基于MapReduce的支持向量機參數選擇研究
2022-03-04 07:46:54劉黎志
武漢工程大學學報 2022年1期
劉黎志,楊 敏
智能機器人湖北省重點實驗室(武漢工程大學),湖北 武漢430205
支持向量機(support vector machine,SVM)分類模型的建立需要經過大量的計算,隨著訓練樣本集規模的增長,不僅會大量消耗主機的CPU及內存資源,而且訓練模型所需要時間也會急劇增加,從而使得在單機環境下得到模型變得十分困難,因此如何針對大規模數據集,使用并行化方式獲得最優支持向量機分類模型,一直是研究的熱點問題[1-3]。基于Hadoop平臺的分布式計算框架MapReduce及Spark為并行化訓練大規模數據集提供了新的方法和手段[4-7],在分布式計算框架的支持下,SVM分類模型的訓練過程可以并行化,從而顯著縮短了得到模型所需要的時間[8-10],層疊化SVM就是基于MapReduce框架并行獲取支持向量的典型應用[11-12]。為了讓SVM分類模型能夠更魯棒地用于實際數據的預測及解決線性不可分問題,在模型的訓練過程中,需要對模型的參數進行選擇,從而得到最優的模型[13-14]。相關研究運用MapReduce框架建立分布式參數尋優模型,完成了模型訓練、預測和參數選擇優化。吳云蔚等[15]針對使用網格搜索對SVM參數進行全局尋優時存在的尋優時間長的問題,提出了一種基于Hadoop分布式文件系統(hadoop distributed file system,HDFS)平臺的分布式參數尋優方法,提高了尋優效率。白玉辛[16]基于Flink并行網格搜索算法對SVM參數進行尋優,將全局參數對文件切分成若干小塊交給各個計算節點并行尋優,最后匯總尋優結果,減少了尋優時間。李坤等[17]基于Spark集群實現了libsvm參數優選的并行化,提出了并行粗粒度網格搜索參數優選算法,相比傳統算法運行速度提升了近7倍,且隨著集群規模的擴大而進一步加大。
但當前的這些研究都缺少在訓練過程對集群內存資源消耗情況的論述。因此本文提出一種在MapReduce框架下進行最優模型參數選擇的新算法,該算法能夠在合理利用集群內存資源及保證進行交叉驗證的Reduce任務充分并行執行的前提下,顯著減少最優模型參數的獲取時間。
1 SVM分類最優模型參數選擇
對于給定的訓練數據集:D={(xi,yi)|xi∈Rn,yi∈(-1,1)}mi=1,求解SVM最優超平面的對偶問題描述為:
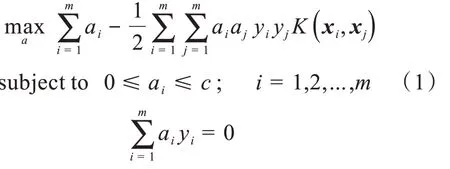
其中m為支持向量的個數,ɑi為支持向量對應的拉格朗日算子。
c為懲罰參數,控制SVM模型如何處理錯誤,對于線性可分問題,合適的c值可以使得超平面間距最大,同時出現的分類錯誤最少。沒有一個特定的c值可以解決所有的線性可分問題,對于具體的問題,最優的c值只能通過實驗的方法得到。
對于線性不可分問題,可以通過核函數將數據映射到多維空間,使其線性可分。核函數K的返回值是數據點在轉換為多維空間向量后的內積值,核函數K的形式化定義為:給定一個映射函數φ:x→ν,函數K:x→R,定義為:

其中,<φ(x),φ(x')>ν表示x,x'在轉換為φ(x),φ(x')后在ν中的內積。核函數的類型有線性核函數、多項式核函數、高斯核函數等。實踐證明,使用高斯核函數對線性不可分問題進行分類,一般可以取得較好的效果,故在選擇核函數時,高斯核函數一般是首選。高斯核函數的描述為:
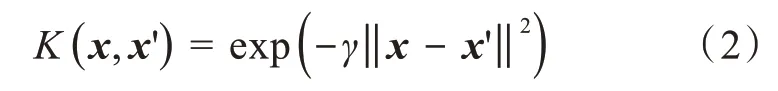
γ和c值一樣需要通過實驗得到其最優值,取得最優值的實驗為采用交叉驗證的網格搜索方法(grid search)。對于第i組給定的(ci,γi),交叉驗證的過程為將訓練集劃分為大小相同的n個等份,依次取其中的第j份為測試集Tj,j=(1,2,…,n),剩下的n-1份為訓練集,使用根據訓練集得到的分類模型預測Pj,得到預測準確率Aj,整個交叉驗證的準確率Ai為:

上述的過程稱為n重交叉驗證(n-fold cross validation)。n重交叉驗證使得整個訓練集中的數據均被預測,其準確率為整個訓練集中的數據被正確分類的百分比,故n重交叉驗證能有效的避免模型的過擬合問題。最優模型參數的選擇就是在集合p={(ci,γi)|ci,γi∈R}mi=1中,使用交叉驗證得到每組參數的Ai,取準確率最高的參數(ci,γi)為最優模型參數。使用網格搜索得到最優模型是個非常耗時的過程,假設參數集合p的參數組數為m,每組參數進行n重交叉驗證,每一次交叉驗證的平均時間為w,若為串行執行,網格搜索的總時間t為:

由此可見網格搜索的時間隨著參數組數m及交叉驗證的重數n而線性增長。在網格搜索的過程中,由于對某組參數進行交叉驗證的過程與其它參數組無關,故多組參數的交叉驗證過程可以并行執行,從而縮短網格搜索得到最優模型所需要的時間。
2 分布式集群環境下的最優模型參數選擇
2.1 最優模型參數的選擇過程
在分布式集群環境下,MapReduce框架負責處理并行計算中的分布式存儲、工作調度、負載均衡、容錯均衡、容錯處理以及網絡通信等復雜問題。MapReduce框架采用“分而治之”的策略,其核心步驟主要分兩部分:Map和Reduce。在向MapReduce框架提交一個計算作業后,MapReduce會首先把作業拆分成若干個Map任務,然后這些Map任務被分配到不同的機器上執行,這些Map任務完成后會產生一些鍵值對構成的中間文件,它們將會作為Reduce任務的輸入數據。Reduce任務的主要目標就是把前面若干個Map的輸出進行處理并給出結果。MapReduce框架的作業配置非常靈活,可以指定只單獨運行Map或者Reduce任務;指定完成具體任務的Reduce的個數;通過key值指定Map任務與Reduce任務的對應關系等。本文提出的最優模型參數選擇方法首先在Map任務中讀取存儲在HDFS文件系統中的參數文件,然后在Reduce任務中進行模型的訓練及交叉驗證,得到模型的準確率。基于MapReduce的SVM最優分類模型參數選擇的過程如圖1所示。
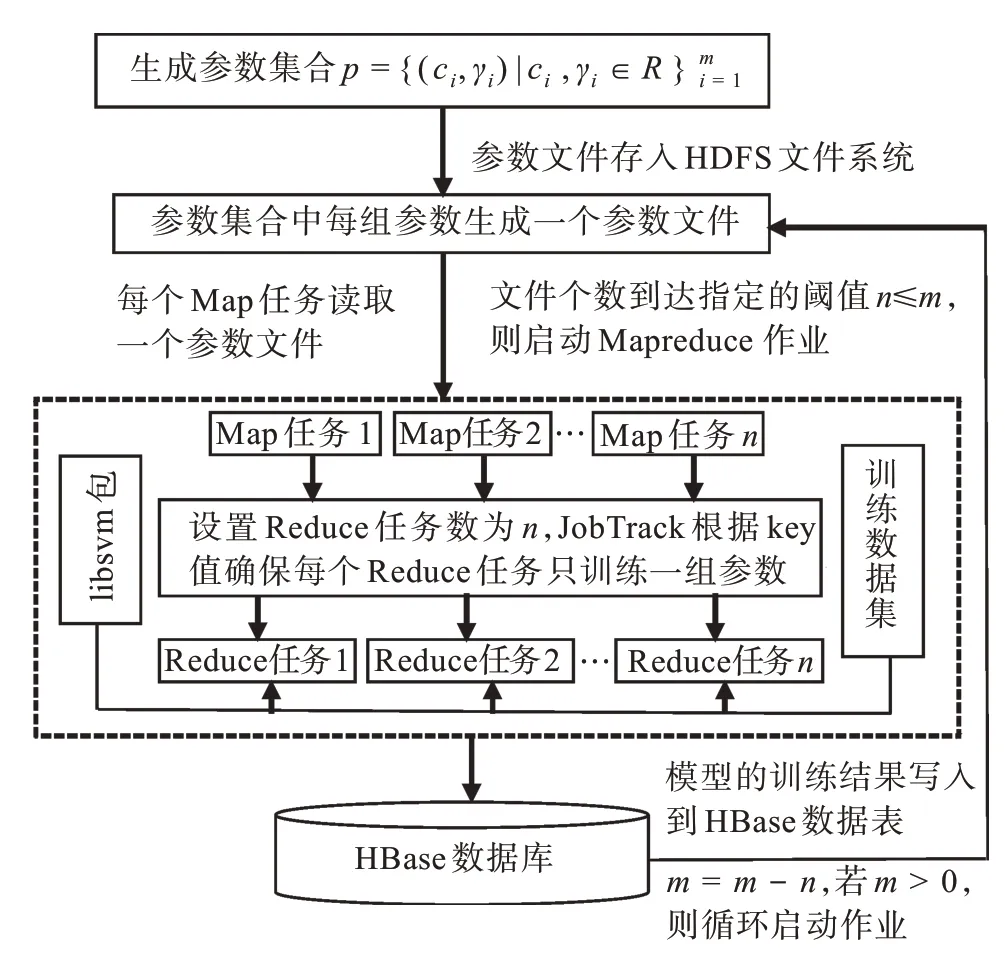
圖1 基于MapReduce的最優模型參數選擇過程Fig.1 Optimal model parameter selection processbased on MapReduce
分布式集群環境下的最優模型選擇的核心思想就是讓多組參數可以同時訓練,以縮短得到最優模型參數的時間。將需要訓練的參數集合參數p={(c i,γi)|c i,γi∈R}m i=1中的每組參數(c i,γi)以一個文件的方式寫入到HDFS文件系統,當文件的個數達到指定的閾值n(n≤m)時,啟動MapReduce作業,通過重載Map任務讀取文件的模式,使得每個Map任務讀取輸入參數文件的所有內容,在確保key唯一后,將<key,參數>寫入到中間結果。由于每組參數的key值不同,且Reduce的個數設置為n,所以JobTrack可以保證每個Reduce任務只訓練一組參數。每個Reduce任務讀取緩存在集群內存中的訓練數據集文件及調用緩存在集群中的libsvm包中的方法訓練模型并進行交叉驗證,模型訓練的結果寫入HBase數據庫,以便對訓練過程進行統計分析。
2.2 最優模型選擇算法設計
由于每組參數的交叉驗證過程要在Reduce任務中完成,增加Reduce的任務并發數顯然可以加快獲得最優模型參數的速度。但是,當并發執行的Reduce任務個數到達一定閾值后,集群的內存資源將被全部占用,從而導致其它的MapReduce作業由于缺少內存資源而無法執行。因此,必須限制并發執行的Reduce的任務個數。一種限制Reduce任務個數的方式為:將需要選擇的m個參數劃分為n個MapReduce作業(J1,J2,…,Jn-1,Jn),n≥1,其中(J1,J2,…,Jn-1)執行mn個參數的驗證,Jn執行m%n個參數的驗證,(J1,J2,…,Jn-1)在JobTrack的控制下串行執行,執行過程如圖2所示。
圖2(a)中的每個Ji中并行執行m n個或者m%n個Reduce任務,矩形條表示每個Reduce任務的完成時間。對于第i個作業Ji,執行交叉驗證耗時最長的Reduce任務完成時間為Ri,由于Ji為串行執行方式,所以使用該方式進行最優參數選擇的總時間G為:

另一種方式為單個MapReduce作業方式,即只啟動MapReduce作業一次,讓m個Reduce任務全部處于就緒狀態,但限制能獲得資源并行執行的Reduce的任務個數為k,k≤m。當某個Reduce任務執行完成后,處于就緒等待隊列中的某個Reduce任務獲得資源開始執行,直到就緒隊列中的所有Reduce任務執行完成。單個MapReduce作業方式的執行過程如圖2(b)所示。
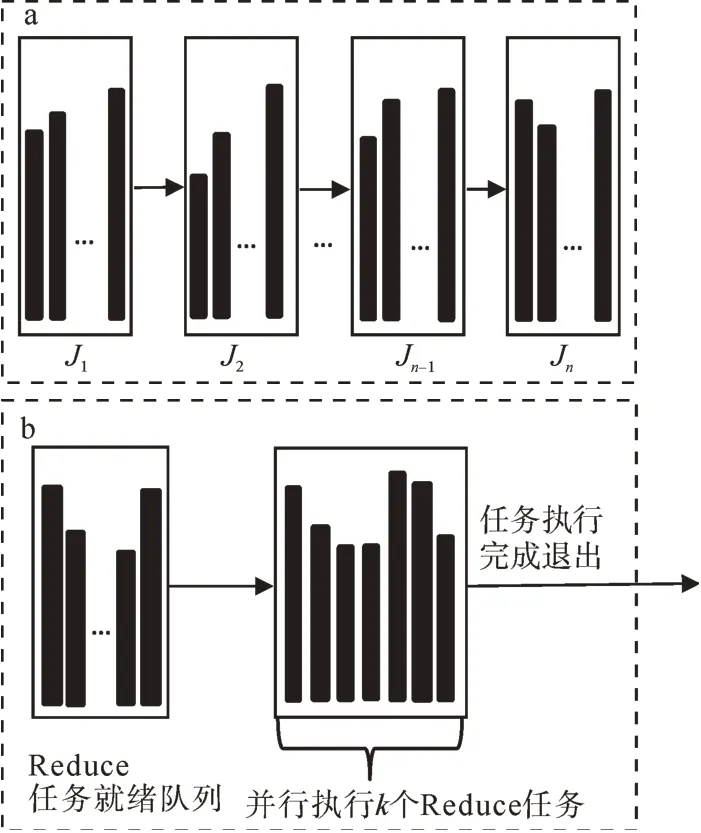
圖2 (a)串行MapReduce作業方式;(b)單個MapReduce作業方式Fig.2(a)Serial MapReduce job mode;(b)Single MapReduce job mode
單個MapReduce作業方式只在執行最后一批k個Reduce任務時,需要等待耗時其中最長的任務執行完成,其它情況下,耗時長的任務將和其它任務一起并行執行。
通過比較兩種MapReduce作業方式可以發現,串行MapReduce作業方式調度簡單,不需要維護額外的Reduce任務就緒隊列或者等待任務執行,但當作業中存在耗時的Reduce任務時,會顯著增加整個作業的完成時間,因此串行MapReduce作業方式適合并行執行的各個Reduce任務的完成時間差距不大的細粒度最優參數搜索。單個MapReduce作業方式只向集群提交一次作業,如果運行失敗,整個參數選擇的過程必須重做。但當作業中包括耗時的Reduce任務時,該作業方式可以使得耗時的任務和其它任務同時執行,從而加快最優參數的獲取速度,因此單個MapReduce作業方式適合Reduce任務的完成時間差距較大的粗粒度最優參數搜索。
SVM最優模型參數選擇的算法流程如圖3所示,其中reduceNums參數用于控制作業中并發執行的Reduce任務的個數,reduceNumsAllowed參數用于控制集群中允許執行的Reduce任務的個數。當reduceNums<=cnum*gnum,reduceNums-Allowed<=reduceNums時為串行MapReduce作業方式。當reduceNums<=cnum*gnum,reduceNums-Allowed<=reduceNums時為單個MapReduce作業方式。
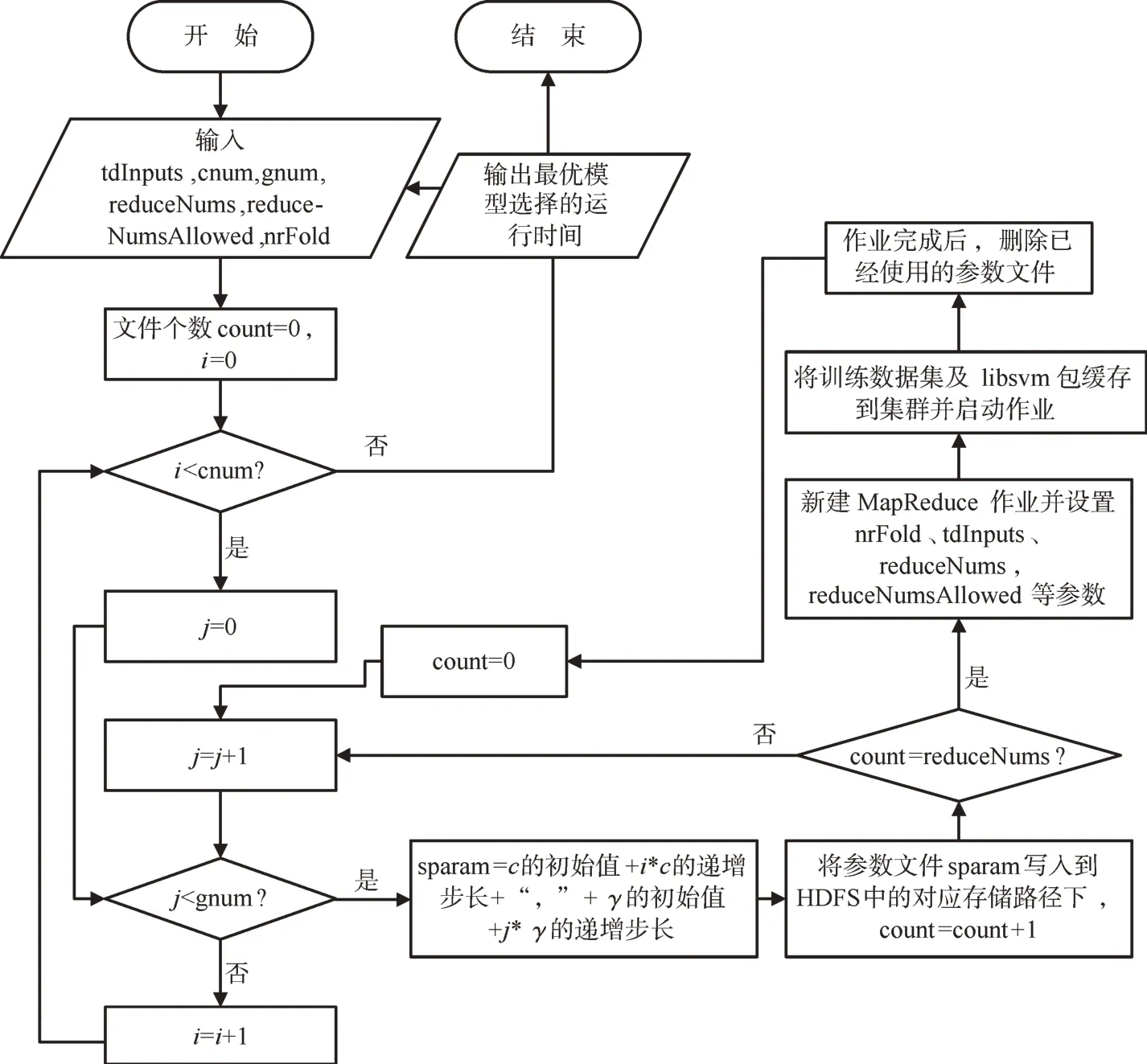
圖3 SVM最優模型參數選擇算法流程圖Fig.3 Flow chart of SVM optimal model parameter selection algorithm
MapReduce作業中的Map任務讀取存儲在HDFS文件系統中的參數文件,并以<key,value>的形式寫成,交給Reduce處理,其算法描述如圖4和圖5所示,其中paramFile表示當前參數文件,context表示MapReduce作業上下文。
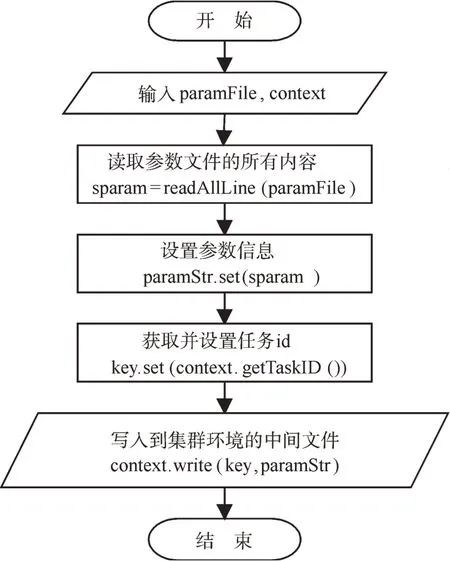
圖4 MapReduce作業中的Map任務流程圖Fig.4 Flow chart of Map task in MapReducejob
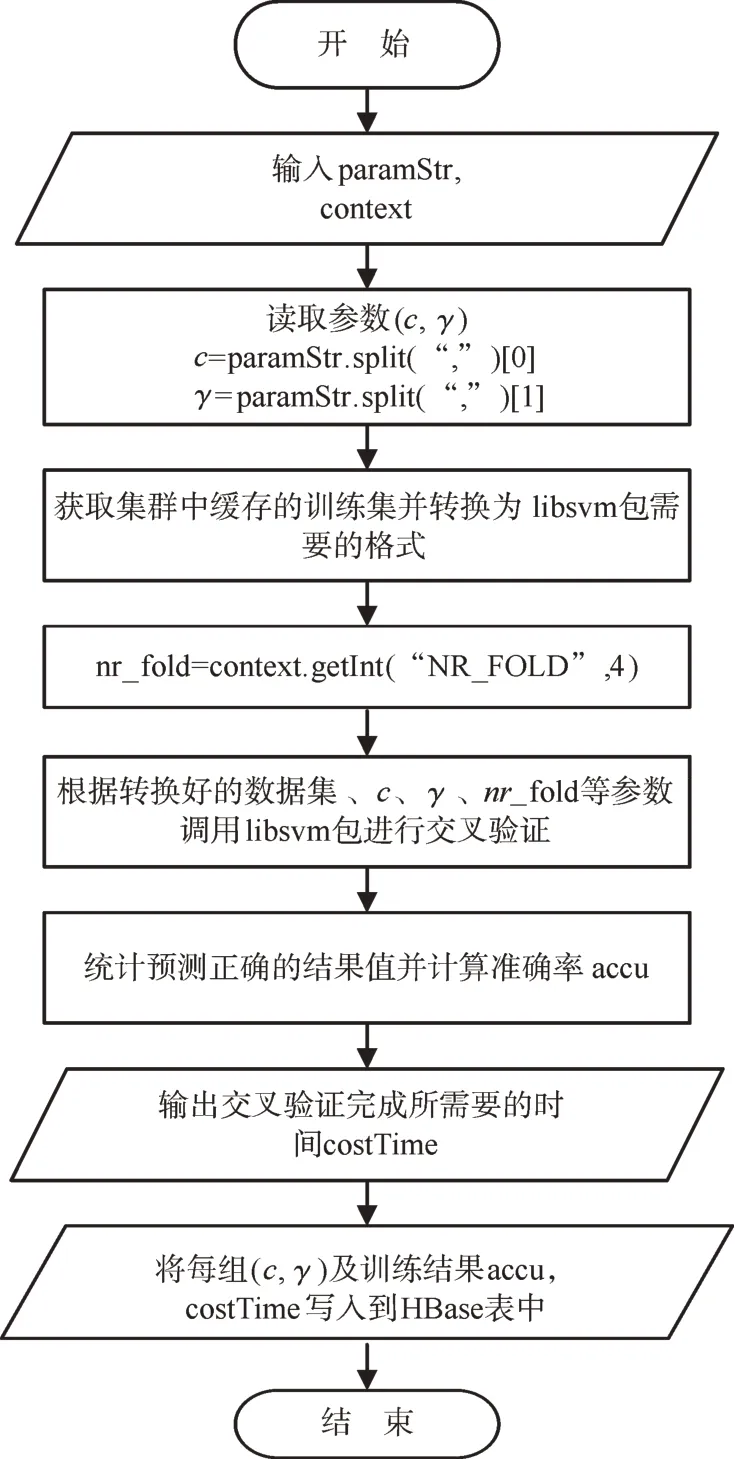
圖5 MapReduce作業中的Reduce任務流程圖Fig.5 Flow chart of Reduce task in MapReduce job
存儲在HDFS文件系統中的參數文件經過Map任務處理后,由于各自的key值不同,所以MapReduce框架的JobTrack把每組參數交給一個Reduce任務來處理,從而使得模型的選擇過程并行化,在Reduce任務的算法描述中,paramStr表示參數字符串,context表示MapReduce作業上下文。
Reduce任務中的交叉驗證過程直接調用libsvm包中的方法完成,訓練數據集中的輸入特征需要按libsvm規定的稀疏矩陣格式進行壓縮,輸入特征值一般需要進行歸一化處理,避免特征值之間的數量級差距過大對訓練算法的影響。在每組參數對應的Reduce任務完成后,將其交叉驗證的結果寫入HBase表,以便對數據進行統計分析,得到最優模型的參數及其它性能指標。HBase的表結構如圖6所示。
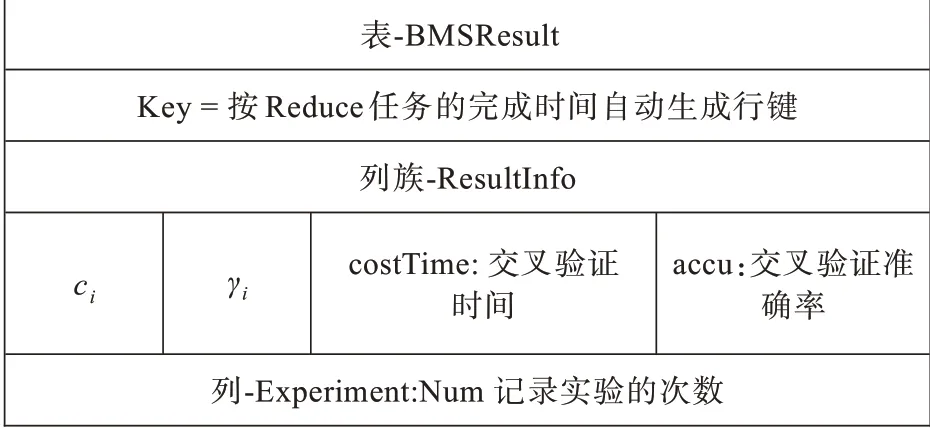
圖6 實驗結果存儲HBase表結構Fig.6 Structure of HBase table of storing experiment results
3 實驗部分
實驗用服務器為DELL PowerEdge R720,其配置為2個物理CPU(Intel Xeon E5-2620 V2 2.10 GHz,每個CPU含6個內核,共12個內核),32 GB內存,8 TB硬盤,4個物理網卡。服務器安裝VMWare esxi6.0.0操作系統,虛擬化整個服務器環境。客戶端使用VMWare VSphere client 6.0.0將服務器劃分為4個虛擬機,每個虛擬機的配置為3內核CPU,8 GB內存,2 TB硬盤,1個物理網卡。每個虛擬機安裝ubuntu-16.04.1-server-amd64操作系統,Hadoop 2.7.3分布式計算平臺,組成含1個主節點,4個數據節點(主節點也是數據節點)的集群。實驗選用https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/中的a8a二分類訓練數據集,a8a共包含22 696條數據,大小在1.6 MB左右。
進行粗粒度參數選擇,比較在Reduce任務完成時間差距較大時,串行MapReduce作業方式和單個MapReduce作業方式在最優模型參數選擇時的時間性能和集群內存消耗上的差別。設置參數nrFold=4,cnum=8,c初始值為0,遞增步長為1,搜索范圍為0~7。參數gnum=8,γ的初始值為0,遞增步長為10-1,搜索范圍為0~10-7。ci和γi的笛卡爾積為64,在這64組參數中進行粗粒度搜索。設置reduceNums/reduceNumsAllowed參數分別為4/4,8/8,16/16,32/32,64/64,即reduceNums<=cnum*gnum,reduceNums=reduceNumsAllowed,進行串行MapReduce作業方式實驗,得到的實驗數據如表1所示。
表1中的Reduce任務的最快、最慢及平均完成時間,均通過查詢統計BMSResult表得到,具體過程在此不詳細描述。分析表1可以發現,1)集群內存資源的消耗隨著并行執行的Reduce的任務個數的增加而增加,當Reduce的任務數量達到32個時,內存被100%全部占用,無法得到內存資源的Reduce任務只能等待正在執行的任務完成后,再由JobTrack調度執行。2)Reduce任務的平均完成時間,隨著并行執行的任務數的增加而增加,說明當集群并發任務數多時,CPU的調度和內存資源的分配緊張,Reduce完成任務的時間增加。3)獲取最優參數的總訓練時間,隨著并行執行的Reduce的任務的個數的增加,MapReduce作業啟動的次數的減少而下降,說明雖然任務并發個數多時,完成每個Reduce任務的平均時間雖然增加,但由于Reduce任務的并發度增加,獲得最優參數的總時間相反會下降。
設置reduceNums/reduceNumsAllowed參數分別為64/4,64/8,64/16,即reduceNums=cnum*gnum,reduceNumsAllowed<reduceNums,進 行 單 個MapReduce作業方式實驗,得到的實驗數據如表2所示。
比較表1中的實驗1-實驗3及表2中的實驗1-實驗3,可發現在內存消耗相等時,粗粒度參數選擇單個MapReduce作業方式獲取最優參數的總時間均優于串行MapReduce作業方式。比較表2中的實驗3和表1中的實驗3,在內存消耗相等時,獲取最優模型的時間性能提高(4 559-3 506)/3 506≈30%;比較表2中的實驗3和表1中的實驗4-實驗5,可以發現單個MapReduce作業方式在僅消耗集群56%的內存時,獲取最優參數的時間與串行MapReduce作業方式消耗100%內存時相近;比較表2中的實驗3和表1中的實驗1,可以發現通過合理的選擇獲取最優參數的方式及設置reduceNums/reduceNumsAllowed參數,在保證集群內存的合理消耗下,獲取最優參數的時間性能提高了(9 599-3 506)/3 506≈174%。
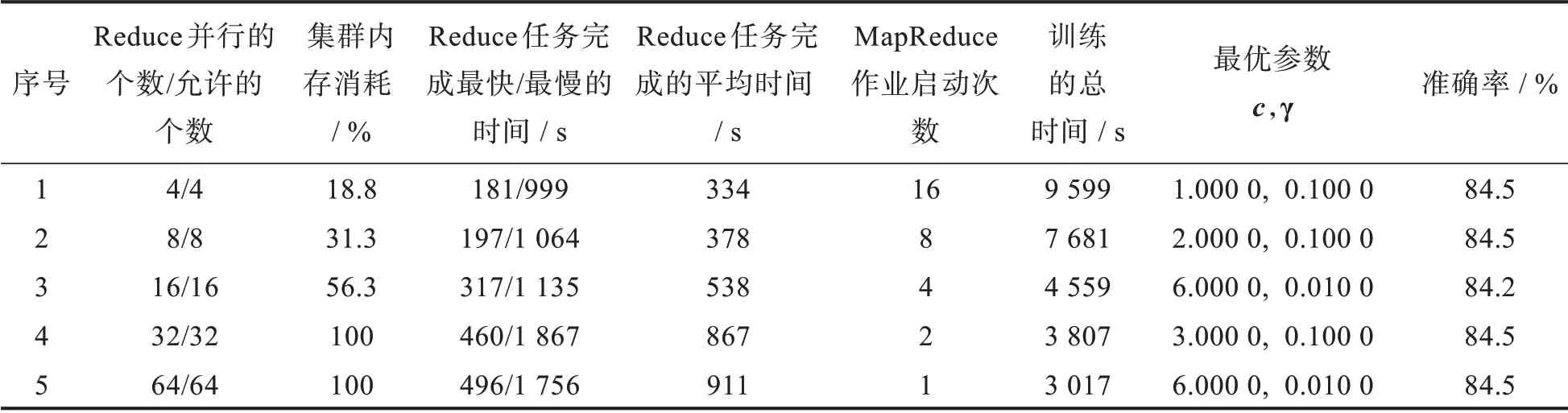
表1 粗粒度參數選擇串行MapReduce作業方式實驗數據表Tab.1 Experimental results of serial MapReduce job mode for coarse-grained parameter selection

表2 粗粒度參數選擇單個MapReduce作業方式實驗數據表Tab.2 Experimental results of single MapReduce job mode for coarse-grained parameter selection
其次,進行細粒度粒度參數選擇,比較在Reduce任務完成時間差距不大時,串行MapReduce作業方式和單個MapReduce作業方式在最優模型參數選擇時的時間性能和集群內存消耗上的差別。設置參數nrFold=4,cnum=8,c初始值為0.5,遞增步長為0.25,搜索范圍為0.5~2.25。參數gnum=8,γ的初始值為0.05,遞增步長為0.012 5,搜索范圍為0.05~0.137 5。設置reduceNums/reduce-NumsAllowed參數分別為4/4,8/8,16/16,64/4,64/8,64/16,得到的實驗結果如表3所示。
比較表3中的實驗1-實驗3和實驗4-實驗6,可以發現在進行細粒度參數選擇時,當Reduce任務的完成時間差距不大時,在同等內存消耗的情況下,兩種MapReduce作業方式在獲取最優模型參數的時間性能上差距不大。
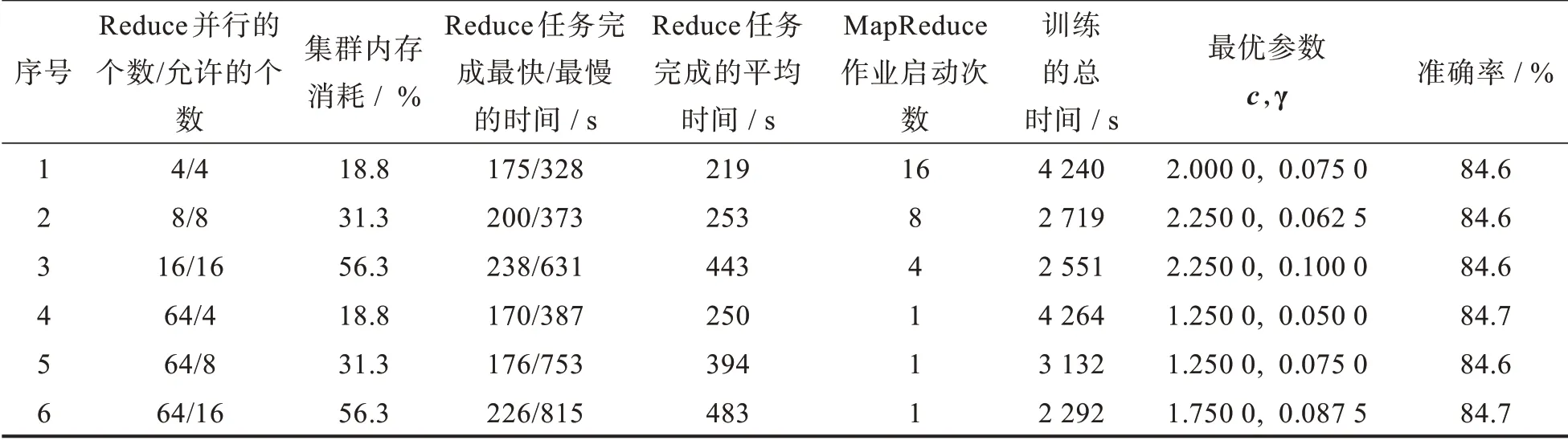
表3 細粒度參數選擇串行/單個MapReduce作業方式對比實驗數據表Tab.3 Comparison of experimental results between serial and single MapReduce job mode for fine-grained parameter selection
4 結 論
SVM分類模型最優參數的選擇是一個非常耗時的過程,本文提出的基于MapReduce框架的最優分類模型參數選擇的算法,能夠在分布式集群環境下,讓模型參數的交叉驗證過程并行執行,并通過選擇不同的MapReduce作業方式,配置集群中的并發任務數,可以在合理的集群內存消耗的情況下,顯著縮短獲取最優參數的時間。后續的研究方向設想為:(1)對于大規模的訓練數據集,可否首先按并行層疊的方式獲取支持向量集合,然后僅根據獲取到的支持向量集合進行最優模型參數選擇,從而減少進行交叉驗證的數據規模,提高獲取最優參數的速度。(2)研究在Spark分布式計算框架進行SVM最優模型參數的選擇的具體方式。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
少年博覽·初中版(2020年6期)2020-06-12 11:42:23
數學物理學報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
光學精密工程(2016年6期)2016-11-07 09:07:19
故事大王(2016年7期)2016-09-22 17:30:08
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
