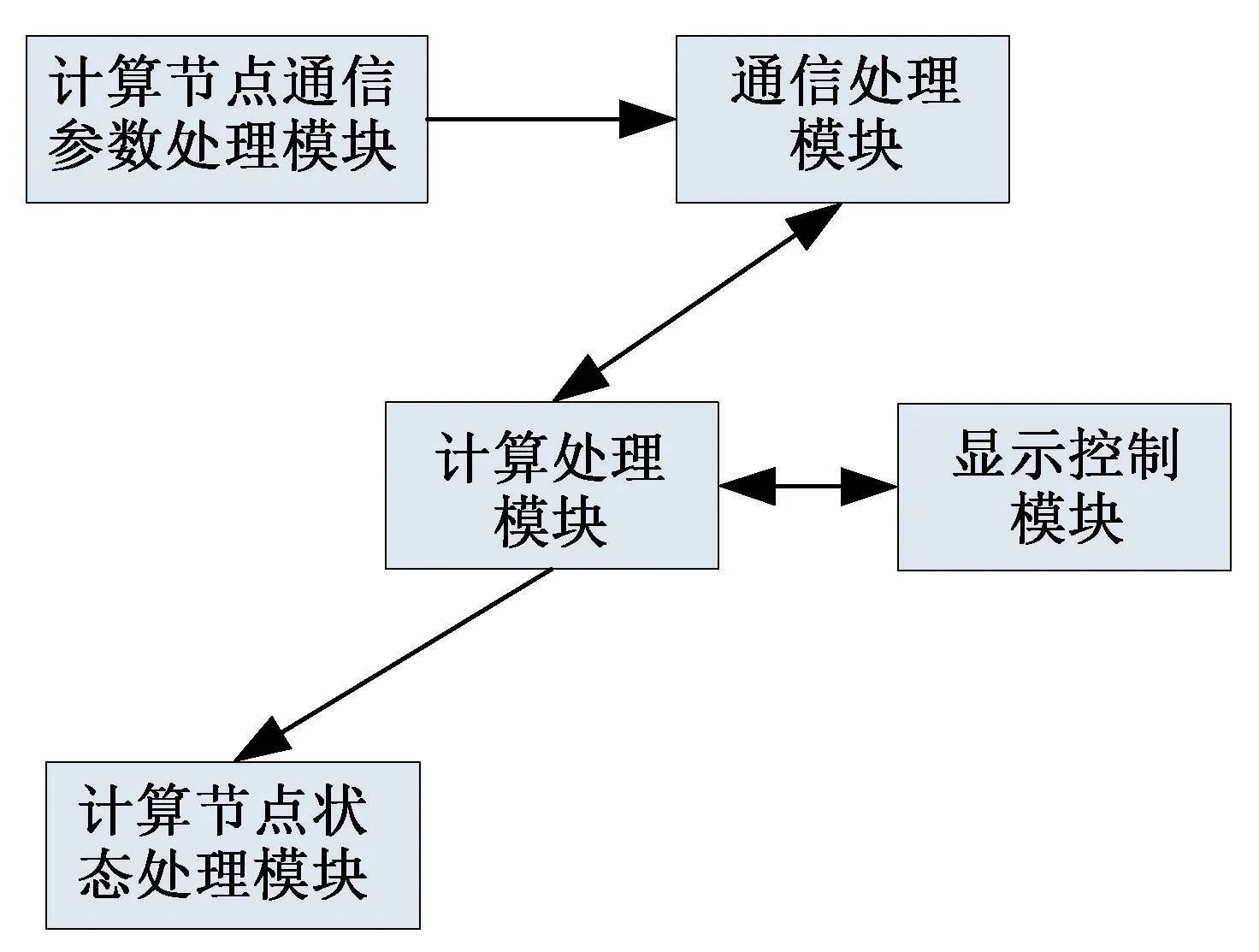
圖4 計算節(jié)點組成關(guān)系圖
計算節(jié)點通信參數(shù)處理模塊在程序初始化的時候,加入指定UDP 組播地址,接收計算服務(wù)中心心跳報文,獲取計算節(jié)點TCP 通信參數(shù)供通信處理模塊使用。
通信處理模塊根據(jù)結(jié)算節(jié)點通信參數(shù)處理模塊提供的TCP 通信參數(shù)初始化TCP 通信鏈路,在整個程序運行過程中,負責(zé)TCP 通信數(shù)據(jù)接收、數(shù)據(jù)發(fā)送的處理。
計算處理模塊實現(xiàn)計算機多核狀態(tài)監(jiān)控、單機并行計算處理等功能。
顯示控制模塊實現(xiàn)計算機多核狀態(tài)監(jiān)控顯示、計算狀態(tài)顯示等功能。
計算節(jié)點狀態(tài)處理模塊實現(xiàn)計算節(jié)點狀態(tài)UDP 組播發(fā)送功能。
2.4 客戶端模塊設(shè)計
客戶端模塊由計算服務(wù)通信參數(shù)處理模塊、通信處理模塊、計算服務(wù)處理模塊組成。 客戶端模塊組成關(guān)系圖見圖5。
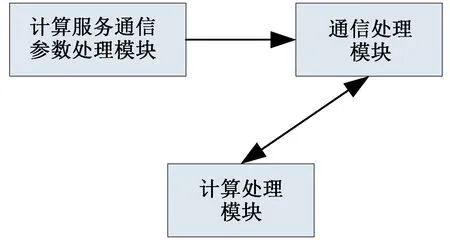
圖5 客戶端模塊組成關(guān)系圖
計算服務(wù)通信參數(shù)處理模塊在程序初始化的時候,加入指定UDP 組播地址,接收計算服務(wù)心跳報文,獲取計算用戶的TCP 通信參數(shù)供通信處理模塊使用。
通信處理模塊根據(jù)計算服務(wù)通信參數(shù)處理模塊提供的TCP 通信參數(shù)初始化TCP 通信鏈路,在整個程序運行過程中,負責(zé)TCP 通信數(shù)據(jù)接收、數(shù)據(jù)發(fā)送的處理。
計算服務(wù)模塊為應(yīng)用程序提供計算輸入、輸出接口。
3 系統(tǒng)驗證
(1)測試環(huán)境
本文中使用單臺高性能計算機進行測試,計算機性能指標(biāo)如下:
CPU:Inter Xeon E5-2640 @2.4GHz(雙處理器40 核)
內(nèi)存:64G
操作系統(tǒng):Windows7 64 位
(2)測試方法
編寫測試程序?qū)?0000 個隨機整數(shù)進行冒泡排序,分別計算1 次、2 次、4 次、8 次、24 次、40次,計算過程中分別設(shè)置1 核、2 核、4 核、8 核、24 核、40 核并行計算,每組測試進行3 次,取運行結(jié)果的平均值。
(3)測試結(jié)果
測試結(jié)果如表1 所示。
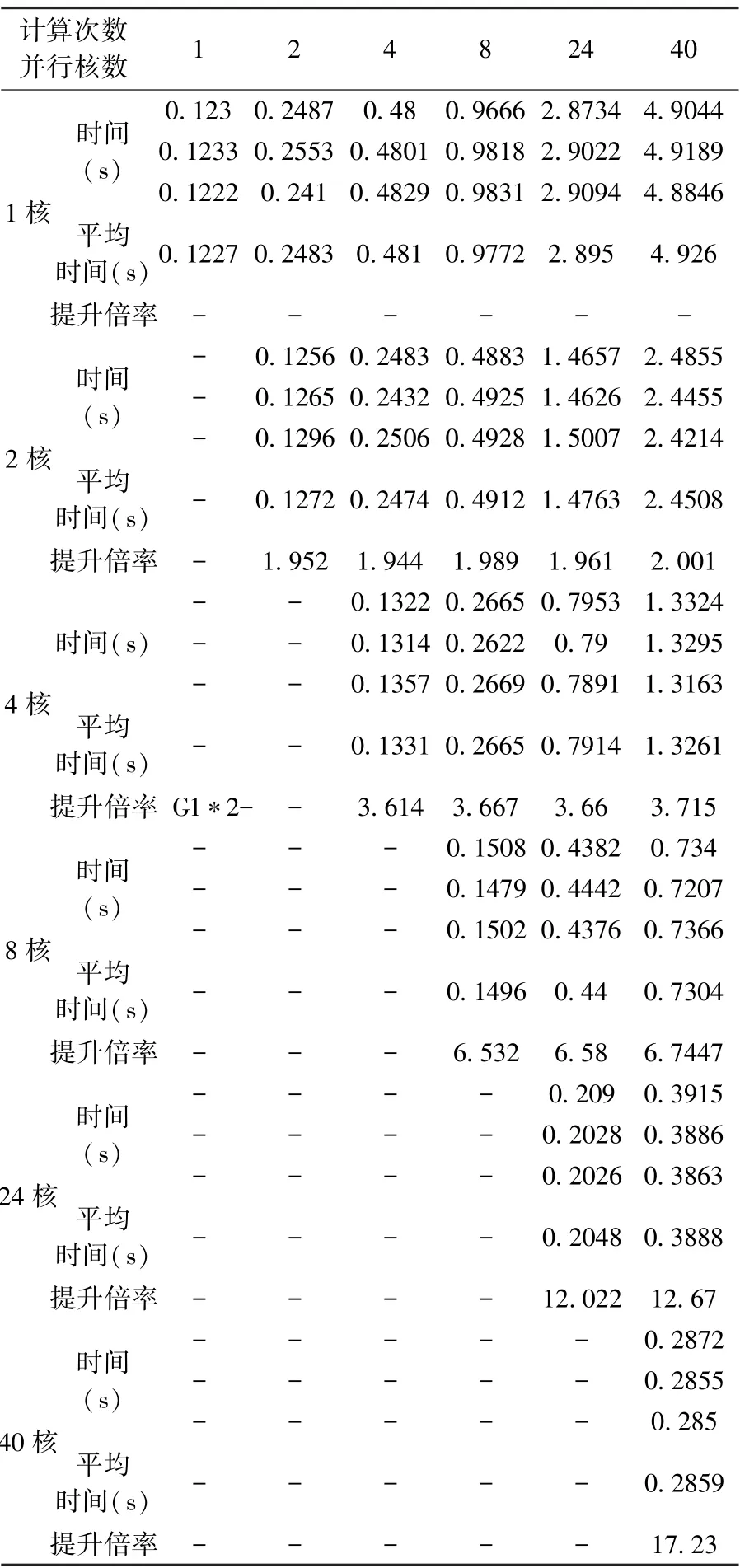
表1 單機計算時間測試結(jié)果
由測試數(shù)據(jù)可以看出,通過應(yīng)用并行計算技術(shù),用40 核同時對測試程序計算40 次,平均用時2.859s,相比于非并行的49.26:速率提高了17.23 倍。 通過使用不同核數(shù)對同一測試程序進行測試,發(fā)現(xiàn)隨著使用核數(shù)的增加,與提升運算效率的倍數(shù)并不是線性關(guān)系,由于存在多核并行分配處理、數(shù)據(jù)回收處理,使用核數(shù)越多,多核并行分配處理、數(shù)據(jù)回收處理占用的時間比重就越多,因此,在并行計算設(shè)計過程中,應(yīng)根據(jù)具體的數(shù)據(jù)處理需求分配計算核數(shù),以達到最優(yōu)的效率。
目前OpenMP 并行計算大多使用單機運行,從理論上分析如果能夠使用多臺計算機同時進行計算,將多計算任務(wù)進行分發(fā)處理,能夠使計算效率得到進一步提升。 本次測試驗證僅使用單臺計算機進行測試,后續(xù)將針對多臺計算機進行補充研究測試。
4 結(jié)束語
本文針對天地一體化信息網(wǎng)絡(luò)對大數(shù)據(jù)計算處理的需求,開展多機集群并行計算架構(gòu)設(shè)計,對OpenMp、MPI 和Spark 技術(shù)進行調(diào)研分析,設(shè)計了一種基于OpenMP 的多機集群并行計算系統(tǒng),并通過試驗驗證對并行計算的性能進行測試,試驗表明該應(yīng)用了并行計算系統(tǒng),使計算速度提升了十幾倍,有效提高了數(shù)據(jù)計算和處理效率,可廣泛應(yīng)用于天地一體化信息網(wǎng)絡(luò)中大數(shù)據(jù)的處理和計算。
猜你喜歡
杭州金融研修學(xué)院學(xué)報(2022年5期)2022-06-15 11:41:48
今日農(nóng)業(yè)(2019年14期)2019-09-18 01:21:54
今日農(nóng)業(yè)(2019年12期)2019-08-15 00:56:32
今日農(nóng)業(yè)(2019年11期)2019-08-13 00:49:08
今日農(nóng)業(yè)(2019年13期)2019-08-12 07:59:04
今日農(nóng)業(yè)(2019年10期)2019-01-04 04:28:15
今日農(nóng)業(yè)(2019年15期)2019-01-03 12:11:33
今日農(nóng)業(yè)(2019年16期)2019-01-03 11:39:20
銅仁學(xué)院學(xué)報(2018年4期)2018-06-13 03:21:34
商周刊(2017年9期)2017-08-22 02:57:56
